阿里通义Z-Image-Turbo部署教程:Windows平台WSL2环境适配指南
本文介绍了如何在星图GPU平台上自动化部署阿里通义Z-Image-Turbo WebUI图像快速生成模型(二次开发构建by科哥)。该平台简化了部署流程,用户可快速搭建AI图像生成环境,轻松应用于创意图片生成、设计素材制作等场景,显著提升内容创作效率。
阿里通义Z-Image-Turbo部署教程:Windows平台WSL2环境适配指南
1. 前言
如果你是一个Windows用户,想体验阿里通义最新的Z-Image-Turbo图像生成模型,可能会遇到一个头疼的问题:这个模型通常是在Linux环境下运行的,而你的电脑装的是Windows系统。难道为了用这个AI模型,还得重装系统或者搞个双系统吗?
别担心,今天我就来分享一个完美的解决方案——在Windows上通过WSL2(Windows Subsystem for Linux)来部署Z-Image-Turbo。这个方法不仅让你能在熟悉的Windows环境下工作,还能享受到Linux系统的兼容性,可以说是两全其美。
我最近刚在自己的Windows 11电脑上成功部署了Z-Image-Turbo的WebUI版本,整个过程比想象中要顺利。下面我就把详细的步骤、遇到的坑以及解决方法都分享出来,让你也能在Windows上轻松玩转这个强大的AI图像生成工具。
2. 什么是Z-Image-Turbo?
在开始部署之前,我们先简单了解一下Z-Image-Turbo到底是什么。
Z-Image-Turbo是阿里通义实验室推出的一个图像生成模型,它基于最新的扩散模型技术,能够根据文字描述快速生成高质量的图像。相比之前的版本,它的生成速度更快,图像质量也更高,而且对中文提示词的支持特别好。
这个模型有几个很实用的特点:
- 快速生成:名字里的"Turbo"不是白叫的,生成速度确实快
- 高质量输出:支持最高2048×2048的分辨率,细节表现很好
- 中文友好:对中文提示词的理解很到位,不用非得用英文
- WebUI界面:有图形化操作界面,不用写代码也能用
现在你可能会问:"这么好的工具,为什么在Windows上部署这么麻烦?" 主要是因为AI模型通常依赖一些在Linux上更成熟的工具链和库,比如PyTorch、CUDA这些。不过有了WSL2,这个问题就迎刃而解了。
3. 环境准备:WSL2安装与配置
3.1 检查系统要求
在开始之前,先确认你的电脑是否符合要求:
- 操作系统:Windows 10版本2004或更高,或者Windows 11
- 内存:建议16GB或以上(AI模型比较吃内存)
- 存储空间:至少50GB可用空间(模型文件就很大)
- 显卡:NVIDIA显卡,支持CUDA(如果没有独显,也可以用CPU模式,但速度会慢很多)
你可以按Win + R,输入winver查看Windows版本。如果是老版本,可能需要先更新系统。
3.2 安装WSL2
WSL2的安装其实很简单,微软已经把它做得很友好了。下面是具体步骤:
-
以管理员身份打开PowerShell
- 在开始菜单搜索"PowerShell"
- 右键选择"以管理员身份运行"
-
启用WSL功能 在PowerShell中输入以下命令:
wsl --install这个命令会自动安装WSL2和默认的Linux发行版(通常是Ubuntu)。
-
重启电脑 安装完成后,系统会提示你重启。一定要重启,否则WSL无法正常工作。
-
设置WSL版本为2 重启后,再次以管理员身份打开PowerShell,输入:
wsl --set-default-version 2 -
安装Ubuntu 打开Microsoft Store,搜索"Ubuntu",选择最新的LTS版本安装。我用的Ubuntu 22.04 LTS,比较稳定。
3.3 配置WSL2
安装完Ubuntu后,第一次启动会要求你创建用户名和密码。记住这个密码,后面会经常用到。
接下来我们需要做一些优化配置,让WSL2更适合跑AI应用:
-
分配更多内存和CPU WSL2默认的内存分配可能不够用,我们需要调整一下。
在Windows用户目录下(通常是
C:\Users\你的用户名),创建或编辑文件.wslconfig,添加以下内容:[wsl2] memory=8GB # 根据你的内存调整,建议8-16GB processors=4 # 分配4个CPU核心 swap=4GB # 交换空间 localhostForwarding=true保存后,在PowerShell中执行:
wsl --shutdown wsl这样WSL2会重启并应用新的配置。
-
更新系统包 在Ubuntu终端中,执行:
sudo apt update sudo apt upgrade -y -
安装必要的工具
sudo apt install -y wget curl git python3 python3-pip python3-venv
4. 安装CUDA和PyTorch
4.1 安装NVIDIA驱动
这是最关键的一步。WSL2中的Linux可以直接使用Windows的NVIDIA驱动,所以我们需要:
-
在Windows上安装NVIDIA驱动
- 访问NVIDIA官网下载最新的Game Ready驱动
- 安装时选择"自定义安装",勾选"执行清洁安装"
- 安装完成后重启电脑
-
验证驱动安装 在PowerShell中运行:
nvidia-smi你应该能看到类似这样的输出,显示你的显卡信息和CUDA版本:
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 535.154.05 Driver Version: 535.154.05 CUDA Version: 12.2 | |-------------------------------+----------------------+----------------------+ | GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 NVIDIA GeForce RTX 4060 | WDDM On | 00000000:01:00.0 On | | N/A 45C P8 10W / 115W | 682MiB / 8192MiB | 0% Default |
4.2 在WSL2中安装CUDA
现在回到Ubuntu终端,安装CUDA工具包:
# 添加NVIDIA CUDA仓库
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt update
# 安装CUDA
sudo apt install -y cuda-toolkit-12-2
# 验证安装
nvcc --version
如果看到CUDA版本信息,说明安装成功。
4.3 安装PyTorch
Z-Image-Turbo基于PyTorch,所以我们需要安装带CUDA支持的PyTorch:
# 创建Python虚拟环境(推荐)
python3 -m venv ~/zimage-env
source ~/zimage-env/bin/activate
# 安装PyTorch(根据你的CUDA版本选择)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 验证PyTorch是否能识别GPU
python3 -c "import torch; print(f'PyTorch版本: {torch.__version__}'); print(f'CUDA可用: {torch.cuda.is_available()}'); print(f'GPU数量: {torch.cuda.device_count()}')"
如果输出显示CUDA可用,并且GPU数量大于0,那么恭喜你,最困难的部分已经完成了!
5. 部署Z-Image-Turbo WebUI
5.1 下载项目代码
现在我们来部署Z-Image-Turbo的WebUI版本。这个版本是科哥基于原模型二次开发的,提供了图形化界面,用起来更方便。
# 克隆项目代码
cd ~
git clone https://github.com/kevin-meng/Z-Image-Turbo-WebUI.git
cd Z-Image-Turbo-WebUI
# 安装依赖
pip install -r requirements.txt
5.2 下载模型文件
Z-Image-Turbo的模型文件比较大(大概7-8GB),需要从ModelScope下载:
# 安装ModelScope
pip install modelscope
# 下载模型(这步可能需要一些时间,取决于你的网速)
python -c "from modelscope import snapshot_download; snapshot_download('Tongyi-MAI/Z-Image-Turbo', cache_dir='./models')"
如果下载速度慢,你也可以手动下载:
- 访问 https://www.modelscope.cn/models/Tongyi-MAI/Z-Image-Turbo
- 下载模型文件
- 解压到项目的
models目录下
5.3 配置环境变量
为了让WebUI能正确找到模型和运行环境,我们需要设置一些环境变量:
# 编辑bash配置文件
nano ~/.bashrc
# 在文件末尾添加以下内容
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export PYTHONPATH=/home/你的用户名/Z-Image-Turbo-WebUI:$PYTHONPATH
# 保存退出后,使配置生效
source ~/.bashrc
6. 启动WebUI并测试
6.1 启动服务
一切准备就绪,现在可以启动WebUI了:
# 进入项目目录
cd ~/Z-Image-Turbo-WebUI
# 激活虚拟环境(如果还没激活)
source ~/zimage-env/bin/activate
# 启动WebUI
bash scripts/start_app.sh
你会看到类似这样的输出:
==================================================
Z-Image-Turbo WebUI 启动中...
==================================================
模型加载成功!
启动服务器: 0.0.0.0:7860
请访问: http://localhost:7860
第一次启动会比较慢,因为需要加载模型到GPU内存,大概需要2-4分钟。耐心等待一下。
6.2 访问WebUI
在Windows的浏览器中打开:http://localhost:7860
你应该能看到这样的界面:
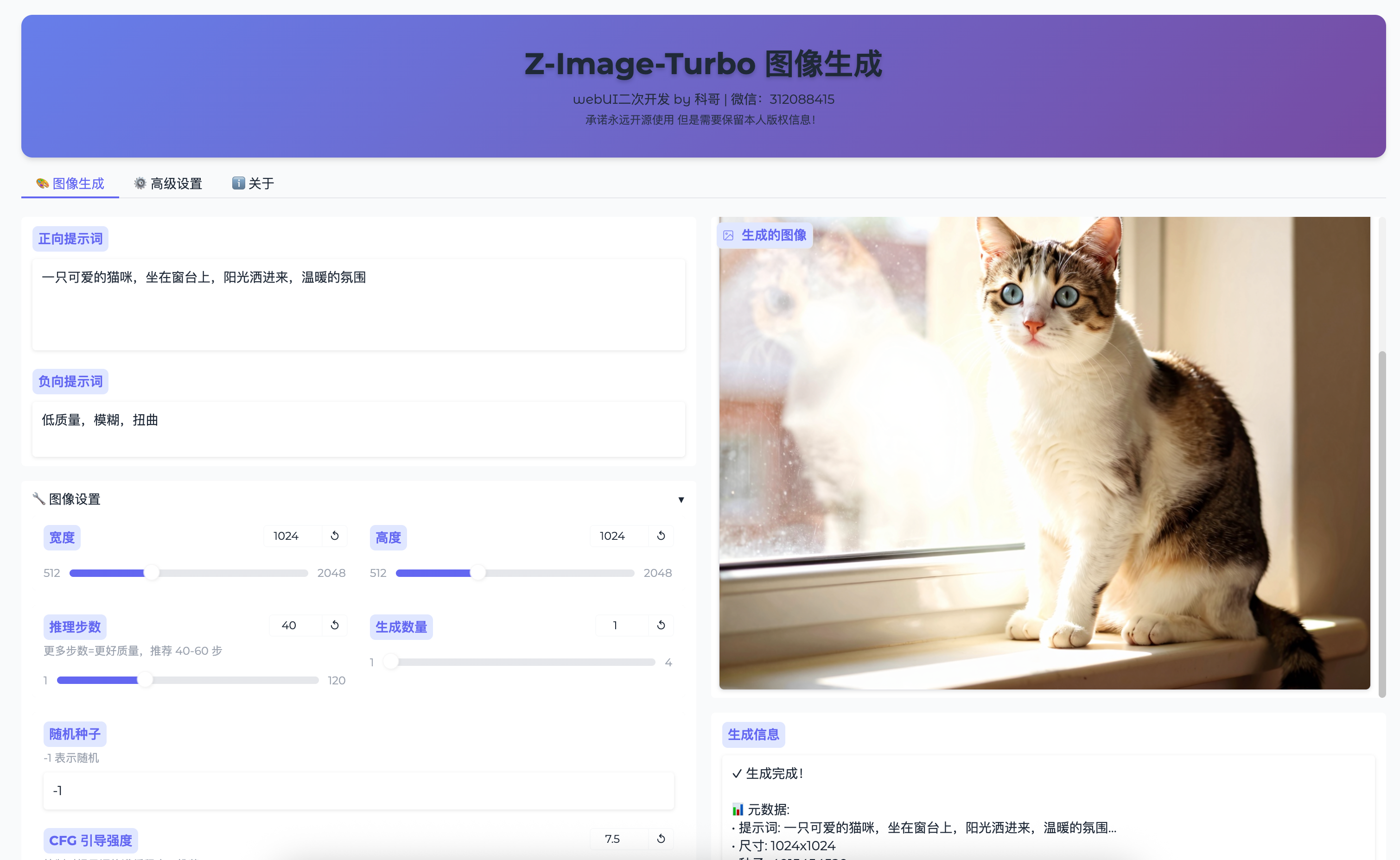
界面分为三个主要部分:
- 左侧参数面板:在这里输入提示词、调整参数
- 中间图像显示区:显示生成的图像
- 右侧信息面板:显示生成信息和操作按钮
6.3 第一次生成测试
让我们做个简单的测试,看看一切是否正常:
- 在"正向提示词"中输入:
一只可爱的橘色猫咪,坐在窗台上,阳光明媚 - 在"负向提示词"中输入:
低质量,模糊,扭曲 - 尺寸选择:
1024×1024 - 推理步数:
40 - CFG引导强度:
7.5 - 点击"生成"按钮
如果一切正常,你应该能在30-60秒内看到生成的猫咪图片。第一次生成后,后续的生成速度会快很多,大概15-30秒一张。
7. 常见问题与解决方法
在部署过程中,你可能会遇到一些问题。下面是我遇到的一些常见问题及其解决方法:
7.1 WSL2相关问题
问题1:WSL2启动失败或很慢
解决方法:
1. 检查虚拟化是否开启
- 重启电脑进入BIOS
- 找到Virtualization Technology或SVM Mode,设置为Enabled
2. 重置WSL2
wsl --shutdown
wsl --terminate Ubuntu
wsl --unregister Ubuntu
# 然后重新安装Ubuntu
问题2:WSL2内存不足
解决方法:
1. 编辑.wslconfig文件,增加内存分配
memory=12GB # 根据你的实际内存调整
2. 清理WSL2磁盘空间
# 在Ubuntu中
sudo apt clean
sudo rm -rf /var/lib/apt/lists/*
# 在PowerShell中压缩虚拟硬盘
wsl --shutdown
diskpart
select vdisk file="C:\Users\你的用户名\AppData\Local\Packages\...\ext4.vhdx"
compact vdisk
7.2 CUDA和PyTorch问题
问题3:PyTorch找不到CUDA
错误信息:CUDA unavailable
解决方法:
1. 确认NVIDIA驱动已安装
nvidia-smi # 应该在Windows PowerShell中运行
2. 检查WSL2中的CUDA
nvcc --version # 应该在Ubuntu中运行
3. 重新安装PyTorch(指定正确的CUDA版本)
pip uninstall torch torchvision torchaudio
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
问题4:显存不足
错误信息:CUDA out of memory
解决方法:
1. 降低图像尺寸
- 从1024×1024降到768×768或512×512
2. 减少生成数量
- 一次只生成1张图
3. 减少推理步数
- 从40步降到20-30步
4. 关闭其他占用显存的程序
7.3 模型加载问题
问题5:模型下载失败或很慢
解决方法:
1. 使用国内镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
2. 手动下载模型
- 从ModelScope网站直接下载
- 解压到项目的models目录
3. 使用代理(如果有的话)
export http_proxy=http://你的代理地址:端口
export https_proxy=http://你的代理地址:端口
问题6:WebUI无法访问
解决方法:
1. 检查服务是否启动
netstat -tlnp | grep 7860
2. 检查防火墙
# 在Windows中
- 打开Windows Defender防火墙
- 添加入站规则,允许7860端口
3. 尝试其他端口
# 修改启动脚本中的端口号
python -m app.main --port 8080
8. 性能优化建议
为了让Z-Image-Turbo在WSL2中运行得更流畅,这里有一些优化建议:
8.1 WSL2配置优化
编辑.wslconfig文件,添加以下优化配置:
[wsl2]
memory=12GB
processors=6
swap=8GB
localhostForwarding=true
# 以下为性能优化选项
[kernel]
commandLine = vsyscall=emulate
[interop]
enabled=true
appendWindowsPath=true
[user]
default=你的用户名
[boot]
systemd=true
8.2 PyTorch性能优化
在代码中添加以下优化:
import torch
# 启用TF32精度(RTX 30/40系列显卡)
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
# 使用更高效的内存分配器
os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'max_split_size_mb:128'
# 启用cudnn基准测试
torch.backends.cudnn.benchmark = True
8.3 生成参数优化
根据你的硬件调整生成参数:
| 硬件配置 | 推荐参数 | 生成时间 |
|---|---|---|
| RTX 4060 8GB | 1024×1024, 40步, CFG 7.5 | 15-25秒 |
| RTX 3060 12GB | 1024×1024, 30步, CFG 7.0 | 20-30秒 |
| RTX 2060 6GB | 768×768, 20步, CFG 6.5 | 25-35秒 |
| 无独显(CPU) | 512×512, 10步, CFG 5.0 | 2-5分钟 |
9. 使用技巧与最佳实践
9.1 提示词编写技巧
Z-Image-Turbo对中文提示词的支持很好,但写好提示词还是有技巧的:
好的提示词结构:
[主体] + [动作/姿态] + [环境] + [风格] + [质量]
示例:
一只可爱的橘色猫咪,坐在窗台上,阳光洒进来,温暖的氛围,
高清照片,景深效果,细节丰富
常用质量词:
高清照片、专业摄影、细节丰富4K分辨率、8K画质、超清电影质感、胶片风格、艺术照
9.2 批量生成技巧
虽然WebUI界面一次最多生成4张,但我们可以用脚本批量生成:
import time
from app.core.generator import get_generator
generator = get_generator()
prompts = [
"一只可爱的橘色猫咪,坐在窗台上,阳光明媚",
"壮丽的山脉日出,云海翻腾,油画风格",
"现代简约风格的客厅,阳光透过窗户,室内设计",
"科幻城市夜景,霓虹灯光,赛博朋克风格"
]
for i, prompt in enumerate(prompts):
print(f"生成第 {i+1} 张: {prompt}")
output_paths, gen_time, metadata = generator.generate(
prompt=prompt,
negative_prompt="低质量,模糊,扭曲",
width=1024,
height=1024,
num_inference_steps=40,
seed=-1, # 随机种子
num_images=1,
cfg_scale=7.5
)
print(f"生成完成,耗时: {gen_time:.2f}秒")
print(f"保存到: {output_paths[0]}")
print("-" * 50)
# 避免连续生成导致过热
if i < len(prompts) - 1:
time.sleep(10)
9.3 资源管理
长时间使用后,WSL2可能会占用较多资源,需要定期清理:
# 清理APT缓存
sudo apt clean
sudo apt autoremove -y
# 清理pip缓存
pip cache purge
# 清理Docker(如果用了)
docker system prune -a -f
# 查看磁盘使用
df -h
du -sh ~/Z-Image-Turbo-WebUI/models/
# 重启WSL2释放内存
wsl --shutdown
10. 总结
通过WSL2在Windows上部署Z-Image-Turbo,虽然步骤稍微多一些,但一旦配置完成,使用体验和原生Linux环境几乎没有区别。这种方法的好处很明显:
- 不用切换系统:在熟悉的Windows环境下就能用Linux工具
- 性能损失小:WSL2的GPU直通性能很好,几乎没损失
- 维护方便:Windows和Linux环境隔离,互不干扰
- 资源可控:可以灵活分配CPU、内存资源
整个部署过程大概需要1-2小时,主要时间花在下载模型和安装依赖上。一旦部署完成,后续使用就非常方便了。
如果你在部署过程中遇到问题,不要着急,按照本文的步骤一步步检查。大多数问题都能在"常见问题与解决方法"部分找到答案。如果还有问题,可以查看项目的GitHub页面,或者加入相关的技术社区讨论。
现在,你已经成功在Windows上部署了Z-Image-Turbo,可以开始你的AI图像创作之旅了。试试用不同的提示词,探索这个模型的无限可能吧!
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 2
2 0
0- 0



 已为社区贡献198条内容
已为社区贡献198条内容

所有评论(0)