Flink流式计算实战专题三:DataStream API与时间语义完全解析
一、Flink计算API概览
Flink提供了三套主要的应用API:
-
DataStream API:用于流式计算,是Flink最核心的模块,体现了其“流批统一”的核心理念。
-
DataSet API:用于批量计算。在Flink中,批量数据被视为有界流,其大部分基础概念已融入DataStream API。
-
Table API & SQL:提供类似关系型数据库的查询接口,用于对流式/批量数据进行查询过滤。此部分功能仍在积极开发中。
因此,学习和应用开发应以DataStream API为主。本文及后续内容均基于 Flink 1.12 版本。
二、DataStream API基础模型
一个DataStream代表一个不可更改的数据集合,可以是无界流,也可以是有界流。一个标准的Flink流式应用遵循以下五个步骤:
-
获取执行环境 (Environment)
-
定义数据来源 (Source)
-
定义数据转换操作 (Transformations)
-
定义结果输出位置 (Sink)
-
提交并启动任务
1. 运行环境 (StreamExecutionEnvironment)
通过 StreamExecutionEnvironment.getExecutionEnvironment() 创建,此方法能根据运行环境(本地IDE或集群)自动创建正确的对象。
关键配置:
-
并行度:通过
env.setParallelism()设置,是贯穿应用的资源主线。 -
运行时模式:通过
env.setRuntimeMode()或配置文件设置。-
STREAMING(默认):连续处理,适用于有界/无界流。 -
BATCH:周期性处理,可提升有界流吞吐量。 -
AUTOMATIC:Flink根据数据源自动选择。
-
建议通过
flink-conf.yaml或提交脚本设置运行时模式,例如:bin/flink run -Dexecution.runtime-mode=BATCH ...
三、数据源 (Source)
Flink提供了丰富的数据源接入方式。
1. 基于文件
java
DataStreamSource<String> stream = env.readTextFile("D://test.txt");
或使用 readFile 方法指定更复杂的输入格式。
2. 基于Socket
java
DataStreamSource<String> stream = env.socketTextStream("localhost", 7777);
3. 基于集合
java
DataStreamSource<Integer> stream1 = env.fromCollection(Arrays.asList(1,2,3)); DataStreamSource<Integer> stream2 = env.fromElements(1, 2, 3);
4. 基于Kafka(主流数据源)
引入Flink Kafka Connector依赖后,使用 FlinkKafkaConsumer 创建Source。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.12.3</version>
</dependency>
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers",
"hadoop01:9092,hadoop02:9092,hadoop03:9092");
properties.setProperty("group.id", "test");
final FlinkKafkaConsumer<String> mysource = new FlinkKafkaConsumer<>
("flinktopic", new SimpleStringSchema(), properties);
// mysource.setStartFromLatest();
// mysource.setStartFromTimestamp();
DataStream<String> stream = env
.addSource(mysource);
stream.print();
env.execute("KafkaConsumer");
此外,Flink还支持HBase、ES、JDBC等众多Connector,详见官网。对于RocketMQ,需使用社区维护的Connector。
5. 自定义Source
实现 SourceFunction<T> 或 RichSourceFunction<T> 接口。
-
SourceFunction:基础接口。 -
RichSourceFunction:提供了open、close等生命周期管理方法。
public class UDFSource {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
final DataStreamSource<Order> orderDataStreamSource = env.addSource(new
MyOrderSource());
orderDataStreamSource.print();
env.execute("UDFOrderSOurce");
}
public static class MyOrderSource implements SourceFunction<Order> {
private boolean running = true;
@Override
public void run(SourceContext<Order> ctx) throws Exception {
final Random random = new Random();
while(running){
Order order = new Order();
order.setId("order_"+System.currentTimeMillis()%700);
order.setPrice(random.nextDouble()*100);
order.setOrderType("UDFOrder");
order.setTimestamp(System.currentTimeMillis());
//发送对象
ctx.collect(order);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running=false;
}
}
}
四、数据输出 (Sink)
1. 输出到控制台
java
stream.print(); stream.printToErr();
2. 输出到文件
旧API (writeAsText, writeAsCsv) 已过时。推荐使用:
-
StreamingFileSink:用于流式场景,支持分区和滚动策略。
-
FileSink (推荐):
StreamingFileSink的升级版,真正实现流批统一,需引入flink-connector-files依赖。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(100);
final URL resource = FileRead.class.getResource("/test.txt");
final String filePath = resource.getFile();
final DataStreamSource<String> stream = env.readTextFile(filePath);
OutputFileConfig outputFileConfig = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".txt")
.build();
final StreamingFileSink<String> streamingfileSink = StreamingFileSink
.forRowFormat(new Path("D:/ft"), new SimpleStringEncoder<>("UTF-8"))
.withOutputFileConfig(outputFileConfig)
.build();
stream.addSink(streamingfileSink);
env.execute();
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.12.5</version>
</dependency>
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(100);
final URL resource = FileRead.class.getResource("/test.txt");
final String filePath = resource.getFile();
final DataStreamSource<String> stream = env.readTextFile(filePath);
OutputFileConfig outputFileConfig = OutputFileConfig
.builder()
.withPartPrefix("prefix")
.withPartSuffix(".txt")
.build();
final FileSink<String> fileSink = FileSink
.forRowFormat(new Path("D:/ft"), new SimpleStringEncoder<>("UTF-8"))
.withOutputFileConfig(outputFileConfig)
.build();
stream.sinkTo(fileSink);
env.execute();
3. 输出到Socket
java
wordcounts.writeToSocket(host, port, new SerializationSchema(){...});
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
final int port = parameterTool.getInt("port");
final DataStreamSource<String> inputDataStream = environment.socketTextStream(host, port);
final DataStream<Tuple2<String, Integer>> wordcounts = inputDataStream
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
final String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
})
.setParallelism(2)
.keyBy(value -> value.f0)
.sum(1)
.setParallelism(3);
wordcounts.print();
wordcounts.writeToSocket(
host,
port,
new SerializationSchema<Tuple2<String, Integer>>() {
@Override
public byte[] serialize(Tuple2<String, Integer> element) {
return (element.f0 + "-" + element.f1).getBytes(StandardCharsets.UTF_8);
}
}
);
environment.execute("stream word count");
}
4. 输出到Kafka
使用 FlinkKafkaProducer,可配置精确一次(EXACTLY_ONCE)语义。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
final DataStreamSource<Integer> stream = env.fromElements(1, 2, 3, 4, 5);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
FlinkKafkaProducer<String> myProducer = new FlinkKafkaProducer<String>(
"my-topic", // 目标 topic
new SimpleStringSchema(), // 序列化 schema
properties, // producer 配置
FlinkKafkaProducer.Semantic.EXACTLY_ONCE // 容错
);
stream.addSink(myProducer);
env.execute("kafka sink");
5. 自定义Sink
实现 SinkFunction<T> 或 RichSinkFunction<T> 接口。后者同样具备生命周期方法。
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
final DataStreamSource<Order> source = env.addSource(new UDFSource.MyOrderSource());
source.addSink(new MyJDBCSink());
env.execute("UDFJDBCSinkDemo");
}
public static class MyJDBCSink extends RichSinkFunction<Order> {
private Connection connection = null;
private PreparedStatement insertStmt = null;
private PreparedStatement updateStmt = null;
@Override
public void open(Configuration parameters) throws Exception {
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/testdb", "root", "root");
insertStmt = connection.prepareStatement("insert into flink_order (id, price, ordertype) values (?, ?, ?)");
updateStmt = connection.prepareStatement("update flink_order set price = ?, ordertype = ? where id = ?");
}
@Override
public void close() throws Exception {
if (insertStmt != null) {
insertStmt.close();
}
if (updateStmt != null) {
updateStmt.close();
}
if (connection != null) {
connection.close();
}
}
@Override
public void invoke(Order value, Context context) throws Exception {
System.out.println("更新记录: " + value);
updateStmt.setDouble(1, value.getPrice());
updateStmt.setString(2, value.getOrderType());
updateStmt.setString(3, value.getId());
updateStmt.execute();
if (updateStmt.getUpdateCount() == 0) {
insertStmt.setString(1, value.getId());
insertStmt.setDouble(2, value.getPrice());
insertStmt.setString(3, value.getOrderType());
insertStmt.execute();
}
}
}
五、数据转换 (Transformation)
这是DataStream API的核心,对数据进行各种处理。
1. Map
一对一转换。
java
dataStream.map(x -> 2 * x);
2. FlatMap
一对多转换,如分词。
java
dataStream.flatMap((String value, Collector<String> out) -> {
for (String word: value.split(" ")) {
out.collect(word);
}
});
3. Filter
过滤。
java
dataStream.filter(x -> x != 0);
4. KeyBy
按键分组,将DataStream转换为KeyedStream。Key不能是集合或数组,POJO需重写hashCode()。
java
dataStream.keyBy(value -> value.f0); // 按元组第一字段分组
5. Reduce
对KeyedStream进行滚动聚合(两两合并)。
java
keyedStream.reduce((v1, v2) -> v1 + v2);
6. Aggregations
对KeyedStream进行聚合(sum, min, max, minBy, maxBy)。min/max返回极值,minBy/maxBy返回极值所在整条数据。
7. Connect 与 CoMap/CoFlatMap
-
connect:连接两个类型可以不同的DataStream,得到ConnectedStreams,数据保持独立。 -
CoMap/CoFlatMap:对ConnectedStreams中的两条流分别应用Map/FlatMap逻辑。
8. Union
合并多个类型相同的DataStream。
9. 其他重要算子
-
shuffle():随机重新分区。 -
rebalance():轮询重新分区,常用于解决数据倾斜。
更多算子参见官方文档。
六、窗口 (Window)
Window将无界流切分为有限大小的“桶”进行计算,是流处理的核心概念。
1. 窗口类型
-
Keyed Window:对KeyedStream开窗。可并行计算,
stream.keyBy(...).window(...)。 -
Non-Keyed Window:对DataStream开窗。全局窗口,并行度为1,
stream.windowAll(...)。
2. 窗口分配器 (WindowAssigner)
-
滚动窗口 (Tumbling Windows):窗口大小固定,不重叠。
TumblingEventTimeWindows.of(Time.seconds(5))。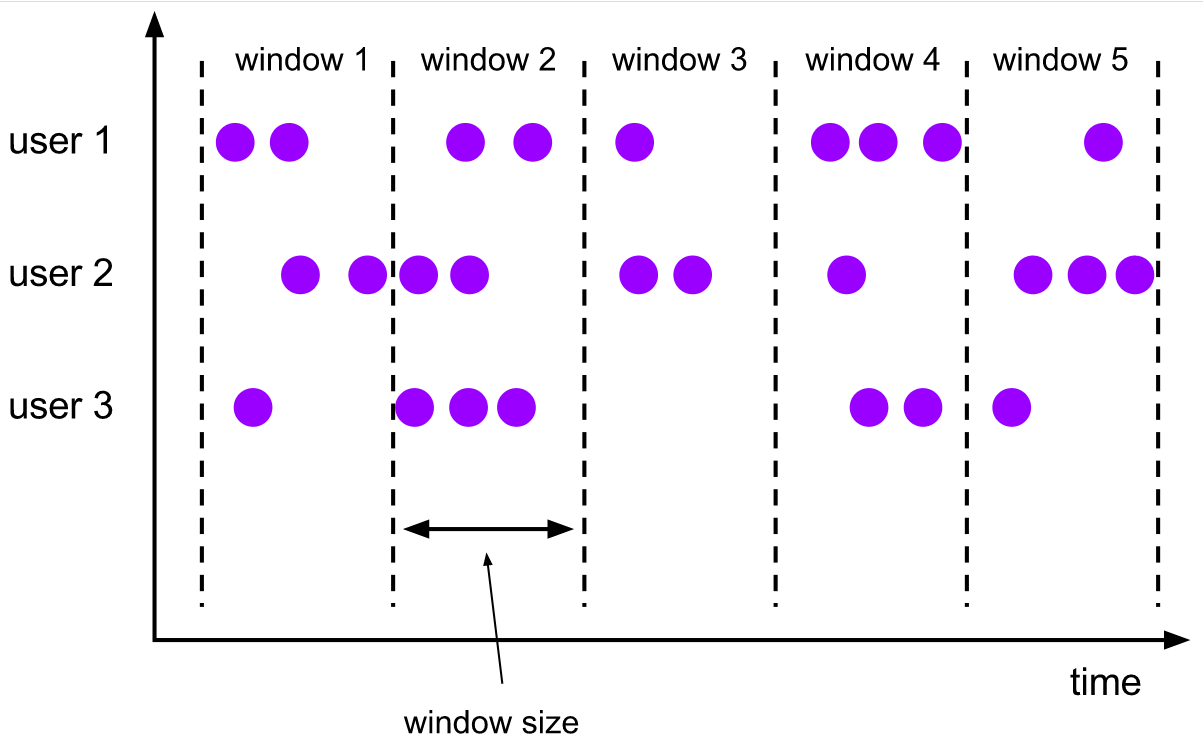
-
滑动窗口 (Sliding Windows):窗口大小固定,有滑动间隔,可重叠。
SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))。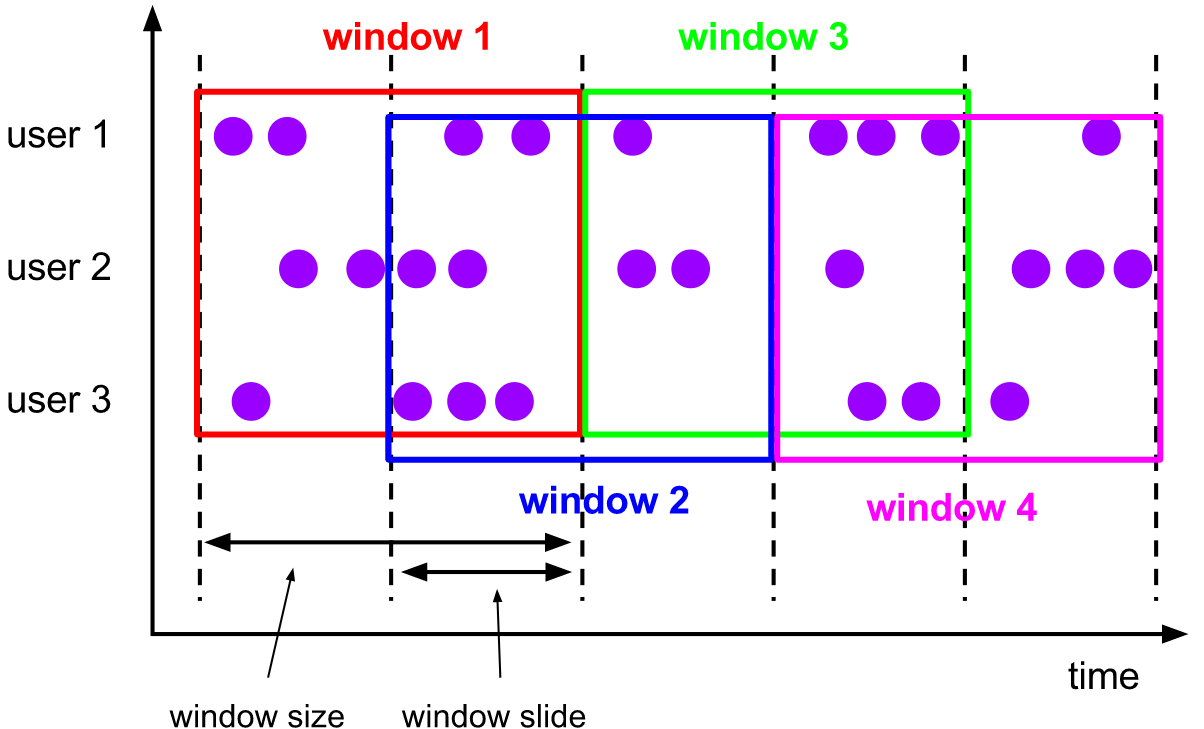
-
会话窗口 (Session Windows):由非活动间隔(session gap)切分。
EventTimeSessionWindows.withGap(Time.minutes(10))。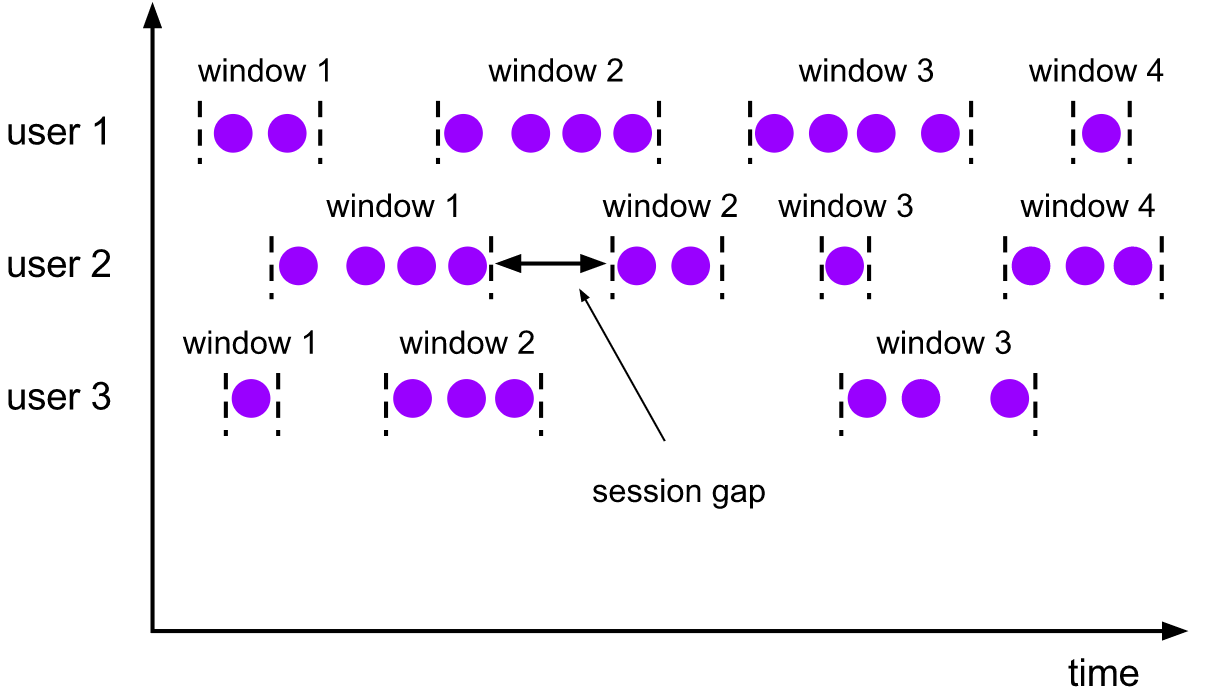
-
全局窗口 (Global Window):所有相同key的数据落入同一窗口,需自定义触发器(Trigger)触发计算。

-
计数窗口:
countWindow/countWindowAll,按元素个数开窗,较少使用。
3. 触发器 (Trigger) 与 驱逐器 (Evictor)
-
Trigger:定义窗口何时触发计算/关闭。内置
EventTimeTrigger、ProcessingTimeTrigger、CountTrigger、DeltaTrigger等。
-
Evictor:定义在触发计算前/后,从窗口中移除哪些数据。内置
TimeEvictor、CountEvictor、DeltaEvictor。
通过 全局窗口 + 自定义Trigger + Evictor 可以实现极其灵活的窗口策略。
4. 窗口函数
窗口聚合的目的是对窗口内数据进行计算。
-
全窗口函数 (Window Apply):
apply()。收集完窗口所有数据后,进行批处理。灵活性强。 -
增量聚合函数 (Window Reduce/Aggregate):
reduce()/aggregate()。来一条数据计算一次,效率高。 -
聚合操作:
sum(),max(),minBy()等,与KeyedStream的聚合类似。
WindowedStream , AllWindowed Stream -> DataStream 给窗口内的所有数据提供一个
整体的处理函数,可以称为全窗口聚合函数。例如下面是求和的示例。windowedStream.apply(new WindowFunction<Tuple2<String, Integer>, Integer, Tuple, Window>() { @Override public void apply(Tuple tuple, Window window, Iterable<Tuple2<String, Integer>> values, Collector<Integer> out) throws Exception { int sum = 0; for (Tuple2<String, Integer> t : values) { sum += t.f1; } out.collect(new Integer(sum)); } }); // applying an AllWindowFunction on non-keyed window stream allWindowedStream.apply(new AllWindowFunction<Tuple2<String, Integer>, Integer, Window>() { @Override public void apply(Window window, Iterable<Tuple2<String, Integer>> values, Collector<Integer> out) throws Exception { int sum = 0; for (Tuple2<String, Integer> t : values) { sum += t.f1; } out.collect(new Integer(sum)); } });Windowed Stream -> DataStream 同样是通过两个相邻元素的处理,来叠加完成整个集合的
处理。windowedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception { return new Tuple2<>(value1.f0, value1.f1 + value2.f1); } });Windowed Steam -> DataStream 在整个window上进行一些整体的统计。
windowedStream.sum(0); windowedStream.sum("key"); windowedStream.min(0); windowedStream.min("key"); windowedStream.max(0); windowedStream.max("key"); windowedStream.minBy(0); windowedStream.minBy("key"); windowedStream.maxBy(0); windowedStream.maxBy("key");同样 min是返回所选列中最小的数据,而minBy是返回所选列最小的这一行。
对于WindowedStream,也可以通过aggregate方法传入一个自定义的AggregateFunction
实现类来实现自定义的窗口聚合。// WindowFunction的四个泛型依次表示:传入数据类型、返回结果类型、key类型、窗口类型。 windowedStream.apply(new WindowFunction<Stock, Tuple2<String, Integer>, String, TimeWindow>() { // 四个参数依次表示:当前数据的key,当前窗口类型,当前窗口内所有数据的迭代器、输出结果收集器 @Override public void apply(String s, TimeWindow window, Iterable<Stock> input, Collector<Tuple2<String, Integer>> out) throws Exception { final int count = IteratorUtils.toList(input.iterator()).size(); out.collect(new Tuple2<>(s, count)); } });在这里重点是需要理解下apply与aggregate两种聚合方式的区别。
apply聚合方式会持续收集窗口内的数据,待窗口的数据全部收集完成后,拿到整个窗口期内
的数据,进行整体处理。相当于是一个批处理的过程。可以称之为全窗口聚合。而aggregate聚合方式则是来一条数据处理一次,并将结果保存到累加器中。当窗口结束后,
直接从累加器中返回当前窗口的计算结果。可以称之为流式聚合。这两种聚合机制,aggregate流式聚合的方式效率会更高,而apply全窗口聚合能够拿到计算
过程中更多的信息,因此会更为灵活。当需要定制时,可以根据业务场景灵活取舍。并且,在具体编码实现时,我们只需要记住这两种机制,就不需要完全记住编码的方式了。
七、CEP复杂事件处理
Flink CEP是在DataStream上进行模式匹配的库,用于识别复杂事件模式。
1. 基本流程
-
获取原始事件流
DataStream<Event> input。 -
定义模式匹配器
Pattern<Event, ?> pattern。 -
将模式应用到流上,得到
PatternStream<Event> patternStream = CEP.pattern(input, pattern)。 -
从PatternStream中提取匹配事件,生成结果
DataStream<Result>。
2. 定义模式匹配器 (Pattern)
模式由序列组合API和条件判断API构成。
-
序列组合API:
begin()、next()(严格连续)、followedBy()(宽松连续)、followedByAny()(非确定宽松连续)、notNext()、notFollowedBy()、within()(时间限制)等。在 Flink CEP 复杂事件处理中,定义模式匹配器时需要使用一组模式组合API来指定事件序列的匹配顺序和连续性。以下是完整的模式组合 API 列表,对应文档第 28 页的表格内容:
模式操作 描述 begin(#name)定义一个开始的模式: Pattern<Event, ?> start = Pattern.<Event>begin("start");begin(#pattern_sequence)定义一个开始的模式序列: Pattern<Event, ?> start = Pattern.begin(Pattern.<Event>begin("start").where(...).followedBy("middle").where(...));next(#name)增加一个新的模式。匹配的事件必须是直接跟在前面匹配到的事件后面(严格连续): Pattern<Event, ?> next = start.next("middle");next(#pattern_sequence)增加一个新的模式序列。匹配的事件序列必须是直接跟在前面匹配到的事件后面(严格连续): Pattern<Event, ?> next = start.next(Pattern.<Event>begin("start").where(...).followedBy("middle").where(...));followedBy(#name)增加一个新的模式。可以有其他事件出现在匹配的事件和之前匹配到的事件中间(松散连续): Pattern<Event, ?> followedBy = start.followedBy("middle");followedBy(#pattern_sequence)增加一个新的模式序列。可以有其他事件出现在匹配的事件序列和之前匹配到的事件中间(松散连续): Pattern<Event, ?> followedBy = start.followedBy(Pattern.<Event>begin("start").where(...).followedBy("middle").where(...));followedByAny(#name)增加一个新的模式。可以有其他事件出现在匹配的事件和之前匹配到的事件中间,每个可选的匹配事件都会作为可选的匹配结果输出(不确定的松散连续): Pattern<Event, ?> followedByAny = start.followedByAny("middle");followedByAny(#pattern_sequence)增加一个新的模式序列。可以有其他事件出现在匹配的事件序列和之前匹配到的事件中间,每个可选的匹配事件序列都会作为可选的匹配结果输出(不确定的松散连续): Pattern<Event, ?> followedByAny = start.followedByAny(Pattern.<Event>begin("start").where(...).followedBy("middle").where(...));notNext()增加一个新的否定模式。匹配的(否定)事件必须直接跟在前面匹配到的事件之后(严格连续)来丢弃这些部分匹配: Pattern<Event, ?> notNext = start.notNext("not");notFollowedBy()增加一个新的否定模式。即使有其他事件在匹配的(否定)事件和之前匹配的事件之间发生,部分匹配的事件序列也会被丢弃(松散连续): Pattern<Event, ?> notFollowedBy = start.notFollowedBy("not");within(time)定义匹配模式的事件序列出现的最大时间间隔。如果未完成的事件序列超过了这个时间,就会被丢弃: pattern.within(Time.seconds(10));关键概念解释:
1、严格连续 (Strict Contiguity):
next()要求两个事件之间没有其他任何事件。例如,模式A next B在序列A C B中不会匹配,因为 A 和 B 之间有 C。2、松散连续 (Relaxed Contiguity):
followedBy()允许两个事件之间有其他不相关的事件。例如,模式A followedBy B在序列A C B中会匹配。3、不确定松散连续 (Non-Deterministic Relaxed Contiguity):
followedByAny()不仅允许中间有其他事件,而且会将所有可能匹配的结果都输出。例如,序列A1 A2 B,模式A followedByAny B会输出两个匹配:(A1, B)和(A2, B)。4、否定模式 (Negative Patterns):
notNext()和notFollowedBy()用于定义不应该出现的事件,用于排除某些模式。5、时间约束 (Time Constraint):
within()为整个模式或子模式添加时间窗口,超过时间未完成匹配的序列会被丢弃。6、严格连续 (Strict Contiguity):
next()要求两个事件之间没有其他任何事件。例如,模式A next B在序列A C B中不会匹配,因为 A 和 B 之间有 C。7、松散连续 (Relaxed Contiguity):
followedBy()允许两个事件之间有其他不相关的事件。例如,模式A followedBy B在序列A C B中会匹配。8、不确定松散连续 (Non-Deterministic Relaxed Contiguity):
followedByAny()不仅允许中间有其他事件,而且会将所有可能匹配的结果都输出。例如,序列A1 A2 B,模式A followedByAny B会输出两个匹配:(A1, B)和(A2, B)。9、否定模式 (Negative Patterns):
notNext()和notFollowedBy()用于定义不应该出现的事件,用于排除某些模式。10、时间约束 (Time Constraint):
within()为整个模式或子模式添加时间窗口,超过时间未完成匹配的序列会被丢弃。使用示例:
java
Pattern<Event, ?> pattern = Pattern.<Event>begin("start") .where(new SimpleCondition<Event>() { @Override public boolean filter(Event event) { return event.getName().equals("start"); } }) .followedBy("middle") .where(new SimpleCondition<Event>() { @Override public boolean filter(Event event) { return event.getValue() > 10.0; } }) .notFollowedBy("not") .where(new SimpleCondition<Event>() { @Override public boolean filter(Event event) { return event.getType().equals("error"); } }) .within(Time.seconds(30));重要区别:
next()vsfollowedBy()next():表示严格连续。例如在网站登录场景中,用于匹配"连续三次登录失败"。followedBy():表示松散连续。例如在网站登录场景中,用于匹配"1分钟内三次登录失败"(中间可能有其他操作)。通常情况下,松散连续模式需要配合
within()方法指定时间范围。一个模式中可以定义多个时间范围,但最终只取最小的一个时间范围作为约束 -
条件判断API:
where()(条件)、or()(或)、until()(停止条件)、subtype()(子类型)、oneOrMore()(至少一次)、times()(次数)、optional()(可选)、greedy()(贪婪)等。在 Flink CEP 复杂事件处理中,定义模式匹配器时需要使用一组条件判断API来指定每个匹配步骤的过滤条件。以下是完整的条件判断 API 列表:
模式操作 描述 where(condition)为当前模式定义一个条件。一个事件必须满足此条件才能匹配该模式。多个连续的 where()语句取与关系组成复合条件。or(condition)增加一个新的判断条件,与当前判断条件取或关系。一个事件只要满足至少一个判断条件就匹配到模式。 until(condition)为循环模式指定一个停止条件。当满足给定条件的事件出现后,就不会再接收新的事件进入该模式。仅适用于与 oneOrMore()同时使用。注意:在基于事件的条件中,可用于清理对应模式的状态。subtype(subClass)为当前模式定义一个子类型条件。一个事件必须是此子类型时才能匹配到模式。例如: pattern.subtype(SubEvent.class)。oneOrMore()指定模式期望匹配到的事件至少出现一次。默认(在子事件间)使用松散的内部连续性。注意:推荐使用 until()或within()来清理状态。times(#ofTimes)指定模式期望匹配到的事件正好出现 #ofTimes 次。默认使用松散的内部连续性。 times(#fromTimes, #toTimes)指定模式期望匹配到的事件出现次数在 #fromTimes 到 #toTimes 之间。默认使用松散的内部连续性。 optional()指定这个模式是可选的,即它可能根本不出现。适用于所有之前提到的量词(如 oneOrMore().optional())。greedy()指定这个模式是贪心的,即它会重复尽可能多的次数。目前只对 oneOrMore()和times()量词适用,还不支持模式组。这一组API中,主要是以where来构成一个基础的条件,然后通过在基础条件下进行相关组合形成更为复杂的判断条件。这一块还是比较容易理解的。其中有点难以理解的是subType方法。这个方法只能声明一个处理的子类,也就是在这一个匹配模式当中,可以将原始数据类型转换成他的一个子类,并且在后续的where处理方法中,也需要使用这个子类的类型来定义判断标准。
使用示例说明:
java
Pattern<Event, ?> pattern = Pattern.<Event>begin("start") .where(new SimpleCondition<Event>() { @Override public boolean filter(Event event) { return event.getId() == 42; } }) .or(new SimpleCondition<Event>() { @Override public boolean filter(Event event) { return event.getName().equals("start"); } }) .oneOrMore() .optional() .until(new SimpleCondition<Event>() { @Override public boolean filter(Event event) { return event.isTerminal(); } });关键要点:
1、条件组合:
where和or用于构建逻辑条件,支持 AND 和 OR 关系。2、量词控制:
oneOrMore()、times()等用于控制事件出现的次数。3、状态管理:
until()和optional()用于控制模式的终止和可选性,有助于管理状态和性能。4、子类型限定:
subtype()可在匹配过程中进行类型转换,便于对特定子类事件进行条件判断。
3. 处理匹配结果
使用 PatternProcessFunction 处理 PatternStream。其核心方法 processMatch 能获取匹配到的模式序列(Map<String, List<IN>>),并通过 Collector 输出结果。对于超时部分匹配,可实现 TimedOutPartialMatchHandler 接口处理。
示例代码参见
com.roy.flink.project.userlogin.UserLoginAna。
八、Flink时间语义与乱序处理
时间是流处理正确性的基石。Flink定义了三种时间:
-
EventTime:事件发生的时间(最常用)。
-
IngestionTime:事件进入Flink的时间。
-
ProcessingTime:事件被处理的时间(默认,Flink可自行获取)。
1. 设置EventTime
Flink 1.12后,EventTime已成为默认时间特征。通常需要从数据字段中提取时间戳,并分配Watermark。
java
WatermarkStrategy<Stock> strategy = WatermarkStrategy
.<Stock>forBoundedOutOfOrderness(Duration.ofSeconds(3)) // 允许3秒乱序
.withTimestampAssigner((event, timestamp) -> event.getTimestamp()); // 提取时间戳
stockStream.assignTimestampsAndWatermarks(strategy);
2. Watermark(水位线)机制
Watermark是Flink处理乱序数据的核心机制。
-
本质:一个单调递增的时间戳,表示“当前事件时间已推进到此刻”。
-
作用:用于衡量事件时间的进度,决定窗口何时关闭触发计算。
-
原理:设置一个延迟(如2秒)。Watermark = 当前最大事件时间 - 延迟时间。窗口会等到Watermark超过窗口结束时间才关闭,从而容忍一定程度的迟到数据。
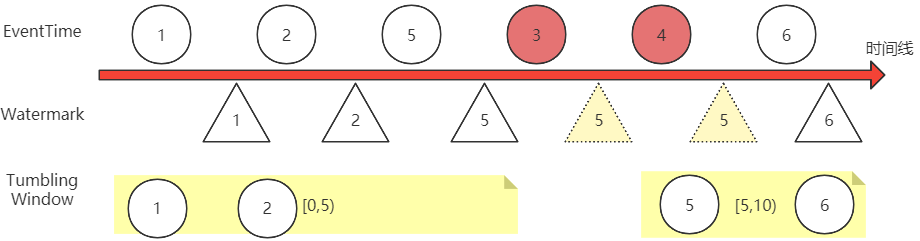
生成策略:
-
forMonotonousTimestamps():用于有序流。 -
forBoundedOutOfOrderness(Duration):用于乱序流,需指定最大乱序时长。 -
可通过实现
WatermarkGenerator接口完全自定义。
3. 处理乱序数据的完整方案
Flink提供了三层防御机制来处理迟到数据:
-
Watermark:第一道闸门,允许短期迟到数据进入窗口。
-
allowedLateness:窗口关闭后,允许一个额外等待时间。此期间到达的迟到数据会触发该窗口的重新计算(输出新的结果)。性能开销较大,时间不宜过长。
-
sideOutputLateData (侧输出流):最后的兜底方案。超过等待时间的数据被放入侧输出流,由用户决定如何处理(如补偿、告警、丢弃)。
DataStream<Integer> input = ...; final OutputTag<String> outputTag = new OutputTag<String>("side-output"){}; SingleOutputStreamOperator<Integer> mainDataStream = input .process(new ProcessFunction<Integer, Integer>() { @Override public void processElement(Integer value, Context ctx, Collector<Integer> out) throws Exception { // 发送数据到主要的输出 out.collect(value); // 发送数据到旁路输出 ctx.output(outputTag, "sideout-" + String.valueOf(value)); } });接下来,可以在DataStream的运算结果上使用getSideOutput(OutputTag)方式获取侧输出流,进行后续的侧输出流处理。
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){}; SingleOutputStreamOperator<Integer> mainDataStream = ...; DataStream<String> sideOutputStream = mainDataStream.getSideOutput(outputTag);
整个侧输出流相当于是对所有异常数据的一个兜底操作,不光对于超时的事件可以用侧输出流
进行最后的补偿处理,对于一些不正确的噪点事件,也可以用侧输出流的方式进行最后的操作。
而对于侧输出流中没有捕获的事件, Flink就爱莫能助,只能放弃了。
4. Watermark传播机制
在多并行度下,Watermark会在算子间传递。下游算子会接收所有上游并行子任务的Watermark,并取其中的最小值作为自己的时钟推进依据,这保证了所有分区数据都已处理到该时间点。
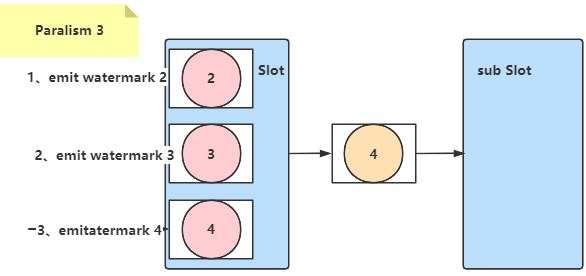
这种传播机制,对于SocketStream这个数据源,有序需要阻塞线程,所以只能以一个线程(也
就是并行度1)读取数据。所以这时,Flink只能通过读取三个或以上的数据,将这些数据尽量平均
的分配给各个线程(并行度),这样才能保证能够正常往下游slot传递Watermark。所以才会出现
示例中说到的那种情况。
在对接Kafka这样的数据源时,这个问题就不会太过明显。因为这些数据源本身就实现了多线
程的数据读取。
总结
本文系统梳理了Flink DataStream API的核心内容与时间语义。DataStream API通过 Source、Transformation、Sink 构成流式应用骨架,Window 与 CEP 提供了高级流处理能力。而 时间语义(尤其是EventTime)与Watermark机制,是保证流式计算在乱序场景下结果正确的根本。
掌握这些内容,就掌握了Flink流式处理的精髓。对于批量处理的DataSet API,由于其核心概念已融入DataStream的“流批统一”思想,可以触类旁通。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)