MySQL Binlog 配置与数据同步完全指南
基础配置:开启 Binlog,选择 ROW 格式,配置 server-id日常管理:使用 mysqlbinlog 解析,定期清理日志主从复制:异步/半同步复制配置,故障排查异构同步:使用 Canal 实现 MySQL → Kafka → ES 数据流生产实践:性能优化、监控告警、故障恢复生产环境务必使用ROW格式 +保证数据安全复杂拓扑使用 GTID 模式简化故障恢复大数据量同步优先考虑 Cana
一、Binlog 基础概念
什么是 Binlog?
Binlog(Binary Log,二进制日志)是 MySQL 服务器层维护的一种日志文件,记录了所有修改数据库数据的 SQL 语句(DDL 和 DML)以及每条语句的执行时间。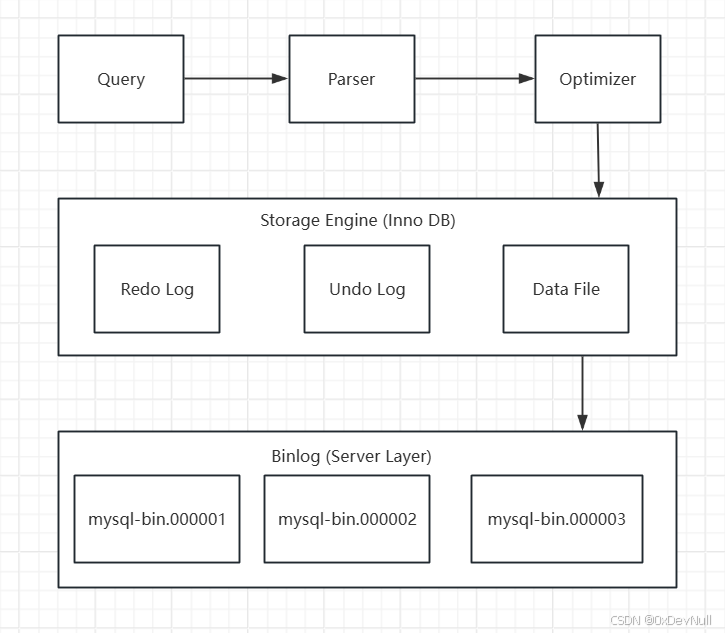
Binlog 的三种格式
| 格式 | 特点 | 适用场景 |
|---|---|---|
| STATEMENT | 记录原始 SQL 语句,日志量小 | 简单 SQL,无随机函数 |
| ROW | 记录每行数据的变化,日志量大但精确 | 需要精确复制,复杂 SQL |
| MIXED | 混合模式,MySQL 自动选择 | 一般生产环境推荐 |
生产环境强烈推荐使用 ROW 格式,虽然日志量较大,但能保证数据一致性,避免主从数据不一致问题。
Binlog 的核心用途
-
数据恢复:基于时间点恢复(Point-in-Time Recovery, PITR)
-
主从复制:实现读写分离、高可用架构
-
数据同步:CDC(Change Data Capture)捕获数据变更
-
审计追踪:记录数据变更历史
二、开启 Binlog 配置
2.1 修改配置文件
编辑 MySQL 配置文件(Linux 通常为 /etc/my.cnf 或 /etc/mysql/my.cnf,Windows 为 my.ini):
[mysqld]
# ============================================
# Binlog 基础配置(必须)
# ============================================
# 开启 Binlog,并指定文件名前缀
log-bin=mysql-bin
# 或指定完整路径(推荐)
log-bin=/var/lib/mysql/mysql-bin
# Binlog 格式:ROW 推荐用于生产环境
binlog_format=ROW
# 服务器唯一标识,集群中每个节点必须不同
server-id=1
# ============================================
# Binlog 高级配置(推荐)
# ============================================
# 单个 Binlog 文件大小限制(默认 1GB)
max_binlog_size=1G
# Binlog 过期时间(天),自动清理过期日志
expire_logs_days=7
# 保留 Binlog 个数(MySQL 8.0 推荐用此替代 expire_logs_days)
# binlog_expire_logs_seconds=604800 # 7天 = 7*24*3600
# 同步写磁盘策略(0: 依赖 OS,1: 每次提交都同步,N: 每 N 次提交同步)
sync_binlog=1
# 事务提交时同时刷盘(配合 sync_binlog=1 保证数据安全)
innodb_flush_log_at_trx_commit=1
# 记录完整行镜像(FULL: 记录变更前后完整行,MINIMAL: 只记录必要字段)
binlog_row_image=FULL
# 是否记录原始 SQL(用于审计,MySQL 5.6+)
binlog_rows_query_log_events=ON
# 只记录特定数据库(可选,逗号分隔)
# binlog-do-db=db1,db2
# 忽略特定数据库(可选,与 binlog-do-db 互斥)
# binlog-ignore-db=mysql,information_schema,performance_schema,sys
# GTID 配置(MySQL 5.6+,推荐用于复杂拓扑)
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON2.2 配置参数详解
关键参数说明
-- 查看当前 Binlog 配置
SHOW VARIABLES LIKE '%binlog%';
SHOW VARIABLES LIKE '%log_bin%';
SHOW VARIABLES LIKE '%server_id%';
SHOW VARIABLES LIKE '%gtid%';| 参数 | 说明 | 建议值 |
|---|---|---|
log-bin |
开启 Binlog 并指定前缀 | 必须设置 |
server-id |
服务器唯一 ID | 1-2^32-1,集群内唯一 |
binlog_format |
日志格式 | ROW |
sync_binlog |
刷盘策略 | 1(数据安全优先)或 1000(性能优先) |
expire_logs_days |
过期天数 | 7-30 天 |
max_binlog_size |
单个文件大小 | 1G |
binlog_row_image |
行镜像格式 | FULL |
sync_binlog 与 innodb_flush_log_at_trx_commit 组合
| sync_binlog | innodb_flush_log_at_trx_commit | 安全性 | 性能 | 适用场景 |
|---|---|---|---|---|
| 1 | 1 | 最高 | 最低 | 金融级,不允许丢数据 |
| 1 | 2 | 高 | 中 | 一般生产环境 |
| 1000 | 2 | 中 | 最高 | 允许秒级数据丢失 |
| 0 | 0 | 低 | 最高 | 测试环境 |
2.3 重启并验证
# Linux 系统重启 MySQL
sudo systemctl restart mysqld
# 或
sudo service mysql restart
# Windows 系统
net stop MySQL
net start MySQL-- 登录 MySQL 验证
mysql -u root -p
-- 查看 Binlog 是否开启
SHOW VARIABLES LIKE 'log_bin';
-- 结果应为 ON
-- 查看当前使用的 Binlog 文件
SHOW MASTER STATUS;
-- 查看所有 Binlog 文件列表
SHOW BINARY LOGS;
-- 查看 Binlog 格式
SHOW VARIABLES LIKE 'binlog_format';预期输出:
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.000001 | 154 | | | 0d3f3a8e-1234-11ef-8e32-080027a5c0e1:1-5 |
+------------------+----------+--------------+------------------+------------------------------------------+三、Binlog 管理与查看
3.1 Binlog 文件管理
-- 查看所有 Binlog 文件及大小
SHOW BINARY LOGS;
-- 刷新 Binlog(生成新文件)
FLUSH LOGS;
-- 查看当前正在写入的 Binlog
SHOW MASTER STATUS;
-- 清理指定日期前的 Binlog(手动清理)
PURGE BINARY LOGS BEFORE '2024-03-01 00:00:00';
-- 清理指定文件之前的所有 Binlog
PURGE BINARY LOGS TO 'mysql-bin.000010';
-- 查看 Binlog 占用磁盘空间
SELECT
SUM(LOG_FILE_SIZE)/1024/1024/1024 AS total_size_gb
FROM
performance_schema.binary_log_stats;3.2 使用 mysqlbinlog 工具解析
# 查看 Binlog 文件内容(基本)
mysqlbinlog /var/lib/mysql/mysql-bin.000001
# 查看特定时间范围
mysqlbinlog --start-datetime="2024-03-22 10:00:00" \
--stop-datetime="2024-03-22 12:00:00" \
/var/lib/mysql/mysql-bin.000001
# 查看特定位置范围
mysqlbinlog --start-position=154 --stop-position=1000 \
/var/lib/mysql/mysql-bin.000001
# 以 ROW 格式查看(转换为可读 SQL)
mysqlbinlog --base64-output=DECODE-ROWS -v \
/var/lib/mysql/mysql-bin.000001
# 只查看特定数据库
mysqlbinlog --database=mydb /var/lib/mysql/mysql-bin.000001
# 远程查看(指定服务器连接信息)
mysqlbinlog --read-from-remote-server \
--host=localhost \
--user=repl \
--password \
--raw mysql-bin.0000013.3 Binlog 内容解析示例
ROW 格式 Binlog 示例:
-- 原始操作
UPDATE users SET age = 30 WHERE id = 1;mysqlbinlog -v 输出:
### UPDATE `test`.`users`
### WHERE
### @1=1 /* INT meta=0 nullable=0 is_null=0 */
### @2='Alice' /* VARSTRING(60) meta=60 nullable=0 is_null=0 */
### @3=25 /* INT meta=0 nullable=1 is_null=0 */
### SET
### @1=1 /* INT meta=0 nullable=0 is_null=0 */
### @2='Alice' /* VARSTRING(60) meta=60 nullable=60 is_null=0 */
### @3=30 /* INT meta=0 nullable=1 is_null=0 */解读:
-
@1,@2,@3对应表的第 1, 2, 3 列 -
WHERE部分是修改前的数据 -
SET部分是修改后的数据
四、基于 Binlog 的数据同步方案
4.1 常见数据同步架构
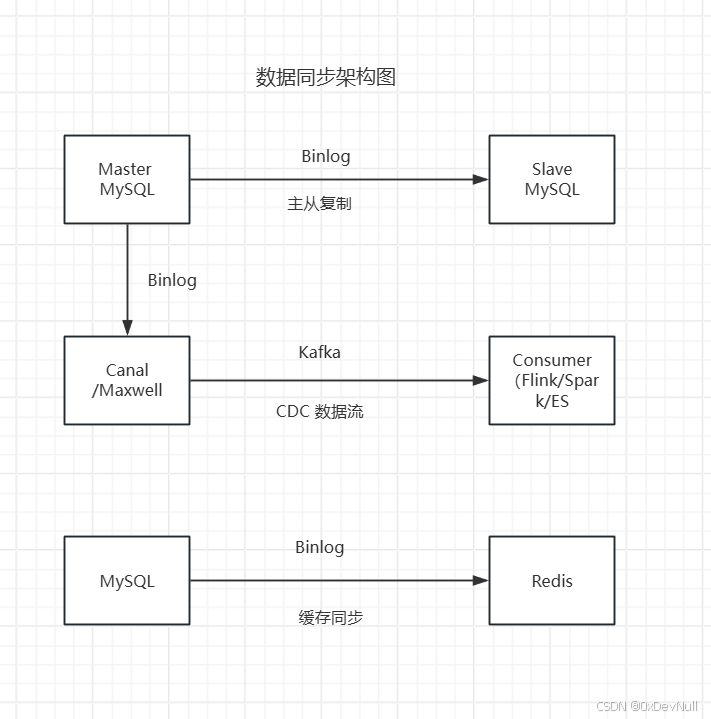
4.2 主流 Binlog 同步工具对比
| 工具 | 开发方 | 特点 | 适用场景 |
|---|---|---|---|
| Canal | 阿里巴巴 | 成熟稳定,支持 Kafka/RocketMQ | 大规模数据同步 |
| Maxwell | Zendesk | 轻量级,直接输出 JSON | 简单同步,快速上手 |
| Debezium | RedHat | 基于 Kafka Connect,生态完善 | 企业级 CDC 平台 |
| Flink CDC | Apache | 实时流处理集成 | 实时数仓建设 |
| DataX | 阿里巴巴 | 离线同步为主 | 批量数据迁移 |
五、实战:MySQL 主从复制配置
5.1 架构规划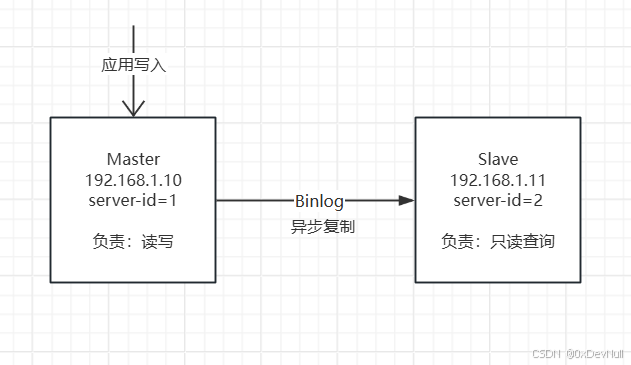
5.2 Master 节点配置(192.168.1.10)
# /etc/my.cnf
[mysqld]
server-id=1
log-bin=mysql-bin
binlog_format=ROW
expire_logs_days=7
max_binlog_size=1G
# 可选:只同步特定数据库
# binlog-do-db=production_db
# 可选:不同步系统库
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
binlog-ignore-db=sys创建复制专用账号:
-- 创建复制用户
CREATE USER 'repl'@'192.168.1.%' IDENTIFIED BY 'StrongPassword123!';
-- 授权复制权限
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.1.%';
-- 刷新权限
FLUSH PRIVILEGES;
-- 查看当前 Binlog 位置(记录 File 和 Position)
SHOW MASTER STATUS;
-- 输出示例:
-- File: mysql-bin.000001
-- Position: 1545.3 Slave 节点配置(192.168.1.11)
# /etc/my.cnf
[mysqld]
server-id=2
log-bin=mysql-bin # 可选,级联复制时需要
binlog_format=ROW
read_only=1 # 只读模式,防止误写入
# 可选:只同步特定数据库
# replicate-do-db=production_db
# 可选:忽略特定表
# replicate-ignore-db=test
# replicate-ignore-table=production_db.logs配置主从连接:
-- 停止 Slave(如果之前配置过)
STOP SLAVE;
RESET SLAVE ALL;
-- 配置主节点信息
CHANGE MASTER TO
MASTER_HOST='192.168.1.10',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='StrongPassword123!',
MASTER_LOG_FILE='mysql-bin.000001', -- 从 SHOW MASTER STATUS 获取
MASTER_LOG_POS=154, -- 从 SHOW MASTER STATUS 获取
MASTER_CONNECT_RETRY=10,
MASTER_RETRY_COUNT=86400;
-- 或使用 GTID 模式(推荐,MySQL 5.6+)
CHANGE MASTER TO
MASTER_HOST='192.168.1.10',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='StrongPassword123!',
MASTER_AUTO_POSITION=1; -- 自动定位 GTID
-- 启动 Slave
START SLAVE;
-- 查看 Slave 状态
SHOW SLAVE STATUS\G5.4 验证主从复制
-- Slave 节点执行
SHOW SLAVE STATUS\G
-- 关键指标检查:
-- Slave_IO_Running: Yes (IO 线程运行状态)
-- Slave_SQL_Running: Yes (SQL 线程运行状态)
-- Seconds_Behind_Master: 0 (延迟秒数,0 表示无延迟)
-- Last_IO_Error: (IO 错误信息,应为空)
-- Last_SQL_Error: (SQL 错误信息,应为空)测试数据同步:
-- Master 节点
CREATE DATABASE test_replication;
USE test_replication;
CREATE TABLE t1 (id INT PRIMARY KEY, name VARCHAR(50));
INSERT INTO t1 VALUES (1, 'Master Data');
-- Slave 节点验证
SHOW DATABASES; -- 应看到 test_replication
USE test_replication;
SELECT * FROM t1; -- 应看到 (1, 'Master Data')5.5 主从复制模式选择
| 模式 | 配置 | 特点 |
|---|---|---|
| 异步复制 | 默认 | 性能最好,可能丢数据 |
| 半同步复制 | plugin-load=rpl_semi_sync_master |
至少一个 Slave 确认,平衡性能与安全 |
| 组复制 | group_replication |
多主架构,自动故障转移 |
| GTID 复制 | gtid_mode=ON |
自动定位,故障恢复简单 |
半同步复制配置:
# Master 配置
plugin-load=rpl_semi_sync_master=semisync_master.so
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000 # 超时 1 秒降级为异步
# Slave 配置
plugin-load=rpl_semi_sync_slave=semisync_slave.so
rpl_semi_sync_slave_enabled=1六、实战:使用 Canal 实现异构数据同步
6.1 架构设计:MySQL → Kafka → Elasticsearch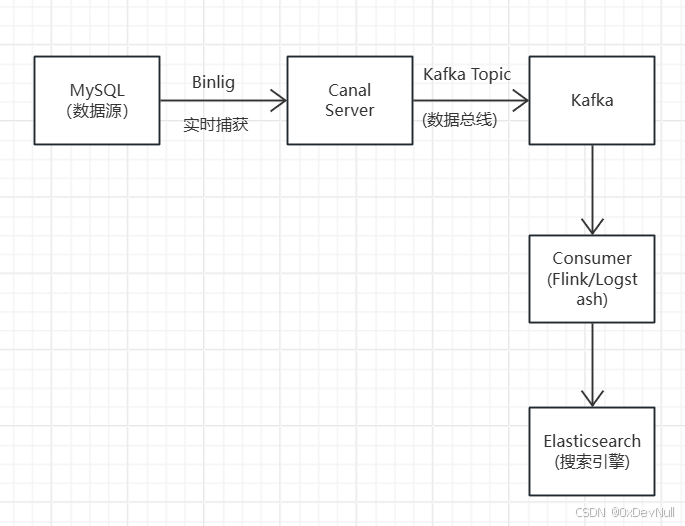
6.2 Canal 部署配置
步骤 1:MySQL 准备(已开启 Binlog,ROW 格式)
-- 创建 Canal 专用账号
CREATE USER 'canal'@'%' IDENTIFIED BY 'Canal@123456';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;步骤 2:Canal Server 配置
canal.properties(主配置):
# Canal 实例名称
canal.destinations = example
# Canal Server 模式:tcp/kafka/rocketMQ/rabbitMQ
canal.serverMode = kafka
# Kafka 配置
canal.mq.servers = 192.168.1.20:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = allinstance.properties(实例配置):
# MySQL 连接配置
canal.instance.master.address=192.168.1.10:3306
canal.instance.dbUsername=canal
canal.instance.dbPassword=Canal@123456
# 连接编码
canal.instance.connectionCharset=UTF-8
# 订阅配置(正则匹配)
# 订阅所有库所有表:.*\\..*
# 订阅特定库:mydb\\..*
# 订阅特定表:mydb\\.users,mydb\\.orders
canal.instance.filter.regex=mydb\\..*
# 过滤黑名单
canal.instance.filter.black.regex=mysql\\..*,information_schema\\..*
# 表结构缓存
canal.instance.tsdb.enable=true
# GTID 模式(推荐)
canal.instance.gtidon=true步骤 3:Kafka 消息格式
Canal 发送到 Kafka 的消息为 JSON 格式:
{
"data": [
{
"id": "1",
"name": "Alice",
"age": "30",
"update_time": "2024-03-22 14:30:00"
}
],
"database": "mydb",
"table": "users",
"type": "UPDATE",
"ts": 1711098600,
"sql": "UPDATE `users` SET `age` = 30 WHERE `id` = 1",
"old": [
{
"age": "25"
}
],
"pkNames": ["id"],
"mysqlType": {
"id": "int",
"name": "varchar(50)",
"age": "int",
"update_time": "datetime"
}
}6.3 消费端处理示例(Python)
from kafka import KafkaConsumer
import json
import requests
# 连接 Kafka
consumer = KafkaConsumer(
'mydb_users', # Topic 名称为 {数据库}_{表名}
bootstrap_servers=['192.168.1.20:9092'],
group_id='es-sync-group',
auto_offset_reset='latest',
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
# ES 连接配置
ES_HOST = 'http://192.168.1.30:9200'
def sync_to_es(message):
"""同步数据到 Elasticsearch"""
event_type = message['type'] # INSERT/UPDATE/DELETE
database = message['database']
table = message['table']
data = message['data']
pks = message.get('pkNames', ['id'])
index_name = f"{database}_{table}"
for row in data:
# 构建文档 ID(使用主键)
doc_id = '-'.join(str(row[pk]) for pk in pks)
if event_type == 'DELETE':
# 删除文档
url = f"{ES_HOST}/{index_name}/_doc/{doc_id}"
requests.delete(url)
print(f"Deleted: {doc_id}")
elif event_type in ['INSERT', 'UPDATE']:
# 插入或更新文档
url = f"{ES_HOST}/{index_name}/_doc/{doc_id}"
requests.put(url, json=row)
print(f"Upserted: {doc_id}")
# 消费消息
for msg in consumer:
try:
sync_to_es(msg.value)
except Exception as e:
print(f"Error processing message: {e}")
# 实现死信队列或重试逻辑七、常见问题与排错
7.1 Binlog 相关故障
问题 1:Binlog 未开启
-- 现象:SHOW MASTER STATUS 返回空
-- 解决:检查配置并重启
SHOW VARIABLES LIKE 'log_bin';
-- 如果为 OFF,检查 my.cnf 中 log-bin 配置并重启 MySQL问题 2:Binlog 磁盘空间满
# 现象:磁盘空间不足,MySQL 无法写入
# 紧急处理:清理过期 Binlog
# 方法 1:在 MySQL 中清理
PURGE BINARY LOGS BEFORE DATE(NOW() - INTERVAL 3 DAY);
# 方法 2:设置更短的过期时间
SET GLOBAL expire_logs_days=3;
# 方法 3:手动删除文件(谨慎!)
# 先执行 PURGE,再删除文件7.2 主从复制故障
问题 3:Slave_IO_Running: No
-- 检查网络连接
-- 检查复制账号权限
-- 检查 Binlog 文件是否存在
-- 查看详细错误
SHOW SLAVE STATUS\G
-- 查看 Last_IO_Error
-- 修复步骤:
STOP SLAVE;
-- 如果主库 Binlog 已被清理,需要重新同步数据
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.0000xx', MASTER_LOG_POS=xxx;
START SLAVE;问题 4:主从数据不一致
-- 使用 pt-table-checksum 检查一致性(Percona Toolkit)
pt-table-checksum --host=master --user=root --password=xxx \
--databases=mydb --replicate=percona.checksums
-- 使用 pt-table-sync 修复
pt-table-sync --execute --replicate=percona.checksums \
h=master,u=root,p=xxx h=slave,u=root,p=xxx问题 5:复制延迟高(Seconds_Behind_Master 很大)
-- 优化方案:
-- 1. 升级 Slave 硬件(特别是磁盘 I/O)
-- 2. 使用多线程复制(MySQL 5.6+)
SET GLOBAL slave_parallel_workers=4;
SET GLOBAL slave_parallel_type='LOGICAL_CLOCK'; # MySQL 5.7+
-- 3. 减少大事务,拆分批量操作
-- 4. 使用半同步复制减少延迟累积7.3 Canal 同步故障
| 问题 | 原因 | 解决 |
|---|---|---|
| Canal 无法连接 MySQL | 账号权限不足或网络不通 | 检查 GRANT 权限,检查防火墙 |
| 消费延迟大 | 消费端处理能力不足 | 增加消费者,优化消费逻辑 |
| 消息丢失 | Kafka 配置不当 | 设置 acks=all,启用幂等性 |
| 数据格式错误 | 表结构变更 | 重启 Canal 实例刷新表结构 |
7.4 性能优化建议
# my.cnf 优化配置
[mysqld]
# Binlog 优化
binlog_cache_size=1M # 事务缓存大小
max_binlog_cache_size=2G # 最大缓存
binlog_stmt_cache_size=32K # 非事务语句缓存
# 主从复制优化(Slave)
slave_parallel_workers=8 # 并行复制线程数
slave_parallel_type=LOGICAL_CLOCK
slave_preserve_commit_order=ON
# 半同步复制优化(Master)
rpl_semi_sync_master_wait_for_slave_count=1 # 等待确认 Slave 数
rpl_semi_sync_master_wait_point=AFTER_SYNC # 等待时机总结
本教程涵盖了 MySQL Binlog 的完整知识体系:
-
基础配置:开启 Binlog,选择 ROW 格式,配置 server-id
-
日常管理:使用 mysqlbinlog 解析,定期清理日志
-
主从复制:异步/半同步复制配置,故障排查
-
异构同步:使用 Canal 实现 MySQL → Kafka → ES 数据流
-
生产实践:性能优化、监控告警、故障恢复
关键要点:
-
生产环境务必使用
ROW格式 +sync_binlog=1保证数据安全 -
复杂拓扑使用 GTID 模式简化故障恢复
-
大数据量同步优先考虑 Canal + Kafka 架构
-
定期检查
SHOW SLAVE STATUS监控复制健康度

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)