使用UCI数据集进行多模型分类对比及特征选择
采用UCI公开数据集进行随机森林特征选择RF,利用选择后的特征进行分类训练,训练模型采用KNNK邻近,SVM支持向量机,ELM极限学习机,RF随机森林。 对测试机分类结果对比。 代码注释清楚,适合新手学习对比分类模型可以更换。
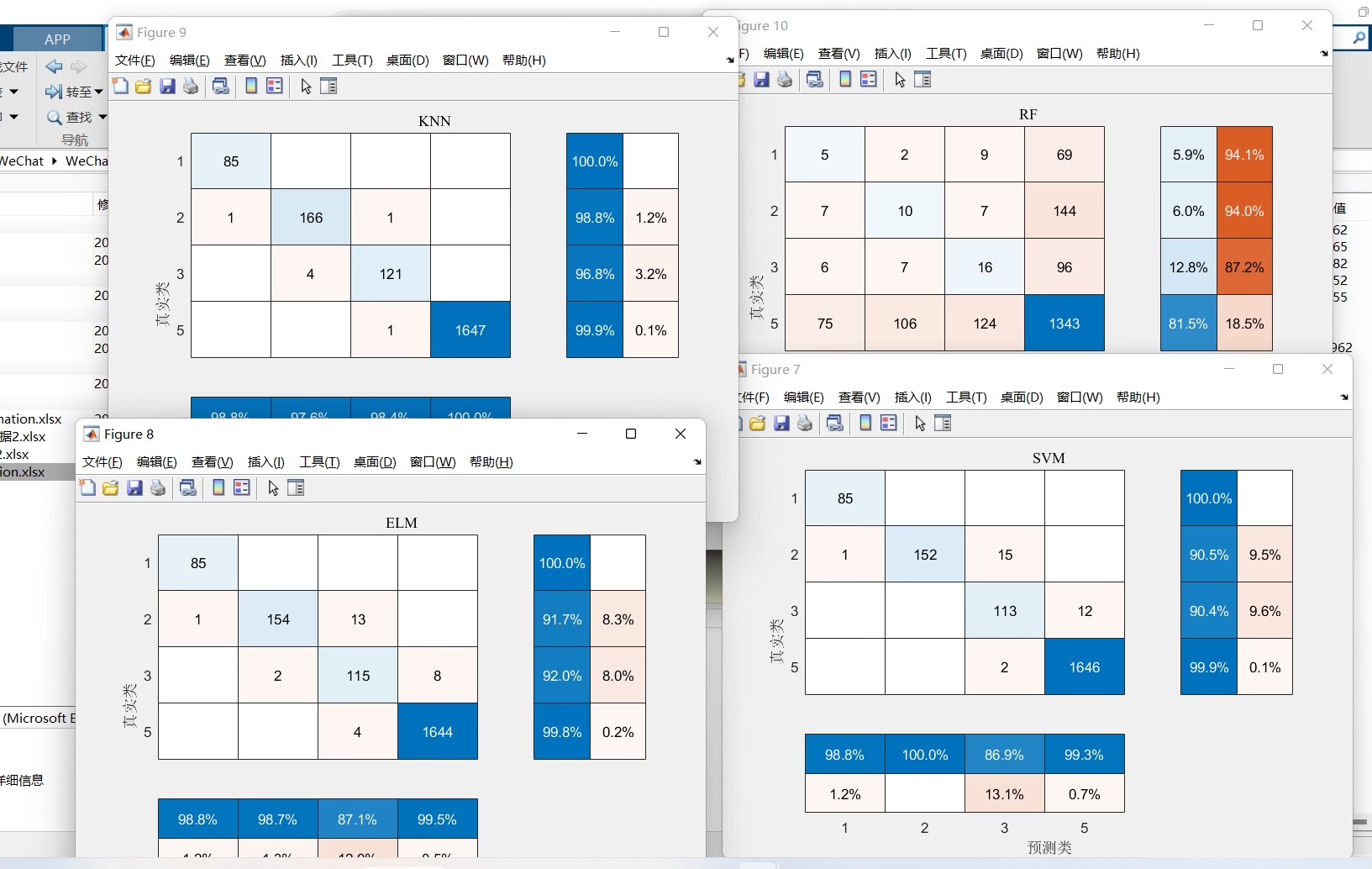
在机器学习的世界里,选择合适的特征和分类模型是提升预测性能的关键。今天咱们就来聊聊如何使用UCI公开数据集,通过随机森林(RF)进行特征选择,然后利用选择后的特征,用KNN(K邻近)、SVM(支持向量机)、ELM(极限学习机)以及RF(随机森林)这些经典模型进行分类训练,并对测试集的分类结果做对比。
1. 数据准备
咱们首先得从UCI下载数据集,这里假设数据集是.csv格式,包含特征和标签。为了方便,我们用Python的pandas库来读取数据。
import pandas as pd
# 读取UCI数据集
data = pd.read_csv('your_uci_dataset.csv')
# 假设最后一列是标签
X = data.iloc[:, :-1]
y = data.iloc[:, -1]上述代码中,pd.read_csv 函数读取了数据集。然后通过切片操作,将特征数据(除了最后一列)赋值给 X,将标签数据(最后一列)赋值给 y。
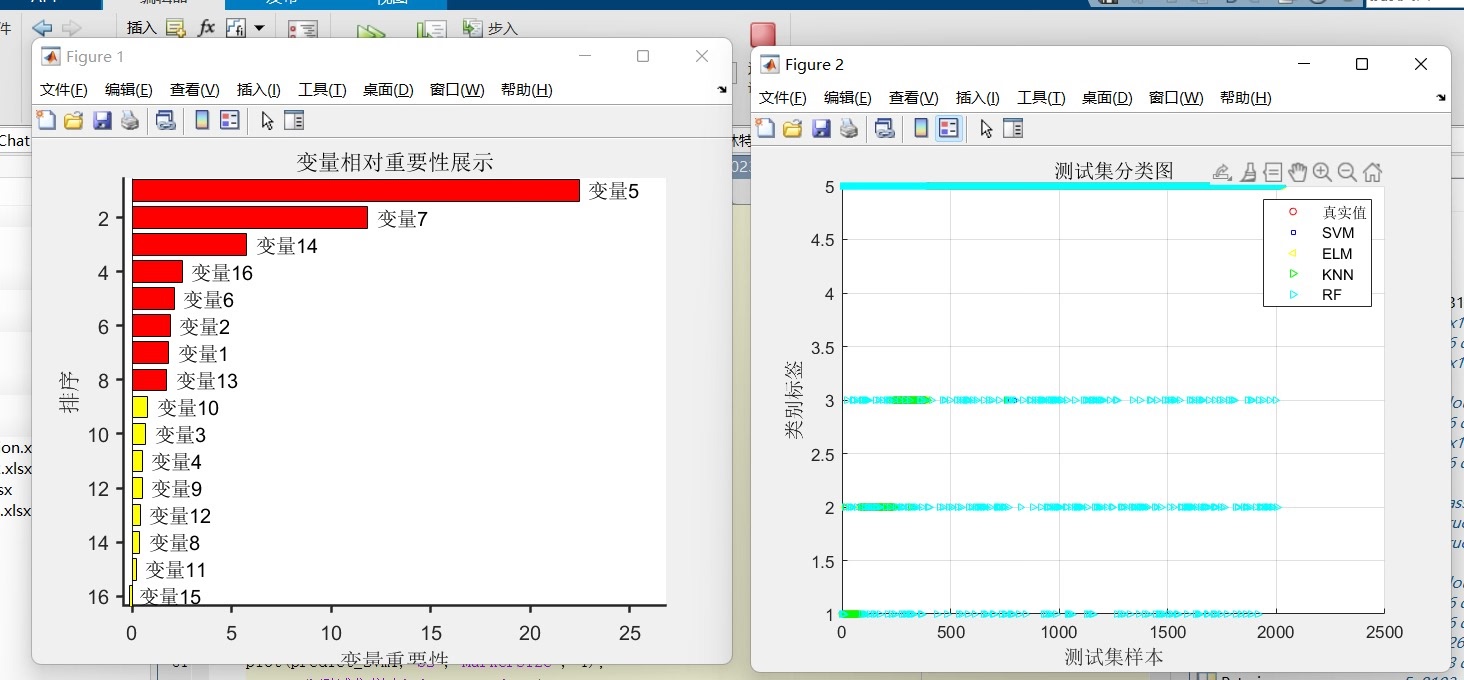
2. 随机森林特征选择(RF)
随机森林不仅可以用于分类,还能用来做特征选择。它通过计算每个特征的重要性,我们可以筛选出重要特征。
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectKBest, f_classif
# 初始化随机森林分类器
rf = RandomForestClassifier()
rf.fit(X, y)
# 获取特征重要性
feature_importances = pd.Series(rf.feature_importances_, index=X.columns)
feature_importances.nlargest(10).plot(kind='barh')
# 选择K个最好的特征
selector = SelectKBest(score_func=f_classif, k=10)
X_selected = selector.fit_transform(X, y)这里,我们先初始化并训练了一个随机森林分类器 rf。通过 rf.featureimportances 获取每个特征的重要性,并使用 SelectKBest 结合 fclassif 这个打分函数,选择了10个最好的特征,得到 Xselected。
3. 分类模型训练
3.1 KNN (K 邻近)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_selected, y, test_size=0.3, random_state=42)
# 初始化KNN分类器,这里K取5
knn = KNeighborsClassifier(n_neighbors = 5)
knn.fit(X_train, y_train)
y_pred_knn = knn.predict(X_test)这段代码中,先把选择特征后的数据划分成训练集和测试集,然后初始化一个K值为5的KNN分类器,训练模型并预测测试集的结果。
3.2 SVM (支持向量机)
from sklearn.svm import SVC
# 初始化SVM分类器,采用rbf核
svm = SVC(kernel='rbf')
svm.fit(X_train, y_train)
y_pred_svm = svm.predict(X_test)这里初始化了一个使用径向基函数(RBF)核的SVM分类器,训练后预测测试集。
3.3 ELM (极限学习机)
from sklearn.elm import ELMClassifier
# 初始化ELM分类器
elm = ELMClassifier()
elm.fit(X_train, y_train)
y_pred_elm = elm.predict(X_test)简单初始化并训练ELM分类器,对测试集做预测。
3.4 RF (随机森林)
# 重新初始化随机森林分类器
rf_new = RandomForestClassifier()
rf_new.fit(X_train, y_train)
y_pred_rf = rf_new.predict(X_test)再次初始化随机森林分类器,训练并预测。
4. 结果对比
from sklearn.metrics import accuracy_score
# 计算KNN的准确率
accuracy_knn = accuracy_score(y_test, y_pred_knn)
# 计算SVM的准确率
accuracy_svm = accuracy_score(y_test, y_pred_svm)
# 计算ELM的准确率
accuracy_elm = accuracy_score(y_test, y_pred_elm)
# 计算RF的准确率
accuracy_rf = accuracy_score(y_test, y_pred_rf)
print(f'KNN准确率: {accuracy_knn}')
print(f'SVM准确率: {accuracy_svm}')
print(f'ELM准确率: {accuracy_elm}')
print(f'RF准确率: {accuracy_rf}')通过 accuracy_score 函数计算每个模型在测试集上的准确率,直观地对比不同模型的性能。这样,我们就能清晰地看到在经过特征选择后,不同分类模型在同一数据集上的表现差异啦。大家可以根据自己的数据集和需求,灵活更换对比的分类模型哦。希望这篇文章对新手朋友们在理解特征选择和多模型对比上有所帮助。
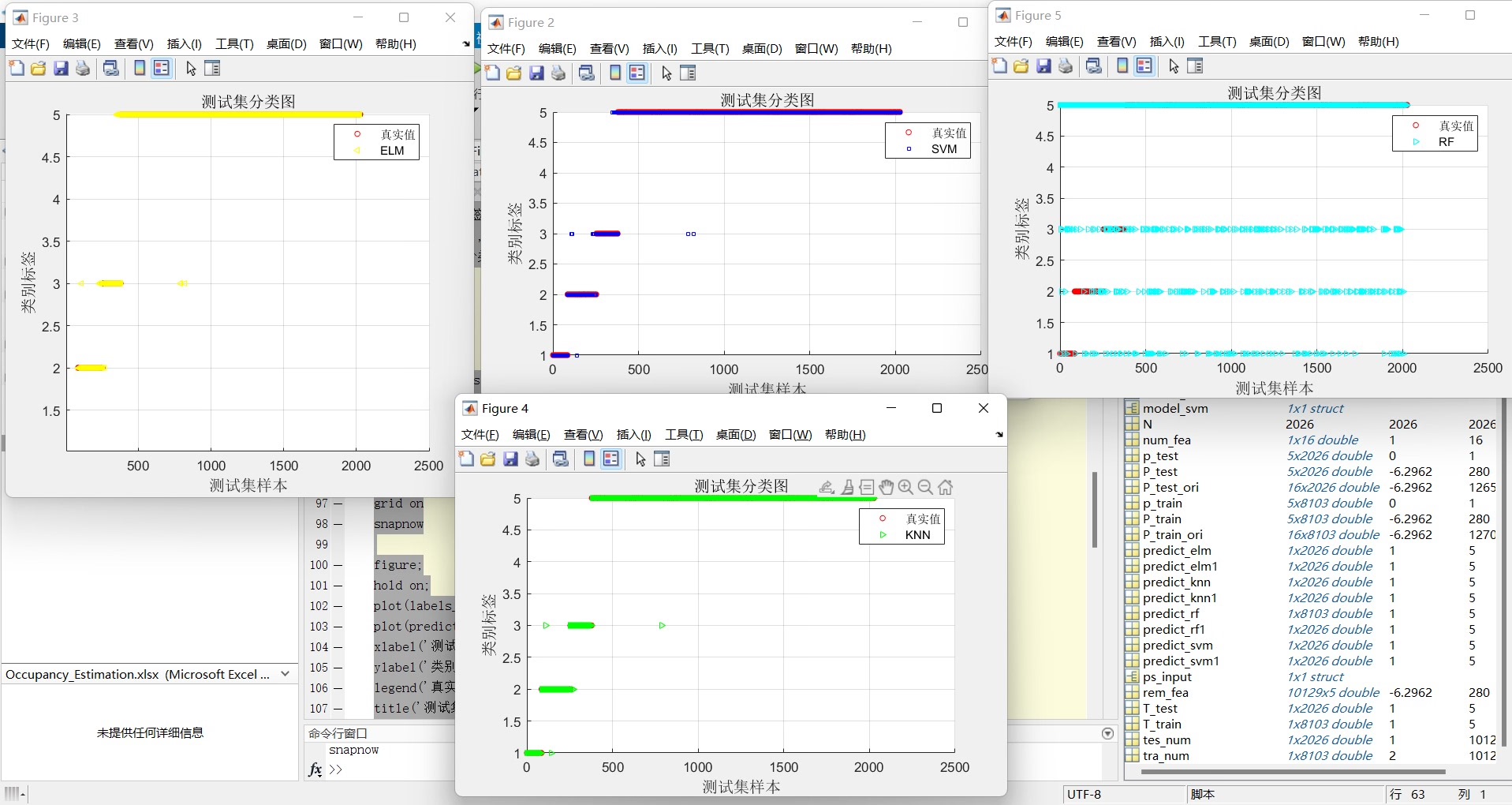
采用UCI公开数据集进行随机森林特征选择RF,利用选择后的特征进行分类训练,训练模型采用KNNK邻近,SVM支持向量机,ELM极限学习机,RF随机森林。 对测试机分类结果对比。 代码注释清楚,适合新手学习对比分类模型可以更换。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)