nnU-Net:医学图像分割的自适应自动化框架
食管癌平均 DSC = 40.7;为了解决这些问题,德国癌症研究中心团队提出了 nnU-Net(no-new-UNet),这是一种自配置医学图像分割框架,它能够根据数据集特征自动推导预处理、网络拓扑、训练计划以及后处理策略,从而获得稳健的分割基线。结果非常令人鼓舞,在七大赛道中,nnU-Net 在论文提交时的在线排行榜上除了 brain tumor 数据集中的第一类外,所有任务的所有类别均取得了最

向AI转型的程序员都关注公众号 机器学习AI算法工程
在计算机视觉领域,医学图像分割是一项至关重要的任务,它在临床诊断、放疗计划、辅助导航等场景中发挥着重要作用。然而,医学图像分割面临着诸多挑战,如数据模态和设备差异巨大、传统分割网络需要针对每个任务调整超参数等。为了解决这些问题,德国癌症研究中心团队提出了 nnU-Net(no-new-UNet),这是一种自配置医学图像分割框架,它能够根据数据集特征自动推导预处理、网络拓扑、训练计划以及后处理策略,从而获得稳健的分割基线。本文将详细介绍 nnU-Net 的算法原理、优缺点、评测案例以及 Python 代码实现。
nnU-Net 的算法原理
核心设计理念
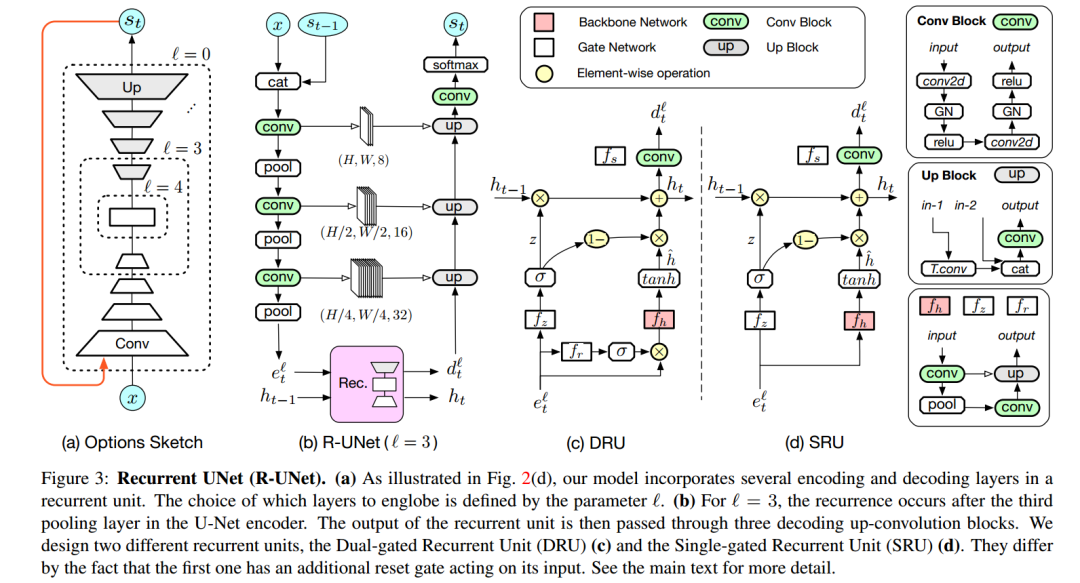
nnU-Net 的核心理念是:在无需专家手动调参的情况下,让框架根据数据集特征自动推导预处理、网络拓扑、训练计划以及后处理策略,从而获得稳健的分割基线。它不是“新网络”,而是 U-Net 的自动化配置引擎,通过规则+数据+经验的三层决策,将 U-Net 的潜力最大化。
核心技术体系
1. 数据集指纹(Dataset Fingerprint)
数据集指纹是数据理解的基石,它提取了数据集的几何特征、模态特征、语义特征和强度统计等信息。这些信息包括:
-
几何特征:图像尺寸、体素间距、非零区域占比
-
模态特征:CT(Hounsfield 单位)、MRI(相对强度)、显微镜(荧光/电子)
-
语义特征:类别数、前景体素占比
-
强度统计:全局/前景的均值、标准差、0.5-99.5 百分位区间(CT 专用)
2. 规则引导的自动配置
规则引导的自动配置是专家知识的代码化,它根据数据集指纹自动生成适合特定数据集的最佳网络结构、学习率调度器以及数据增强策略。具体包括:
网络结构动态生成
-
2D U-Net:适用于各向异性数据(如 MRI 的层间距>2mm),输入切片大小=数据集中最大切片尺寸,池化至特征图<8 像素(最多 6 次)。
-
3D U-Net:基础 patch 体积=min(128³, 显存限制),根据中位体素间距调整长宽高比例(如 512×512×32→匹配 z 轴稀疏性),批量大小≥2(显存不足时缩小 patch)。
-
级联 U-Net:触发条件=重采样后体素数>3D U-Net 单 batch 处理量的 4 倍(如肝脏 CT)。第一阶段低分辨率粗分割(下采样 2-4 倍),第二阶段融合粗结果与原图精修。
预处理流水线
-
裁剪:非零区域最小包围盒(如去除 MRI 背景空气),减少无效计算。
-
重采样:统一至数据集的中位体素间距(图像三次样条,标签最近邻),各向异性先对齐高分辨率轴。
-
归一化:CT 用全局前景百分位截断+Z-score;MRI 用逐病例 Z-score;裁剪超 25%时仅前景归一化。
硬件适配
根据 CUDA_VISIBLE_DEVICES 自动分配显存,动态调整 batch_size(支持 DP/DDP 多卡,级联第二阶段暂不支持 DDP)。
3. 经验优化
经验优化是五折交叉验证的实证选择,它通过五折训练 2D、3D、级联三种模型,选验证集平均 Dice 最高的单模型或集成(最多 5 模型投票)。具体包括:
训练策略
-
损失函数:Dice+CrossEntropy(3D 网络按样本平均,2D 按 batch 伪体积)。
-
数据增强:固定组合(旋转±90°、缩放 0.5-2x、弹性形变 σ=5-15、伽马 0.5-2.0、镜像),3D 极端拉长时切换 2D 增强。
-
级联增强:第二阶段输入的粗分割结果添加随机形态学噪声(腐蚀/膨胀),避免过拟合。
模型选择
五折训练 2D、3D、级联三种模型,选验证集平均 Dice 最高的单模型或集成(最多 5 模型投票)。
后处理
自动判断是否应用最大连通域保留(如肝脏肿瘤去除小噪点),基于验证集前景体素分布决策。
U-Net 结构
U-Net 是一种经典的医学图像分割网络,它由编码器和解码器组成,编码器用于提取图像特征,解码器用于恢复图像细节。以下是 U-Net 的结构示意图:
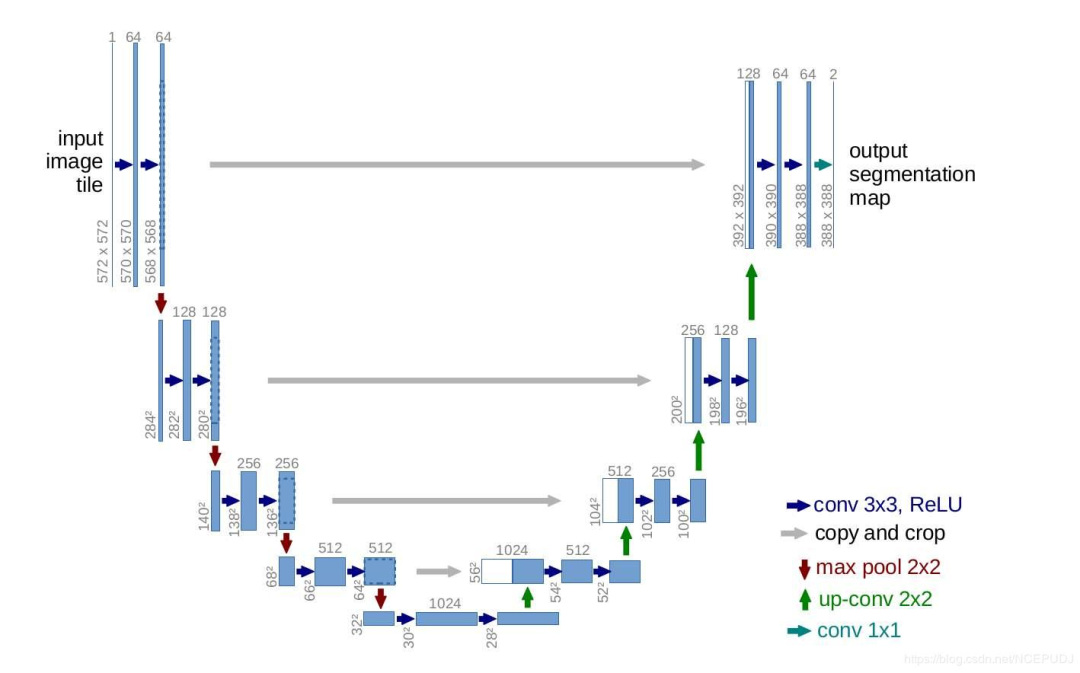
U-Net 的主要特点是:
-
编码器:由多个卷积层和池化层组成,用于提取图像的多尺度特征。
-
解码器:由多个反卷积层和卷积层组成,用于恢复图像的细节。
-
跳跃连接:将编码器的特征图与解码器的特征图进行拼接,用于保留图像的细节信息。
nnU-Net 的优缺点
优点
-
高效性:由于引入了大量经验驱动的设计决策,使得研究人员不需要花费过多时间去探索最佳实践组合即可获得良好性能的结果。
-
泛化能力强:无论面对何种规模或者复杂性的新问题实例时都能表现出稳定可靠的解答质量水平;这得益于内部复杂的正则项机制防止过拟合现象发生的同时还保留足够的表达自由度以便捕捉潜在模式特征。
-
易于部署:整个过程完全由脚本控制完成,极大地降低了技术门槛,让更多的临床医生也能参与到先进算法的应用实践中来。
-
性能表现优异:基于数据驱动的配置策略,模型能自适应数据集特性,分割准确率与鲁棒性远超同类工具。
-
工程化成熟:代码结构清晰、文档完善,支持多 GPU 训练、断点续训、结果自动评估,具备工业级落地潜力。
-
生态完善:兼容主流医学影像格式(DICOM、NIfTI),支持与医学影像处理软件(如 3D Slicer)联动。
缺点
-
灵活性不足:自适应配置策略限制了用户对模型结构的深度定制,难以满足特殊场景(如小样本、极端不平衡数据)的个性化需求。
-
计算资源依赖:3D U-Net 架构对硬件要求较高,训练大规模 3D 影像(如全脑 MRI)需多 GPU 支持,单机单卡训练速度较慢。
-
非医学场景适配差:设计初衷聚焦医学影像,对自然图像分割等非医学场景的支持不足,数据预处理 pipeline 难以直接复用。
-
实时性欠缺:推理阶段对大尺寸影像需分块处理,实时性表现一般,难以满足临床实时分割的需求。
-
依赖专业数据格式:对医学影像格式(如 DICOM)的依赖较强,普通用户需额外学习数据格式转换,增加使用成本。
nnU-Net 的评测案例
案例 1:医学分割十项全能挑战赛
nnU-Net 参加了医学分割十项全能挑战赛,这是一个非常严苛的测试,涵盖了实体识别、图像模块、几何结构和数据集规模等多个维度,要求参赛者不得对不同数据集进行人工调整。结果非常令人鼓舞,在七大赛道中,nnU-Net 在论文提交时的在线排行榜上除了 brain tumor 数据集中的第一类外,所有任务的所有类别均取得了最高平均 Dice 分数,这充分证明了 nnU-Net 的鲁棒性和强大的跨数据集及泛化能力。
案例 2:鼻咽癌 GTV 分割
本研究旨在开发鼻咽癌(NPC)放疗计划 CT 图像的 GTV 自动分割流程,并评估放射学、临床及综合特征对 DFS 的预测性能。采用 nnU-Net 模型在 SeGrap2023 数据集上训练,五折交叉验证 DSC 达 0.79,但跨机构测试时 DSC 骤降至 0.36,表明领域转移显著影响分割效果。结合 Acibadem 和 SeGrap2023 数据集后,nnU-Net 平均 DSC 为 0.73。DFS 预测中,结合放射学与临床特征的特征集 AUC 最高(0.79),优于单一特征组。结论表明多机构训练可缓解领域转移,提升分割鲁棒性,而整合多模态特征能有效提高 DFS 预测精度,为个性化放疗管理提供支持。
案例 3:PET-CT 肿瘤分割
本研究首次对 nnU-Net 在 PET-CT 上进行跨癌症评估,引入了两个新的、专家标注的全身数据集:279 名食管癌患者(澳大利亚队列)和 54 名肺癌患者(印度队列)。这些队列补充了公共 AutoPET 数据集,能够系统地测试跨领域性能。我们在三种范式下训练和测试 3D nnU-Net 模型:仅目标(食管癌)、仅公共(AutoPET)和联合训练。对于测试集,仅食管癌模型在域内准确性最高(平均 DSC = 57.8),但在外部印度肺癌队列上失败(平均 DSC ≤3.4),表明严重过拟合。仅公共模型泛化更广泛(AutoPET 上平均 DSC = 63.5,印度肺癌队列上平均 DSC = 51.6),但在澳大利亚食管癌队列上表现不佳(平均 DSC =26.7)。联合方法提供了最平衡的结果(肺癌平均 DSC = 52.9;食管癌平均 DSC = 40.7;AutoPET 平均 DSC = 60.9),减少了边界误差并提高了所有队列的鲁棒性。这些发现表明,数据集多样性,特别是多人口统计学、多中心和多癌症整合,比架构新颖性更能决定分割模型的稳健性和泛化性。
nnU-Net 的 Python 代码实现
环境准备
首先,我们需要安装 nnU-Net 和相关依赖:
# 安装依赖
pip install torch numpy scipy simpleitk numba matplotlib
# 安装 nnU-Net
pip install nnunetv2数据准备
nnU-Net 期望数据集以结构化的格式存在,这种格式受到医学分割十项全能赛(Medical Segmentation Decathlon)数据结构的启发。从版本 2 开始,我们支持多种图像文件格式(.nii.gz、.png、.tif 等)。以下是一个简化版的数据准备代码,将 DICOM 格式转换为 nnU-Net 标准 NIfTI 格式:
import osimport SimpleITK as sitkimport numpy as npdef prepare_nnunet_data(raw_data_dir, output_dir): """ 简化版数据准备:将 DICOM 格式转换为 nnU-Net 标准 NIfTI 格式 """ # 创建 nnU-Net 标准目录结构 os.makedirs(os.path.join(output_dir, "imagesTr"), exist_ok=True) os.makedirs(os.path.join(output_dir, "labelsTr"), exist_ok=True) # 遍历原始 DICOM 数据 for patient_id in os.listdir(raw_data_dir): patient_dir = os.path.join(raw_data_dir, patient_id) if not os.path.isdir(patient_dir): continue # 读取 DICOM 图像 img_reader = sitk.ImageSeriesReader() img_filenames = img_reader.GetGDCMSeriesFileNames(patient_dir) img_reader.SetFileNames(img_filenames) img = img_reader.Execute() # 读取标签(假设标签为单独的 DICOM 序列) label_dir = os.path.join(patient_dir, "label") label_filenames = img_reader.GetGDCMSeriesFileNames(label_dir) img_reader.SetFileNames(label_filenames) label = img_reader.Execute() # 保存为 NIfTI 格式(nnU-Net 标准命名:patient_id_0000.nii.gz,0000 表示模态) sitk.WriteImage(img, os.path.join(output_dir, "imagesTr", f"{patient_id}_0000.nii.gz")) sitk.WriteImage(label, os.path.join(output_dir, "labelsTr", f"{patient_id}.nii.gz"))# 调用示例prepare_nnunet_data(raw_data_dir="./raw_dicom", output_dir="./nnunet_data")# 调用示例
prepare_nnunet_data(raw_data_dir="./raw_dicom", output_dir="./nnunet_data")模型训练
nnU-Net 提供了一系列命令行工具来进行模型训练。以下是一个简化版的训练代码:
import subprocess# 定义要运行的命令,这里以 nnUNetv2_train 为例,实际参数需要根据你的训练任务设置# 例如:nnUNetv2_train DATASET_NAME_OR_ID 3d_fullres 0# 我们将命令拆分成一个列表command = [ "nnUNetv2_train", "DATASET_NAME_OR_ID", # 替换为实际的数据集名称或 ID "3d_fullres", # 配置名称 "0", # fold 号 # 可以添加其他参数,如 --npz(保存 softmax 预测)等]try: # 运行命令 result = subprocess.run(command, check=True, text=True, capture_output=True) # 打印标准输出 print("输出:", result.stdout) # 如果有标准错误,打印出来 if result.stderr: print("错误:", result.stderr)except subprocess.CalledProcessError as e: print(f"命令执行失败,返回码: {e.returncode}") print("错误输出:", e.stderr)except Exception as e: print(f"发生未知错误: {str(e)}")模型推理
训练完成后,我们可以使用训练好的模型进行推理。以下是一个简化版的推理代码:
import subprocess# 定义要运行的命令,这里以 nnUNetv2_predict 为例,实际参数需要根据你的推理任务设置# 例如:nnUNetv2_predict -i INPUT -o OUTPUT -d 4 -c 2d -f 0 --save_probabilities# 我们将命令拆分成一个列表command = [ "nnUNetv2_predict", "-i", "INPUT", # 输入目录 "-o", "OUTPUT", # 输出目录 "-d", "4", # 数据集 ID "-c", "2d", # 配置名称 "-f", "0", # fold 号 "--save_probabilities" # 保存 softmax 预测]try: # 运行命令 result = subprocess.run(command, check=True, text=True, capture_output=True) # 打印标准输出 print("输出:", result.stdout) # 如果有标准错误,打印出来 if result.stderr: print("错误:", result.stderr)except subprocess.CalledProcessError as e: print(f"命令执行失败,返回码: {e.returncode}") print("错误输出:", e.stderr)except Exception as e: print(f"发生未知错误: {str(e)}")结论
nnU-Net 是一种非常强大的医学图像分割框架,它通过自动化配置流程,能够根据数据集特征自动推导预处理、网络拓扑、训练计划以及后处理策略,从而获得稳健的分割基线。它在多个医学图像分割任务中表现出色,包括肿瘤分割、器官分割、细胞分割等。然而,nnU-Net 也存在一些缺点,如灵活性不足、计算资源依赖等。未来,我们可以通过引入更多的自动化机制和优化策略,进一步提升 nnU-Net 的性能和易用性。
参考文献
-
Isensee F, Jaeger PF, Kohl SAA, Petersen J, Maier-Hein KH. nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation. Nat Methods 2020; Published December 7, 2020. doi: 10.1038/s41592-020-01008-z.
-
nnU-Net 学习与思考 - CSDN 博客. https://blog.csdn.net/qq_68418742/article/details/154493663.
-
nnUNet 项目深度分析 - CSDN 博客. https://blog.csdn.net/weixin_46041161/article/details/155002490.
-
多机构深度学习在鼻咽癌的 GTV 分割和生存预测中的应用 - 生物通. https://m.ebiotrade.com/newsf/2026-2/20260224001548128.htm.
-
Stress-testing cross-cancer generalizability of 3D nnU-Net for PET-CT tumor segmentation: multi-cohort evaluation with novel oesophageal and lung cancer datasets. https://web3.arxiv.org/pdf/2508.18612.
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)