C++,OpenCV,VS2015,HOG+SVM行人检测项目一整套,具体包括以下内容: 1...
C++,OpenCV,VS2015,HOG+SVM行人检测项目一整套,具体包括以下内容: 1.行人检测数据集,正负样本 2.数据集准备,模型训练,模型测试,视频测试和图片测试 3.界面,使用Qt搭建可视化交互界面 代码操作流程说明书,Word版
刚把毕设收尾的HOG+SVM行人检测项目翻出来整理了一遍,从数据集准备到Qt可视化界面全流程撸完了,用的是VS2015+OpenCV3.4.10,今天就把整个过程唠唠,踩过的坑和能用的代码片段都给你们扒出来,绝对不整那些干巴巴的论文套话。
首先得先搞数据集,这是最磨人的一步,别嫌麻烦。正样本就是纯行人的图,得统一缩成64*128像素,这是HOG特征要求的输入尺寸,我最开始偷懒没统一,结果训练的时候直接报错说特征维度不对,差点把我整崩溃。负样本就是不带行人的背景图,比如街道、草地、车流啥的,数量最好比正样本多一点,我当时是1:3的比例,大概2000张正样本配6000张负样本,负样本找的时候一定要仔细,别把行人混进去,不然训练出来的模型会瞎识别。
给你们看一段批量预处理正样本的代码,当时我写了个小脚本干这个活:
#include <opencv2/opencv.hpp>
#include <iostream>
#include <vector>
#include <filesystem>
// 划重点!VS2015默认不支持C++17的filesystem,记得去项目属性里把C++语言标准改成C++17或者更高,不然编译的时候会报错找不到头文件
namespace fs = std::filesystem;
int main()
{
// 原始正样本文件夹和保存路径,记得提前建好
std::string src_path = "./raw_pos/";
std::string save_path = "./norm_pos/";
if(!fs::exists(save_path)) fs::create_directory(save_path);
for(auto& entry : fs::directory_iterator(src_path)){
// 只处理jpg和png格式的图,其他的跳过
if(entry.path().extension() != ".jpg" && entry.path().extension() != ".png") continue;
cv::Mat img = cv::imread(entry.path().string());
if(img.empty()) continue;
cv::Mat resize_img;
// 统一缩成64*128,刚好符合HOG的输入尺寸
cv::resize(img, resize_img, cv::Size(64,128));
std::string save_name = save_path + entry.path().filename().string();
cv::imwrite(save_name, resize_img);
}
std::cout << "正样本预处理搞定!" << std::endl;
return 0;
}这个代码其实挺直白的,就是遍历文件夹里的所有图片,统一缩成要求的尺寸,负样本的预处理也是一样的逻辑,只是不用抠图,直接用原图缩就行,毕竟负样本只要尺寸对就行。

C++,OpenCV,VS2015,HOG+SVM行人检测项目一整套,具体包括以下内容: 1.行人检测数据集,正负样本 2.数据集准备,模型训练,模型测试,视频测试和图片测试 3.界面,使用Qt搭建可视化交互界面 代码操作流程说明书,Word版
接下来是模型训练,用OpenCV自带的HOG+SVM模块就行,不用自己从头写特征提取,省了好多事。我写了个封装好的特征提取函数,重点来了,所有参数必须和后面检测的时候完全一致,一个都不能改,不然特征维度对不上,模型直接废了:
#include <opencv2/opencv.hpp>
#include <opencv2/ml.hpp>
using namespace cv;
using namespace cv::ml;
// 提取单张图片的HOG特征
Mat getHogFeature(const Mat& img)
{
HOGDescriptor hog;
// 这里的参数必须和检测时的参数完全一致!
hog.winSize = Size(64,128);
hog.blockSize = Size(16,16);
hog.blockStride = Size(8,8);
hog.cellSize = Size(8,8);
hog.nbins = 9;
std::vector<float> descriptors;
hog.compute(img, descriptors, Size(8,8), Size(0,0));
Mat feature = Mat(descriptors).clone();
return feature;
}然后训练的主函数大概是这样的:
int trainModel()
{
// 先加载所有预处理好的正负样本,这里省略遍历文件夹读图片的代码,直接给个大概的逻辑
std::vector<Mat> pos_imgs, neg_imgs;
// 读取norm_pos和norm_neg文件夹里的所有图片到vector里
Mat train_data, train_labels;
// 正样本标签是1,负样本是-1
for(auto& img : pos_imgs){
Mat feat = getHogFeature(img);
if(feat.empty()) continue;
// 把每个样本的特征按行拼到训练集里
train_data.push_back(feat);
train_labels.push_back(1.0);
}
for(auto& img : neg_imgs){
Mat feat = getHogFeature(img);
if(feat.empty()) continue;
train_data.push_back(feat);
train_labels.push_back(-1.0);
}
// 初始化SVM分类器
Ptr<SVM> svm = SVM::create();
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::LINEAR);
svm->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER | TermCriteria::EPS, 1000, 1e-6));
// 开始训练
svm->train(train_data, ROW_SAMPLE, train_labels);
// 保存训练好的模型
svm->save("hog_svm_model.xml");
std::cout << "模型训练完成,已保存!" << std::endl;
return 0;
}我当时第一次训练的时候就是改了blockStride的大小,结果检测的时候一个行人都没找不出来,调了快俩小时才发现是参数没对上,血的教训。
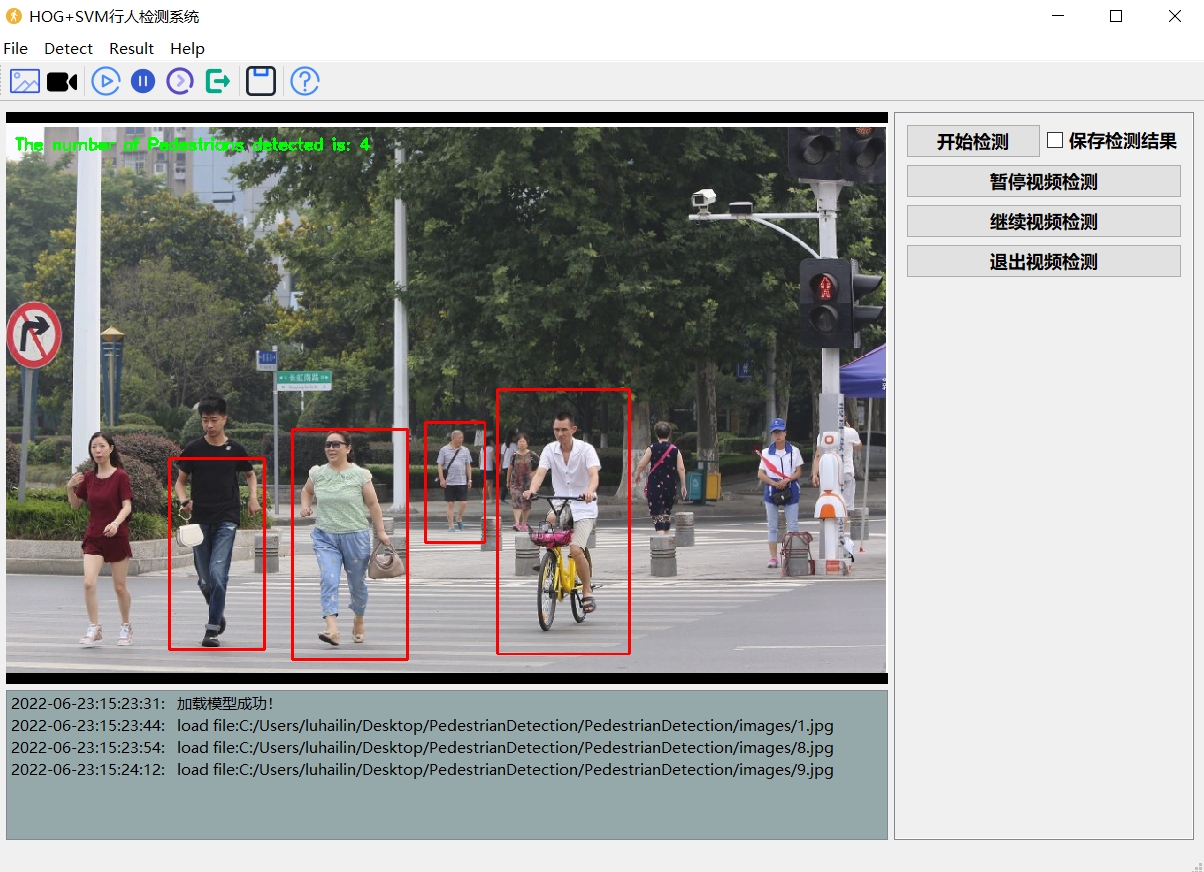
然后是模型测试,单张图片测试的代码就更简单了,直接加载模型,然后用HOG自带的detectMultiScale来检测,这个函数自带非极大值抑制,不用自己写,省了好多事:
// 单张图片检测
void detectSingleImg(const std::string& img_path)
{
Mat img = cv::imread(img_path);
if(img.empty()){
std::cout << "图片打不开啊!" << std::endl;
return;
}
// 加载训练好的模型
Ptr<SVM> svm = SVM::load("hog_svm_model.xml");
HOGDescriptor hog;
// 参数必须和训练的时候完全一致!
hog.winSize = Size(64,128);
hog.blockSize = Size(16,16);
hog.blockStride = Size(8,8);
hog.cellSize = Size(8,8);
hog.nbins =9;
// 把SVM分类器加载到HOG里
hog.setSVMDetector(svm->getSupportVectors());
std::vector<Rect> found;
// 检测行人框,参数可以自己调,比如缩放步长和置信度阈值
hog.detectMultiScale(img, found, 0, Size(8,8), Size(0,0), 1.05, 2);
// 把检测到的框画在图上
for(auto& rect : found){
cv::rectangle(img, rect, cv::Scalar(0,255,0), 2);
}
cv::imshow("行人检测结果", img);
cv::waitKey(0);
}视频检测的话就是用VideoCapture循环读每一帧,调用上面的检测逻辑就行:
// 视频检测,支持摄像头和本地视频文件
void detectVideo(const std::string& video_path)
{
cv::VideoCapture cap(video_path);
if(!cap.isOpened()){
std::cout << "视频打不开!" << std::endl;
return;
}
Ptr<SVM> svm = SVM::load("hog_svm_model.xml");
HOGDescriptor hog;
// 同样设置参数
Mat frame;
while(cap.read(frame)){
if(frame.empty()) break;
std::vector<Rect> found;
hog.detectMultiScale(frame, found, 0, Size(8,8), Size(0,0), 1.05, 2);
for(auto& r : found) cv::rectangle(frame, r, cv::Scalar(0,255,0),2);
cv::imshow("视频检测", frame);
if(cv::waitKey(30)>=0) break;
}
}然后是Qt界面的部分,这个是用来做可视化的,我当时做了个简单的界面,有选图片、选视频、检测的按钮,还有显示结果的标签,大概的Qt代码片段:
// Qt的MainWindow类里的槽函数,选图片按钮的部分
void MainWindow::on_btn_selectImg_clicked()
{
QString img_path = QFileDialog::getOpenFileName(this, "选择测试图片", "./", "图片文件(*.jpg *.png");
if(img_path.isEmpty()) return;
// 显示原图
ui->label_origin->setPixmap(QPixmap(img_path));
// 调用检测函数,把结果转成QImage显示
Mat img = cv::imread(img_path.toStdString());
// 检测代码和之前的一样,然后把带框的图转成QImage
QImage q_img = QImage(img.data, img.cols, img.rows, img.step, QImage::Format_RGB888);
ui->label_result->setPixmap(QPixmap::fromImage(q_img.rgbSwapped()));
}搭Qt界面的时候还要注意把OpenCV的dll要放到Qt的编译输出目录里,不然运行的时候找不到,我当时就是把dll直接扔到了exe同目录下才解决的这个问题。
最后还整理了一份Word版的操作说明书,大概的目录是:
- 开发环境配置(VS2015配置OpenCV、Qt5.x配置VS2015)
- 数据集准备(正负样本收集、预处理代码)
- 模型训练代码使用说明)
- 单张/视频/图片测试代码使用说明)
- Qt界面搭建步骤)
- 常见问题解决(比如dll找不到、检测不出行人、特征维度不对)
其实这个项目虽然不算难,但是踩过的坑还是挺多的,比如一开始没统一样本尺寸、参数不一致、dll找不到这些,要是你们也在做这个项目的话,可以参考一下我上面的代码,有啥问题也可以在评论区唠唠。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)