第四篇:在Kubernetes上的Flask论坛项目,集成Prometheus+Grafana监控
fix-monitor-final.yaml文件的作用:Helm Chart 的自定义配置文件,用于覆盖 kube-prometheus-stack 默认参数,实现:使用阿里ACR镜像源(避免拉取失败)开启/关闭组件(如 node-exporter)配置监控目标(如外部 MariaDB)设置 Grafana 访问方式(NodePort + 密码)调整存储、安全、网络等高级选项什么是 CRD?
python-flask项目开发:
- flask开发完整过程总结:https://blog.csdn.net/qq_38444844/article/details/151928286?spm=1011.2415.3001.5331
- 项目源码:https://gitee.com/loveTianWen/Forum-platform/tree/master
- 第一篇: 使用Docker部署flask项目(Flask + DB 容器化)https://blog.csdn.net/qq_38444844/article/details/155862905?sharetype=blogdetail&sharerId=155862905&sharerefer=PC&sharesource=qq_38444844&spm=1011.2480.3001.8118
- 第二篇: 部署 Kubernetes 集群(Ubuntu 24.04.3)
https://blog.csdn.net/qq_38444844/article/details/156615128?spm=1011.2415.3001.5331 - 第三篇: 将 Flask 应用部署到 Kubernetes 集群中,实现自动化管理https://blog.csdn.net/qq_38444844/article/details/157064314?spm=1011.2415.3001.5331
目标:在Kubernetes上的Flask论坛项目,集成Prometheus+Grafana监控
项目架构
| 组件 | 技术栈 | 部署方式 |
|---|---|---|
| 后端应用 | Python Flask | 容器化部署在 K8s(Deployment + Service) |
| 数据库 | MariaDB | 运行在独立主机 192.168.56.109 上(非 K8s 内) |
| 容器运行时 | Containerd | 所有节点(包括 K8s master/worker) |
| K8s 版本 | v1.28.2 | 使用 kubeadm 搭建 |
| 网络插件 | Flannel | 已正常运行 |
| 应用镜像 | 私有 ACR(阿里云) | 通过 imagePullSecret 拉取 |
Prometheus + Grafana 监控部署方案(K8s 原生)
采用 kube-prometheus-stack Helm Chart 部署 Kubernetes 原生监控体系,可一站式实现基础设施、平台组件和应用层的全栈可观测性:
kube-prometheus-stack 核心优势
1 自动发现 K8s 组件(API Server, etcd, kubelet, cAdvisor) 内置 30+ Grafana 仪表盘(Node, Pod, Deployment, Network, PersistentVolume)
2 支持 自定义 ServiceMonitor 微服务监控你的 Flask 应用(暴露/metrics指标)
3 自带 Alertmanager 实现微信/钉钉/邮件告警(可后续扩展) 社区活跃,CNCF 毕业项目,兼容性好
| 监控对象 | 监控内容 | 实现方式 | 数据来源 | 是否自动发现 |
|---|---|---|---|---|
| Flask Pod | CPU、内存、网络、磁盘 I/O | 内置 cAdvisor + kubelet metrics | kubelet / cAdvisor |
✅ 是(通过 PodMonitor 或默认指标) |
| Flask 应用 | QPS、响应时间、自定义业务指标 | 应用暴露 /metrics,配置 ServiceMonitor |
Flask 应用(需集成 Prometheus Client) | ❌ 需手动配置 |
| 外部 MariaDB/MySQL | 连接数、慢查询、QPS、InnoDB 状态等 | 部署 mysqld-exporter + ServiceMonitor |
mysqld_exporter(连接 DB 拉取指标) |
❌ 需手动配置 |
| Node 节点 | CPU、内存、磁盘、负载、温度等 | Node Exporter(DaemonSet) | node-exporter |
✅ 是(Helm 自带) |
| K8s 核心组件 | API Server、etcd、Scheduler、Controller Manager | 组件自身暴露指标 + ServiceMonitor | 各组件 /metrics 端点 |
✅ 是(kube-prometheus-stack 默认启用) |
| Grafana 可视化 | 预置仪表盘:Node、Pod、Deployment、Network 等 | 内置 30+ Dashboard(ID: 315, 6417, 11074 等) | Prometheus 数据源 | ✅ 开箱即用 |
方案核心组件说明
| 组件 | 作用 | 是否由 Helm 自动部署 |
|---|---|---|
| Prometheus | 时序数据库 + 指标拉取引擎 | ✅ |
| Prometheus Operator | 声明式管理 Prometheus 实例 | ✅ |
| kube-state-metrics | 将 K8s 对象状态转为指标(如 Deployment 副本数) | ✅ |
| Node Exporter | 采集主机级指标(CPU/内存/磁盘) | ✅ |
| Alertmanager | 告警路由、去重、通知(邮件/钉钉/微信) | ✅(可选启用) |
| Grafana | 可视化面板,预置 K8s Dashboard | ✅(可配置 NodePort 访问) |
| ServiceMonitor | 自定义服务发现规则(用于 Flask / MySQL) | ❌ 需手动创建 |
Prometheus + Grafana 傻瓜式部署方案(K8s 原生)
1、部署监控系统 (Kube-Prometheus-Stack)
使用官方的Helm Chart图表包,它包含了Prometheus、Grafana、Alertmanager等全套组件,并已针对Kubernetes优化。
- 在Kubernetes集群主节点56.111(或可访问集群的机器)上执行:
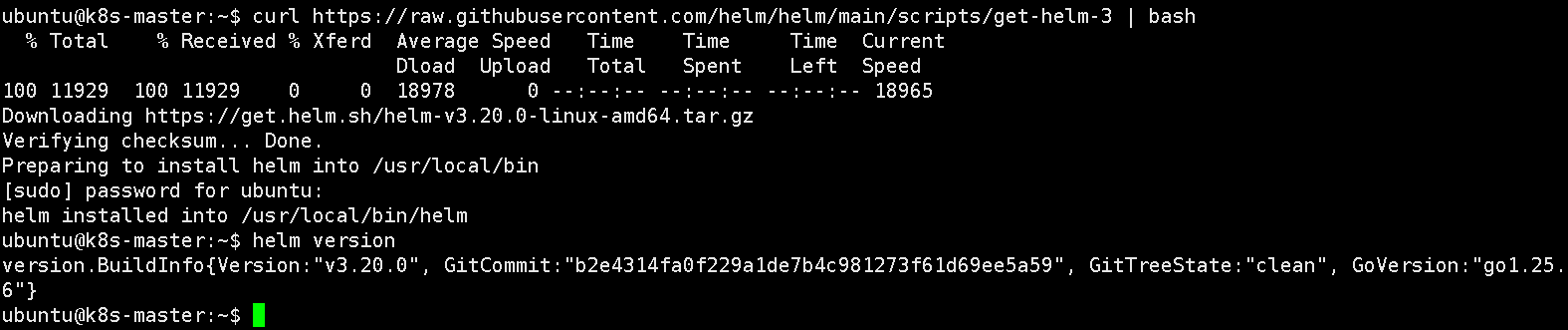
下载Helm仓库并立即执行安装脚本(k8s-master 节点执行)
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
helm version
- helm version:v3.20.0
2、添加 Prometheus Community Helm 仓库
方法1
官方Helm 镜像源(不稳定)
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
阿里云 Helm 镜像源 (虽然可用,但组件不全)
helm repo add prometheus-community https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
更新仓库
helm repo update

问题1:添加 Helm 库失败,无法访问gtihub.com
解决方法:
1)将github的ip地址添加到本地的hosts文件中
- 编辑C:\Windows\System32\drivers\etc下的hosts文件,将github的ip地址:140.82.113.3 github.com 保持到hosts文件

2)添加Helm 官方源
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
- 添加成功

- 可以访问github
3)2FA认证
登录github后可能会提示,需要2FA认证:Enable two-factor authentication (2FA)
解决方法:https://blog.csdn.net/liu_chen_yang/article/details/146147952
方法2
1)绕过 Helm 仓库机制,采用 离线部署(air-gapped style):下载 → 上传 → 本地 Helm 安装。
直接在浏览器中下载kube-prometheus-stack-81.6.9.tgz,再从本地使用fliezilla上传到K8smaster111服务器:
兼容 Kubernetes v1.28+
支持 Prometheus v2.50+
2) 在浏览器中下载kube-prometheus-stack-81.6.9.tgz
https://github.com/prometheus-community/helm-charts/releases/download/kube-prometheus-stack-81.6.9/kube-prometheus-stack-81.6.9.tgz
3) 从本地使用fliezilla上传到K8s master111服务器后,等待后续部署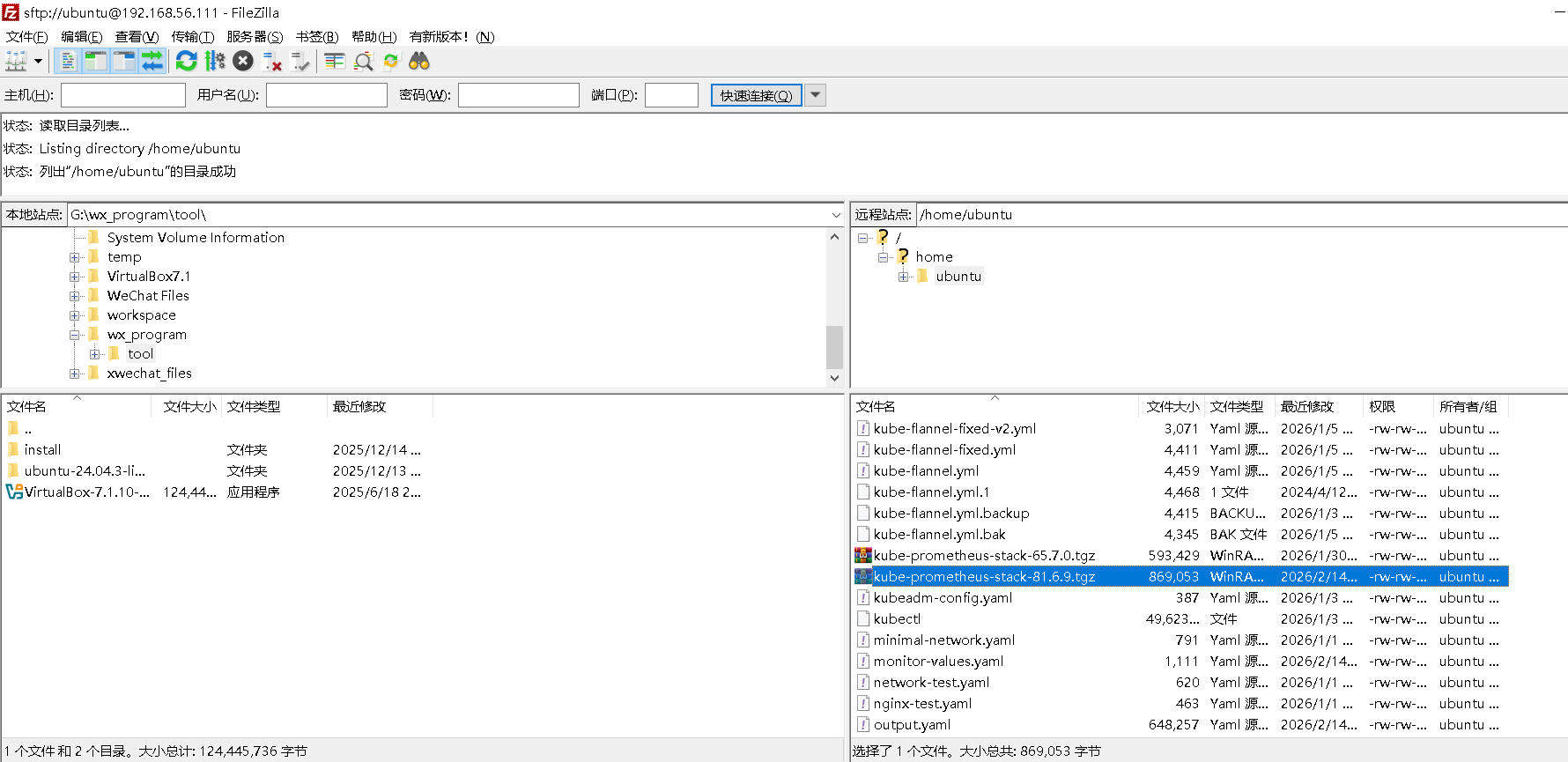
如果后续想升级版本,需要:
前提:版本一定要兼容!!!
1 去 GitHub Releases - kube-prometheus-stack 下载新 .tgz 上传到
master
2 修改 fix-monitor-final.yaml(适配新版本字段)
3 helm upgrade 或卸载重装
3、创建 monitoring 命名空间
kubectl create namespace monitoring

4、创建自定义 fix-monitor-final.yaml
fix-monitor-final.yaml文件的作用:
Helm Chart 的自定义配置文件,用于覆盖 kube-prometheus-stack 默认参数,实现:使用阿里ACR镜像源(避免拉取失败)
开启/关闭组件(如 node-exporter)
配置监控目标(如外部 MariaDB)
设置 Grafana 访问方式(NodePort + 密码)
调整存储、安全、网络等高级选项
第一步:创建 imagePullSecrets
Kubernetes 必须能登录 ACR 才能拉取私有镜像。
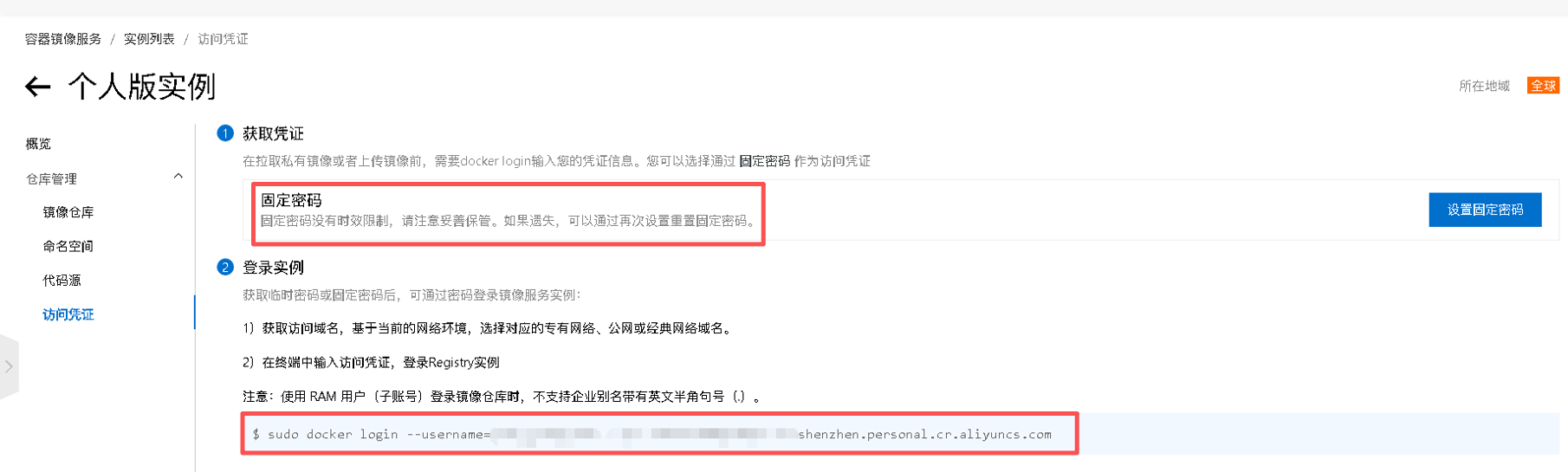
阿里云ACR: https://cr.console.aliyun.com/cn-shenzhen/instance/credentials
- 获取 ACR镜像源 凭证
在阿里云账号中,进入「访问凭证」页面,点击「设置固定密码」
复制 用户名 和 密码 - 创建 Secret (填写镜像地址,账密)
kubectl create secret docker-registry acr-secret \
--namespace monitoring \
--docker-server=crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com \
--docker-username="xxx" \
--docker-password="xxx" \
第二步:拉取所需镜像到acr镜像库
可参考之前写的如何用云效获取所需镜像:https://blog.csdn.net/qq_38444844/article/details/156084907?spm=1011.2415.3001.5331
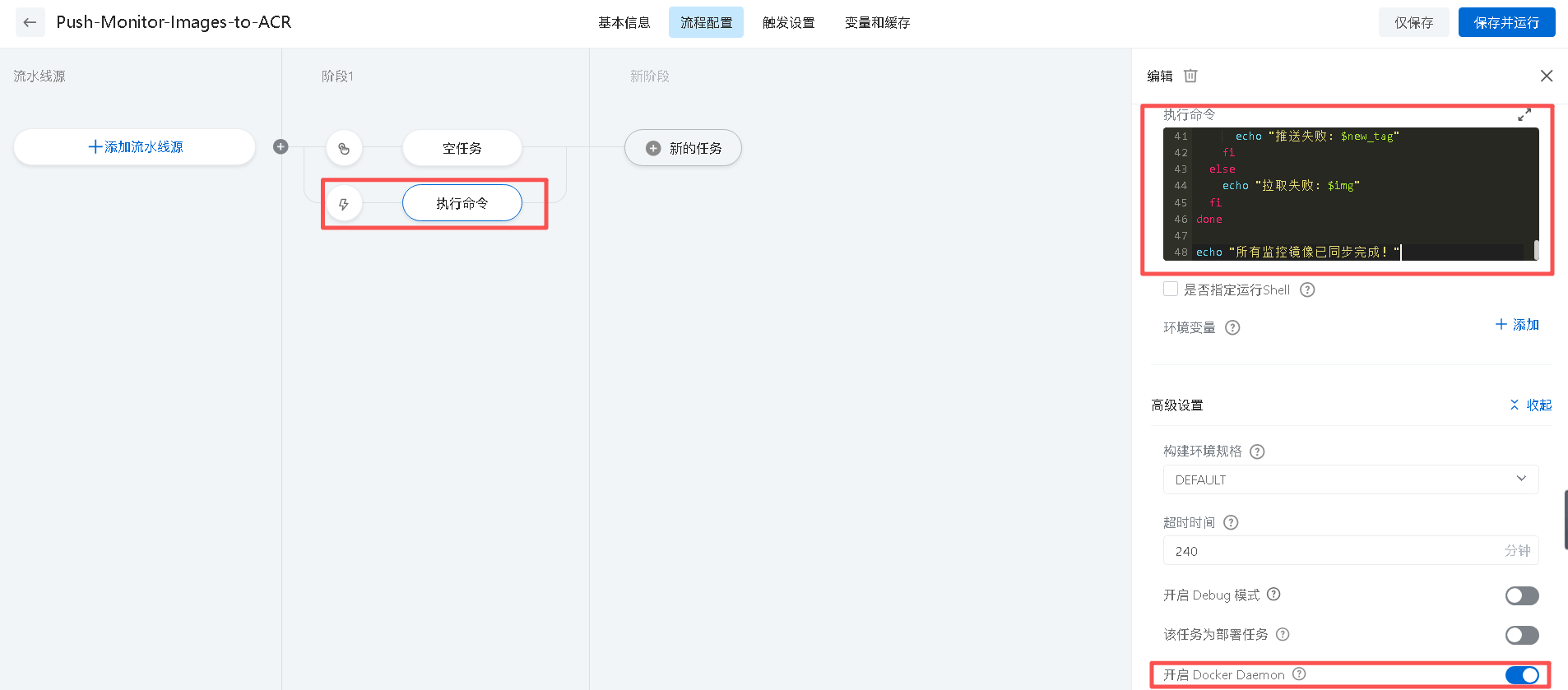
- 在云效中拉取镜像的脚本
#!/bin/bash
# === 配置参数,在第一步中获取! ===
USERNAME="xxx"
PASSWORD="xxx"
REGISTRY_DOMAIN="xxx"
# 登录 ACR
echo "$PASSWORD" | docker login --username="$USERNAME" --password-stdin "$REGISTRY_DOMAIN"
# 定义要同步的镜像列表
images=(
"quay.io/prometheus-operator/prometheus-operator:v0.77.0"
"quay.io/prometheus-operator/prometheus-config-reloader:v0.77.0"
"quay.io/thanos/thanos:v0.36.1"
"registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.12.0"
"prom/prometheus:v2.50.1"
"prom/alertmanager:v0.27.0"
"prom/node-exporter:v1.8.2"
"grafana/grafana:10.4.3"
"kiwigrid/k8s-sidecar:1.28.0"
)
# 同步每个镜像
for img in "${images[@]}"; do
echo "处理镜像: $img"
# 拉取原始镜像
if docker pull "$img"; then
# 构造新标签:使用 mirrors-yuan 命名空间
new_tag="${REGISTRY_DOMAIN}/mirrors-yuan/$(echo "$img" | sed 's/[\/:]/-/g')"
# 打 tag
docker tag "$img" "$new_tag"
# 推送
if docker push "$new_tag"; then
echo "成功推送: $new_tag"
else
echo "推送失败: $new_tag"
fi
else
echo "拉取失败: $img"
fi
done
echo "所有监控镜像已同步完成!"
- 在云效中拉取镜像的脚本(优化版)
修改了推送到个人ACR后所有镜像版本都显示是latest的问题,应该是各个镜像对应版本号
#!/bin/bash
# === 配置参数 ===
USERNAME="xxx"
PASSWORD="xxx"
REGISTRY_DOMAIN="xxx"
# 登录 ACR
echo "$PASSWORD" | docker login --username="$USERNAME" --password-stdin "$REGISTRY_DOMAIN"
# 定义要同步的镜像列表
images=(
"quay.io/prometheus-operator/prometheus-operator:v0.77.0"
"quay.io/prometheus-operator/prometheus-config-reloader:v0.77.0"
"quay.io/thanos/thanos:v0.36.1"
"registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.12.0"
"prom/prometheus:v2.50.1"
"prom/alertmanager:v0.27.0"
"prom/node-exporter:v1.8.2"
"grafana/grafana:10.4.3"
"kiwigrid/k8s-sidecar:1.28.0"
)
# 同步每个镜像
for img in "${images[@]}"; do
echo "处理镜像: $img"
# 拉取原始镜像
if docker pull "$img"; then
# 分离镜像名和版本号
image_name=$(echo "$img" | cut -d':' -f1) # 如: quay.io/prometheus-operator/prometheus-operator
version=$(echo "$img" | cut -d':' -f2) # 如: v0.77.0
# 构造新的镜像名:将路径中的 / 替换为 -,但保留版本号
new_image_name="${REGISTRY_DOMAIN}/mirrors-yuan/$(echo "$image_name" | sed 's/\//-/g')"
# 构造完整的新标签(带版本号)
new_tag="${new_image_name}:${version}"
# 打 tag
docker tag "$img" "$new_tag"
# 推送
if docker push "$new_tag"; then
echo "成功推送: $new_tag"
else
echo "推送失败: $new_tag"
fi
else
echo "拉取失败: $img"
fi
done
echo "所有监控镜像已同步完成!"
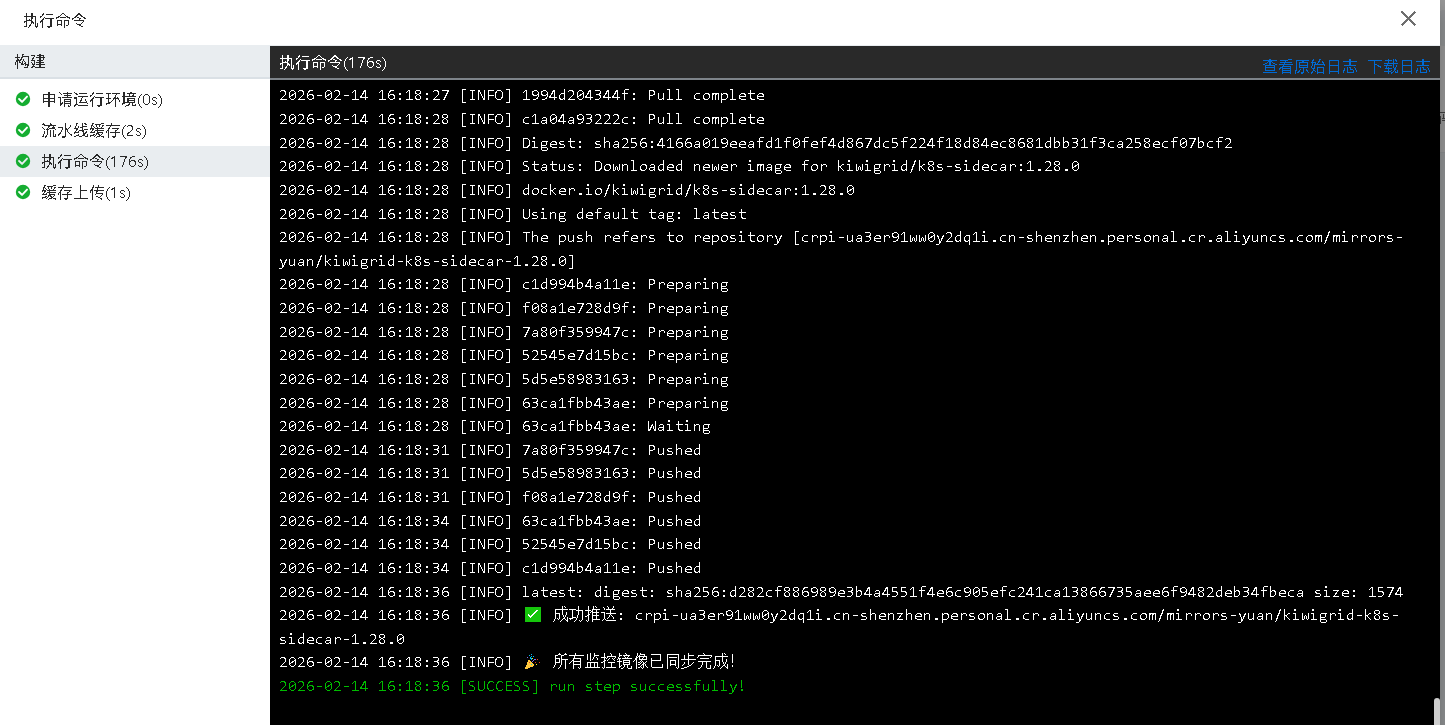
- 成功推送镜像到个人acr仓库
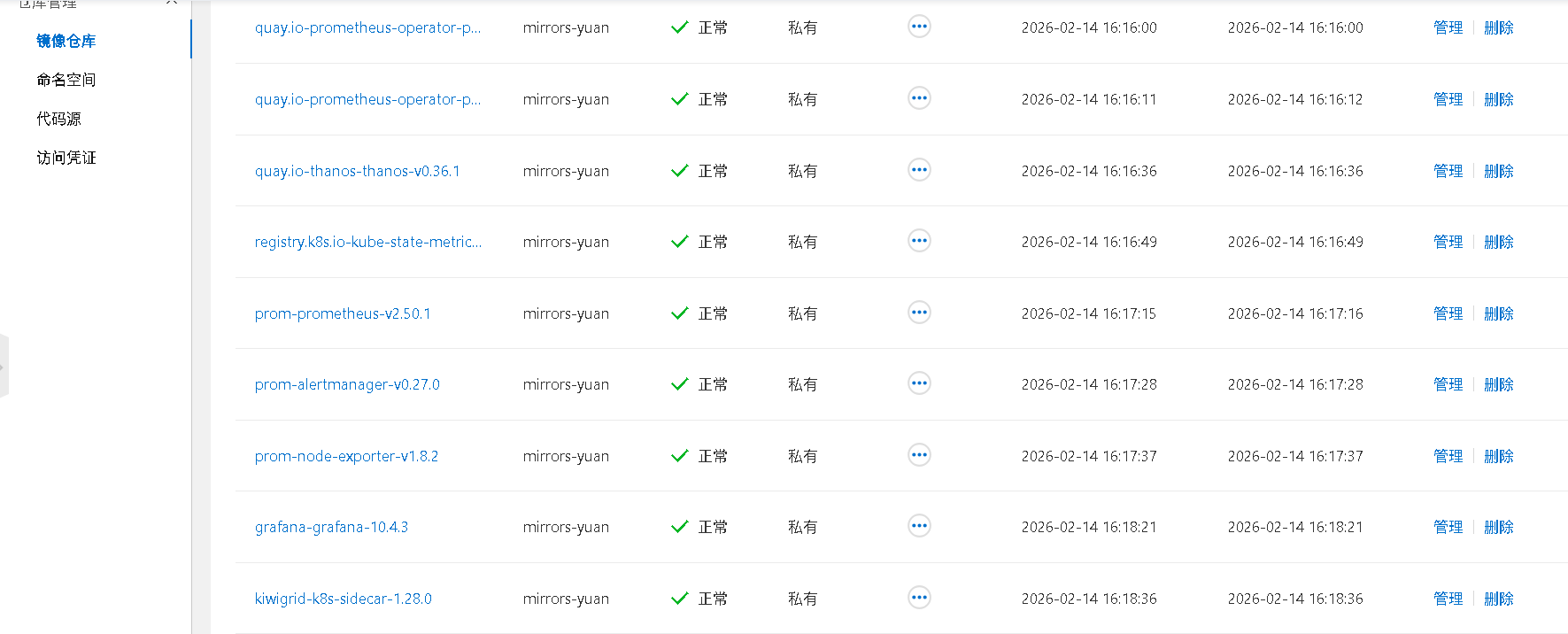
第三步:创建fix-monitor-final.yaml 配置文件
- cd ~ :回到home目录当前用户下创建fix-monitor-final.yaml 文件:
- 把配置文件中所有官方镜像改为acr镜像
镜像格式:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/具体镜像名和版本
cat > fix-monitor-final.yaml << 'EOF'
# 全局配置,包含镜像拉取密钥
global:
imagePullSecrets:
- name: acr-secret
# Prometheus Operator 配置
prometheusOperator:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/quay.io-prometheus-operator-prometheus-operator-v0.77.0
tag: latest
admissionWebhooks:
enabled: false # 禁用webhook
tls:
enabled: false # 新增:禁用 TLS,避免挂载 secret
# Prometheus配置重载器镜像配置
prometheusConfigReloader:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/quay.io-prometheus-operator-prometheus-config-reloader-v0.77.0
tag: latest
# Thanos 相关配置
thanos:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/quay.io-thanos-thanos-v0.36.1
tag: latest
# kube-state-metrics 配置
kube-state-metrics:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/registry.k8s.io-kube-state-metrics-kube-state-metrics-v2.12.0
tag: latest
# Prometheus 自身配置
prometheus:
prometheusSpec:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/prom-prometheus-v2.50.1
tag: latest
# Alertmanager 配置
alertmanager:
alertmanagerSpec:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/prom-alertmanager-v0.27.0
tag: latest
# Node Exporter 配置
prometheus-node-exporter:
version: 1.8.2
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/prom-node-exporter-v1.8.2
tag: latest
# Grafana 配置
grafana:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/grafana-grafana-10.4.3
tag: latest
sidecar:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/kiwigrid-k8s-sidecar-1.28.0
tag: latest
EOF
- 优化后的fix-monitor-final.yaml 配置文件,把latest修改成对应版本号
cat > fix-monitor-final.yaml << 'EOF'
# 全局配置,包含镜像拉取密钥
global:
imagePullSecrets:
- name: acr-secret
# Prometheus Operator 配置
prometheusOperator:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/quay.io-prometheus-operator-prometheus-operator
tag: v0.77.0
admissionWebhooks:
enabled: false # 禁用 webhook
tls:
enabled: false # 禁用 TLS
# Prometheus 配置重载器镜像配置
prometheusConfigReloader:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/quay.io-prometheus-operator-prometheus-config-reloader
tag: v0.77.0
# Thanos 相关配置
thanos:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/quay.io-thanos-thanos
tag: v0.36.1
# kube-state-metrics 配置
kube-state-metrics:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/registry.k8s.io-kube-state-metrics-kube-state-metrics
tag: v2.12.0
# Prometheus 自身配置
prometheus:
prometheusSpec:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/prom-prometheus
tag: v2.50.1
# Alertmanager 配置
alertmanager:
alertmanagerSpec:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/prom-alertmanager
tag: v0.27.0
# Node Exporter 配置
prometheus-node-exporter:
version: 1.8.2
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/prom-node-exporter
tag: v1.8.2
# Grafana 配置
grafana:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/grafana-grafana
tag: "10.4.3"
sidecar:
image:
registry: crpi-ua3er91ww0y2dq1i.cn-shenzhen.personal.cr.aliyuncs.com
repository: mirrors-yuan/kiwigrid-k8s-sidecar
tag: "1.28.0"
EOF
- 验证配置文件
1 验证文件是否创建成功
ls -l fix-monitor-final.yaml
2 查看当前 Helm release 实际生效的配置
helm get values monitoring -n monitoring
拓展:webhook准入控制器
为什么禁用禁Webhook:因为它不是Prometheus 核心监控功能所必需的
在 kube-prometheus-stack(即 Prometheus Operator)中,Admission Webhooks 指的是 Kubernetes 准入控制器(Admission Controller),具体是:
Validating Admission Webhook:在你创建/更新PrometheusRule、AlertmanagerConfig、ServiceMonitor 等自定义资源(CR)时,自动校验其YAML 是否合法。它由一个叫 kube-webhook-certgen 的 Job 动态生成 TLS 证书,并注册到 Kubernetes 的ValidatingWebhookConfiguration 中。
Webhook 启动需要运行两个一次性 Job:
admission-create:生成证书
admission-patch:注入证书到 webhook 配置
这两个 Job 使用的镜像是:
registry.k8s.io/kube-webhook-certgen:v1.5.3
5、部署Prometheus 监控栈(kube-prometheus-stack)
1. 回到主目录
cd /home/ubuntu
2. 创建目录
mkdir -p /home/ubuntu/prometheus-crd
cd /home/ubuntu/prometheus-crd
3. 解压:安装时会自动解压 (查看文件是否完整)
tar xzf /home/ubuntu/kube-prometheus-stack-81.6.9.tgz
4. 返回主目录
cd /home/ubuntu
4.1 检查文件是否存在
ls -l kube-prometheus-stack-81.6.9.tgz fix-monitor-final.yaml
4.2 本地安装 或 升级 Helm Chart (监控栈)
helm upgrade --install monitoring ./kube-prometheus-stack-81.6.9.tgz \
--namespace monitoring \
--create-namespace \ # 如果 namespace 可能不存在
-f fix-monitor-final.yaml \
--timeout 10m0s \ # 建议设置足够长的时间,避免因镜像拉取慢而超时
--wait # 等待所有 Pod 就绪
优化后的流程:
- 因为Kubernetes 集群里的 Pod 仍然会尝试去拉取旧的 latest 标签,所以需要重新执行helm部署命令
helm upgrade --install monitoring ./kube-prometheus-stack-81.6.9.tgz \
--namespace monitoring \
--create-namespace \
-f fix-monitor-final.yaml \
--timeout 10m0s \
--wait \
--debug # 开启调试模式,能看拉取镜像日志过程
查看pod状态
watch kubectl get pods -n monitoring
删除所有非 Running 的 Pod
kubectl delete pod -n monitoring --field-selector=status.phase!=Running
如果有问题,查看具体pod日志
kubectl describe pod -n monitoring monitoring-kube-prometheus-operator-d96568494-7gwbc
问题2:CRI 插件配置错误
问题场景:
Kubernetes 节点使用 containerd 作为容器运行时(v1.6+), 因为容器中 systemd_cgroup = true配置位置有问题,导致失败且重启服务后,出现 kubelet 无法与 containerd 通信,导致 Pod无法创建,集群不可用。
后果:
containerd 启动失败 → CRI 插件未加载kubelet 无法调用 CRI 接口 → 所有 Pod 处于 Pending 或 ContainerCreating
Helm 安装(如 Prometheus)因无法调度 Pod 而卡住或失败
错误日志:
failed to load plugin "io.containerd.grpc.v1.cri":
invalid plugin config: `systemd_cgroup` only works for runtime io.containerd.runtime.v1.linux
配置分析:
| 旧配置(错误) | 新配置(正确) |
|---|---|
[plugins."io.containerd.grpc.v1.cri"]systemd_cgroup = true |
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]SystemdCgroup = true |
字段名:systemd_cgroup(小写) |
字段名:SystemdCgroup(驼峰命名) |
- 根据containerd 版本调整配置,修改了下/etc/containerd/config.toml
1 停止 containerd
sudo systemctl stop containerd
2 使用这个配置,它兼容大多数 containerd 版本
sudo tee /etc/containerd/config.toml << 'EOF'
version = 2
root = "/var/lib/containerd"
state = "/run/containerd"
[grpc]
address = "/run/containerd/containerd.sock"
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.9"
# 移除 systemd_cgroup 设置,只在 runtime.options 中设置
# systemd_cgroup = true # 注释掉或删除这一行
[plugins."io.containerd.grpc.v1.cri".cni]
bin_dir = "/opt/cni/bin"
conf_dir = "/etc/cni/net.d"
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "runc"
snapshotter = "overlayfs"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true # 移到这里
[plugins."io.containerd.grpc.v1.cri".registry]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://docker.m.daocloud.io"]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."registry.k8s.io"]
endpoint = ["https://registry.aliyuncs.com/google_containers"]
EOF
- 验证并重启containerd
1 验证配置语法
sudo containerd config dump /etc/containerd/config.toml
2 重启 containerd
sudo systemctl start containerd
sudo systemctl status containerd
3 检查 CRI 插件是否正常
sudo ctr plugins ls | grep cri
4 如果上面显示正常,测试 CRI
sudo crictl version
- 重启 kubelet 测试
1 重启 kubelet
sudo systemctl restart kubelet
2 查看状态
sudo systemctl status kubelet
3 查看日志
sudo journalctl -u kubelet -n 20 --no-pager
总结:问题是之前博文中的配置与当前 containerd 版本不兼容导致的。在新版本的 containerd 中,systemd_cgroup 设置应该只在 runtime.options 中配置,而不是在 CRI 插件的顶层配置中。
一切正常,继续部署 Prometheus
拓展:CRD介绍
什么是 CRD?
CRD(Custom Resource Definition) 是 Kubernetes的扩展机制,允许用户定义自己的资源类型(如 Prometheus、ServiceMonitor、Alertmanager 等)。
作用:让Prometheus Operator 能通过声明式 API 管理监控组件。
为什么有时需要单独安装?
Helm 默认会在安装时创建 CRD,但 CRD 不属于 Helm Release 生命周期管理。
如果网络慢或镜像拉取失败,Helm 可能因等待 CRD 就绪而超时(报错:timed out waiting for the condition)
可以先手动应用 CRD,再用 --skip-crds 安装 Helm Chart。
- 手动安装方式
cd /home/ubuntu
1 从官方下载单文件 CRD
curl -L -o crd-all.yaml \
https://github.com/prometheus-community/helm-charts/raw/kube-prometheus-stack-81.6.9/charts/kube-prometheus-stack/crds/crd-all.yaml
2 应用CRD
kubectl apply -f crd-all.yaml
- CRD文件路径:/home/ubuntu/prometheus-crd/current

- 这些 CRD 共同构成了 Prometheus Operator 生态的核心,像管理 Deployment 一样用 YAML声明式地管理监控组件。
| 文件名 | 对应的自定义资源(kubectl 可操作) | 作用 |
|---|---|---|
prometheuses.monitoring.coreos.com.yaml |
Prometheus |
定义 Prometheus 实例(如副本数、存储、配置等) |
servicemonitors.monitoring.coreos.com.yaml |
ServiceMonitor |
声明如何监控某个 Service(自动发现 Pod + 抓取指标) |
podmonitors.monitoring.coreos.com.yaml |
PodMonitor |
直接监控一组 Pod(不通过 Service) |
prometheusrules.monitoring.coreos.com.yaml |
PrometheusRule |
定义告警规则和记录规则 |
alertmanagers.monitoring.coreos.com.yaml |
Alertmanager |
管理 Alertmanager 实例 |
thanosrulers.monitoring.coreos.com.yaml |
ThanosRuler |
用于 Thanos 的规则评估(高级用法) |
probes.monitoring.coreos.com.yaml |
Probe |
主动探测(HTTP/TCP 黑盒监控) |
scrapeconfigs.monitoring.coreos.com.yaml |
ScrapeConfig |
静态抓取配置(类似 Prometheus 的 static_configs) |
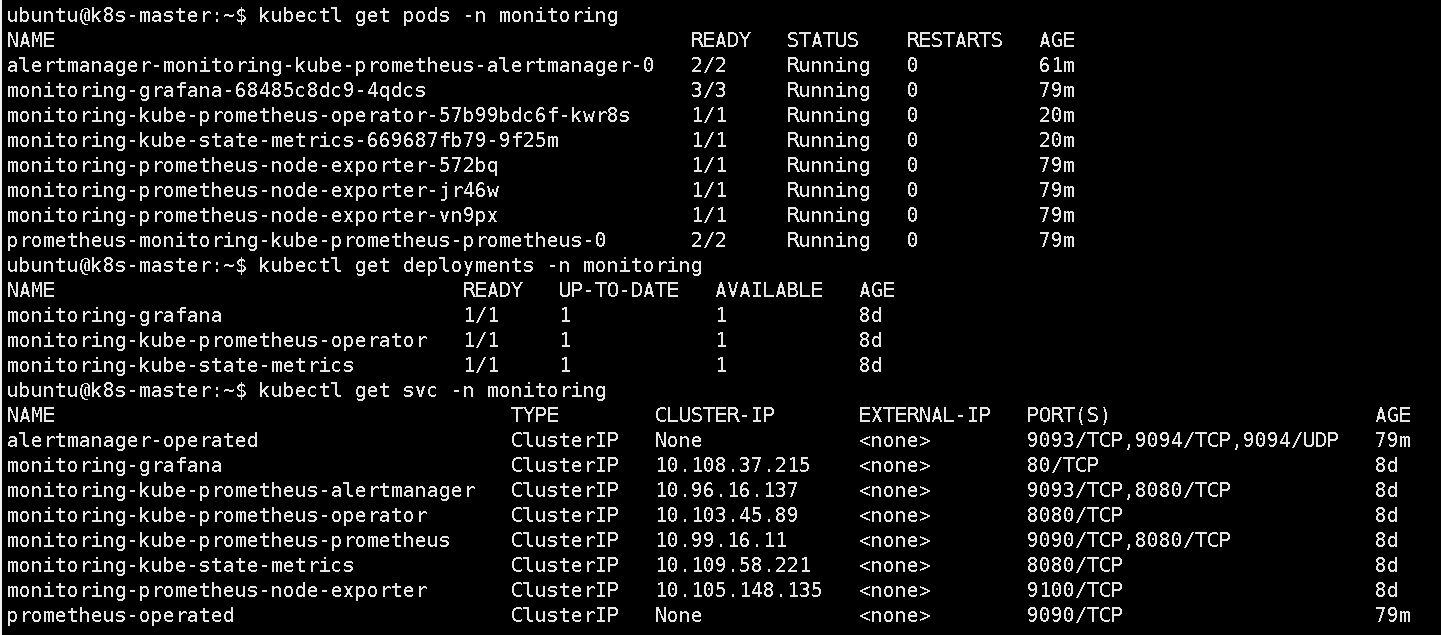
6、验证部署
1 查看监控命名空间下的所有 Pod
kubectl get pods -n monitoring
2 查看详细信息
kubectl get pods -n monitoring -o wide
3 查看部署状态
kubectl get deployments -n monitoring
4 查看服务
kubectl get svc -n monitoring
5 持续监控 Pod 状态
kubectl get pods -n monitoring -w
7、访问Prometheus Targets健康检查仪表盘
1 清理旧进程,避免端口被占用(可选)
pkill -f "kubectl port-forward"
2 启动转发(绑定到 0.0.0.0,防止 IPv6 问题)
kubectl port-forward -n monitoring svc/monitoring-kube-prometheus-prometheus --address 0.0.0.0 9090:9090
# Forwarding from 0.0.0.0:9090 -> 9090 表示成功
3 浏览器访问Prometheus,k8s-master IP + 端口
http://192.168.56.111:9090
http://192.168.56.111:9090/targets
- Prometheus 的工作原理是定期去拉取(Scrape)各种服务(如 Kubernetes 节点、Pod、Grafana等)的监控数据
8、访问 Grafana 仪表板
当 Grafana 显示无数据时,大部分的情况是因为 Prometheus 没有抓到数据。
方法1:端口转发,保持此终端窗口打开
1 获取密码
kubectl get secret --namespace monitoring monitoring-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo
2 确保 3000 端口未被占用,如果有输出,用 sudo kill -9 <PID> 杀死。
sudo ss -tlnp | grep :3000
3 启动端口转发并绑定所有网卡,持此终端窗口打开(不要按 Ctrl+C)
kubectl port-forward --address 0.0.0.0 -n monitoring svc/monitoring-grafana 3000:80
4 打开浏览器访问
http://192.168.56.111:3000/
账号:admin (默认)
密码:从上面命令中获取的值
- Prometheus+Grafana监控访问成功
方法2:长期稳定访问 Grafana(待优化!)
- 改用 NodePort 长期暴露服务(无需一直运行端口转发)
1 将 Grafana 服务类型改为 NodePort
kubectl patch svc -n monitoring monitoring-grafana -p '{"spec":{"type":"NodePort"}}'
2 查看分配的 NodePort
kubectl get svc -n monitoring monitoring-grafana
- 修改完成

问题:
从 master 节点 执行curl -I http://10.244.1.108:3000 直接访问 Pod超时,可能是CNI 网络插件(Flannel)有问题,导致无法跨节点通信,待优化!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)