【大模型微调实战】第2期:从“懂行”到“会用”——523条数据让存储模型学会专业问答
本文详细记录了存储领域大模型SFT(监督微调)的全过程。作者通过三层策略构建了523条高质量指令数据,包括手写核心样本和API批量生成数据。在6GB显存的限制下,采用QLoRA(4bit)和rank=8的配置完成微调,loss从2.43降至1.62。效果评估显示,SFT模型在专业术语使用、回答结构化和自然度方面显著提升,但也暴露出概念泛化不足的问题。文章还总结了数据生成、格式处理和显存优化等实战经
前言
在上一篇文章中,我完成了存储领域大模型的 CPT(持续预训练) 阶段。通过在 4790 个存储技术段落上训练,基座模型 Qwen3-4B 对存储术语和行文风格的建模能力显著提升,PPL 从 32.57 下降至 25.66,降幅达 21.2%。
但 CPT 模型有一个致命短板:它只会“续写”,不会“对话”。你给它一段存储文档,它能顺着往下编;但你问它“什么是 NVMe 协议”,它大概率会一脸茫然。
这正是 SFT(监督微调) 要解决的问题——教会模型遵循指令,根据用户的问题生成专业、准确、结构化的回答。
本文将完整记录我从 SFT 数据构建、训练配置调优到 效果评估的全过程。最终,我用 523 条高质量指令数据,让模型在 5 道存储核心问题上的回答专业度显著提升,同时也踩了不少值得反思的坑。
一、SFT 数据构建:质量优先的三层策略
SFT 的核心是 指令数据。每条数据包含 instruction(用户问题)、input(上下文,可为空)和 output(标准回答)。
我的目标是用最小成本构建 500 条左右的高质量存储领域问答对。为此设计了三层策略:
第一层:手写核心样本(23 条)
选取 NVMe 协议、V-NAND 原理、QLC 特性、预留空间(OP)、TurboWrite、FusionStorage 六个核心概念,每个概念手写 3~5 条不同角度的问答。
示例:
json
{
"instruction": "什么是 NVMe 协议?它相比 SATA 有什么优势?",
"input": "",
"output": "NVMe 是一种专为闪存设计的高速传输协议,通过 PCIe 总线直连 CPU,支持 64K 队列和每队列 64K 命令,延迟比 SATA 低一个数量级..."
}这 23 条样本的作用是 建立质量标准——让我清楚“好数据”应该长什么样。
第二层:API 批量生成(500 条)
基于 CPT 阶段切分好的 4012 个文档片段(每个 600 字符),调用阿里云百炼的 qwen3-vl-flash API 自动生成问答对。
选择这个模型的原因是它速度快、成本低。在严格限长后,单条问答消耗仅约 140 Token,最终生成 500 条仅用了约 7 万 Token。
生成提示词:
text
基于以下存储技术文档段落,生成一个高质量的问答对。
要求:
1. 问题必须像用户真实会问的,角度可以是定义解释、技术对比、操作指导等。
2. 回答必须专业、准确,严格基于段落内容,不得编造信息。
3. 输出格式为严格的JSON:{"instruction": "问题", "input": "", "output": "回答"}
段落内容:{paragraph}第三层:严格后处理(500 条 → 500 条)
对生成的 500 条数据执行了以下过滤:
-
JSON 格式校验(剔除解析失败的样本)
-
回答长度 ≥ 30 字符(剔除敷衍回答)
-
禁用词过滤(剔除包含“占位符”、“TODO”等词的样本)
-
基于
instruction字段的语义去重
最终 500 条全部合格,合格率 100%,无需额外清洗。
合并数据集
手写 23 条 + 自动生成 500 条 = 523 条 storage_sft_final.jsonl,覆盖存储协议、硬件原理、企业架构等全技术栈。
二、SFT 训练:在 6GB 显存上的又一次精打细算
2.1 关键配置
| 配置项 | 值 | 说明 |
|---|---|---|
| 基座模型 | Qwen3-4B-Instruct | 与 CPT 一致 |
| 检查点路径 | CPT 阶段 LoRA 权重 | 在领域知识基础上微调 |
| 微调方法 | QLoRA(4bit) | 6GB 显存刚需 |
| LoRA rank | 8(alpha=16) | 比 CPT 的 rank=16 更低,防 OOM |
| 学习率 | 2e-5 | SFT 通常略低于 CPT |
| 训练轮数 | 2 epochs | 523 条数据充分学习 |
| 截断长度 | 1024 | 与 CPT 一致 |
| 批处理大小 | 1 × 梯度累积 8 | 等效 batch=8 |
2.2 又遇 OOM:一个参数的差距
初次配置时,我使用了 rank=16,训练启动后直接 OOM。排查发现 SFT 加载 CPT 权重时,合并适配器会产生额外显存峰值,加上 WebUI 本身的显存占用,刚好超出 6GB 上限。
解决方案:
-
将 LoRA rank 降至 8
-
勾选
Upcast LayerNorm(将 LayerNorm 上转为 float32,提升量化训练稳定性) -
改用命令行启动,省去 WebUI 的约 300MB 显存
调整后显存峰值稳定在 5GB 左右,训练顺利进行。耗时约 35 分钟,loss 从 2.43 平稳降至 1.62。
2.3 Loss 曲线:训练收敛的可视化证明
LLaMA-Factory 自动记录了每一步的 loss 值,生成的 loss 曲线如下:
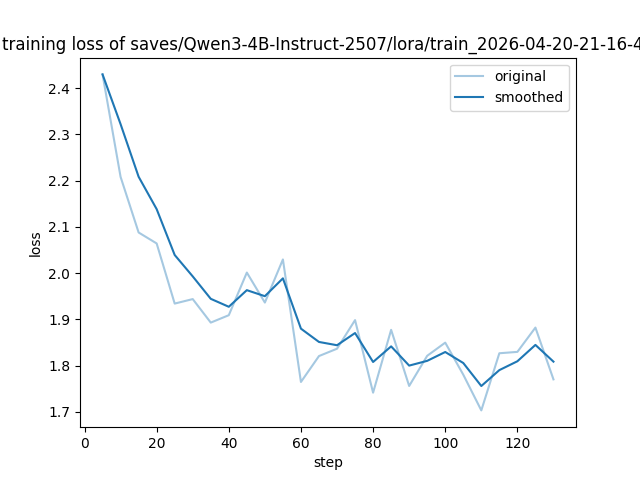
从图中可以看到:
-
初始 loss 约 2.43,随着训练推进稳步下降;
-
最终 loss 稳定在 1.62 左右;
-
整个下降过程平滑,未出现剧烈震荡或回升。
这表明训练过程稳定,模型收敛良好,未出现过拟合迹象。
三、效果评估:三级模型正面对比
为了客观衡量 SFT 的效果,我设计了 5 道存储领域核心问题,分别用 基座模型、CPT 模型 和 SFT 模型 生成回答,从四个维度进行对比:
| 维度 | 基座 → CPT | CPT → SFT | SFT 增量价值 |
|---|---|---|---|
| 术语准确性 | 小幅提升 | 显著提升 | SFT 能说出“自适应磨损均衡”、“读取预取”等具体技术名词 |
| 回答结构化 | 持平 | 显著提升 | SFT 用“硬件融合、软件融合、服务融合”三点概括复杂问题 |
| 回答自然度 | 持平 | 显著提升 | SFT 用口语化解释替代知识罗列,更贴近真实助手 |
| 泛化鲁棒性 | — | ⚠️ 部分问题偏差 | OP 问题回答跑偏,暴露了概念泛化不足 |
典型回答对比:NVMe 协议问题
问题:什么是 NVMe 协议?它相比 SATA 有什么优势?
基座模型回答(节选):
NVMe 协议是一种为固态硬盘设计的高速存储访问协议,基于 PCIe 总线,支持多队列、超低延迟和高吞吐量。相比 SATA,NVMe 避免了传统 ATA/SATA 接口的低效瓶颈。
CPT 模型回答(节选):
NVMe 协议是为 PCIe 上的 SSD 设计的,通过 NVMe over PCIe 将 SSD 暴露给操作系统。相比 SATA,NVMe 支持并行访问、命令可并发,读写速度极快、延迟低。
SFT 模型回答(节选):
NVMe 是一种用于在支持非易失性内存的存储设备上进行高效、低延迟数据访问的通信标准。它允许主机通过标准 PCIe 接口直接访问 SSD,从而实现极高的数据吞吐量和低延迟。相比 SATA,NVMe 的优势包括:异步操作降低命令响应时间、多队列支持提升并发能力、端到端错误报告增强可靠性。
分析:基座和 CPT 模型偏向“知识罗列”,而 SFT 模型的回答更口语化,用“允许主机通过标准 PCIe 接口直接访问 SSD”这样的解释性语言,更贴近真实用户的期待。
典型回答对比:FusionStorage 融合架构
问题:FusionStorage 8.0 的融合架构主要体现在哪些方面?
基座模型回答(节选):
融合架构体现在存储与计算的深度融合、多业务场景的融合支持、分布式架构与高可用性融合等方面。
CPT 模型回答(节选):
FusionStorage 8.0 采用统一的融合架构,将计算、存储、网络、管理等资源深度融合,支持资源池化和动态调度。
SFT 模型回答(节选):
FusionStorage 8.0 的融合架构主要体现在:① 硬件融合,采用统一硬件平台支持多种存储类型的混合部署;② 软件融合,通过统一软件栈实现跨存储类型的资源调度;③ 服务融合,所有存储服务在融合架构下统一管理。这三者共同构建了高效、灵活、可扩展的融合架构。
分析:SFT 模型的回答用“硬件融合、软件融合、服务融合”三点高度概括,结构清晰、语言专业,展现了极强的信息归纳能力。这是基座和 CPT 模型都不具备的。
翻车案例:预留空间(OP)问题
问题:预留空间(OP)如何影响 SSD 的随机写入性能和寿命?
基座模型回答:正确解释了 OP 的定义,以及它如何通过降低写放大、提升垃圾回收效率来改善性能和寿命。
SFT 模型回答:将 OP 误解为“保留空间(Reservation Space)”,回答偏离了问题本意。
原因分析:SFT 数据集中 OP 相关的问法较单一(主要是“什么是 OP”、“OP 有什么作用”),模型对“同义异述”(将 OP 与“随机写入性能”关联提问)的泛化能力不足。这恰恰是评估体系应该暴露的问题——如果只看熟悉的测试题,永远发现不了模型的短板。
启示:SFT 数据的问法多样性比绝对数量更重要。在实际生产环境中,需要持续收集用户真实提问,不断补充变体问法来迭代模型。
四、踩坑与反思
坑 1:自动生成数据的 Token 异常飙升
初次生成时,单条问答消耗竟高达 6 万 Token。排查发现 corpus.txt 中 NVMe 规范段落长达 224 万字符,API 每次送入数万 Token。
解决:重建切分脚本,将片段严格限制在 600 字符以内,单条 Token 消耗降至 140。
坑 2:手写样本格式混乱导致合并失败
手写样本保存时混用了独立 JSON 对象和数组格式,导致解析脚本跳过所有手写数据。
解决:编写正则脚本,将混合格式统一转换为标准 JSONL。
坑 3:SFT 训练 OOM
见上文,本质是显存临界状态下多个因素叠加。
启示:消费级显卡上做微调,必须精打细算每一 MB 显存——截断长度、LoRA rank、是否启用 WebUI,每个选择都可能是 OOM 与否的分水岭。
坑 4:评估体系设计不足
OP 问题的翻车让我意识到:如果只用训练集中出现过的问法来评估,永远发现不了泛化问题。评估体系必须包含“同义异述”测试,才能真实反映模型的鲁棒性。
五、阶段性成果与展望
| 阶段 | 状态 | 核心产出 |
|---|---|---|
| CPT 训练 | ✅ 完成 | 领域 PPL 下降 21.2% |
| SFT 数据构建 | ✅ 完成 | 523 条高质量指令数据 |
| SFT 训练 | ✅ 完成 | SFT LoRA 权重已保存 |
| SFT 效果评估 | ✅ 完成 | 5 题对比,4 题显著提升,1 题暴露泛化短板 |
当前模型定位:一个能听懂存储问题、并用专业术语给出结构化回答的领域助手。但它在安全性、偏好对齐和推理效率上还有提升空间。
下一步计划:
-
DPO 阶段:构造偏好数据,让回答更符合“专业、准确、安全”的人类偏好。
-
部署阶段:模型量化(AutoAWQ)+ vLLM 推理加速 + 性能剖析,打造完整的训练-部署闭环。
写在最后
如果说 CPT 是让模型“上专业课”,那 SFT 就是让它“做练习题”——学会把知识用对地方。523 条数据看似不多,但每一条都经过精心设计和严格过滤,最终带来了肉眼可见的回答质量提升。
当然,SFT 不是终点。如何让模型在“不懂”时坦诚说“不知道”,如何在部署时榨干硬件的每一分性能,是接下来要攻克的下一个山头。
敬请期待本系列第三期:从“会用”到“用得好”——DPO 偏好对齐与模型部署实战。
附:SFT 阶段关键文件
text
~/KnowledgeForge/ ├── storage_sft_final.jsonl # 最终 SFT 数据集(523 条) ├── sft_config.yaml # SFT 训练配置 ├── eval_sft_compare.py # 三级模型对比评估脚本 ├── sft_eval_results.json # 评估结果 ├── sft_training_loss.png # 训练 Loss 曲线图 └── checkpoints/sft/ # SFT LoRA 权重

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)