ClickStack 最新动态:2026 年 1 月版

本文字数:9753;估计阅读时间:25 分钟
作者:ClickStack team
本文在公众号【ClickHouseInc】首发

欢迎阅读 1 月版 What’s New in ClickStack。ClickStack 是专为 ClickHouse 打造的开源可观测性 (observability) 技术栈。每个月,我们都会带来 ClickStack 的最新进展,帮助团队以更快的速度、更清晰的视角、更从容的方式探索和分析可观测性数据。1 月对 ClickStack 来说格外忙碌。我们发布了一系列具有重要影响的改进,解锁了全新的工作负载场景,同时也加入了一些虽小但非常有趣、实用的优化。和往常一样,我们力求覆盖各个层面。衷心感谢所有用户持续不断的反馈,正是这些建议帮助我们不断打磨功能,让 ClickStack 变得更好。
新贡献者
在开放模式下构建 ClickStack,意味着它的发展始终由每天使用它的人所推动。我们感谢社区持续高涨的参与热情,尤其感谢本月加入的新贡献者。你们的想法、代码和反馈,直接影响着 ClickStack 的未来方向,也让它变得更加健壮和完善。
motsc, yeldiRium, gyancr7, gingerwizard, adri, akalitenya
Managed ClickStack
本月初,我们正式发布了 Managed ClickStack。Managed ClickStack 是基于 ClickHouse Cloud 构建的全托管可观测性产品,专为希望获得 ClickStack 强大性能与扩展能力、但不想自行运维底层基础设施的团队而设计。它提供了与开源版本相同的高速查询体验,覆盖日志、指标、追踪和会话数据,同时从根本上重塑了可观测性的成本模型。
Managed ClickStack 仅按计算与存储资源计费,而不是按事件数、主机数或用户数计费。这使团队能够在大规模场景下接入并长期保留全保真、高基数数据,总成本低至每 GB 每月几美分。得益于存储与计算分离架构,数据接入与查询负载可以独立扩展,你只需为实际使用的资源付费。
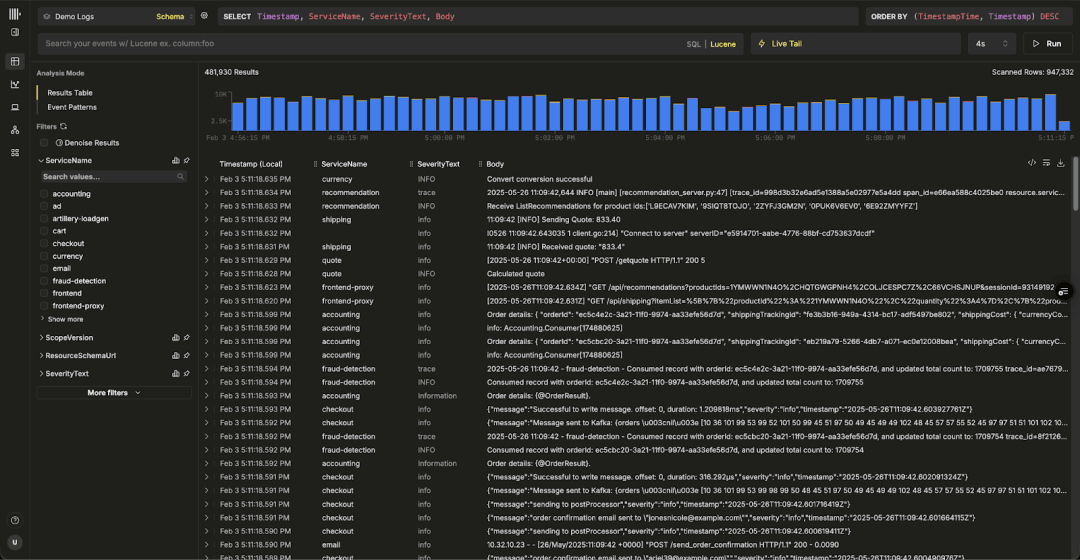
更重要的是,Managed ClickStack 代表了我们对可观测性未来形态的判断。通过在 ClickHouse Cloud 上运行 ClickStack,我们能够实现基于低成本对象存储的长期数据保留,为调查分析和告警提供弹性计算能力,并为将可观测性与分析型工作负载及其他业务场景整合打下坚实基础。
这也契合我们一贯的观点:可观测性归根结底是一个数据问题,而解决这一问题的最佳方式,是依托为大规模分析型工作负载而生的平台。如果你希望深入了解 Managed ClickStack 背后的愿景与经济模型,欢迎阅读我们介绍该 beta 版本的发布文章。
增强的索引支持
在 ClickStack 中,我们始终致力于更充分地发挥 ClickHouse 各项特性的能力——无论是新发布的功能,还是长期存在但仍有优化空间的能力。本月正是这一理念的体现。我们重点投入改进索引支持,使其在大规模数据集上的查询性能得到显著提升。
改进 Bloom 过滤器支持
对于使用 ClickStack 处理日志和追踪数据的用户来说,Bloom 过滤器早已是加速文本搜索的核心机制。Bloom 过滤器作为一种轻量级的跳过索引,为关键字查询提供支持,使 ClickHouse 可以避免扫描大量无关数据。
在 ClickHouse 中,Bloom 过滤器作为跳过索引使用,用于快速排除不可能匹配查询的数据块。数据写入时,字段值或派生出的 Token 会被哈希,并以紧凑的概率结构存储在每个 granule 级别。查询阶段,ClickHouse 会在读取 granule 之前先检查 Bloom 过滤器。如果过滤器判断某个值不存在,则整个 granule 会被直接跳过。Bloom 过滤器保证不会出现假阴性,也就是说不会漏掉匹配数据,但可能会出现假阳性,从而导致额外的 granule 被扫描。这种权衡使 ClickHouse 能在保持索引体积较小的同时,大幅降低文本搜索和高基数查询所需的 IO 与 CPU 开销。
此前,ClickStack 在日志正文搜索中使用的是 tokenbf_v1 索引。该索引会先按非字母数字字符对文本进行预分词,然后将生成的 Token 存入 Bloom 过滤器。虽然使用方便,但它提供了多个在实际场景中较难把握的调优参数。用户需要自行决定过滤器大小、哈希函数数量、随机种子以及 granularity。虽然 granularity 设为 8 通常效果不错,但其他参数往往需要反复试验,甚至需要 ClickHouse 专家的协助。
在本次发布中,我们新增支持更简洁的 bloom_filter 索引,并结合 tokens 函数进行显式分词处理。该索引只包含一个可选参数:可接受的假阳性率,取值范围为 0 到 1,默认值为 0.01。分词逻辑则单独处理,默认仍按非字母数字字符拆分,但现在可以根据需要显式调整分词方式(这也为我们后续探索更多可能性打开了空间!)。
这一变化大幅缩小了调优面。用户无需再权衡多个底层参数,只需关注 granularity 和假阳性率即可。我们仍建议日志正文搜索使用 granularity 为 8,而在大多数场景下,默认的假阳性率已经足够。如果确实需要调优,只需在默认值附近略微调整,并观察对查询性能的影响即可。
需要注意的是,并非假阳性率越低越好。过度降低假阳性率虽然理论上可以跳过更多 granule,但会导致过滤器体积增大,从而拖慢评估过程并增加加载时间——尽管这一问题在一定程度上已通过 [recent changes to stream skip indices](https://clickhouse.com/blog/streaming-secondary-indices) 得到缓解。适度提高假阳性率反而可能因降低索引开销而提升整体性能。实践中,最简单有效的方式是在默认值附近进行测试,如果没有明显收益,则保持默认配置即可。
新方案还带来了其他显著收益。在 granularity 为 8 的情况下,索引体积通常可缩小约 15%。索引分析速度最高可提升 50%,在某些数据集中,数据裁剪效率甚至可提升至原来的 7 倍,不过具体效果取决于数据特征。综合来看,在调优更简单的前提下,搜索性能最高可提升 5 倍。
举例来说,在我们的 playground OpenTelemetry 演示数据集中,执行对 “Failed to place” 的搜索:
-- example tokenbf_v1 schema
CREATE TABLE otel_v2.otel_logs
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
...
`Body` String CODEC(ZSTD(1)),
...
INDEX idx_body Body TYPE tokenbf_v1(32768, 3, 0) GRANULARITY 8
)
ENGINE = MergeTree
PARTITION BY toDate(TimestampTime)
PRIMARY KEY (ServiceName, TimestampTime)
ORDER BY (ServiceName, TimestampTime, Timestamp)-- example bloom_filter schema
CREATE TABLE otel_v2.otel_logs_bloom_filter
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
...
`Body` String CODEC(ZSTD(1)),
...
INDEX idx_body tokens(lower(Body)) TYPE bloom_filter (0.025) GRANULARITY 8
)
ENGINE = MergeTree
PARTITION BY toDate(TimestampTime)
PRIMARY KEY (ServiceName, TimestampTime)
ORDER BY (ServiceName, TimestampTime, Timestamp)-- query performance with no index!
SELECT count() FROM otel_v2.otel_logs WHERE (((hasToken(lower(Body), lower('Failed'))) AND (hasToken(lower(Body), lower('to'))) AND (hasToken(lower(Body), lower('place'))))) SETTINGS use_skip_indexes=0
1 row in set. Elapsed: 0.655 sec. Processed 90.58 million rows, 14.03 GB (138.20 million rows/s., 21.40 GB/s.)-- query performance using tokenbf_v1
SELECT count() FROM otel_v2.otel_logs WHERE (((hasToken(lower(Body), lower('Failed'))) AND (hasToken(lower(Body), lower('to'))) AND (hasToken(lower(Body), lower('place')))))
1 row in set. Elapsed: 0.199 sec. Processed 10.66 million rows, 2.66 GB (53.68 million rows/s., 13.40 GB/s.) -- query performance using bloom_filter
SELECT count() FROM otel_v2.otel_logs_bloom_filter WHERE hasAll(tokens(lower(Body)), tokens(lower('Failed to place')))
1 row in set. Elapsed: 0.096 sec. Processed 1.76 million rows, 159.73 MB (17.73 million rows/s., 1.61 GB/s.)
Peak memory usage: 234.32 MiB.结果显示,在使用 bloom_filter 索引的情况下,查询性能提升约 50%,数据裁剪效率提升超过 4 倍(处理 1.76m 行,相比 10.66m 行)。同时可以看到,与完全不使用索引相比,两种索引方案的性能都有明显优势。
细心的读者可能已经注意到,查询语法也随之发生了变化。
为了确保索引能够正确生效,我们调整了 ClickStack UI 中生成文本搜索查询的方式。此前,UI 会将日志正文和查询字符串统一转换为小写(日志场景通常采用大小写不敏感搜索),并依赖 Bloom 过滤器内部的隐式分词机制。同时,UI 会将查询拆分为多个 Token,使用 hasToken 函数,并通过布尔 AND 逻辑进行组合,例如 (((hasToken(lower(Body), lower('Failed'))) AND (hasToken(lower(Body), lower('to'))) AND (hasToken(lower(Body), lower('place')))))
在新的过滤器方案下,查询阶段会显式使用 tokens 和 lower 函数,将分词逻辑交由 ClickHouse 执行,并通过 hasAll 函数判断 Token 是否全部存在,即 hasAll(tokens(lower(Body)), tokens(lower('Failed to place')))。这样既能确保索引被正确利用,又能保持原有的搜索行为不变。
ClickStack 会自动检测当前使用的索引类型,并采用对应的查询方式。
文本索引支持
Bloom 过滤器依然非常强大,但它并非没有局限。假阳性不可避免,即便在调优简化之后,也仍然存在性能与资源之间的权衡。在某些场景下,尤其是大规模日志搜索,倒排索引往往能带来更具吸引力的优势(当然同样伴随着一定成本)。
ClickHouse 的倒排文本索引近期经历了重要重构,目前已以 beta 形式提供。近期优化的重点在于让它能够在大规模场景中真正可用,尤其是在基于对象存储的 ClickHouse Cloud 上。内部实现中仍然借助 Bloom 过滤器进行轻量级存在性判断,当某个术语可以确定不在某个 granule 中时,ClickHouse 便可直接跳过昂贵的索引评估过程。
在我们的日志数据集基准测试中,结果尤为亮眼:倒排索引在过滤效率和查询延迟两方面都优于 Bloom 过滤器。
因此,ClickStack 现已在 UI 中直接支持该索引类型。为此,我们进一步升级了 Lucene 到 SQL 的编译流程,使其在检测到文本索引存在时自动使用 hasAllTokens。需要注意的是,文本索引本身负责分词与预处理——也就是在创建索引时定义的表达式。在 ClickStack 中,我们使用 splitByNonAlpha 作为分词器,使用 lower 作为预处理函数,从而保持与现有搜索行为一致。
INDEX idx_body Body TYPE text(tokenizer = 'splitByNonAlpha', preprocessor = lower(Body))需要了解一些限制条件。hasAllTokens 函数每次调用最多支持 64 个 Token,因此对于更长的搜索词,会拆分成多个批次并结合子字符串匹配进行处理。此外,该功能依赖 enable_full_text_index 设置,而这一设置仅在 ClickHouse v25.12 及更高版本中可用。因此,使用 OSS 部署的用户需要在 ClickHouse 用户配置文件中手动启用该选项。
目前我们仅支持 splitByNonAlpha 分词器。如果文本索引使用了其他分词器,ClickStack 会自动回退到现有的搜索方式。探索更多适用于日志搜索的分词器,是我们正在积极推进的方向——例如 sparseGrams,在提升文本搜索性能方面已展现出潜力。
以我们之前的搜索示例为例。可以看到,现在使用 hasAllTokens,并将分词与小写处理逻辑交由索引完成:
– new text index
INDEX idx_body Body TYPE text(tokenizer = 'splitByNonAlpha', preprocessor = lower(Body)) GRANULARITY 64
SELECT count()
FROM otel_v2.otel_logs_inverted_index
WHERE hasAllTokens(Body, 'Failed to place')
SETTINGS enable_full_text_index = 1, query_plan_direct_read_from_text_index = 1, use_skip_indexes_on_data_read = 1
┌─count()─┐
│ 194124 │
└─────────┘
1 row in set. Elapsed: 0.011 sec. Processed 1.33 million rows, 1.33 MB (116.59 million rows/s., 116.59 MB/s.)
Peak memory usage: 27.70 MiB.在这个示例中,查询性能相比 bloom filter 提升接近 9 倍,读取数据量减少超过 100 倍。我们也建议感兴趣的读者深入了解实现这一性能提升所采用的 direct-read 优化,以及文本索引可用的缓存调优选项。
接下来,我们将在更大规模、更多类型的工作负载下对倒排索引进行系统化基准测试,并在新的性能调优文档中发布详细指南。倒排索引功能强大,但也会带来额外的存储和资源成本,因此并非适用于所有场景。
敬请期待。围绕一个大规模可观测性的核心问题——在什么情况下应该使用倒排索引——我们将持续分享更多数据与洞察。
告警能力接入物化视图
现在,ClickStack 中的告警功能也可以直接受益于物化视图。上个月,我们已为 ClickStack 引入物化视图支持。凡是在 ClickHouse 中创建,并在 ClickStack UI HyperDX 中注册为数据源的物化视图,都会自动用于加速全产品范围内的聚合查询——包括图表、搜索直方图以及预设分析视图。在本次发布中,告警功能也已完全接入相同的查询路径,从而同样享受这些优化能力。
物化视图天然适合用于支撑告警场景。告警通常关注最近数据,而物化视图在数据写入时就完成聚合计算,将工作从查询阶段前移至数据摄取阶段。随着数据写入,聚合状态会被计算并存储到更小的目标表中,使后续的聚合查询大幅提速。借助物化视图,即便在大量告警并发运行的情况下,告警评估依然可以保持轻量、高效。
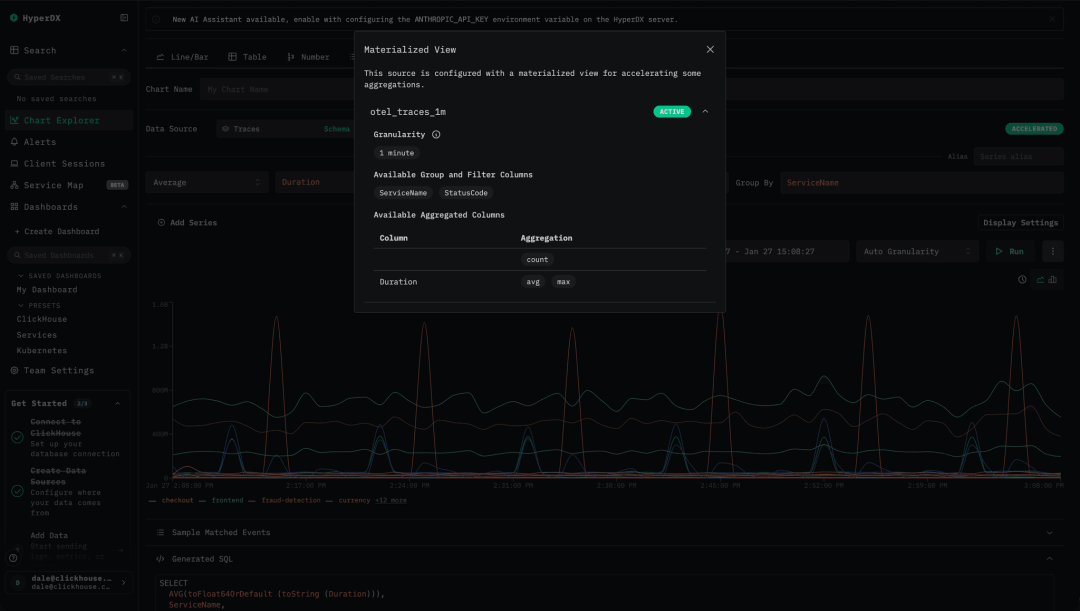
最终效果是,用户可以放心运行数百甚至数千条告警规则,而对整体集群性能的影响极小。相关成本在数据写入阶段逐步支付,并在所有流入数据中进行摊销,从而将单次写入的额外开销控制在较低水平。在 HyperDX 中构建告警可视化时,用户可以通过界面上的图标判断该告警是否会自动使用物化视图进行加速。
更多细节优化
在带来一系列索引能力提升的同时,我们也持续交付许多细节层面的优化,让 ClickStack 在日常使用中更加顺手。这些改进聚焦于可用性、工作流程的流畅度以及更简化的部署方式,帮助团队更快产出价值,同时不断提升整体体验。
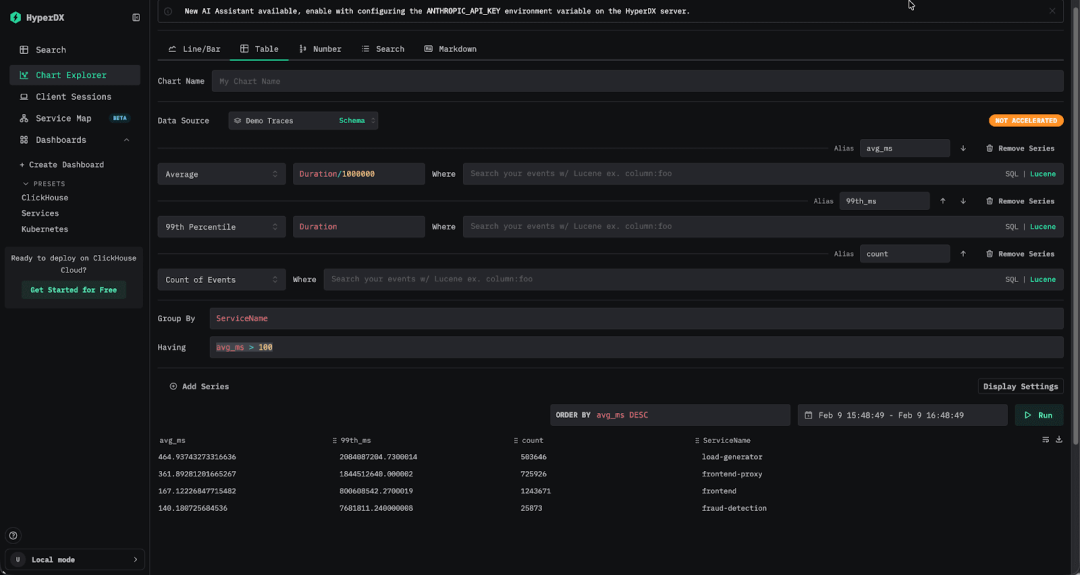
表格查询支持 HAVING 过滤
熟悉数据分析的用户一定清楚 SQL 中 HAVING 子句的价值。在查询可观测性数据时,它同样非常实用。与在聚合前过滤数据的 WHERE 不同,HAVING 可以基于查询过程中计算出的聚合结果进行过滤。例如,你可以按服务计算平均延迟和 99 分位延迟,然后只返回平均延迟超过 100 毫秒的服务。这种方式非常适合将庞大的结果集收敛为更有意义、可操作的信息。
SELECT
ServiceName,
round(avg(Duration / 1000000), 2) AS avg_ms,
round(quantile(0.99)(Duration / 1000000), 2) AS `99th_ms`,
count() AS count
FROM otel_traces
GROUP BY ServiceName
HAVING avg_ms > 100
ORDER BY avg_ms DESC
┌─ServiceName─────┬─avg_ms─┬─99th_ms─┬────count─┐
│ load-generator │ 584.3 │ 2668.15 │ 20564626 │
│ frontend-proxy │ 408.94 │ 1935.34 │ 31968439 │
│ frontend │ 203.57 │ 906.38 │ 54885807 │
│ fraud-detection │ 158.13 │ 8 │ 1050226 │
└─────────────────┴────────┴─────────┴──────────┘
4 rows in set. Elapsed: 0.502 sec. Processed 216.70 million rows, 1.95 GB (431.85 million rows/s., 3.89 GB/s.)
Peak memory usage: 239.85 MiB.在最新版本中,ClickStack 已支持在 UI 中查询表格时使用 HAVING。用户现在可以基于任意聚合表达式过滤结果,而不仅限于原始字段。实际使用中,你可以直接基于别名进行过滤,例如 avg_duration > 100,或者在过滤条件中定义新的聚合表达式,例如 median(Duration) > 100,在分析和优化聚合结果时拥有更高的灵活度。
图例过滤功能
图例过滤为图表交互带来了一项贴心的小改进。现在,你可以直接通过图表图例来筛选时间序列。点击某个图例项即可立即在图表中单独显示该序列,无需修改查询语句即可专注于某个信号。再次点击,即可恢复显示全部数据。
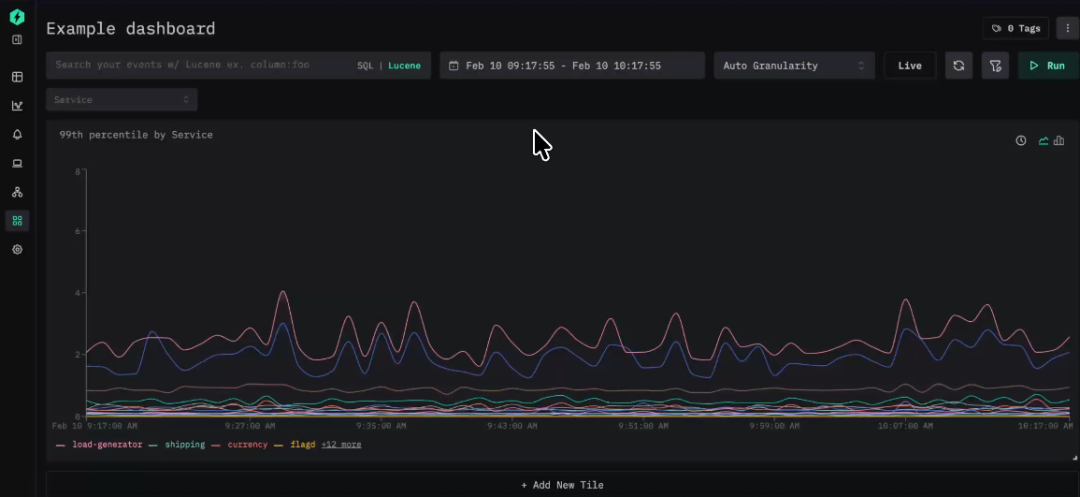
我们还对这一功能做了额外优化。按住 Shift 键可以同时选择多个序列进行对比。所有图例项始终可见,并通过清晰的视觉提示区分已选中和暂时弱化的序列,同时 Y 轴会自动缩放以匹配当前可见数据。这虽是一个小功能,却显著提升了图表探索的效率与交互体验。
Collector 改进
ClickStack 的目标之一,是尽可能降低可观测性系统的上手门槛。它内置了一个预配置的 OpenTelemetry Collector,可直接与 ClickHouse 协同工作,并默认启用了合理的批处理、自定义处理以及模式校验配置。
默认情况下,Collector 通过 OpAMP 进行管理,并使用在 UI 中展示的接入密钥来保护 OTLP 数据接入端点。用户只需复制该密钥,并在请求中添加相应的授权头,即可安全地将数据发送到 Collector,从第一个事件开始便拥有顺畅、安全的接入体验。
随着 ClickStack 的持续发展,以及托管版本的推出,越来越多的用户希望在脱离 UI 的情况下独立运行 OpenTelemetry Collector,同时仍然受益于 ClickStack 发行版及其持续优化能力。为此,我们现在支持将数据接入与 UI 解耦。如果未设置 OPAMP_SERVER_URL 环境变量,或将其设为空值,则会关闭与 OpAmp 服务器的通信。Collector 将独立运行,无需依赖 UI 配置。
在这种模式下,为保障数据接入安全,用户可以设置 OTLP_AUTH_TOKEN。启用后,所有发送至 OTLP 端点的数据都必须携带该 Token。这一改进不仅让 Managed ClickStack 更易上手,也为高级用户提供了更大的灵活性,使其能够运行自定义 Collector,同时继续享受 ClickStack 提供的标准化处理与模式校验能力。
# Example command for running the ClickStack OpenTelemetry collector
docker run -e CLICKHOUSE_ENDPOINT=https://myhost:8443 -e CLICKHOUSE_USER="default" - e CLICKHOUSE_PASSWORD="<password>" -p 4317 -p 4318 -e OTLP_AUTH_TOKEN "a_secure_string_value" clickhouse/clickhouse-otel-collector:latest全新主题
阅读前文关于 Managed ClickStack 的介绍时,你或许已经注意到 HyperDX 界面有些变化。随着 Managed ClickStack 的发布,我们也推出了一个全新的 ClickStack 主题。自 ClickStack 发布以来,一直存在一个小困惑:HyperDX 到底是产品名称还是 UI 名称——界面上的 HyperDX 品牌标识并没有让事情更清晰。今后,你会越来越多地看到我们将界面称为“ClickStack UI”,同时仍然尊重其最初的 HyperDX 身份。
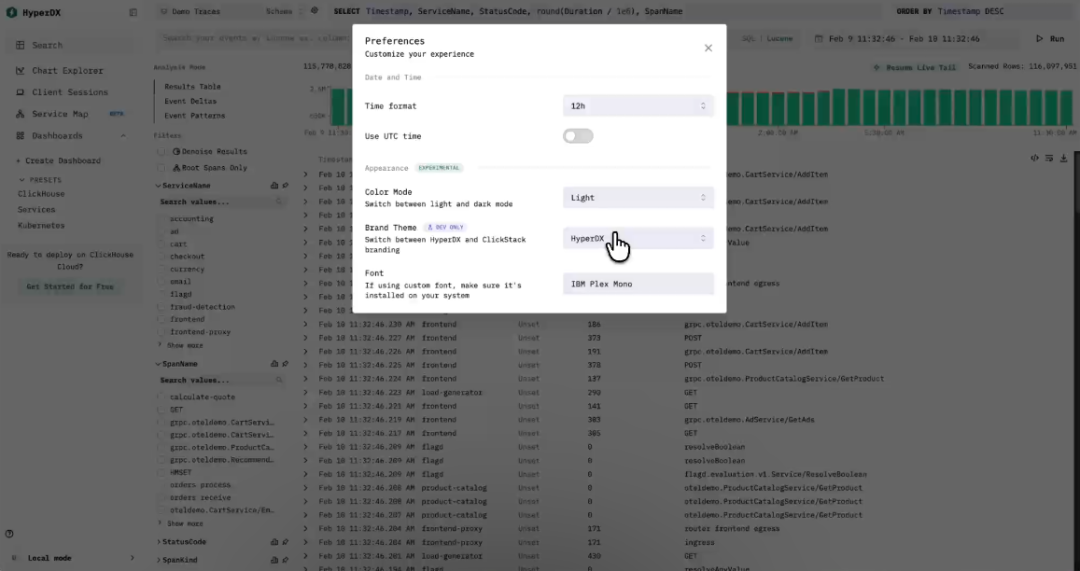
新的 ClickStack 主题默认应用于托管版本,并与整体 ClickHouse 品牌风格更加统一——延续了白色、黄色和黑色的经典配色。开源用户可以在用户偏好设置中切换至这一主题,或者继续使用原本的 HyperDX 绿色风格——完全取决于你的喜好。两种主题均提供浅色与深色模式,方便根据个人习惯选择。
结语
以上就是 ClickStack 1 月份的更新内容。未来几周,我们还将带来更多令人期待的功能更新,其中 API 和 RBAC 位于路线图的优先位置。我们将持续专注于提升 ClickStack 的集成能力与大规模运维体验。也欢迎你随时告诉我们,希望接下来看到哪些功能。
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)