企业级本地知识库:Dify+Ollama+RAG实战
摘要:本文详细介绍了如何搭建企业级本地RAG知识库系统,主要包含三个核心组件:Ollama(本地大语言模型部署工具)、Dify(可视化AI应用开发平台)和RAG(检索增强生成技术)。文章首先解释了这三个组件的概念、作用及协同关系,然后提供了基于Docker的完整部署流程,包括Ollama的CPU/GPU版本配置、Dify的安装与设置,以及RAG知识库的创建方法。通过这套方案,企业可以构建一个安全、
前言:
欢迎来到这篇关于搭建企业级本地RAG知识库的教程。在开始“动手”之前,咱们得先搞清楚几个核心概念:Dify、Ollama 和 RAG 到底是什么?它们在这套方案中扮演什么角色?为什么我们要用它们?
想象一下,我们要建造一个只属于自己公司的“智能问答机器人”。这个机器人需要具备“大脑”(大语言模型)、“心脏”(数据和知识库)以及灵活的身躯(应用流程)。而我们今天的主角,就分别对应了这些部分。
一.简单介绍Dify、Ollama、RAG概念
1.Ollama:你的“本地大脑”管理员
一句话解释: Ollama 是一个让你能在自己的电脑或服务器上,轻松运行大语言模型(比如 Llama 3、Qwen 2 等)的工具。它就像是一个“模型管理员”,你只需要敲一行命令,它就能帮你把 AI 的大脑(模型)下载下来,并让它转起来。
概念与作用: 过去,我们要用 AI,大多得通过网络调用 OpenAI 等公司的 API(应用程序编程接口)。这意味着我们的数据需要发送到别人那里,对于企业来说,这存在很大的数据安全隐患。而 Ollama 的出现解决了这个问题 。
-
核心价值:本地私有化部署。它把所有计算都放在你自己的机器上,数据“足不出户”,彻底规避了隐私泄露的风险 。
-
简单易用:它封装了复杂的底层配置(如 GPU(图形处理器)加速、模型依赖等),让你感觉像是在用 App Store 一样管理模型。想用 Llama 3 就用
ollama run llama3,想用阿里的千问就用ollama run qwen2。 -
硬件友好:Ollama 对硬件非常友好,不仅支持 GPU 加速,也能在只有 CPU 的环境下运行,大大降低了企业和个人玩转大模型的门槛 。
-
大数据分析佐证: 根据百度智能云的一篇文章指出,传统使用 AI 的方式面临“硬件门槛高”和“技术复杂度高”两大痛点。Ollama 通过“零依赖运行”和“开箱即用”的特性,让中小企业甚至个人开发者都能以极低的成本构建自己的 AI 能力中心,推动了 AI 技术的“民主化”进程。
2.Dify:你的“AI 应用装配工厂”
一句话解释: 如果说 Ollama 提供了“大脑”,那 Dify 就是那个把“大脑”装进身体、赋予它行动能力的装配工厂。它是一个开源的、可视化的 AI 应用开发平台,让你可以通过“拖拖拉拉”的方式,把模型、知识库、各种工具组合起来,变成一个真正能用的应用(比如客服机器人)。
概念与作用: 想象一下,没有 Dify 之前,开发者要写大量的代码去连接模型、处理文档、管理对话流程。而 Dify 把这些繁琐的后台工作(后端即服务,BaaS)和模型运维(LLMOps,大语言模型运维)都打包好了 。
-
可视化编排:它提供了一个画布,你可以像画流程图一样,把“用户输入”、“知识库检索”、“调用大模型”、“返回结果”这些节点拖拽到一起,几分钟就能搭好一个应用,开发周期从“数周”缩短到“分钟级” 。
-
企业级功能:它内置了处理 PDF、Word 等文档的能力,可以自动清洗、分段,并存入向量库;还支持接入不同的模型(比如我们刚用 Ollama 部署的本地模型),以及设置权限和监控日志 。
-
RAG 管道集成:Dify 最强大的地方在于,它把 RAG(检索增强生成)的整个流程都做成了标准化模块,开箱即用 。
大数据分析佐证: 阿里云开发者社区的文章指出,Dify 作为一个融合 BaaS 与 LLMOps 的开源平台,其核心优势在于“可视化工作流 + 预置组件 + 企业级引擎”。某金融客户在使用 Dify 后,风险评估流程从 3 天压缩至 2 小时,错误率下降 90% 。这表明 Dify 能极大提升 AI 应用的落地效率。
3.RAG:让 AI 拥有“实时更新的知识库”
一句话解释: RAG(检索增强生成)是一种让大模型在回答问题前,先去你的知识库里“查资料”的技术。它解决了大模型“一本正经胡说八道”(幻觉)和知识过时的问题 。
概念与作用: 大模型本身的知识是训练时“记住”的,就像高考前的学生,知识截止到考试那天。如果你问它公司最新的内部规章制度,它肯定不知道。RAG 就是来解决这个问题的。
-
工作原理三步走:
检索:当你提问时,RAG 系统会先去你的“知识库”(比如一堆公司文档)里,找出与问题最相关的内容片段 。
增强:它把找到的这些内容片段,连同你的问题,一起组装成一个更详细的提示词 。
生成:然后,它才把这个“加料”后的提示词发给大模型,让大模型基于你提供的资料来生成答案 。
-
核心优势:
知识实时更新:你只需要更新知识库里的文档,AI 就能学到新知识,无需重新训练模型 。
答案有据可循:AI 的回答不再是“凭空捏造”,而是基于你提供的资料,大大提升了准确性和可信度 。
保护私有知识:整个检索过程在本地进行,企业的核心文档和数据不会泄露出去 。
大数据分析佐证: 达观数据在一篇关于企业知识库的文章中提到,传统知识库面临“静态化”、“检索模糊化”的困境。引入 RAG 技术后,某重型机械企业的设备故障修复时间从 4.5 小时缩短至 1.3 小时(效率提升 70%),年损失降低超 5000 万 。百度开发者中心的文章也强调,RAG 通过 Embedding 模型和向量数据库的结合,在智能客服场景中可将问题解决率提升 40% 。
总结:三位一体,构建企业级本地知识库
现在我们把这三个概念串起来:
我们用 Ollama 在本地服务器上部署了一个强大的“大脑”(比如 Llama 3 模型)。
我们有很多公司内部的“知识文档”(产品手册、规章制度等)。
RAG 提供了一套方法论,教“大脑”如何根据你的问题去这些文档里“查资料”再回答。
而 Dify 则是一个强大的“操作台”,它把 Ollama(大脑)、知识文档(知识库)和 RAG(查资料的方法论)完美地整合在一起,让我们能通过点点鼠标、拖拽组件的方式,快速构建出一个智能、安全、不涉及网络延迟的企业级本地知识库问答系统。
这就是我们接下来要一步一步搭建的东西。听起来是不是既强大又清晰?准备好,我们马上开始动手实践!
二.搭建流程(采用docker方式)
博主有话说:
这里先说明一下,我使用的是Ubuntu 24.04.3 LTS系统,内核版本为Linux 6.14.0-37-generic,我这台服务器是有2块GPU显卡的,所以演示的时候使用的Ollama为GPU版本,当然我也给出了CPU版本的yml文件,可以直接使用,一键启动!
1.Ollama 搭建部署
(1) CPU版
root@ai:/AI/ollama# vim docker-compose.yml
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: always
ports:
- "11434:11434"
environment:
- OLLAMA_HOST=0.0.0.0
volumes:
- ./ollama_data:/root/.ollama
networks:
- docker_default
networks:
docker_default:
external: true(2) GPU版,增加参数
root@ai:/AI/ollama# nvidia-smi
Tue Mar 3 11:28:56 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.163.01 Driver Version: 550.163.01 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA RTX A6000 Off | 00000000:21:00.0 Off | Off |
| 30% 28C P8 22W / 300W | 44MiB / 49140MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA RTX A6000 Off | 00000000:23:00.0 Off | Off |
| 30% 28C P8 27W / 300W | 13MiB / 49140MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 2974 G /usr/lib/xorg/Xorg 22MiB |
| 0 N/A N/A 3594 G /usr/bin/gnome-shell 9MiB |
| 1 N/A N/A 2974 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------------------+
root@ai:/AI/ollama# vim docker-compose.yml
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
environment:
- OLLAMA_HOST=0.0.0.0
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=compute,utility
runtime: nvidia
volumes:
- ./ollama_data:/root/.ollama
networks:
- docker_default
networks:
docker_default:
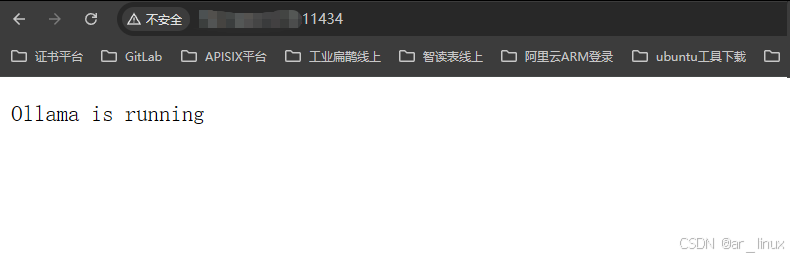
external: true服务启动之后可以在浏览器访问一下 http://localhost:11434/ ,如图所示,说明Ollama服务启动成功,接下来需要拉取我们需要的大模型
(3) 拉取大模型并运行
方法一:
# 先进入容器交互式终端
docker exec -it ollama /bin/bash
# 在容器内执行(现在已经在容器里了)
ollama run qwen2.5:7b
方法二:
# 进入容器并运行/下载模型
docker exec -it ollama ollama run qwen2.5:7b
解释:
ollama pull:只下载模型,不运行
ollama run:如果本地没有该模型,会先自动下载,然后再运行,直接进入对话界面2.Dify 搭建部署
官方部署文档地址:https://docs.dify.ai/zh/self-host/quick-start/docker-compose
API参考:https://docs.dify.ai/api-reference/documents/create-a-document-from-a-file
(1)部署前准备
请确保你的机器满足以下最低系统要求。
硬件
-
CPU >= 2 Core
-
RAM >= 4 GiB
软件
| 操作系统 | 所需软件 | 说明 |
|---|---|---|
| macOS 10.14 或更高版本 | Docker Desktop | 将 Docker 虚拟机配置为至少 2 个虚拟 CPU 和 8 GiB 内存。 安装说明请参阅 Mac 版 Docker Desktop 安装指南。 |
| Linux 平台 | Docker 19.03+ Docker Compose 1.28+ | 安装说明请参阅 Docker 引擎安装指南 和 Docker Compose 安装指南。 |
| 启用了 WSL 2 的 Windows | Docker Desktop | 建议将源代码和绑定到 Linux 容器的数据存储在 Linux 文件系统中,而不是 Windows 文件系统中。 安装说明请参阅 Windows 版 Docker Desktop 安装指南。 |
(2)部署并启动Dify
克隆Dify仓库:git clone https://github.com/langgenius/dify.git
小白如果看不懂以上git操作,也可以直接在github上下载zip压缩包,然后通过远程工具传输到服务器中进行解压,我下边的演示就是通过zip包获取
地址:https://github.com/langgenius/dify/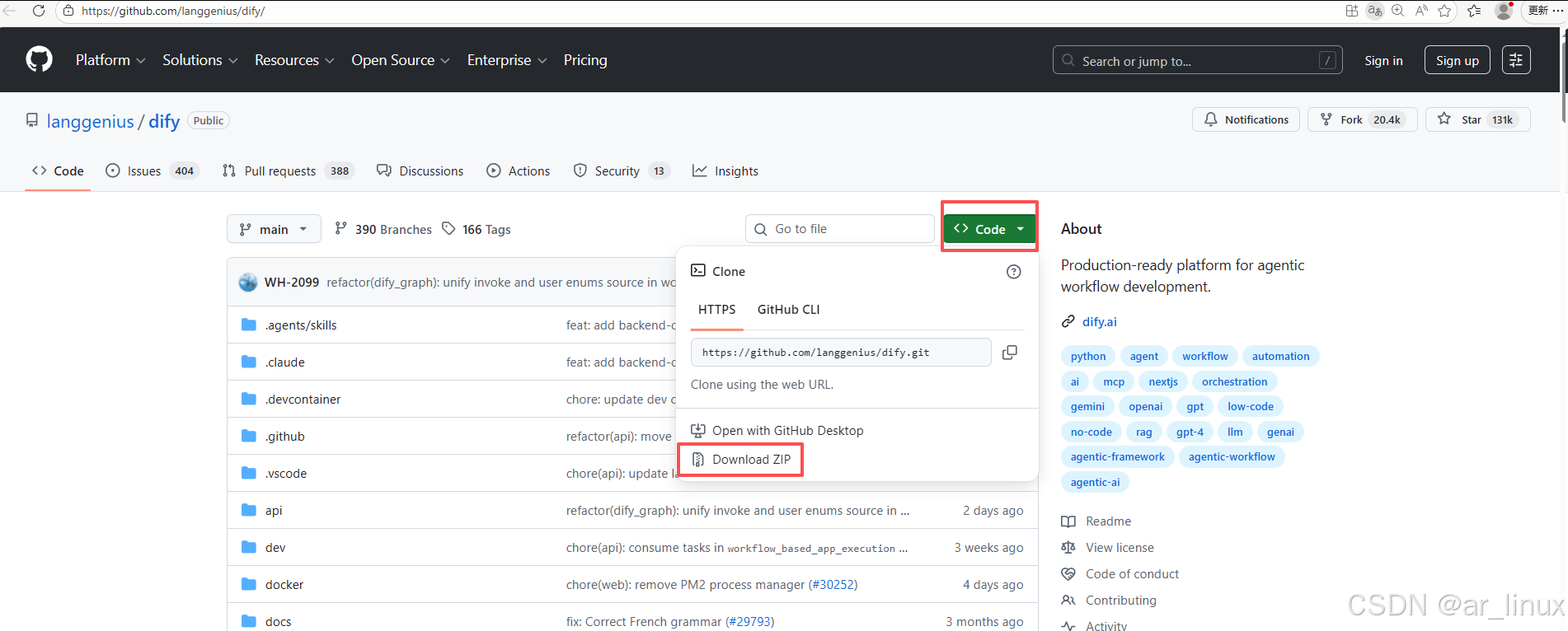
环境配置以及启动服务
#导航到 Dify 源代码中的 docker 目录
root@ai:/AI/dify# ll
total 23260
drwxr-xr-x 3 root root 4096 Jan 9 14:08 ./
drwxr-xr-x 6 root root 4096 Jan 29 10:26 ../
drwxr-xr-x 4 root root 4096 Jan 11 19:42 dify-main/
-rw-r--r-- 1 root root 23802776 Jan 9 14:07 dify-main.zip
root@ai:/AI/dify# cd dify-main/docker/
#复制示例环境配置文件
root@ai:/AI/dify# cp .env.example .env
#注意:当前端和后端运行在不同子域名时,需要在 .env 文件中将 COOKIE_DOMAIN 设置为站点的顶级域名(例如 example.com),并将 NEXT_PUBLIC_COOKIE_DOMAIN 设置为 1。前端和后端必须位于同一顶级域名下才能共享认证 Cookie。
#查看项目完整目录
root@ai:/AI/dify/dify-main/docker# ll
total 500
drwxr-xr-x 12 root root 4096 Mar 3 09:20 ./
drwxr-xr-x 4 root root 4096 Jan 11 19:42 ../
drwxr-xr-x 2 root root 4096 Jan 8 22:53 certbot/
drwxr-xr-x 2 root root 4096 Jan 8 22:53 couchbase-server/
-rwxr-xr-x 1 root root 14857 Jan 8 22:53 dify-env-sync.sh*
-rw-r--r-- 1 root root 10211 Jan 8 22:53 docker-compose.middleware.yaml
-rw-r--r-- 1 root root 174447 Jan 8 22:53 docker-compose.png
-rw-r--r-- 1 root root 32731 Jan 8 22:53 docker-compose-template.yaml
-rw-r--r-- 1 root root 74036 Mar 3 09:20 docker-compose.yaml
drwxr-xr-x 2 root root 4096 Jan 8 22:53 elasticsearch/
-rw-r--r-- 1 root root 53824 Jan 9 14:14 .env
-rw-r--r-- 1 root root 53824 Jan 8 22:53 .env.example
-rwxr-xr-x 1 root root 4097 Jan 8 22:53 generate_docker_compose*
drwxr-xr-x 2 root root 4096 Jan 8 22:53 iris/
-rw-r--r-- 1 root root 8461 Jan 8 22:53 middleware.env.example
drwxr-xr-x 4 root root 4096 Jan 8 22:53 nginx/
drwxr-xr-x 2 root root 4096 Jan 8 22:53 pgvector/
-rw-r--r-- 1 root root 8942 Jan 8 22:53 README.md
drwxr-xr-x 2 root root 4096 Jan 8 22:53 ssrf_proxy/
drwxr-xr-x 2 root root 4096 Jan 8 22:53 startupscripts/
drwxr-xr-x 3 root root 4096 Jan 8 22:53 tidb/
drwxr-xr-x 12 root root 4096 Jan 12 08:48 volumes/
服务端口配置修改(可选)
考虑到端口占用的问题,如果需要修改dify可视化界面端口,需要调整相关配置项 。将变量EXPOSE_NGINX_PORT修改为新的可视化界面端口。
修改.env文件下,Nginx的默认端口号。80改成81,443改成4433等非默认端口,防止冲突。
EXPOSE_NGINX_PORT=81
EXPOSE_NGINX_SSL_PORT=4433
#启动服务
root@ai:/AI/dify# cd dify-main/docker/
root@ai:/AI/dify/dify-main/docker# docker compose up -d如果启动报错,大概率是镜像没有拉下来,dify用到的镜像大都是国外镜像,需要开代理拉取
涉及到的镜像列表
root@aiinside:/xsensus/AI/dify/dify-main/image# ll
total 5514216
drwxr-xr-x 2 root root 4096 Jan 11 21:34 ./
drwxr-xr-x 4 root root 4096 Jan 11 19:42 ../
-rw-r--r-- 1 root root 4677120 Jan 11 19:37 busybox-latest.tar
-rw-r--r-- 1 root root 2536400384 Jan 11 19:30 dify-api-1.11.2.tar
-rw-r--r-- 1 root root 1522632192 Jan 11 19:30 dify-plugin-daemon-0.5.2-local.tar
-rw-r--r-- 1 root root 595398144 Jan 11 19:32 dify-sandbox-0.2.12.tar
-rw-r--r-- 1 root root 417000448 Jan 11 19:28 dify-web-1.11.2.tar
-rw-r--r-- 1 root root 164290048 Jan 11 19:27 nginx-latest.tar
-rw-r--r-- 1 root root 31015936 Jan 11 19:32 redis-6-alpine.tar
-rw-r--r-- 1 root root 213025792 Jan 11 19:31 squid-latest.tar
-rw-r--r-- 1 root root 162062848 Jan 11 19:38 weaviate-1.27.0.tar
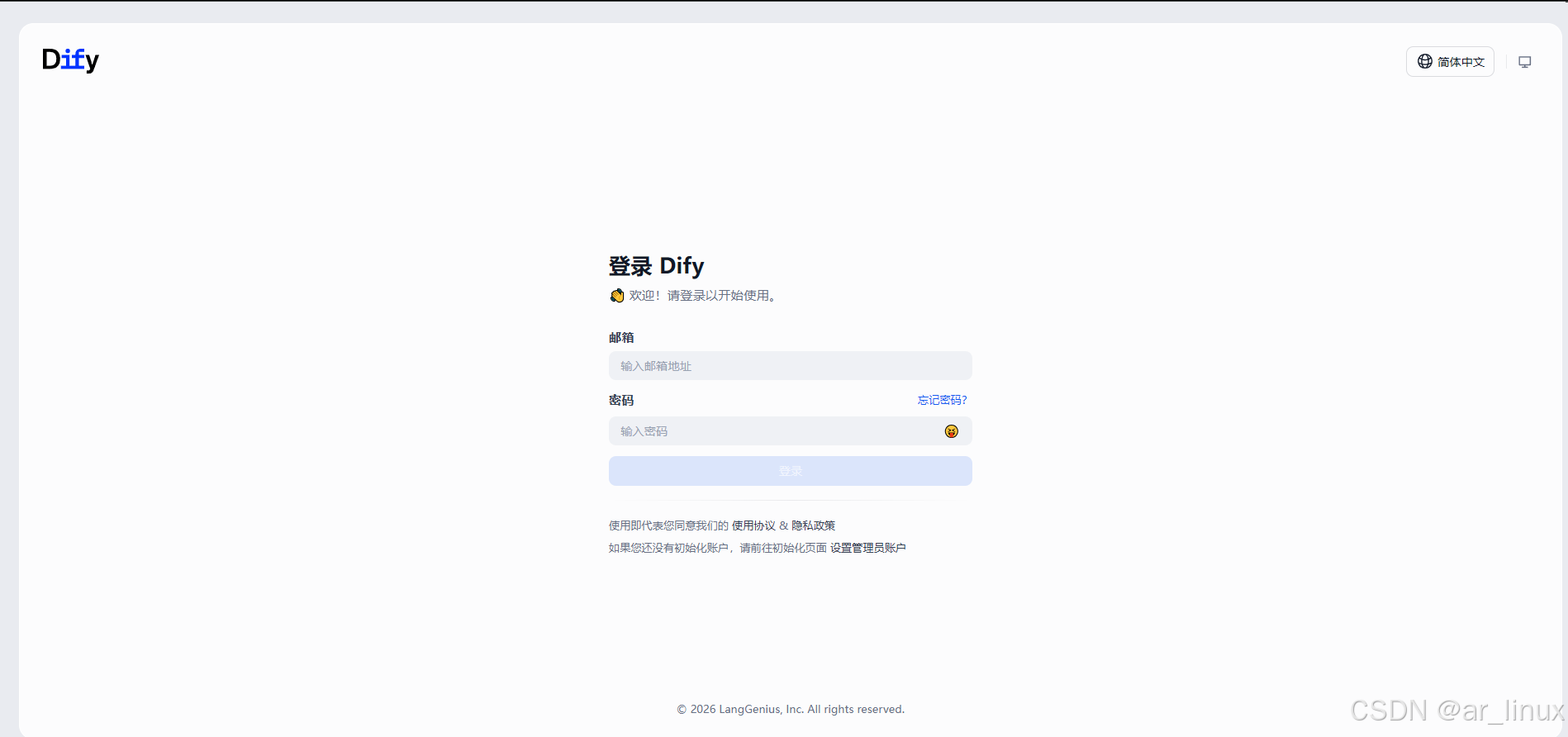
服务启动之后,浏览器访问地址 http://localhost 进入Dify可视化界面,首次进入需要注册用户登录信息。注册完后,将出现登录界面。
3.RAG知识库搭建
进入Dify后顶部可以看到知识库功能,选择创建知识库,按照步骤来即可,这里不多赘述
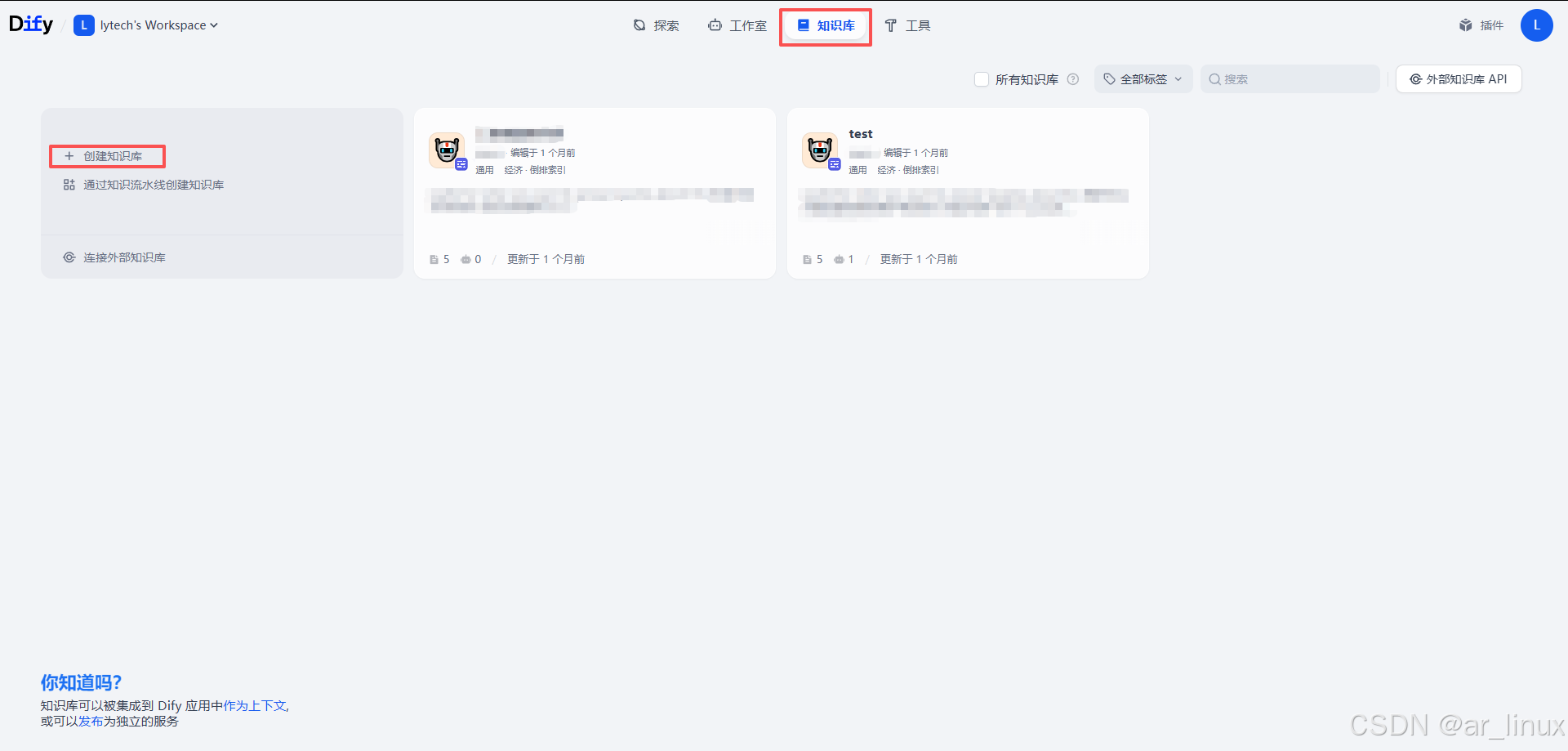
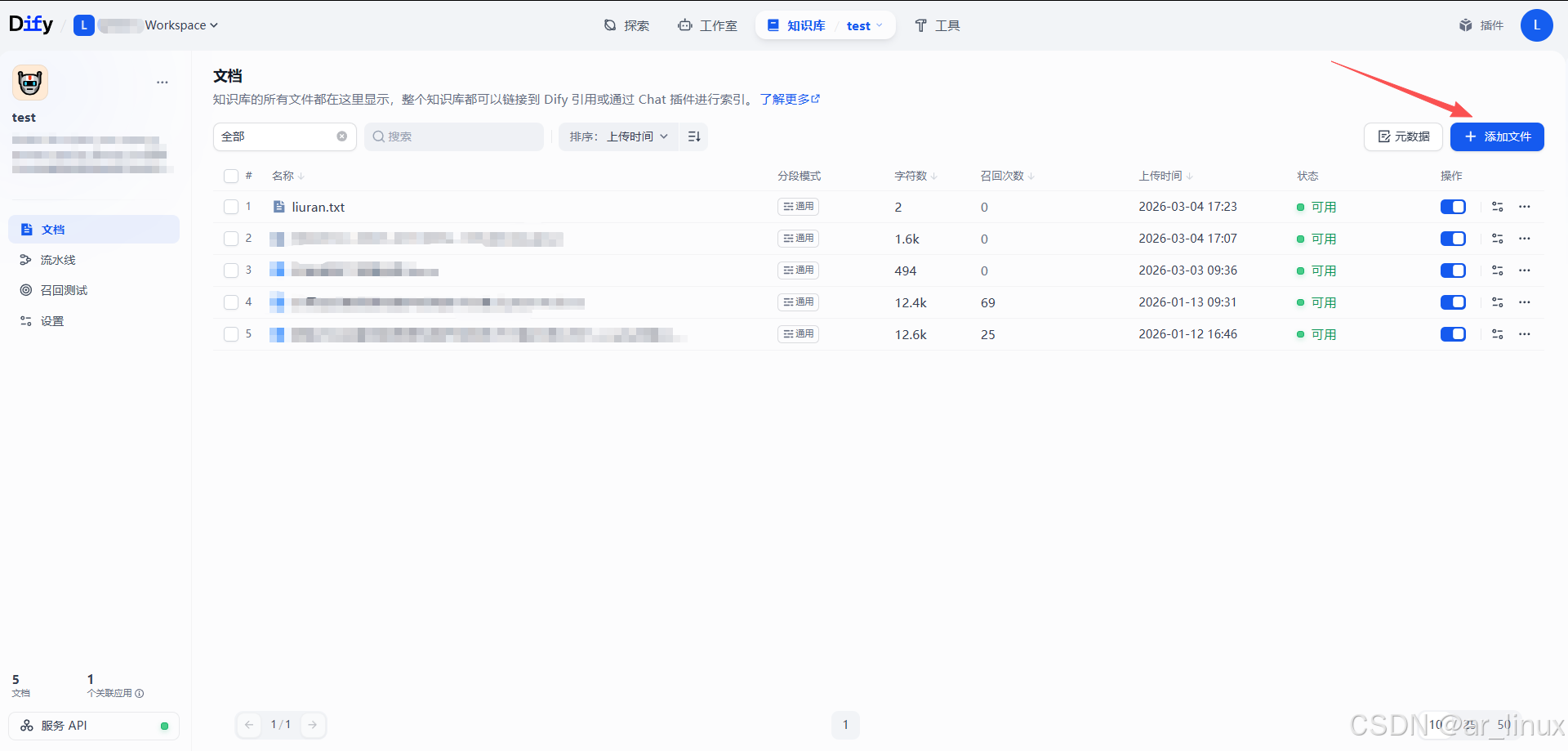
可以在这里上传知识库的文档
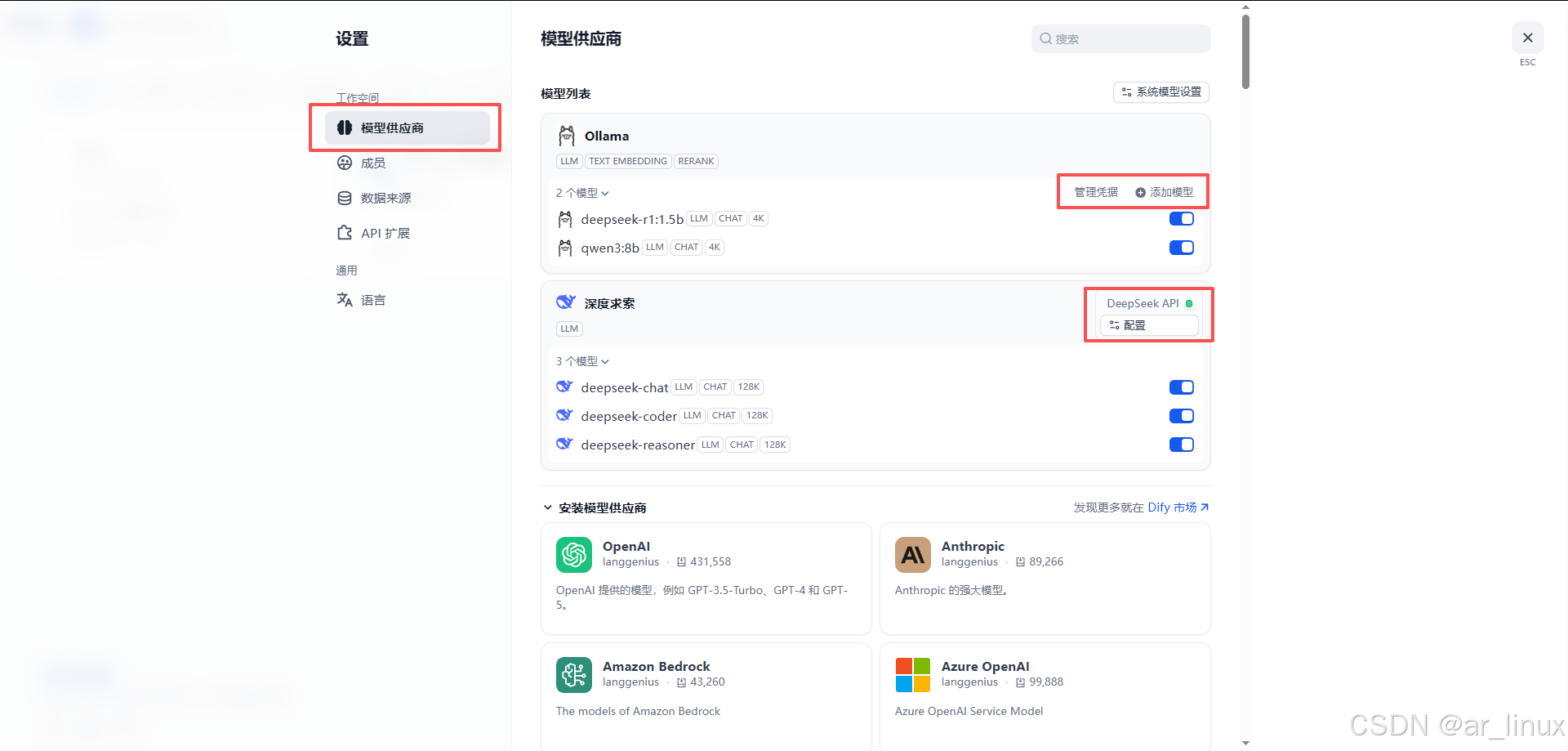
接入大模型
我这里是配置了两个,第一个就是前边部署的Ollama,另一个是公司购买的DeepSeek官方的API
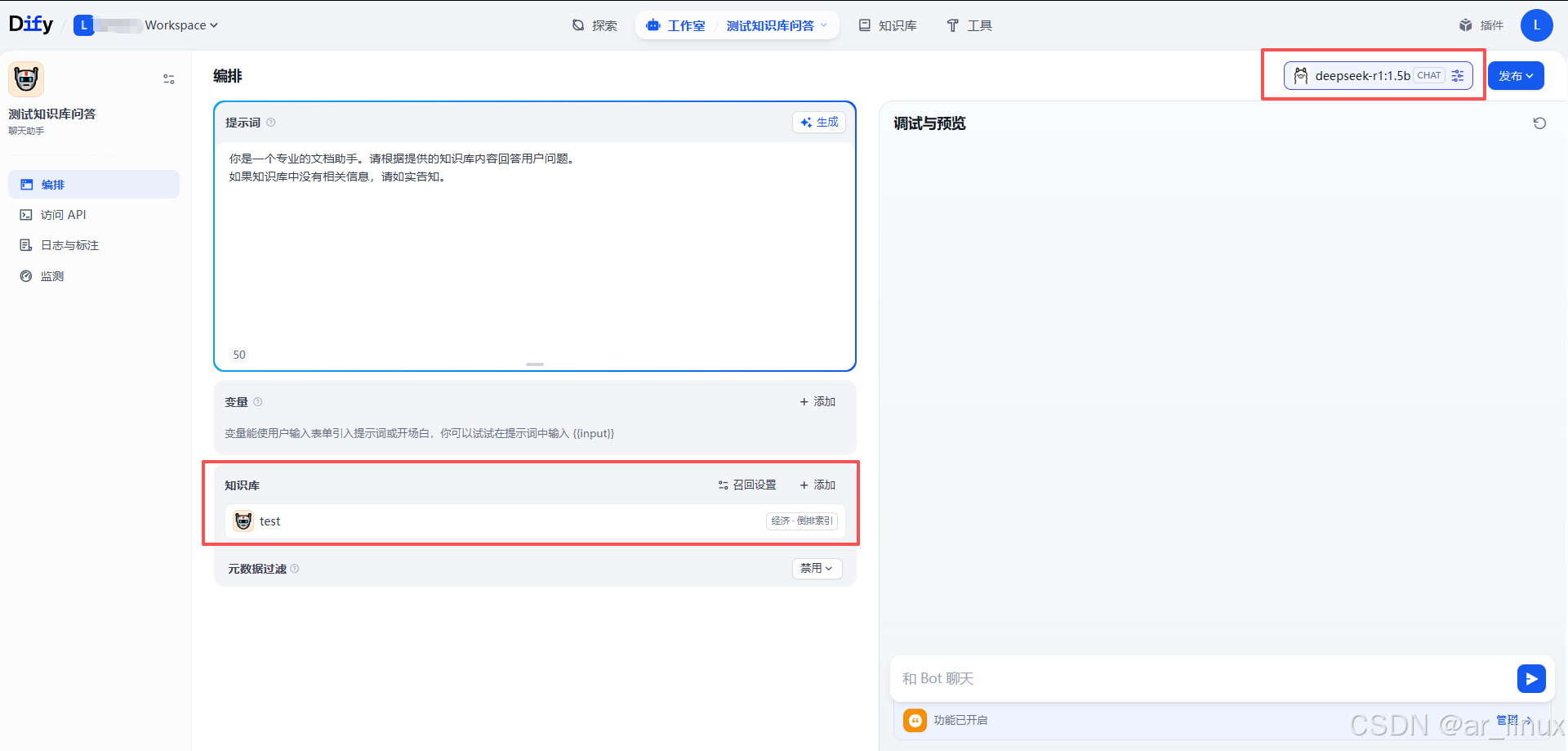
选择工作室,然后创建一个聊天助手,一定要配置并保存启用之前创建的测试知识库,然后此时可以在右侧进行测试
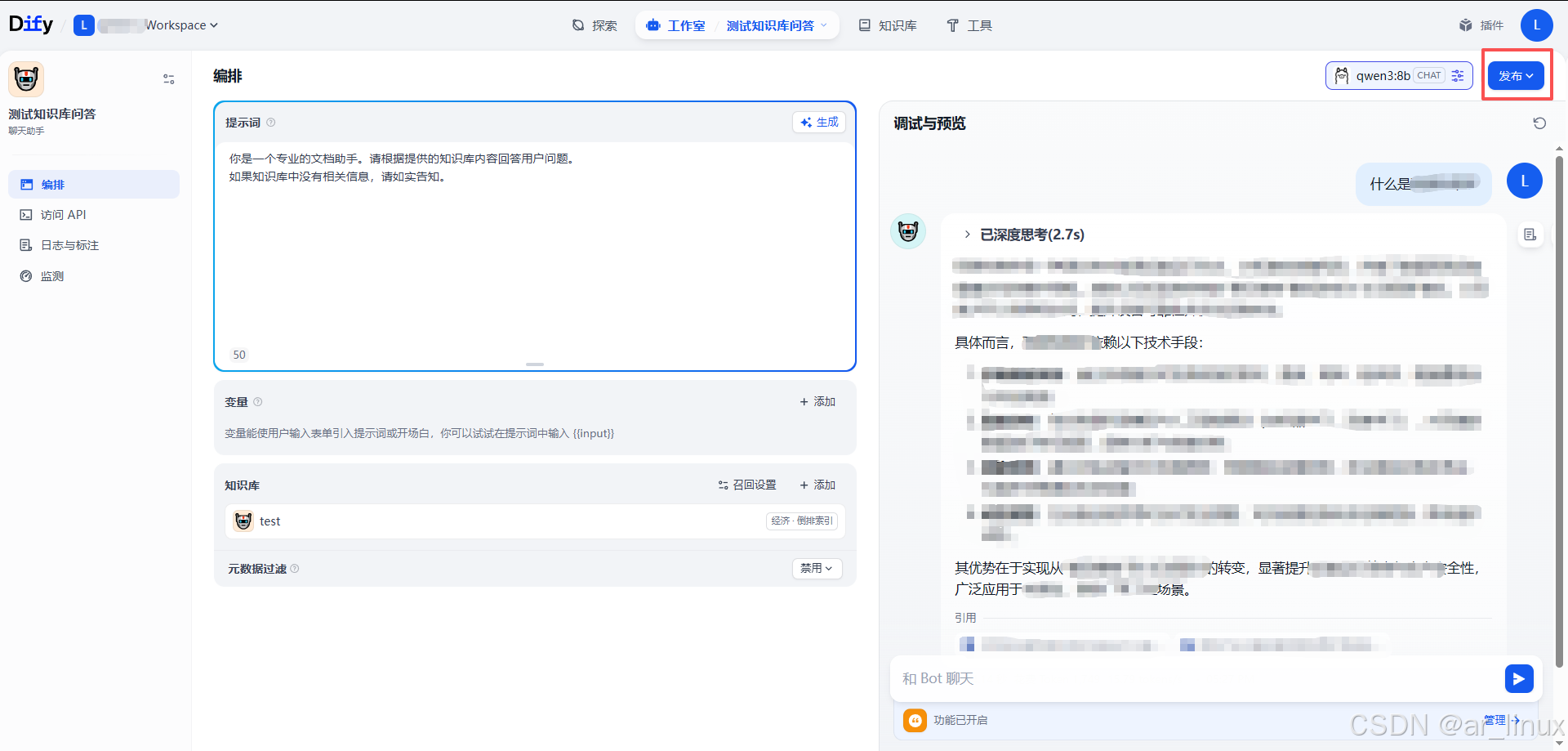
测试完没什么问题后可以点击发布,就会获得一个聊天助手了,想要获取准确回答就要多喂数据到知识库中
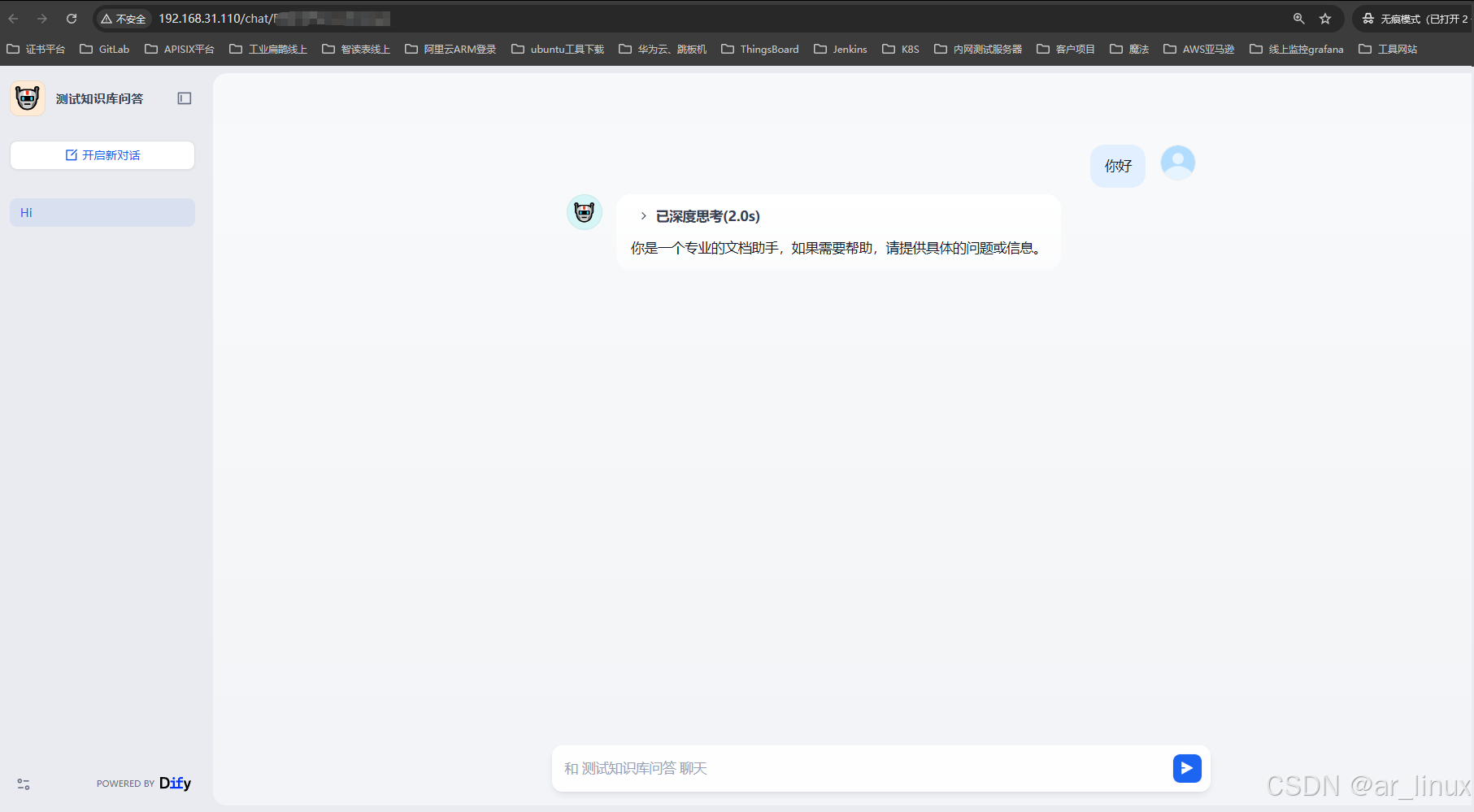
还可以搞工作流,自动化等,也可以结合n8n进行使用。
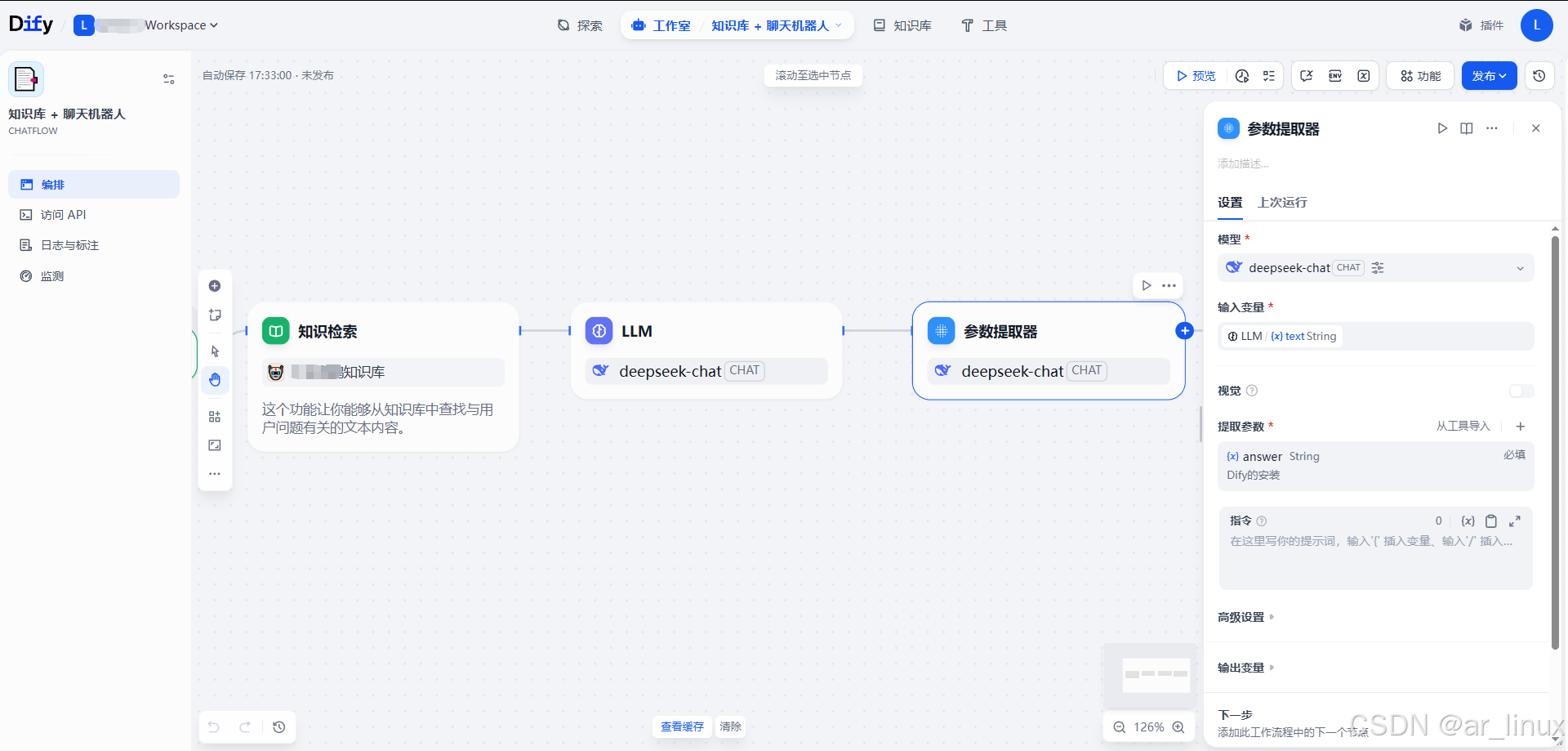
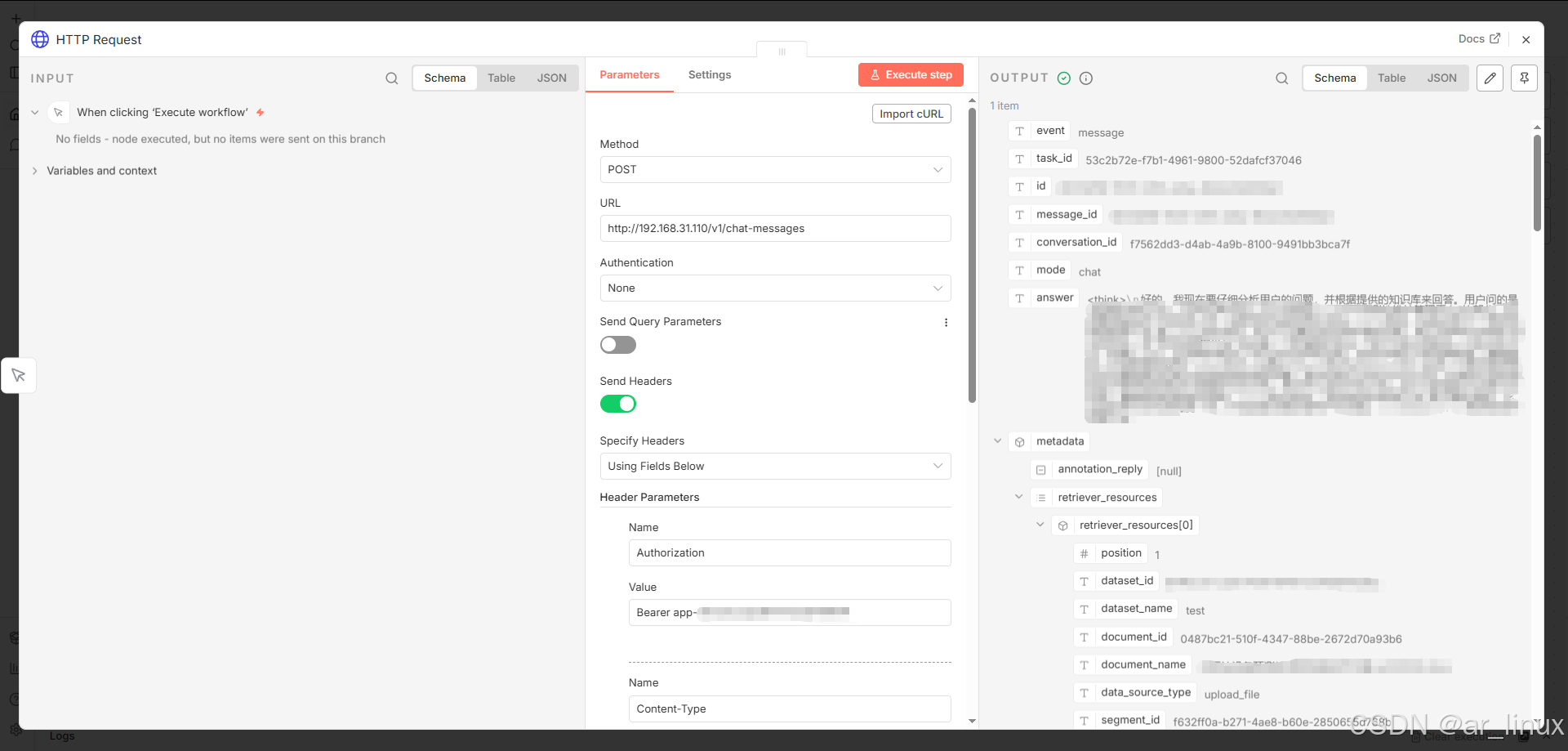
另外Dify也是支持外接知识库的,这个我没有测试过,官方有提供文档,我把链接放在这里
https://docs.dify.ai/zh/use-dify/knowledge/connect-external-knowledge-base
用户指南:介绍 - Dify 文档
有需要的朋友可以参考文档自行测试,有问题可在评论区交流!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)