Kafka Connect框架:构建可靠的数据管道
Kafka Connect支持两种运行模式:独立模式和分布式模式。独立(Standalone)模式所有组件运行在单个进程中适合开发、测试或小规模部署配置通过属性文件静态定义不提供自动容错和扩展能力分布式(Distributed)模式多个Worker节点组成集群支持自动负载均衡和故障转移通过REST API动态管理配置提供水平扩展能力和高可用性实践建议:虽然独立模式配置简单,但在生产环境中,强烈推荐
在当今数据驱动的世界里,如何高效地在不同系统间移动数据已成为企业的关键挑战。就像城市需要完善的交通网络一样,现代企业也需要强大的数据管道来保证信息的流动。本文将深入探讨Kafka Connect这一强大的数据集成框架,带你掌握构建高效可靠数据管道的核心技术。
1. 引言
Kafka生态系统与Kafka Connect的定位
Apache Kafka作为一个分布式流处理平台,已经成为许多企业数据基础设施的核心。而在这个生态系统中,Kafka Connect就像是连接各个数据系统的"万能适配器",它专注于数据的进出,将数据从外部系统导入到Kafka(Source),或从Kafka导出到外部系统(Sink)。
如果把Kafka比作一个繁忙的高速公路系统,那么Kafka Connect就是连接各个城市与高速公路的出入口匝道,确保数据能够顺畅地在不同系统间流动。
传统数据集成的痛点
在Kafka Connect出现之前,工程师们通常面临以下挑战:
- 重复开发:为每个数据源编写定制代码,劳动密集且易出错
- 运维复杂:各种自定义脚本和程序需要单独维护和监控
- 扩展困难:难以应对数据量增长或添加新的数据源
- 容错能力差:自定义解决方案通常缺乏完善的错误处理机制
- 一致性保障弱:难以确保数据的准确性和完整性
目标读者和收益
本文适合以下人群阅读:
- 数据工程师和架构师
- DevOps和SRE团队成员
- 对数据集成感兴趣的后端开发人员
- 希望构建实时数据管道的技术决策者
阅读本文,你将获得:
- 深入了解Kafka Connect的核心概念和工作原理
- 掌握配置和部署Kafka Connect的实用技巧
- 学习如何解决实际项目中的常见问题
- 获取构建企业级数据管道的最佳实践
接下来,让我们一起深入Kafka Connect的世界,探索这个强大框架的内部机制。
2. Kafka Connect基础概念
在开始构建数据管道之前,我们需要理解Kafka Connect的基础架构和核心组件。就像学习驾驶之前需要了解汽车的结构一样,掌握这些基础知识将帮助你更好地驾驭Kafka Connect。
Connect架构概述
Kafka Connect支持两种运行模式:独立模式和分布式模式。
独立(Standalone)模式:
- 所有组件运行在单个进程中
- 适合开发、测试或小规模部署
- 配置通过属性文件静态定义
- 不提供自动容错和扩展能力
分布式(Distributed)模式:
- 多个Worker节点组成集群
- 支持自动负载均衡和故障转移
- 通过REST API动态管理配置
- 提供水平扩展能力和高可用性
实践建议:虽然独立模式配置简单,但在生产环境中,强烈推荐使用分布式模式来获得更好的可靠性和可扩展性。
核心组件解析
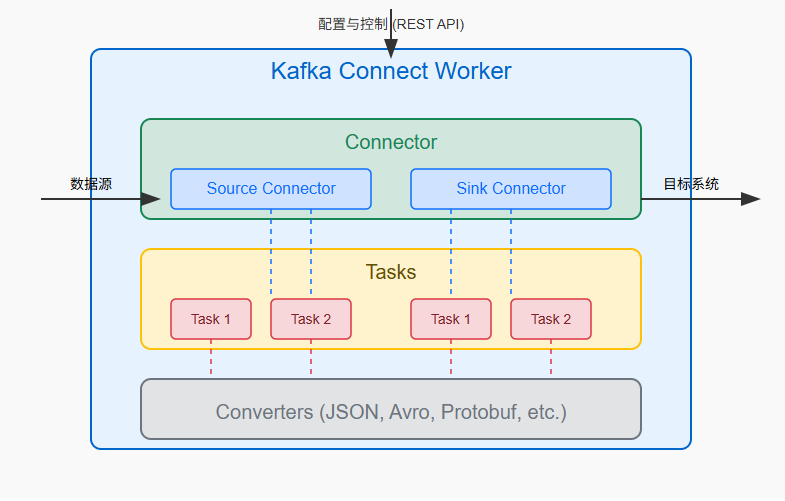
1. Worker:
- Kafka Connect的运行时进程
- 负责启动Connector和Task
- 管理配置和REST API接口
- 处理数据转换和传输
2. Connector:
- 协调数据流动的高级组件
- 决定需要多少Task来执行工作
- 管理数据分区与并行策略
- 分为Source Connector和Sink Connector两种类型
3. Task:
- 实际执行数据移动的工作单元
- 由Connector创建和管理
- 每个Task负责处理数据的子集
- 可以根据负载动态调整数量
4. Converter:
- 负责序列化和反序列化数据
- 在Kafka和外部系统数据格式间转换
- 常用的包括JSON、Avro、Protobuf等
- 可以对key和value单独配置不同的转换器
Source与Sink Connector的区别
Source Connector:
- 负责从外部系统读取数据到Kafka
- 典型应用:数据库CDC、日志采集、API轮询
- 需要管理偏移量和增量读取策略
- 示例:Debezium MySQL Connector、File Connector
Sink Connector:
- 负责从Kafka写入数据到外部系统
- 典型应用:数据库写入、索引构建、通知触发
- 需要处理幂等性和事务性写入
- 示例:Elasticsearch Connector、JDBC Connector
配置管理与REST API
在分布式模式下,Kafka Connect提供了一套完整的REST API,用于管理connector的生命周期:
# 查看所有已部署的connector
curl -X GET http://connect:8083/connectors
# 创建新的connector
curl -X POST -H "Content-Type: application/json" --data @connector-config.json http://connect:8083/connectors
# 查看connector状态
curl -X GET http://connect:8083/connectors/my-connector/status
# 暂停connector
curl -X PUT http://connect:8083/connectors/my-connector/pause
# 恢复connector
curl -X PUT http://connect:8083/connectors/my-connector/resume
# 删除connector
curl -X DELETE http://connect:8083/connectors/my-connector
这些API使得我们可以通过程序化方式管理数据管道,实现自动化部署和管理。
了解了这些基础概念后,我们可以更深入地探索Kafka Connect的核心优势,这些优势使它成为构建数据管道的理想选择。
3. Kafka Connect的核心优势
选择技术工具时,了解其核心优势至关重要。就像选择交通工具时会考虑速度、舒适度和安全性一样,我们需要全面了解Kafka Connect的优势,才能充分发挥其潜力。
声明式配置与无代码集成
Kafka Connect采用声明式配置方法,这意味着你只需描述"想要什么",而不是"如何做":
{
"name": "mysql-source",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "mysql-server",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "1",
"database.server.name": "mysql-server-1",
"database.include.list": "inventory",
"table.include.list": "inventory.customers",
"topic.prefix": "mysql"
}
}
优势对比:
| 传统自定义集成方式 | Kafka Connect方式 |
|---|---|
| 需要编写大量代码 | 只需提供配置文件 |
| 需要处理连接池管理 | 框架自动处理连接管理 |
| 手动实现错误处理逻辑 | 内置错误处理机制 |
| 需要自行管理状态 | 框架管理偏移量和状态 |
| 每添加一个数据源需要新开发 | 复用现有connector,只修改配置 |
实践心得:我在一个项目中曾需要从10个不同数据源采集数据,使用传统方式需要花费数周开发,而采用Kafka Connect后,3天内就完成了全部集成工作。
容错性与可靠性保障机制
Kafka Connect提供了多层保障,确保数据管道的可靠性:
- 自动重启:当Task失败时,Worker会自动尝试重启
- 偏移量跟踪:精确记录处理到的位置,确保不丢失数据
- 分布式协调:通过Kafka的消费者组机制实现负载均衡
- 状态备份:在Kafka主题中保存配置和状态信息
- 死信队列(DLQ):将无法处理的消息路由到专门主题以便后续处理
扩展性与可伸缩性设计
水平扩展能力:
- 只需添加新的Worker节点,无需修改配置
- 自动重新平衡Task分配
- 支持增加单个Connector的并行度(tasks.max)
垂直分离:
- 可以为不同类型的Connector部署专用Worker组
- 根据负载特性优化资源分配
- 实现关键业务与非关键业务的隔离
与Kafka生态的无缝集成
Kafka Connect天然与Kafka生态系统紧密集成:
- Kafka Streams:处理和转换来自Connect的数据流
- ksqlDB:对导入的数据进行SQL查询和分析
- Schema Registry:管理和演进数据架构
- MirrorMaker2:基于Connect构建,用于Kafka集群间复制
丰富的社区Connector资源
目前已有超过100个开源和商业Connector可用,覆盖了大多数主流系统:
数据库类:
- MySQL, PostgreSQL, MongoDB, Oracle, SQL Server (Debezium)
- Elasticsearch, Redis, Cassandra
云服务类:
- Amazon S3, GCS, Azure Blob Storage
- Snowflake, BigQuery, Redshift
消息系统类:
- RabbitMQ, ActiveMQ, IBM MQ
- JMS, MQTT, AMQP
应用服务类:
- Salesforce, SAP, Workday
- JIRA, GitHub, ServiceNow
选型建议:优先考虑活跃维护的开源Connector或商业产品,自研Connector应作为最后选择。我曾在项目中优先使用Debezium和Confluent提供的Connector,获得了良好的效果。
掌握了Kafka Connect的核心优势后,让我们通过一个实际案例,一步步构建第一个数据管道,将理论知识付诸实践。
4. 实战:构建第一个Kafka Connect数据管道
纸上得来终觉浅,绝知此事要躬行。本节将通过构建一个MySQL到Elasticsearch的实时数据同步管道,带你体验Kafka Connect的实战应用。
环境搭建与配置
首先,我们需要一个包含所有必要组件的环境。以下是使用Docker Compose快速搭建的配置:
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:6.2.0
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka:6.2.0
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
mysql:
image: mysql:8.0
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: inventory
MYSQL_USER: mysqluser
MYSQL_PASSWORD: mysqlpw
volumes:
- ./mysql-init:/docker-entrypoint-initdb.d
elasticsearch:
image: elasticsearch:7.14.0
environment:
- discovery.type=single-node
- xpack.security.enabled=false
connect:
image: confluentinc/cp-kafka-connect:6.2.0
depends_on:
- kafka
- mysql
- elasticsearch
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka:9092
CONNECT_GROUP_ID: connect-cluster
CONNECT_CONFIG_STORAGE_TOPIC: connect-configs
CONNECT_OFFSET_STORAGE_TOPIC: connect-offsets
CONNECT_STATUS_STORAGE_TOPIC: connect-status
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_REST_PORT: 8083
CONNECT_PLUGIN_PATH: /usr/share/java,/usr/share/confluent-hub-components
volumes:
- ./connect-plugins:/usr/share/confluent-hub-components
启动环境:
# 安装必要的connector插件
mkdir -p connect-plugins
confluent-hub install --no-prompt debezium/debezium-connector-mysql:1.8.0
confluent-hub install --no-prompt confluentinc/kafka-connect-elasticsearch:11.1.0
# 启动环境
docker-compose up -d
实现MySQL到Elasticsearch的数据同步案例
让我们通过三个步骤实现完整的数据同步:
1. Source Connector配置详解
创建mysql-source.json文件:
{
"name": "mysql-source",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "mysqluser",
"database.password": "mysqlpw",
"database.server.id": "1",
"database.server.name": "dbserver1",
"database.include.list": "inventory",
"table.include.list": "inventory.customers",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "schema-changes.inventory",
"include.schema.changes": "true",
"transforms": "unwrap", // 应用单消息转换
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState", // 提取变更后的记录状态
"transforms.unwrap.drop.tombstones": "false", // 保留删除事件
"key.converter": "org.apache.kafka.connect.json.JsonConverter", // 键的转换器
"value.converter": "org.apache.kafka.connect.json.JsonConverter" // 值的转换器
}
}
核心配置解析:
connector.class: 指定使用Debezium的MySQL连接器database.server.name: 为生成的Kafka主题名称提供前缀table.include.list: 限定只捕获特定表的变更transforms: 对捕获的数据应用转换,将变更数据格式简化为当前值
踩坑提示:确保MySQL用户有足够权限执行
SHOW DATABASES,SHOW TABLES,SELECT,REPLICATION SLAVE,REPLICATION CLIENT等操作,否则连接器会启动失败。
2. Sink Connector配置详解
创建elasticsearch-sink.json文件:
{
"name": "elasticsearch-sink",
"config": {
"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
"tasks.max": "1",
"topics": "dbserver1.inventory.customers", // 订阅Source Connector生成的主题
"connection.url": "http://elasticsearch:9200", // Elasticsearch连接地址
"key.ignore": "false", // 不忽略消息键,用作文档ID
"schema.ignore": "true", // 忽略schema信息
"transforms": "TimestampRouter", // 应用时间戳路由转换
"transforms.TimestampRouter.type": "org.apache.kafka.connect.transforms.TimestampRouter",
"transforms.TimestampRouter.topic.format": "${topic}-${timestamp}", // 索引命名格式
"transforms.TimestampRouter.timestamp.format": "yyyy.MM.dd", // 时间格式
"write.method": "upsert", // 使用upsert操作,支持更新
"batch.size": "1000", // 批处理大小
"max.in.flight.requests": "5", // 最大并发请求数
"retry.backoff.ms": "5000", // 重试间隔时间
"max.retries": "10", // 最大重试次数
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
}
}
核心配置解析:
topics: 指定要消费的Kafka主题transforms: 应用时间戳路由转换,将数据写入按日期分区的索引write.method: 使用upsert方法,支持插入和更新操作
3. 转换与过滤配置
Kafka Connect提供了强大的单消息转换(SMT)功能,用于在数据流动过程中修改消息内容:
时间戳提取:
"transforms": "ExtractTimestamp",
"transforms.ExtractTimestamp.type": "org.apache.kafka.connect.transforms.TimestampConverter$Value",
"transforms.ExtractTimestamp.field": "updated_at",
"transforms.ExtractTimestamp.format": "yyyy-MM-dd HH:mm:ss",
"transforms.ExtractTimestamp.target.type": "unix"
字段重命名:
"transforms": "RenameField",
"transforms.RenameField.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.RenameField.renames": "old_field_name:new_field_name"
过滤记录:
"transforms": "Filter",
"transforms.Filter.type": "org.apache.kafka.connect.transforms.Filter",
"transforms.Filter.predicate": "IsActiveCustomer",
"predicates": "IsActiveCustomer",
"predicates.IsActiveCustomer.type": "org.apache.kafka.connect.transforms.predicates.TopicNameMatches",
"predicates.IsActiveCustomer.pattern": ".*active.*"
运行与监控数据管道
现在,让我们部署和监控我们的数据管道:
# 部署MySQL Source Connector
curl -X POST -H "Content-Type: application/json" \
--data @mysql-source.json \
http://localhost:8083/connectors
# 部署Elasticsearch Sink Connector
curl -X POST -H "Content-Type: application/json" \
--data @elasticsearch-sink.json \
http://localhost:8083/connectors
# 检查Connector状态
curl http://localhost:8083/connectors/mysql-source/status
curl http://localhost:8083/connectors/elasticsearch-sink/status
数据流验证:
- 向MySQL插入数据:
INSERT INTO inventory.customers (first_name, last_name, email)
VALUES ('John', 'Doe', 'john.doe@example.com');
- 检查Kafka中的数据:
kafka-console-consumer --bootstrap-server kafka:9092 \
--topic dbserver1.inventory.customers --from-beginning
- 验证Elasticsearch中的数据:
curl -X GET "http://localhost:9200/dbserver1.inventory.customers-$(date +%Y.%m.%d)/_search" | jq
监控提示:在生产环境中,应该设置JMX监控和告警,关注以下指标:
- Task错误率和重启次数
- 消息滞后时间(lag)
- 处理吞吐量
- 连接器延迟时间
随着数据管道的基本功能搭建完成,下面我们将深入探讨一些高级特性和最佳实践,帮助你构建更加健壮和高效的数据管道。
5. 高级特性与最佳实践
掌握了基础知识后,让我们进一步探索Kafka Connect的高级特性。就像汽车驾驶,掌握基本操作后学习高级技巧可以让你在各种复杂情况下游刃有余。
单消息转换(SMT)应用技巧
SMT是Kafka Connect最强大的特性之一,它允许你在不编写代码的情况下转换消息。以下是一些高级应用技巧:
1. 转换链组合使用
多个转换可以通过逗号分隔组成转换链,按顺序应用:
"transforms": "unwrap,extractTime,filter",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.extractTime.type": "org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.extractTime.timestamp.field": "event_time",
"transforms.filter.type": "org.apache.kafka.connect.transforms.Filter",
"transforms.filter.condition": "$.value.status == 'ACTIVE'"
2. 动态主题路由
根据消息内容动态决定目标主题:
"transforms": "router",
"transforms.router.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.router.regex": "([^.]+)\\.([^.]+)\\.([^.]+)",
"transforms.router.replacement": "$3-events"
3. 自定义SMT实现
对于复杂的转换需求,可以实现自定义SMT:
package com.example.kafka.connect.transforms;
import org.apache.kafka.common.config.ConfigDef;
import org.apache.kafka.connect.connector.ConnectRecord;
import org.apache.kafka.connect.transforms.Transformation;
import java.util.Map;
public class CustomTransform<R extends ConnectRecord<R>> implements Transformation<R> {
@Override
public R apply(R record) {
// 实现自定义转换逻辑
return record;
}
@Override
public ConfigDef config() {
return new ConfigDef();
}
@Override
public void close() {
// 清理资源
}
@Override
public void configure(Map<String, ?> configs) {
// 初始化配置
}
}
最佳实践:当标准SMT无法满足需求时,考虑结合使用多个SMT,而不是立即开发自定义SMT。只有在组合方式仍无法满足需求时,再考虑自定义开发。
死信队列(DLQ)处理策略
当消息处理失败时,DLQ提供了一种安全机制,防止整个管道因少量错误数据而停止。
配置DLQ:
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name": "dlq-elasticsearch",
"errors.deadletterqueue.context.headers.enable": "true",
"errors.deadletterqueue.topic.replication.factor": 1
DLQ处理流程:
- 监控DLQ:设置告警监控DLQ主题的消息数量
- 分析错误:使用专门的消费者分析DLQ中的错误消息和异常
- 修复数据:根据错误类型编写修复脚本
- 重新处理:将修复后的数据重新发送到原始主题
常见错误类型及处理方法:
| 错误类型 | 可能原因 | 处理方法 |
|---|---|---|
| 序列化错误 | 数据格式不匹配 | 调整转换器或使用SMT转换格式 |
| 空值错误 | 必填字段为空 | 使用InsertField SMT添加默认值 |
| 类型错误 | 字段类型不兼容 | 使用Cast SMT转换数据类型 |
| 连接错误 | 目标系统不可用 | 等待系统恢复后重试 |
Connector的并行度调优
合理配置并行度可以显著提升性能,但需要平衡资源使用:
任务并行度配置:
"tasks.max": "10" // 最大任务数
并行度调优指南:
- 分析瓶颈:使用监控工具确定当前瓶颈是CPU、内存、网络还是I/O
- 基于分区:理想情况下,任务数应与源数据的并行度匹配(如Kafka分区数)
- 渐进式调整:从较小值开始,逐步增加并监控性能变化
- 考虑资源限制:确保Worker节点有足够资源处理增加的并行任务
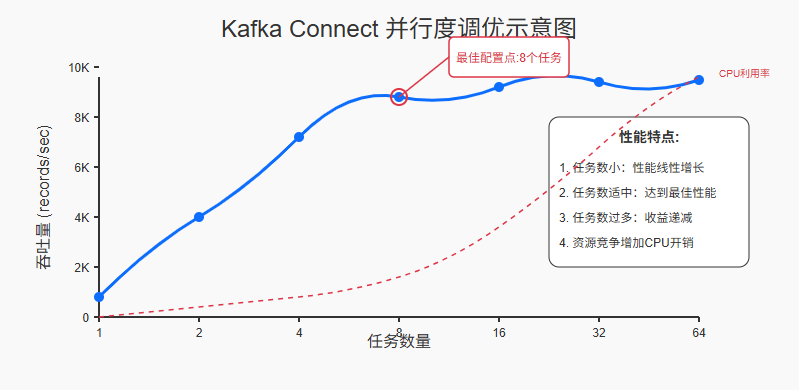
实践心得:在一个大型电商项目中,我们将MySQL Connector的任务数从1增加到8,吞吐量提升了5倍,但继续增加到16后,吞吐量只提升了10%,同时CPU使用率急剧上升,因此我们最终选择了8作为最佳配置。
Schema管理与演进策略
在生产环境中,数据结构不可避免地会发生变化。有效的Schema管理至关重要:
使用Schema Registry:
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081"
Schema演进最佳实践:
- 向后兼容性:添加字段时使用默认值,避免删除字段
- 版本控制:使用Schema Registry跟踪和管理Schema版本
- 渐进式迁移:先添加新字段,等所有消费者兼容后再弃用旧字段
- 异步迁移:创建新主题和新Connector,而不是修改现有配置
处理Schema变更的SMT:
"transforms": "dropFields",
"transforms.dropFields.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.dropFields.blacklist": "old_field1,old_field2"
配置验证与安全策略
确保Connector配置安全且正确:
配置验证工具:
kafka-run-class org.apache.kafka.connect.cli.ConnectorVerifier --config connector-config.properties
安全配置最佳实践:
-
敏感信息保护:
"database.password": "${file:/opt/kafka/secrets/db-password:password}" -
网络安全:
"connection.url": "https://elasticsearch:9200", "connection.username": "${file:/opt/kafka/secrets/es-user:username}", "connection.password": "${file:/opt/kafka/secrets/es-password:password}", "ssl.truststore.location": "/opt/kafka/ssl/truststore.jks", "ssl.truststore.password": "${file:/opt/kafka/secrets/ssl-password:password}" -
访问控制:
- 限制REST API访问,使用基本认证或OAuth
- 为Connect用户配置最小权限原则的Kafka ACL
-
安全审计:
- 启用详细日志记录所有配置更改
- 实现配置更改的审批流程
在掌握了这些高级特性后,让我们看看在实际项目中可能遇到的常见问题及其解决方案。
6. 常见踩坑经验与解决方案
即使是经验丰富的工程师,在使用Kafka Connect构建数据管道时也会遇到各种挑战。本节将分享我在多个项目中积累的实战经验,帮助你避开常见陷阱。
Connector重启与数据一致性保障
问题:Connector重启可能导致数据重复或丢失。
原因:
- 偏移量提交与实际处理不同步
- 目标系统不支持幂等性操作
- 重启过程中的数据积压
解决方案:
-
确保端到端幂等性:
// 对于Elasticsearch Sink "write.method": "upsert", "key.ignore": "false" // 对于JDBC Sink "insert.mode": "upsert", "pk.mode": "record_key" -
自定义偏移量控制:
// 在Source Connector中实现精确的偏移量跟踪 Map<String, Object> offset = new HashMap<>(); offset.put("file", filename); offset.put("position", position); context.offsetStorageReader().offset(Collections.singletonMap("file", filename)); -
批处理与事务:
// JDBC Sink的事务配置 "batch.size": 100, "transaction.isolation": "read_committed"
实战案例:在一个金融数据同步项目中,我们发现JDBC Sink在重启后会产生重复数据。通过配置
insert.mode=upsert并确保目标表有唯一约束,成功解决了这个问题,保证了数据一致性。
处理大数据量时的性能优化
问题:数据量增长导致管道性能下降,无法满足实时性要求。
性能优化策略:
-
批处理参数调优:
"batch.size": 1000, // 增加批处理大小 "flush.timeout.ms": 10000, // 延长刷新间隔 "max.buffered.records": 20000 // 增加缓冲区大小 -
资源分配优化:
// Worker JVM配置 KAFKA_HEAP_OPTS="-Xms4G -Xmx4G" // GC优化 KAFKA_JVM_PERFORMANCE_OPTS="-XX:+UseG1GC -XX:MaxGCPauseMillis=20" -
并行度优化:
- 增加任务数量:
"tasks.max": "16" - 增加Worker节点数量
- 根据业务特点进行分片,创建多个专用Connector
- 增加任务数量:
-
网络与I/O优化:
- 使用连接池:
"connection.pool.size": "20" - 减少往返次数:
"max.in.flight.requests": "10" - 压缩数据:
"compression.type": "gzip"
- 使用连接池:
性能监控指标:
| 指标 | 描述 | 优化方向 |
|---|---|---|
| 处理延迟 | 数据从源到目的地的时间 | 减少延迟 |
| 吞吐量 | 每秒处理的记录数 | 增加吞吐量 |
| 资源利用率 | CPU/内存/网络使用率 | 平衡利用率 |
| 错误率 | 处理失败的记录百分比 | 减少错误率 |
踩坑经验:在一个物联网项目中,我们最初将sink.max.retries设置过高,导致错误数据反复重试,占用大量资源。通过设置合理的重试次数并启用DLQ,我们提高了系统的整体吞吐量。
断点续传与恢复机制实现
问题:系统故障或维护后,需要确保数据管道从中断点恢复,不丢失数据。
解决方案:
-
CDC源的恢复机制:
// Debezium MySQL配置 "snapshot.mode": "when_needed", // 需要时自动创建快照 "snapshot.locking.mode": "minimal", // 最小化锁定,减少对源系统影响 "database.history.kafka.recovery.poll.interval.ms": 5000 // 恢复轮询间隔 -
文件源的断点续传:
// FileStreamSource配置 "file": "/data/logs/app.log", "topic": "file-data", "tail": true, // 持续读取新内容 "recursive": false -
自定义恢复点:
// 自定义Source Connector中实现精确的断点记录 @Override public List<SourceRecord> poll() { Map<String, Object> sourceOffset = context.offsetStorageReader() .offset(sourcePartition); long position = 0L; if (sourceOffset != null) { position = (Long) sourceOffset.get("position"); } // 从记录的位置继续读取 List<SourceRecord> records = readFromPosition(position); // 更新偏移量 sourceOffset = Collections.singletonMap("position", newPosition); return records.stream() .map(record -> new SourceRecord( sourcePartition, sourceOffset, topic, Schema.STRING_SCHEMA, record)) .collect(Collectors.toList()); }
实战技巧:在生产环境中,我们发现定期备份Connect的内部主题(connect-configs, connect-offsets, connect-status)非常重要。我们实现了一个自动备份机制,在系统崩溃后可以快速恢复整个Connect集群的状态。
处理敏感字段的安全策略
问题:数据管道中可能包含敏感信息,需要确保安全合规。
解决方案:
-
字段级加密:
"transforms": "encrypt", "transforms.encrypt.type": "com.example.kafka.connect.transforms.FieldEncryptor", "transforms.encrypt.fields": "credit_card,ssn,password", "transforms.encrypt.key.provider": "file", "transforms.encrypt.key.location": "/opt/kafka/secrets/encryption.key" -
字段屏蔽/脱敏:
"transforms": "maskFields", "transforms.maskFields.type": "org.apache.kafka.connect.transforms.MaskField$Value", "transforms.maskFields.fields": "credit_card,password", "transforms.maskFields.replacement": "****" -
字段过滤:
"transforms": "dropFields", "transforms.dropFields.type": "org.apache.kafka.connect.transforms.ReplaceField$Value", "transforms.dropFields.blacklist": "credit_card,ssn,password" -
审计日志:
// 在log4j配置中启用审计日志 log4j.logger.org.apache.kafka.connect.runtime=INFO, auditLog log4j.appender.auditLog=org.apache.log4j.RollingFileAppender log4j.appender.auditLog.File=/var/log/kafka/connect-audit.log
合规提示:在处理涉及GDPR或其他数据保护法规的数据时,确保实施数据分类、访问控制和审计机制。我们在一个欧洲客户项目中,通过实现自定义的加密转换器,成功处理了包含PII的数据流。
监控告警体系构建
问题:缺乏有效的监控机制,难以及时发现和解决问题。
解决方案:
-
核心监控指标:
- Connector状态
- Task状态
- 处理延迟
- 错误率
- 处理速率
- 资源使用情况
-
JMX监控配置:
// Worker配置 KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=9999" -
Prometheus + Grafana监控:
# prometheus.yml scrape_configs: - job_name: 'kafka-connect' static_configs: - targets: ['connect:9999'] jmx_exporter_config: lowercaseOutputName: true rules: - pattern: "kafka.connect<type=connect-worker-metrics>([^:]+):" name: "kafka_connect_worker_$1" -
告警规则配置:
# alert_rules.yml groups: - name: connect_alerts rules: - alert: ConnectorFailed expr: kafka_connect_connector_task_failed_count > 0 for: 5m labels: severity: critical annotations: summary: "Connector {{ $labels.connector }} has failed tasks" description: "Connector {{ $labels.connector }} has {{ $value }} failed tasks" -
自定义健康检查接口:
@Path("/health") public class HealthResource { @GET @Produces(MediaType.APPLICATION_JSON) public Response getHealth() { Map<String, Object> health = new HashMap<>(); // 检查Connect集群状态 health.put("status", "UP"); health.put("timestamp", System.currentTimeMillis()); return Response.ok(health).build(); } }
监控建议:不要只监控技术指标,还要监控业务指标。例如,在一个零售项目中,我们设置了监控规则,当订单事件的处理延迟超过30秒时触发告警,这有效地保障了业务SLA。
通过这些实战经验和解决方案,你应该能够更加自信地构建和维护生产级别的Kafka Connect数据管道。接下来,让我们看一些真实的企业级应用案例,了解Kafka Connect如何在不同行业中发挥作用。
7. 企业级应用案例分享
理论和经验固然重要,但真实的企业案例能够为我们提供更加直观的参考。以下分享几个我亲自参与或了解的案例,展示Kafka Connect如何在不同行业解决实际问题。
金融行业:实时数据同步与分析平台
背景:某大型银行需要构建实时数据平台,将交易数据从核心银行系统同步到分析平台,用于风险监控和实时决策。
挑战:
- 核心系统使用Oracle数据库,不能有任何性能影响
- 数据必须实时、准确,零容忍数据丢失
- 需要处理敏感数据,确保安全合规
- 峰值交易量可达每秒数千笔
解决方案:
-
架构设计:
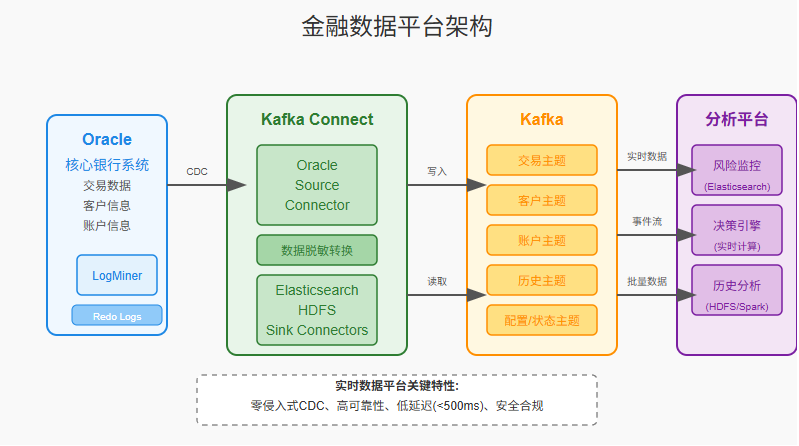
-
核心组件:
- Oracle LogMiner CDC Source Connector
- Kafka作为消息中间层
- HDFS和Elasticsearch Sink Connector
- 自定义转换器处理数据脱敏
-
关键配置:
// Oracle Source Connector { "name": "oracle-source", "config": { "connector.class": "io.debezium.connector.oracle.OracleConnector", "database.hostname": "oracle-primary", "database.port": "1521", "database.user": "c##dbzuser", "database.password": "${file:/opt/kafka/secrets/oracle.txt:password}", "database.dbname": "ORCLCDB", "database.pdb.name": "ORCLPDB1", "database.server.name": "banking", "table.include.list": "BANKING.TRANSACTIONS,BANKING.ACCOUNTS", "database.history.kafka.bootstrap.servers": "kafka:9092", "database.history.kafka.topic": "schema-changes.banking", "transforms": "unwrap,mask", "transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState", "transforms.mask.type": "org.apache.kafka.connect.transforms.MaskField$Value", "transforms.mask.fields": "CARD_NUMBER,SSN", "transforms.mask.replacement": "****" } } -
成果:
- 实现近实时数据同步,延迟小于500毫秒
- 支持每秒5000+交易事件处理
- 确保数据一致性和安全合规
- 实现7x24不间断运行,可靠性达99.99%
关键经验:针对Oracle数据库,我们发现将更改捕获方法从LogMiner改为XStream可以显著提高性能,但需要额外的Oracle许可。在评估成本和性能后,客户选择了LogMiner方案并通过优化批处理参数来提升性能。
电商领域:订单数据流处理管道
背景:大型电商平台需要构建从订单系统到多个下游系统的实时数据流,包括仓储、配送、客服和分析系统。
挑战:
- 多源数据集成(MySQL、MongoDB、Redis、API)
- 订单状态变更需要实时触发后续流程
- 峰值期(如大促活动)数据量激增
- 需要灵活的数据转换和路由机制
解决方案:
-
架构设计:
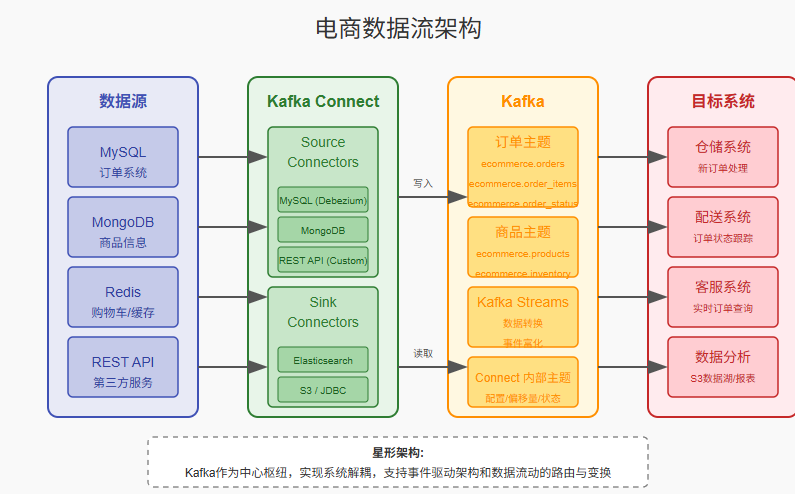
-
核心组件:
- Debezium MySQL CDC Source Connector
- MongoDB Source Connector
- REST API Source Connector(自定义开发)
- Elasticsearch、S3、JDBC Sink Connector
- Kafka Streams进行数据转换和富化
-
关键配置:
// MySQL Source Connector(订单系统) { "name": "orders-mysql-source", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "database.hostname": "mysql-master", "database.port": "3306", "database.user": "debezium", "database.password": "${file:/etc/kafka-connect/mysql-creds:password}", "database.server.id": "1", "database.server.name": "ecommerce", "database.whitelist": "orders", "table.whitelist": "orders.orders,orders.order_items,orders.order_status", "transforms": "unwrap,route", "transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState", "transforms.route.type": "org.apache.kafka.connect.transforms.RegexRouter", "transforms.route.regex": "([^.]+)\\.([^.]+)\\.([^.]+)", "transforms.route.replacement": "ecommerce.$3" } } // Elasticsearch Sink Connector(搜索服务) { "name": "orders-es-sink", "config": { "connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector", "connection.url": "http://elasticsearch:9200", "topics": "ecommerce.orders", "key.ignore": "false", "schema.ignore": "true", "behavior.on.null.values": "delete", "write.method": "upsert", "transforms": "filter", "transforms.filter.type": "io.confluent.connect.transforms.Filter", "transforms.filter.condition": "$.value.status !== 'DELETED'", "transforms.filter.predicate": "$.value.status !== 'DELETED'" } } -
动态路由策略:
- 基于订单状态将事件路由到不同的系统:
- 新订单 → 仓储系统
- 支付完成 → 配送系统
- 配送中 → 客服系统
- 全部事件 → 数据湖/分析系统
- 基于订单状态将事件路由到不同的系统:
-
成果:
- 处理峰值期每秒10,000+订单事件
- 实现业务系统解耦,提高整体系统弹性
- 减少50%的开发工作量
- 支持业务快速迭代和新系统集成
创新点:我们开发了一个动态配置管理系统,允许业务人员通过UI界面定义数据路由规则,无需开发人员介入。这大大提高了业务响应速度,使营销活动相关的数据流配置变更从天级缩短到分钟级。
物联网场景:设备数据采集与分析
背景:智能制造企业需要从数千台设备采集数据,进行实时监控、预测性维护和生产优化。
挑战:
- 设备类型多样,数据格式不统一
- 设备连接不稳定,需要处理间歇性连接
- 数据量大,但价值密度低,需要边缘过滤
- 需要支持设备固件升级和配置回传
解决方案:
-
架构设计:
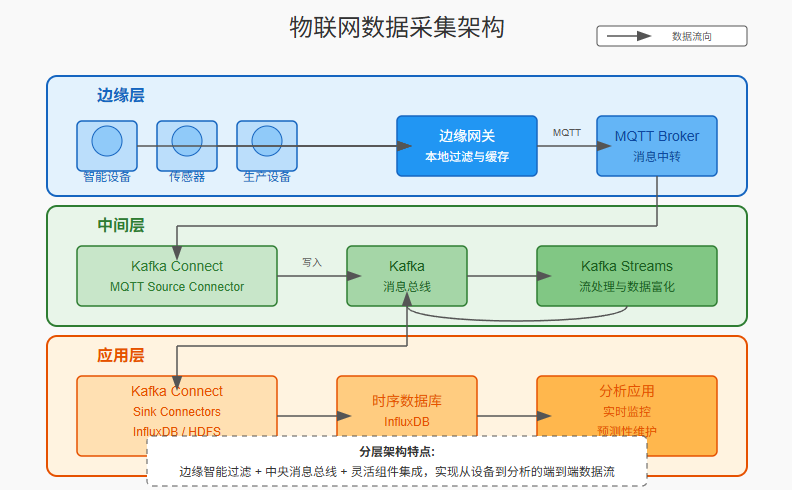
-
核心组件:
- MQTT Source Connector
- Kafka作为中央消息总线
- InfluxDB Sink Connector存储时序数据
- HDFS Sink Connector存储原始数据
- 自定义边缘处理组件
-
关键配置:
// MQTT Source Connector { "name": "mqtt-source", "config": { "connector.class": "io.confluent.connect.mqtt.MqttSourceConnector", "mqtt.server.uri": "tcp://mqtt-broker:1883", "mqtt.topics": "devices/+/telemetry", "mqtt.qos": "1", "mqtt.username": "${file:/etc/kafka-connect/mqtt-creds:username}", "mqtt.password": "${file:/etc/kafka-connect/mqtt-creds:password}", "kafka.topic": "iot.device.telemetry", "value.converter": "org.apache.kafka.connect.json.JsonConverter", "value.converter.schemas.enable": "false", "transforms": "extractDeviceId,addMetadata", "transforms.extractDeviceId.type": "org.apache.kafka.connect.transforms.RegexRouter", "transforms.extractDeviceId.regex": "devices/(.*)/telemetry", "transforms.extractDeviceId.replacement": "device_id", "transforms.addMetadata.type": "org.apache.kafka.connect.transforms.InsertField$Value", "transforms.addMetadata.timestamp.field": "ingestion_time" } } // InfluxDB Sink Connector { "name": "influxdb-sink", "config": { "connector.class": "io.confluent.connect.influxdb.InfluxDBSinkConnector", "topics": "iot.device.telemetry", "influxdb.url": "http://influxdb:8086", "influxdb.db": "device_metrics", "influxdb.username": "${file:/etc/kafka-connect/influxdb-creds:username}", "influxdb.password": "${file:/etc/kafka-connect/influxdb-creds:password}", "measurement.name.format": "device_${device_id}", "transforms": "flattenJson", "transforms.flattenJson.type": "com.github.jcustenborder.kafka.connect.transform.common.FlattenJson$Value", "transforms.flattenJson.delimiter": "_" } } -
边缘处理策略:
- 在设备侧实现初步过滤和聚合
- 只有超出阈值的数据才发送至中心
- 实现本地缓存,处理网络不稳定情况
- 动态下发过滤规则,适应不同场景
-
成果:
- 支持5,000+设备同时连接和数据采集
- 减少70%的数据传输量,降低网络和存储成本
- 实现设备异常的秒级检测和告警
- 预测性维护模型提前48小时预测设备故障
技术创新:我们实现了一个动态阈值调整系统,基于机器学习模型自动优化每台设备的数据采集策略。这使得系统能够自适应地采集关键数据,在保证数据质量的同时最小化传输和存储成本。
这些案例展示了Kafka Connect在不同行业的灵活应用。通过学习这些实践经验,你可以更好地设计和实现自己的数据管道。接下来,让我们展望Kafka Connect的未来发展趋势,并总结全文要点。
8. 未来展望与总结
走过了Kafka Connect的理论基础、实践应用和案例分析,我们已经对这个强大的数据集成框架有了全面的认识。在本章中,让我们一起展望未来,并总结关键的学习成果。
Kafka Connect生态发展趋势
1. 云原生与Kubernetes集成
随着云计算的普及,Kafka Connect正在向云原生方向发展:
- Kubernetes Operator:简化在K8s上的部署和运维
- 自动扩缩容:基于负载自动调整工作节点数量
- 无服务器Connect:按需付费的托管服务模式
- 多云部署:跨云厂商的一致性体验
行业观察:Strimzi和Confluent Operator等项目正在简化Kafka Connect在Kubernetes上的管理。未来2-3年内,基于K8s的部署将成为主流模式。
2. 数据治理与合规
随着数据隐私法规的加强,数据治理成为关键焦点:
- 细粒度访问控制:字段级别的权限管理
- 数据血缘追踪:记录数据流动全路径
- 加密与脱敏:内置的数据保护机制
- 审计与合规:满足GDPR、CCPA等法规要求
3. 实时ETL与流处理融合
传统ETL与流处理的界限正在模糊:
- 内置转换功能增强:更丰富的SMT和处理逻辑
- 与ksqlDB集成:SQL式的流处理能力
- 流式机器学习:集成ML预处理和推理能力
- 流批一体化:统一处理实时和批量数据
4. 开发者体验提升
更加友好的开发和运维体验:
- 图形化管理界面:可视化配置和监控
- 声明式API:基于GitOps的配置管理
- 测试框架:简化Connector测试
- Schema演进自动化:智能处理Schema变更
与其他数据集成工具的比较
为了帮助你在技术选型时做出明智决策,这里列出了Kafka Connect与其他主流数据集成工具的比较:
| 特性 | Kafka Connect | Apache NiFi | Apache Flink | Airbyte |
|---|---|---|---|---|
| 主要优势 | Kafka生态集成,扩展性 | 可视化,丰富处理器 | 复杂流处理,低延迟 | 简单易用,SaaS选项 |
| 架构模式 | 分布式 | 分布式流 | 流批一体 | 容器化微服务 |
| 数据转换能力 | 有限,需结合流处理 | 丰富的内置处理器 | 强大的流处理API | 基本变换,外部dbt |
| 扩展性 | 优秀 | 良好 | 优秀 | 一般 |
| 学习曲线 | 中等 | 陡峭 | 陡峭 | 平缓 |
| 最适用场景 | Kafka生态,数据管道 | 复杂数据路由,ETL | 高级流处理,CEP | 简单数据复制 |
选型建议:如果你已经使用Kafka作为消息总线,并希望构建可靠的数据管道,Kafka Connect是最佳选择。对于需要复杂转换和可视化编排的场景,可以考虑Apache NiFi;而对于需要复杂流处理逻辑的场景,Apache Flink会更适合。
总结与进阶学习资源
核心要点回顾:
- Kafka Connect架构:统一的数据集成框架,简化数据进出Kafka的流程
- 声明式配置:无需编码即可实现数据集成,减少开发和维护成本
- 可扩展性:支持水平扩展,满足从小型到企业级的各种需求
- 容错能力:内置容错机制,确保数据可靠性和一致性
- 生态系统:丰富的连接器支持各类数据源和目标系统
- 高级特性:SMT、DLQ、并行化处理等功能满足复杂业务需求
个人经验分享:
在我参与的多个数据集成项目中,Kafka Connect始终是连接异构系统的可靠桥梁。关键成功因素包括:详细的前期评估、合理的架构设计、充分的性能测试和完善的监控告警。最具挑战性的环节通常是处理各种边缘情况和保证数据一致性,这需要对Kafka Connect的内部工作原理有深入理解。
进阶学习资源:
-
官方文档:
-
书籍推荐:
- 《Kafka: The Definitive Guide》(O’Reilly)
- 《Kafka Connect in Action》(Manning)
-
开源项目:
- Debezium - CDC连接器套件
- Camel Kafka Connector - 基于Apache Camel的连接器
-
社区资源:
- Kafka Summit - 年度Kafka技术大会
- Confluent Community - 社区讨论和资源
结语
Kafka Connect已经成为构建实时数据管道的标准工具。通过本文的介绍,希望你已经掌握了使用Kafka Connect构建可靠数据管道的核心知识和技能。
记住,数据管道不仅是技术工具,更是连接业务需求与数据价值的桥梁。随着组织对实时数据需求的增长,掌握Kafka Connect这样的工具将使你在数据工程领域具备核心竞争力。
最后,鼓励你从小规模试点开始,在实践中不断积累经验,逐步构建起适合你业务场景的数据集成架构。数据的旅程永无止境,而Kafka Connect将是你可靠的旅途伙伴。
祝你在数据集成之路上一帆风顺!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)