DolphinScheduler 任务阻塞死锁排查与解决方案
一次 ClickHouse 宕机引发的「血案」:200+ 任务疯狂重试把 CK 打挂,串行等待策略造成死锁,任务动弹不得。本文记录完整的排查过程和终极解决方案。
一、事故背景
1.1 事故经过
时间线:
- 2026-02-03:ClickHouse 挂了,DolphinScheduler 任务随之停止
- 2026-02-04:发现问题,重启 Dolphin,瞬间产生 200+ 补数任务
- 结果:任务洪峰直接把刚恢复的 ClickHouse 再次打挂
重启 CK 后,发现任务全部阻塞,界面一片红:
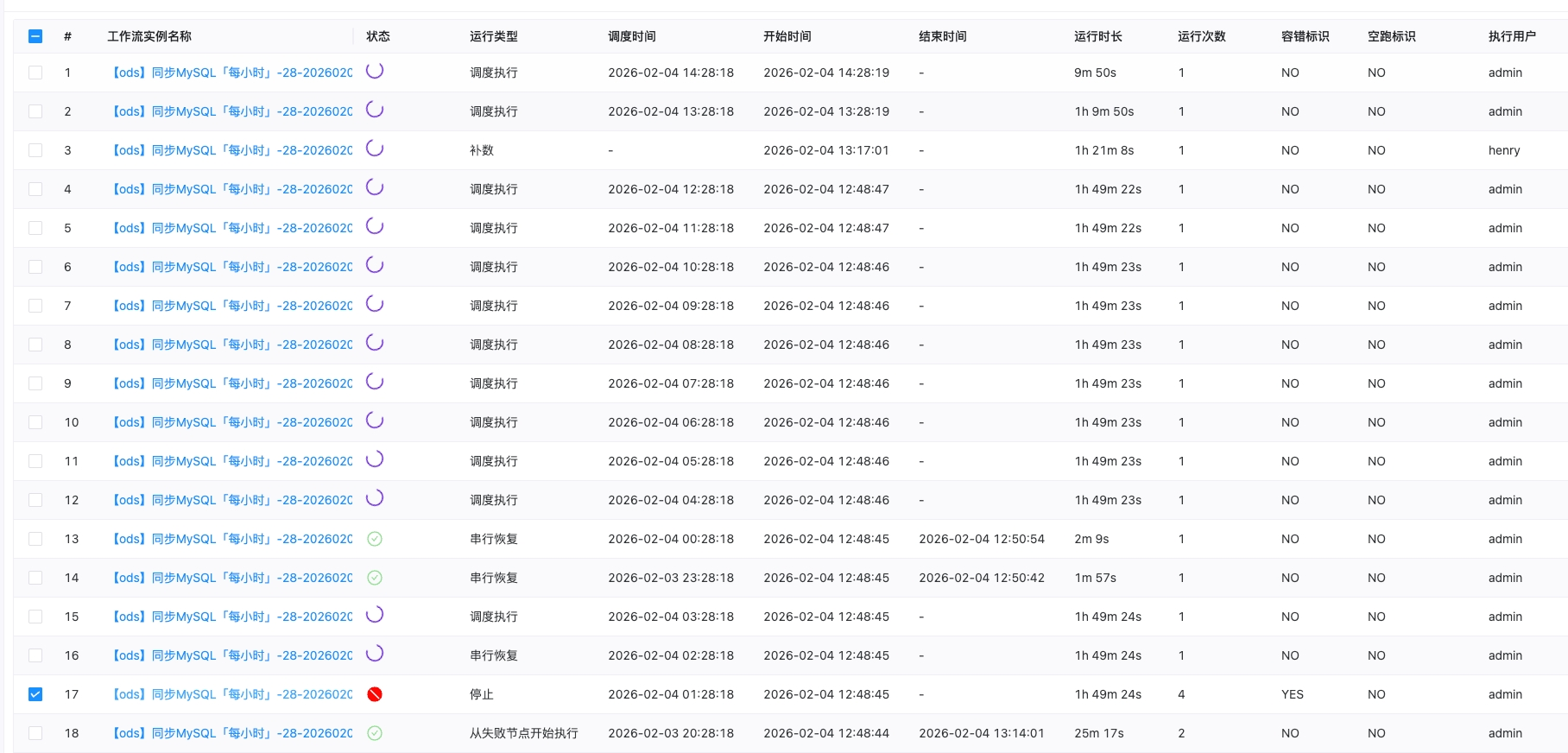
现象:
- 最底部的任务:状态 = 失败,点击停止后变成「准备停止」,卡住不动
- 后续所有任务:状态 = 串行等待
- 整个工作流:死锁,彻底动不了
机器配置:4C 32G,资源不是问题,问题出在调度策略上。
1.2 原因分析
罪魁祸首:任务执行策略配置了「串行等待」
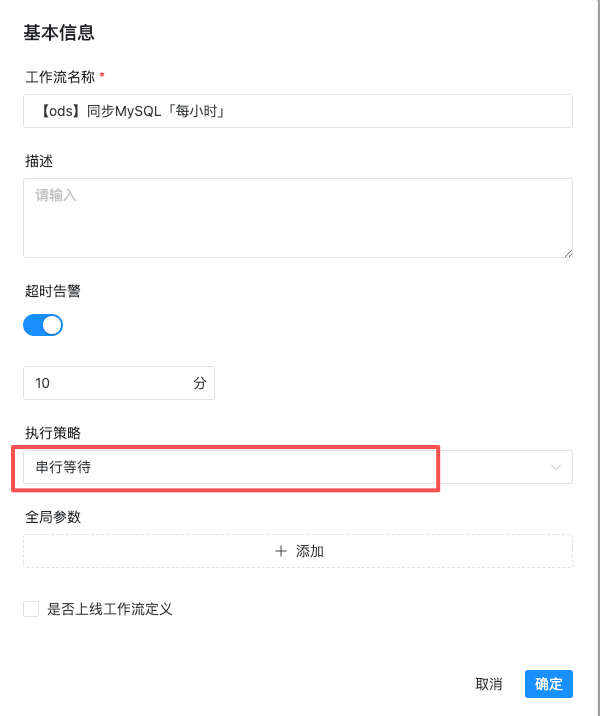
串行等待的坑:
- 当一个任务实例在运行时,后续实例会排队等待
- 如果正在运行的任务异常(失败 / 准备停止),它既不释放锁,也不真正停止
- 后续任务永远等不到「前任」完成 → 死锁形成
尝试通过「补数运行」重新执行任务,直接报错:
“已经有一个进行中的任务了”(大意如此,现场没保留)
重启 Dolphin?没用。
手动停止任务?卡在「准备停止」。
等它自己恢复?别做梦了。
二、解决方案:直接改库
既然 UI 层面无能为力,那就釜底抽薪——直接操作 MySQL 数据库。
2.1 定位关键表
打开 DolphinScheduler 的数据库,共 65 张表。
根据命名规律,t_ds_process_* 开头的表与任务执行相关:
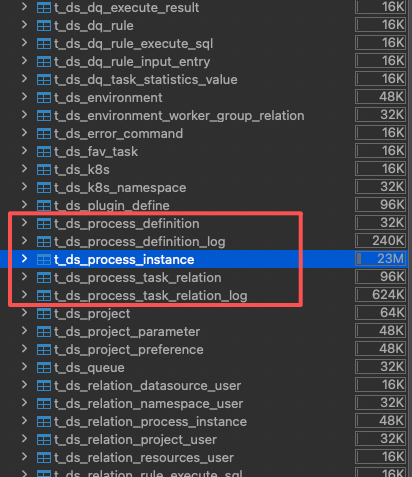
核心表:
| 表名 | 用途 |
|---|---|
t_ds_process_instance |
工作流实例(每次运行生成一条记录) |
t_ds_task_instance |
任务实例(工作流中每个节点的执行记录) |
t_ds_process_definition |
工作流定义 |
2.2 查看异常数据
查询 t_ds_process_instance 表,找到那些阻塞的任务实例:
SELECT id, name, state, start_time, end_time
FROM t_ds_process_instance
WHERE state NOT IN (7) -- 7 = 执行成功
ORDER BY id DESC
LIMIT 50;
状态码对照(常用):
| state | 含义 |
|---|---|
| 0 | 提交成功 |
| 1 | 正在运行 |
| 2 | 准备暂停 |
| 3 | 暂停 |
| 4 | 准备停止 |
| 5 | 停止 |
| 6 | 失败 |
| 7 | 成功 |
| 14 | 串行等待 |
果然,一堆 state = 14(串行等待)和 state = 4(准备停止)的记录:
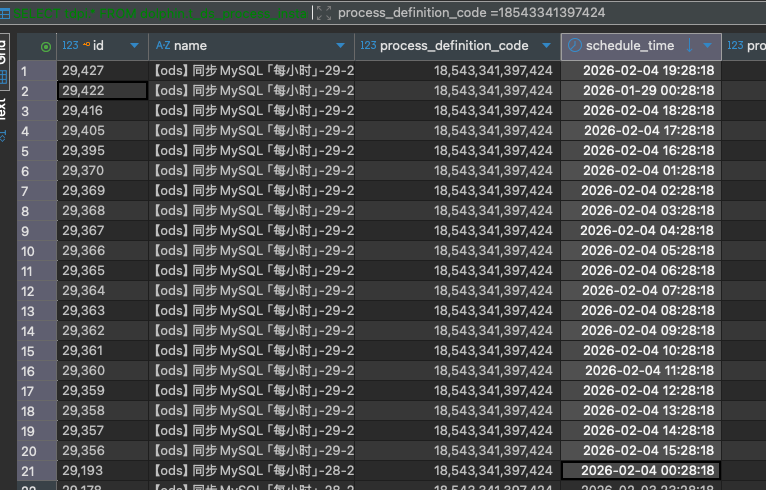
2.3 清理阻塞数据
方案一:直接删除(简单粗暴)
-- 删除阻塞的工作流实例(谨慎操作,建议先备份)
DELETE FROM t_ds_process_instance
WHERE state IN (4, 14) -- 准备停止、串行等待
AND process_definition_code = <你的工作流code>;
-- 同时清理对应的任务实例
DELETE FROM t_ds_task_instance
WHERE process_instance_id IN (
SELECT id FROM t_ds_process_instance
WHERE state IN (4, 14)
);
方案二:修改状态(相对温和)
-- 将阻塞任务改为「失败」状态,释放锁
UPDATE t_ds_process_instance
SET state = 6 -- 6 = 失败
WHERE state IN (4, 14);
注意:操作前务必备份数据,生产环境别直接 DELETE,先 SELECT 确认。
2.4 重新补数
清理完数据后,回到 DolphinScheduler 界面:
工作流定义 → 点击运行 → 选择「补数」
这次终于不报错了,任务顺利执行:
三、预防措施
吃一堑长一智,总结几点避坑经验:
3.1 慎用「串行等待」策略
| 策略 | 说明 | 适用场景 |
|---|---|---|
| 并行 | 多个实例同时运行 | 无状态任务、幂等任务 |
| 串行等待 | 排队执行,前一个完成才开始下一个 | 有严格顺序依赖的任务 |
| 串行抛弃 | 有运行中的实例时,直接丢弃新实例 | 防止任务堆积 |
| 串行优先 | 优先执行最新的实例,停止旧实例 | 只关心最新数据 |
建议:除非业务强依赖顺序,否则用「串行抛弃」代替「串行等待」,避免任务堆积导致死锁。
3.2 配置任务超时
给任务设置合理的超时时间,避免任务长时间卡住占用资源:
超时告警 + 超时失败
3.3 监控告警
- 监控 Dolphin 任务积压数量
- 监控下游服务(如 ClickHouse)的健康状态
- 任务失败及时告警,别等第二天才发现
3.4 下游服务容灾
这次事故的根源是 ClickHouse 宕机。考虑:
- CK 集群部署,避免单点故障
- 任务侧增加重试机制和熔断逻辑
- 限制并发,防止重启后任务洪峰
四、总结
问题本质:串行等待策略 + 任务异常状态 = 死锁
解决思路:UI 搞不定就直接改库,清理 t_ds_process_instance 表中的异常记录
核心教训:
- 「串行等待」是把双刃剑,用不好容易死锁
- 调度系统的数据库是最后的救命稻草
- 监控告警要到位,问题发现得越早,损失越小
希望你永远用不上这篇文章的解决方案。但如果用上了,记得先备份再动手。
如果这篇文章帮你解决了问题,欢迎点赞收藏。有更优雅的方案,欢迎评论区交流。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)