【深度学习实战】阿里“小云”语音唤醒模型部署全攻略:从环境填坑到执行推理
本文详细介绍了阿里iic实验室开源的speech_charctc_kws_phone-xiaoyun语音唤醒模型的部署过程。该模型基于FSMN-CTC架构,针对移动端优化,具有高效推理能力。文章重点解决了部署中的常见问题:库版本冲突(建议锁定datasets 2.16.0)、缺失依赖包和官方Bug(通过Monkey Patch修复writer属性缺失)。提供了完整的Python推理脚本,并强调音频
1. 背景介绍
语音唤醒(Keyword Spotting, KWS)是智能家居、手机助手的核心功能。本文将带大家部署阿里 iic 实验室开源的 speech_charctc_kws_phone-xiaoyun 模型。该模型基于 FSMN-CTC 架构,专门针对移动端优化,具有极高的推理效率。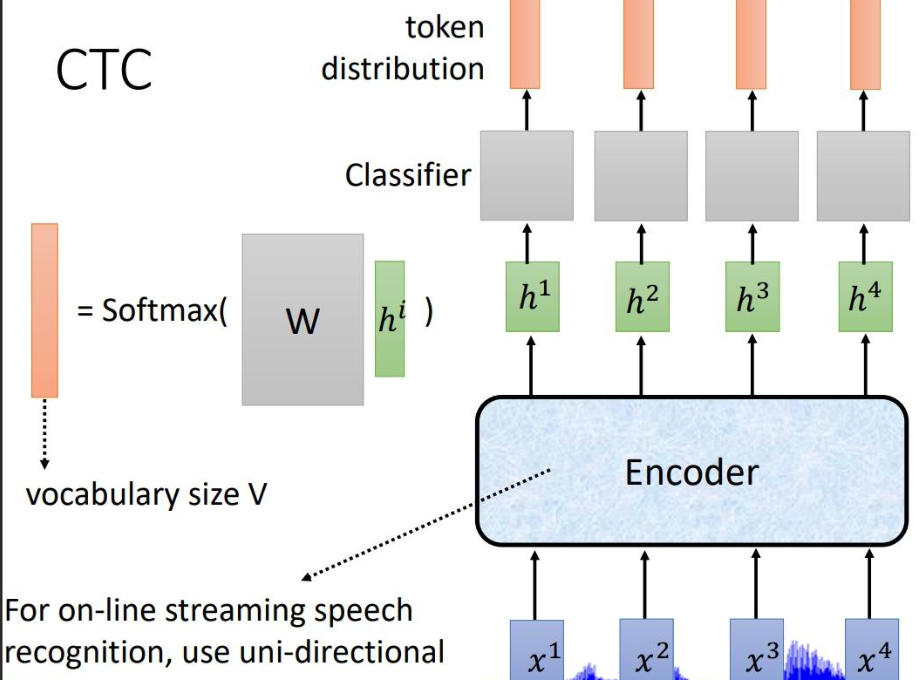
我们将解决部署过程中常见的库版本冲突、缺失依赖包以及官方库内部 Bug 等硬核问题。
2. 实验环境准备
- 硬件:NVIDIA GeForce RTX 4090 D (24GB 显存)
- 操作系统:Linux
- Python 环境:Python 3.11 + PyTorch 2.6.0
- 核心框架:ModelScope (模型下载) + FunASR (推理框架)
3. 环境配置与“填坑”指南
部署的第一步是安装依赖库。由于 Hugging Face 的 datasets 库频繁更新,会导致 ModelScope 报错,我们需要锁定特定版本。
3.1 安装核心库
执行以下命令,建议锁定 datasets 版本以避开 ImportError:
# 卸载可能冲突的旧版本
pip uninstall -y modelscope datasets
# 安装经过验证的稳定组合
pip install modelscope==1.13.3 datasets==2.16.0 funasr==1.3.1 torchaudio
3.2 解决音频后端问题
如果系统没有安装 ffmpeg,torchaudio 会自动接管,但为了保证音频加载不出错,可以额外安装:
pip install soundfile librosa
4. 模型下载
并不是所有的服务器都预装了模型。我们使用 ModelScope 的 SDK 编写一个脚本,将模型下载到本地。
下载逻辑说明:
ModelScope 会将模型下载到 ~/.cache/modelscope/hub/ 目录下。
from modelscope.hub.snapshot_download import snapshot_download
# 指定模型 ID 和版本号
model_id = 'iic/speech_charctc_kws_phone-xiaoyun'
model_dir = snapshot_download(model_id, revision='v1.1.3')
print(f"模型已成功下载至:{model_dir}")
5. 核心代码实现(包含 Bug 修复补丁)
在实际推理中,FunASR 1.3.1 版本在处理 KWS 任务时存在一个内部 Bug(缺少 writer 属性)。我们通过 Monkey Patch(猴子补丁) 动态修复它。
5.1 完整推理脚本 test_kws.py
import os
import sys
import torch
from funasr import AutoModel
from modelscope.hub.snapshot_download import snapshot_download
# 1. 下载并获取模型路径
model_id = 'iic/speech_charctc_kws_phone-xiaoyun'
model_path = snapshot_download(model_id, revision='v1.1.3')
print(f"正在加载模型自:{model_path}")
# 2. 初始化 FunASR 模型
# 必须显式指定 keywords 参数(通常为 '小云小云')
model = AutoModel(model=model_path, keywords="小云小云")
# 3. 【核心补丁】修复 'FsmnKWS' object has no attribute 'writer' 报错
# 这是 FunASR 1.3.1 的一个官方 Bug,手动为其添加日志占位符
if not hasattr(model.model, 'writer'):
model.model.writer = {"detect": {}}
print("已成功应用推理补丁!")
print("--- 模型加载成功 ---")
# 4. 推理测试
audio_path = "test.wav" # 请确保当前目录下有这个 16k 采样率的文件
if os.path.exists(audio_path):
print(f"开始分析音频:{audio_path}")
# generate 推理接口
res = model.generate(input=audio_path, is_final=True)
print("\n" + "="*40)
print(f"最终识别结果: {res}")
print("="*40)
else:
print(f"\n[环境就绪] 请上传 16000Hz 采样率的 {audio_path} 进行测试。")
6. 测试与音频准备
唤醒模型对音频格式有极高的硬性要求,不满足以下条件的音频将无法被识别(结果返回 rejected):
- 采样率:16000 Hz (16k)
- 声道:单声道 (Mono)
- 格式:16bit PCM WAV
6.1 使用 FFmpeg 转换音频
如果你从手机录制的音频(通常是 48k)需要转换:
ffmpeg -i my_voice.wav -ar 16000 -ac 1 -f wav test.wav
6.2 结果分析
运行 python test_kws.py 后,你会看到:
[{'key': 'test', 'text': 'rejected'}]:说明模型正常工作,但音频中未检测到“小云小云”,或采样率不对。[{'key': 'test', 'text': '小云小云', 'score': 0.98}]:恭喜你,唤醒成功!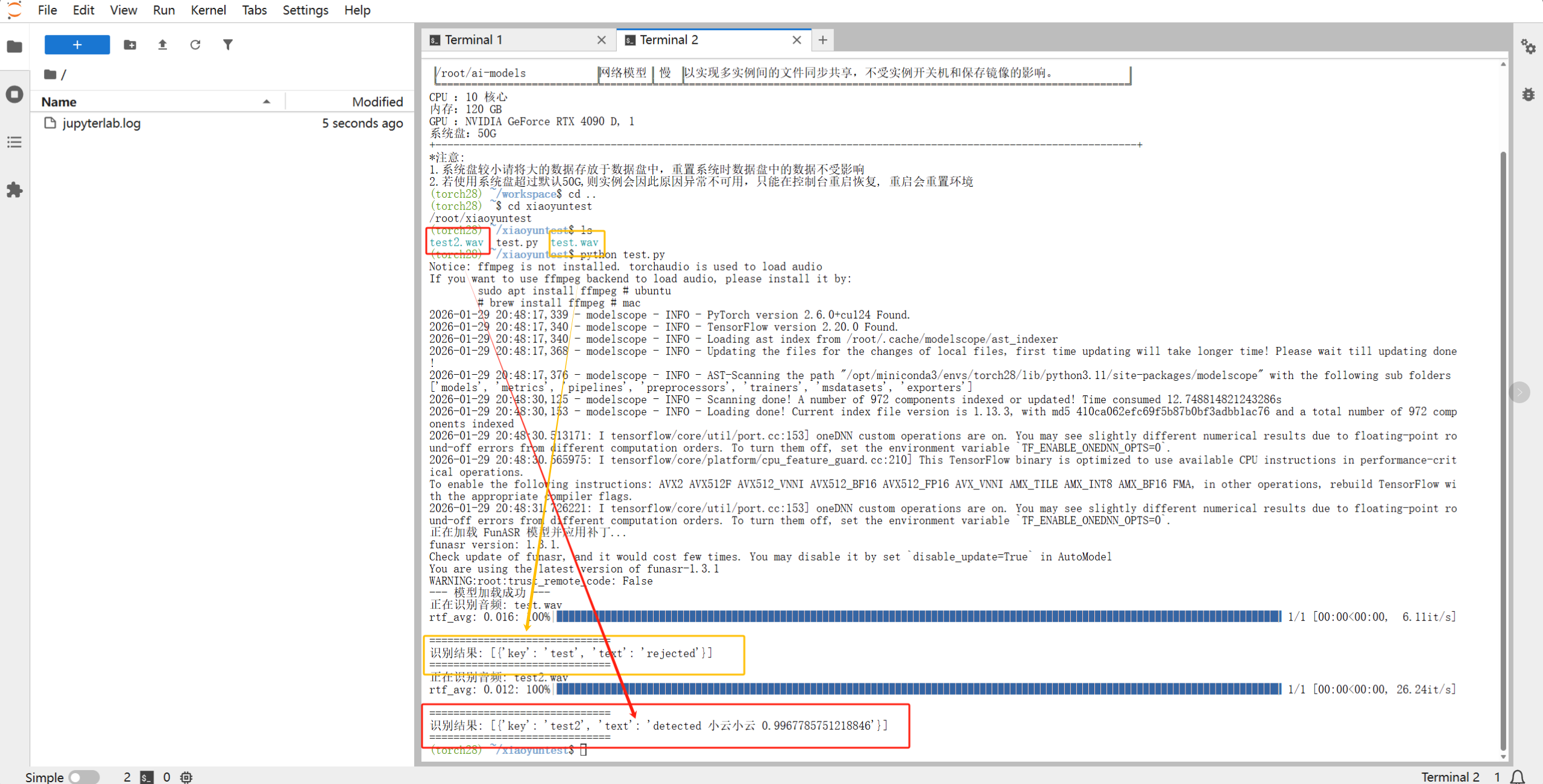
7. 避坑总结
- 路径坑:ModelScope 的
pipeline模式经常找不到kws_util脚本,切换到FunASR框架可以完美避开路径依赖。 - 版本坑:
datasets库一定要降级到2.16.0左右,否则 ModelScope 初始化就会崩溃。 - 补丁坑:报错
AttributeError: ... object has no attribute 'writer'时,不要去改库源码,直接在脚本里用hasattr动态添加属性即可。
8. 结语
阿里小云语音唤醒模型体积小、响应快,非常适合作为 AI 项目的语音入口。通过本文的“保姆级”教学,相信你已经能够在任何 Linux 服务器上流畅运行它。
如果你在部署中遇到其他报错,欢迎在评论区留言讨论!
作者:ChenAI_TGF
发布于:2026年1月

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)