LangChain 入门(上):LCEL 链式开发、LangSmith 追踪、RAG 检索与自定义 Agent 工具实战
LangChain 是大模型应用开发的主流框架,专注于构建LLM workflows,是生成式 AI 时代的软件工程工具。面向开发者,生态丰富解决复杂工作流手撸效率低、难维护的问题标准结构:Input → Processing → Output相比 AutoGen 更贴近工程化支持 LangGraph 多智能体流程LangSmith 提供中间过程可视化,弥补调试盲区推荐学习资料:《大模型应用开发
LangChain 入门:LCEL 链式开发、LangSmith 追踪、RAG 检索与自定义 Agent 工具实战
- https://github.com/langchain-ai/langchain/tree/master/cookbook
- https://python.langchain.com/v0.2/docs/concepts/#langchain-expression-language-lcel
- https://python.langchain.com/v0.1/docs/expression_language/why/
- https://ai.plainenglish.io/understanding-large-language-model-based-agents-27bee5c82cec
1 LangChain 介绍
- LangChain 是大模型应用开发的主流框架,专注于构建LLM workflows,是生成式 AI 时代的软件工程工具。
- 面向开发者,生态丰富
- 解决复杂工作流手撸效率低、难维护的问题
- 标准结构:Input → Processing → Output
- 相比 AutoGen 更贴近工程化
- 支持 LangGraph 多智能体流程
- LangSmith 提供中间过程可视化,弥补调试盲区
- 推荐学习资料:《大模型应用开发 动手做 AI Agent》,系统全面,适合开发者入门。
2 LCEL (LangChain Expression Language)
-
LCEL 是 LangChain 的核心灵魂,通过重写 | 运算符,让链式调用极简、清晰、可组合。
-
核心特点:
- | 管道符串联组件
- 所有组件都是 Runnable
- 支持 invoke /stream/batch 统一调用
-
关键组件
- RunnablePassthrough:透传输入,不做修改,常用于构建字典结构
- RunnableLambda:自定义函数包装为可运行组件
- RunnableParallel:并行执行多个 Runnable
-
LCEL 让大模型应用像写管道命令一样简单清晰,是 LangChain 的最佳实践。
3 LCEL 代码示例
代码逻辑清晰直观:输入 → 透传构建参数 → 填充 Prompt → 调用 LLM → 解析输出。
dotenv 可见补充一节。
import os
from dotenv import load_dotenv
load_dotenv()
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.chat_models import ChatZhipuAI
# 加载模型
zhipuai_api_key = os.getenv("ZHIPU_API_KEY")
llm = ChatZhipuAI(api_key=zhipuai_api_key, model="glm-4-flash")
# 构建组件
prompt = ChatPromptTemplate.from_template("Tell me a short joke about {topic}")
output_parser = StrOutputParser()
# LCEL 链式调用
chain = (
{"topic": RunnablePassthrough()}
| prompt
| llm
| output_parser
)
chain.invoke("ice cream")
输出
'Why did the ice cream scream?\n\nBecause it was in danger of being melted!'
查看提示词
prompt.invoke({'topic': 'ice cream'})
输出
ChatPromptValue(messages=[HumanMessage(content='Tell me a short joke about ice cream', additional_kwargs={}, response_metadata={})])
查看llm输出
llm.invoke(prompt.invoke({'topic': 'ice cream'}))
输出
AIMessage(content="Why don't scientists trust atoms?\n\nBecause they make up everything!", additional_kwargs={}, response_metadata={'token_usage': {'completion_tokens': 15, 'prompt_tokens': 13, 'total_tokens': 28}, 'model_name': 'glm-4-flash', 'finish_reason': 'stop'}, id='lc_run--019d918a-9497-7a41-a5f2-98166210ab86-0', tool_calls=[], invalid_tool_calls=[])
查看解析后输出
output_parser.invoke(llm.invoke(prompt.invoke({'topic': 'ice cream'})))
输出
"Why don't scientists trust atoms? Because they make up everything!"
4 LangSmith 介绍、使用与运行效果展示
LangSmith 是 LangChain 官方提供的全链路追踪与调试平台,核心价值在于将原本黑盒的大模型调用转化为透明可观测的工程化流程,是大模型应用开发、调试与优化的必备工具。通过它,可清晰查看每一步调用的输入输出、耗时、Token 消耗、执行链路及报错信息,无需额外修改业务代码,配置环境变量后即可实现自动上报。
4.1 配置方法(.env 文件)
在项目根目录的 .env 文件中配置以下环境变量,即可开启 LangSmith 追踪功能。其中 LANGCHAIN_API_KEY 需要先在 LangSmith 平台注册并获取,具体步骤如下:
-
访问 LangSmith 官方平台:smith.langchain.com,可通过 GitHub、Google 账号或邮箱完成注册登录;
-
登录后,点击右上角头像,进入「Settings」(设置)页面,找到「API Keys」选项;
-
点击「Create API Key」(创建 API Key),生成专属密钥,生成后及时复制保存(仅显示一次,丢失需重新创建);
-
若需指定项目,可在平台创建项目(如示例中的「for study」),确保 .env 中 LANGCHAIN_PROJECT 的值与平台项目名一致。
获取 API Key 后,将其填入 .env 文件对应位置,完整配置如下:
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
LANGCHAIN_API_KEY=你从LangSmith平台获取的专属密钥(lsv2_开头)
LANGCHAIN_PROJECT=for study
4.2 运行效果与界面解读
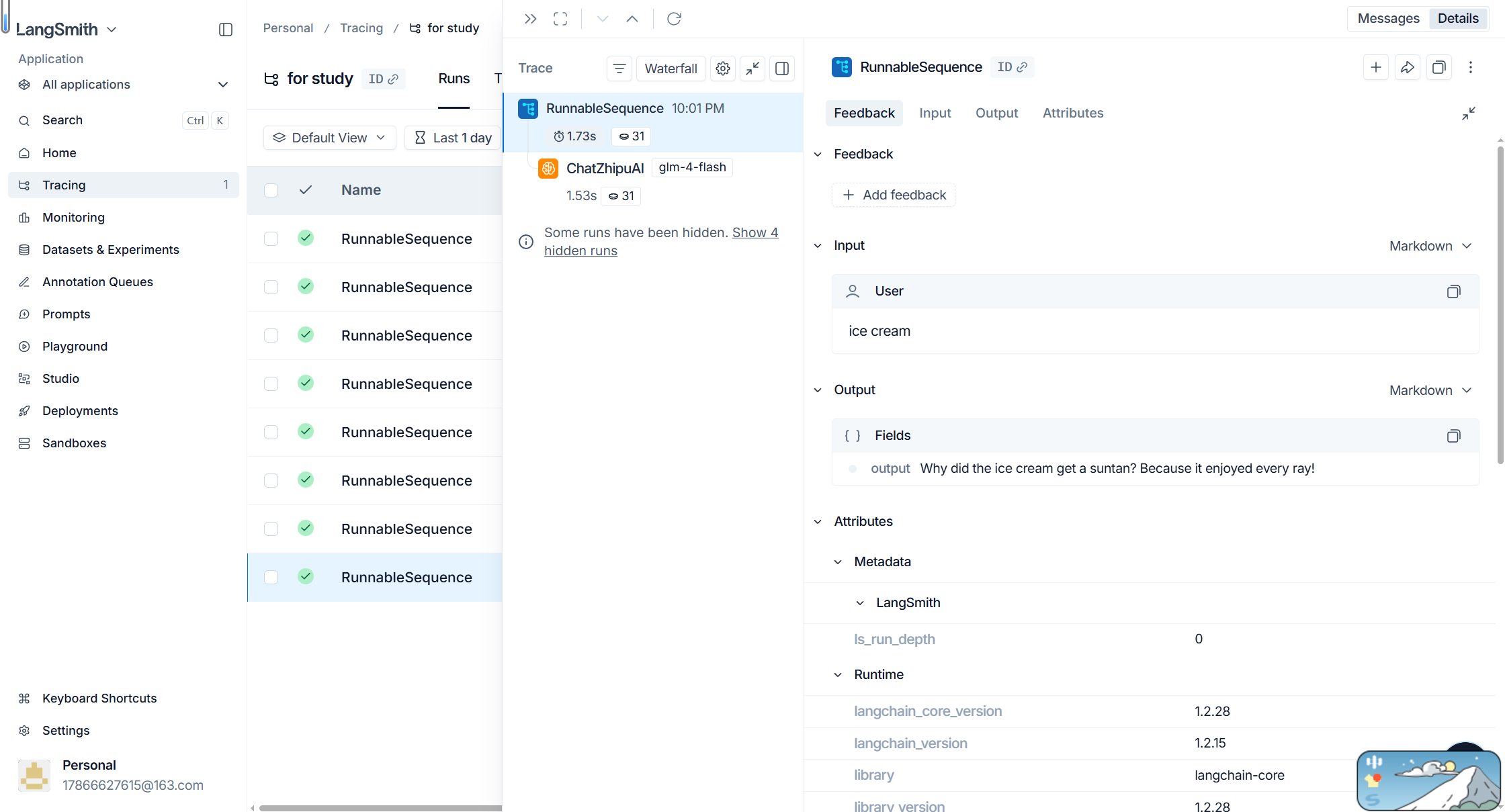
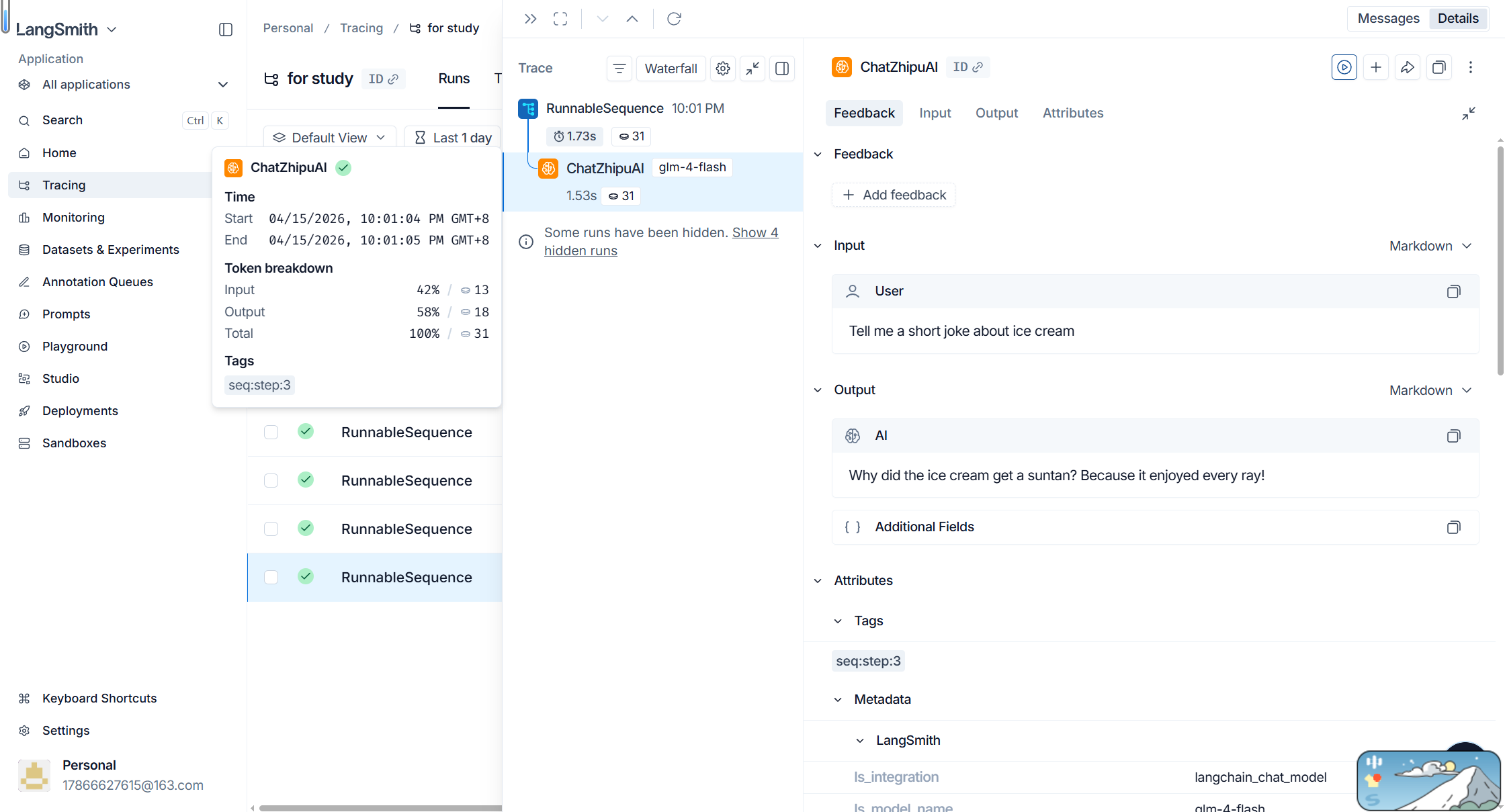
配置完成后,执行 LCEL 链式代码,打开 smith.langchain.com 即可看到完整的追踪记录,核心界面信息解读如下:
-
RunnableSequence:对应整条 LCEL 链,是本次调用的根节点,统筹所有组件执行流程;
-
ChatZhipuAI:对应智谱 GLM-4-Flash 模型的实际调用,是链路中核心的网络IO环节;
-
耗时 1.73s:整条 LCEL 链的总执行时间,其中模型调用占比最高;
-
Token 31:本次调用的输入与输出总 Token 消耗,直观反映调用成本;
-
Input / Output:清晰展示真实的请求参数(如本次的 “ice cream”)与模型返回结果,便于核对调用准确性。
5 Runnable
在 LangChain 的生态中,LCEL(LangChain Expression Language) 是串联组件、构建复杂链路的核心语法,而 Runnable 正是 LCEL 的底层核心载体。无论是简单的字符串处理,还是复杂的 RAG 检索增强生成、智能代理搭建,本质上都是通过 Runnable 组件的组合与串联实现的。
本节从基础概念、核心组件、实战示例三个维度,彻底拆解 Runnable 的逻辑与用法,帮你建立 LangChain 链式编程的底层思维。
5.1 什么是Runnable,为什么需要runnable
LangChain 里只要能被 | 串联、能调用 .invoke() 执行的东西,全都是 Runnable。
示例
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
# 这三个全部都是 Runnable
chain = (
RunnablePassthrough() # 1. 透传Runnable
| RunnableLambda(lambda x: x.upper()) # 2. 自定义函数Runnable
)
chain.invoke("hi")
扩展(最常见)
- 大模型 llm 👉 是 Runnable
- 提示词模板 prompt 👉 是 Runnable
- 输出解析器 👉 是 Runnable
LangChain 中的各类组件(如模型、检索器、工具、输出解析器等)本质上都是“数据处理单元”,而 Runnable 就是为了统一这些单元的调用标准,让它们可以通过简单的语法规则自由组合。
简单来说,Runnable 解决了两个核心问题:
- 统一接口:所有 Runnable 组件都具备
invoke(同步调用)、ainvoke(异步调用)、stream(流式调用)等标准方法,无需适配不同组件的不同调用逻辑。 - 灵活组合:通过管道符
|可以将多个 Runnable 串联成执行链,实现数据的流式处理,也能通过RunnableParallel实现并行处理,适配复杂的业务逻辑。
可以理解为:Runnable 是 LangChain 组件的“通用包装”,LCEL 是这些组件的“组合语法”,二者结合构成了 LangChain 的核心执行逻辑。
5.2 Runnable 核心组件详解
Runnable 体系包含多个基础组件,其中 RunnablePassthrough、RunnableLambda 是最基础、最常用的两个,也是理解所有复杂 Runnable 组合的前提。
1 RunnablePassthrough:透明透传器
核心作用:执行恒等变换,即原封不动地将输入透传给下一个组件,不做任何数据修改。
通俗理解:它就像一条“透明管道”,输入什么,输出就是什么,核心作用是占位、保留原始数据、串联链路。
关键特性
- 输入 = 输出,无任何逻辑处理;
- 可在链路中任意位置插入,不影响前后组件的执行逻辑;
- 常作为占位符使用:开发初期先用它占位置,后续替换为真正的业务逻辑。
示例
from langchain_core.runnables import RunnablePassthrough
# 单个透传器
passthrough = RunnablePassthrough()
result = passthrough.invoke("hello langchain")
print(result) # 输出:hello langchain
# 多个透传器串联(效果完全一致)
chain = RunnablePassthrough() | RunnablePassthrough() | RunnablePassthrough()
result = chain.invoke("hello")
print(result) # 输出:hello
2 RunnableLambda:自定义逻辑封装器
核心作用:将普通 Python 函数包装为 Runnable 组件,让自定义函数能融入 LCEL 链式链路中。
通俗理解:它是“桥梁”,把你写的任意数据处理逻辑(如字符串转换、数据清洗、业务计算),变成 LangChain 标准的可组合组件。
关键特性
- 支持传入任意无参/有参函数;
- 函数的输入/输出会自动适配 Runnable 的调用规则;
- 是实现自定义逻辑的核心工具,弥补了基础组件无法覆盖所有业务场景的不足。
示例
from langchain_core.runnables import RunnableLambda
# 定义自定义函数:将输入字符串转大写
def to_upper(text: str) -> str:
return text.upper()
# 包装为 Runnable
lambda_runnable = RunnableLambda(to_upper)
result = lambda_runnable.invoke("hello langchain")
print(result) # 输出:HELLO LANGCHAIN
# 也可以直接使用 lambda 表达式
lambda_runnable2 = RunnableLambda(lambda x: x.lower())
result = lambda_runnable2.invoke("HELLO LANGCHAIN")
print(result) # 输出:hello langchain
3 管道符 |:Runnable 串联核心
核心作用:LCEL 的核心语法,用于串联多个 Runnable 组件,形成执行链。
执行逻辑:数据从左到右依次流转,前一个组件的输出作为后一个组件的输入,最终输出最后一个组件的结果。
组合规则
- 左侧组件的输出类型,必须兼容右侧组件的输入类型,否则会报错;
- 支持无限串联,可构建复杂的线性执行链路;
- 结合
RunnablePassthrough和RunnableLambda,可实现任意线性逻辑。
组合示例
结合前两个基础组件,我们来看三个核心组合场景,这也是实际开发中最常用的模式。
场景 1:透传 + 自定义逻辑(基础组合)
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
# 串联:透传器 + 转大写 Lambda
chain = RunnablePassthrough() | RunnableLambda(lambda x: x.upper())
result = chain.invoke("hello langchain")
print(result) # 输出:HELLO LANGCHAIN
逻辑拆解:输入 "hello langchain" → 透传器原封不动传递 → Lambda 执行转大写 → 输出结果。
场景 2:透传 + 逻辑 + 透传(无侵入透传)
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
# 串联:透传器 + Lambda + 透传器
chain = RunnablePassthrough() | RunnableLambda(lambda x: x.upper()) | RunnablePassthrough()
result = chain.invoke("hello langchain")
print(result) # 输出:HELLO LANGCHAIN
逻辑拆解:透传器仅负责传递数据,不影响 Lambda 的执行逻辑,最终结果与场景 1 完全一致。
场景 3:复杂业务组合(结合模型组件)
Runnable 的核心价值是组合复杂组件,比如结合大语言模型实现完整链路:
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI
# 1. 定义提示词模板处理函数
def format_prompt(text: str) -> str:
return f"请回答以下问题:{text},请用中文简洁回答"
# 2. 初始化大语言模型
llm = ChatOpenAI(model="gpt-3.5-turbo", api_key="你的API密钥")
# 3. 串联执行链:透传器 -> 格式化提示词 -> 模型调用
chain = (
RunnablePassthrough()
| RunnableLambda(format_prompt) # 格式化输入
| llm # 大语言模型调用
| RunnableLambda(lambda x: x.content) # 提取模型输出内容
)
# 执行调用
result = chain.invoke("什么是Runnable?")
print(result)
逻辑拆解:输入问题 → 透传传递 → 格式化提示词 → 模型生成 → 提取输出内容 → 最终结果。
5.3 进阶:RunnableParallel 并行处理
除了线性串联,Runnable 还支持并行处理,通过 RunnableParallel 实现,这是处理复杂多分支逻辑的关键。
核心作用:同时执行多个 Runnable 组件,并行处理数据,最终将结果整合为字典。
适用场景:需要同时获取“原始数据”和“处理后数据”、“多分支检索”等需要并行执行的逻辑。
示例
from langchain_core.runnables import RunnablePassthrough, RunnableLambda, RunnableParallel
# 定义并行链路
parallel_chain = RunnableParallel(
# 保留原始输入
original=RunnablePassthrough(),
# 转大写处理
upper=RunnableLambda(lambda x: x.upper()),
# 转小写处理
lower=RunnableLambda(lambda x: x.lower())
)
# 执行调用
result = parallel_chain.invoke("Hello LangChain")
print(result)
# 输出:{'original': 'Hello LangChain', 'upper': 'HELLO LANGCHAIN', 'lower': 'hello langchain'}
核心价值:并行执行多个逻辑,避免线性串联的冗余,提升执行效率,同时整合多维度结果。
5.4 Runnable 核心方法总结
所有 Runnable 组件都具备以下核心方法,掌握这些方法是灵活使用 Runnable 的关键:
| 方法名 | 作用 | 适用场景 |
|---|---|---|
invoke(input) |
同步执行链路,输入数据,输出最终结果 | 简单同步调用,无需流式输出 |
ainvoke(input) |
异步执行链路,支持异步编程 | 高并发场景、异步应用(如 FastAPI) |
stream(input) |
流式输出结果,逐段返回数据 | 大模型对话、实时流式响应 |
batch(inputs) |
批量执行多个输入,批量返回结果 | 批量处理数据,提升执行效率 |
5.5 总结
Runnable 的本质、基础组件、组合规则 三大核心内容:
- Runnable 是 LangChain 组件的“通用包装”,统一了组件的调用标准;
RunnablePassthrough是透明透传器,负责占位、保留原始数据;RunnableLambda是自定义逻辑封装器,让普通函数融入链式链路;- 管道符
|实现线性串联,RunnableParallel实现并行处理; - 掌握
invoke、stream等核心方法,可灵活执行各类链路。
Runnable 是 LangChain 所有复杂应用的基础,从简单的字符串处理到复杂的智能代理、RAG 系统,都离不开它。理解了 Runnable 与 LCEL,就真正掌握了 LangChain 编程的核心逻辑。
6 JSON解析器
在使用大语言模型时,我们经常需要固定格式的结构化输出(比如提取姓名、年龄、商品信息等),但模型默认会返回自由文本,很难直接用于代码逻辑。
LangChain 提供了强大的 JsonOutputParser,能轻松让模型输出标准 JSON 格式,还能自动解析为 Python 字典,零代码处理结构化数据。
本节实现:从文本中提取信息 → 模型输出 JSON → 自动解析为可用数据的完整流程。
6.1 核心知识点前置
JsonOutputParser:LangChain 内置的 JSON 解析器,负责两件事——告诉模型「必须输出 JSON」、把模型返回的字符串自动转成 Python 字典- LCEL 链式调用:LangChain 推荐的极简管道写法,一行串联「输入→提示词→模型→解析器」
- 提示词模板:固定指令,让模型严格按照指定 JSON 结构输出
6.2 完整可运行代码
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts.chat import SystemMessagePromptTemplate
from langchain_core.output_parsers import JsonOutputParser
# 初始化 JSON 解析器
json_parser = JsonOutputParser()
# 创建提示模板
prompt = ChatPromptTemplate.from_messages([
("system", '''I want you to extract the person name, age and a description from the following text.
Here is the JSON object, output:
{{
"name": string,
"age": int,
"description": string
}}'''),
("human", "{input}")
])
# 创建 LCEL 链
chain = (
{"input": RunnablePassthrough()}
| prompt
| llm
| json_parser
)
# 测试调用:传入文本,直接拿到结构化结果
result = chain.invoke("John is 20 years old. He is a student at the University of California, Berkeley. He is a very smart student.")
result
输出结果(Python 字典,可直接使用)
{'name': 'John',
'age': 20,
'description': 'student at the University of California, Berkeley and a very smart student'}
6.3 代码核心解析
1 构建提示词模板
提示词是让模型输出 JSON 的关键,我们通过系统提示词明确要求模型按照指定 JSON 结构输出:
#### 创建提示模板(核心:指定 JSON 输出格式)
prompt = ChatPromptTemplate.from_messages([
("system", '''I want you to extract the person name, age and a description from the following text.
Here is the JSON object, output:
{{
"name": string,
"age": int,
"description": string
}}'''),
("human", "{input}")
])
也可以使用消息模板类的写法,效果完全一致:
# 等价写法
ChatPromptTemplate.from_messages(
[SystemMessagePromptTemplate.from_template('''I want you to extract the person name, age and a description from the following text.
Here is the JSON object, output:
{{
"name": string,
"age": int,
"description": string
}}'''),
HumanMessagePromptTemplate.from_template("{input}")
]
)
2 JSON 解析器的作用
json_parser = JsonOutputParser()
- 自动校验模型输出是否为合法 JSON
- 把字符串格式的 JSON 转成 Python 字典
- 无需手动写
json.loads(),减少代码冗余
3 LCEL 链式调用的优势
chain = ({"input": RunnablePassthrough()} | prompt | llm | json_parser)
- 管道式写法,逻辑清晰、可读性拉满
- 可随时增删组件(比如加日志、加缓存)
- 支持流式输出、异步调用,扩展性极强
6.4 总结
JsonOutputParser 是 LangChain 处理结构化输出的神器,核心价值:
- 让大模型从「自由文本」变成「规范 JSON」
- 自动解析,无需手动处理字符串
- LCEL 链式调用,代码极简、易维护
7 RAG检索增强生成详解与实操
7.1 什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合「信息检索」与「大模型生成」的技术,核心逻辑是:在大模型生成回答前,先从外部知识库(如本地文档、数据库)中检索与问题相关的上下文,将检索到的信息与用户问题拼接后,再输入大模型生成回答。
简单来说,RAG相当于给大模型“配备了一个可查询的知识库”——大模型本身的训练数据有时间局限性、无法包含私有数据(如公司内部文档、个人笔记),而RAG通过实时检索外部信息,解决了这一核心痛点。
7.2 为什么需要RAG
在LangChain开发中,RAG是最基础、最常用的场景之一,其核心作用体现在3点,也是我们必须使用RAG的原因:
- 解决大模型“知识滞后”问题:大模型的训练数据截止到某个时间点(如智谱GLM-4截止到2024年),无法获取最新信息(如2025年的新政策、新技术),RAG可检索实时/最新文档,让回答更具时效性。
- 解决“私有数据无法调用”问题:大模型没有学习过你的个人笔记、公司内部文档、行业专属资料,RAG可将这些私有数据构建成向量库,让大模型基于私有数据生成回答(如企业知识库问答、个人笔记检索)。
- 提升回答的准确性、降低幻觉:大模型在面对不熟悉的领域时,容易“编造信息”(即幻觉),RAG通过检索真实存在的上下文,让回答有依据、可追溯,大幅降低幻觉概率。
7.3 RAG是Agent开发的一个方向吗?
结论:RAG不是Agent开发的一个方向,而是Agent开发中最核心、最基础的组件之一,是Agent实现“信息检索、知识问答”能力的关键技术。
具体区别与关联:
- RAG:专注于「检索外部信息 + 辅助生成回答」,核心是“信息获取与复用”,是一个“被动的知识工具”。
- Agent:是具备“自主决策、多工具调用”能力的智能体(如自动规划任务、调用RAG检索、调用计算器、调用数据库),核心是“自主行为”。
举个例子:一个智能问答Agent,其核心模块就是RAG(负责检索相关知识),同时还会搭配“任务解析”“工具选择”模块——当用户提问时,Agent先判断“是否需要检索知识”,如果需要,就调用RAG模块检索,再根据检索结果生成回答。因此,学习RAG是入门Agent开发的必经之路。
7.4 LangChain集成智谱AI实现RAG实操
本节将基于LangChain,结合智谱AI对话大模型 + 本地开源嵌入模型,搭建完整RAG链路,解决实操中常见的依赖、API密钥、配额等问题,适合新手入门练习。
1 环境准备与组件说明
核心依赖安装
优先使用conda安装FAISS(支持GPU加速,若没有GPU可替换为faiss-cpu),再安装其他依赖:
# 安装FAISS(GPU版,需配置CUDA;无GPU则用 pip install faiss-cpu)
conda install faiss-gpu -c pytorch
# 安装核心依赖
pip install langchain langchain-community zhipuai sentence-transformers
2 组件导入说明
新版LangChain将第三方模型(如智谱)统一收敛至langchain_community,需使用最新导入路径;同时用本地开源嵌入模型替代智谱Embedding,规避配额不足问题。
Embedding 是将非结构化文本转为稠密向量的技术,核心作用:语义向量化、相似度计算、向量检索
# 配置LangChain项目(可选,用于LangChain追踪)
os.environ["LANGCHAIN_PROJECT"] = 'rag_test'
# 1. FAISS向量库(本地存储,用于存储文档向量)
from langchain_community.vectorstores import FAISS
# 2. 智谱AI对话大模型(使用已有资源包,避免额外计费)
from langchain_community.chat_models import ChatZhipuAI
# 3. 本地开源嵌入模型(替代智谱ZhipuAIEmbeddings,免费无配额)
from langchain_community.embeddings import HuggingFaceEmbeddings
# 4. LangChain基础组件(提示词、链路组装、输出解析)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
2 核心组件配置
1 嵌入模型配置(本地开源,免费无配额)
这里使用本地已下载的bge-large-zh-v1.5模型(中文适配更好),若已手动下载模型到本地文件夹,直接填写本地路径即可;若未下载,可直接填写模型名(如all-MiniLM-L6-v2),库会自动下载并缓存(hin慢)。
# ====================== 核心:本地嵌入模型(免费无配额) ======================
# 说明:若已手动下载模型到本地,填写本地路径(如下);若未下载,替换为 model_name="bge-large-zh-v1.5" 即可自动下载
embeddings_path = "H:\\AI\\Agent\\models\\bge-large-zh-v1.5"
embeddings = HuggingFaceEmbeddings(model_name=embeddings_path)
# 补充:无需本地路径的写法(自动下载+缓存)
# embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
关键提醒:
- 传入的
model_name可是「模型官方编号」或「本地文件夹路径」,新手推荐用官方编号(自动下载,无需手动管理路径)。 - 模型缓存路径:Windows为
C:\Users\你的用户名\.cache\huggingface\hub,Mac/Linux为~/.cache/huggingface/hub,一次下载,永久复用。
2 智谱大模型配置(使用已有资源包)
填写你的智谱API_KEY,选用自己有资源包的模型(如glm-4.5-air),避免调用无配额的模型导致429报错。
# ====================== 智谱大模型配置 ======================
ZHIPU_API_KEY = "你的智谱API_KEY" # 替换为你的智谱API密钥
llm = ChatZhipuAI(
model="glm-4.5-air", # 选用自己有资源包的模型,避免配额不足
api_key=ZHIPU_API_KEY,
temperature=0.1 # 温度越低,回答越精准,适合问答场景
)
3 完整RAG链路搭建
1 构建FAISS本地向量库
将测试文本(可替换为你的私有文档、笔记)转换为向量,存储到FAISS向量库中,用于后续相似度检索。
# ====================== 构建FAISS向量库 ======================
# 测试文档(可替换为你的私有文档、行业资料等)
texts = ["Cats love tuna", "Dogs like bones", "Rabbit eats grass"]
# 将文本转换为向量,存入FAISS向量库
vectorstore = FAISS.from_texts(
texts=texts,
embedding=embeddings # 使用本地嵌入模型,不消耗智谱配额
)
# 构建检索器(用于后续相似度检索)
retriever = vectorstore.as_retriever()
# 测试检索:输入问题,检索相关上下文
retriever.invoke("What do cats like to eat?")
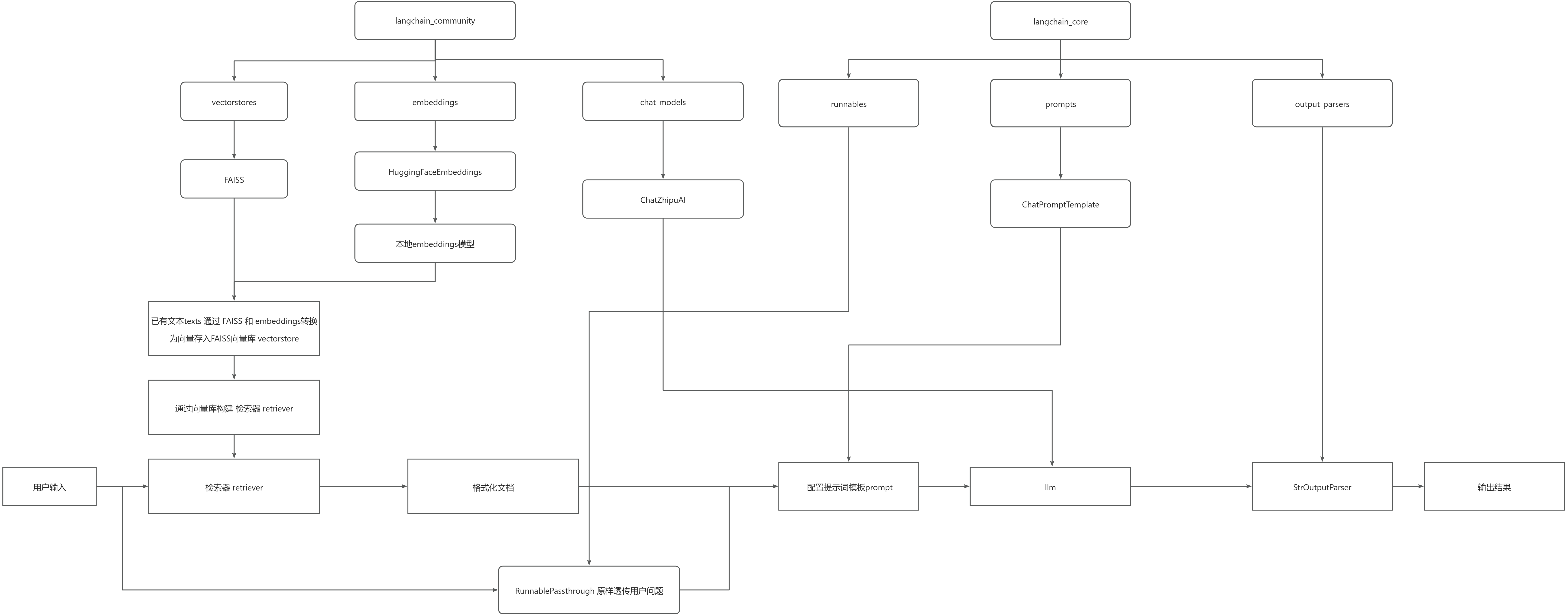
2 组装RAG链路(LCEL链式写法)
使用LangChain原生LCEL(LangChain Expression Language)写法,将「检索器、提示词、大模型、输出解析器」串联起来,形成完整RAG链路。
# ====================== 配置提示词模板 ======================
# 提示词模板:严格根据检索到的上下文回答问题,禁止编造信息
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template=template)
# 格式化检索到的文档(将多个文档拼接为字符串,方便大模型读取)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# ====================== 组装RAG链路 ======================
# 链路逻辑:用户问题 → 检索相关文档 → 格式化文档 → 拼接提示词 → 大模型生成 → 解析输出
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
3 测试RAG链路
调用RAG链路,输入问题,验证是否能基于检索到的上下文生成准确回答。
# 测试RAG链路(基于检索到的上下文回答问题)
result = rag_chain.invoke("What do cats like to eat?")
print("RAG回答:", result)
# 预期输出:Cats love tuna
4 总结
4 实操常见报错排查(新手必看)
实操中容易遇到API密钥、依赖、配额等问题,以下是3个高频报错的原因及解决方案,帮你快速避坑。
1 报错1:ValidationError(缺少智谱APIKey)
错误信息:ValidationError: Did not find api_key, please add an environment variable ZHIPUAI_API_KEY``
原因:ChatZhipuAI初始化必须携带智谱API_KEY,未配置环境变量、未手动传参都会校验失败。
解决方案:
- 方式1(调试首选):在代码中直接注入
api_key=ZHIPU_API_KEY(如4.2.2节代码)。 - 方式2(全局配置):通过环境变量配置,避免代码中暴露密钥。
2 报错2:ModuleNotFoundError(缺少zhipuai依赖)
错误信息:ImportError: Could not import zhipuai python package. Please install it with pip install zhipuai``
原因:LangChain的智谱模型封装,底层强依赖智谱官方zhipuai SDK,仅安装LangChain无法正常使用。
解决方案:执行命令pip install zhipuai,安装官方SDK即可。
3 报错3:APIReachLimitError(智谱配额不足)
错误信息:APIReachLimitError: Error code: 429, {"error":{"code":"1113","message":"余额不足或无可用资源包,请充值。"}}
核心原因:智谱资源包按模型隔离计费,大模型资源包(如glm-4.5-air)与嵌入模型资源包(如embedding-2)不互通,调用无配额的模型会直接拦截。
解决方案:
- 开发调试:使用本地开源嵌入模型(如本节方案),不调用智谱嵌入接口,零配额消耗。
- 正式部署:单独购买智谱
embedding-2专属资源包,用于线上向量生成。
7.5 本节总结
- RAG是LangChain入门的核心场景,核心价值是“让大模型能检索外部/私有数据,提升回答准确性和时效性”。
- RAG不是Agent,但却是Agent开发的基础组件,掌握RAG是入门Agent的第一步。
- 国产大模型(智谱)接入LangChain时,需注意3点:最新导入路径、安装官方SDK、区分模型资源包(避免配额报错)。
- 新手最优实践:智谱对话大模型(复用资源包)+ 本地开源嵌入模型(免费无配额)+ FAISS本地向量库(纯本地运行),适合快速上手。
- 后续扩展:可将
texts替换为本地文档(如TXT、PDF),通过LangChain的文档加载器(如TextLoader)批量导入,搭建真正的私有知识库问答系统。
8 自定义Tools实践
8.1 本节学习目标
- 掌握使用
@tool装饰器自定义工具的标准写法 - 学会搭建工具调用智能代理(Agent)
- 实现大模型自动调用工具完成高精度数学计算
- 完成Sigmoid导数计算实战,验证工具能力
8.2 环境与依赖配置
# 配置LangSmith项目名称,用于追踪调试
os.environ["LANGCHAIN_PROJECT"] = 'tools_test2'
# 导入数值计算库 + 工具装饰器
import numpy as np
from langchain_core.tools import tool
代码解读
os.environ["LANGCHAIN_PROJECT"]:给当前任务命名,方便在LangSmith查看执行日志np:用于高精度指数运算,弥补大模型计算短板@tool:LangChain官方工具装饰器,一键把普通函数变成大模型可调用的工具
8.3 自定义数学计算工具(核心)
# 加法工具
@tool
def add(num1: float, num2: float) -> float:
"Add two numbers."
return num1 + num2
# 减法工具
@tool
def subtract(num1: float, num2: float) -> float:
"""Subtract two numbers."""
return num1 - num2
# 乘法工具
@tool
def multiply(num1: float, num2: float) -> float:
"""Multiply two float ."""
return num1 * num2
# 除法工具
@tool
def divide(numerator: float, denominator: float) -> float:
"""Divides the numerator by the denominator."""
result = numerator / denominator
return result
# 幂运算工具
@tool
def power(base: float, exponent: float) -> float:
"Take the base to the exponent power, base^exponent."
return base**exponent
# 自然指数 e^x 工具
@tool
def exp(x):
"""Calculate the natural exponential $e^x$"""
return np.exp(x)
# 把所有工具放入列表,统一管理
tools = [add, subtract, multiply, divide, power, exp]
代码解读
@tool装饰器- 作用:将Python函数注册为LangChain标准工具
- 大模型会自动读取函数注释、参数,判断什么时候调用
- 函数规范
- 必须写文档字符串:告诉大模型这个工具是干嘛的
- 推荐写参数类型注解:让大模型知道传什么类型数据
- 工具功能
- 基础运算:加减乘除、幂运算
- 高级运算:
np.exp(x)高精度计算自然指数
tools列表- 把所有自定义工具打包,后续直接交给Agent调用
8.4 构建工具调用Agent
# 导入大模型、Agent、提示词模板
from langchain_openai import ChatOpenAI
from langchain.agents import create_openai_tools_agent
from langchain_core.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate,
)
# 初始化大模型:gpt-4o,温度0保证计算准确
llm = ChatOpenAI(model="gpt-4o", temperature=0, streaming=True)
# 系统提示词:定义AI角色
system_template = """
You are a helpful math assistant that uses calculation functions to solve complex math problems step by step.
"""
human_template = "{input}"
# 构建提示词模板(工具调用必备格式)
prompt = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template(system_template),
MessagesPlaceholder(variable_name="chat_history", optional=True), # 对话历史
HumanMessagePromptTemplate.from_template(input_variables=["input"], template=human_template),
MessagesPlaceholder(variable_name="agent_scratchpad"), # Agent思考+调用工具的临时空间
]
)
# 创建OpenAI工具调用Agent
agent = create_openai_tools_agent(llm, tools, prompt)
代码解读
- 大模型设置
temperature=0:计算任务必须关闭随机性,保证结果唯一准确。- temperature 是温度系数,控制大模型回答的 “随机性 / 创造性”。
- 数字越大(0.7 ~ 1.0)→ 越有创意、越多样、越天马行空→ 适合写文案、写诗、编故事
- 数字越小(0 ~ 0.1)→ 越严谨、越固定、越保守→ 适合计算、数学、逻辑、代码、 factual 问答
streaming=True:开启流式输出
- 提示词模板关键占位符
chat_history:可选,支持多轮对话agent_scratchpad:工具调用必须加,存储Agent思考过程
create_openai_tools_agent- 专门适配OpenAI系列模型的工具调用代理
- 自动实现:理解问题 → 选工具 → 传参数 → 接收结果 → 回答问题
8.5 运行Agent执行器
from langchain.agents import AgentExecutor
# 封装代理执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 调用:计算sigmoid(2.5)的导数
agent_executor.invoke({"input": "What is the result of directive of sigmoid(2.5)?"})
代码解读
AgentExecutor- Agent的“运行引擎”,负责执行大模型的工具调用指令
- Agent 只负责 “想” 和 “决定”,AgentExecutor 才负责 “真正动手执行”。
verbose=True:打印完整执行流程(思考→调用工具→返回结果)
- Agent的“运行引擎”,负责执行大模型的工具调用指令
- 执行逻辑
- 大模型读懂需求:计算sigmoid(2.5)导数
- 自动推导公式 → 调用
exp等工具分步计算 → 输出答案
8.6 结果验证(PyTorch对标)
import torch
import torch.nn.functional as F
# Sigmoid函数及其导数公式
$$
\begin{split}
\sigma(x)&=\frac{1}{1+\exp(-x)}\\
\sigma'(x)&=\sigma(x)(1-\sigma(x))\\
\end{split}
$$
# PyTorch原生计算,用于校验结果
F.sigmoid(torch.tensor([2.5])) * (1-F.sigmoid(torch.tensor([2.5])))
代码解读
- 使用PyTorch官方
sigmoid函数计算导数,作为标准答案 - 对比Agent调用自定义工具的计算结果,验证工具链路100%准确
8.7 本节核心总结
- 自定义工具三步法
- 用
@tool装饰函数 - 写清晰的函数注释
- 放入
tools列表
- 用
- Agent工作模式
- 大模型:负责理解问题、推导公式、规划步骤
- 自定义工具:负责高精度、确定性计算
- 关键组件
@tool:工具封装create_openai_tools_agent:工具代理AgentExecutor:执行引擎agent_scratchpad:工具调用必备占位符
- 适用场景
- 数学计算、代码执行、数据库查询、API调用、文件操作等所有大模型自身做不到的外部能力
补充
dotenv 与 load_dotenv
python-dotenv 用于读取项目根目录的 .env 文件,load_dotenv() 会将文件中的密钥、配置等临时加载到当前 Python 进程的环境变量中,方便代码通过 os.getenv() 获取,避免密钥硬编码泄露。
通过 dotenv 加载的环境变量仅在当前程序运行期间有效,程序关闭、终端退出或电脑重启后立即失效,不会写入系统环境变量,每次运行代码都需要重新调用 load_dotenv() 加载。
可以把环境变量里的glm api key删掉了。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)