大模型入门-CSDN博客-AI基础篇
大模型入门CSDN博客
万字长文讲透大模型:从 1943 到 2025,我把 AI 的前世今生给你扒明白了
大家好,我是海宁,好久不见!
熟悉我的老粉都知道,我从 2018 年加入 CSDN,到现在已经肝了 210 篇原创,攒了 87 万 + 访问,8000 多粉丝。之前停更了一段时间,好多朋友私信催更,问我是不是退圈了?
怎么可能!这不,我带着憋了好久的干货回来了!最近后台问得最多的就是:海宁,现在大模型这么火,我一个小白怎么入门?它到底是怎么发展起来的?有啥用?
别急,我花了一周时间,把大模型从诞生到现在的所有关键节点、入门必懂的知识、大家最关心的问题,全都整理成了这篇保姆级文章。不管你是刚接触 AI 的小白,还是想跟上技术浪潮的开发者,看完这篇,你就能彻底搞懂大模型。
先放个我的主页证明一下,这次我要重回江湖,继续和大家一起学技术!
一、大模型的前世今生:80 年的进化之路
很多人以为大模型是最近几年才火起来的新东西?其实早在上世纪 40 年代,科学家们就已经埋下了 AI 的种子,这一路走了 80 年,才走到我们现在的大模型时代。
1. 早期理论奠基:AI 的萌芽期(1940s-1960s)
1943 年,两个名字有点长的大佬 —— 沃伦・麦卡洛克和沃尔特・皮茨,干了一件改变世界的事:他们第一次用数学公式,模拟了人脑神经元的工作方式,造出了全世界第一个神经网络计算模型。
这一下就给 AI 研究开了个好头,也让整个领域分成了两个完全不同的方向:
-
一派想搞懂人脑本身:研究我们的大脑到底是怎么处理信息的,属于生物神经科学的方向;
-
另一派想造机器:想用这个原理,做出能像人一样思考的 AI,这就是我们现在说的人工智能的源头。
到了 40 年代末,心理学家唐纳德・赫布提出了著名的赫布型学习,简单说就是一句大白话:“一起放电的神经元,连接会越来越强”。你可以理解成,我们大脑学东西的时候,用得越多的神经通路,就会越顺畅,记得越牢。这个理论直到现在,还是神经网络学习的核心基础之一。
之后的十几年,大家都在这个基础上摸索:1957 年,弗兰克・罗森布拉特搞出了感知机—— 这可以说是最早的 “AI 分类器”,简单的加减法就能让机器学会识别简单的图案,当时轰动了整个学界,大家都觉得 AI 马上就要成了!
结果没过多久,1969 年,马文・明斯基和西摩尔・派普特浇了一盆冷水:他们发现,感知机连最简单的 “异或问题” 都解决不了 —— 说白了就是,它没法处理 “要么 A 要么 B,但不能同时有” 这种基础逻辑。而且更要命的是,当时的电脑算力太差了,根本跑不动复杂的神经网络。
这一下就把 AI 的研究打入了第一次寒冬,之后十几年,神经网络的研究几乎没人碰了。不过幸好,这些早期的探索没有白费,后来的反向传播算法,就是在这些基础上搞出来的,成了神经网络发展的转折点。
🤔 看完这部分,不妨停下来思考几个问题,帮你加深理解:
-
麦卡洛克和皮茨的神经网络模型,对后来的 AI 研究到底产生了多大的影响?
-
赫布型学习的核心是什么?为什么它能成为神经网络的基础?
-
明斯基提出的那两个问题,为什么会让 AI 研究停滞了十几年?
2. 技术初步发展:AI 的童年期
过了寒冬之后,随着电脑算力慢慢提升,研究者们又开始捡起来神经网络的研究。不过这时候的模型,都还很 “稚嫩”。
当时的模型都很简单,只有几层神经网络,神经元也没多少,说白了就是 “小破模型”。这种模型的好处是简单好懂,研究者调参也方便,能处理一些很简单的任务,比如识别一下手写数字,或者给文本分个类。
但是一遇到复杂点的任务就拉胯了:比如要识别不同场景下的猫,或者理解一段有歧义的话,它就懵了。因为它的结构太简单了,根本学不会复杂的规律,准确率低,换个数据就不行了,泛化能力特别差。
🤔 思考时间:
-
早期模型的 “简单”,给它的性能带来了哪些限制?
-
为什么早期模型处理复杂任务的时候,会准确率低、泛化差?
-
这些问题,给后来的研究者提出了哪些新的方向?
3. 瓶颈与突破:AI 的青春期
到了后来,大家想把模型做大,结果发现遇到了一堆拦路虎。
首先就是算力不够!你想啊,模型越大,参数越多,要算的东西就越多。原来的硬件,单张显卡根本扛不住,就算用多张卡,原来的连接方式速度太慢了,数据传不过来,卡得要死。就好比你有一堆工人,但是他们之间只能靠写信沟通,效率能高吗?
然后还有算法的问题,模型做大了,怎么保证它算得准?怎么让它能处理各种不同的任务?越做越复杂,精度也很难保证。
不过幸好,这些问题都一个个被解决了:
-
尺度定律:大家发现,模型越大,能力就越强!参数从千亿涨到万亿,GPT-4 比 GPT-3.5 强了一大截,就是这个道理。
-
新模型结构:原来的 Transformer 不够用了,大家又搞出了扩散模型、MoE 混合专家模型。MoE 是什么?简单说就是 “专家团队”,原来的模型是所有人一起干所有活,MoE 是把模型分成很多小专家,遇到写代码的找代码专家,遇到做数学的找数学专家,既省算力,效率还高。
-
硬件升级:为了解决卡之间通信慢的问题,中国移动的大佬们搞出了全向智感互联,让所有 GPU 之间都能直接通信,不用绕来绕去,数据传输速度一下就提上来了,大模型训练的速度一下就快了好多。
🤔 思考时间:
-
大模型训练的时候,算力不够到底是卡在了硬件还是软件?
-
像 MoE 这种新结构,提升了性能的同时,会带来什么新问题?
-
全向智感互联的那些优化,是怎么一起把算力提上去的?
4. 深度学习兴起:AI 的成年礼
到了 2010 年之后,深度学习彻底火了,这一下就把 AI 拉上了快车道。
什么是深度学习?简单说就是,我们不用人工给机器教特征了,让机器自己从海量数据里学。以前的 AI,我们要告诉它,猫有耳朵有尾巴,你要找这些特征;现在的深度学习,你给它几百万张猫的图片,它自己就能学会猫长什么样,比我们人工找的特征准多了。
这时候,各种牛逼的模型也出来了:
-
DIFF Transformer:解决了长文本的问题,以前的模型读长文章,读着读着就忘了前面的,这个新的差分注意力机制,让它能读几十万字的长文都不忘,不管是写小说还是处理长文档,都没问题。
-
UniME 多模态框架:这个更厉害,能同时处理文字、图片、语音、视频,把这些信息融合到一起,刷新了好多世界纪录,现在的多模态大模型,很多都是基于这个思路来的。
🤔 思考时间:
-
深度学习自动学特征,在实际任务里到底比人工强在哪?
-
DIFF Transformer 的注意力机制,和原来的有啥不一样?
-
多模态融合的时候,最难的是什么?UniME 是怎么解决的?
5. 大模型时代:AI 的爆发期
然后就到了我们现在的大模型时代!
2018 年之后,GPT 出来了,一下就把整个行业炸了。原来的 AI 都是专才,下围棋的只会下棋,识别图片的只会识别图片,结果大模型出来,直接成了通才!
GPT-3 用 1750 亿参数,一下就能写文章、写代码、翻译、做题,什么都能干;然后 BERT 又搞了双向预训练,理解文本的能力一下就上去了。
然后大模型就开始遍地开花,在各个领域都能用了:
-
自然语言处理领域:聊天机器人、翻译、问答,什么都能做;
-
计算机视觉领域:识别图片、生成图片,你给它一句话,它就能给你画出来;
-
还有医疗、金融、教育,大模型都能进去,帮医生看片子,帮金融分析师做报告,帮老师改作业。
🤔 思考时间:
-
大模型用到不同行业的时候,最难的是什么?
-
怎么把大模型做得又快又好?
-
大模型用多了,会有什么伦理和社会问题?
6. 现在:中国大模型的爆发
现在,国内的大模型也起来了,2023 年被称为 “中国大模型元年”,百度、阿里、字节、清华,好多公司和机构都搞出了自己的大模型。
比如字节的豆包,2024 年上半年下载量就超了 3300 万,月活 2100 万,直接领跑国内 AI 应用;百度的文心一言,也越来越好用,越来越多人用。
不过现在大模型也还有不少问题:
-
数据隐私:训练要用到大量用户数据,怎么保证不泄露?
-
伦理问题:模型会不会学了数据里的偏见,生成有害的内容?
-
就业问题:会不会抢了人的工作?
这些都是我们现在要解决的问题。
🤔 思考时间:
-
怎么在发展大模型的同时,保护用户的隐私?
-
怎么解决大模型的伦理问题?
-
大模型来了,我们普通人该怎么应对就业的变化?
7. 未来:AI 会走向何方?
那未来大模型会变成什么样呢?
首先,算法会越来越强,现在的大模型还是有很多不懂的,未来会有更厉害的语义分析,能真正理解我们说的话,而不是猜下一个词;还有元学习、强化学习,让模型能快速适应新的场景,学新东西越来越快。
然后硬件也会越来越适配,大模型的训练和推理成本会越来越低,以后我们手机上都能跑大模型,不用依赖云端了。
对社会的影响也会很大,大模型会把很多重复性的工作替掉,比如写文案、做表格,但是也会催生很多新的工作,比如大模型训练师、AI 伦理专家,我们要做的,就是跟上这个变化,学会用 AI 工具,提升自己的能力。
🤔 思考时间:
-
除了我们说的这些,大模型的算法还有什么可能的发展方向?
-
怎么应对大模型带来的就业变化?
-
未来大模型还会遇到什么新的挑战?
二、入门必懂:大模型核心知识全梳理
搞懂了历史,你肯定想问:那到底什么是大模型?它和我们以前用的 AI 有啥不一样?别急,这部分我给你讲透最基础的概念,保证小白也能看懂。
1. 到底什么是大模型?
很多人刚接触大模型,第一个问题就是:这玩意到底是啥?和我以前用的 AI 有啥不一样?
很简单,大模型就是参数特别多的深度学习模型,一般参数都超过 10 亿,多的能到万亿。它最大的特点就是通用:
-
以前的 AI 是专才:AlphaGo 只会下围棋,人脸识别只会识别人脸,一个 AI 只能干一件事;
-
大模型是通才:它能写文章、写代码、做题、画图、聊天,什么都能干,就像一个通用的大脑。
很多人问我,参数是什么?为什么参数越大模型越厉害?
你可以把参数理解成模型的 “脑细胞”,就是模型从数据里学到的规律和知识。参数越多,模型的脑容量就越大,能记住的东西就越多,能学会的规律就越复杂,这就是为什么大模型能有 “涌现能力”—— 比如突然就会推理了,突然就会创作了,这都是小模型做不到的。
还有人问,预训练和微调是什么?
这是训练大模型的两个步骤,你可以理解成上学:
-
预训练:就是上大学,让模型在海量的互联网数据里学,学语言、学知识、学逻辑,这一步成本特别高,一般都是大公司来做;
-
微调:就是毕业后找工作实习,用特定领域的数据,比如医疗的、法律的,给模型做针对性的训练,让它变成某个领域的专家,适合企业自己用。
2. 大模型是怎么发展到今天的?
从 2017 年到现在,大模型只用了 8 年,就完成了飞跃,这中间有四个关键的里程碑:
-
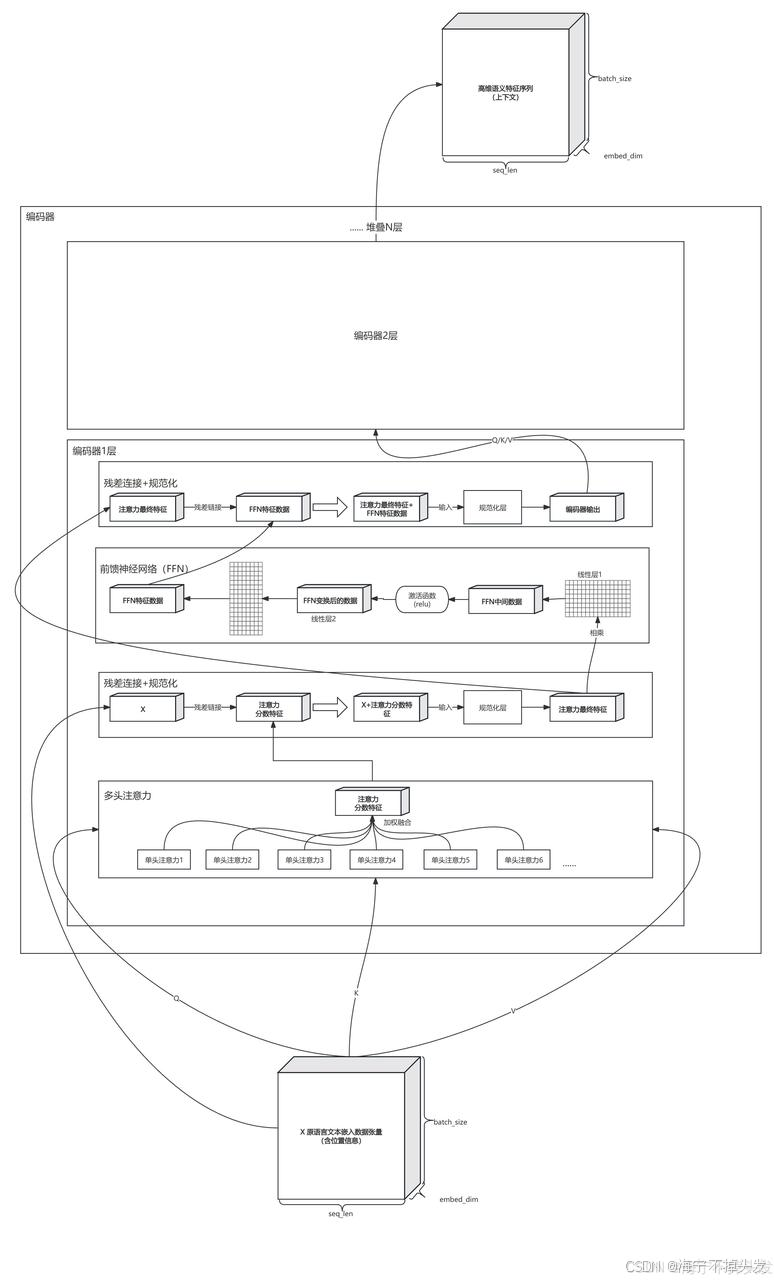
2017 年:Transformer:这是大模型的基石,之前的模型处理文本都是一个词一个词读,读完就忘,Transformer 的自注意力机制,让它能同时看到所有的词,理解上下文,一下就解决了长文本的问题。
-
2018 年:GPT:OpenAI 搞出了 GPT,第一次证明了 “越大的模型越强”,他们用海量数据训练了一个大模型,发现它什么都能干,一下就把 AI 的水平拉上了新台阶。
-
多模态时代:GPT4o:后来大家发现,光处理文字不够啊,还要处理图片、语音、视频,于是多模态大模型就出来了,GPT4o 就是代表,它能同时看图片、听声音、读文字,和人交互就像真人一样。
-
推理时代:o1 和 DeepSeek-R1:到了最近,大家发现,大模型光会生成文字不够,还要会思考,会做数学题、会写代码。于是 OpenAI 搞出了 o1,DeepSeek 搞出了 R1,这些推理模型,能让模型自己在脑子里想,把问题拆开来,一步步解决,就像人做题一样,一下就把复杂推理的能力拉满了,而且成本还降了好多。
3. 现在主流的大模型,都有哪些?
现在市面上的大模型太多了,很多人看了头大,我给你整理了现在最主流的几大家族:
-
GPT 系列(OpenAI):行业老大,不用多说,GPT-3、GPT-4,到现在的 o1 推理模型,一直是行业的标杆,能力最强,但是闭源,要用得调用 API。
-
LLaMA 系列(Meta):开源界的顶流,从 LLaMA1 到 LLaMA3,Meta 把模型开源了,所有人都能拿来改,所以现在国内好多大模型都是基于它改的,特别适合开发者自己玩。
-
01 系列(零一万物):国内的大佬做的,专门针对中文优化,参数量 100B,还有多模态的 Yi-VL,中文处理的能力特别强。
-
GLM 系列(清华智源):清华搞的,国产大模型的代表,ChatGLM-6B 特别小,普通的电脑就能跑,很多人入门大模型都是从它开始的,最新的 GLM-4 已经能和 GPT-4 掰手腕了。
-
Qwen 系列(阿里云):阿里的大模型,从 18 亿到 720 亿参数都有,最新的 Qwen2.5 已经到 3000 亿参数了,支持百万 token 的上下文,你把一整本书丢进去,它都能处理,特别强。
-
DeepSeek(深度求索):专注于推理的大模型,他们的 DeepSeek-R1,推理能力特别强,而且开源,成本还特别低,很多做代码、数学的开发者都喜欢用。
4. 大模型还分类型?生成式和推理型有啥区别?
很多人不知道,大模型还分两种,干的活完全不一样:
-
生成式模型:就是会 “创作” 的模型,写文章、写文案、画图、做视频,都是它干的,比如我们平时用的 ChatGPT 聊天,Stable Diffusion 画图,都是生成式模型,它的任务就是生成新的内容。
-
推理型模型:就是会 “做题” 的模型,解数学题、写代码、分析法律文书,都是它干的,比如 DeepSeek-R1、OpenAI o1,这些模型能逻辑推理,解决复杂的问题,这是生成式模型做不到的。
5. 这些大模型术语,你必须懂
刚接触大模型的人,肯定会被一堆术语搞懵,我给你解释几个最常见的:
-
多模态:就是能处理多种数据,比如文字、图片、语音、视频,以前的模型只能处理文字,多模态的能同时看图片读文字,就像我们人一样,既能看又能听。
-
通用模型:就是什么都能干的模型,比如 GPT-4,你让它干啥它都能试试,适合各种场景。
-
行业模型:就是针对某个行业优化的,比如医疗大模型,专门学了医疗的知识,给医生用;金融大模型,专门学了金融的知识,给分析师用,比通用模型更专业。
-
还有国内大家常用的 AI 工具:DeepSeek(中文好,推理强)、豆包(聊天好用,国内的)、Kimi(能处理长文档,还能画图),这些都是我们平时能用的。
6. 大家最关心的 10 个问题,一次性解答
最后,我整理了大家问得最多的 10 个问题,一次性给你解答清楚:
基础概念类
Q:大模型是怎么生成一句话的?
A:它其实是一个 “猜词游戏”,你输入问题之后,它会算下一个最可能出现的词是什么,输出这个词,然后再用已经生成的词,猜下一个,一直到生成完整个句子。它不是从数据库里抄,是真的自己 “创作” 的。
Q:Transformer 到底是什么?为什么这么重要?
A:它就是大模型的骨架,核心就是自注意力机制,让模型处理每个词的时候,都能同时看到所有其他的词,搞清楚上下文的关系,比如 “它” 指代的是谁,这样就能处理长文本,理解复杂的语义,没有它,就没有现在的大模型。
Q:什么是提示工程?
A:就是怎么和大模型说话,让它给你你想要的答案。比如你要让它写文案,你说 “写个文案” 它可能写不好,但是你说 “你是一个资深的文案,给我写一个面向年轻人的奶茶广告文案,要活泼,100 字以内”,它就能写得很好,这就是提示工程,现在和大模型沟通,已经是一个新的技能了。
应用类
Q:大模型能帮程序员干啥?
A:太多了!代码补全,写代码的时候它给你提示下一行;根据你的描述生成代码;帮你解释复杂的代码,找 bug;甚至帮你把代码从 Python 转成 Java,效率提升不是一点半点,GitHub Copilot 就是干这个的。
Q:大模型在内容创作上能做什么?
A:写文案、写小说、写诗歌、写剧本,都可以;还能帮你总结长文章,提炼会议纪要;甚至根据你的描述生成图片、视频,现在很多博主都是用大模型做内容的。
Q:企业怎么用大模型?
A:一般是微调,或者接外部知识库。比如做智能客服,24 小时在线,能解决复杂问题;做内部的知识管理,把公司的文档都丢进去,员工问啥它都能答;还能做数据分析,你用自然语言问,它就给你生成分析报告。
挑战类
Q:大模型的 “幻觉” 是什么?怎么解决?
A:幻觉就是模型一本正经地胡说八道,生成看起来很对,其实完全错的内容。现在没有完美的解决办法,但是可以缓解:比如重要的信息,你要自己去核实;让模型给你注明来源;用检索增强生成,让模型先去知识库查资料,再回答,这样就不容易瞎说了。
Q:大模型有什么风险?
A:主要有几个:幻觉刚才说了;还有偏见,训练数据里有偏见,模型就会学过去;还有信息安全,有人用它生成钓鱼邮件、恶意代码;还有知识过时,它的知识截止到训练的时候,不知道最新的事,除非接了实时数据。
Q:大模型会让我失业吗?
A:不会,它不会替代人,只会替代不会用大模型的人。它会把重复性的工作替掉,让你从那些无聊的活里解放出来,去做更有创意、更需要情感的工作。会用大模型的人,效率会比原来高好多,反而会更有竞争力。
写在最后
附带文中提到的问题参考答案:
-
麦卡洛克和皮茨的神经网络模型,对后来的 AI 研究到底产生了多大的影响?
答:这个模型是整个神经网络领域的 “开山之作”,它第一次证明了:我们可以用数学公式模拟人脑神经元的工作方式,给后来所有的 AI 研究指明了核心方向。相当于在黑暗里点亮了一盏灯,告诉大家 “造会思考的机器是有可能的”,不管是后来的感知机、深度学习,还是现在的大模型,本质上都是在这个基础上发展来的。 -
赫布型学习的核心是什么?为什么它能成为神经网络的基础?
答:核心就是大脑的 “用进废退” 规则 —— 两个神经元经常一起工作,它们之间的连接就会变强。这个规律完美解释了大脑怎么学习新知识,也给神经网络的训练提供了最基础的逻辑:我们可以通过调整神经元之间的连接强度,让模型学会新的规律。直到现在,不管是深度学习的梯度下降,还是各种优化算法,本质上都是在调整这些连接,所以它成了整个领域的基础。 -
明斯基提出的那两个问题,为什么会让 AI 研究停滞了十几年?
答:因为这两个问题在当时是完全无解的。第一个,感知机解决不了异或问题,相当于直接证明了当时最火的感知机模型,连最基础的逻辑都搞不定,大家一下就发现,原来这个方向根本走不通;第二个,算力不够,当时的电脑连个简单的神经网络都跑不动,更别说复杂的了。那时候大家看不到解决的希望,投资人不愿意投钱,研究者也不愿意做看不到结果的方向,所以整个领域就停滞了十几年。 -
大模型训练的时候,算力不够到底是卡在了硬件还是软件?
答:其实两边都卡。硬件上,单芯片的算力早就跟不上大模型的需求了,而且多张卡之间的通信带宽不够,原来的 PCIe 连接速度太慢,数据传不动,算完了等数据要等半天;软件上,原来的训练算法、并行策略都是针对小模型设计的,大模型用不了,分布式训练的通信开销特别大,很多算力都浪费在传数据上了,所以两边的问题都要解决。 -
像 MoE 这种新结构,提升了性能的同时,会带来什么新的挑战?
答:首先是训练更难了,怎么给任务分配对应的专家?怎么平衡所有专家的负载?不然有的专家忙死有的闲死,训练就不稳定了;然后是推理的调度变复杂了,要快速判断当前的任务该用哪个专家,不然调度的开销反而会把效率拖下来;还有就是模型的泛化性,有的专家只擅长某一类任务,遇到没见过的新任务,就找不到合适的专家来处理了。 -
全向智感互联的那些优化,是怎么一起把算力提上去的?
答:这几个优化是从不同层面一起发力的:首先全方位连接,让所有 GPU 都能直接通信,不用像原来那样绕中转节点,一下就解决了通信延迟的问题;然后优化的报文和协议,减少了通信的额外开销,把网络的利用率提上去了;然后物理层的优化,让数据传得更快更稳,还降低了功耗;最后灵活扩展,加新 GPU 的时候不用改整个架构,想扩就扩。几个点加起来,整个集群的通信效率直接拉满,算力自然就上去了。 -
深度学习自动学特征,在实际任务里到底比人工强在哪?
答:首先是能学非常复杂、抽象的特征,比如图像里的高层语义,人工根本想不到这么复杂的规律;然后是效率高,不用人花几个月甚至几年去做特征工程,模型自己从数据里学,节省了海量的人力;还有就是泛化性好,自动学的特征能适配不同的任务,人工设计的特征往往只能用在特定的任务上,换个场景就没用了。比如人脸识别,人工设计的特征只能认正脸,自动学的能认各种角度、各种光线的脸。 -
DIFF Transformer 的注意力机制,和原来的有啥不一样?
答:原来的注意力机制,要给每两个词都算一次关联权重,长序列的话复杂度是平方级的,特别慢,而且很容易把噪声的权重也算进去,导致模型抓不住重点。DIFF Transformer 的差分注意力,是把注意力的分布做了差分处理,只关注有差异的关键部分,不仅把复杂度降下来了,能处理百万级的长序列,还能过滤掉噪声,抓长距离的依赖更准,不会读了后面就忘前面。 -
多模态融合的时候,最难的是什么?UniME 是怎么解决的?
答:最难的就是不同模态的数据完全不一样:文字是序列、图片是二维的、语音是一维的,怎么把它们映射到同一个空间里,让模型能理解它们的对应关系?还有不同模态的信息密度差很多,怎么平衡它们的权重?UniME 的解决办法就是用了统一的编码器,把所有模态的数据都转换成同一个维度的表示,然后用对比学习让模型学习不同模态之间的对应关系,还加了模态自适应的调整,自动平衡不同模态的信息权重,所以就能很好地把多模态数据融合起来了。 -
大模型用到不同行业的时候,最难的是什么?
答:首先是行业数据少,很多细分行业的标注数据特别少,大模型微调根本不够用;然后是专业知识门槛高,通用大模型没学过行业的专业知识,很容易一本正经地胡说八道;还有合规要求,比如医疗要保密患者数据,金融要符合监管,通用大模型根本满足不了;还有实时性,很多行业需要低延迟的推理,通用大模型太慢了,满足不了业务需求。 -
怎么把大模型做得又快又好?
答:首先是架构优化,比如用 MoE、GQA 这些结构,减少没用的计算量,提升效率;然后是推理优化,比如量化、模型蒸馏,把大模型压缩变小,速度提上来,还不怎么损失精度;还有硬件适配,针对大模型做专门的硬件,比如 GPU 的高速互联,还有专用的 AI 芯片;还有数据优化,用更高质量的清洗过的数据训练,不用堆那么多参数也能达到很好的效果。 -
大模型用多了,会有什么伦理和社会问题?
答:首先是偏见问题,模型会把训练数据里的性别、种族偏见学过来,输出歧视性的内容;然后是虚假信息,模型能生成以假乱真的假新闻、假图片,很容易被用来造谣、诈骗;然后是隐私问题,训练数据里的用户个人信息很容易泄露;还有就业冲击,很多重复性的工作会被替代;还有垄断问题,大模型的技术现在掌握在少数大公司手里,很容易形成技术垄断。 -
怎么在发展大模型的技术的同时,保护用户的隐私?
答:首先是技术手段,比如用联邦学习,不用把用户的数据集中起来训练,各个节点自己训,只传模型参数,不传原始数据;还有差分隐私,给数据加噪声,让模型学不到具体的用户信息;还有数据脱敏,把用户的个人信息都去掉再训练。然后是合规,制定法律规范数据的使用,明确哪些数据能用哪些不能用,给用户数据的知情权和删除权。 -
怎么解决大模型的伦理问题?
答:首先是数据层面,清洗训练数据,把里面的偏见、有害内容都去掉,从源头减少问题;然后是模型对齐,用 RLHF 人类反馈的强化学习,让模型的输出符合人类的价值观;然后是内容审核,给模型加审核机制,生成有害内容就直接拦下来;还有监管,制定行业标准,要求大模型做安全备案和评估,把风险管住。 -
大模型来了,我们普通人该怎么应对就业的变化?
答:首先是把大模型当工具,学会用它提升自己的工作效率,变成 “会用 AI 的人才”,而不是被它替代;然后是转向 AI 替代不了的岗位,比如创意创作、情感沟通、复杂决策这些需要人的温度和判断的工作;还有就是终身学习,不断更新自己的知识,跟上技术的变化,不要停在原来的技能上,比如原来做基础文案的,现在可以转成 AI 内容策划,用 AI 帮你干活。 -
除了我们说的这些,大模型的算法还有什么可能的发展方向?
答:比如神经符号 AI,把神经网络和传统的符号逻辑结合起来,解决大模型的推理和幻觉问题;还有世界模型,让模型能模拟真实世界的物理规律,做预测和规划,比如做机器人的大脑;还有自主智能,让模型能自己主动学习,自己完成复杂的任务,不用人一步步教;还有类脑 AI,模仿人脑的结构做更高效的模型,比现在的 Transformer 更省电、更聪明。 -
怎么应对大模型带来的就业变化?
答:首先是教育改革,学校要提前教大家怎么用 AI,培养新的技能,比如 AI 训练师、提示工程师这些新职业的能力;然后是社会保障,给被替代的工人提供转岗培训和失业保障,帮他们过渡;然后是产业升级,用大模型催生新的产业和岗位,比如 AI 内容创作、AI 咨询、AI 训练这些,抵消原来的岗位减少,总的来说,新岗位的数量其实会比被替代的岗位更多。 -
未来大模型还会遇到什么新的挑战?
答:首先是超级智能的对齐问题,模型越来越强,怎么保证它的目标和人类的一致,不会出现失控的风险;然后是能源问题,大模型越来越大,耗的电越来越多,对环境的压力很大;然后是数字鸿沟,会用 AI 的人越来越强,不会用的人越来越落后,贫富差距会越来越大;还有监管的问题,技术发展太快,监管的速度跟不上,很容易出现各种风险没人管的情况。
好了,这篇万字长文到这里就结束了。
从 1943 年的第一个神经元模型,到现在能推理、能多模态的大模型,AI 用了 80 多年,才从一个科幻的概念,变成了我们每个人都能用到的工具。
我花了一周的时间,把这些内容整理成这篇文章,就是希望能帮更多想入门大模型的朋友,少走弯路,不用再去看那些晦涩的论文,不用再被一堆术语搞懵。
熟悉我的老粉都知道,我一直都是这样,把复杂的技术,用大白话讲给大家听。这次回来,就是想继续做这件事,接下来我还会更新更多大模型的实战内容:比如怎么在自己的电脑上跑本地大模型,怎么微调自己的专属大模型,怎么用大模型提高工作效率,甚至怎么用大模型搞副业。
感兴趣的朋友,点个关注,点个赞,收藏一下,我们一起跟上 AI 的浪潮,一起重回技术的江湖,一起进步!
有什么问题,评论区留言,我都会一一回复!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)