(2025|CVPR|Meta,dino.txt,冻结 ViT,拼接类别和图像嵌入,基于对比的图文对齐,LiT)DINOv2 遇见文本:用于图像和像素的视觉语言对齐框架
本文提出 dino.txt,它成功地将一个从零训练的文本编码器与冻结的自监督视觉模型 DINOv2 对齐,从而解锁了开放词汇能力。该方法结合了无需人工标注的自监督数据筛选技术,实现了快速训练,并在零样本分类和开放词汇分割上取得了顶尖性能。
DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment

论文地址:https://arxiv.org/abs/2412.16334
项目页面:https://github.com/facebookresearch/dinov3
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
【由于 dino.txt 的源码并未直接给出,而在 DINOv3(参考我明天的博文)中使用的与文本对齐的方法遵循 dino.txt。因此,此处的项目页面放的是 DINOv3 的。】
目录
1. 引言
自监督视觉基础模型能产生强大的特征嵌入,在多种下游任务中表现卓越。然而,与 CLIP 等视觉-语言模型不同,自监督视觉特征并未与语言天然对齐,这限制了其在开放词汇任务中的应用。
本文提出的方法名为 dino.txt,旨在为广泛使用的自监督视觉编码器 DINOv2 解锁这一新能力。
(2024|TMLR|Meta,DINOv2,ViT,自蒸馏,iBOT,SwAV 中心化,判别式自监督预训练,分类/分割,分辨率调整)无监督稳健的视觉特征学习
本文基于 图像锁定的文本调优(Locked-image text tuning,LiT)训练策略,该策略训练一个文本编码器以与冻结的视觉模型对齐。
然而,直接将 LiT 应用于强大的 DINOv2 编码器并非易事,在需要细粒度细节的任务(如语义分割或图像-文本检索)上表现不佳。这主要是因为:
- 从仅对比全局图像和文本表示的 CLIP/LiT 训练范式中,难以获得良好的密集特征(dense features);
- 冻结的视觉编码器导致的视觉预训练数据与 LiT 训练数据之间的领域差异,可能会阻碍图像与其描述的对齐。
为解决这些问题,本文对 LiT 范式进行了几项改进:
-
改进的图像表示:不再仅使用 [CLS] token,而是将其与所有图像块 token 的平均池化结果拼接,作为视觉表示,以同时将图像的全局上下文和局部信息与其文本描述对齐。
-
增加可学习模块:在冻结的视觉编码器之上添加两个可学习的视觉块,使视觉特征能够适应新的训练数据,从而减少领域差异。
预训练数据的质量对模型性能影响巨大。
- 本文通过同时关注文本和图像模态的数据分布,对训练数据集进行平衡筛选。
- 一个良好平衡的数据分布简化了训练过程,使本文仅用一小部分计算成本就能达到良好性能,并允许本文尝试更大的文本编码器,进一步提升性能。
3. dino.txt
本文展示了对齐文本编码器与自监督视觉基础模型的简洁与高效。模型能直接在基础模型的嵌入空间上进行零样本分类和开放词汇语义分割。
3.1. 图像锁定的文本对齐
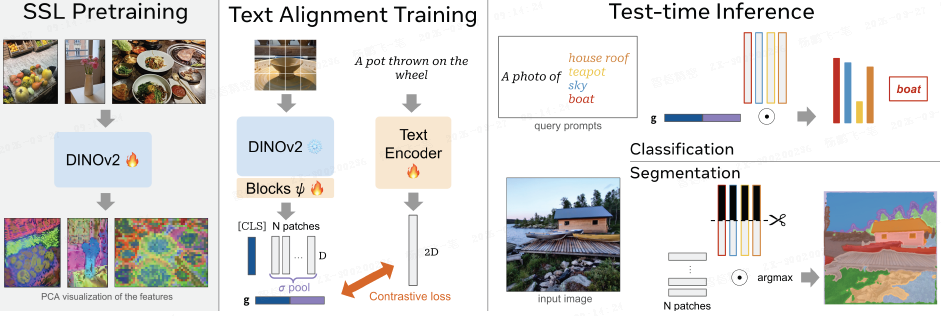
图像与文本编码器:
- 图像编码器使用冻结的 DINOv2 ViT 模型。
- 文本编码器是一系列 Transformer 块和一个线性层,遵循 LiT,其参数从头开始训练。
改进的用于文本对齐的图像表示:
1)拼接表示:为同时实现全局和局部对齐,将图像表示定义为
![]()
其中,c' 是经过可学习视觉块更新的 [CLS] token。σ 是平均池化操作,作用于更新后的图像 patch token。
该表示维度为 2D,同时包含了全局(类别)和局部(图像 patch)信息。
2)可学习视觉块:在冻结的 DINOv2 模型之后添加两个可训练的 Transformer 块 ψ,用于微调视觉特征以更好地适应文本对齐,同时保持输出维度不变。
![]()
对比式图像锁定文本对齐:
- 使用对比学习目标,将上述图像描述符
g与对应的文本嵌入拉近,并推远非配对样本。 - 训练部分仅包括新增的视觉块和文本编码器。
3.2. 基于文本和图像的数据筛选
仅依赖文本的数据筛选(如 MetaCLIP)可能因图像与文本描述不完美对齐而效果不佳。因此,本文提出结合两种筛选方法:
-
文本筛选:采用 MetaCLIP 的方法,基于预定义的概念集(如 WordNet)对数据池中的图像-文本对进行平衡采样。
-
图像筛选:采用 Vo et al. 的基于聚类的方法,使用 DINOv2 提取图像特征,并通过分层 k-means 聚类,从不同大小的簇中均匀采样,以平衡视觉概念的分布。
-
最终数据集:取两种筛选结果的交集,构建最终的训练数据集 LVTD-2.3B。
3.3. 推理
图像级任务(分类/检索):使用全局图像描述符 g 与编码后的文本查询计算余弦相似度。
像素级任务(分割):
- 使用模型输出的每个图像 patch 的特征 f'_p,以及文本嵌入中与平均池化的 patch 对齐的部分,直接计算它们的余弦相似度,然后上采样到原始图像分辨率。
- 这种方法无需像 MaskCLIP 那样进行特殊的模型适配。
4. 实验
4.1. 任务与指标
评估了零样本分类、图像-文本检索和开放词汇语义分割任务,并使用了相应的标准指标(如准确率、Recall@1、mIoU)。
4.2. 实现细节
训练:使用 PyTorch,CLIP 损失函数来自 OpenCLIP。DINOv2 视觉编码器冻结,使用 32K 或 65K 的大 batch,仅训练 50K 步(约 1.6~3.2B 样本)。
训练数据集:LVTD-2.3B,由 2.3B 原始 CommonCrawl 数据经过文本和图像筛选后得到,每个 epoch 采样 650M 对。
高分辨率推理:采用滑动窗口策略,采样不同大小和形状的作物,提取特征后融合,并使用 k-means 聚类和零样本分类器进行预测。
4.3. 方法消融研究
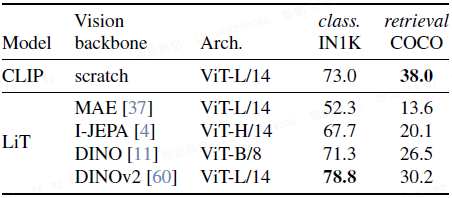
LiT 与 SSL 视觉模型:如上表所示,在多个冻结的 SSL 模型中,DINOv2 表现最佳。但相比 CLIP,其在检索任务上存在差距,说明需要新策略(也就是本文的改进)。
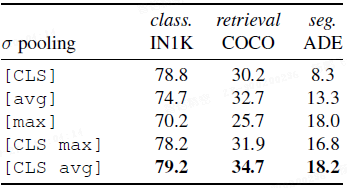
池化操作的影响:如上表所示,单独使用 [avg] 或 [max] 池化会损害分类性能,而提出的 [CLS avg] 拼接策略则在分类、检索和分割任务上都取得了最佳或显著提升的效果。
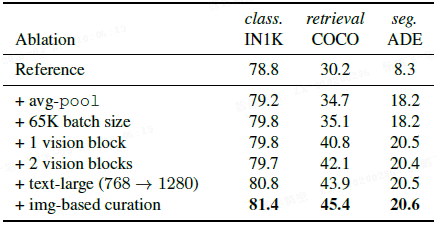
改进的训练策略:上表逐步展示了各组件的作用。从基础 LiT 开始,依次加入 [CLS avg] 池化、更大批量、1-2个可学习视觉块、更大的文本编码器、以及图像+文本联合筛选,各项指标(尤其是检索和分割)持续提升。
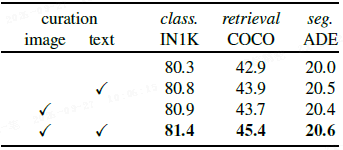
数据筛选的影响:如上表所示,文本筛选和图像筛选各自都能提升性能,而两者的结合效果最佳,验证了联合筛选的重要性。
4.4. 与现有技术比较
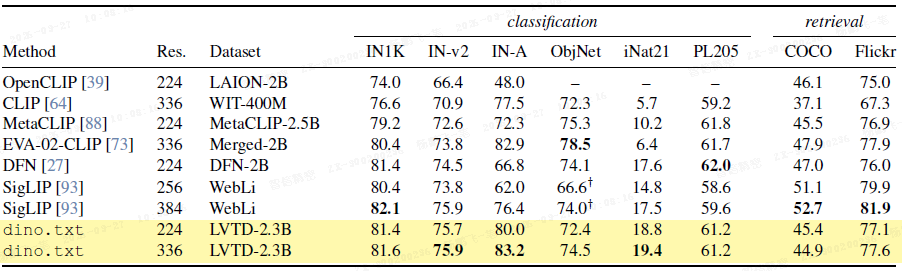
零样本分类与检索:如上表所示,dino.txt 在多个分类基准(尤其是 ImageNet-v2, -A, iNaturalist)上达到或超越了现有 CLIP 类模型,但在检索任务上略低于 SigLIP。

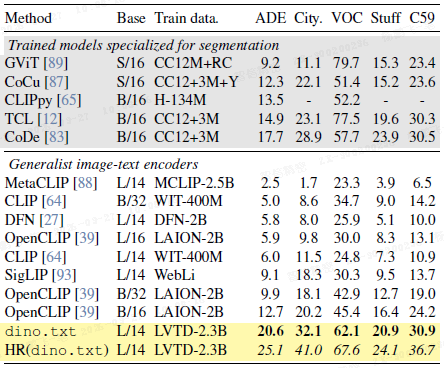
开放词汇分割:如上表所示,dino.txt 在所有分割基准上均大幅超越其他通用的图像-文本编码器,并与专门为分割设计的模型性能相当甚至更好。这得益于其同时优化的图像级和像素级对齐能力。
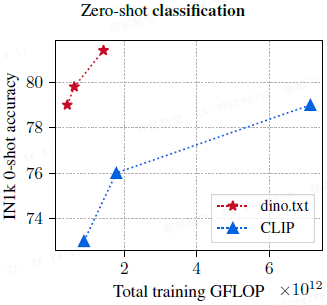
训练效率:如上图所示,dino.txt 达到 SOTA 分类精度所需的计算量(GFLOPS)远小于从头训练的 CLIP。
4.5. 进一步分析
失败模式分析:
-
物体边界:使用真实 mask 进行预测的 “上界” 实验表明,剩余的性能差距主要源于图像与文本的对齐误差。
-
物体重叠:模型能预测出重叠物体,但数据集的标注通常将重叠物体视为单一实体(例如,窗户是在建筑物上的),导致评分偏低。
-
类别名称:数据集的类别名称(如 "person")与模型训练数据中常见的词汇(如 "people")不匹配,通过优化类别名称可以显著提升 mIoU(+2.1)。
文本编码器质量:在 MTEB 基准上,dino.txt 的文本编码器性能弱于 CLIP 的文本编码器,表明冻结视觉编码器可能限制了文本编码器的潜力。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)