编译安装CUDA版本的opencv-python包
如题。探索了如何从源代码编译安装opencv-python并开启cuda支持。
一、背景介绍
这个问题来自于前几天朋友的求助。由于课题需要,她想在Linux GPU服务器上安装opencv-python这个软件包。虽然官方提供了针对 conda 和 pypi 平台的预编译版本,但是按照官方文档的说法,这些预编译版本是针对CPU架构编译的,并不支持GPU加速(即CUDA)。
检索了一下互联网,也参考了几个AI工具的回答,最终得出的结论是要想启用cuda支持,只能从opencv源代码开始手动编译安装。因此,利用闲暇时间,对这一部分的工作进行了一下探索。
二、一些参考资料和需要准备的东西
下面是一些有用的教程和博客
- 《在 Linux 系统中编译安装 带GPU支持的OpenCV》 - 知乎用户2iUCri的文章 - 知乎
- 《Windows安装CUDA版OpenCV【really有用哦+墙裂推荐!】》 - AI技术库的文章 - 知乎
- 《【OpenCV】 OpenCV 源码编译并实现 CUDA 加速 (Windows)》 - 椒颜皮皮虾的文章 - 博客园
另外,在开始本篇的工作前,需要准备好一台装有GPU的Linux服务器,并安装好驱动程序(GPU driver和CUDA)。这一部分可以参考博客的先前文章 《Ubuntu系统的从头安装、显卡驱动与CUDA安装》 。此外,编译过程还需要cmake以及gcc套件,需要预先准备好。
在安装过程中,需要配置ARCH_BIN 参数(即Compute Capability参数,与显卡型号有关),这个参数需要从 Nvidia官网的 这个页面上获取。此处我测试的机器上安装的GPU是Tesla P40,因此对应的 ARCH_BIN 参数是6.1。
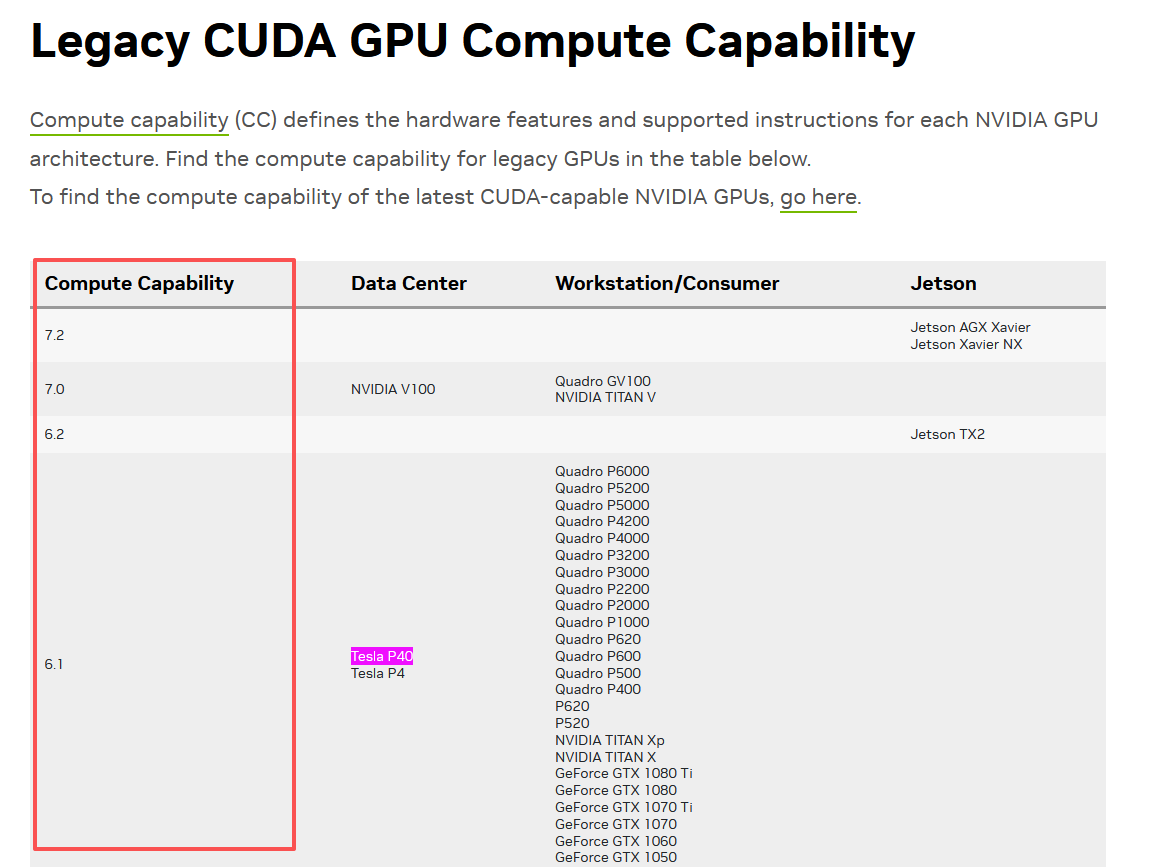
opencv源代码要从GitHub存储库下载,链接如下。其中,opencv_contrib 在opencv主仓库的基础上增加了许多拓展功能,推荐一起安装。
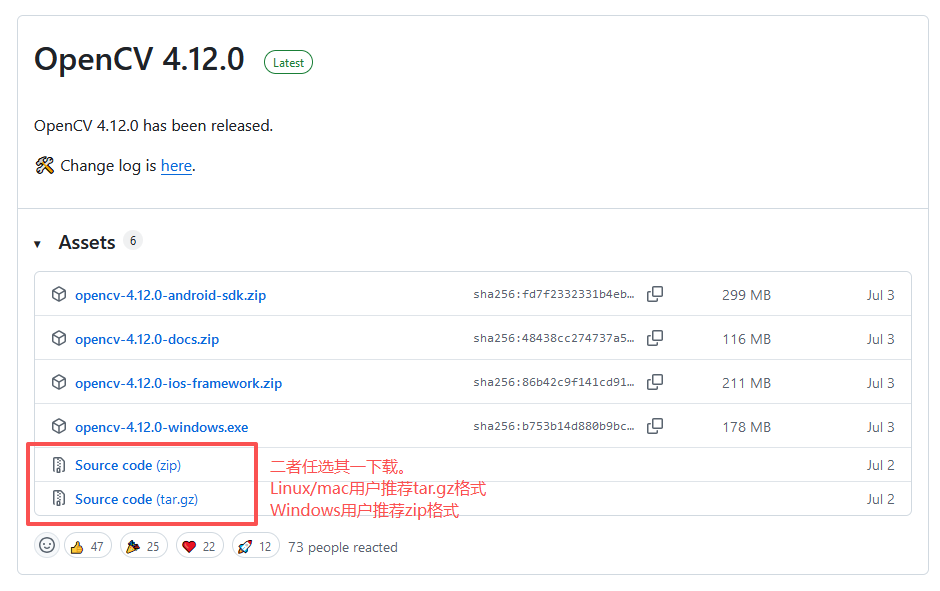
进入上述网站以后,点击页面右侧的release,然后选择最新版本的tag(本文写作时是4.12.0),从此处下载tar.gz或者zip格式的文件,这个文件就是最新版的opencv的源代码包。推荐Windows用户下载zip格式,Linux/mac用户下载tar.gz格式。
三、编译安装:step-by-step的过程
3.1 安装准备:新建文件夹、解压源代码
如题。
下面我们以有root权限的用户身份演示代码。理论上,一些步骤可以在无root权限的情况下成功运行,只需要调整一下环境变量即可。
## 创建工作目录。如果非root,可以在自己的home目录下创建
cd /opt
mkdir opencv_compile
cd opencv_compile
## 下载源代码包并解压
# 如果网络不好,下载失败,可以在本地下载之后手动上传到服务器
wget https://github.com/opencv/opencv/archive/refs/tags/4.12.0.tar.gz -o opencv-4.12.0.tar.gz
wget https://github.com/opencv/opencv_contrib/archive/refs/tags/4.12.0.tar.gz -o opencv_contrib-4.12.0.tar.gz
tar -zxvf opencv-4.12.0.tar.gz
tar -zxvf opencv_contrib-4.12.0.tar.gz
## 创建build目录,后续编译工作将在此处进行
mkdir -p opencv-4.12.0/build
3.2 通过cmake预生成配置文件
这里需要用到cmake工具——这是make的前置步骤,用于生成针对特定系统和硬件配置的makefile——后者是编译步骤(也就是make)时需要用到的配置文件。
可以使用 which cmake 检查系统中是否安装。如果未安装,则需要预先运行 sudo apt install cmake (Ubuntu/Debian)或 sudo yum install cmake (Redhat/CentOS/RockyLinux)
另外,后续的编译步骤需要GCC套件,可以使用 which gcc 和 which g++ 检查是否安装。如果未安装,则需要 sudo apt install gcc g++ 或 sudo yum install gcc g++ 来安装。
接下来, 我们创建一个自动化脚本,用来调用cmake,生成make的配置文件 。这个自动化脚本的文件路径是 /opt/opencv_compile/auto_compile.sh ,因为涉及到一些相对路径,所以文件路径不要放错。
文件内容如下:
#!/bin/bash
cd opencv-4.12.0/build
cmake \
-D CMAKE_C_COMPILER=/usr/bin/gcc \
-D CMAKE_CXX_COMPILER=/usr/bin/g++ \
-D CUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda-12.4 \
-D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=$(python3 -c "import sys; print(sys.prefix)") \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D INSTALL_C_EXAMPLES=OFF \
-D OPENCV_ENABLE_NONFREE=ON \
-D WITH_CUDA=ON \
-D WITH_CUDNN=ON \
-D OPENCV_DNN_CUDA=ON \
-D ENABLE_FAST_MATH=1 \
-D CUDA_FAST_MATH=1 \
-D CUDA_ARCH_BIN=6.1 \
-D WITH_CUBLAS=ON \
-D OPENCV_EXTRA_MODULES_PATH=/opt/opencv_compile/opencv_contrib-4.12.0/modules \
-D OPENCV_PYTHON3_INSTALL_PATH=/opt/minconda3/envs/pytorch_env/lib/python3.12/site-packages \
-D BUILD_EXAMPLES=ON \
-D PYTHON_EXECUTABLE=$(which python3) ..
其中的部分参数的解释:
| 参数 | 说明 |
|---|---|
CMAKE_C_COMPILER |
C语言编译器的位置。可以通过 which gcc 找到 |
CMAKE_CXX_COMPILER |
C++语言编译器的位置。可以通过 which g++ 找到 |
CUDA_TOOLKIT_ROOT_DIR |
CUDA的安装目录。可以通过 which nvcc 找到,注意只保留到cuda这一层目录,不要带子目录 |
CUDA_ARCH_BIN |
Compute Capability参数,与显卡型号有关,获取方法见上一节 |
OPENCV_EXTRA_MODULES_PATH |
opencv_contrib的源码路径 |
OPENCV_PYTHON3_INSTALL_PATH |
当前环境下python3的site-package目录的路径。需要手动检查,一般来说在 conda/envs 的某个子目录下 |
WITH_CUDA 和 WITH_CUDNN |
编译带有CUDA支持的版本 |
上述shell脚本末尾的 .. 不要删,表示使用当前目录的上一级(即 /opt/opencv_compile/opencv-4.12.0 )作为cmake的工作目录。
读者朋友可以根据自身的实际情况调整参数,并保存为 auto_compile.sh 文件。
之后,运行下面的指令进行cmake。
sudo bash ./auto_compile.sh 2>&1 | tee output.log
这个过程中的所有输出会打印到控制台,同时在 /opt/opencv_compile/output.log 文件当中保存一份副本——这份输出日志可以用于后续问题的排查(比如说,交给AI判断cmake是否成功)
整个过程大约会持续几分钟,最终的输出大致如下(只截取最后一部分输出):
3.3 编译与安装
cmake会有几千行输出。可以把最后几百行输出发送给AI,让其帮忙判断是否cmake成功。如果cmake成功,我们就可以正式进入编译的过程了。
下面是编译指令。其中, nproc 是CPU核数——使用 make -j$nproc 可以调用机器上的所有CPU核并行编译,从而加快编译速度。在我们实验室的服务器上,总共有8个核,并行编译大约花了几十分钟。
cd /opt/opencv_compile/opencv-4.12.0/build
# 使用多核编译(根据你的CPU调整线程数)
nproc=`grep -c ^processor /proc/cpuinfo`
sudo make -j$nproc 2>&1 | tee make.output.log
# 编译成功以后,再使用下面的指令安装,否则在python中import cv2会报错
sudo make install
编译过程的所有输出同样会打印到控制台,同时在 /opt/opencv_compile/opencv-4.12.0/build/make.output.log 文件当中保存一份副本——这份输出日志可以用于后续问题的排查(比如说,交给AI判断make是否成功)
make阶段耗时最长,大约几十分钟的样子,最终的输出大致如下:
make install阶段要快很多,几分钟就可以完成,输出大致如下:
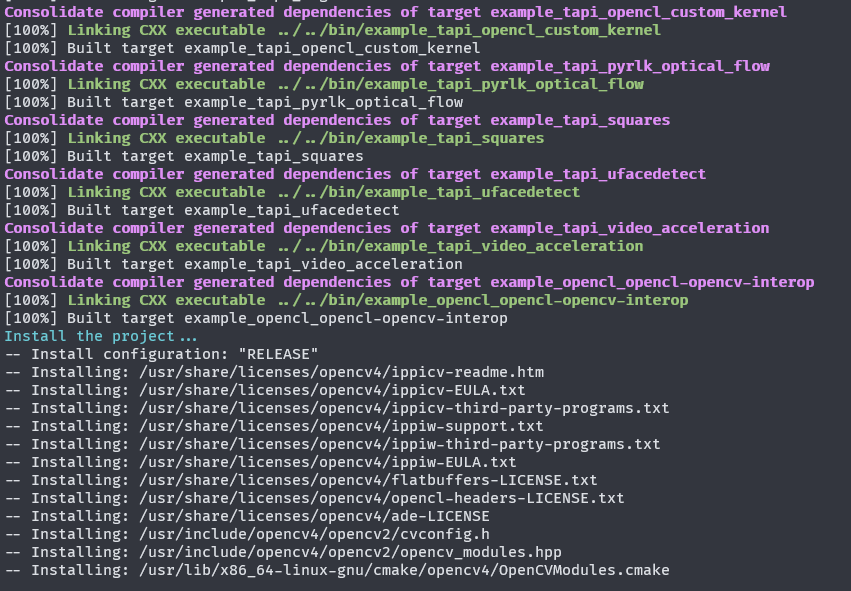
四、在python中检测opencv是否安装成功
运行下面的python代码:
import cv2
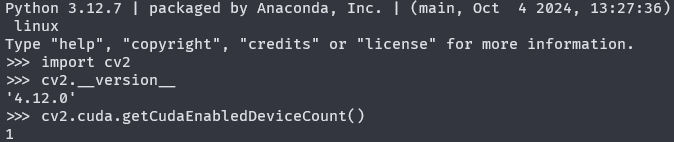
print(cv2.__version__) # 查看opencv的版本号
print(cv2.cuda.getCudaEnabledDeviceCount()) # 查看opencv启用了多少个CUDA设备
对于CPU版本的opencv,其启用的CUDA设备数量为0。只要CUDA设备的数量大于0,就说明opencv启用GPU成功。
实际运行截图:
完结撒花!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)