渐进式文件发布day04
草稿:草稿 是知识帖子的一种临时状态,用于用户在发布内容前进行编辑和完善。对象键:对象键 (Object Key)是在对象存储服务(如阿里云OSS)中用于 唯一标识一个对象 的字符串。每一步都可独立失败和重试,草稿状态是整个流程的"检查点",极大提升了用户体验和系统健壮性。- 作用 :清理可能存在的旧缓存,为后续的数据库更新做准备。- 目的 :确保数据库更新完成后,缓存中的旧数据被彻底清除。1.分
雪花ID:
雪花ID组成:
64bit位(1bit符号位+41bit时间戳+10bit机器id+12bit序列号)
时间戳:从自定义的时间开始,到现在的时间差(单位为毫秒)
机器id:区分机器
序列号:同一毫秒、同一台机器里,自增。
雪花ID vs UUID vs 自增ID
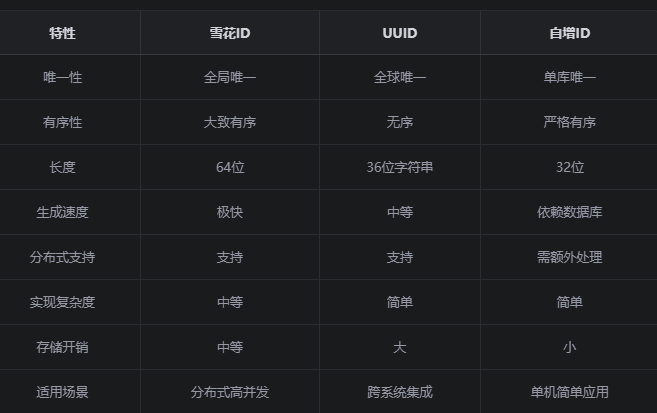
项目为什么选择雪花ID:
1.分布式中的唯一标识,而自增ID只能满足单jvm唯一
2.雪花ID占8字节64位,而UUID占16字节128位,内存开销大
3.帖子需要按时间排序,便于展示feed流
渐进式发布系统:
传统的一次发布(图片,正文.....)局限:
1.单次请求体积大
2.在后端发布占用性能
3.如果其中一个元素上传失败,会导致全部重来
4.一体化提交无法记录中间状态,如果中间有断点则全部重来
渐进式发布:
将内容发布拆解成独立的、可重试的原子步骤:
![]()
每一步都可独立失败和重试,草稿状态是整个流程的"检查点",极大提升了用户体验和系统健壮性。
流程:
1.创建草稿
草稿:草稿 是知识帖子的一种临时状态,用于用户在发布内容前进行编辑和完善。它是一种渐进式内容创作的中间状态。
生成草稿,插入数据库,并返回id
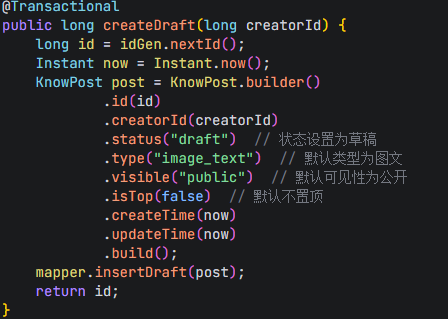
调用nextId()生成雪花id,为什么不用数据库自增id
数据库自增id在数据库分片后不是全局唯一
数据库自增id简单,竞争对手可通过id推测发文量
2.申请直传签名
后端生成预签名传递给前端,是一种临时授权
1.前端传入请求预签名,后端检验id是否有效

2.生成对象键
对象键:对象键 (Object Key)是在对象存储服务(如阿里云OSS)中用于 唯一标识一个对象 的字符串
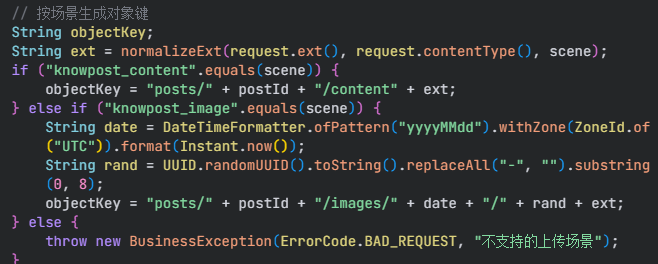
3.调用生成预签名方法,并且设置10分钟有效期

预签名方法:
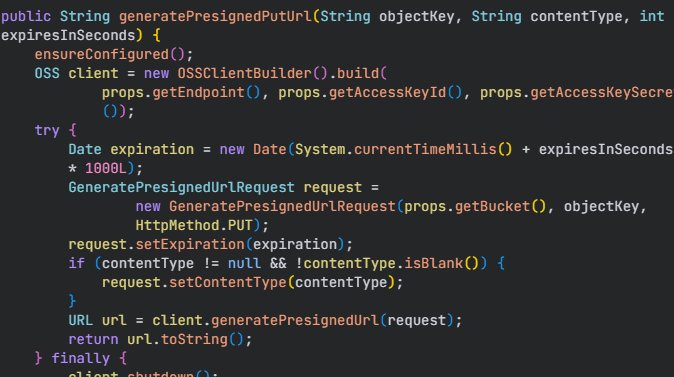
发送给前端
3.客户端直传oss
客户端将获取的的实际文件数据直接传给oss,这一步完全在客户端和 OSS 之间发生,后端不参与数据传输:
客户端在上传成功后需要保存:
-
objectKey(从第二步返回) -
etag(从 OSS 响应 Header 中读取) -
size(文件字节数) -
sha256(本地计算,用于完整性校验)
4.确定内容并上传
将文件存储数据的元数据保存在mysql
1.客户端传入给后端元数据
2.第一次缓存双删
![]()
3.将信息保存进数据库
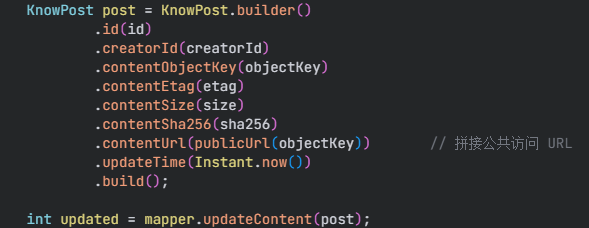
4.第二次缓存双删
![]()
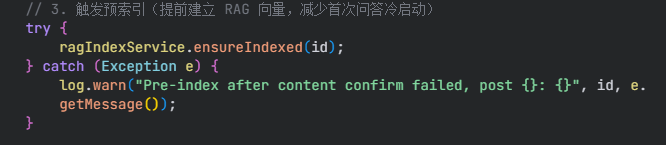
5.建立rag向量
.
缓存删除的对象
- L1 缓存 :Caffeine 本地缓存中的帖子详情缓存
- L2 缓存 :Redis 中的帖子详情缓存
为什么需要缓存双删
1. 第一次删除(写数据库前)
- 目的 :防止在数据库更新期间,其他请求读到旧的缓存数据
- 时机 :在执行数据库更新操作之前
- 作用 :清理可能存在的旧缓存,为后续的数据库更新做准备
2. 第二次删除(写数据库后)
- 目的 :确保数据库更新完成后,缓存中的旧数据被彻底清除
- 时机 :在数据库更新操作完成之后
- 作用 :处理可能的竞态条件,确保缓存与数据库保持一致
5.填写元数据
更新帖子的元数据,同上
6.发布
更新状态为发布


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)