语音降噪风雨六十载(上)——传统信号处理黄金时代
语音降噪是语音信号处理里面的一个经典领域,距离Schroeder在1965年首次提出语音降噪概念,距今已经60多年。在这60多年里,语音降噪从信号处理走向深度学习,对语音质量提升了一次又一次。语音降噪的目标是从麦克风接收的信号提取干净的语音以提升信噪比和语音可懂度,虽然提升语音质量对语音识别不一定有正向提升,但在诸如实时会议系统,耳机,助听器等场景却具有重要的实际意义。
语音降噪既可以在时域进行也可以在频域进行,但是从学术界和工业界这么多年的发展来看,频域语音降噪可以取得更好的效果,因此被更为广泛的研究。今天就来回顾下基于信号处理的降噪算法发展历程,体验下信号处理大师们的灵光一闪。
本文相关代码:https://github.com/ryuk17/noise-xorcist
01 语音降噪建模
对于只有单个麦克风的系统来说,其接收的信号可以表示为:
![]()
其中s(t)是纯净语音信号,h(t)是声源到麦克风的传递函数,v(t)是加性噪声信号。当麦克风在封闭空间内拾取纯净语音时,麦克风信号中会包含直达声、早期混响以及晚期混响声成分。一般认为早期混响有助于提升语音可懂度,晚期混响损害语音质量和可懂度。对公式(1)进行短时傅里叶变换,可以得到其在时频域的表示
![]()
其中Y(k,l),S(k,l),V(k,l)的复数谱,H(k,l)是h(t)的频域表示。如果我们只考虑降噪,即H(k,l)≡1,此时公式(2)变为,
![]()
语音降噪的目的就是从Y(k,l)估计S(k,l),即抑制V(k,l)。其中估计S(k,l)的方法可以分为两类:间接估计和直接估计。大部分方法都是采用间接估计,即估计一个0~1之间的增益G(k,l)施加在Y(k,l)上,获得纯净语音估计的复数谱
![]()
基于人耳对语音相位不敏感这一假设,增益只施加在幅度谱上,然后和带噪的相位谱一起重构语音时域信号。然而,随着深度学习语音增强网络建模能力的不断提升,这一假设也被打破,研究者发现深度学习映射纯净语音的实部和虚部,比映射幅度谱具有更优的性能,其本质是估计纯净语音幅度谱的同时也估计了纯净语音的相位谱。估计S(k,l)的直接方法则是直接估计S(k,l)的幅度谱,或者同时估计S(k,l)的实部和虚部,受限于语音的动态范围较大,直接估计方法还是比较困难的。
02 基于统计信号处理的语音降噪
基于统计信号处理的降噪算法基于这样的假设,语音和噪声是互相独立的,且服从特定的分布,如Gaussian分布,Gamma分布,Laplacian分布等。有些工作认为语音是一个随机信号,但是更多的工作认为语音是一个确定信号。对于传统的降噪算法来说,其流程一般包含以下几个关键步骤:噪声估计、先验信噪比估计、语音存在概率估计、谱增益估计以及相位估计,如下图所示。
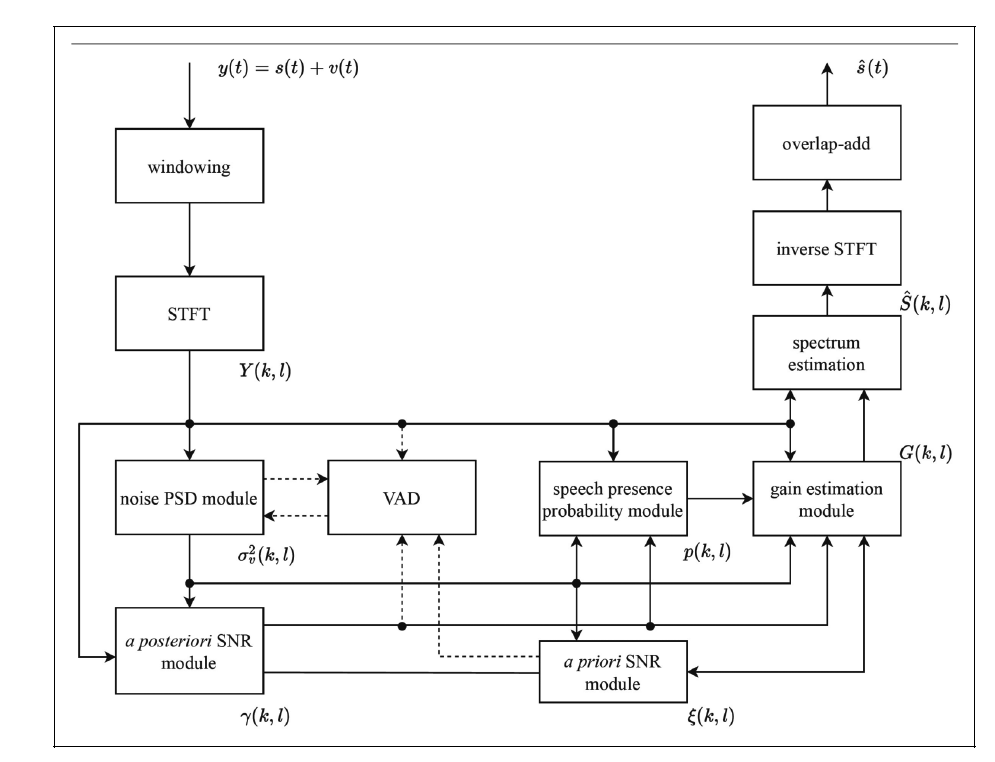
噪声估计
噪声估计是传统语音降噪中的一个关键模块,它对噪声残留和语音失真有着直接的影响。当噪声功率谱密度被低估时,降噪量会随之减小,进而导致语音放大失真。这可以解释为何传统方法虽能在准平稳噪声环境下提升语音质量,使听障人士与正常听力人群均受益,却无法改善非平稳噪声中正常听力人群的语音可懂度。反之,当噪声功率谱密度被高估时,尽管降噪量会增加,但会导致语音衰减失真。噪声估计的重要性不言而喻,因此大量的工作在研究如何对噪声进行精确的估计。
在早期的工作中,噪声功率谱密度是基于VAD实现的,将语音帧分为语音存在和语音缺失两类,然后噪声功率谱密度仅在语音不存在帧中进行更新,并在后续的语音存在帧中保持该估计值不变,即
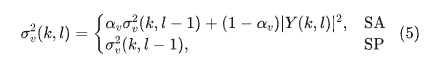
其中αv是平滑因子。显而易见,上述的方法有比较大的缺点,首先是噪声估计的结果严重依赖于VAD的准确性,而当信噪比比较低或者非稳态噪声的情况下,VAD的结果很难保证准确性;其次由于在被判定为语音存在的帧中不对噪声功率谱密度进行更新,因此语音在时频域内的稀疏性并未得到充分利用。为了避免使用VAD导致错误噪声功率谱密度,可以引入一个很直观的假设:“语音 + 噪声” 时频bin的功率谱密度始终大于或等于对应时频单元的噪声功率谱密度。显然,在加性噪声的条件下,上述假设必然成立。此时,不依赖于VAD的递归噪声估计算法可以表示为:
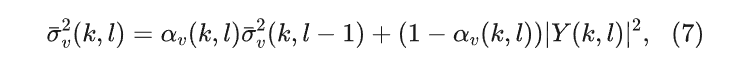 其中
其中
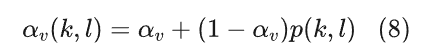
最终的噪声功率谱为
![]()
公式(9)中Ov是偏置补偿因子。后来基于噪声短时傅里叶变换系数模平方的最小均方误差准则,对噪声功率谱密度进行估计的方法取得了最优的效果,由于其低复杂度、低时延的特点,该基于 MMSE 的方法已成为传统单声道语音增强中最常用的方法之一。尽管已有众多研究者尝试对其进行改进,但是很难再前进一步了,因为传统算法需要持续多帧对噪声进行跟踪,然后非稳态噪声变换很快,算法来不及跟踪,噪声可能已经结束了。至此,传统的噪声估计算法落幕,基于数据驱动的时代来临了。
先验信噪比估计
尽管使用极大似然估计计算先验信噪比在1979年就被提出了,然而直到1994年Cappé提出决策引导(decision-directed)方法之前,先验信噪比在语音增强中的重要性并未得到充分认识。使用极大似然估计先验信噪比可以表示为
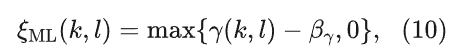
使用判决引导估计先验信噪比,可以表示为
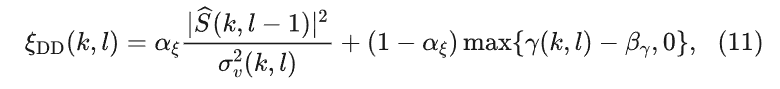 当αξ为0时,决策引导方法退化为极大似然估计算法,决策引导方法可以视为是极大似然估计方法的一个递归平滑版本,因此可以写为
当αξ为0时,决策引导方法退化为极大似然估计算法,决策引导方法可以视为是极大似然估计方法的一个递归平滑版本,因此可以写为
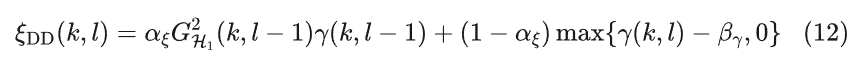
其中G是语音存在时的谱增益,可以通过先验信噪比获得
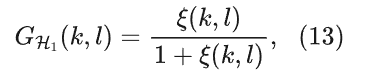
基于决策引导的方法有两个缺点:首先在语音起始段跟踪先验信噪比时需要一帧的延迟,这会导致语音失真;其次其次,在语音结束段跟踪后验信噪比时同样需要一帧的延迟。为了解决上述问题,Plapous等人提出了一个两阶段的先验信噪比方法,如下所示:
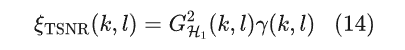
其中
![]()
在这个过程中,首先使用决策引导粗略估计一个先验信噪比,然后这个先验信噪比的值会用于计算维纳滤波器增益去对后验信噪比进行加权。维纳滤波器增益通过最小化估计的纯净语音与真实纯净语音的MSE获得。在噪声段时,ξDD(k,l)接近于0,从而ξTSNR(k,l)也接近于0;对于语音开始帧,由于1帧的延迟,ξDD(k,l)接近于0,然而此时γ(k,l)不小,因此接近了决策引导的延迟问题;类似的,在语音结束帧时,ξDD(k,l)很大,然而γ(k,l)接近于0,使得ξTSNR(k,l)小于ξDD(k,l),故两阶段的先验信噪比方法解决了决策引导的问题。上述的先验信噪比估计方法都只研究了时间上的相关性,而忽略了频率的相关性,因此后续有工作在倒谱域对语音功率的极大似然估计进行选择性平滑,从而提出了一种新颖的先验信噪比估计器,该方法在稳态和非稳态噪声条件下都由于判决引导的方法并且在抑制音乐噪声的同时,残留噪声更加自然。
需要说明的是,上述所有先验信噪比估计器均需要对后验信噪比进行初始估计。若因噪声功率谱密度被低估而导致后验信噪比被高估,通常会进一步造成先验信噪比被高估。解决上述问题有两种方法,一种是提高噪声估计的准确性,另一种则是直接估计先验信噪比。
语音存在概率估计
语音存在概率(Speech Presence Probability, SPP)计算如下所示,其依赖于后验信噪比γ(k,l),先验信噪比ξ(k,l)和先验语音缺失概率q(k,l):
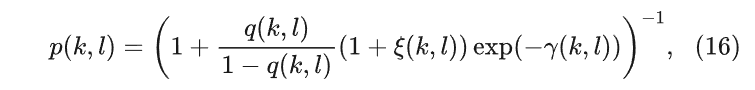
先验语音存在概率在每个T-Fbin上的值均不相同,且会有一个初始值,一般设为0.5。先验语音存在概率对谱增益有着直接的影响,当ξ(k,l)较大时,随着γ(k,l)减小,q(k,l)增大会使谱增益降低。q(k,l)通过如下递归的方式进行计算
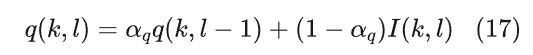
其中αq是平滑因子,I(k,l)当语音不存在是为1,反之为0,它只与后验信噪比相关,当γ(k,l)<γTH时,I(k,l)为1。为了减少语音存在估计的方差,可以对q(k,l)和γ(k,l)进行时间维度上的平滑。后续也有一些改进算法,比如该方法并非仅使用单个时频单元,而是通过平滑后的后验信噪比来确定局部语音存在概率与全局语音存在概率。其中,局部 SPP所使用的帧与频点数量远少于全局 SPP。最终的语音存在概率由局部 SPP 与全局 SPP 相乘得到。ξ(k,l)和q(k,l)依赖于γ(k,l),当γ(k,l)过估计时,ξ(k,l)和q(k,l)也过估计,从而导致SPP增加,因此该方法解耦了SPP与ξ(k,l)和q(k,l),从而导致SPP估计精度上升。
谱增益估计
谱增益估计方法可分为三类:确定性方法、随机方法与随机–确定性混合方法。确定性方法认为语音和噪声是相互独立的且满足
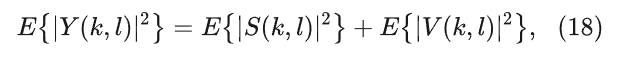
我们认为语音是非稳态的,而噪声是稳态的并且不会快速改变,因此可以得到如下的近似公式
![]()
基于公式(19),语音的幅度谱为
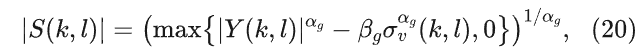
其中βg为减法因子,当为αg=1时,公式(20)退化为谱减法。值得一提的是,如果使用均方根(αg=0.5)保持降噪量的同时可以在倒谱距离等指标上获得更好的性能。因此将公式(20)改写为
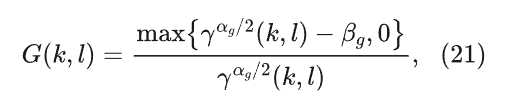
令
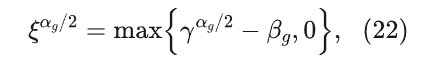
将公式(21)改写成先验信噪比的形式
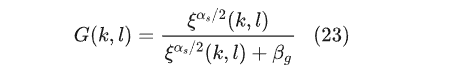
先验信噪比现有的多种估计器能够有效减小纯噪声段后验信噪比的剧烈波动,并在高信噪比含噪段中较好地跟踪后验信噪比,从而缓解音乐噪声问题并减少语音失真。如果使用基于后验信噪比的公式(21)则会有音乐噪声的问题,为了解决这一问题,有如下方法:1)增大βg的同时减少αg;2)增加噪声门限,mask掉音乐噪声;3)在频率轴方向对噪声功率谱密度进行平滑;4)设计符合人类听觉的mask,比如
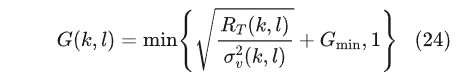
其中RT(k,l)噪声mask的阈值。
随机方法则认为语音和噪声是两个独立的随机分布,比如Gaussion分布,因此可以使用极大似然估计计算语音频谱,几个经典的估计器如下所示。MMSE-STSA,当语音存在时,其谱增益为:
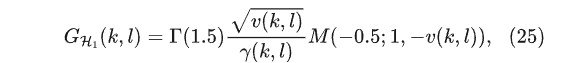
MMSE-LSA,当语音存在时,其谱增益为:
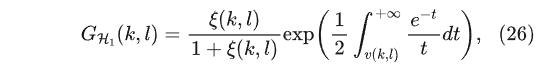
比较MMSE-LSA和MMSE-STSA,前者最小化估计语音与干净语音的对数谱,后者最小化计语音与干净语音的幅度谱。对语音功率谱取对数会显著降低其动态范围,从而放大语音频谱低能量部分的估计误差。由于 GH1(k,l) 是在语音存在条件下推导得到的,因此当 S(k,l)=0 时若存在残留噪声,对数功率谱的估计误差会远大于功率谱本身的估计误差,进而使得MMSE-LSA 估计器对残留噪声具有更强的抑制能力。
对于随机–确定性混合方法认为,语音并不是一个完全随机的过程,可以使用线性预测系数来表示,而噪声则可以视为一个随机过程,因此对于语音和噪声分别建模以计算谱增益,然而虽然在客观指标上优于现有方法,但是其提升有限。非常理想的情况是:谱增益能够根据噪声特性自动选择,这样有望在多种噪声类型下均取得良好性能。然而,在不使用监督式方法的前提下,这即便不是完全不可能,也是一项极其困难的任务。
相位估计
相位估计一开始被认为对于降噪不是必须的,因此在很长一段时间里,相位估计并不受重视。此外,从带噪语音中估计干净语音的相位是十分困难的,特别是在低信噪比的情况下,这也是相位估计被忽视的另一个原因。直到2008年Wojcicki提出了一种修改带噪语音相位谱的方法,其在PESQ上优于谱减法和MMSE-STAT。后续有工作提出当谱幅度与相位估计采用不匹配的分析窗时,使用纯净语音相位谱能够显著提升语音质量。在这类方法中,动态范围较低的窗函数(如多尔夫 - 切比雪夫窗)被用于相位估计,而汉宁窗 / 哈明窗通常用于谱幅度估计。当将相位谱补偿方法与 MMSE-STSA 估计器结合实现时,相比仅修正幅度谱或仅修正相位谱,能够获得更优的性能。后续有一些在相位谱估计山的工作,但是随着深度学习时代的来临,有了更直接的方法对纯净语音的复数谱进行估计。
03 传统语音降噪总结
在传统语音降噪方法中,都基于以下四个假设
-
假设一、语音和噪声是统计独立的;
-
假设二、噪声相比于语音更加平稳;
-
假设三、时频点是统计独立的;
-
假设四、人耳对语音相位不敏感;
第一个假设是合理的,然而其他三个假设在某些条件下并不真正成立。
假设二是传统语音降噪中噪声估计模块的基础,然而实际场景中非稳态噪声也是普遍存在的。
对于假设三来说,语音和噪声频点之间必然存在相关性,这就导致基于统计模型的方法比不可能完全成立,这也限制了传统降噪算法的性能。
对于最后一个假设,相位在时间和频域上完全随机的特性使其很难进行估计,这也是传统算法大都没有考虑修改相位的原因。
在语音合成中有从幅度谱估计相位谱的方法,但是因为语音降噪的实时性,实用价值有限。传统语音降噪自Schroeder在1965始,到2013年徐博士将DNN引入语音降噪为止,在接近50年的时间里诞生了大量的论文工作,将语音降噪一步步推向实用,给用户带来了更好的体验。然而,深度学习以其强大的非线性能力,达到了传统算法无法比拟的效果,属于传统语音降噪的时代就此落幕。
参考文献:
[1]. Sixty Years of Frequency-Domain Monaural Speech Enhancement: From Traditional to Deep Learning Methods
[2]. https://mp.weixin.qq.com/s/NhtVlhNHxbUoS1AcFNFtJw
[3]. Speech Enhancement Theory and Practice

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)