Deformable Mamba:广角图像分割新思路
在计算机视觉的密集预测任务(如语义分割)中,状态空间模型(SSM,如 Mamba)凭借其线性的计算复杂度,正逐渐成为 Transformer 的有力竞争者。然而,当我们把目光从标准的针孔相机转向广角相机(如 180° 鱼眼或 360° 全景)时,现有的视觉 Mamba 模型往往会出现问题。本文将深度解析发表于 2025 年的一篇具有工程实用价值的论文——。作者提出了一种轻量级的。它不仅将参数量和计
Deformable Mamba:广角图像分割新思路
在计算机视觉的密集预测任务(如语义分割)中,状态空间模型(SSM,如 Mamba)凭借其线性的计算复杂度,正逐渐成为 Transformer 的有力竞争者 。然而,当我们把目光从标准的针孔相机转向广角相机(如 180° 鱼眼或 360° 全景)时,现有的视觉 Mamba 模型往往会出现问题 。
本文将深度解析发表于 2025 年的一篇具有工程实用价值的论文——《Deformable Mamba for Wide Field of View Segmentation》 。作者提出了一种轻量级的可变形 Mamba 解码器(Deformable Mamba Decoder) 。它不仅将参数量和计算量大幅压缩,还作为一种“即插即用”的插件,赋予了常规骨干网络处理广角畸变的能力 。本文最后将可变形Mamba块实现为可插拔模块方便读者理解使用。
一、问题的起源:广角镜头的“几何扭曲”
在目前的视觉预训练模型中,大多数数据都是基于窄视角的针孔相机(Pinhole)采集的 。针孔相机的成像符合常规的透视几何,物体比例匀称。但在自动驾驶、机器人导航等领域,为了获取更开阔的视野,常常使用鱼眼或全景相机 。
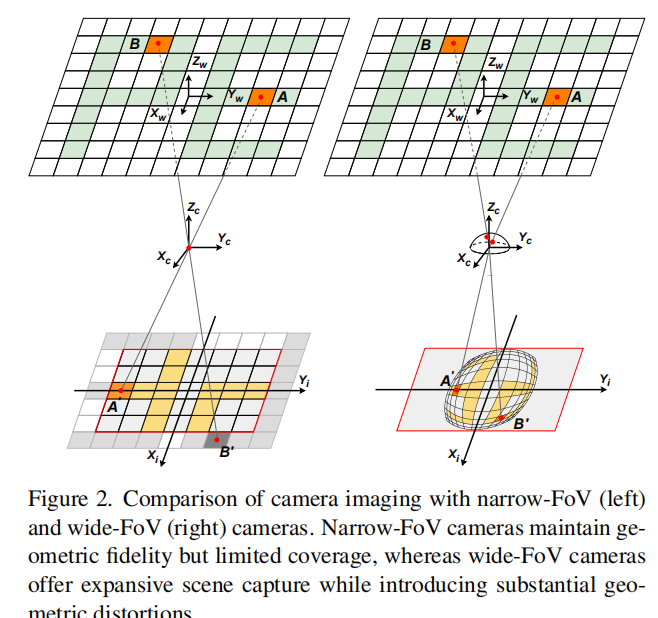
上图对比了窄视角相机(左)与广角相机(右)的成像网格 。可以直观看到广角相机边缘的像素网格被严重拉伸。这就好比我们平时习惯了看平面的镜子(针孔相机),突然换成了一面哈哈镜(广角相机)。虽然我们看到了更多的场景,但边缘的汽车、行人全都被拉扯变形了 。如果我们直接用看平面镜的经验(传统分割模型)去识别哈哈镜里的物体,准确率必然大幅下降 。此前的研究通常会为了应对畸变而重新设计整个网络(编码器+解码器) 。但这带来了一个弊端:我们很难直接复用那些在海量正常图像上训练好的强大骨干网络(Backbone) 。
二、核心架构拆解:DMF 模块的“双路并行”
作者提出了一种解耦的思路:让编码器(Encoder)保持不变,把抗畸变的任务全部交给专门设计的解码器(Decoder) 。解码器是一个名为 可变形 Mamba 融合块(Deformable Mamba Fusion, DMF Block) 的结构 。
在这里,要说明一个问题:**本文的 Mamba 真的像可变形卷积那样“变形”了吗?答案是并没有直接变形。Mamba 的底层逻辑是将图像展平为 1D 序列进行扫描,在这种一维序列中强行加入空间二维坐标的可学习形变,会导致计算复杂度失去线性优势,在工程上难以高效实现 。因此,作者采用了一种务实的“并行处理”**策略 。在 DMF 模块中,特征被分发到两条截然不同的支路:
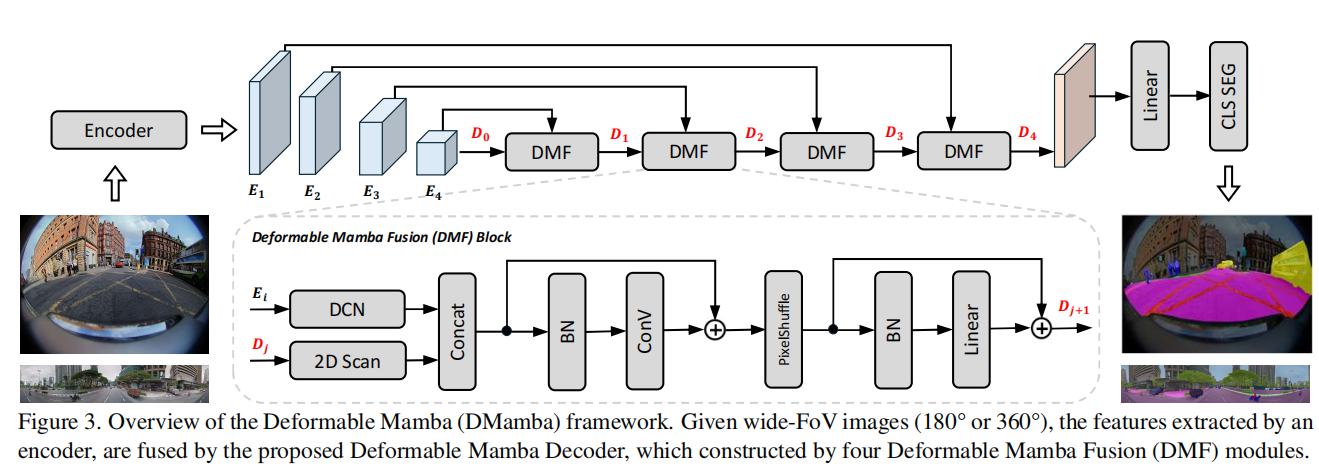
1. 局部抗畸变支路:可变形卷积 (DCN)
来自骨干网络的多尺度特征 EiE_iEi 进入了一个 3×33 \times 33×3 的可变形卷积层(DCNv2) 。其数学表达为:
Eout(p)=∑k=1KwkmkEin(p+pk+Δpk)E_{out}(p) = \sum_{k=1}^{K} w_k m_k E_{in}(p + p_k + \Delta p_k)Eout(p)=∑k=1KwkmkEin(p+pk+Δpk)
公式中的核心是 Δpk\Delta p_kΔpk(偏移量) 。 面对被拉伸的广角图像,DCN 能够通过学习偏移量,自动让卷积核的采样点去“贴合”变形的物体,从而提取出纠正后的局部特征 。
2. 全局上下文支路:2D Mamba 扫描 (SS2D)
来自上一层解码器的特征 DjD_jDj 则进入了 Mamba 的 2D 扫描模块 。该模块利用四个方向的连续扫描机制(Quadri-directional scanning) ,以极低的计算代价捕获整张图像的全局上下文依赖 。
3. 巧妙的融合:为什么选用 PixelShuffle?
两路特征在拼接(Concat)后,需要进行上采样(放大分辨率) 。作者没有使用传统的双线性插值(Bilinear Interpolation),而是采用了 PixelShuffle(亚像素卷积/像素洗牌) :
PS(T)h,w,2c=T2h,2w,c2\mathcal{PS}(T)_{h,w,2c} = T_{2h, 2w, \frac{c}{2}}PS(T)h,w,2c=T2h,2w,2c
双线性插值本质上是在两个已知像素之间做数学估算,这种“无中生有”的做法容易模糊掉模型好不容易提取出的高频抗畸变特征 。 而 PixelShuffle 就像是**“发牌”,它将拼接后多出来的通道(Channel)维度,按照特定的空间排列规律,均匀地平摊到图像的高度和宽度上 。这种做法是纯粹的空间重组,不仅实现了分辨率翻倍,还无损保留了**双支路提取的所有特征信息 。
三、代码实现
为了让大家看清 DMF 模块的骨架,我将核心源码进行了抽象与注释:
import torch
import torch.nn as nn
import torchvision
from timm.models.layers import DropPath
# =====================================================================
# 模块一:局部抗畸变支路 —— Deformable Feature Transformation (DFT)
# 对应论文:负责学习像素偏移量,利用可变形卷积(DCN)纠正广角畸变
# =====================================================================
class DFT(nn.Module):
def __init__(self, in_chans, out_chans, kernel_size=3):
super().__init__()
self.padding = (kernel_size - 1) // 2
# 1. 主特征提取卷积 (真正用于提取特征的权重)
self.proj = nn.Conv2d(in_chans, out_chans, kernel_size=kernel_size, padding=self.padding)
# 2. 偏移量预测网络 (输出通道数为 2 * K * K,代表X和Y方向的偏移)
self.offset_conv = nn.Conv2d(in_chans, 2 * kernel_size * kernel_size,
kernel_size=kernel_size, padding=self.padding)
# 3. 掩码预测网络 (输出通道数为 K * K,代表每个采样点的重要性权重)
self.mask_conv = nn.Conv2d(in_chans, kernel_size * kernel_size,
kernel_size=kernel_size, padding=self.padding)
self.norm = nn.BatchNorm2d(out_chans)
self.act = nn.GELU()
def forward(self, x):
# 步骤A:限制最大偏移量,防止训练初期采样点飞出边界(极其关键的工程Trick)
max_offset = torch.tensor((min(x.shape[-2], x.shape[-1]) // 4)).to(x.device)
offset = self.offset_conv(x).clamp(-max_offset, max_offset)
# 步骤B:生成采样点权重掩码 (0到1之间)
mask = 2. * torch.sigmoid(self.mask_conv(x))
# 步骤C:执行标准的 DCNv2 (可变形卷积) 操作
x = torchvision.ops.deform_conv2d(
input=x,
offset=offset,
weight=self.proj.weight,
bias=self.proj.bias,
padding=self.padding,
mask=mask,
stride=1,
)
return self.act(self.norm(x))
# =====================================================================
# 模块二:全局上下文支路 —— SS2D (简化版 Wrapper)
# 对应论文:利用 Mamba 的四向选择性扫描(Quadri-directional scan)捕获全局信息
# =====================================================================
class Mamba2D_Wrapper(nn.Module):
def __init__(self, dim):
super().__init__()
# 在实际工程中,这里会调用复杂的mamba_ssm底层CUDA算子
# 为了核心逻辑清晰,此处封装为一个 Wrapper。
# 2D展开 -> 4个方向的1D扫描 -> 状态空间矩阵运算 -> 2D重组
from mamba_ssm import Mamba # 假设已安装
self.mamba = Mamba(d_model=dim)
self.norm = nn.LayerNorm(dim)
def forward(self, x):
# x shape: [B, C, H, W]
B, C, H, W = x.shape
# Mamba 接收的是 1D 序列,所以需要拉平并调换维度
x_flat = x.flatten(2).transpose(1, 2) # [B, H*W, C]
# 执行全局状态空间扫描 (内部包含多向扫描合并)
out = self.mamba(x_flat)
out = self.norm(out)
# 重新折叠回 2D 图像特征
out = out.transpose(1, 2).view(B, C, H, W)
return out
# =====================================================================
# 模块三:核心中枢 —— Deformable Mamba Fusion (DMF) Block
# 对应论文:图3中的核心模块,将“抗畸变”与“全局感知”合并,并无损放大
# =====================================================================
class DeformableMambaFusionBlock(nn.Module):
def __init__(self, dim, if_up_sample=True):
super().__init__()
self.if_up_sample = if_up_sample
# 支路 1:走深层特征,负责大感受野和全局理解
self.global_branch = Mamba2D_Wrapper(dim=dim)
# 支路 2:走浅层特征,负责应对物体形变和广角畸变
self.local_branch = DFT(in_chans=dim, out_chans=dim)
# 融合层:用于拼接后的特征降维和混合
self.fusion_conv = nn.Conv2d(dim * 2, dim * 2, kernel_size=1, stride=1)
self.norm1 = nn.BatchNorm2d(dim * 2)
self.norm2 = nn.BatchNorm2d(dim * 2)
# 上采样层:使用 PixelShuffle 代替双线性插值
if self.if_up_sample:
self.upsampling = nn.PixelShuffle(2)
# 洗牌后通道数会除以 4,因此增加一个 MLP 补充特征表达能力
self.channel_mix = nn.Sequential(
nn.Conv2d(dim // 2, dim, 1),
nn.GELU(),
nn.Conv2d(dim, dim // 2, 1)
)
self.norm3 = nn.BatchNorm2d(dim // 2)
def forward(self, x_deep, x_shallow):
"""
x_deep: 来自上一层解码器的深层特征 (对应论文图3的 Dj)
x_shallow: 来自骨干网络的浅层特征 (对应论文图3的 Ei)
"""
# (1) 双路并行特征提取
x_global = self.global_branch(x_deep) # 拿到全局上下文
x_local = self.local_branch(x_shallow) # 拿到抗畸变细节
# (2) 特征拼接与通道融合
x_cat = torch.cat([x_global, x_local], dim=1) # 通道数翻倍: dim -> dim*2
x_fused = self.norm1(x_cat)
x_fused = x_fused + self.norm2(self.fusion_conv(x_fused)) # 残差连接
# (3) 像素洗牌无损放大 (将通道维度的特征平摊到空间维度)
if self.if_up_sample:
x_out = self.upsampling(x_fused) # 分辨率 H,W 翻倍;通道数变为 (dim*2)/4 = dim/2
x_out = x_out + self.channel_mix(self.norm3(x_out))
return x_out
return x_fused
在实际的代码中,作者在计算 DCN 的偏移量(Offset)时,使用了一个极具实战价值的 .clamp() 操作。这是为了限制训练初期预测出的偏移量过大,防止采样点飞出图像边界而导致梯度爆炸,极大地提升了模型训练的稳定性。
四、实验表现:以少胜多的算力优化
通过这种解耦的并行设计,Deformable Mamba Decoder 展现出了优异的算力性价比。在 Stanford2D3D(360° 全景)数据集上,相比于经典的 UperHead 解码器,本方法的解码器参数量减少了 72%,计算量(FLOPs)骤降了 97% 。 但在如此严苛的算力压缩下,其最终的分割 mIoU 依然实现了 +2.5% 的绝对提升 。从视觉效果上看,该模型在全景图边缘那些被极度扭曲的小目标(如交通杆、门框)上,表现出了显著的抗畸变识别能力 。
五、评判性分析与未来展望
作为一项应用导向的研究,本文的务实性值得肯定,但也存在一定的探讨空间:
(1) 优势:极强的解耦与复用性 本文最大的贡献在于将抗畸变能力封装成了一个纯粹的解码器插件 。这意味着它可以无缝对接到 ResNet、Swin Transformer 或 VMamba 等任何预训练骨干网络后 。这种设计在算力受限的工业部署(如边缘端自动驾驶设备)中具有巨大的应用潜力。
(2) 局限性:治标不治本的隐患 严格意义上讲,该模型是一个“搭载了 DCN 的 Mamba 解码器”,其 Mamba 的状态空间矩阵并未真正实现空间自适应变形 。此外,抗畸变被后置到解码器,意味着骨干网络(编码器)在提取特征时,依然是在被扭曲的几何关系中进行的 。早期丢失的关键纹理信息,有时仅靠解码器是难以完全挽回的。
(3) 可能的改进 未来的研究或许可以探索在保持线性复杂度的前提下,将基于图像内容预测的局部偏移量,直接融入到 Mamba 选择性扫描机制(Selective Scan)的内部参数(如 BBB 矩阵和 CCC 矩阵)中 ,从而构建出纯粹且原生的 Deformable Mamba 架构。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)