kafka入门
右上角创建主题Topic Name:Topic 的唯一标识,用于消息的发布与订阅(必填):分区数(必填)清理策略,当前选择Delete(删除),表示消息到期后直接删除;另一种常见策略是Compact(压缩),用于保留键的最新值。:副本数,决定每个分区的副本数量,提升数据可靠性,建议 ≥3。:最小同步副本数,要求至少多少个副本完成写入才认为消息提交成功,用于保证数据不丢失。
RabbitMq和kafka差别
1. 定位与设计目标
-
RabbitMQ
- 传统消息中间件
- 追求:可靠、灵活、路由强、延迟低
- 适合:业务解耦、异步通知、可靠投递
-
Kafka
- 分布式流处理平台(本质是 commit log)
- 追求:超高吞吐、顺序、可回溯、多订阅
- 适合:日志采集、大数据、监控、流计算、高并发链路
-
2.核心架构差别
-
特性 RabbitMQ Kafka 存储模型 队列 / 交换机 分区日志(append-only) 消费方式 推模式(push) 拉模式(pull) 消息顺序 单队列有序 分区内严格有序 消息回溯 不支持 支持(按 offset) 路由能力 极强(direct/topic/fanout/headers) 弱(只按 topic 匹配) - 推模式:broker主动将消息推送给消费者;
- 拉模式:消费者自己从broker中拉取消息
-
3. 性能与吞吐
- RabbitMQ:万级 TPS,低延迟,消息堆积多时性能下降
- Kafka:十万级 + TPS,堆积不影响性能,顺序写磁盘
-
4. 可靠性
- RabbitMQ:
- 消息确认、持久化、死信、事务、镜像队列
- Kafka:
- ISR 副本、acks 机制、日志落盘、幂等生产者
-
5. 适用场景
-
选 RabbitMQ :
- 复杂路由、延迟队列、死信队列
- 金融 / 支付等强可靠业务消息
- 低延迟、实时通知
-
选 Kafka :
- 高吞吐、日志 / 埋点 / 用户行为采集
- 流处理(Flink/Spark 对接)
- 多系统订阅同一份数据
- 消息可回溯、重放
-
Kafka的安装:
- 在windos上我们直接利用docker安装kafka,以及zookeeper和gui
- 创建kafka的文件夹,并创建一个配置文件docker-compose.yml
- 在yml里配置(具体网上有)
- 我们执行cd (kafka文件夹地址)
- docker-compose up -d即可创建并运行
-
kafka-gui的介绍:
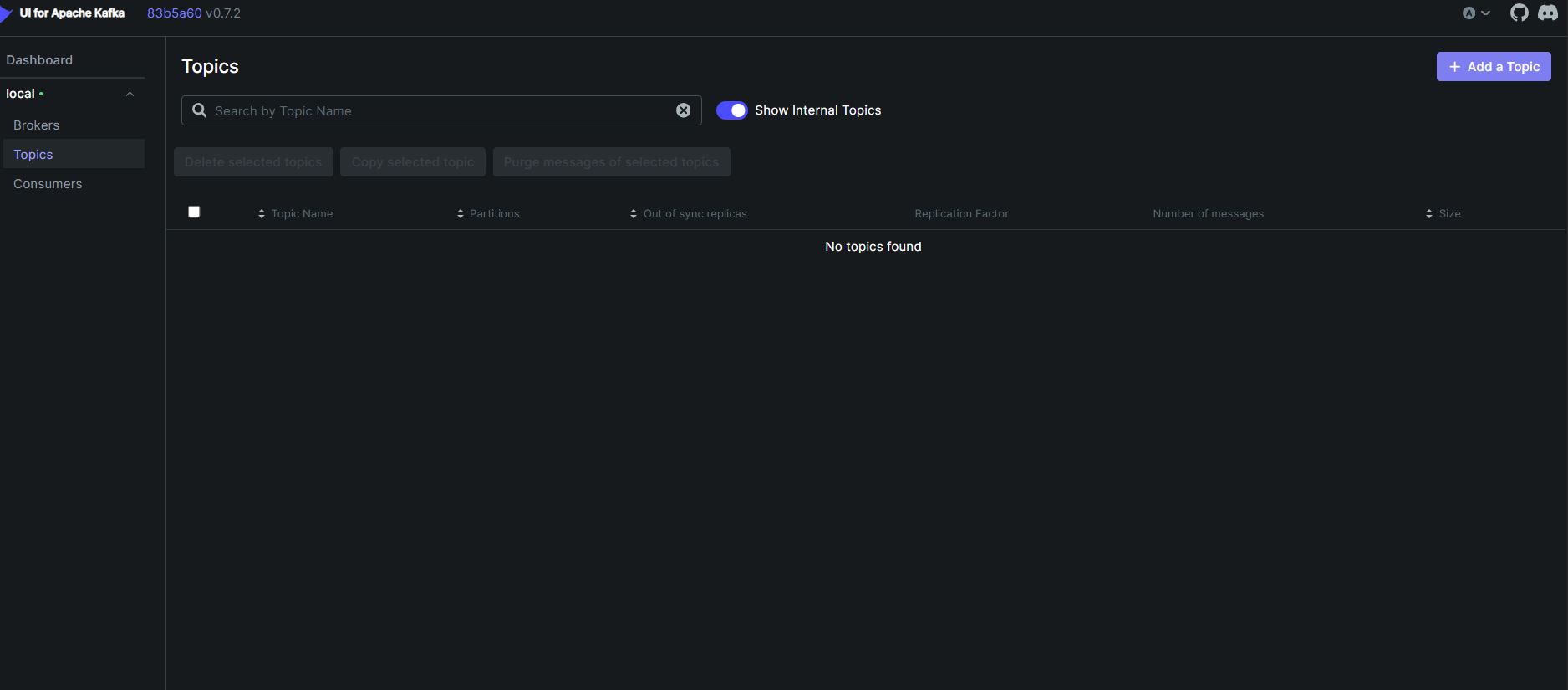
- 右上角创建主题
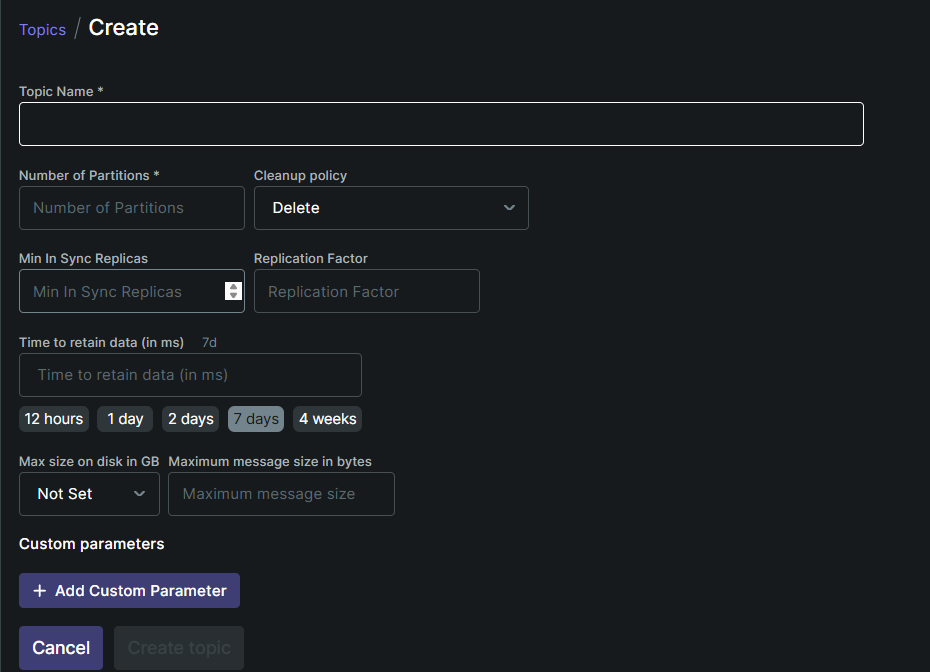
- Topic Name:Topic 的唯一标识,用于消息的发布与订阅(必填)
- Number of Partitions:分区数(必填)
- Cleanup policy:清理策略,当前选择
Delete(删除),表示消息到期后直接删除;另一种常见策略是Compact(压缩),用于保留键的最新值。 - Replication Facto:副本数,决定每个分区的副本数量,提升数据可靠性,建议 ≥3。
- Min In Sync Replicas:最小同步副本数,要求至少多少个副本完成写入才认为消息提交成功,用于保证数据不丢失。
Kafka各组件以及流程:
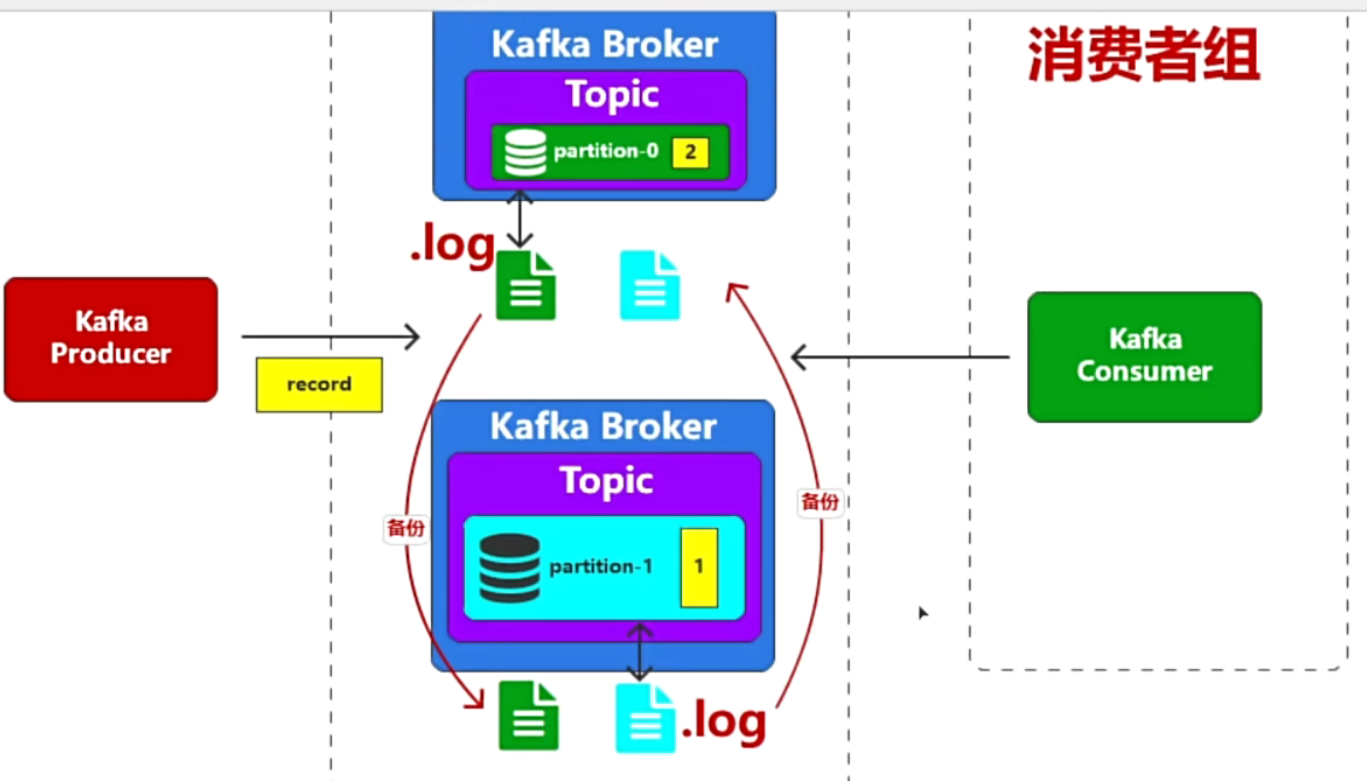
producer:消息生产者,负责将业务数据封装成消息记录,并发送给指定的topic的指定的partition特性:可以通过分区策略(轮询/hashkey)方式决定那个partition
broker:服务节点,kafka集群中的基本单元,负责消息的接受,存储,转发
topic:主题,生产者发送消息在topic,消费者订阅topic决定接受那条消息,topic本身不储存消息,只是多个partition的管理入口
partition:分区,真正的存储单元。每个partition是一个不可变的,有序的消息队列,以偏移量为唯一标识,每一个分区都有对应的独立的.log文件,是分区中的数据存储载体。分区有多个副本,包含一个Leader副本,负责信息的读写,和多个follower副本,负责拉去leader副本的最新消息,保持信息同步,这个机制实现了kafka的高可用
consumer:消息消费者,从topic中拉取消息并进行业务逻辑处理,
- 属于某个
Consumer Group(消费者组),同一 Group 内的消费者共同瓜分 Topic 的 Partition,一个 Partition 只会分配给 Group 内一个消费者。 - 通过
Offset记录消费进度,支持断点续传和回溯消费。
Kafka架构:
leader副本:
在partition中,通常有一个leader副本和多个follower副本,负责读取分区里的数据
元数据:
包括有多少topic,topic包含多少分区,
分区包含多少副本在那个topic,
每个分区的leader副本是谁
controller:
在kafka集群中有多个broker,
而其中一个broker会被选举为controller(集群唯一),管理所有分区,副本,
负责leader副本的选举,
所有元数据变更由controller发送给其他broker
zookeeper:
记录那些broker的存活,broker的上下线自动通知kafka
负责controller的选举
存储集群元数据
offset(偏移量):
消息在分区的唯一编号,分区唯一(不是全局唯一)
如果说分区是书,offset是页数
消费者组:
由多个消费者组成的消费者组,
不同的消费者组中的broker可以同时获得同一个分区里的信息,而同一个消费者组里的只能有一个broker获取同一个消息
不同消费者组之间互不影响
在java中使用:
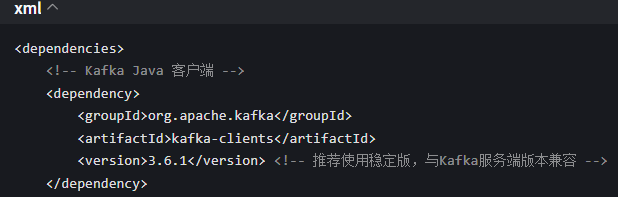
1.引入依赖
2.配置和创建生产者
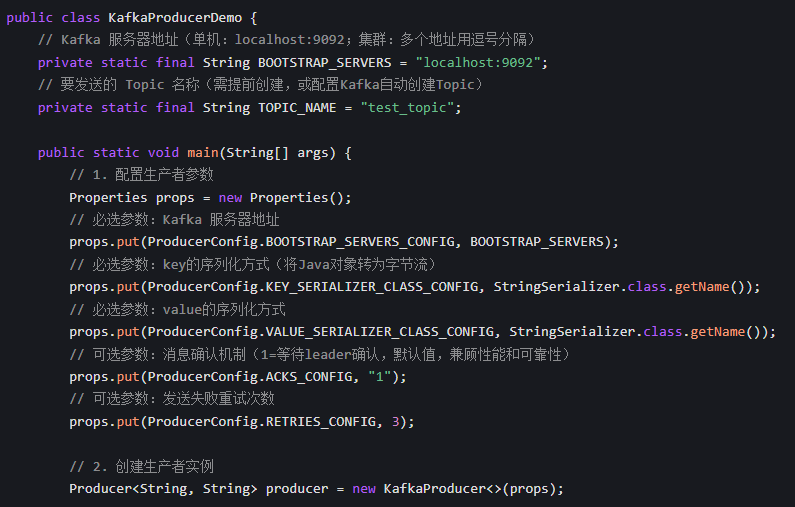
ACKS_CONFIG:消息确认级别
0:发送即忘,性能最高,可能丢消息;1:Leader 接收并确认,默认值;all:Leader + 所有副本确认,最可靠,性能最低。
生产者和消费者以key-value格式,key为分区的标准,默认利用key的哈希值分组
也可以自己实现分区策略
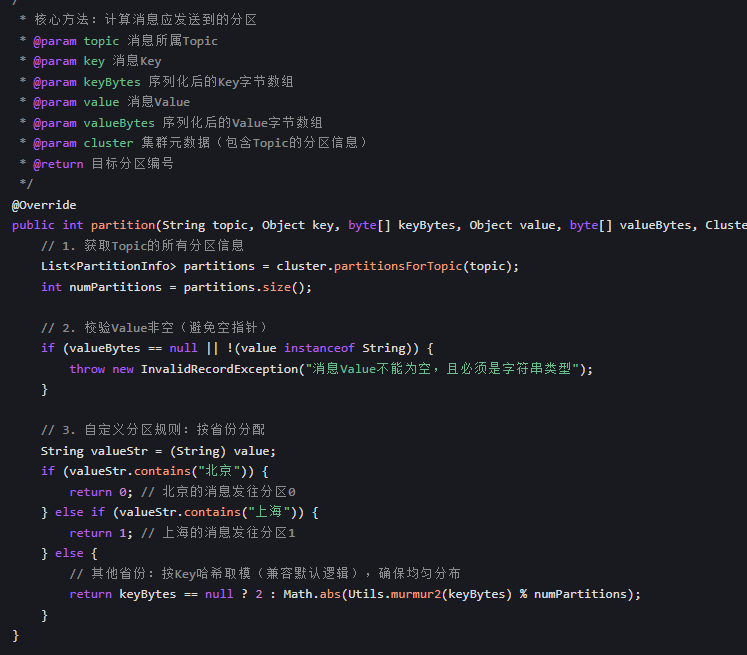
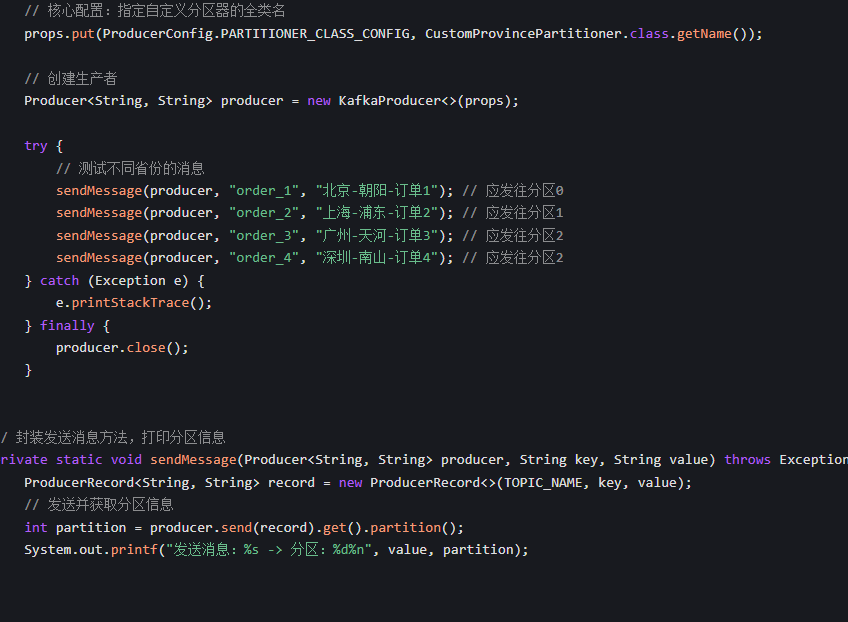
在生产者配置中配置
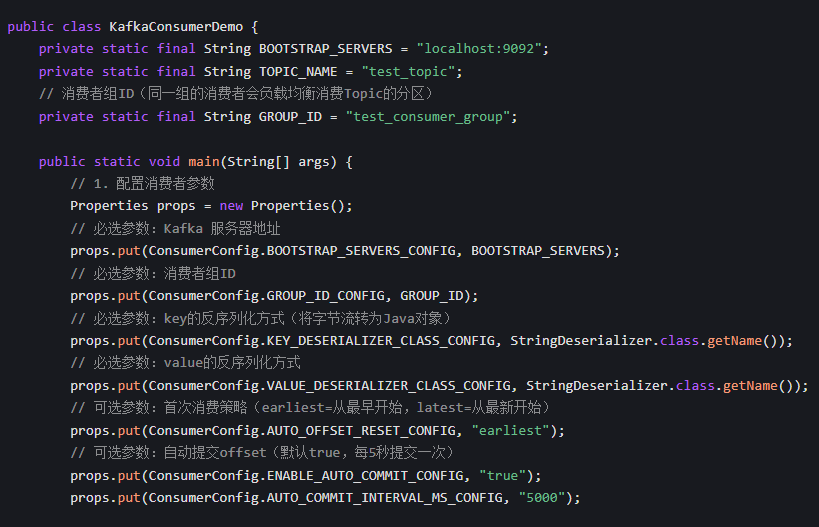
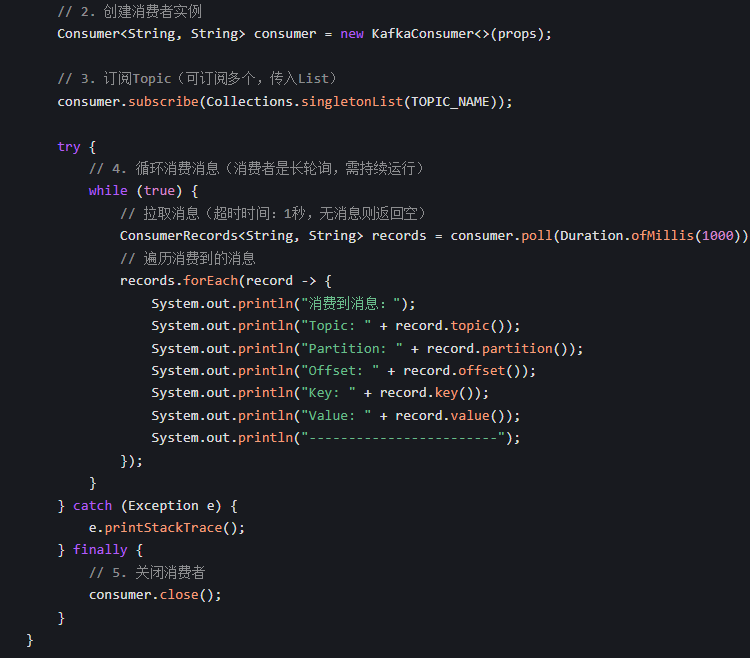
3.消费者配置:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)