基于OpenCV的图片文本信息提取工具
本项目是一个基于深度学习的图片文本信息提取系统,集成了文本检测与识别两大核心功能。系统采用YOLOv8进行文本区域检测,使用PaddleOCR进行文字识别,并通过Streamlit构建了友好的Web交互界面。
基于OpenCV的图片文本信息提取工具
目录
1. 项目概述
1.1 项目背景
本项目是一个基于深度学习的图片文本信息提取系统,集成了文本检测与识别两大核心功能。系统采用YOLOv8进行文本区域检测,使用PaddleOCR进行文字识别,并通过Streamlit构建了友好的Web交互界面。
1.2 核心技术栈
- 文本检测: YOLOv8 (Ultralytics)
- 文本识别: PaddleOCR v4
- 前端框架: Streamlit
- 数据处理: OpenCV, NumPy, Pandas
- 可视化: Plotly, Matplotlib
- 数据库: SQLite3
- 深度学习框架: PyTorch, PaddlePaddle
1.3 系统特点
- 实时文本检测与识别
- 多数据集统计分析
- 完整的训练与评估流程
- 历史记录追踪
- 可视化模型性能分析
2. 系统架构
2.1 整体架构图
┌─────────────────────────────────────────────────────────┐
│ Streamlit Web界面层 │
├─────────────────────────────────────────────────────────┤
│ 系统介绍 │ 数据分析 │ 文本检测 │ 文本识别 │ 历史记录 │
├─────────────────────────────────────────────────────────┤
│ 业务逻辑层 │
├──────────────────────┬──────────────────────────────────┤
│ YOLOv8检测模块 │ PaddleOCR识别模块 │
├──────────────────────┴──────────────────────────────────┤
│ 数据处理层 │
│ OpenCV │ NumPy │ Pandas │ Plotly │
├─────────────────────────────────────────────────────────┤
│ 数据存储层 │
│ SQLite数据库 │ 文件系统 │
└─────────────────────────────────────────────────────────┘
2.2 技术架构说明
表示层: 使用Streamlit构建Web界面,提供用户交互功能
业务层:
- 文本检测模块:基于YOLOv8实现文本区域定位
- 文本识别模块:基于PaddleOCR实现文字内容识别
数据层:
- SQLite数据库存储历史记录
- 文件系统存储模型、数据集和训练结果
3. 数据集介绍
3.1 ICDAR2013数据集
数据集概述:
- 用途: 场景文本检测
- 图片数量: 462张
- 标注数量: 1944个文本区域
- 格式: COCO JSON格式
- 类别: 1类 (text)
数据特点:
- 包含自然场景中的文本图片
- 标注了文本的边界框位置
- 适用于文本检测模型训练
数据转换:
使用data_utils.py将COCO格式转换为YOLO格式:
- 训练集/验证集按4:1划分
- 边界框坐标归一化
- 生成对应的标签文件
3.2 SCUT-CTW1500数据集
数据集概述:
- 用途: 曲线文本检测
- 训练图片: 1000张
- 测试图片: 500张
- 训练标注: 1000个XML文件
- 测试标注: 1500个TXT文件
数据特点:
- 专注于曲线和任意形状文本
- 包含复杂场景文本
- 提供详细的多边形标注
3.3 PaddleOCR识别数据集
数据集概述:
- 用途: 文本识别模型训练
- 训练样本: 4468个
- 测试样本: 数百个
- 格式: 图片+标签文本
数据特点:
- 包含中文字符识别样本
- 每行格式:
图片路径\t文本内容 - 适用于序列识别任务
4. 算法原理
4.1 YOLOv8文本检测算法
算法架构:
YOLOv8是YOLO系列的最新版本,采用anchor-free检测方式。
核心特点:
- Backbone: CSPDarknet53,提取多尺度特征
- Neck: PANet结构,融合不同层级特征
- Head: 解耦头设计,分离分类和回归任务
- 损失函数: CIoU Loss + BCE Loss
检测流程:
输入图像 → 预处理(640×640) → 特征提取 → 多尺度检测 → NMS后处理 → 输出边界框
训练策略:
- 输入尺寸: 640×640
- 批次大小: 16
- 训练轮数: 100 epochs
- 优化器: AdamW
- 学习率: 0.01 (余弦退火)
- 数据增强: Mosaic, MixUp, HSV变换
4.2 PaddleOCR文本识别算法
算法架构:
PaddleOCR采用经典的检测+识别两阶段方案。
识别模型结构:
- 特征提取: MobileNetV3/ResNet作为骨干网络
- 序列建模: BiLSTM捕获上下文信息
- 解码器: CTC解码输出文本序列
识别流程:
文本区域图像 → 预处理 → 特征提取 → 序列建模 → CTC解码 → 输出文本+置信度
技术优势:
- 支持80+语言识别
- 轻量级模型设计
- 高精度识别效果
- CPU/GPU灵活部署
5. 模型训练
5.1 训练环境配置
硬件环境:
- CPU: Intel/AMD处理器
- 内存: 16GB+
- 存储: 50GB+
软件环境:
- Python 3.8+
- PyTorch 2.0+
- CUDA 11.8 (可选)
- Conda环境: ocr-training
5.2 训练过程
数据准备:
- 数据集格式转换 (COCO → YOLO)
- 数据集划分 (训练集/验证集)
- 数据增强配置
模型训练:
# YOLOv8训练命令
yolo detect train data=dataset.yaml model=yolov8n.pt epochs=100 imgsz=640
训练监控:
- 实时损失曲线
- 验证集精度
- 学习率变化
- 训练时间统计
5.3 训练结果分析
5.3.1 训练曲线

曲线说明:
- train/box_loss: 边界框回归损失,反映定位精度
- train/cls_loss: 分类损失,反映类别预测准确性
- train/dfl_loss: 分布焦点损失,优化边界框质量
- metrics/precision: 精确率,预测为正样本中真正为正的比例
- metrics/recall: 召回率,所有正样本中被正确预测的比例
- metrics/mAP50: 在IoU=0.5时的平均精度
- metrics/mAP50-95: IoU从0.5到0.95的平均精度
5.3.2 精确率曲线

分析:
- 横轴: 置信度阈值
- 纵轴: 精确率
- 曲线显示不同置信度下的精确率变化
- 用于选择最优检测阈值
5.3.3 召回率曲线
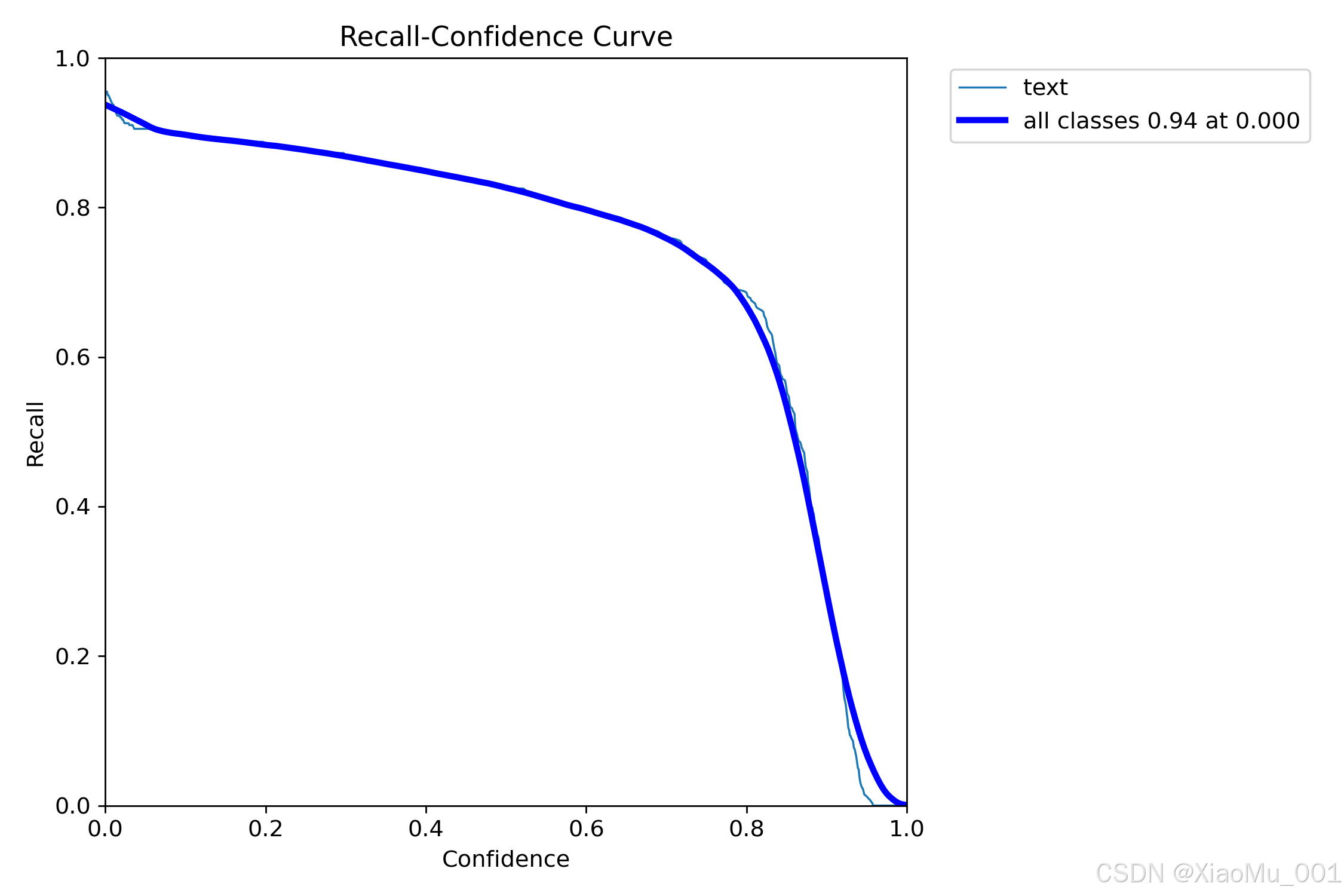
分析:
- 横轴: 置信度阈值
- 纵轴: 召回率
- 反映模型检测文本区域的完整性
- 高召回率意味着漏检率低
5.3.4 F1分数曲线
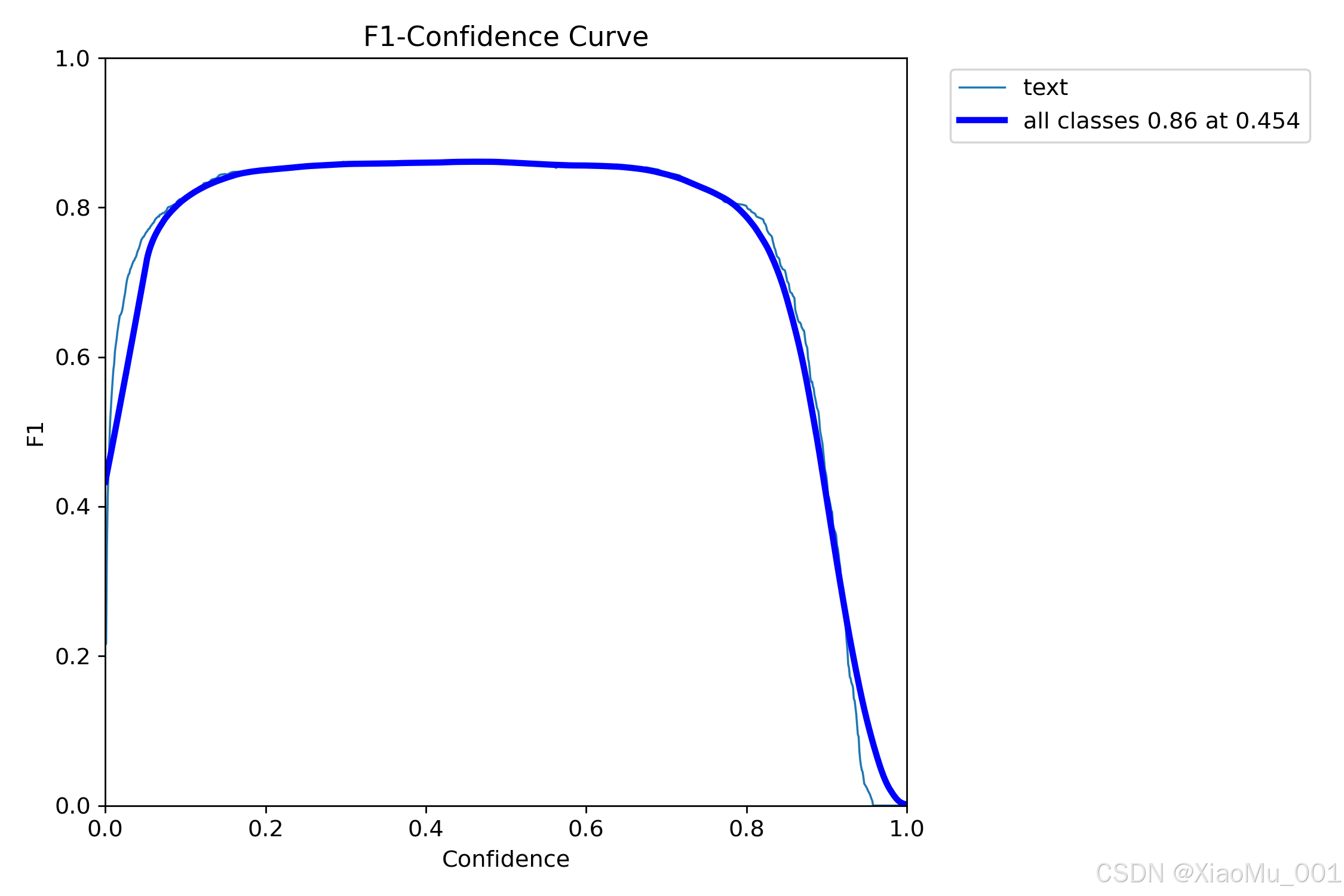
分析:
- F1 = 2 × (Precision × Recall) / (Precision + Recall)
- 综合评估精确率和召回率
- 曲线峰值对应最优置信度阈值
5.3.5 PR曲线
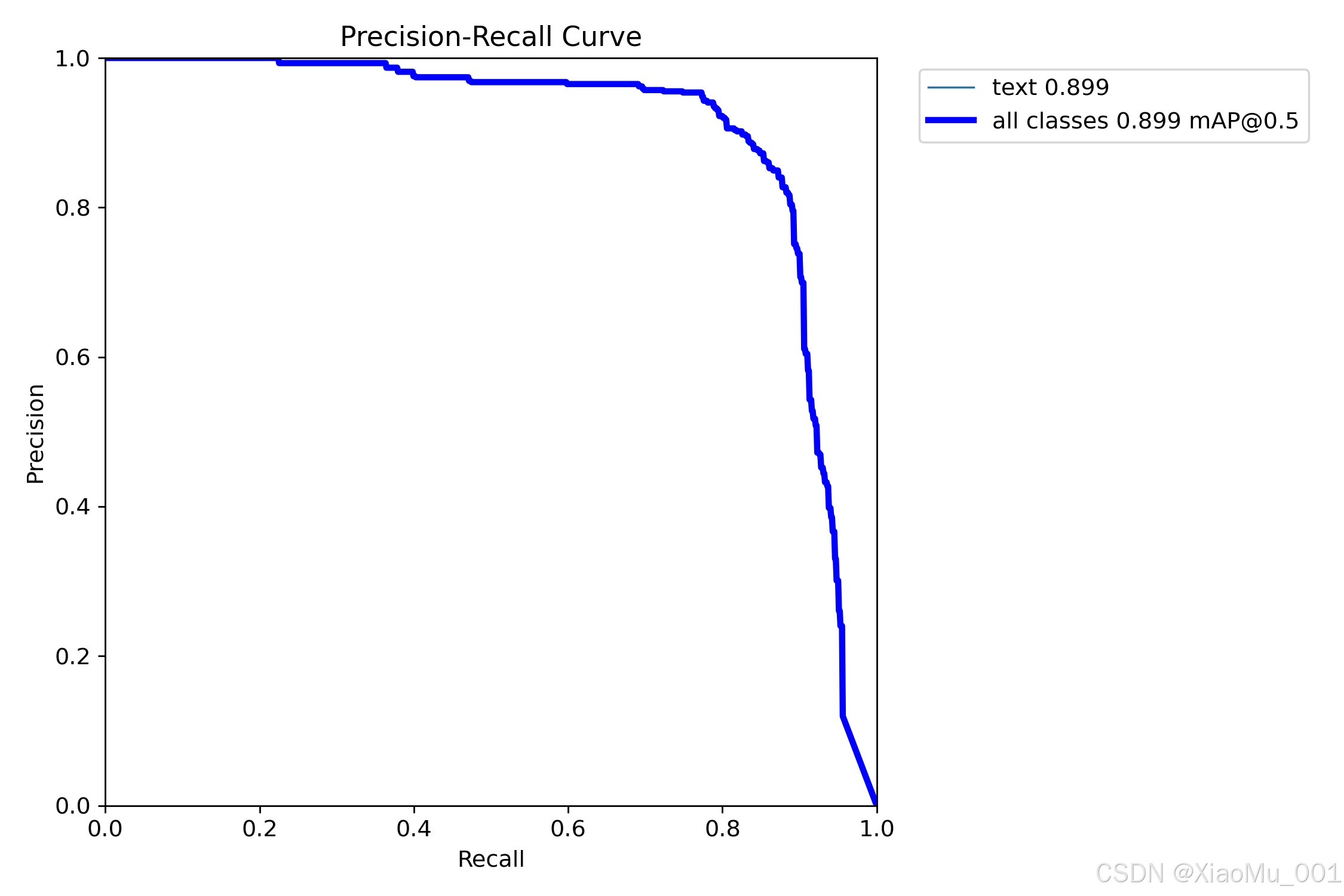
分析:
- 横轴: 召回率
- 纵轴: 精确率
- 曲线下面积(AUC)反映模型整体性能
- 曲线越靠近右上角,性能越好
5.3.6 混淆矩阵
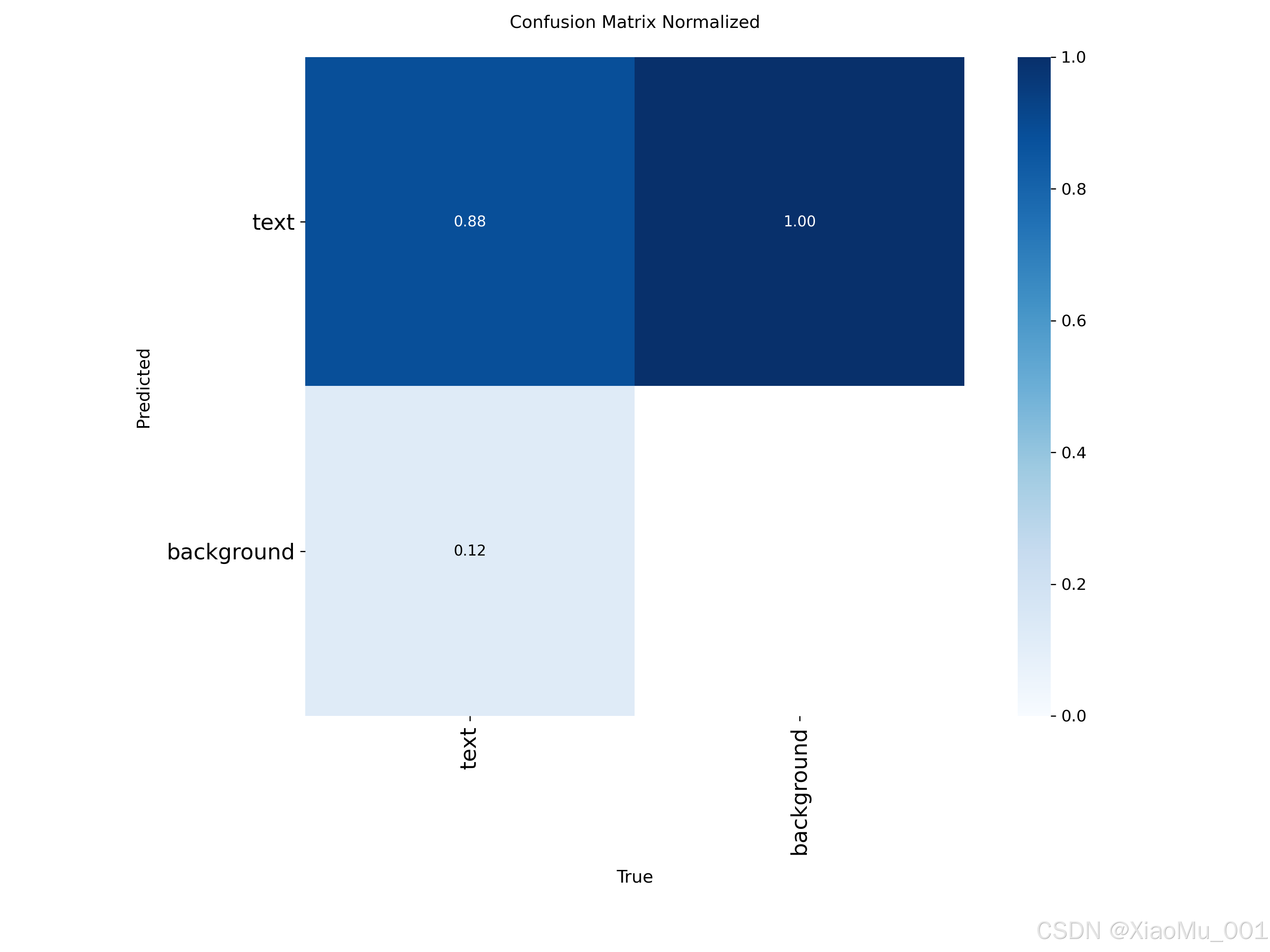
分析:
- 对角线: 正确分类的样本比例
- 非对角线: 误分类情况
- 归一化显示,便于不同类别对比
5.3.7 标签分布
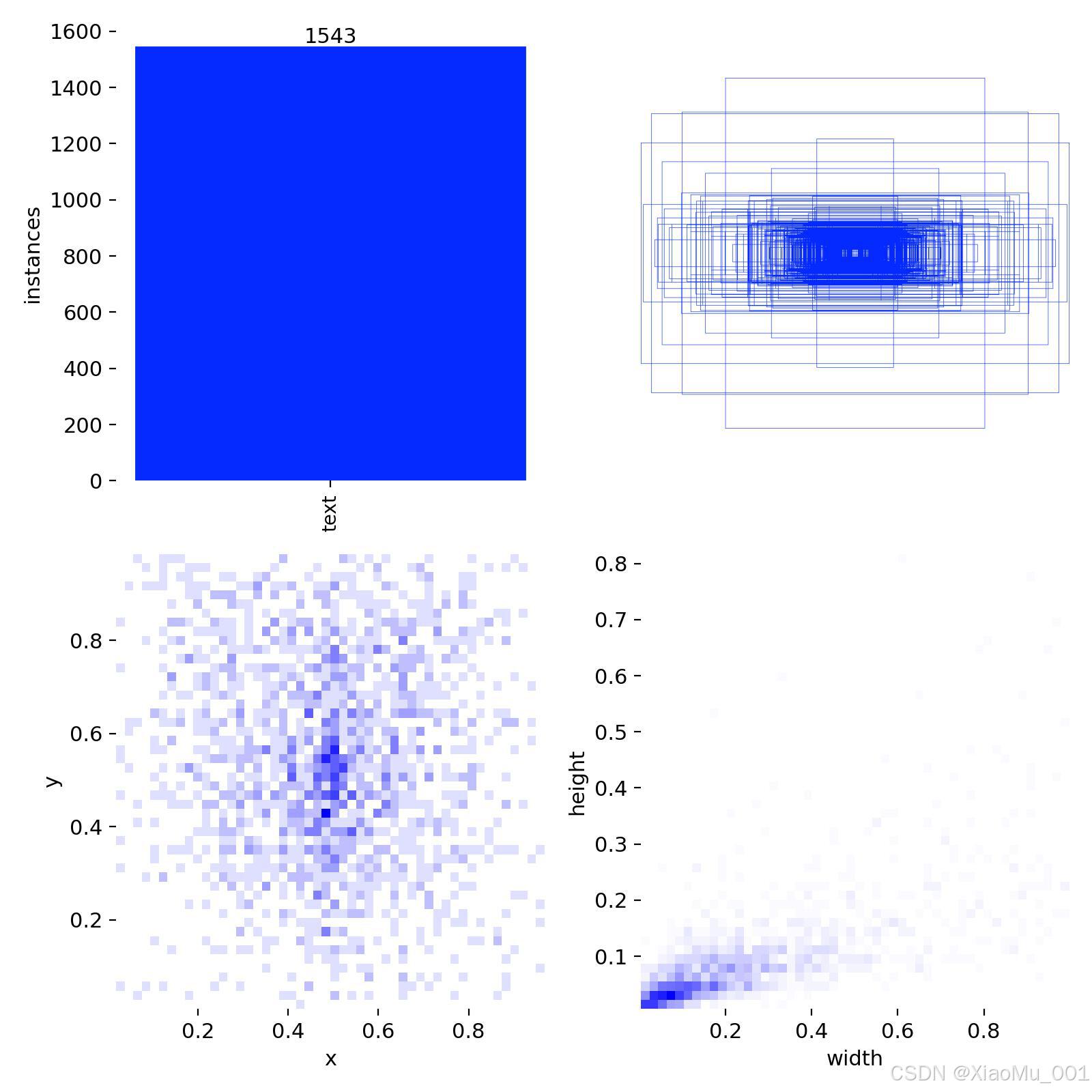
分析:
- 显示数据集中标注框的尺寸分布
- 帮助理解数据集特征
- 指导anchor设计和数据增强策略
5.3.8 训练结果示例
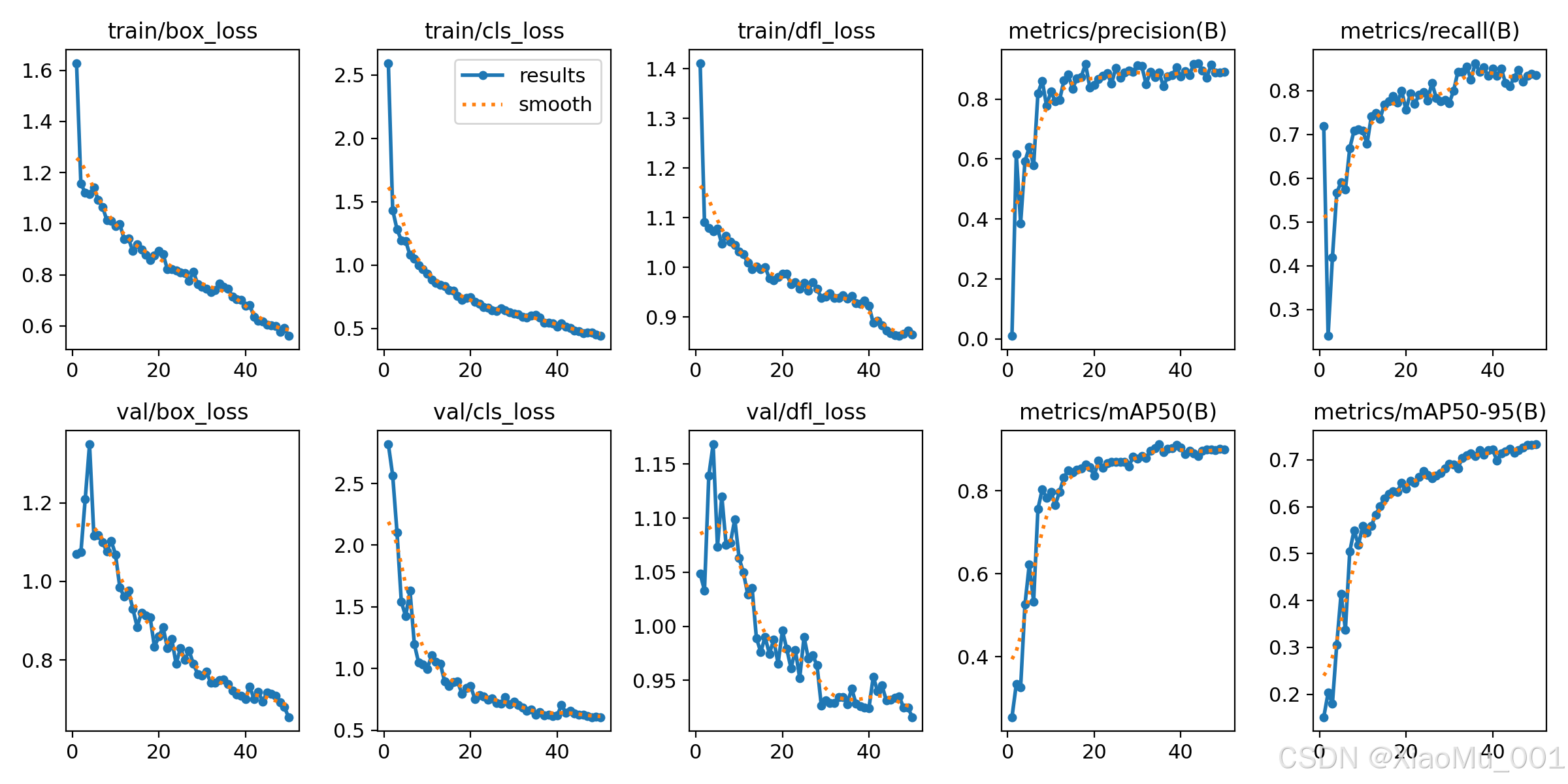
说明:
- 展示各项指标随训练进程的变化
- 包括损失、精度、召回率、mAP等
- 用于判断模型收敛情况
5.3.9 验证集预测结果

说明:
- 展示模型在验证集上的检测效果
- 绿色框: 真实标注
- 红色框: 模型预测
- 直观评估模型性能
6. 数据库设计
6.1 数据库概述
系统使用SQLite3轻量级数据库存储检测识别历史记录,数据库文件为history.db。
6.2 表结构设计
6.2.1 detection_history表
表名: detection_history
表说明: 存储文本检测和识别的历史记录
字段详情:
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 默认值 | 说明 |
|---|---|---|---|---|---|---|---|
| id | INTEGER | - | 是 | 是 | 是 | 自增 | 记录唯一标识符 |
| timestamp | TEXT | 50 | 是 | 否 | 否 | - | 记录创建时间 (YYYY-MM-DD HH:MM:SS) |
| image_name | TEXT | 255 | 是 | 否 | 否 | - | 上传图片的文件名 |
| detect_count | INTEGER | - | 是 | 否 | 否 | 0 | 检测到的文本区域数量 |
| recognize_text | TEXT | - | 否 | 否 | 否 | NULL | 识别出的文本内容 (多个文本用换行分隔) |
| confidence | REAL | - | 否 | 否 | 否 | NULL | 平均识别置信度 (0.0-1.0) |
建表SQL:
CREATE TABLE IF NOT EXISTS detection_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
image_name TEXT NOT NULL,
detect_count INTEGER NOT NULL DEFAULT 0,
recognize_text TEXT,
confidence REAL
);
索引设计:
-- 时间索引,加速按时间查询
CREATE INDEX idx_timestamp ON detection_history(timestamp);
-- 图片名索引,加速按图片查询
CREATE INDEX idx_image_name ON detection_history(image_name);
6.3 数据操作
插入记录:
cursor.execute('''
INSERT INTO detection_history
(timestamp, image_name, detect_count, recognize_text, confidence)
VALUES (?, ?, ?, ?, ?)
''', (timestamp, image_name, detect_count, recognize_text, confidence))
查询记录:
# 查询所有记录
cursor.execute('SELECT * FROM detection_history ORDER BY timestamp DESC')
# 按时间范围查询
cursor.execute('''
SELECT * FROM detection_history
WHERE timestamp BETWEEN ? AND ?
ORDER BY timestamp DESC
''', (start_time, end_time))
统计分析:
# 统计总记录数
cursor.execute('SELECT COUNT(*) FROM detection_history')
# 统计平均检测数量
cursor.execute('SELECT AVG(detect_count) FROM detection_history')
# 统计平均置信度
cursor.execute('SELECT AVG(confidence) FROM detection_history WHERE confidence IS NOT NULL')
7. 系统功能
7.1 系统介绍模块

功能说明:
- 展示系统整体架构和技术栈
- 介绍核心功能模块
- 说明系统特点和优势
- 提供快速入门指南
界面特点:
- 清晰的模块划分
- 直观的功能介绍
- 友好的用户引导
7.2 数据统计分析模块
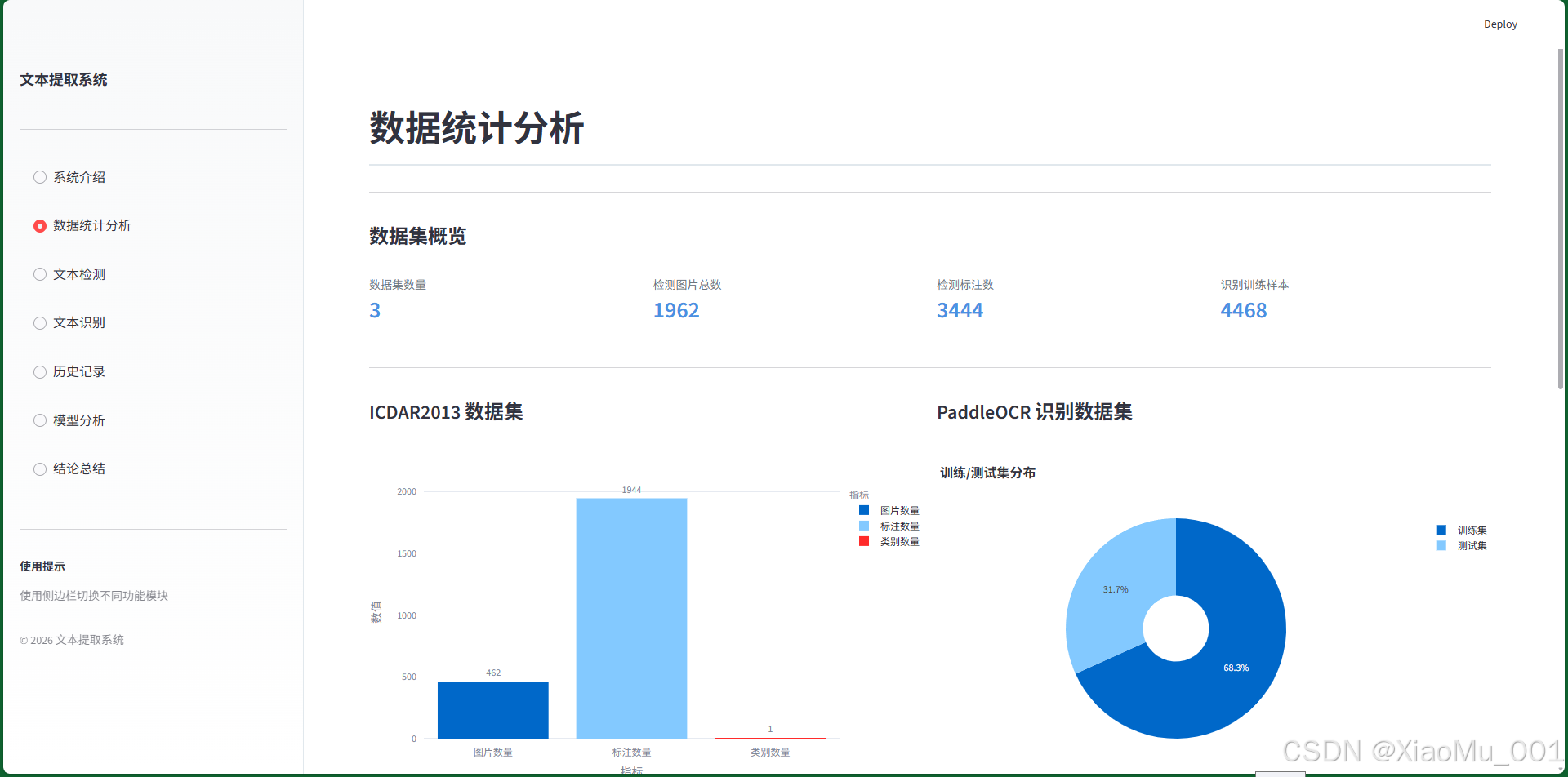
功能说明:
- 统计三个数据集的基本信息
- 可视化数据分布情况
- 对比不同数据集特征
- 展示数据集详细信息
统计指标:
- 数据集数量: 3个
- 总图片数: 1962张 (ICDAR2013: 462 + SCUT-CTW1500: 1500)
- 标注数量: 4444个 (检测标注: 1944 + 1000 + 1500)
- 训练样本: 4468个 (PaddleOCR识别样本)
可视化图表:
- 数据集规模对比柱状图
- 图片数量分布饼图
- 标注类型统计图
- 数据集详细信息表格
7.3 文本检测模块
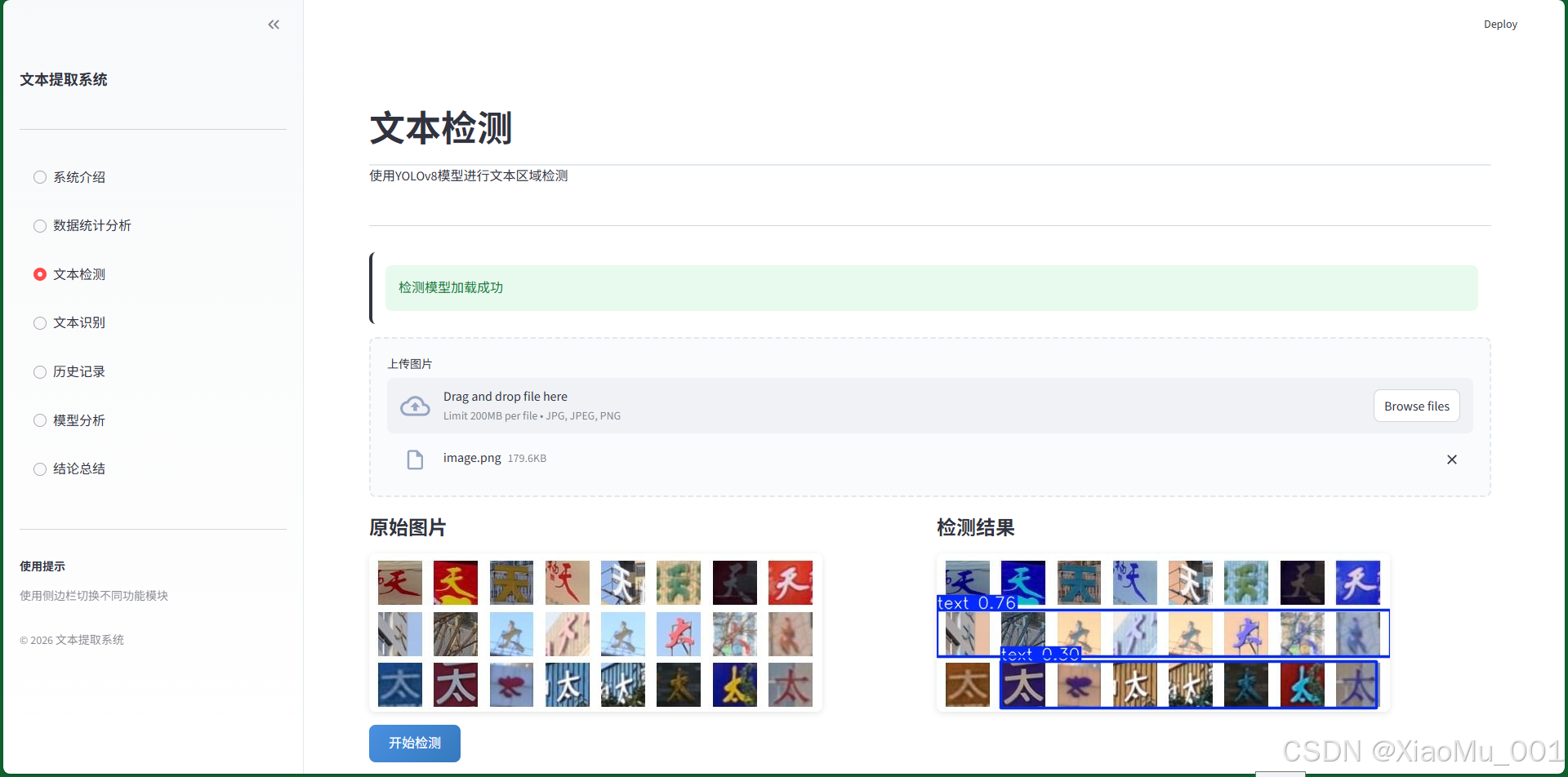
功能说明:
- 上传图片进行文本区域检测
- 实时显示检测结果
- 标注文本边界框
- 显示检测置信度
使用流程:
- 点击"上传图片"按钮
- 选择待检测的图片文件
- 系统自动进行文本检测
- 显示标注后的结果图像
- 展示检测到的文本区域数量
技术实现:
- 模型: YOLOv8n
- 模型路径:
runs/detect/text_detect/weights/best.pt - 推理设备: CPU
- 输入尺寸: 640×640
- 置信度阈值: 0.25
7.4 文本识别模块
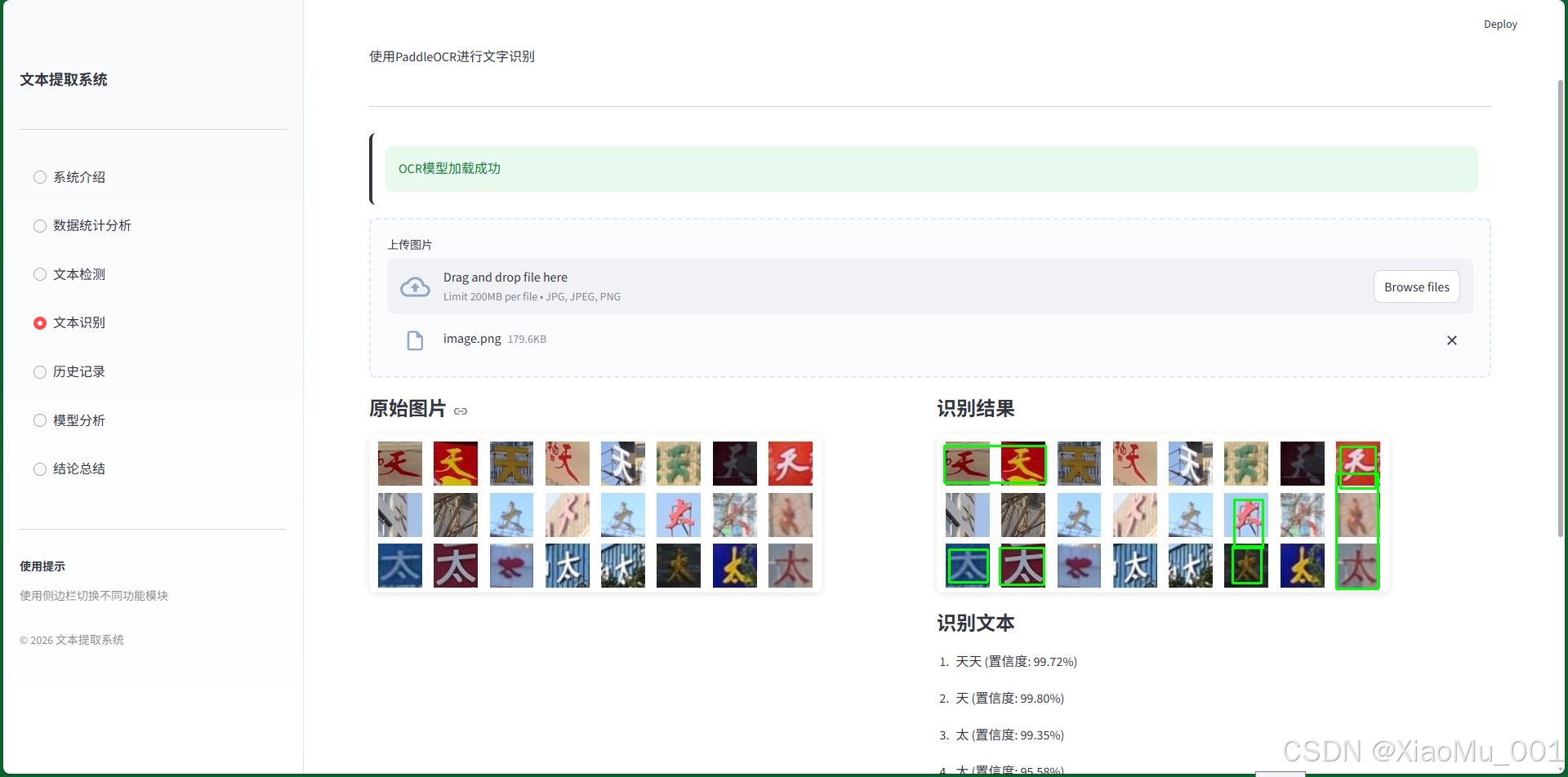
功能说明:
- 对检测到的文本区域进行识别
- 提取文字内容
- 显示识别置信度
- 支持中英文混合识别
使用流程:
- 上传包含文本的图片
- 系统先进行文本检测
- 对每个文本区域进行识别
- 显示识别结果和置信度
- 结果自动保存到数据库
技术实现:
- 模型: PaddleOCR v4
- 语言: 中文+英文
- 识别方向: 支持旋转文本
- 输出: 文本内容 + 置信度
7.5 历史记录模块
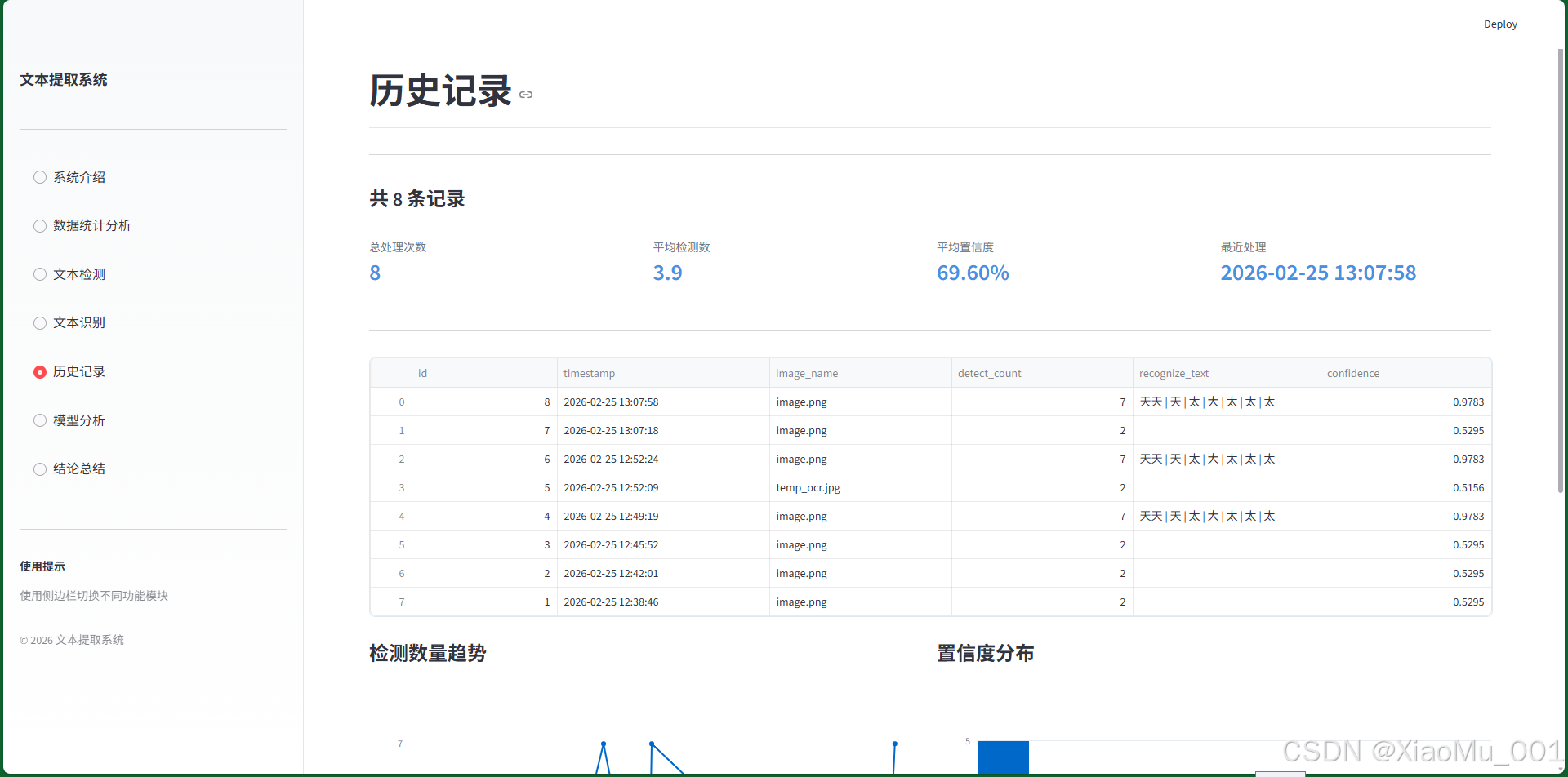
功能说明:
- 查看所有检测识别历史
- 按时间倒序排列
- 显示详细记录信息
- 支持数据导出
记录信息:
- 记录ID
- 处理时间
- 图片名称
- 检测数量
- 识别文本
- 平均置信度
数据展示:
- 表格形式展示
- 支持分页浏览
- 可按条件筛选
- 统计汇总信息
7.6 模型分析模块
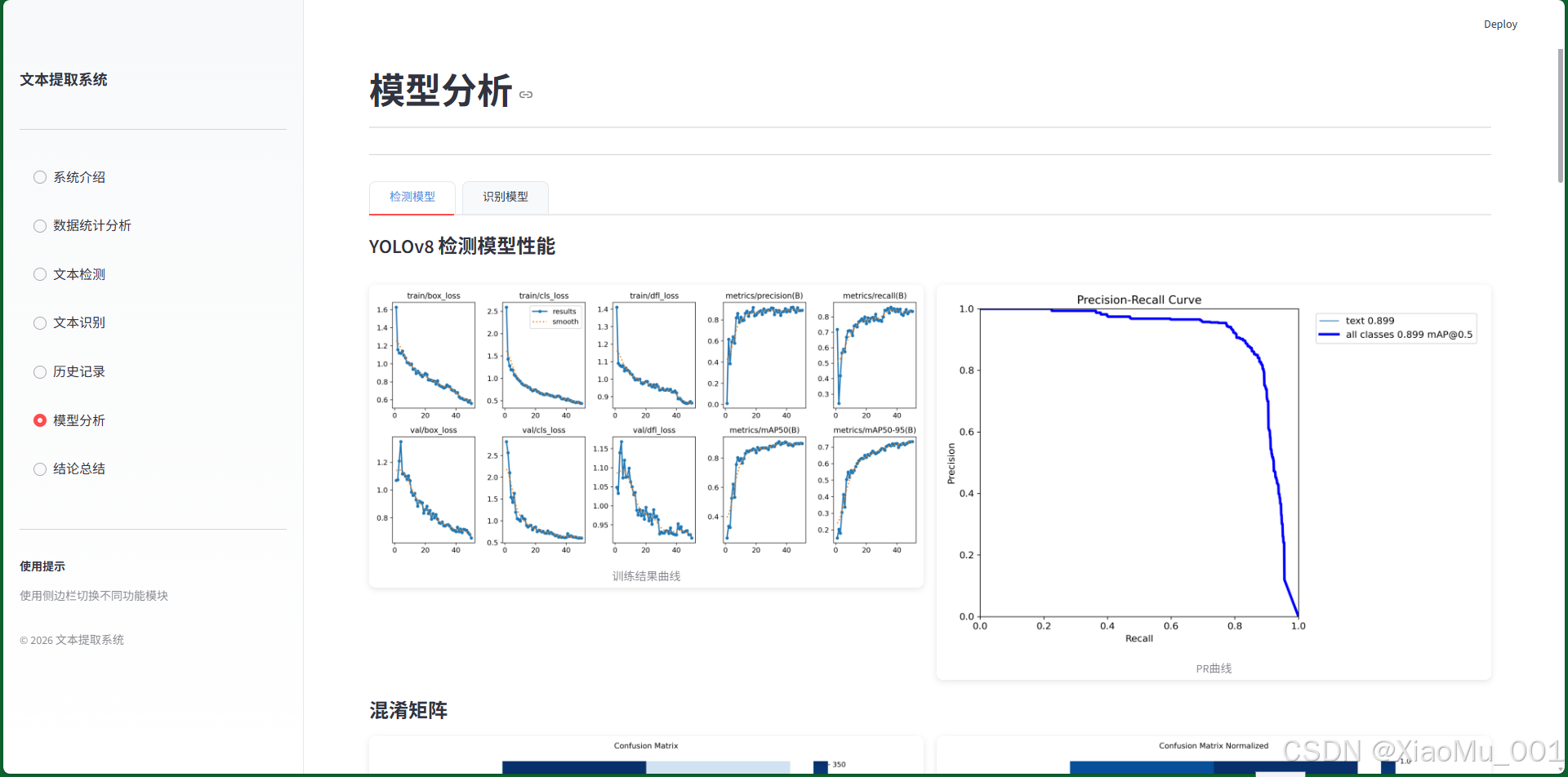
功能说明:
- 展示模型训练指标
- 可视化性能曲线
- 分析模型优缺点
- 提供优化建议
分析内容:
- 训练损失曲线
- 精确率/召回率曲线
- mAP指标变化
- 混淆矩阵分析
- 验证集预测结果
性能指标:
- mAP50: 模型在IoU=0.5时的平均精度
- mAP50-95: 综合评估指标
- Precision: 精确率
- Recall: 召回率
- F1-Score: 综合评分
8. 技术实现
8.1 核心技术
8.1.1 YOLOv8文本检测
实现原理:
YOLOv8采用端到端的检测方式,将图像划分为网格,每个网格预测边界框和类别概率。
代码实现:
from ultralytics import YOLO
# 加载模型
model = YOLO('runs/detect/text_detect/weights/best.pt')
model.to('cpu') # 使用CPU推理
# 进行检测
results = model(image, device='cpu', conf=0.25)
# 获取检测结果
boxes = results[0].boxes
for box in boxes:
x1, y1, x2, y2 = box.xyxy[0]
confidence = box.conf[0]
class_id = box.cls[0]
优化策略:
- 使用CPU推理,避免CUDA依赖
- 设置合适的置信度阈值
- 图像预处理优化
- 批量推理提升效率
8.1.2 PaddleOCR文本识别
实现原理:
PaddleOCR采用检测+识别的两阶段方案,先定位文本区域,再识别文字内容。
代码实现:
from paddleocr import PaddleOCR
# 初始化OCR
ocr = PaddleOCR(
use_angle_cls=True, # 使用方向分类器
lang='ch', # 中文识别
use_gpu=False # 使用CPU
)
# 进行识别
result = ocr.ocr(image_path, cls=True)
# 解析结果
for line in result[0]:
text = line[1][0] # 文本内容
confidence = line[1][1] # 置信度
技术特点:
- 支持多语言识别
- 自动文本方向检测
- 高精度识别效果
- 轻量级模型设计
8.1.3 Streamlit界面开发
实现原理:
Streamlit是一个Python Web框架,通过简单的API快速构建数据应用。
代码实现:
import streamlit as st
# 页面配置
st.set_page_config(
page_title="文本提取系统",
page_icon="📝",
layout="wide"
)
# 侧边栏导航
page = st.sidebar.radio("导航", ["系统介绍", "数据统计", ...])
# 文件上传
uploaded_file = st.file_uploader("上传图片", type=['jpg', 'png'])
# 图片显示
st.image(image, caption="检测结果")
# 数据表格
st.dataframe(df)
# 图表展示
st.plotly_chart(fig)
界面优化:
- 自定义CSS样式
- 响应式布局设计
- 交互组件优化
- 加载动画效果
8.2 数据处理流程
8.2.1 数据集转换
COCO转YOLO格式:
def coco_to_yolo(coco_json, output_dir):
# 读取COCO JSON
with open(coco_json, 'r') as f:
data = json.load(f)
# 转换每个标注
for ann in data['annotations']:
image_id = ann['image_id']
bbox = ann['bbox'] # [x, y, w, h]
# 归一化坐标
x_center = (bbox[0] + bbox[2]/2) / img_width
y_center = (bbox[1] + bbox[3]/2) / img_height
width = bbox[2] / img_width
height = bbox[3] / img_height
# 写入YOLO格式
with open(f'{output_dir}/{image_id}.txt', 'a') as f:
f.write(f'0 {x_center} {y_center} {width} {height}\n')
8.2.2 图像预处理
预处理流程:
import cv2
import numpy as np
def preprocess_image(image):
# 1. 读取图像
img = cv2.imread(image)
# 2. 调整大小
img = cv2.resize(img, (640, 640))
# 3. 颜色空间转换
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 4. 归一化
img = img / 255.0
# 5. 转换为张量
img = np.transpose(img, (2, 0, 1))
return img
8.2.3 后处理优化
NMS非极大值抑制:
def nms(boxes, scores, iou_threshold=0.5):
# 按置信度排序
indices = np.argsort(scores)[::-1]
keep = []
while len(indices) > 0:
# 保留置信度最高的框
current = indices[0]
keep.append(current)
# 计算IoU
ious = compute_iou(boxes[current], boxes[indices[1:]])
# 过滤重叠框
indices = indices[1:][ious < iou_threshold]
return keep
8.3 性能优化
8.3.1 推理加速
优化策略:
- 使用CPU推理,避免GPU依赖问题
- 批量处理多张图片
- 模型量化压缩
- 图像尺寸优化
8.3.2 内存优化
优化方法:
- 及时释放不用的变量
- 使用生成器处理大数据
- 图像分块处理
- 缓存机制优化
8.3.3 数据库优化
优化措施:
- 添加索引加速查询
- 批量插入数据
- 定期清理历史数据
- 连接池管理
9. 目录结构
9.1 项目目录树
algorithm/
├── streamlit_app.py # Streamlit主程序
├── data_utils.py # 数据处理工具
├── history.db # SQLite历史数据库
├── image.png # 测试图片
├── test-paddleocr.py # PaddleOCR测试脚本
│
├── ICDAR2013-Focused-Scene-Text-COCO-master/ # ICDAR2013数据集
│ ├── ICDAR2013.json # COCO格式标注
│ ├── ImageSets/ # 数据集划分
│ │ └── Main/
│ │ ├── test.txt # 测试集列表
│ │ └── trainval.txt # 训练验证集列表
│ └── JPEGImages/ # 图片文件 (462张)
│
├── SCUT-CTW1500/ # SCUT-CTW1500数据集
│ └── raw/ # 原始数据
│ ├── train_images/ # 训练图片 (1000张)
│ ├── test_images/ # 测试图片 (500张)
│ ├── ctw1500_train_labels/ # 训练标注 (1000个XML)
│ └── gt_ctw1500/ # 测试标注 (1500个TXT)
│
├── paddle_rec_data/ # PaddleOCR识别数据集
│ ├── train_data/ # 训练数据
│ │ ├── images/ # 图片文件
│ │ └── train_list.txt # 训练列表 (4468条)
│ └── test_data/ # 测试数据
│ ├── images/ # 图片文件
│ └── test_list.txt # 测试列表
│
├── PaddleOCR/ # PaddleOCR源码
│ ├── ppocr/ # 核心代码
│ ├── configs/ # 配置文件
│ ├── tools/ # 训练工具
│ └── doc/ # 文档
│
└── runs/ # 训练输出目录
├── detect/ # 检测模型
│ └── text_detect/
│ ├── weights/
│ │ └── best.pt # 最佳模型权重
│ ├── BoxF1_curve.png # F1曲线
│ ├── BoxP_curve.png # 精确率曲线
│ ├── BoxPR_curve.png # PR曲线
│ ├── BoxR_curve.png # 召回率曲线
│ ├── confusion_matrix_normalized.png # 混淆矩阵
│ ├── labels.jpg # 标签分布
│ ├── results.png # 训练结果
│ ├── training_curves.png # 训练曲线
│ └── val_batch0_pred.jpg # 验证预测
└── train/ # 训练记录
explaination/ # 说明文档目录
├── 详解.md # 本文档
└── images/ # 图片资源
├── system/ # 系统界面截图
│ ├── 系统介绍.png
│ ├── 数据统计分析.png
│ ├── 文本检测.png
│ ├── 文本识别.png
│ ├── 历史记录.png
│ └── 模型分析.png
└── algorithm/ # 算法图表
├── BoxF1_curve.png
├── BoxP_curve.png
├── BoxPR_curve.png
├── BoxR_curve.png
├── confusion_matrix_normalized.png
├── labels.jpg
├── results.png
├── training_curves.png
└── val_batch0_pred.jpg
9.2 关键文件说明
streamlit_app.py:
- 系统主程序
- 包含7个功能模块
- 实现Web界面交互
- 集成检测识别功能
data_utils.py:
- 数据格式转换工具
- COCO转YOLO格式
- 数据集划分功能
- 标注文件处理
history.db:
- SQLite数据库文件
- 存储历史记录
- 包含detection_history表
- 支持查询统计
best.pt:
- YOLOv8训练的最佳模型
- 用于文本检测
- 输入640×640图像
- 输出文本边界框
10. 使用说明
10.1 环境安装
创建Conda环境:
conda create -n ocr-training python=3.8
conda activate ocr-training
安装依赖:
pip install streamlit
pip install ultralytics
pip install paddleocr
pip install opencv-python
pip install plotly
pip install pandas
10.2 运行系统
启动Streamlit应用:
cd algorithm
streamlit run streamlit_app.py
访问界面:
- 本地地址: http://localhost:8501
- 网络地址: http://[your-ip]:8501
10.3 功能使用
文本检测:
- 进入"文本检测"模块
- 上传图片文件
- 等待检测完成
- 查看标注结果
文本识别:
- 进入"文本识别"模块
- 上传图片文件
- 系统自动检测+识别
- 查看识别文本和置信度
历史记录:
- 进入"历史记录"模块
- 查看所有处理记录
- 可按时间筛选
- 支持数据导出
11. 总结与展望
11.1 项目总结
本项目成功实现了一个完整的图片文本信息提取系统,具有以下特点:
技术优势:
- 采用先进的YOLOv8检测算法
- 集成高精度PaddleOCR识别引擎
- 友好的Web交互界面
- 完整的数据管理功能
功能完善:
- 支持实时文本检测识别
- 提供数据统计分析
- 记录历史处理信息
- 可视化模型性能
实用价值:
- 可应用于文档数字化
- 支持场景文字提取
- 辅助图像内容理解
- 提供二次开发基础
11.2 未来展望
功能扩展:
- 支持批量图片处理
- 添加文本翻译功能
- 实现文档结构分析
- 支持手写文字识别
性能优化:
- 模型轻量化压缩
- GPU加速推理
- 分布式处理支持
- 实时视频文字提取
应用拓展:
- 移动端应用开发
- API服务接口
- 云端部署方案
- 多语言支持
12. 参考资料
12.1 技术文档
12.2 数据集
12.3 相关论文
- YOLOv8: Ultralytics YOLOv8
- PP-OCR: A Practical Ultra Lightweight OCR System
- DBNet: Real-time Scene Text Detection with Differentiable Binarization

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 13
13 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)