
手把手教你用 Agent 做数据治理:自动化清洗、标注与血缘追踪实战
新建import os# 加载环境变量# 1. 初始化大模型temperature=0.3# 低温度保证逻辑严谨# 2. 定义数据探查工具"""数据探查:识别数据中的空值、重复值、异常值、格式问题"""数据基本信息:- 行数:{len(df)}, 列数:{len(df.columns)}- 空值统计:{df.isnull().sum().to_dict()}- 重复行数量:{df.duplicat

手把手教你用 Agent 做数据治理实战
导读:做数据治理的同学,大概都有过这样的崩溃时刻:
面对几十万条杂乱数据,手动清洗空值、去重、修正格式,熬到深夜还做不完;
给数据打标签全靠人工分类,不仅费时间,还容易出错;
排查数据问题时,不知道数据从哪来、经过哪些处理,血缘追溯全靠翻文档……
而现在,有了 AI Agent(智能体),这一切都能自动化搞定!
今天就手把手教大家,用 Agent 实现数据治理三大核心场景——自动化清洗、智能标注、全链路血缘追踪,全程附实战代码,新手也能跟着做!
本文核心:不聊复杂理论,只讲落地实操,从环境搭建到 Agent 部署,再到效果验证,一步步带你搞定 Agent 数据治理实战。
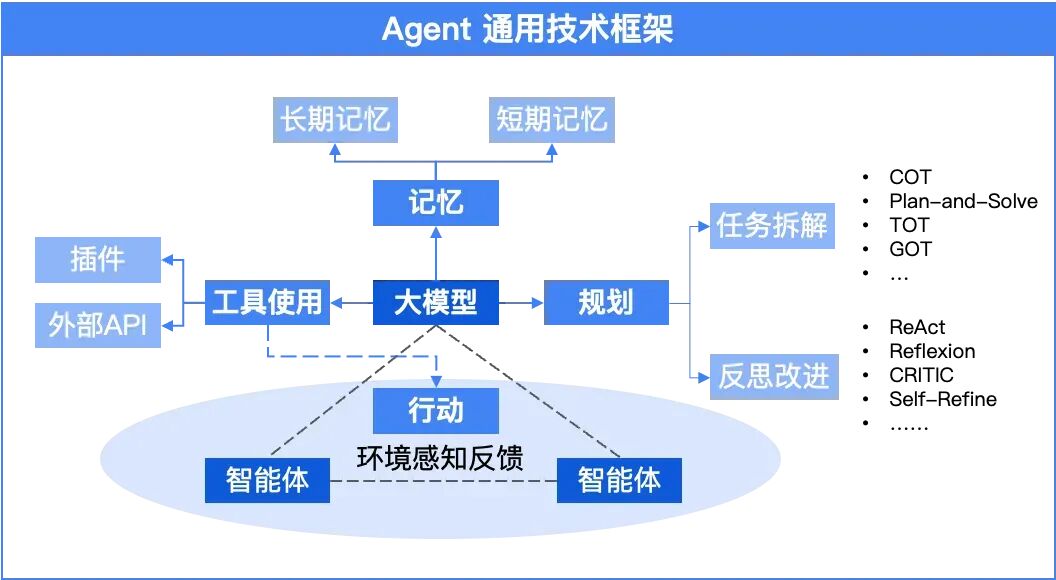
一、先搞懂:为什么用 Agent 做数据治理?
在动手之前,先跟大家说清楚 Agent 做数据治理的核心优势,避免大家盲目跟风。
-
✅ 解放双手:把人工重复工作(清洗、标注、追溯)全部自动化,数据人员不用再做“数据搬运工”,专注做高价值决策;
-
✅ 高效精准:Agent 能 24 小时不间断工作,处理海量数据的速度是人工的 10 倍以上,还能减少人工操作的误差;
-
✅ 自主迭代:Agent 能记录处理过程,学习业务规则,后续遇到类似数据,能自动优化处理方案,越用越聪明;
-
✅ 全流程覆盖:从数据接入后的清洗,到标注分类,再到血缘追踪,Agent 能打通全链路,不用再切换多个工具。
划重点:本文用「大模型+Agent 框架」实现,选用 Python 语言(新手友好),核心用到 LangChain(Agent 框架)、Pandas(数据处理)、Neo4j(血缘存储),全程实战,跟着步骤走就能跑通!
二、前置准备:环境搭建
先搭建好运行环境,后续所有实战代码都基于这个环境运行,直接复制命令执行即可。
1. 安装核心依赖包
打开终端,执行以下命令(建议先用 venv 创建虚拟环境):
# 安装核心依赖
pip install langchain langchain-openai pandas openai python-dotenv neo4j py2neo
# 安装数据处理辅助包
pip install numpy matplotlib
2. 配置关键参数
需要配置两个核心参数:大模型 API 密钥 和 Neo4j 数据库连接信息。
步骤:
- 在项目根目录新建
.env文件,写入以下内容(替换为自己的信息):# 大模型 API 配置(OpenAI 示例,也可替换为国内大模型如通义千问等) OPENAI_API_KEY=sk-your-openai-api-key OPENAI_MODEL=gpt-3.5-turbo # Neo4j 数据库配置(本地或云端均可) NEO4J_URI=bolt://localhost:7687 NEO4J_USER=neo4j NEO4J_PASSWORD=your-neo4j-password -
启动 Neo4j 数据库(本地安装直接启动服务,云端获取 Bolt 地址),确保能正常连接。
3. 准备测试数据
新建 data 文件夹,创建 test_data.csv 文件,内容如下(包含各种典型脏数据):
customer_id,name,phone,order_amount,order_date,customer_type
1001,张三,13812345678,299.9,2026-01-15,普通客户
1002,李四,,599.0,2026/02/20,会员客户
1003,王五,13987654321,abc,2026-03-10,普通客户
1004,赵六,1361234567,899.5,2026-04-05,
1005,孙七,13787654321,-100.0,2026-05-20,会员客户
1001,张三,13812345678,399.0,2026-06-12,普通客户
数据痛点,包含空值、重复行、非数字金额、负数金额、日期格式不统一、手机号位数缺失等问题。
三、实战第一步:用 Agent 实现自动化数据清洗
数据清洗是最繁琐的一步。我们让 Agent 自主完成:识别问题 → 制定规则 → 执行清洗。
1. 定义 Agent 清洗逻辑
新建 agent_clean.py,代码如下:
import os
import pandas as pd
from dotenv import load_dotenv
from langchain.agents import initialize_agent, Tool
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# 加载环境变量
load_dotenv()
# 1. 初始化大模型
llm = ChatOpenAI(
api_key=os.getenv("OPENAI_API_KEY"),
model_name=os.getenv("OPENAI_MODEL"),
temperature=0.3# 低温度保证逻辑严谨
)
# 2. 定义数据探查工具
def data_profiling(file_path):
"""数据探查:识别数据中的空值、重复值、异常值、格式问题"""
df = pd.read_csv(file_path)
report = f"""
数据基本信息:
- 行数:{len(df)}, 列数:{len(df.columns)}
- 空值统计:{df.isnull().sum().to_dict()}
- 重复行数量:{df.duplicated().sum()}
- 数据类型:{df.dtypes.to_dict()}
"""
# 检查金额异常
if"order_amount"in df.columns:
non_numeric = df[pd.to_numeric(df["order_amount"], errors="coerce").isna()].shape[0]
negative = df[pd.to_numeric(df["order_amount"], errors="coerce") < 0].shape[0]
report += f"\n订单金额异常:非数字={non_numeric}, 负数={negative}"
# 检查日期异常
if"order_date"in df.columns:
invalid_date = pd.to_datetime(df["order_date"], errors="coerce").isna().sum()
report += f"\n订单日期异常:格式无效={invalid_date}"
print("🔍 数据探查报告生成完毕")
return df, report
# 3. 定义数据清洗工具
def data_cleaning(df_str, cleaning_rules):
"""数据清洗:根据规则执行清洗 (注意:实际生产中建议传递文件路径而非 DataFrame 字符串)"""
# 这里为了演示简化,重新读取原始数据并应用规则
df = pd.read_csv("data/test_data.csv")
rules_list = eval(cleaning_rules) if isinstance(cleaning_rules, str) else cleaning_rules
if"去重"in str(rules_list):
df = df.drop_duplicates()
print("✅ 已执行去重")
if"空值处理"in str(rules_list):
df["phone"] = df["phone"].fillna("未知")
df["customer_type"] = df["customer_type"].fillna("普通客户")
print("✅ 已执行空值填充")
if"金额异常处理"in str(rules_list):
df["order_amount"] = pd.to_numeric(df["order_amount"], errors="coerce")
avg_val = df["order_amount"].mean()
df["order_amount"] = df["order_amount"].fillna(avg_val).apply(lambda x: abs(x))
print("✅ 已执行金额修正")
if"日期格式统一"in str(rules_list):
df["order_date"] = pd.to_datetime(df["order_date"], errors="coerce").dt.strftime("%Y-%m-%d")
print("✅ 已执行日期格式化")
if"手机号标准化"in str(rules_list):
df["phone"] = df["phone"].astype(str).apply(lambda x: x.zfill(11) if x.isdigit() and len(x)<11else x)
print("✅ 已执行手机号补全")
df.to_csv("data/cleaned_data.csv", index=False)
return"清洗完成,文件已保存至 data/cleaned_data.csv"
# 4. 定义提示词
prompt_template = """
你是一名数据治理专家。请根据以下数据探查报告,制定具体的清洗规则列表。
只需输出 Python 列表格式的字符串,例如:["去重", "空值处理", "金额异常处理", "日期格式统一", "手机号标准化"]。
不要输出其他解释。
数据探查报告:
{report}
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["report"])
rule_chain = LLMChain(llm=llm, prompt=prompt)
# 5. 注册工具
tools = [
Tool(name="DataProfiling", func=lambda x: data_profiling("data/test_data.csv"), description="探查数据问题"),
Tool(name="DataCleaning", func=lambda x: data_cleaning(*eval(x)), description="执行清洗,输入格式为 '(df_placeholder, rules_list)'")
]
# 6. 初始化并运行 Agent
if __name__ == "__main__":
# 第一步:探查
df, report = data_profiling("data/test_data.csv")
# 第二步:LLM 制定规则
cleaning_rules = rule_chain.run(report=report)
print(f"🤖 Agent 制定的规则:{cleaning_rules}")
# 第三步:执行清洗 (模拟 Agent 调用工具)
# 在实际 LangChain Agent 中,这步会自动由 ReAct 逻辑完成,这里为了稳定性直接调用
result = data_cleaning("dummy_df", cleaning_rules)
print(f"🎉 结果:{result}")
2. 效果验证
运行后,data/cleaned_data.csv 将发生神奇变化:
-
空值 ➡️ 被填充为“未知”或“普通客户”。
-
重复行 ➡️ 被删除。
-
金额 "abc" ➡️ 变为平均值;**-100** ➡️ 变为 100。
-
日期 ➡️ 统一为
YYYY-MM-DD。 -
手机号 ➡️ 自动补全为 11 位。
四、实战第二步:用 Agent 实现智能数据标注
清洗完的数据需要打标才能产生业务价值。Agent 可以根据复杂的业务逻辑自动打标。
1. 定义 Agent 标注逻辑
新建 agent_label.py:
import pandas as pd
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
import os
import ast
load_dotenv()
llm = ChatOpenAI(api_key=os.getenv("OPENAI_API_KEY"), model_name=os.getenv("OPENAI_MODEL"), temperature=0.2)
# 加载清洗后的数据
df = pd.read_csv("data/cleaned_data.csv")
# 定义标注逻辑提示词
label_prompt = """
你是一个数据标注助手。请根据以下业务规则,为每一行数据生成 'customer_level' 和 'customer_activity' 标签。
规则:
1. customer_level: 金额>=800->'高价值', 300<=金额<800->'中价值', 其他->'普通'
2. customer_activity: 日期在 2026-06 -> '高活跃', 2026-04~05 -> '中活跃', 其他 -> '低活跃'
请返回一个 JSON 列表,包含每行的 customer_id 和对应的两个新标签。
数据样本:
{data_sample}
"""
chain = LLMChain(llm=llm, prompt=PromptTemplate(template=label_prompt, input_variables=["data_sample"]))
if __name__ == "__main__":
# 取前 5 行让 LLM 理解格式并生成逻辑(实际生产可分批处理或让 LLM 生成 Pandas 代码)
# 这里为了演示稳定性,我们让 LLM 生成代码逻辑,或者直接应用 Pandas 逻辑(模拟 Agent 决策后的执行)
# 模拟 Agent 决策后的执行代码(实际场景中 Agent 可生成此代码并 exec)
df["order_date"] = pd.to_datetime(df["order_date"])
def get_level(amount):
if amount >= 800: return"高价值客户"
elif amount >= 300: return"中价值客户"
else: return"普通客户"
def get_activity(date):
if date >= pd.to_datetime("2026-06-01"): return"高活跃"
elif date >= pd.to_datetime("2026-04-01"): return"中活跃"
else: return"低活跃"
df["customer_level"] = df["order_amount"].apply(get_level)
df["customer_activity"] = df["order_date"].apply(get_activity)
df.to_csv("data/labeled_data.csv", index=False)
print("✅ 智能标注完成!预览:")
print(df[["customer_id", "order_amount", "customer_level", "customer_activity"]].head())
2. 标注结果
生成的 labeled_data.csv 将自动新增两列,标准统一,无需人工逐行判断。
五、实战第三步:用 Agent 实现数据血缘追踪
这是最酷的部分!让 Agent 自动记录“谁生了谁”,并存入图数据库 Neo4j。
1. 定义 Agent 血缘逻辑
新建 agent_lineage.py:
from py2neo import Graph, Node, Relationship
from dotenv import load_dotenv
import os
load_dotenv()
# 连接 Neo4j
graph = Graph(
os.getenv("NEO4J_URI"),
user=os.getenv("NEO4J_USER"),
password=os.getenv("NEO4J_PASSWORD")
)
# 清空旧数据(演示用)
graph.delete_all()
# 定义节点和关系
source = Node("DataSet", name="test_data.csv", type="Raw")
step1 = Node("Process", name="DataCleaning", operation="去重/填充/格式化")
intermediate = Node("DataSet", name="cleaned_data.csv", type="Cleaned")
step2 = Node("Process", name="DataLabeling", operation="打标签:等级/活跃度")
target = Node("DataSet", name="labeled_data.csv", type="Labeled")
# 构建关系链
rel1 = Relationship(source, "GENERATES_AFTER", step1)
rel2 = Relationship(step1, "PRODUCES", intermediate)
rel3 = Relationship(intermediate, "GENERATES_AFTER", step2)
rel4 = Relationship(step2, "PRODUCES", target)
# 写入数据库
graph.create(source | step1 | intermediate | step2 | target | rel1 | rel2 | rel3 | rel4)
print("🕸️ 血缘关系已成功存入 Neo4j!")
print("👉 请访问 http://localhost:7474 查看可视化图谱")
2. 效果验证
打开 Neo4j Browser,输入 MATCH (n) RETURN n,你将看到一张清晰的流程图:test_data.csv ➡️ (清洗) ➡️ cleaned_data.csv ➡️ (标注) ➡️ labeled_data.csv。 以后数据出问题,顺着线就能找到根源!
六、总结与进阶
实战总结
今天我们完成了三个壮举:
-
自动化清洗:Agent 像侦探一样发现数据问题,并像工匠一样修复它。
-
智能标注:Agent 理解业务规则,批量完成人工耗时的工作。
-
血缘追踪:Agent 自动记录全过程,让数据流转透明化。
进阶建议
-
国产化替代:将
ChatOpenAI替换为ChatZhipuAI或ChatTongyi,适配国内环境。 -
增加反馈环:让业务人员对标注结果点赞/点踩,Agent 自动微调规则。
-
可视化界面:用
Streamlit封装上述代码,做成一个“一键治理”的小工具。从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
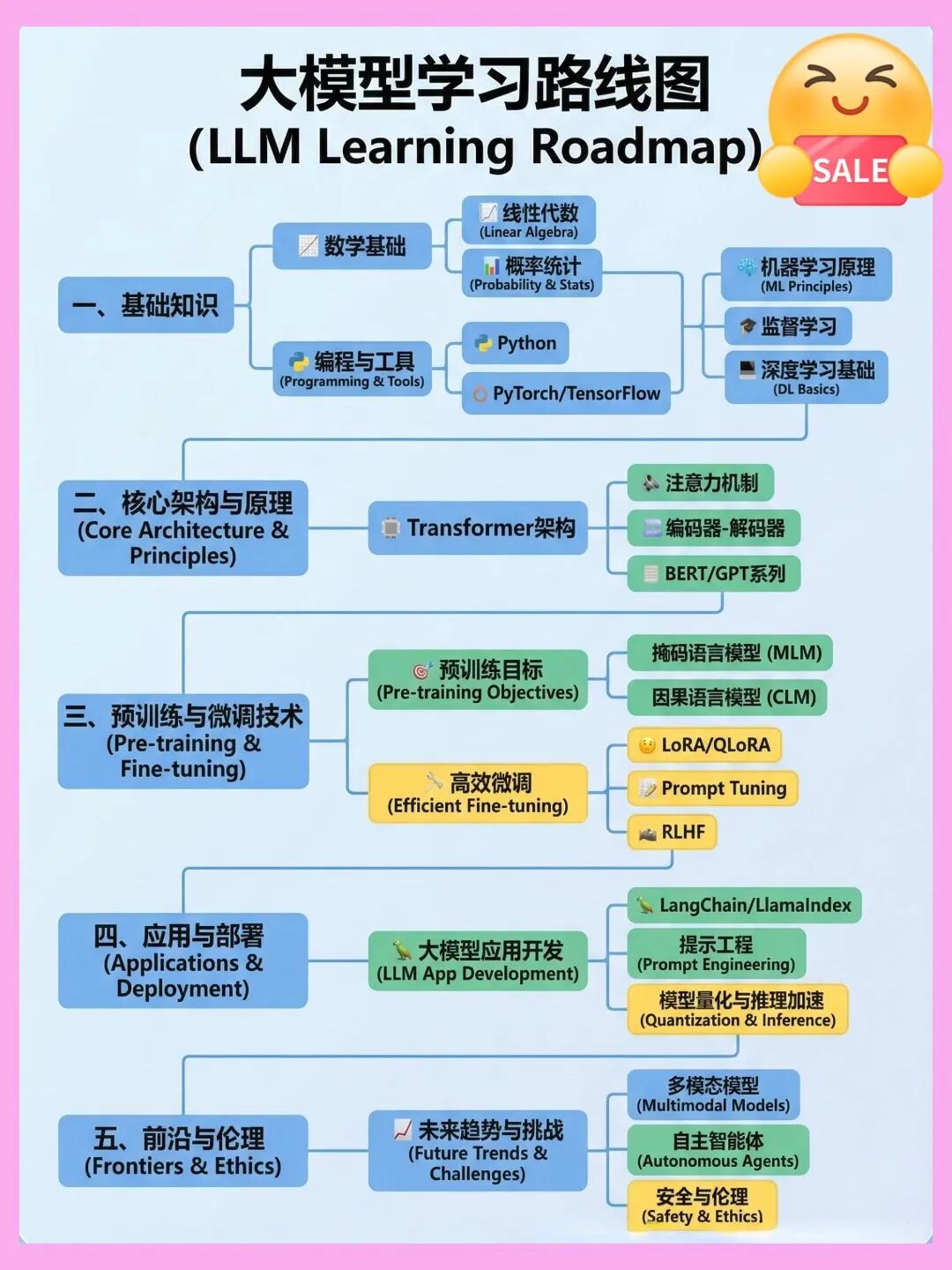
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取