【Python/Pytorch - 网络模型】-- 手把手搭建3D ResUNet模型
·
文章目录
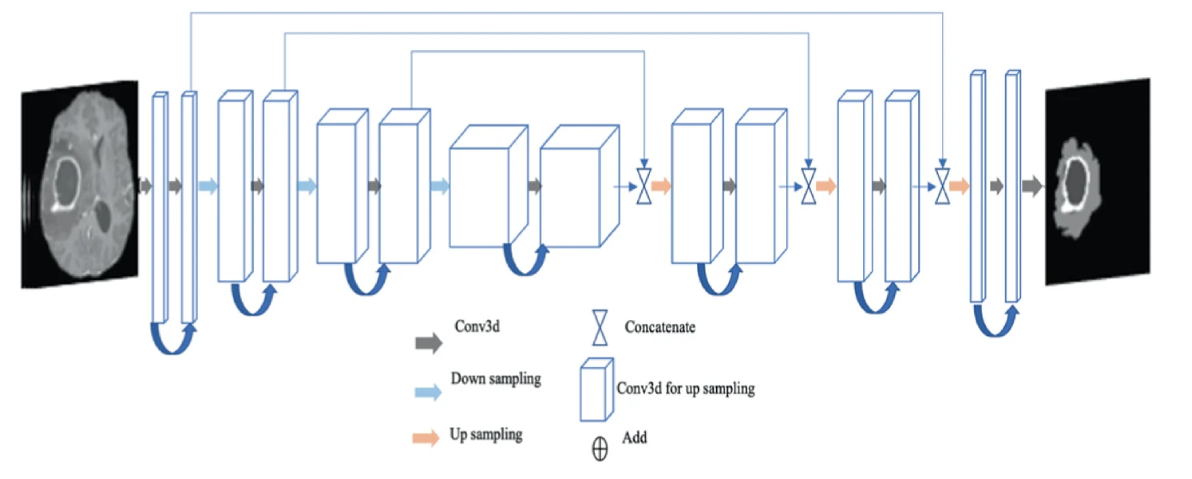
00 3D ResUNet模型
1、该网络模型是在U-Net模型基础上,结合3D 卷积模块、残差跳跃连接,构建了3D ResUNet模型;
2、在实验过程中,我将批归一化(BatchNorm3d)注释,其对MRI定量任务,存在较大影响。这块可根据各位的实验情况,进行灵活调整。
01 基于Pytorch版本的3D ResUNet代码
import torch
import torch.nn as nn
from torchinfo import summary
# UNet3DMMS is a 3D medical image segmentation model. It is:
# Based on U-Net architecture with encoder-decoder structure.
# Uses residual connections to make training easier, which can solve the problems of gradient disappearance and
# gradient explosion in deep neural networks.
# Has skip connections to keep detailed information.
# Works on 3D medical images (like MRI/CT) for heart structure segmentation.
class Conv3D_Block(nn.Module):
def __init__(self, in_feat, out_feat, kernel=3, stride=1, padding=1, residual=True):
"""
3D Convolutional Block with optional residual connection
Args:
in_feat (int): Number of input channels
out_feat (int): Number of output channels
kernel (int): Convolution kernel size, default 3
stride (int): Convolution stride, default 1
padding (int): Convolution padding, default 1
residual (bool): Whether to use residual connection, default True
"""
super(Conv3D_Block, self).__init__()
# Define the main path with two 3D convolutional layers
self.conv = nn.Sequential(
# First convolution + BN + ReLU
nn.Conv3d(in_feat, out_feat, kernel_size=kernel, stride=stride, padding=padding, bias=True),
# nn.BatchNorm3d(out_feat),
nn.ReLU(inplace=True),
# Second convolution + BN + ReLU
nn.Conv3d(out_feat, out_feat, kernel_size=kernel, stride=stride, padding=padding, bias=True),
# nn.BatchNorm3d(out_feat),
nn.ReLU(inplace=True)
)
# Residual connection flag
self.residual = residual
# If residual connection is enabled, 1x1x1 convolution is needed to match dimensions
if self.residual:
self.residual_conv = nn.Conv3d(in_feat, out_feat, kernel_size=1, stride=1, padding=0, bias=False)
def forward(self, x):
# Save input for residual
res = x
# If residual connection is enabled, return convolution result + residual
if self.residual:
return self.conv(x) + self.residual_conv(res)
else:
# Otherwise return only the convolution result
return self.conv(x)
class Up_Block(nn.Module):
def __init__(self, init_feat, scale_factor=(2, 2, 2)):
"""
3D Upsampling Block for decoder part of UNet architecture
Args:
init_feat (int): Number of input channels
scale_factor (tuple): Upsampling scale factor, default (2, 2, 2)
indicates doubling in depth, height and width
"""
super(Up_Block, self).__init__()
# Define 3D trilinear upsampling layer with align_corners=True for better geometric alignment
# align_corners=True is more suitable for tasks requiring strict geometric preservation
# (e.g., medical images) where boundary accuracy is critical
self.up = nn.Upsample(scale_factor=scale_factor, mode="trilinear", align_corners=True)
# Define 3x3 convolution layer to reduce the number of channels by half
self.conv = nn.Conv3d(init_feat, int(init_feat / 2), kernel_size=3, stride=1, padding=1, bias=True)
def forward(self, x):
"""
Forward pass
Args:
x (torch.Tensor): Input tensor [B, C, D, H, W]
Returns:
torch.Tensor: Output tensor [B, C/2, D*2, H*2, W*2]
"""
# Perform upsampling to increase spatial dimensions
out = self.up(x)
# Reduce channel count via convolution while extracting features
out = self.conv(out)
return out
class UNet3DMMS(nn.Module):
def __init__(self, input_ch=1, output_ch=4, init_feats=16):
"""
Multi-scale 3D UNet model designed for cardiac MRI segmentation
Args:
input_ch (int): Number of input channels, default 1 (grayscale MRI)
output_ch (int): Number of output channels, default 4 (corresponding to different cardiac structures)
init_feats (int): Initial number of feature channels, default 16
"""
super(UNet3DMMS, self).__init__()
# Encoder part: Use MaxPool3d with different kernel sizes for multi-scale downsampling
# Asymmetric pooling strategy to better handle anisotropic properties of 3D medical images
self.pool1 = nn.MaxPool3d(kernel_size=(1, 2, 2), stride=(1, 2, 2)) # Downsample only in H/W dimensions
self.pool2 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2)) # Downsample in D/H/W dimensions
self.pool3 = nn.MaxPool3d(kernel_size=(1, 2, 2), stride=(1, 2, 2))
self.pool4 = nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2))
self.pool5 = nn.MaxPool3d(kernel_size=(1, 2, 2), stride=(1, 2, 2))
# Decoder part: Use Up_Block for upsampling to gradually restore spatial resolution
self.up7 = Up_Block(init_feat=init_feats * 32, scale_factor=(1, 2, 2))
self.up8 = Up_Block(init_feat=init_feats * 16, scale_factor=(2, 2, 2))
self.up9 = Up_Block(init_feat=init_feats * 8, scale_factor=(1, 2, 2))
self.up10 = Up_Block(init_feat=init_feats * 4, scale_factor=(2, 2, 2))
self.up11 = Up_Block(init_feat=init_feats * 2, scale_factor=(1, 2, 2))
# Convolutional blocks: Use 3D convolutional blocks with residual connections (Conv3D_Block)
# to enhance feature extraction capabilities
self.conv1 = Conv3D_Block(in_feat=input_ch, out_feat=init_feats)
self.conv2 = Conv3D_Block(in_feat=init_feats, out_feat=init_feats * 2)
self.conv3 = Conv3D_Block(in_feat=init_feats * 2, out_feat=init_feats * 4)
self.conv4 = Conv3D_Block(in_feat=init_feats * 4, out_feat=init_feats * 8)
self.conv5 = Conv3D_Block(in_feat=init_feats * 8, out_feat=init_feats * 16)
self.conv6 = Conv3D_Block(in_feat=init_feats * 16, out_feat=init_feats * 32) # Bottleneck layer
# Decoder convolutional blocks
self.conv7 = Conv3D_Block(in_feat=init_feats * 32, out_feat=init_feats * 16)
self.conv8 = Conv3D_Block(in_feat=init_feats * 16, out_feat=init_feats * 8)
self.conv9 = Conv3D_Block(in_feat=init_feats * 8, out_feat=init_feats * 4)
self.conv10 = Conv3D_Block(in_feat=init_feats * 4, out_feat=init_feats * 2)
self.conv11 = Conv3D_Block(in_feat=init_feats * 2, out_feat=init_feats)
# Final 1x1x1 convolution layer: Convert feature maps to class predictions
self.conv12 = nn.Conv3d(init_feats, output_ch, kernel_size=1, stride=1, padding=0)
def forward(self, x):
"""
Forward pass
Args:
x (torch.Tensor): Input tensor [B, C, D, H, W]
Returns:
torch.Tensor: Output segmentation result [B, num_classes, D, H, W]
"""
# Encoder path: Feature extraction and downsampling
conv1 = self.conv1(x) # First convolution, retain features at original resolution
pool1 = self.pool1(conv1)
conv2 = self.conv2(pool1)
pool2 = self.pool2(conv2)
conv3 = self.conv3(pool2)
pool3 = self.pool3(conv3)
conv4 = self.conv4(pool3)
pool4 = self.pool4(conv4)
conv5 = self.conv5(pool4)
pool5 = self.pool5(conv5)
conv6 = self.conv6(pool5) # Bottleneck layer, capture high-level abstract features
# Decoder path: Upsampling and feature fusion (skip connections)
up7 = self.up7(conv6)
conv7 = self.conv7(torch.cat([conv5, up7], dim=1)) # Fusion of encoder and decoder features
up8 = self.up8(conv7)
conv8 = self.conv8(torch.cat([conv4, up8], dim=1))
up9 = self.up9(conv8)
conv9 = self.conv9(torch.cat([conv3, up9], dim=1))
up10 = self.up10(conv9)
conv10 = self.conv10(torch.cat([conv2, up10], dim=1))
up11 = self.up11(conv10)
conv11 = self.conv11(torch.cat([conv1, up11], dim=1))
# Final classification layer: Convert feature maps to class predictions
conv12 = self.conv12(conv11)
return conv12
if __name__ == '__main__':
device = torch.device("cuda:5" if torch.cuda.is_available() else "cpu")
model = UNet3DMMS(1, 4).to(device)
summary(model, (1, 1, 32, 32, 32))
02 论文下载
Multimodal Brain Tumor Segmentation Using a 3D ResUNet in BraTS 2021

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)