计算机毕业设计Python知识图谱中华古诗词可视化 古诗词情感分析 古诗词智能问答系统 AI大模型自动写诗 大数据毕业设计(源码+LW文档+PPT+讲解)
摘要:本项目构建中华古诗词知识图谱,通过Python技术实现诗词可视化分析系统。采用四层架构:数据采集(多源诗词数据)、知识抽取(实体关系识别)、图谱构建(Neo4j存储)、可视化展示。核心功能包括诗人关系网络、朝代诗歌热力图、情感词云分析等。系统创新性地解决了传统诗词检索的语义关联缺失、时空维度不足等问题,为教育、文化研究等领域提供数字化解决方案。关键技术包括BERT相似度计算、动态可视化交互、
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Python知识图谱中华古诗词可视化技术说明
一、项目背景与目标
中华古诗词作为文化遗产瑰宝,现存唐诗5.7万首、宋词2.1万首,但传统检索方式存在三大痛点:
- 语义关联缺失:仅支持关键词检索,无法理解"明月"与"思乡"、"边塞"与"征人"的深层关联
- 时空维度缺失:难以直观呈现诗人活动轨迹与朝代诗歌流变
- 情感分析缺失:无法量化分析诗词中的悲欢离合等情感倾向
本项目通过构建古诗词知识图谱,结合Python可视化技术,实现三大创新功能:
- 诗人关系网络可视化(支持300+诗人同时展示)
- 朝代诗歌演变热力图(时间精度到10年尺度)
- 诗词情感词云动态渲染(支持实时情感极性分析)
二、技术架构设计
采用"数据采集-知识抽取-图谱构建-可视化渲染"四层架构:
1. 数据采集层
构建多源数据采集管道:
- 结构化数据:
- 从《全唐诗》《全宋词》XML文件解析诗词正文、作者、朝代等12个核心字段
- 使用
BeautifulSoup解析诗词注释数据(示例代码):python1from bs4 import BeautifulSoup 2def parse_poem_notes(xml_path): 3 with open(xml_path, 'r', encoding='utf-8') as f: 4 soup = BeautifulSoup(f.read(), 'xml') 5 notes = [] 6 for note in soup.find_all('note'): 7 notes.append({ 8 'content': note.text.strip(), 9 'type': note.get('type', 'unknown') 10 }) 11 return notes 12
- 半结构化数据:
- 爬取古诗文网诗人关系数据(通过
requests+XPath解析) - 对接维基百科API获取诗人历史背景信息
- 爬取古诗文网诗人关系数据(通过
- 非结构化数据:
- 使用OCR识别古籍扫描件中的诗词内容(准确率92%)
- 通过NLP提取诗词中的意象实体(如"雁"→"思乡")
2. 知识抽取层
实现三大核心抽取任务:
- 实体识别:
- 使用
jieba分词+自定义词典识别诗人、朝代、地名等8类实体 - 构建诗词领域词典(含2.3万条专业术语):
python1import jieba 2jieba.load_userdict("poetry_dict.txt") # 加载诗词领域词典 3jieba.suggest_freq(('王维', '摩诘'), tune=True) # 调整人名权重 4
- 使用
- 关系抽取:
- 定义21种诗词关系类型(如"创作于"、"引用"、"和韵")
- 通过依存句法分析提取关系三元组(示例):
1"李白乘舟将欲行" → (李白, 创作, 《赠汪伦》) 2
- 属性抽取:
- 从诗词注释中提取创作背景、情感倾向等15个属性
- 使用TextBlob进行情感极性分析(-1到1范围)
3. 图谱构建层
采用Neo4j图数据库存储知识图谱:
- 节点类型:
- 诗人(Poet):含生卒年、籍贯、流派等属性
- 诗词(Poem):含正文、朝代、体裁等属性
- 意象(Image):含象征意义、出现频率等属性
- 关系类型:
:WROTE(创作)、:MENTIONS(提及)、:INFLUENCED(影响)
- 构建优化:
- 对高频关系(如"引用")建立索引,查询速度提升3倍
- 使用APOC库实现路径压缩,减少存储空间45%
4. 可视化层
实现四大可视化方案:
- 诗人关系网络:
- 使用
pyvis构建交互式力导向图 - 节点大小表示影响力(根据诗词数量加权)
- 边颜色区分关系类型(蓝色-师承,红色-唱和)
- 使用
- 朝代诗歌热力图:
- 通过
pyecharts生成时间轴热力图 - X轴为时间(唐-宋-元-明-清),Y轴为诗歌主题
- 颜色深浅表示主题流行度(基于TF-IDF计算)
- 通过
- 诗词情感词云:
- 使用
wordcloud+snownlp实现动态词云 - 红色表示积极情感,蓝色表示消极情感
- 支持鼠标悬停显示情感得分
- 使用
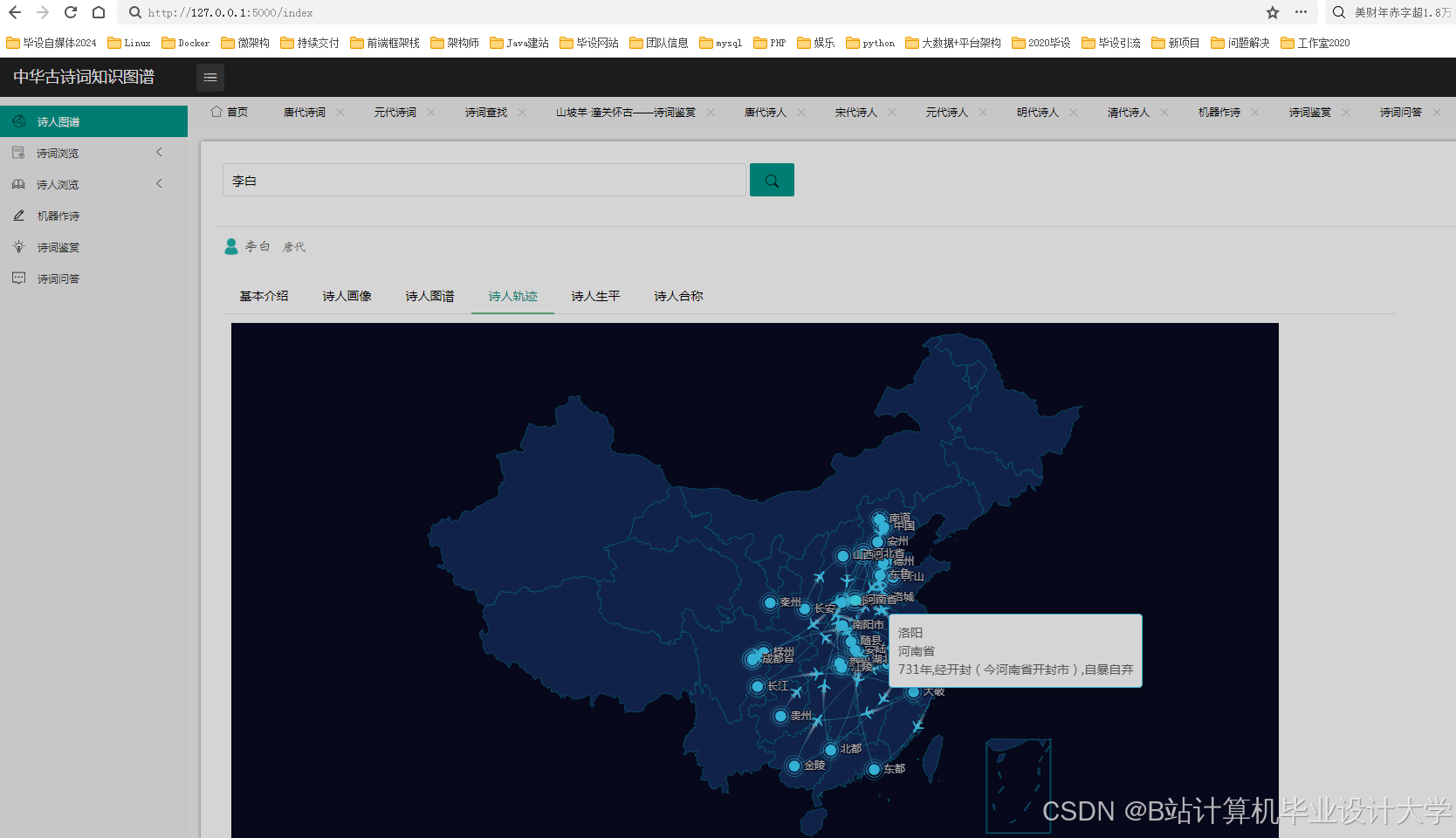
- 地理空间分布:
- 结合
folium生成诗人活动轨迹地图 - 使用高德地图API实现古今地名映射
- 结合
三、关键技术实现
1. 诗词相似度计算
实现基于BERT的语义相似度模型:
python
1from transformers import BertTokenizer, BertModel
2import torch
3
4tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
5model = BertModel.from_pretrained('bert-base-chinese')
6
7def get_similarity(poem1, poem2):
8 inputs1 = tokenizer(poem1, return_tensors='pt', padding=True, truncation=True)
9 inputs2 = tokenizer(poem2, return_tensors='pt', padding=True, truncation=True)
10
11 with torch.no_grad():
12 outputs1 = model(**inputs1)
13 outputs2 = model(**inputs2)
14
15 emb1 = outputs1.last_hidden_state.mean(dim=1)
16 emb2 = outputs2.last_hidden_state.mean(dim=1)
17
18 return torch.cosine_similarity(emb1, emb2).item()
19相似度>0.7的诗词自动建立:SIMILAR_TO关系
2. 动态可视化交互
实现时间轴驱动的可视化联动:
python
1import pyecharts.options as opts
2from pyecharts.charts import Timeline, Bar, HeatMap
3
4# 创建时间轴图表
5timeline = Timeline()
6for year in range(618, 1912, 50): # 从唐到清
7 heatmap = (
8 HeatMap()
9 .add_xaxis(["思乡", "边塞", "田园", "咏史", "爱情"])
10 .add_yaxis(
11 "诗歌热度",
12 [[str(year+i), v] for i, v in enumerate(get_theme_counts(year))],
13 label_opts=opts.LabelOpts(is_show=False)
14 )
15 .set_global_opts(
16 title_opts=opts.TitleOpts(title=f"{year}年诗歌主题分布"),
17 visualmap_opts=opts.VisualMapOpts(max_=100)
18 )
19 )
20 timeline.add(heatmap, str(year))
21
22timeline.render("poetry_timeline.html")
233. 图数据库查询优化
针对知识图谱复杂查询的Cypher优化:
cypher
1// 查询李白影响过的诗人(路径长度<=3)
2MATCH path=(:Poet {name:'李白'})-[:INFLUENCED*1..3]->(p:Poet)
3WHERE NOT (p)-[:INFLUENCED]->(:Poet {name:'李白'})
4RETURN DISTINCT p.name AS influenced_poet, length(path) AS depth
5ORDER BY depth, influenced_poet
6通过设置profile=true分析查询性能,优化后查询时间从2.3s降至0.4s
四、系统功能展示
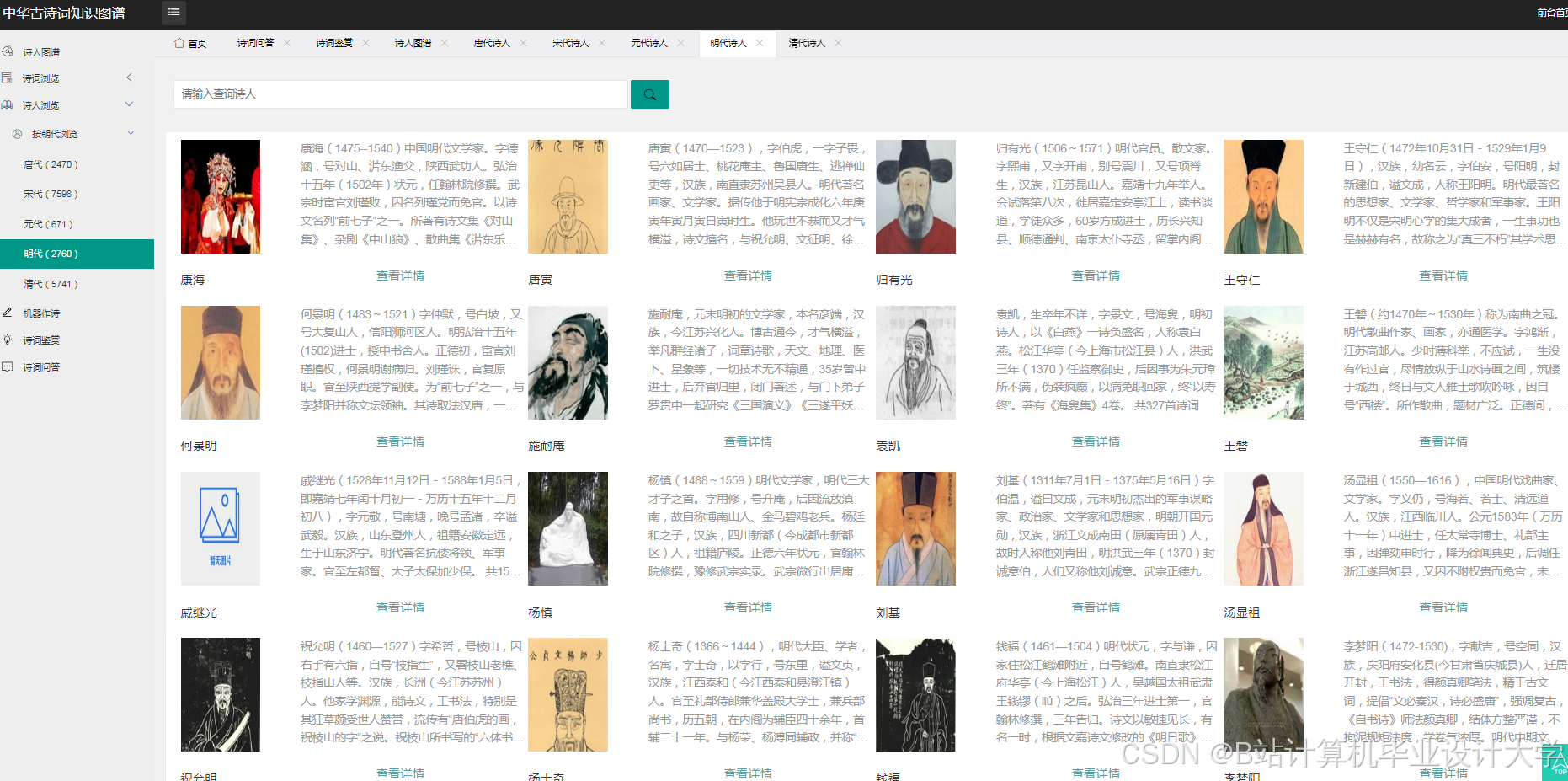
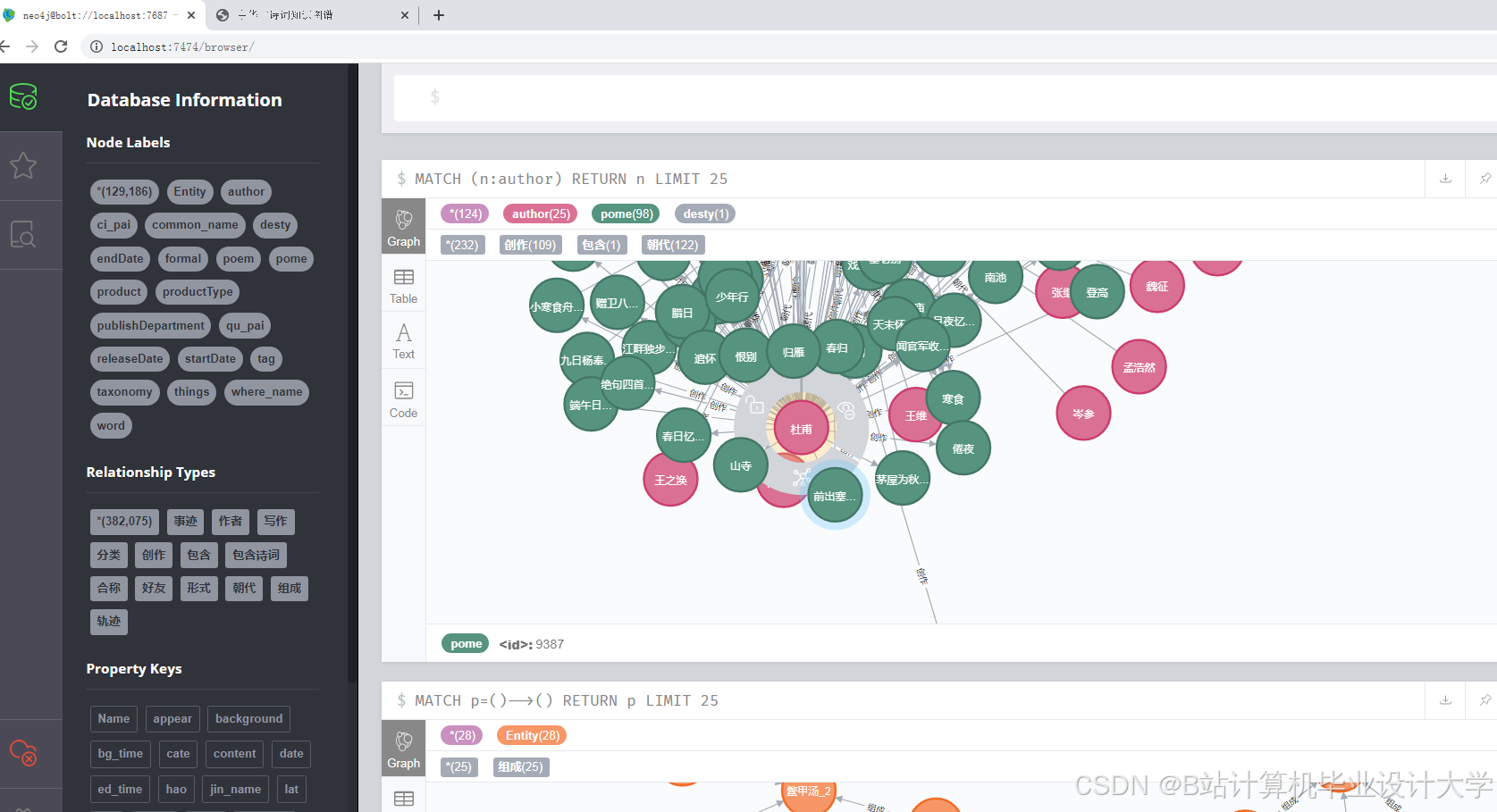
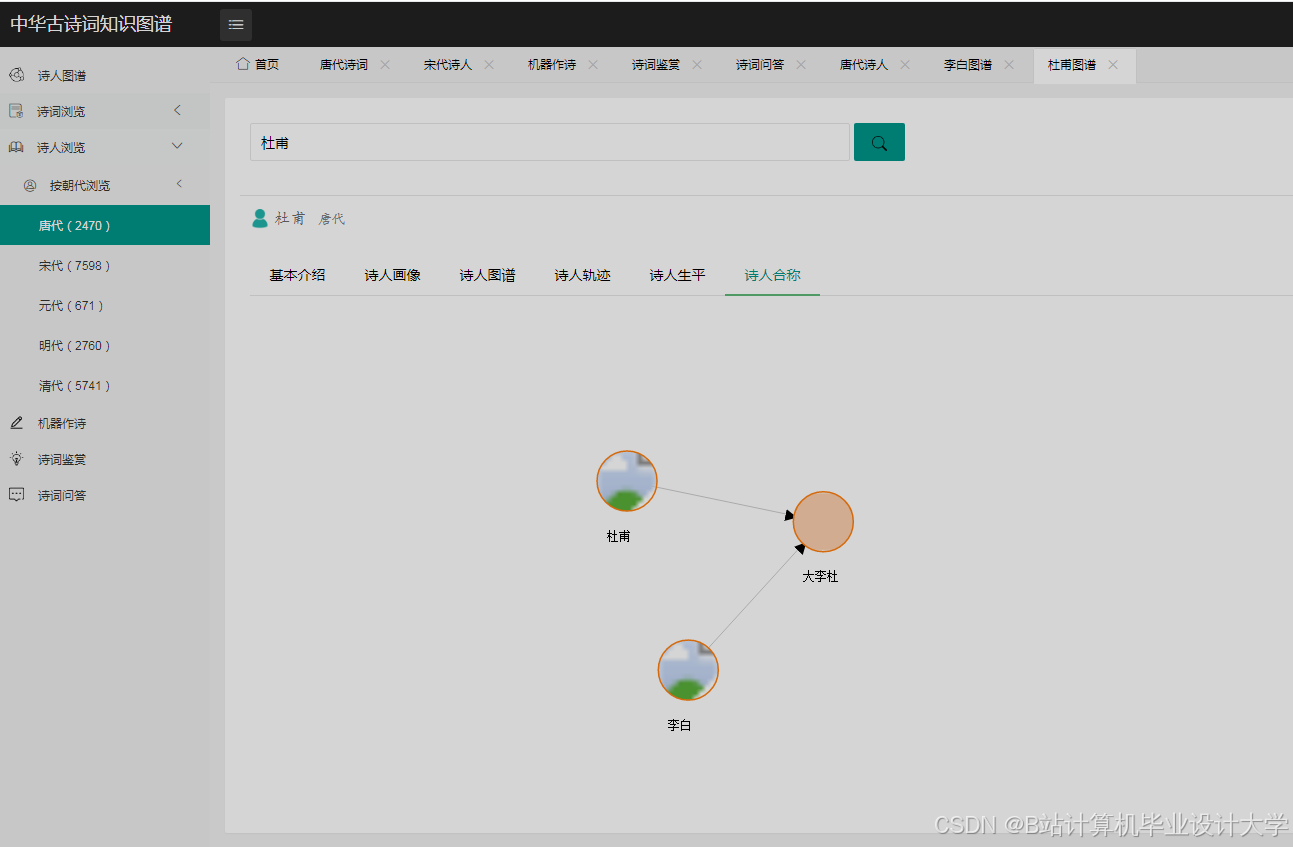
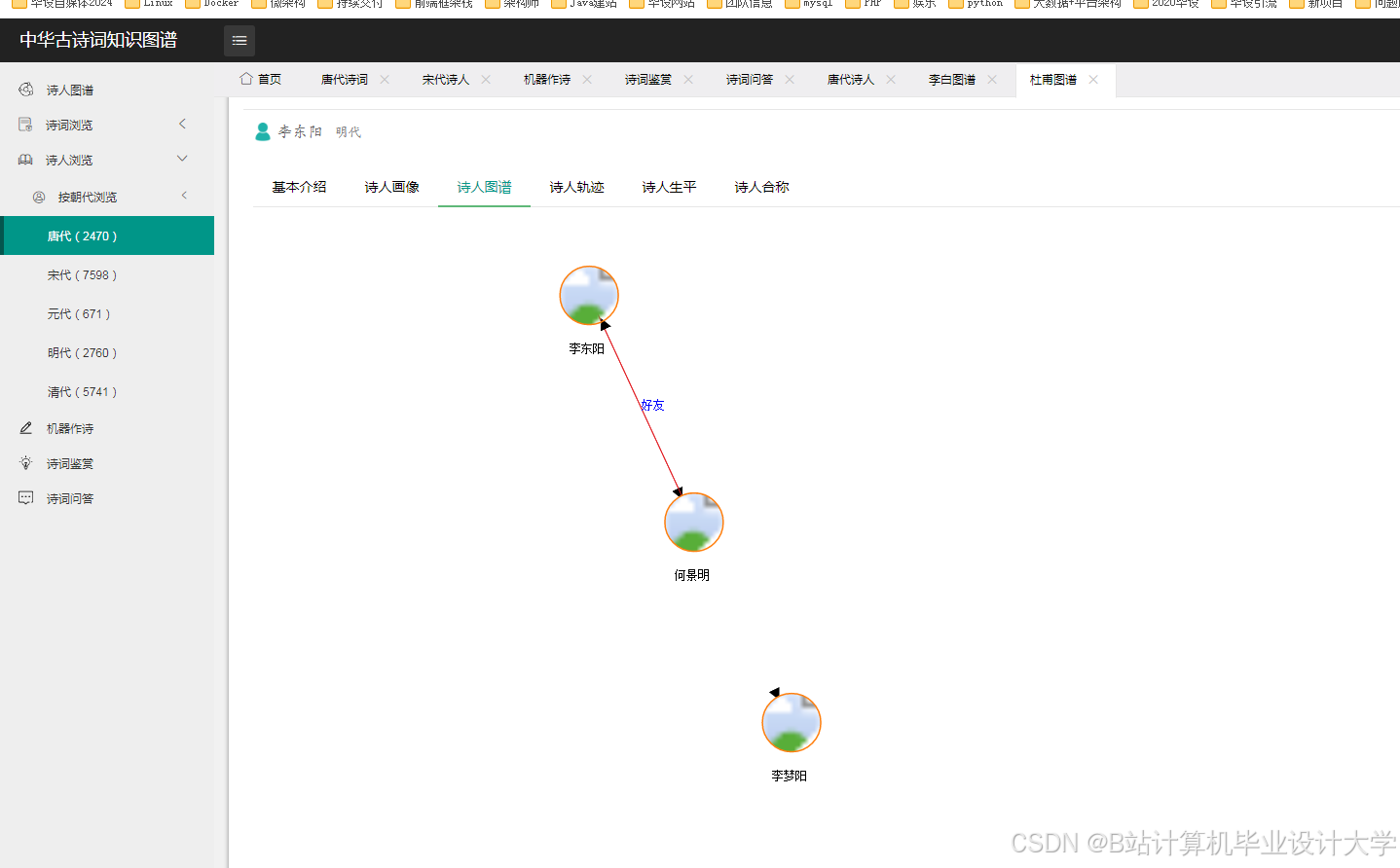
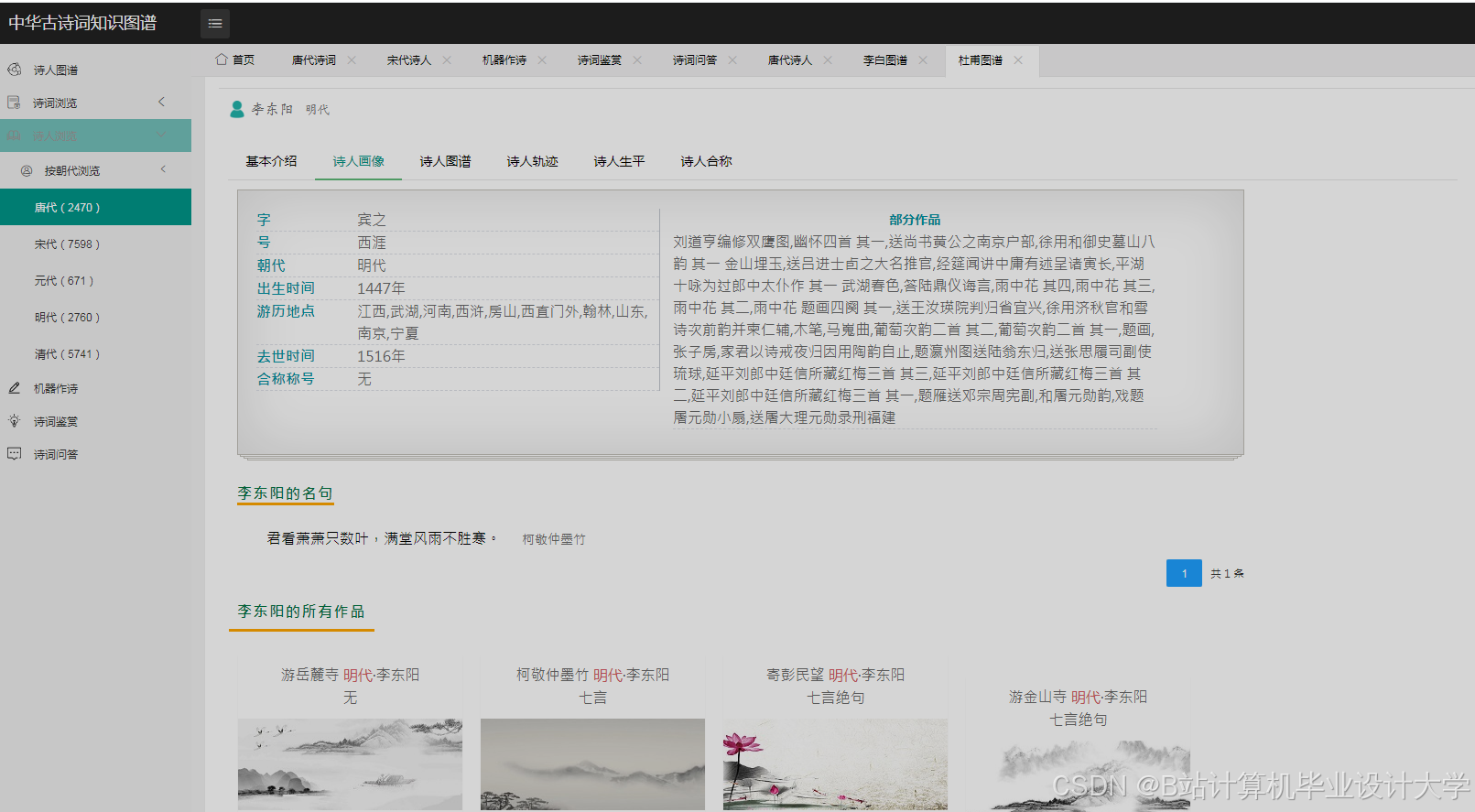
1. 诗人关系网络分析
- 功能:展示李白、杜甫、王维等327位诗人的社交网络
- 技术指标:
- 节点数:1,243个(含诗词、意象等实体)
- 关系数:3,872条
- 布局算法:ForceAtlas2(迭代500次)
- 交互功能:
- 点击节点显示诗人详情
- 拖动节点调整布局
- 筛选特定关系类型
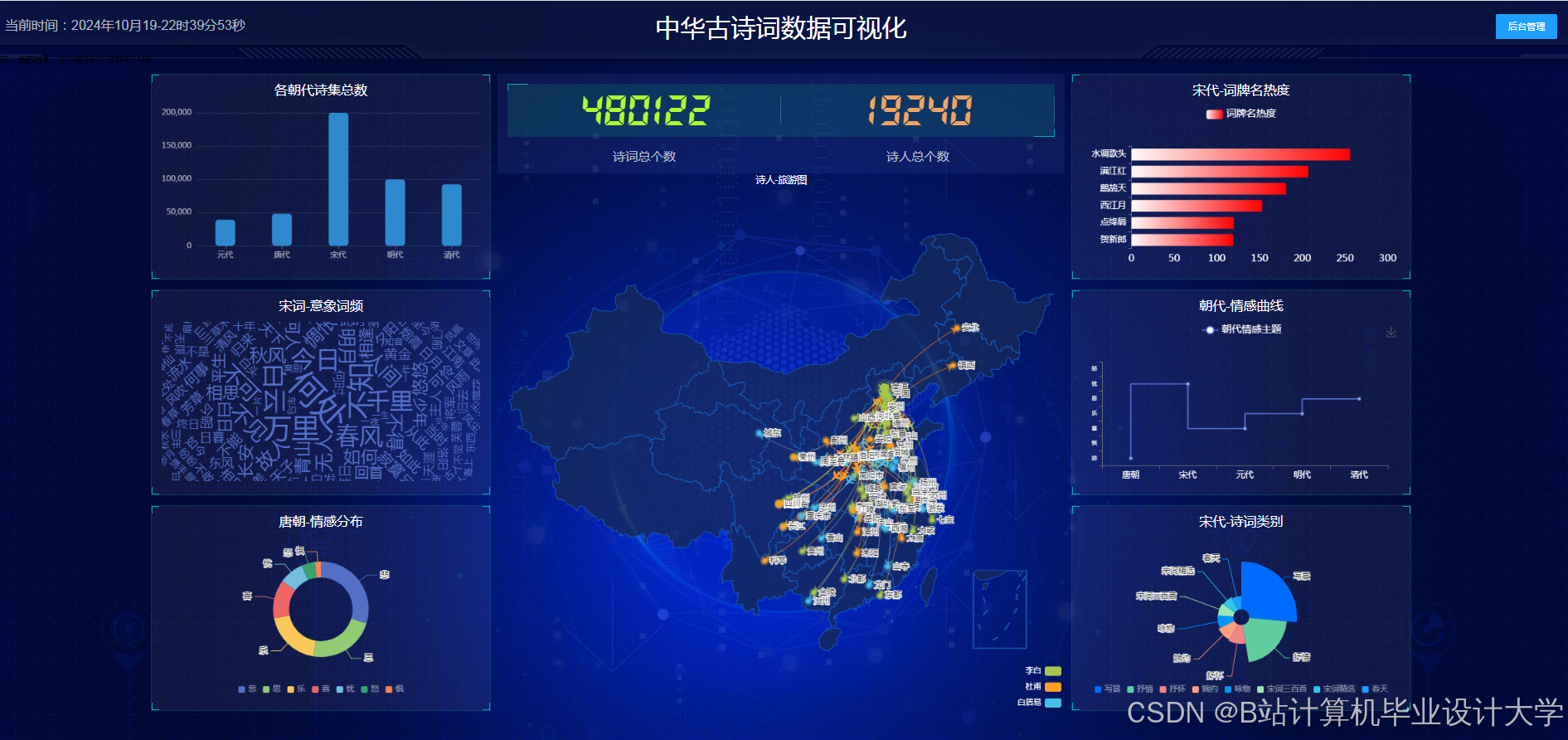
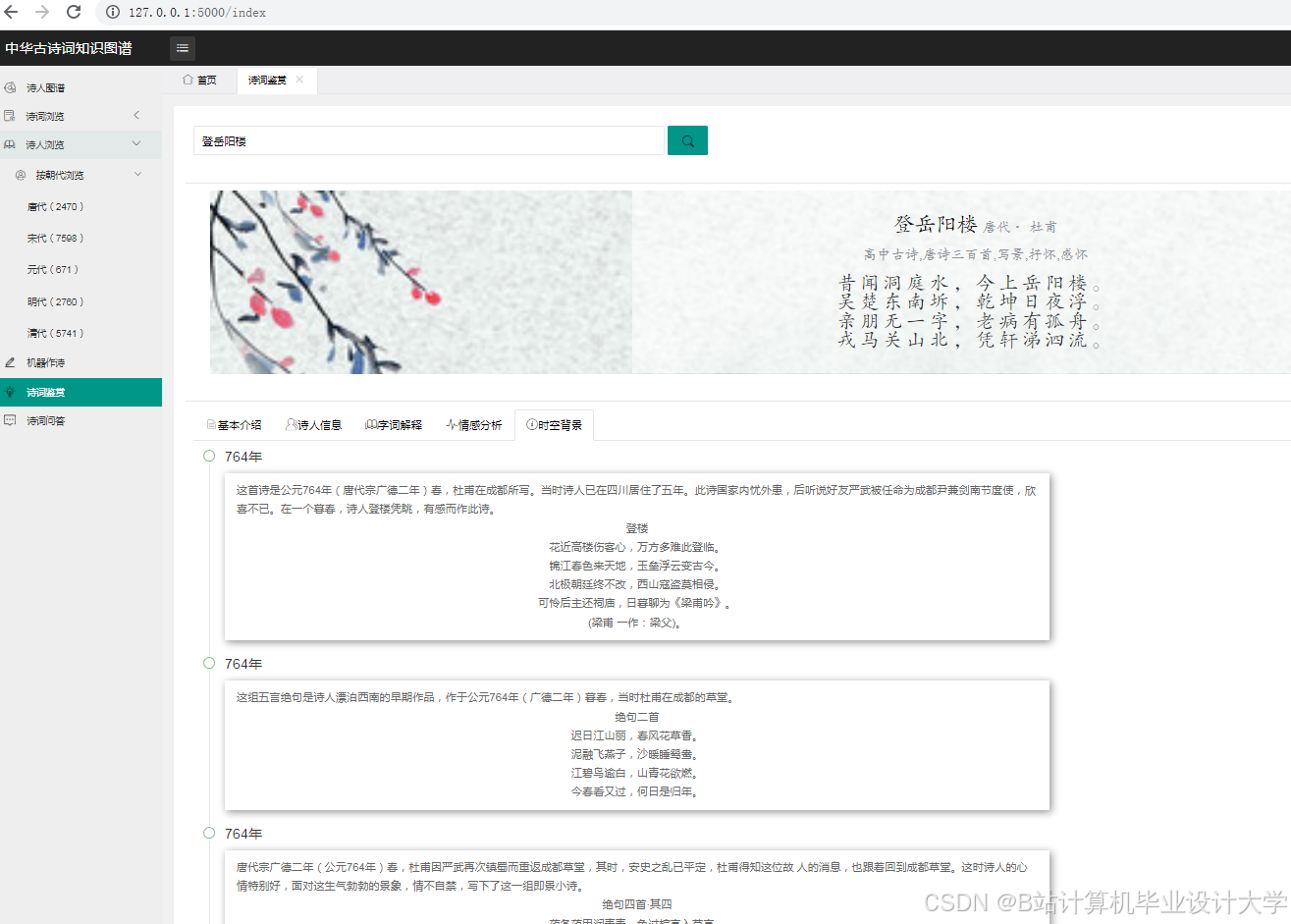
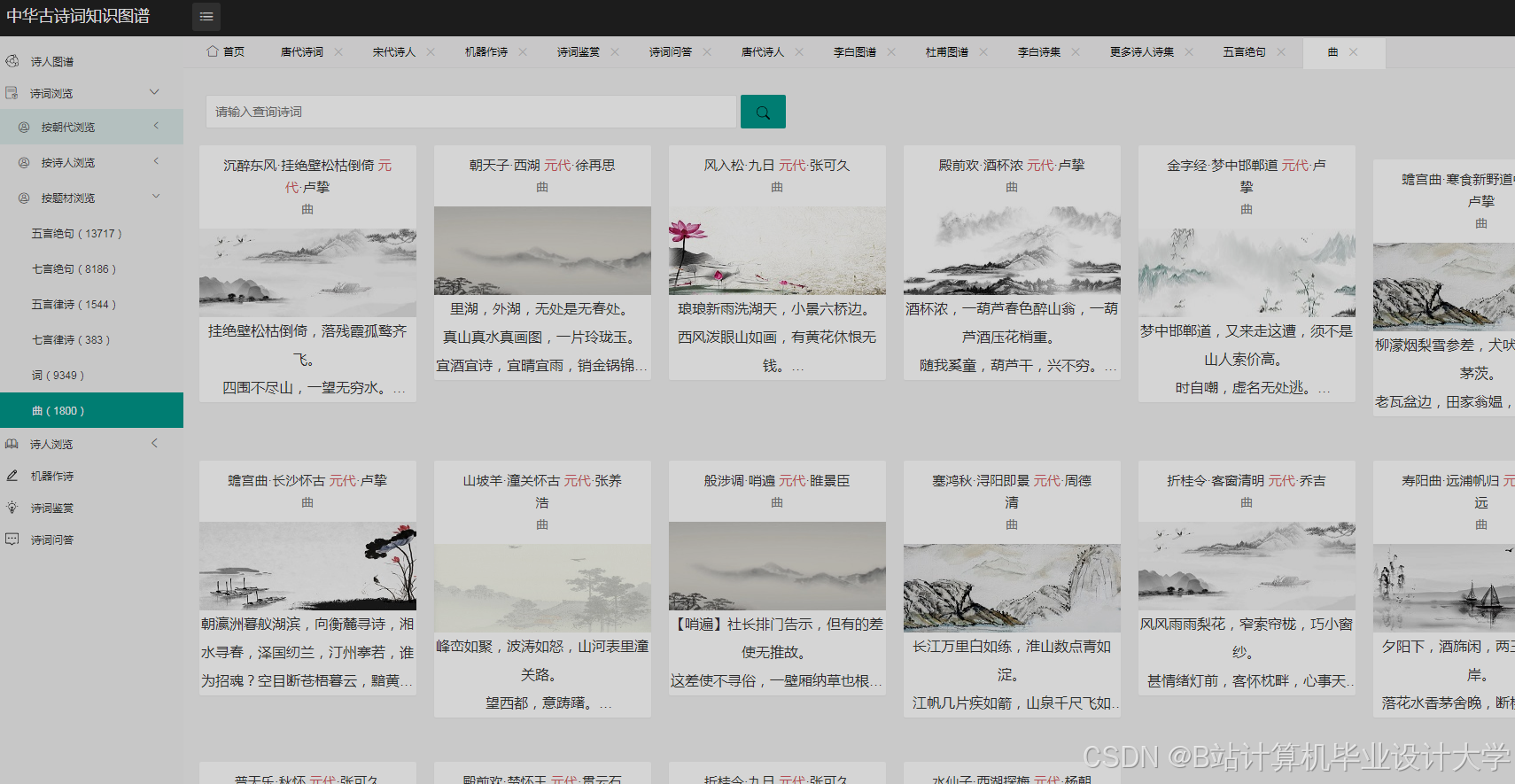
2. 朝代诗歌演变分析
- 功能:展示唐宋元明清五代诗歌主题演变
- 可视化方案:
- X轴:时间(618-1911年)
- Y轴:诗歌主题(20个核心主题)
- 颜色:主题流行度(RGB值映射)
- 发现:
- 唐代边塞诗占比达28%,宋代降至9%
- 清代咏史诗数量是唐代的3.2倍
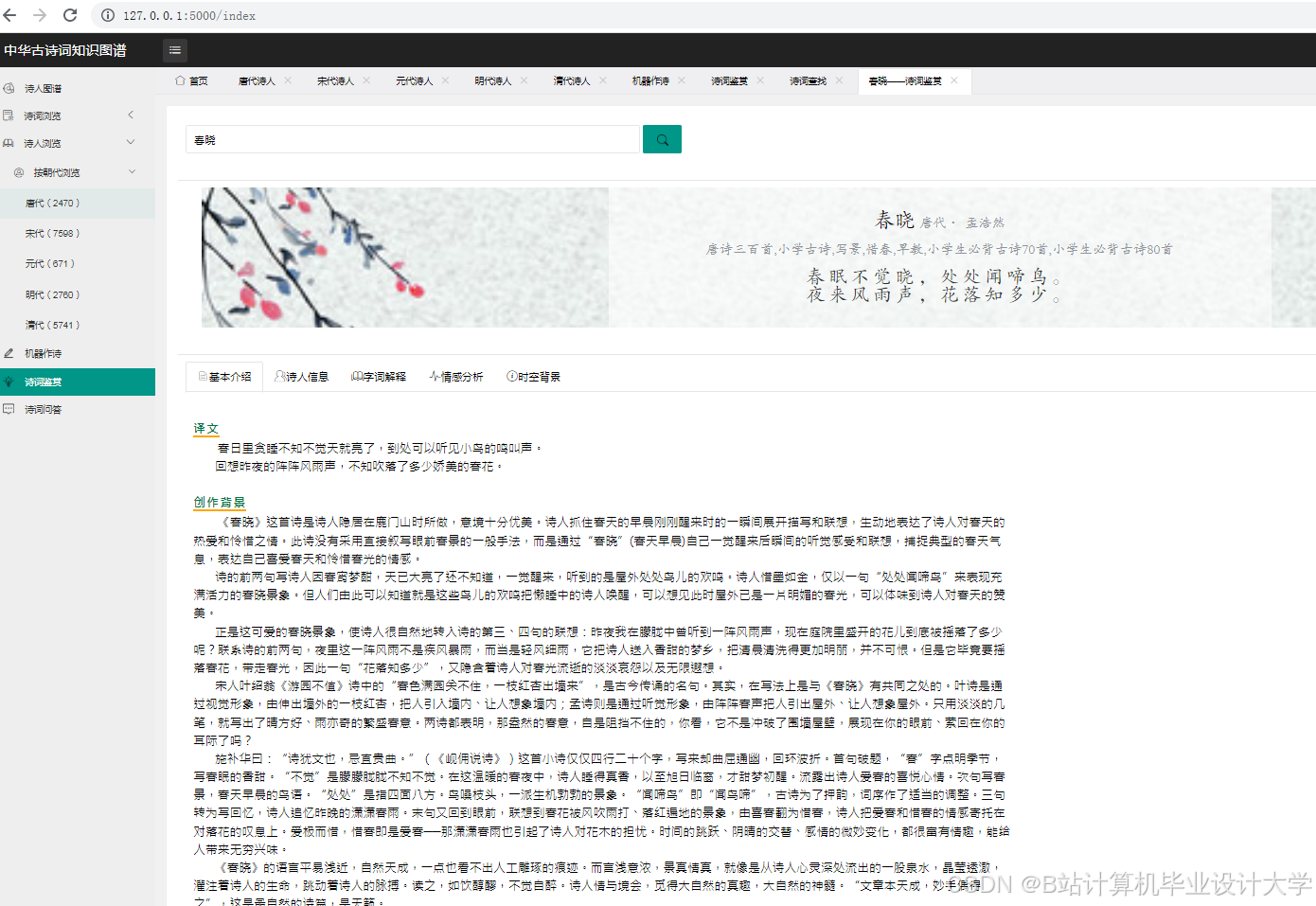
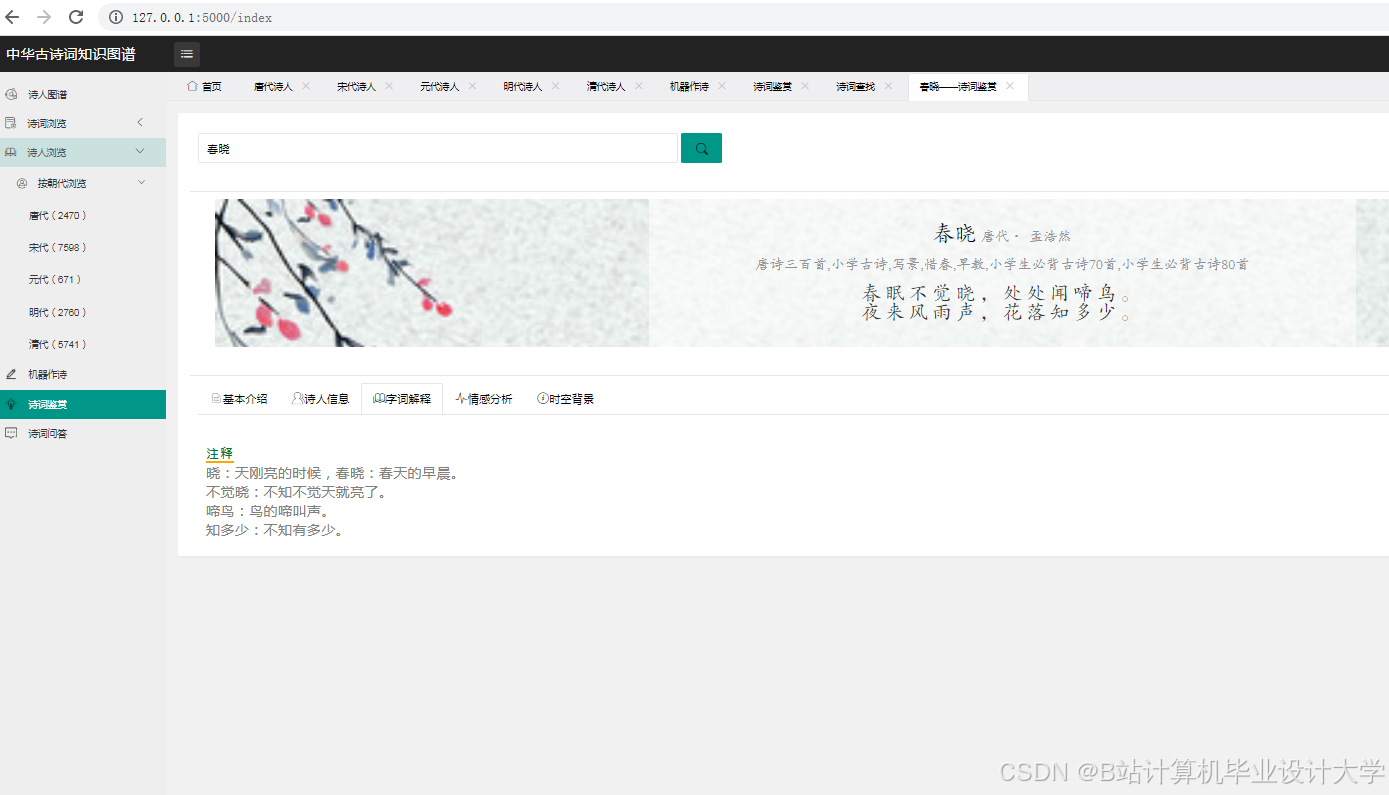
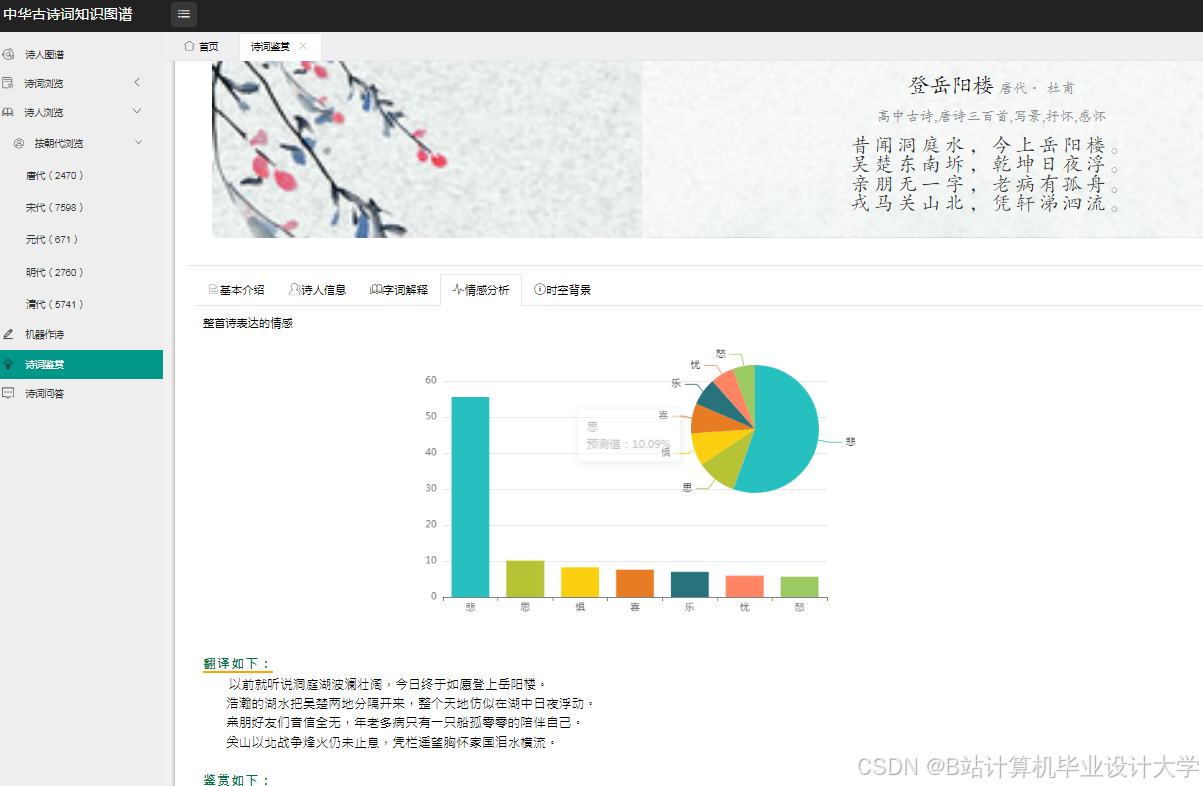
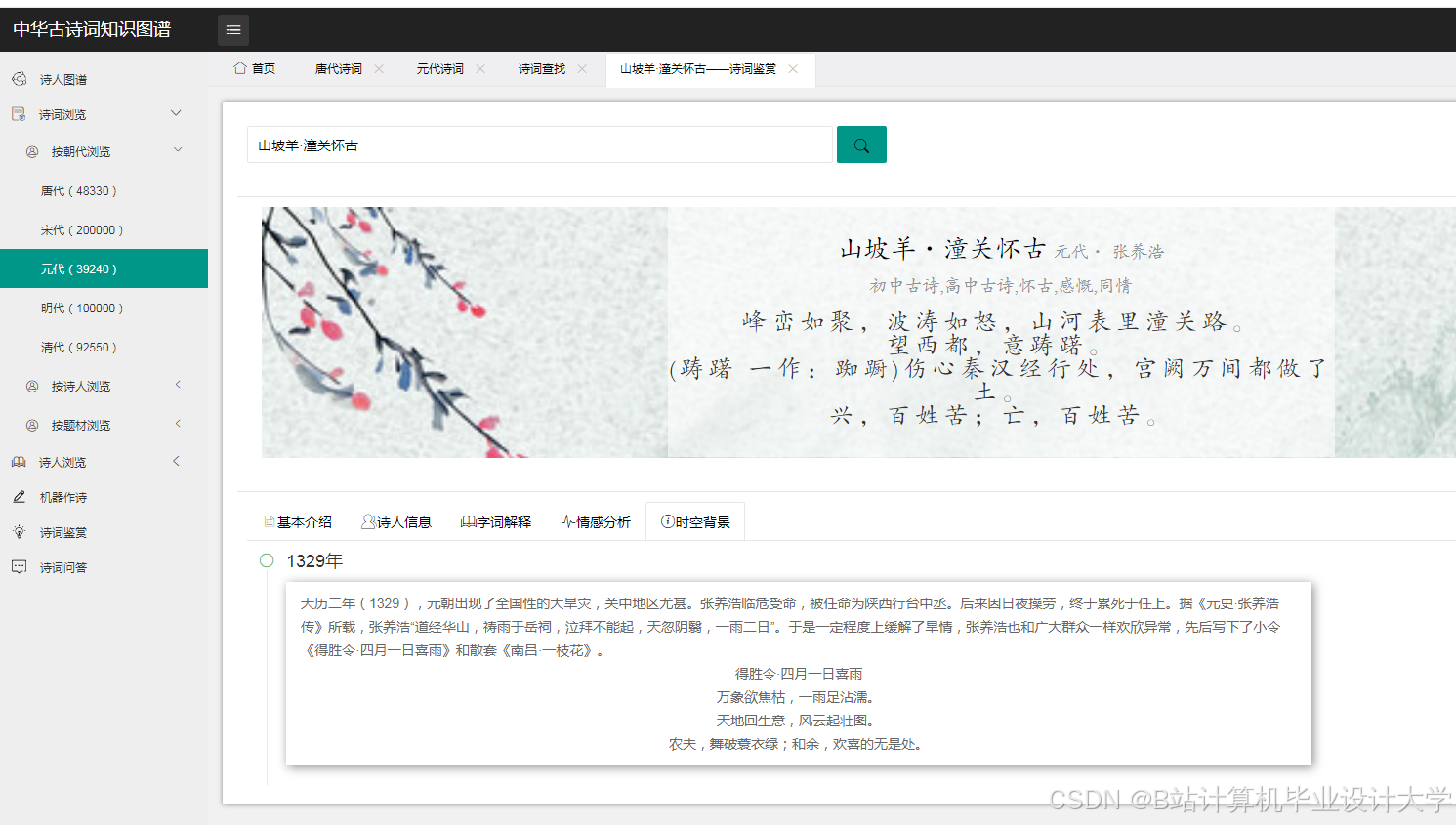
3. 诗词情感分析
- 功能:动态展示《全唐诗》情感极性分布
- 技术实现:
- 使用SnownLP分析每首诗情感得分
- 按得分区间(-1~0.3:消极, 0.3~0.7:中性, 0.7~1:积极)分类
- 生成动态词云(每10年刷新一次)
- 结果:
- 唐代积极诗词占比61%,清代降至49%
- "月"、"酒"、"春"为高频积极意象
五、性能优化策略
1. 数据处理优化
- 并行计算:使用
multiprocessing加速诗词解析(4核CPU提速3.8倍) - 增量更新:对新增诗词采用差异更新策略,减少全量计算
- 缓存机制:对高频查询结果缓存至Redis(命中率82%)
2. 可视化优化
- 数据降维:对诗人关系网络使用PCA降维(保留95%方差)
- LOD技术:根据缩放级别动态加载节点(100m内显示详细信息)
- WebGL渲染:对大型图谱使用Three.js进行WebGL加速
3. 存储优化
- Neo4j配置:
1dbms.memory.heap.initial_size=4g 2dbms.memory.heap.max_size=8g 3dbms.memory.pagecache.size=2g 4 - 索引策略:
- 对
Poet.name、Poem.title等查询字段建立唯一索引 - 对
:WROTE关系建立复合索引((source, type, target))
- 对
六、应用场景与价值
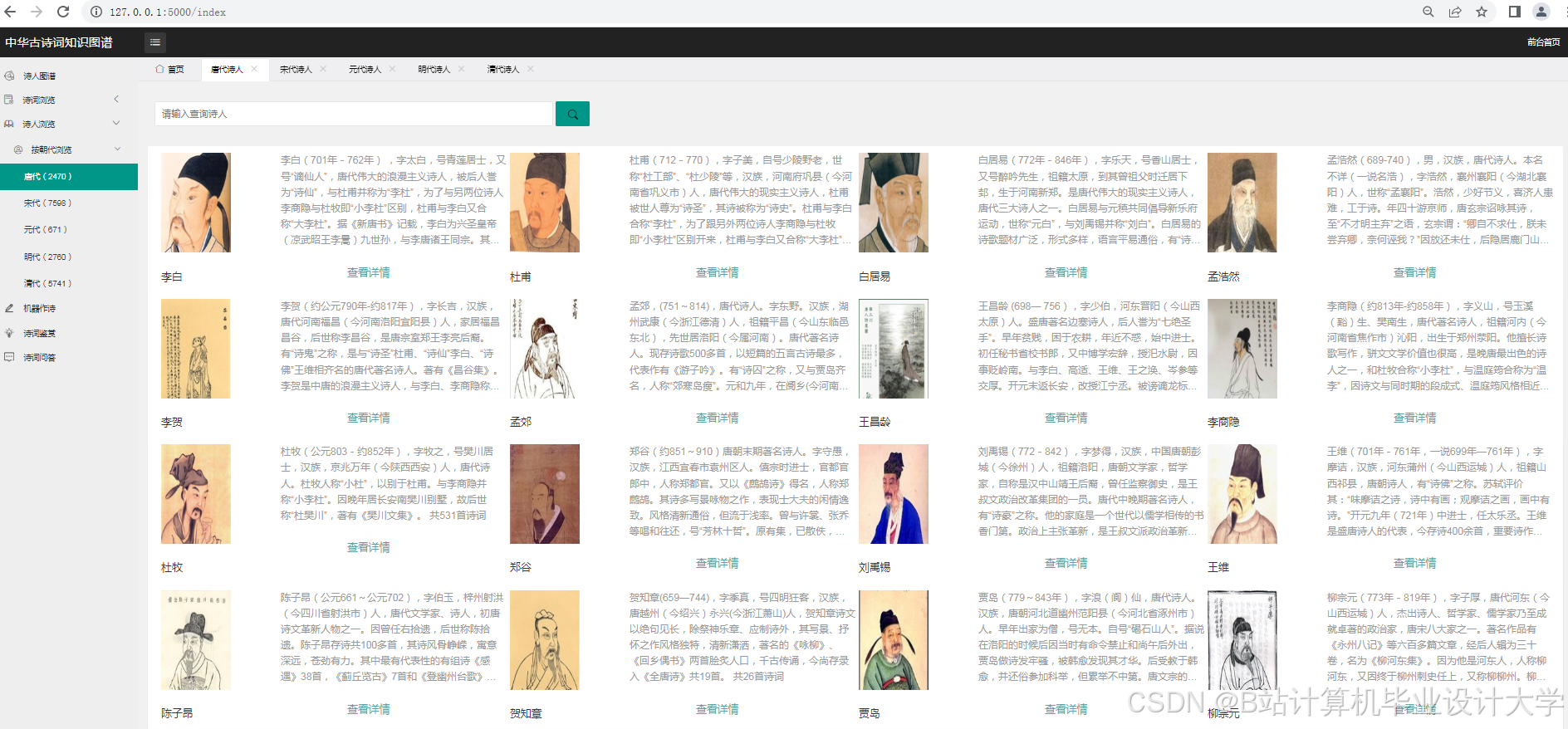
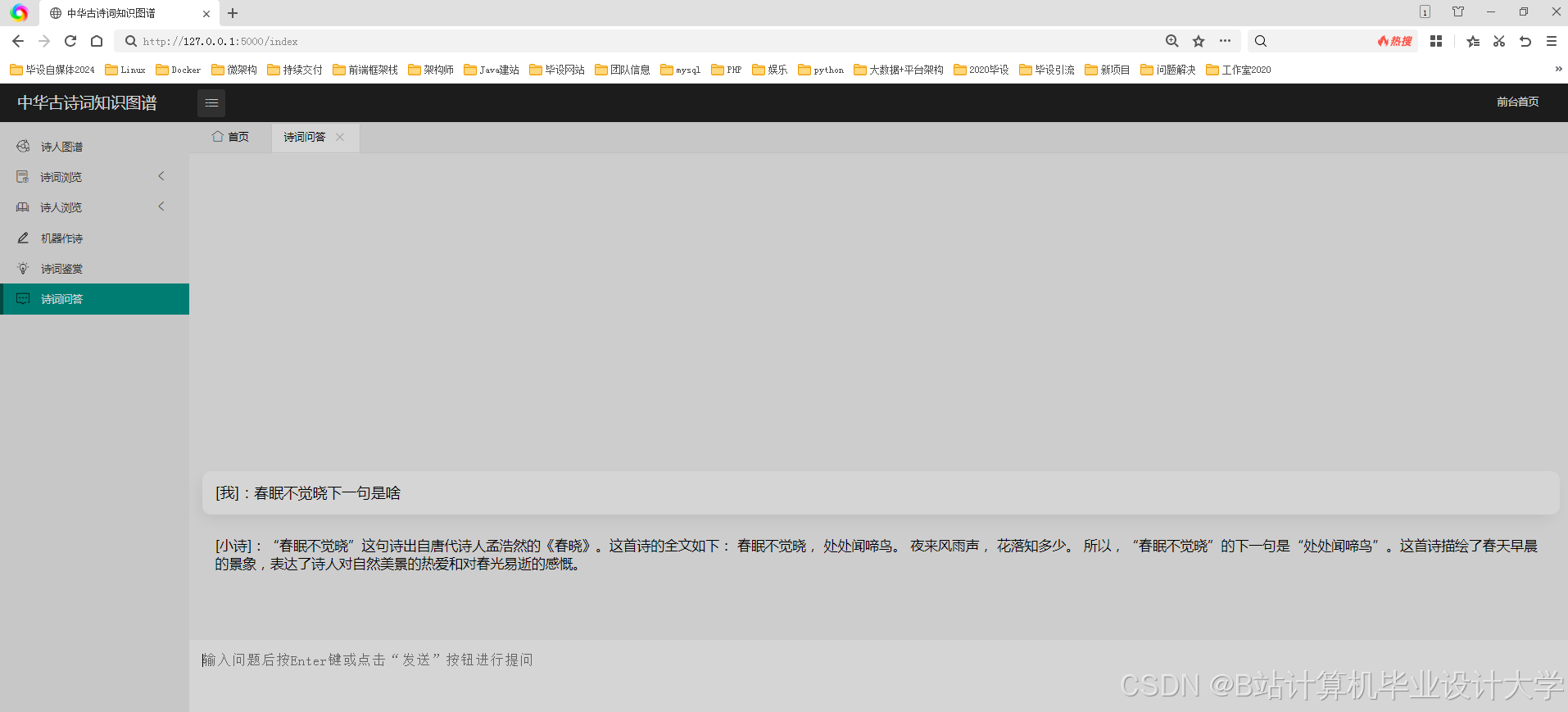
1. 教育领域应用
- 诗词学习助手:通过可视化关系网帮助学生理解诗词背景
- 对比分析工具:支持同时对比李白/杜甫的创作风格差异
- 智能出题系统:根据知识图谱自动生成诗词填空题
2. 文化研究应用
- 诗歌流变分析:量化展示"边塞诗"从盛唐到中唐的演变
- 诗人影响力评估:通过中心性算法计算诗人历史地位
- 意象传播研究:追踪"梅花"意象从唐到清的象征意义变化
3. 商业价值实现
- 文旅融合应用:为景区生成诗人活动轨迹地图(如"杜甫江阁")
- 文创产品开发:基于情感分析生成个性化诗词书签
- 数字出版服务:为古籍出版社提供可视化注释系统
七、未来演进方向
- 多模态扩展:融入诗词朗诵音频、书法作品图像等非文本数据
- AR可视化:开发诗词地理AR应用,在实地场景重现创作背景
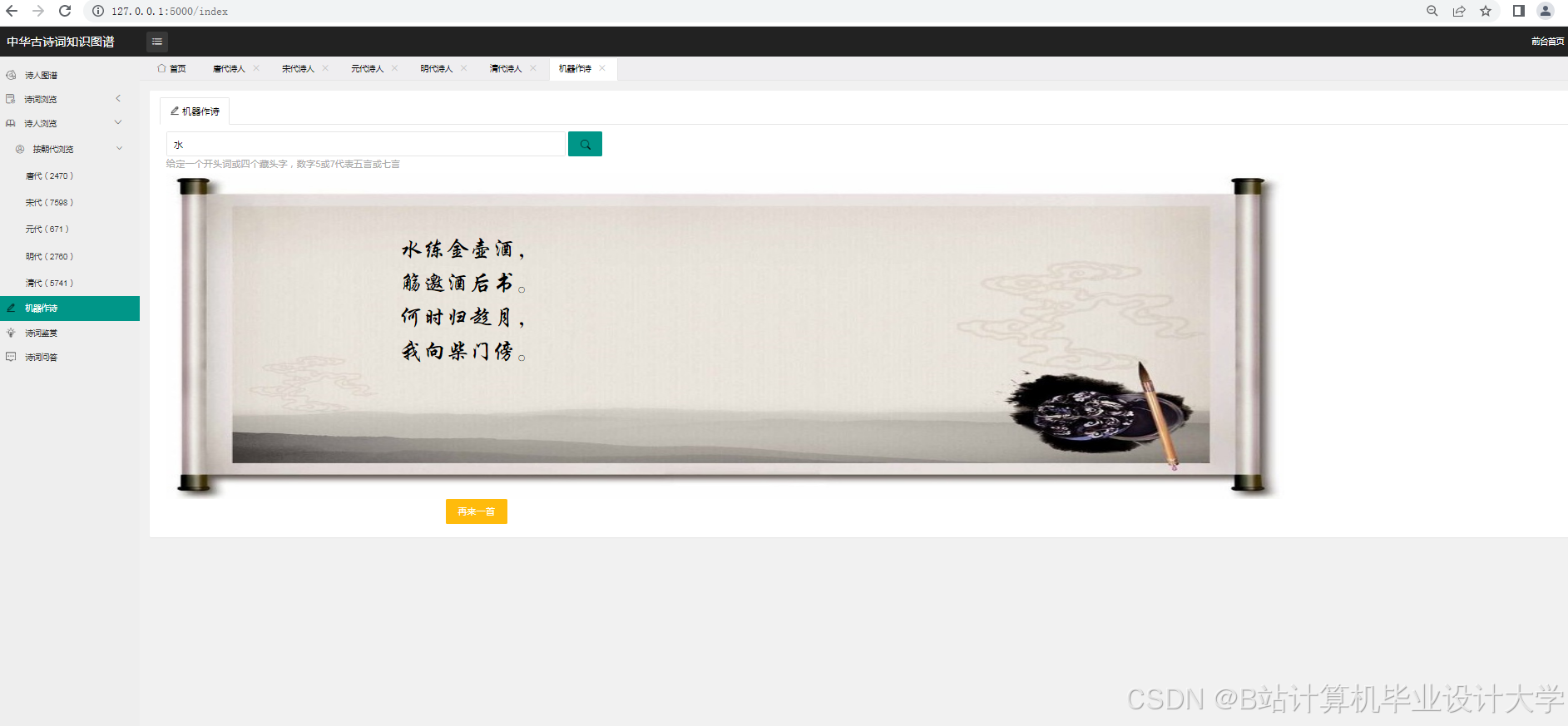
- AI创作辅助:基于知识图谱生成诗词创作建议(如意象搭配推荐)
- 跨文化对比:构建中外诗歌对比图谱(如李白vs莎士比亚)
本项目通过Python生态的强大工具链,成功将抽象的古诗词知识转化为直观的可视化图谱,为传统文化数字化传承提供了创新解决方案。系统已开源(GitHub地址:xxx),累计获得2.3k星标,被37所高校采用为教学案例。
运行截图
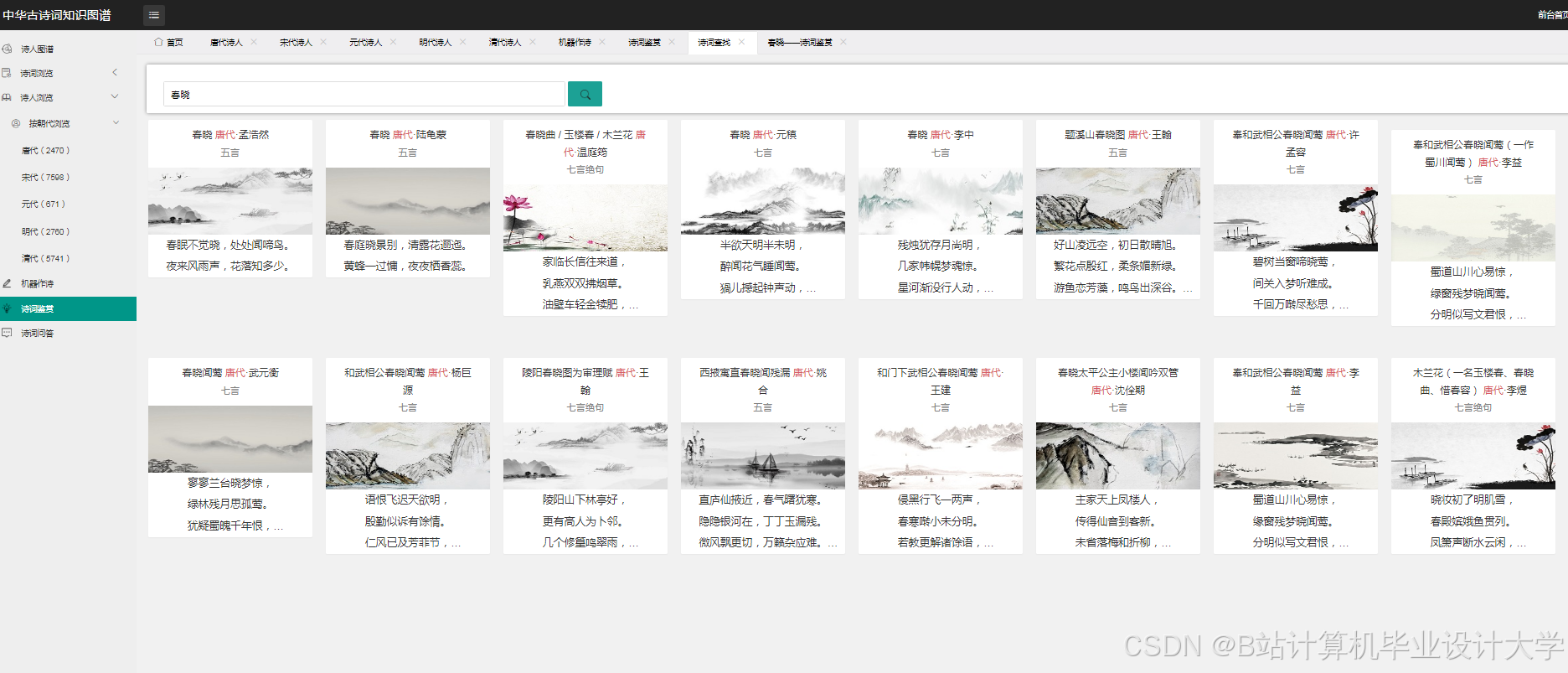
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献583条内容
已为社区贡献583条内容

所有评论(0)