消息中间件架构选型实战:从品类认知到Kafka和RocketMQ 深度对比
摘要
本文聚焦 Kafka、RocketMQ、RabbitMQ 三大主流消息中间件,从架构设计初衷出发划分品类并解析核心特性,精准对比 Kafka 与 RocketMQ 的架构维度、适配场景,结合场景落地双向选型思路,同时沉淀可复用的五步选型决策法,梳理全流程落地避坑要点,为分布式架构下消息中间件的选型与适配提供体系化的技术参考和实战指引。
一、消息中间件的品类认知:选对品类比选对产品更重要
实际架构选型中,先确定品类,再选择产品是最高效的思路 —— 不同品类的消息中间件架构设计初衷截然不同,直接决定了其核心特性和适用场景。
1.1 三大品类核心定义与对比
|
品类分类 |
代表性产品 |
核心架构定位 |
核心特性 |
核心技术指标 |
核心适用场景 |
选型边界 |
|
大数据型 |
Kafka |
分布式日志收集 / 实时数据管道 |
高吞吐、高扩展、低成本、日志式顺序写、深度融合大数据生态;企业级特性需扩展实现 |
百万级 TPS、毫秒级延迟 |
实时计算数据管道、海量日志采集、链路追踪、大数据批处理数据接入、高并发数据同步 |
原生无企业级全量特性,需结合生态组件扩展,不适合直接承载核心业务强一致性链路 |
|
企业级 |
RocketMQ |
企业级分布式消息通信 / 微服务解耦 |
高可靠、高可用、企业级功能丰富(原生事务 / 重试 / 死信 / 延迟)、深度融合 Java / 微服务生态 |
十万级 TPS、微秒级延迟 |
核心业务链路(订单 / 库存 / 财务)、分布式事务、业务消息通知、微服务异步通信、多租户隔离 |
超高吞吐(百万级 TPS)场景下性能和成本不如 Kafka,大数据生态融合性弱 |
|
轻量级 |
RabbitMQ |
中小型系统轻量级消息通信 / 灵活路由 |
AMQP 协议、灵活消息路由(交换机 / 队列)、轻量级部署、运维简单 |
万级 TPS、毫秒级延迟 |
中小型系统解耦、简单消息通知、轻量级异步任务、创业公司初期业务 |
不支持千万级高并发、海量数据处理,企业级特性和高可用能力不足 |
1.2 各品类深度解析
1.2.1 大数据型 - Kafka
核心定位是大数据 / 实时计算场景的高吞吐数据管道,由 LinkedIn 开源,后捐献给 Apache 基金会,架构设计围绕「吞吐最大化」展开,也是此前《Kafka核心架构解析:从CAP理论到消息可靠性的设计哲学》博客的核心讲解对象。
核心设计亮点:
- 日志式存储:消息以日志片段的形式顺序写入磁盘,顺序写性能远高于随机写,磁盘 IO 效率最大化;
- 分区副本模型:Topic 按分区拆分,每个分区有多副本,实现数据分片和容灾,支持集群无缝扩容;
- 零拷贝技术:通过 mmap+sendfile 实现内核态到用户态的零数据拷贝,大幅提升数据传输效率。
企业级特性说明:
Kafka原生无分布式事务、专属死信队列、内置重试机制等企业级特性,需结合生态组件或业务层二次开发实现:
- 分布式事务:需结合 Flink/Spark 等计算引擎实现 Exactly once 语义,或业务层基于幂等 + 消息回溯做补偿;
- 消息重试:无原生消费重试机制,需消费者端自行实现重试逻辑,结合 offset 手动提交避免消息丢失;
- 死信队列:无原生死信机制,需业务层对消费失败的消息做单独存储(如写入 Redis / 数据库),实现死信管理;
- 延迟消息:无原生延迟消息功能,需结合 TimeWheel、Redis ZSet 等组件实现。
1.2.2 企业级 - RocketMQ
RocketMQ 由阿里开发并开源,后捐献给 Apache 基金会,是为 「企业级业务系统和微服务架构」量身设计的消息中间件。其架构围绕「高可靠、高可用」做深度优化,采用多主多从架构,原生支持分布式事务、消息重试、死信队列、延迟消息等企业级特性,开箱即用,深度融合 Spring Cloud/Dubbo 等 Java 微服务生态,是中大型企业核心业务链路的首选。
核心设计亮点:
- 半消息机制:实现分布式事务的最终一致性,完美解决核心业务的跨系统数据一致性问题;
- 多级重试 + 死信队列:消息消费失败后自动重试,超过重试次数进入死信队列,避免消息丢失和消费风暴;
- 多租户隔离:支持按业务线拆分 Topic / 队列,实现资源隔离,适配多业务线的企业级场景。
1.2.3 轻量级 - RabbitMQ
RabbitMQ 基于 AMQP 协议开发,由 Erlang 语言编写,核心定位是 「中小型系统的轻量级消息通信」。其最大优势是灵活的消息路由机制 (直连 / 扇出 / 主题 / 头交换机),支持复杂的消息分发策略,部署和运维简单,资源占用低,适合创业公司初期业务或中小型系统的轻量级解耦场景。短板在性能瓶颈和企业级特性弱。
选型建议:中小团队可快速落地,当业务规模增长至千万级并发 / 海量数据时,建议按场景迁移至 Kafka/RocketMQ。
1.3 品类选择核心决策表
为了方便快速选型,提炼 「业务场景→核心需求→品类选择」 的对应关系:
|
业务场景关键词 |
核心架构需求 |
推荐品类 |
代表产品 |
|
实时计算、Flink/Spark |
高吞吐、高扩展、大数据生态融合 |
大数据型 |
Kafka |
|
海量日志、ELK、链路追踪 |
高吞吐、低成本、简单易用 |
大数据型 |
Kafka |
|
订单、库存、财务、结算 |
高可靠、分布式事务、消息重试 |
企业级 |
RocketMQ |
|
微服务、Spring Cloud/Dubbo |
高可用、多租户、业务解耦 |
企业级 |
RocketMQ |
|
创业初期、中小型系统、简单通知 |
轻量部署、灵活路由、低成本运维 |
轻量级 |
RabbitMQ |
二、核心竞品深度对比:Kafka vs RocketMQ
在中大型企业的实际架构中,大数据实时计算和企业级核心业务是两个最高频的场景,对应的 Kafka 和 RocketMQ 也是消息中间件选型中最常遇到的核心竞品。
本节将以架构设计六大核心维度(高性能、高可用、可扩展、高可靠、功能特性、生态适配)为纲,新增低成本 / 运维性(落地关键),对 Kafka 和 RocketMQ 做深度技术拆解 + 实战场景适配。
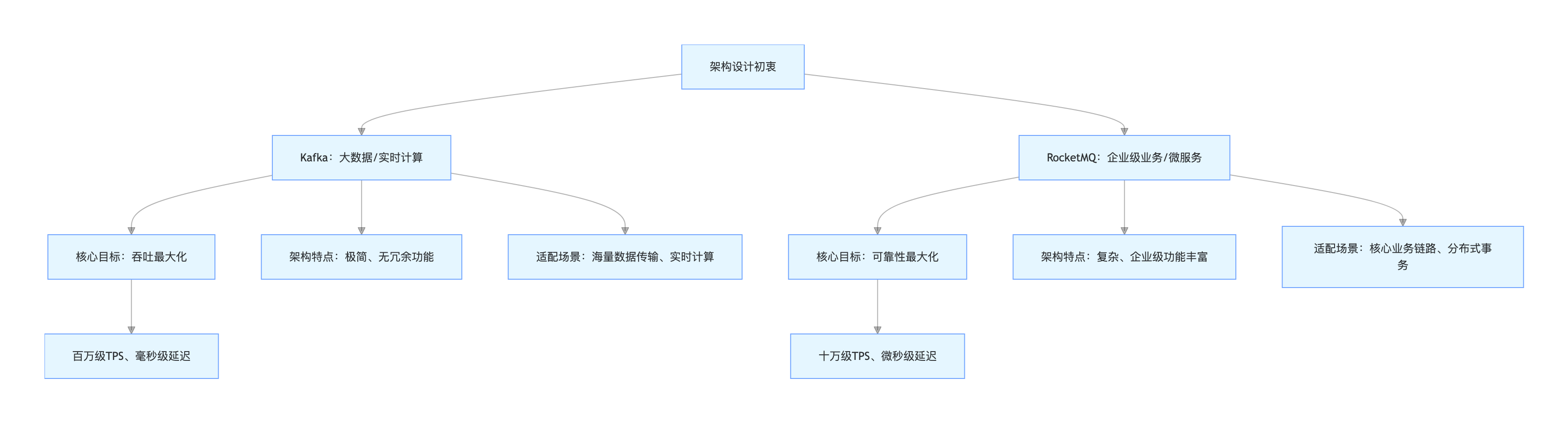
2.1 架构本源差异:决定场景适配的底层逻辑
Kafka 和 RocketMQ 的所有特性差异,本质上源于架构设计初衷的不同(Kafka:吞吐最大化;RocketMQ:可靠性最大化)。
2.2 七大核心维度深度对比
|
架构核心维度 |
Kafka 核心特性 & 适配性 |
RocketMQ 核心特性 & 适配性 |
核心选型关注点 |
|
高性能 |
日志式顺序写 + 零拷贝;批量生产消费;吞吐优先,延迟稳定 |
异步刷盘 + 批量消息;轻量级序列化;延迟优先,微秒级响应 |
TPS>10 万选 Kafka,<10 万选 RocketMQ |
|
高可用 |
分区副本模型(无主从单点);Raft 选主,RTO<10s;支持百台级集群 |
多主多从架构;同步 / 异步复制可选,RTO<5s;支持十台级集群 |
大规模集群选 Kafka,跨机房容灾选 RocketMQ |
|
可扩展 |
分区动态扩展,集群无缝扩容;按数据分层拆分 Topic;适配数据线性增长 |
动态创建 Topic / 队列;按业务线拆分资源;适配业务快速迭代 |
数据量持续增长选 Kafka,多业务线选 RocketMQ |
|
高可靠 |
默认 At most once;Exactly once 需 Flink 实现;无原生重试 / 死信 |
默认 At least once;原生 Exactly once(分布式事务);内置重试 / 死信 |
核心业务强一致选 RocketMQ,大数据最终一致选 Kafka |
|
功能特性 |
特性极简,仅基础生产消费;高级功能需生态扩展 |
企业级功能开箱即用:事务 / 重试 / 死信 / 延迟 / 消息轨迹 |
需丰富企业级功能选 RocketMQ,极简需求选 Kafka |
|
生态适配 |
深度融合大数据生态(Flink/Spark/ELK);多语言客户端 |
深度融合 Java 微服务生态(Spring Cloud/Seata/Nacos);主打 Java 客户端 |
大数据技术栈选 Kafka,微服务技术栈选 RocketMQ |
|
低成本 / 运维 |
部署运维极简,无复杂依赖;资源占用低(JVM 2-4G);机械硬盘即可 |
部署略复杂(需配置主从 / 刷盘);资源稍高(JVM 4-8G);核心业务需 SSD |
海量数据场景选 Kafka(低存储 / 运维成本);企业级业务选 RocketMQ(低开发成本) |
2.3 核心架构图对比
2.3.1 Kafka 核心架构图
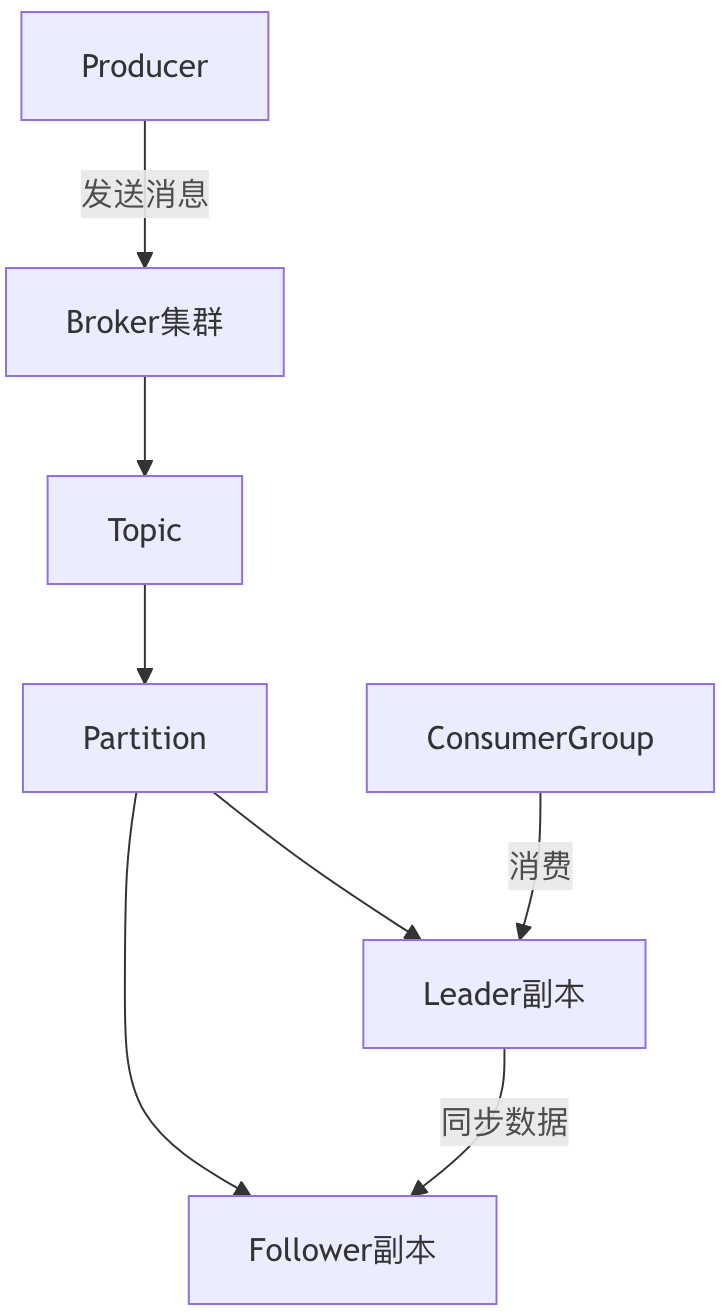
核心组件说明:
- Producer:消息生产者,负责将消息发送到 Kafka Topic,支持批量发送、分区指定;
- Broker:Kafka 服务节点,一个集群包含多个 Broker,负责存储和转发消息;
- Topic:消息主题,按业务维度拆分,每个 Topic 分为多个 Partition;
- Partition:分区,Topic 的最小存储单元,采用日志式存储,支持顺序写;
- Replica:副本,每个 Partition 有 1 个 Leader 和 N 个 Follower,Leader 负责读写,Follower 同步数据;
- Consumer Group:消费者组,多个消费者组成一个组,共同消费一个 Topic 的多个 Partition,实现负载均衡。
2.3.2 RocketMQ 核心架构图
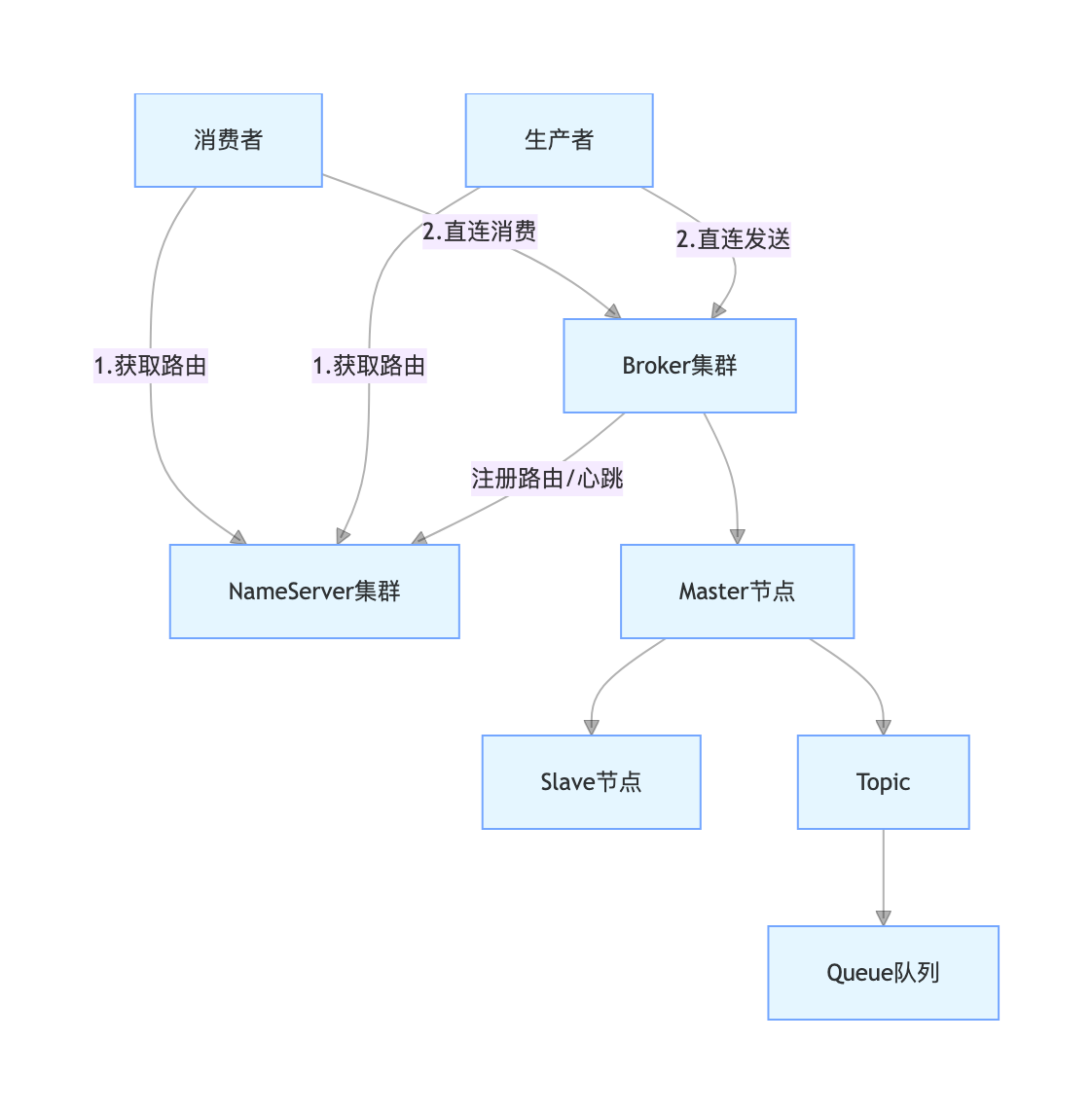
核心组件说明:
- NameServer:命名服务,负责 Broker 的注册与发现,无状态,可集群部署;
- Broker:核心服务节点,分为 Master 和 Slave,Master 负责读写,Slave 同步数据,支持多主多从;
- Topic:消息主题,按业务线拆分,每个 Topic 包含多个 Queue;
- Queue:消息队列,Topic 的最小存储单元,实现消息分片;
三、场景化双向适配:业务→技术| 技术→业务
架构选型的核心是「适配」,而非 “选优”,契合《Java 架构入门:3 大原则 + 4 步流程》博客的「合适原则」,以下分正向选型(架构师思路)和逆向选型(开发者思路),结合 4 大核心场景阐述。
- 正向选型:业务场景→核心需求→技术选型(架构师的核心思路,技术服务业务);
- 逆向选型:技术特性→业务场景(开发者 / 架构师的学习思路,先掌握技术再落地)。
3.1 正向选型:业务场景→核心需求→产品适配
|
业务场景 |
核心业务痛点 |
核心架构需求 |
选型链路 |
|
云选联盟千万级实时计算 |
1 亿 + 日事件、T+1 离线计算、高并发查询 |
高吞吐、低延迟、Exactly once、高扩展 |
实时计算→Kafka+Flink |
|
智慧园区核心业务管理 |
跨系统链路、设备状态同步、数据一致性 |
分布式事务、重试 / 死信、多租户隔离 |
核心业务→RocketMQ+Seata |
|
商品中台海量日志采集 |
全链路日志、业务埋点、ELK 分析、低运维成本 |
高吞吐、低成本、生态融合、简单部署 |
日志采集→Kafka+ELK |
|
智慧园区园区服务通知 |
租户通知、定时提醒 |
高可靠、延迟消息、精准过滤、持久化 |
消息通知→RocketMQ |
3.2 逆向选型:技术特性→业务场景
3.2.1 选型一句话口诀
- 大数据技术栈(Flink/Spark/ELK)+ 高吞吐需求 → 选 Kafka;
- 微服务技术栈(Spring Cloud/Seata)+ 核心业务 / 事务 → 选 RocketMQ(契合微服务事务治理思路);
- 混合场景(实时计算 + 核心业务)→ 异构部署 Kafka+RocketMQ(契合架构演化 & 解耦原则)。
3.2.2 技术特性 - 场景快速匹配表
|
技术特性关键词 |
适用业务场景 |
推荐产品 |
|
高吞吐、百万 TPS、零拷贝 |
实时计算、海量日志、数据同步 |
Kafka |
|
分布式事务、Exactly once |
订单 / 库存 / 财务、跨系统链路 |
RocketMQ |
|
重试 / 死信 / 延迟消息、高可靠 |
企业级通知、库存预警、定时任务 |
RocketMQ |
|
Flink/Spark/ELK 集成 |
大数据分析、链路追踪、日志采集 |
Kafka |
|
Spring Cloud/Seata 集成 |
微服务解耦、分级事务治理 |
RocketMQ |
|
动态扩容、数据线性增长 |
高并发业务、大数据平台 |
Kafka |
3.3 混合场景最佳实践:Kafka+RocketMQ 异构部署
中大型企业主流场景,核心是各司其职、场景隔离、数据互通,契合架构「演化 & 解耦」原则,精简架构图如下:
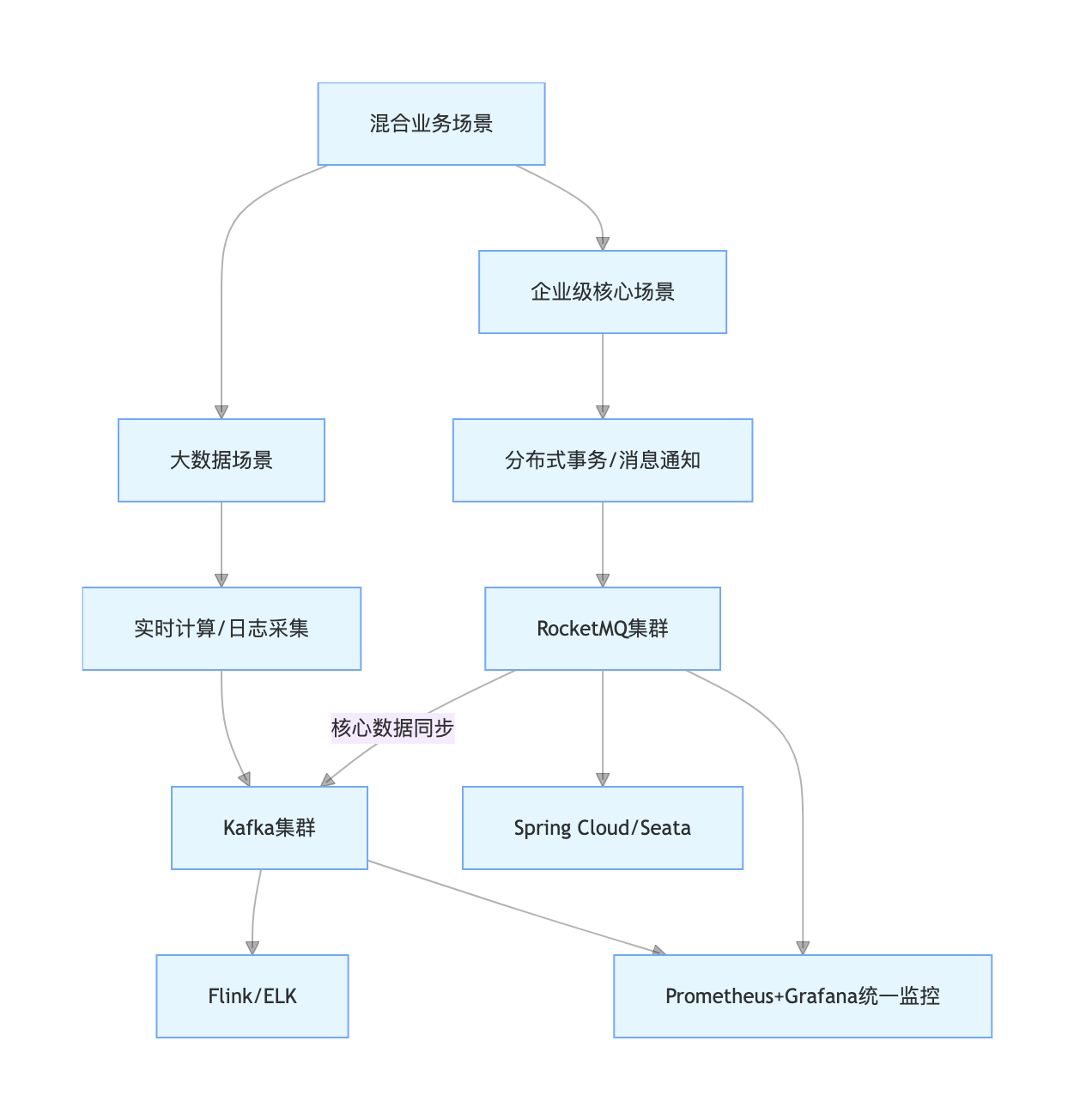
核心部署 4 原则:
- 场景隔离:Kafka 做大数据 / 日志 / 数据同步,RocketMQ 做核心业务 / 事务 / 通知;
- 资源隔离:独立集群部署,Kafka 用机械硬盘,RocketMQ 核心业务用 SSD;
- 数据互通:RocketMQ 核心业务数据同步至 Kafka,支撑大数据分析;
- 统一监控:监控 Kafka 吞吐 / 延迟、RocketMQ 事务 / 成功率,契合可观测性原则。
四、通用消息中间件选型方法论:五步决策法
结合前文品类认知、架构对比、场景适配的核心内容,沉淀可复用、可量化、可落地的消息中间件五步选型决策法,适配所有分布式架构下的中间件选型场景,全程契合架构体系博客的「合适、极简、演化」核心设计原则,每一步均明确执行动作、核心目标、落地要点,可直接落地应用。
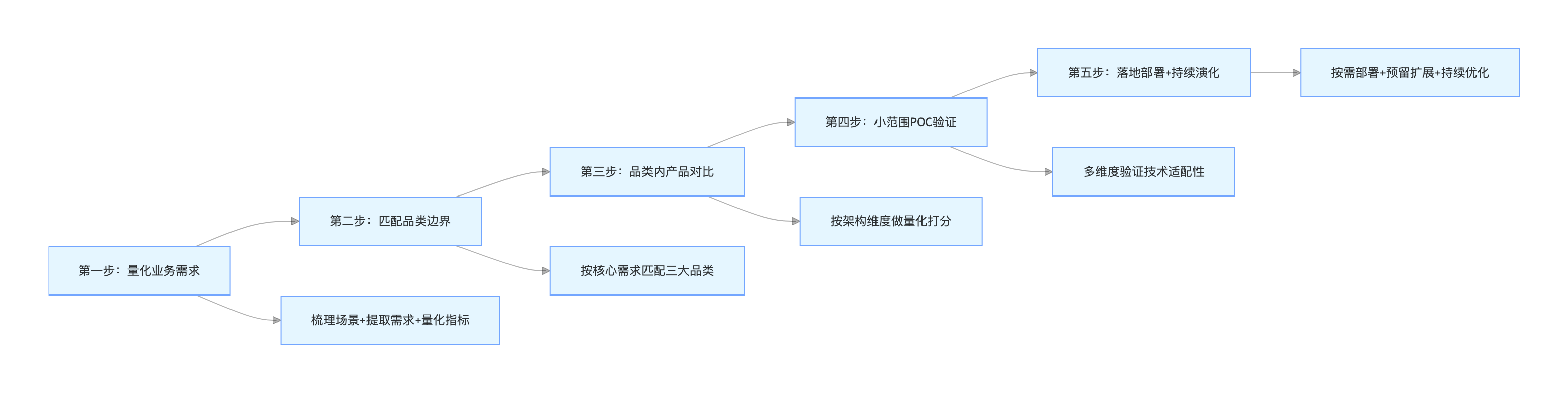
4.1 第一步:量化业务需求,明确核心指标
核心动作:全面梳理业务场景,提取核心诉求,将模糊需求转化为可量化的技术指标,拒绝模糊化描述。
落地要点:
- 梳理业务类型:区分大数据实时计算、企业级核心业务、轻量级解耦等场景;
- 提取核心需求:明确吞吐、延迟、一致性、可靠性、扩展性等核心诉求;
- 量化技术指标:确定峰值 TPS、端到端延迟、事务成功率、存储时长、集群规模等具体数值。
核心目标:让选型有明确的数据参考标准,避免凭经验主观判断。
4.2 第二步:匹配品类边界,锁定选型范围
核心动作:基于量化后的业务需求和技术指标,对照三大品类的核心定位和适用边界,快速锁定单一品类,跳过无意义的跨品类产品对比。
落地要点:
- 高吞吐(TPS>10 万)+ 大数据生态融合 → 匹配大数据型(Kafka);
- 强可靠 + 分布式事务 + 企业级特性 → 匹配企业级(RocketMQ);
- 中小规模 + 轻量部署 + 快速解耦 → 匹配轻量级(RabbitMQ)。
核心目标:大幅缩小选型范围,提升选型效率,避免在错误的品类中做无效对比。
4.3 第三步:品类内产品对比,筛选候选产品
核心动作:在锁定的品类内,按架构核心维度做量化打分,而非单纯的特性堆砌,筛选出 1-2 款候选产品。
落地要点:
- 确定对比维度:选取性能、高可用、可扩展、生态适配、低成本 / 运维等与业务需求强相关的维度;
- 设定维度权重:核心需求对应维度提高权重(如实时计算场景,吞吐 / 延迟权重设为 30%);
- 量化打分评级:按产品特性与业务指标的匹配度,做 1-5 分评级,计算综合得分。
核心目标:通过量化分析筛选出最贴合业务需求的候选产品,避免主观偏好影响选型结果。
4.4 第四步:小范围 POC 验证,用数据验证适配性
核心动作:基于生产环境的核心业务场景,搭建小范围 POC 测试环境,对候选产品做全维度验证,用实际测试数据验证适配性。
落地要点:
- 模拟生产场景:按生产环境的峰值 TPS、数据量、业务链路,搭建测试环境,避免测试与生产脱节;
- 多维度验证:重点验证性能指标、可靠性、生态集成、运维成本等核心维度;
- 记录测试数据:留存 TPS、延迟、事务成功率、故障恢复时间等关键数据,作为最终选型依据。
核心目标:通过实际测试验证候选产品的落地能力,避免 “纸上谈兵” 的选型误区。
4.5 第五步:落地部署 + 持续演化,适配业务增长
核心动作:基于 POC 验证结果,进行正式落地部署,同时遵循架构演化原则,预留扩展空间,根据业务增长持续优化。
落地要点:
- 按需部署:按业务当前需求配置集群规模、资源规格,避免过度部署造成资源浪费;
- 预留扩展:按业务 3-5 年增长预期,预留分区 / 队列、集群节点的扩展空间;
- 统一监控:搭建全链路监控体系,实时监控核心指标,及时发现并解决问题;
- 持续优化:根据业务需求变化和技术迭代,持续优化配置、架构,适配业务增长。
核心目标:让消息中间件架构随业务演化而迭代,始终与业务需求相适配。
4.6 选型核心五原则
五步决策法的核心遵循以下五大原则,也是分布式架构选型的通用准则,与此前架构体系博客的核心思路高度契合:
- 适配原则:组件设计初衷匹配业务核心需求,不盲目追求 “全功能” 和 “主流产品”;
- 极简原则:用最少的组件实现业务需求,降低架构复杂度和运维成本;
- 演化原则:按需部署,预留扩展空间,拒绝一步到位的 “过度设计”;
- 验证原则:所有选型结论需经 POC 测试验证,用数据说话,拒绝主观判断;
- 业务驱动:技术始终为业务服务,选型的最终目标是支撑业务发展,而非技术炫技。
五、核心复习要点
5.1 核心认知要点
- 消息中间件按设计初衷分为大数据型、企业级、轻量级三大品类,选对品类远重要于选对产品,品类由业务核心需求决定;
- Kafka 核心定位是高吞吐数据管道,设计围绕「吞吐最大化」,适配大数据 / 实时计算场景,企业级特性需生态扩展;
- RocketMQ 核心定位是高可靠微服务消息中间件,设计围绕「可靠性最大化」,原生支持分布式事务 / 重试 / 死信,适配核心业务场景;
- Kafka 分区与微服务 / 数据库的分区 / 分片,均源于分布式分片思想,核心目标一致,仅应用维度和实现细节不同;
- Kafka 与 RocketMQ 是互补而非替代关系,混合场景建议异构部署、各司其职,而非单组件全覆盖。
5.2 核心选型要点
- 大数据技术栈(Flink/Spark/ELK)+ 高吞吐(TPS>10 万)需求 → 优先选 Kafka;
- 微服务技术栈(Spring Cloud/Seata)+ 核心业务 / 分布式事务需求 → 优先选 RocketMQ;
- 中小团队 / 创业初期 / 轻量解耦需求 → 优先选 RabbitMQ,业务规模升级后再迁移;
- 混合场景核心部署原则:场景隔离、资源隔离、数据互通、统一监控;
- 通用选型遵循五步决策法,核心是将模糊需求量化、用数据验证适配、让架构随业务演化。
5.3 核心落地避坑要点
通用选型避坑
- 跳过品类直接跨品类对比产品,忽略组件设计初衷;
- 盲目追求全功能,舍长取短(如用 Kafka 做核心事务、用 RocketMQ 做海量日志);
- 混合场景单组件部署,过度依赖一个组件实现所有需求;
- 凭主观偏好选型,未做量化分析和 POC 验证,与生产实际脱节。
Kafka 落地避坑
- 分区数配置过少或数据倾斜,导致吞吐瓶颈;
- 开启 offset 自动提交,消费失败造成消息丢失;
- 副本数过多 / 使用 SSD,增加无意义的硬件 / 存储成本;
- Topic 未按业务 / 数据分层,单 Topic 数据量过大引发运维问题。
RocketMQ 落地避坑
- 核心业务使用异步刷盘 / 异步复制,牺牲可靠性换性能导致消息丢失;
- 保留默认 16 次消费重试,引发消费风暴压垮下游服务;
- 多业务线共用 Topic / 队列,无资源隔离引发竞争和数据混乱;
- 分布式事务未配置超时 / 重试机制,引发跨系统数据一致性问题。
5.4 知识体系衔接要点
本文是对分布式架构系列博客的深度延伸与场景化落地,形成完整知识闭环:
- 衔接《Kafka核心架构解析:从CAP理论到消息可靠性的设计哲学》:从核心设计到千万级场景适配,补充企业级特性扩展和大数据生态集成思路;
- 衔接《微服务事务分级治理:从 Seata 全模式到 TDSQL 实战》:将 RocketMQ 分布式事务与 Seata 结合,落地微服务最终一致性的分级治理方案;
- 衔接《Java 架构体系:从理论到落地》博客:将「合适、极简、演化」核心原则,融入消息中间件选型、部署、迭代全流程。
📚 我的技术博客导航:[点击进入一站式查看所有干货]

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)