Kafka Consumer 核心设计原理 | Apache Kafka 官方学习文档
Kafka 消费者是从 Broker 读取并处理事件的客户端应用,向目标分区的主副本 Broker发起拉取请求,通过指定日志偏移量获取对应数据块。消费组是来自同一应用的一组消费者,协同消费一个或多个 Topic 的消息;任意时刻,一个分区在一个消费组内仅被一个消费者消费。消费者偏移量是一个唯一的整数标识,标记消费者在一个分区中下次要读取的下一条消息;偏移量会被周期性持久化到内部 Topic中。La
Kafka Consumer 核心设计原理 | Apache Kafka 官方学习文档
章节要点
- Kafka 与文件系统:介绍如何利用文件系统实现大规模高性能。
- 高效设计:通过避免字节拷贝、批处理与压缩提升效率。
- ** 生产者设计 ** :实现负载均衡与消息批量发送至代理。
- 消费者设计:采用拉取模式,通过偏移量追踪消费位置。
- 消息投递保障:提供生产与消费间语义保障,支持精确一次投递。
- 副本与已提交消息:通过副本机制与领导者选举实现消息可靠性。
- 日志压缩:用于状态保留及相关配置方式。
- 客户端配额:说明客户端配额的作用与使用方式。
Kafka Consumer 核心设计原理 | Confluent 官方文档深度解析
本文基于 Confluent 官方 Kafka Consumer 设计文档(https://docs.confluent.io/kafka/design/consumer-design.html)整理,系统化讲解 Kafka 消费者的核心设计、拉取模型、消费组机制、重平衡协议及偏移量管理
目录
- Consumer 核心定位与核心能力
- 核心设计:Pull 拉取模型(对比 Push)
- 消费组(Consumer Group):分布式消费核心
- 重平衡协议:分区分配的核心规则
- 偏移量(Offset):消费进度的核心追踪机制
- 消费位置详解:从提交到高水位
- 全文核心总结与设计思想
一、Consumer 核心定位与核心能力
1.1 官方定义
A Kafka consumer is a client application that reads and processes events from a broker. A consumer issues fetch requests to brokers that are leading partitions that it wants to consume from.
Kafka 消费者是从 Broker 读取并处理事件的客户端应用,向目标分区的主副本 Broker 发起拉取请求,通过指定日志偏移量获取对应数据块。
1.2 核心定位
Kafka 消费侧的核心客户端,是「Kafka 集群 → 业务处理系统」的关键桥梁,负责拉取消息、处理消息、追踪消费进度,支持分布式、高并发的消费模式。
1.3 核心设计能力
- 自主控制消费进度,可指定偏移量重放/跳过消息;
- 基于消费组实现分区负载均衡,支持水平扩展;
- 基于拉取模型实现最优批量消费,兼顾吞吐与延迟;
- 通过偏移量持久化实现故障恢复后消费续跑。
二、核心设计:Pull 拉取模型(对比 Push)
Kafka 采用消费者主动拉取的设计模型(Producer → Broker 是 Push 模型,Broker → Consumer 是 Pull 模型),这是 Kafka 消费侧高性能、高可控性的核心基础,与 Scribe、Flume 等Push 推送模型形成本质区别。
2.1 Pull vs Push 模型核心对比表
| 特性 | Pull 拉取模型(Kafka 采用) | Push 推送模型(Scribe/Flume) |
|---|---|---|
| 数据传输方式 | 消费者主动向 Broker 拉取数据 | Broker 主动将数据推送给消费者 |
| 消费速率控制 | 消费者自主控制,适配自身处理能力 | Broker 主导,易造成消费者压垮 |
| 批量消费优化 | 拉取当前日志位置后所有可用消息,实现最优批量 | 要么立即发送(小批量),要么缓存(未知消费者处理能力) |
| 追平落后消费 | 消费者可快速拉取大量数据,轻松追平生产速度 | 推送速率固定,落后后难以快速追平 |
| 延迟特性 | 可灵活权衡,批量拉取提升吞吐,即时拉取降低延迟 | 低延迟配置下易出现单消息发送,吞吐低下 |
| 资源利用率 | 消费者按需拉取,Broker/消费者资源利用率高 | 易出现消息堆积或消费者空闲,资源浪费 |
2.2 Pull 模型核心优势(官方重点强调)
- 消费速率自治:消费者根据自身处理能力调整拉取频率和批量,避免被 Broker 推送的海量数据压垮;
- 最优批量消费:消费者拉取当前偏移量后所有可用消息,无需额外缓存等待,实现无冗余的批量传输;
- 故障恢复灵活:消费落后时,可通过大批次拉取快速追平生产进度,适配流处理、实时计算等场景;
- 无无效缓冲:彻底解决 Push 模型“低延迟配置下单消息发送、高吞吐配置下盲目缓存”的矛盾。
2.3 Pull 模型核心流程
三、消费组(Consumer Group):分布式消费核心
消费组是 Kafka 实现分布式消费、分区负载均衡的核心设计,也是 Kafka 消费侧水平扩展的基础,其核心规则是一个分区在一个消费组内仅被一个消费者消费。
3.1 消费组核心定义
A consumer group is a set of consumers from the same application that work together to consume and process messages from one or more topics. Each partition is consumed by exactly one consumer within each consumer group at any given time.
消费组是来自同一应用的一组消费者,协同消费一个或多个 Topic 的消息;任意时刻,一个分区在一个消费组内仅被一个消费者消费。
3.2 消费组核心组件与关联关系
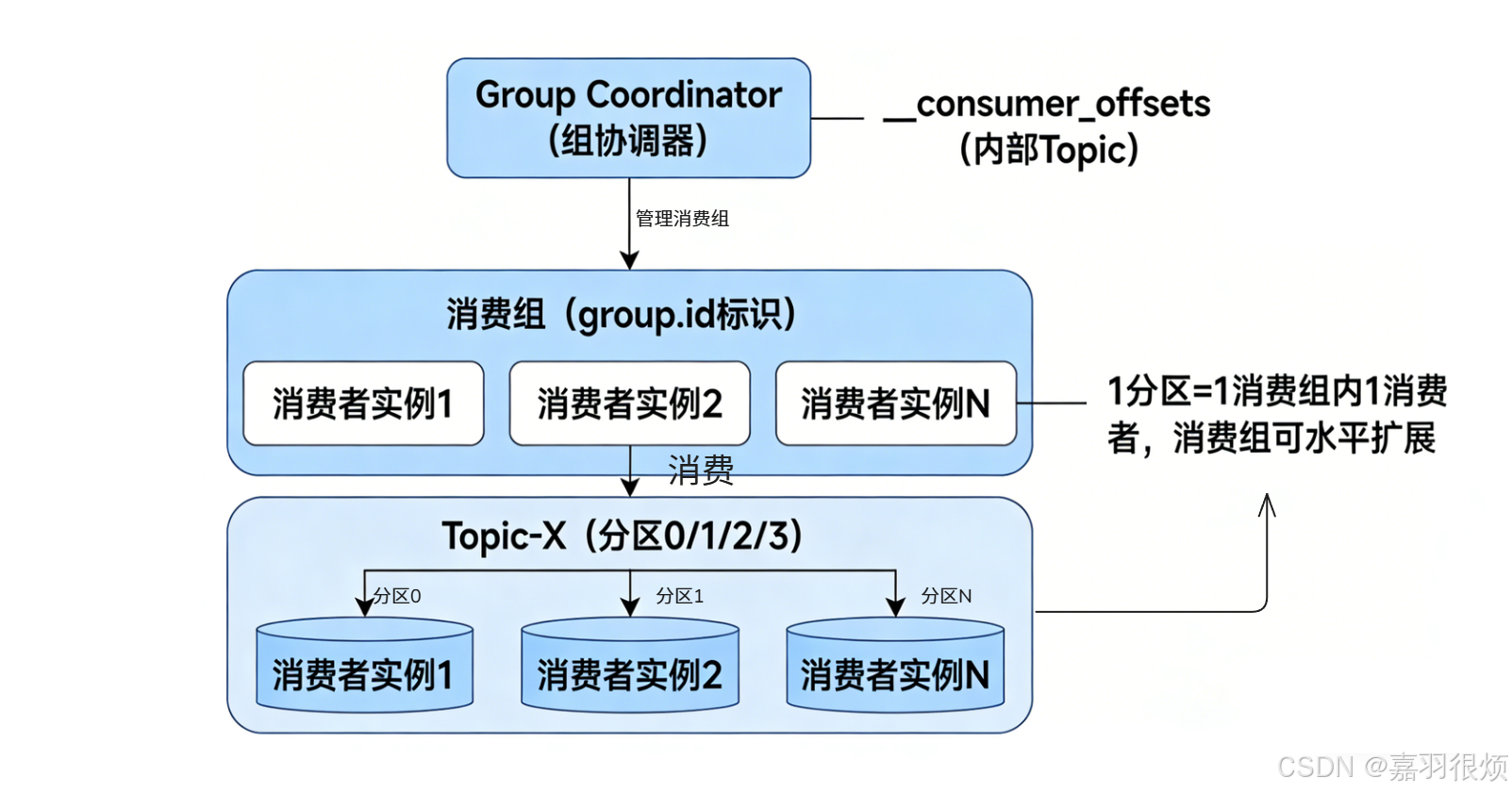
3.3 核心组件功能说明
| 组件 | 核心作用 | 关键特性 |
|---|---|---|
| group.id | 消费组唯一标识 | 同组消费者必须配置相同的 group.id |
| Group Coordinator | 消费组的核心管理节点 | 由 group.id 哈希计算得出,一个 Broker 可作为多个消费组的协调器 |
| __consumer_offsets | 消费组元数据存储Topic | 内部Topic,持久化存储消费组的分区分配关系、消费偏移量 |
3.4 消费组核心规则(不可违反)
- 分区与消费者的映射:一个分区在一个消费组内仅被一个消费者消费,多个消费组可同时消费同一个分区(多租户);
- 消费者数量上限:消费组内的消费者实例数不能超过消费的所有 Topic 的总分区数,超出的消费者会处于空闲状态;
- 水平扩展逻辑:增加消费组内的消费者实例,Group Coordinator 会触发重平衡,将分区重新分配,提升整体消费吞吐。
NOTE: 一般 设置消费组的消费者数与分区数一致 ,这是为了一个消费者能负责一个分区,提高效率。如果消费组的消费者数量小于分区数,则会出现一个消费者负责多个分区。而如果消费组的消费者数量大于分区数,则会出现有消费者分不到分区,造成浪费。所以一般保持一致。
3.5 消费组初始化流程
- 消费者配置
group.id,实例化后订阅目标 Topic; - 根据
group.id哈希计算出对应的 Group Coordinator; - 消费者向 Group Coordinator 注册,加入消费组;
- Group Coordinator 完成分区分配,将分配结果下发给所有消费者;
- 消费者根据分配结果,向对应分区的主副本 Broker 发起拉取请求。
四、Rebalance 重平衡协议:分区分配的核心规则
重平衡(Rebalance)是消费组的核心机制,指当消费组成员变化、Topic 元数据变化(分区数增加)时,Group Coordinator 重新将分区分配给消费者的过程。Kafka 4.0 支持经典协议(Classic Protocol) 和新消费协议(Consumer Rebalance Protocol) 两种,新协议为 GA 版本,是未来主流。
4.1 两种重平衡协议核心对比表
| 对比维度 | 经典协议(Classic Protocol) | 新消费协议(Consumer Rebalance Protocol) |
|---|---|---|
| 组协调器角色 | 管理成员,接收客户端主节点的分配计划 | 管理成员,自主计算并编排最终分配计划 |
| 消费组主节点 | 存在,由一个消费者承担,负责计算分区分配 | 无,无需选举主节点 |
| 分区分配位置 | 客户端侧,由组主节点计算分配逻辑 | 服务端侧,由 Group Coordinator 统一计算 |
| 重平衡触发 | 成员/Topic 元数据变化,全局同步分配 | 成员/Topic 元数据变化,增量式分配 |
| 重平衡行为 | 依赖分配器,可能出现所有消费者暂停并撤销分区 | 增量重新分配,最小化服务中断 |
| 重平衡中断影响 | 高,所有消费者暂停,直到分配完成 | 低,未受影响的消费者继续处理消息 |
| 兼容性 | 支持所有版本的 Kafka 消费组 | Kafka 4.0 GA,需配置 group.protocol=consumer |
| 核心优势 | 兼容性好,实现简单 | 分布式分配、增量重平衡、中断最小化 |
4.2 两种协议核心流程
经典协议流程
新消费协议流程
4.3 重平衡的核心影响与优化
- 重平衡的代价:经典协议会导致消费组整体暂停,新协议虽实现增量重平衡,但仍会有局部消费暂停;
- 核心优化方向:减少重平衡触发次数(如避免消费者频繁上下线、固定消费者实例数)、使用新消费协议降低中断影响。
五、偏移量(Offset):消费进度的核心追踪机制
消费进度追踪是消息队列的核心能力,Kafka 摒弃了传统“Broker 端直接标记已消费”的设计,通过消费者偏移量(Consumer Offset) 实现消费进度的分布式追踪,彻底解决了“消息丢失”和“消息重复消费”的矛盾。
5.1 传统追踪方案的痛点
- Broker 立即标记已消费:Broker 发送消息后直接标记为已消费,若消费者崩溃/请求超时,消息未处理但已被标记,导致消息丢失;
- Broker 等待确认后标记:Broker 等待消费者处理完成的确认后再标记,若消费者处理完成但未发送确认,Broker 会重新推送,导致消息重复消费。
5.2 消费者偏移量官方定义
A consumer offset is a unique identifier, an integer, which marks the next record that should be read by the consumer in a partition. It is periodically checkpointed to the __consumer_offsets internal topic.
消费者偏移量是一个唯一的整数标识,标记消费者在一个分区中下次要读取的下一条消息;偏移量会被周期性持久化到内部 Topic__consumer_offsets中。
5.3 偏移量的核心设计优势
- 消费进度自治:消费进度由消费者自主管理,Broker 仅负责持久化偏移量,无需参与消费进度判断;
- 故障恢复无缝:消费者故障重启/重平衡后,从
__consumer_offsets读取最后提交的偏移量,从该位置继续消费; - 无消息丢失/重复的可控性:通过偏移量提交策略,可灵活选择“至少一次”“最多一次”的消费语义;
- 元数据轻量化:偏移量是整数,存储开销极小,
__consumer_offsets可高效管理大量消费组的进度。
5.4 偏移量核心流程
5.5 偏移量的两种提交策略
| 提交策略 | 核心逻辑 | 消费语义 | 适用场景 |
|---|---|---|---|
| 自动提交(enable.auto.commit=true) | 按固定间隔(auto.commit.interval.ms)自动提交当前消费的偏移量 | 至少一次(可能重复,因提交后消费者崩溃) | 对消息重复不敏感的场景,如日志收集 |
| 手动提交(enable.auto.commit=false) | 消费者处理完消息后,主动调用 API 提交偏移量 | 可实现精确一次(结合业务幂等) | 对消息重复/丢失敏感的场景,如交易、支付 |
六、消费位置详解:从提交到高水位
Kafka 中一个分区的消费过程涉及四个核心消费位置,这是理解消费进度、消息可见性、故障恢复的关键,官方对其做了明确的定义和区分。
6.1 四大核心消费位置(官方定义)
为了直观理解,结合官方的日志偏移量数轴(0-14),对四个位置做精准解析:
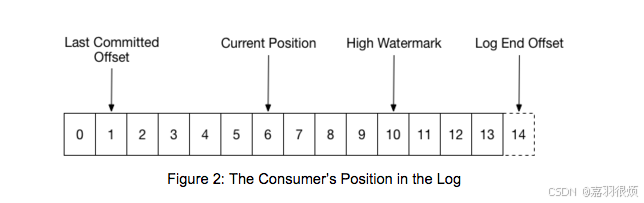
-
Last Committed Offset(最后提交的偏移量)
- 定义:消费者已持久化到__consumer_offsets的偏移量,标记下次要读取的第一条消息;
- 示例:偏移量1 → 下次从1开始读取;
- 核心作用:故障/重平衡后,消费者的初始消费位置。
-
Current Position(当前消费位置)
- 定义:消费者当前正在读取的偏移量,是内存中的临时位置,未提交;
- 示例:偏移量6 → 正在读取偏移量6的消息;
- 核心作用:标记消费者实时的消费进度。
-
High Watermark(高水位)
- 定义:已成功复制到所有副本的最后一条消息的偏移量;
- 示例:偏移量10 → 0-9的消息已完成副本同步,10及以后未完成;
- 核心规则:消费者只能读取高水位之前的消息,防止读取未复制的、可能丢失的消息。
-
Log End Offset(日志末端偏移量)
- 定义:Producer 写入到分区的最后一条消息的偏移量,是分区的最新消息位置;
- 示例:偏移量14 → 分区最新消息为14;
- 核心差值:
Log End Offset - High Watermark= 未完成副本同步的消息数(同步队列)。
6.2 核心位置的关联规则(官方重点)
- 消费可见性:消费者的Current Position 永远 ≤ High Watermark ≤ Log End Offset;
- 故障恢复规则:消费者崩溃后,新的 Current Position = Last Committed Offset,需重处理从提交偏移量到崩溃位置的消息(如示例中1-6);
- 提交的核心意义:将内存中的 Current Position 持久化为 Last Committed Offset,完成消费进度的持久化。
6.3 消费位置核心流程图
七、全文核心总结与设计思想
7.1 核心知识点总结
- 消费模型:采用Pull 拉取模型,消费者自主控制拉取速率和批量,兼顾吞吐与延迟,解决 Push 模型的资源浪费问题;
- 分布式消费:基于消费组实现,核心规则是1分区=1消费组内1消费者,消费者数量不超过总分区数,支持水平扩展;
- 组管理:由Group Coordinator 管理消费组,基于
group.id哈希分配,元数据存储在内部 Topic__consumer_offsets; - 重平衡:Kafka 4.0 支持经典协议和新消费协议,新协议为服务端增量分配,无主节点,中断最小化,是未来主流;
- 消费进度追踪:通过消费者偏移量实现,偏移量标记下次要读取的位置,持久化在
__consumer_offsets,支持自动/手动提交; - 消费位置:四大核心位置(最后提交偏移量、当前位置、高水位、日志末端),消费者仅能读取高水位之前的消息,保证数据可靠性。
7.2 Kafka 消费侧核心设计思想
- 自治性:将消费速率、进度提交、批量控制等能力下放给消费者,Broker 仅负责核心的元数据管理和数据存储,实现“端到端”的可控性;
- 轻量化:用整数偏移量追踪消费进度,元数据存储开销极小,支持海量消费组和分区的管理;
- 分布式:消费组、Group Coordinator、重平衡协议均采用分布式设计,无单点瓶颈,支持水平扩展;
- 可靠性与性能的权衡:通过高水位保证消息不读取未复制的脏数据,通过偏移量提交策略灵活选择消费语义,兼顾数据可靠性和消费性能;
- 最小化中断:新消费协议采用增量重平衡,仅影响受变化的消费者,最大化提升消费系统的可用性。
7.3 官方核心设计建议
- 消费组内的消费者实例数建议等于或略小于总分区数,避免空闲消费者;
- 对消息可靠性要求高的场景,使用手动提交偏移量并结合业务幂等,实现精确一次消费;
- Kafka 4.0+ 版本优先使用新消费协议(
group.protocol=consumer),减少重平衡的中断影响; - 避免消费者频繁上下线,减少重平衡触发次数,提升消费系统的稳定性。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)