YOLO26边缘设备部署准备:模型导出与ONNX转换前瞻教程
本文介绍了如何在星图GPU平台上自动化部署最新 YOLO26 官方版训练与推理镜像,完成模型导出与ONNX转换。基于该环境可高效实现目标检测模型向边缘设备的迁移,典型应用于智能安防、工业质检等场景中的实时视频分析任务。
YOLO26边缘设备部署准备:模型导出与ONNX转换前瞻教程
随着AI推理向端侧迁移的趋势日益明显,将高性能目标检测模型轻量化并部署到边缘设备已成为落地应用的关键环节。YOLO26作为Ultralytics最新推出的统一架构模型,在保持高精度的同时进一步优化了推理效率,为边缘部署提供了理想选择。本文将基于官方训练与推理镜像环境,系统讲解如何完成从训练后模型到ONNX格式的转换全过程,为后续在Jetson、瑞芯微等嵌入式平台上的部署打下坚实基础。
本教程不只关注“怎么操作”,更强调每一步背后的逻辑和常见坑点,帮助开发者真正掌握模型导出的核心方法论。无论你是刚接触模型部署的新手,还是希望提升工程化能力的进阶用户,都能从中获得实用价值。
1. 镜像环境说明
- 核心框架:
pytorch == 1.10.0 - CUDA版本:
12.1 - Python版本:
3.9.5 - 主要依赖:
torchvision==0.11.0,torchaudio==0.10.0,cudatoolkit=11.3,numpy,opencv-python,pandas,matplotlib,tqdm,seaborn等。
该镜像已预装YOLO26所需全部依赖,并内置了完整的Ultralytics代码库(v8.4.2),省去了繁琐的环境配置过程。更重要的是,它已经包含了多个预训练权重文件,可直接用于推理或微调,极大提升了开发效率。
2. 快速上手
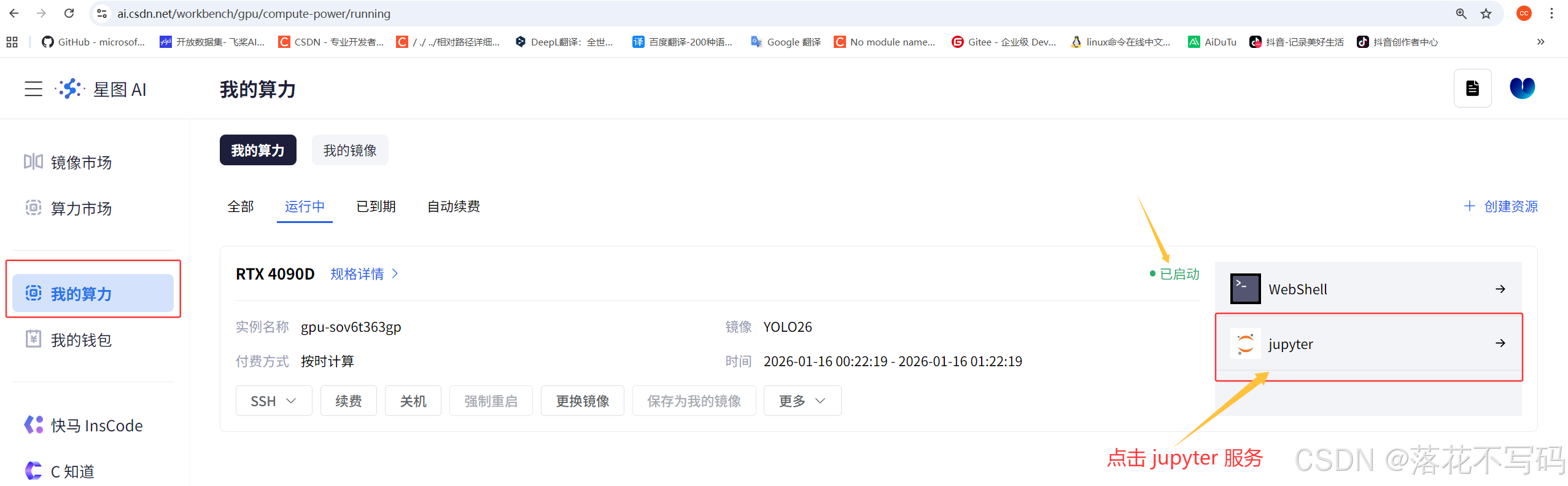 启动完是这样的
启动完是这样的 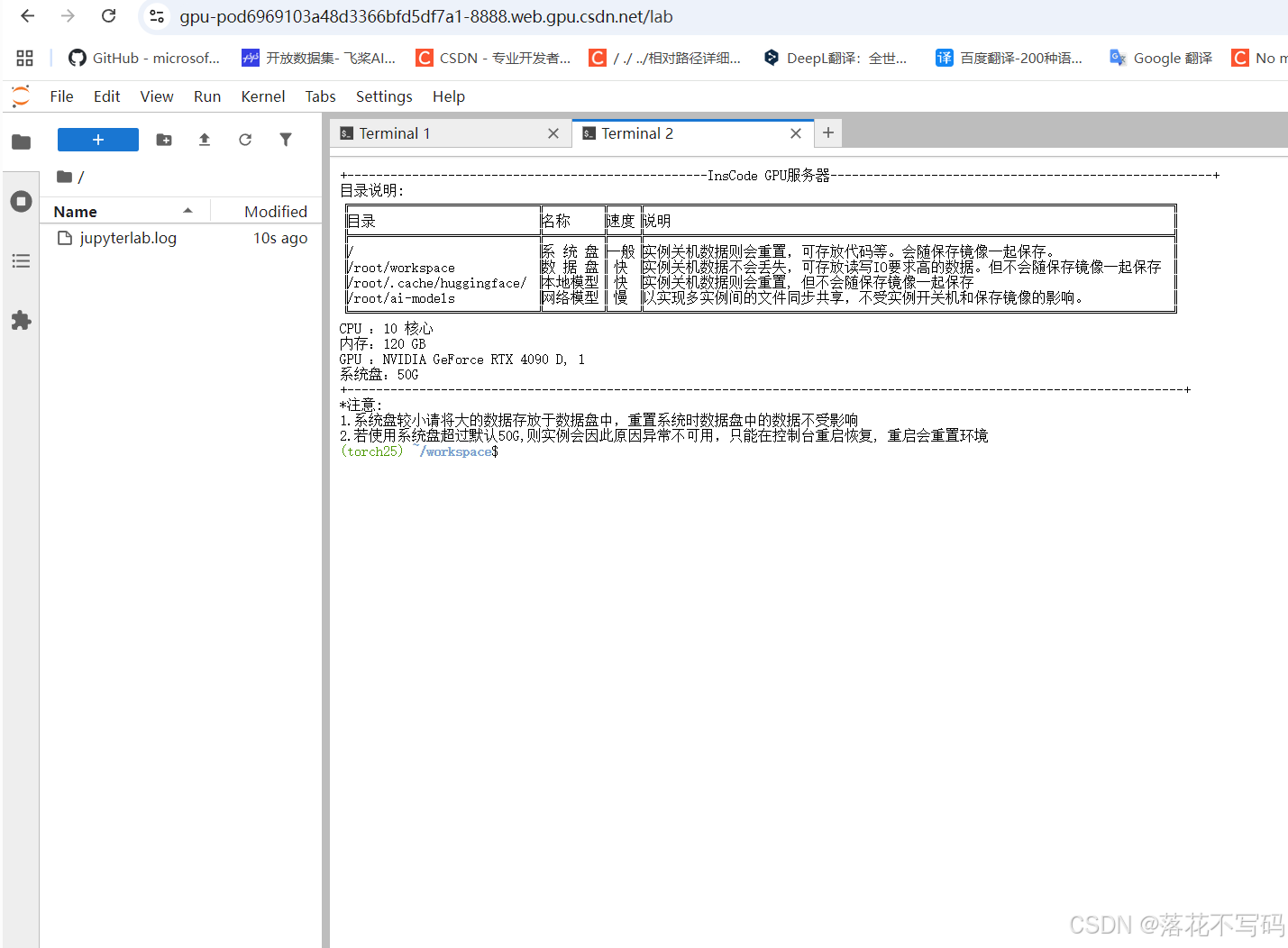
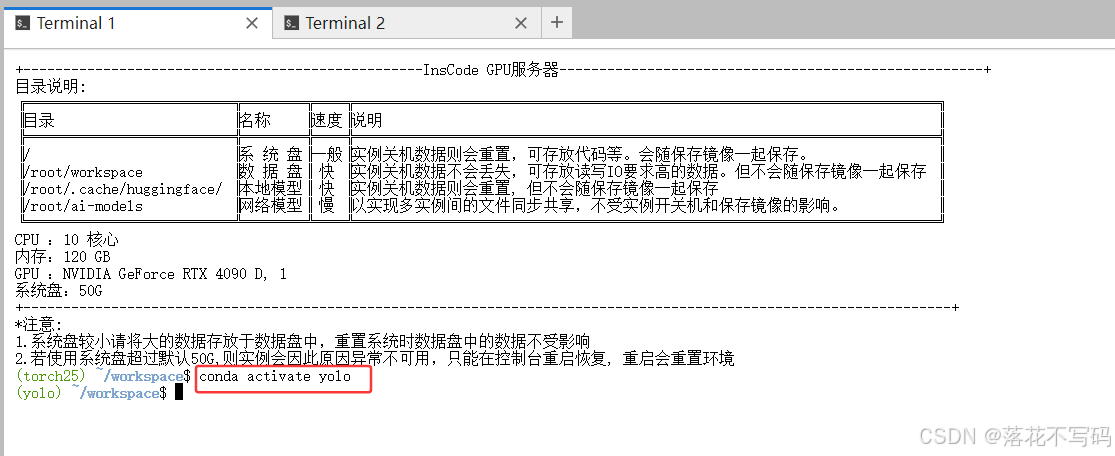
2.1 激活环境与切换工作目录
在使用前,请先激活Conda环境:
conda activate yolo
由于默认代码位于系统盘,建议复制到数据盘以便修改:
cp -r /root/ultralytics-8.4.2 /root/workspace/
cd /root/workspace/ultralytics-8.4.2
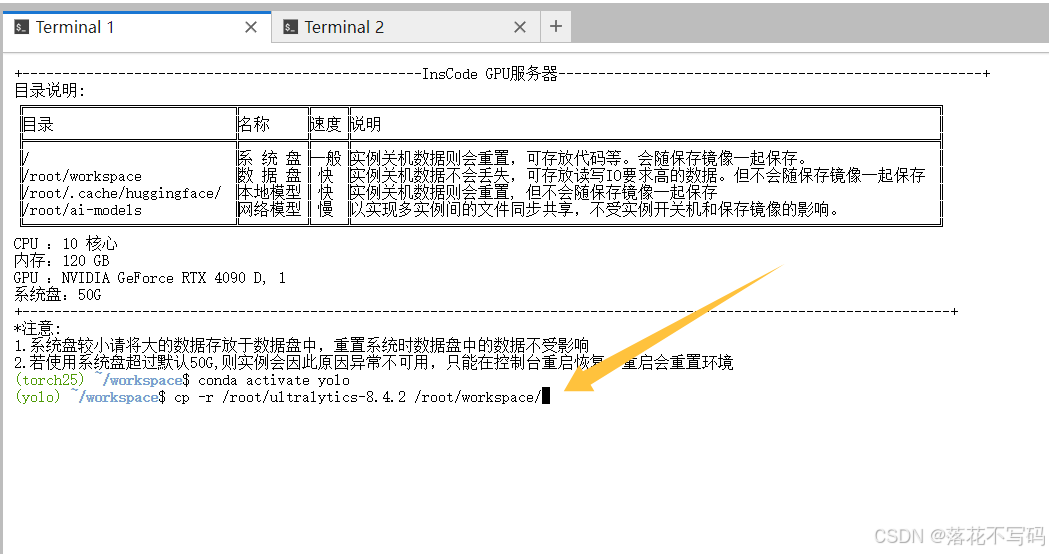

这样做的好处是避免误操作影响原始文件,同时便于后续打包和迁移。
3. 模型导出:从PyTorch到ONNX的关键一步
要让YOLO26跑在边缘设备上,必须将其从PyTorch格式转换为通用中间表示——ONNX(Open Neural Network Exchange)。这是实现跨平台部署的第一步,也是最关键的一步。
3.1 为什么选择ONNX?
ONNX是一种开放的模型交换格式,支持包括TensorRT、OpenVINO、NCNN、ONNX Runtime在内的多种推理引擎。通过一次导出,你可以将同一个模型部署到不同硬件平台上,大大增强了灵活性。
举个例子:你在GPU服务器上训练好的模型,可以通过ONNX转成TensorRT引擎部署到Jetson Nano;也可以转成MNN格式运行在安卓手机上。这种“一次训练,多端部署”的能力正是ONNX的核心价值。
3.2 准备导出脚本
我们创建一个名为 export_onnx.py 的新文件,专门用于模型导出:
# -*- coding: utf-8 -*-
"""
@File :export_onnx.py
"""
from ultralytics import YOLO
if __name__ == '__main__':
# 加载训练好的模型
model = YOLO('runs/train/exp/weights/best.pt') # 替换为你自己的best.pt路径
# 导出为ONNX格式
model.export(
format='onnx',
dynamic=True, # 启用动态输入尺寸
simplify=True, # 简化计算图(推荐开启)
opset=12, # ONNX算子集版本
imgsz=640, # 输入图像大小
device='cuda' # 使用GPU加速导出
)
参数详解:
format='onnx':指定输出格式。dynamic=True:允许输入图片尺寸动态变化,适合实际场景中不同分辨率的输入。simplify=True:调用onnx-simplifier工具简化网络结构,减少冗余节点,提升推理速度。opset=12:推荐使用较新的算子集以兼容更多功能。imgsz=640:定义输入张量的尺寸,需与训练时一致。device='cuda':利用GPU加速导出过程,尤其对大模型更有效。
执行命令开始导出:
python export_onnx.py
成功后你会看到类似以下输出:
Export success
- onnx: ./runs/train/exp/weights/best.onnx
- metadata: {'stride': 32, 'batch_size': 1, 'imgsz': [640, 640], ...}
这意味着你的模型已经成功转换为ONNX格式。
4. 验证ONNX模型有效性
导出只是第一步,我们必须验证生成的ONNX模型是否正确无误。
4.1 使用ONNX Runtime进行推理测试
安装ONNX Runtime(如果未预装):
pip install onnxruntime-gpu
编写测试脚本 test_onnx.py:
import cv2
import numpy as np
import onnxruntime as ort
def preprocess(image_path, input_size=640):
image = cv2.imread(image_path)
h, w = image.shape[:2]
ratio = input_size / max(h, w)
new_h, new_w = int(h * ratio), int(w * ratio)
resized = cv2.resize(image, (new_w, new_h))
padded = np.full((input_size, input_size, 3), 114, dtype=np.uint8)
padded[:new_h, :new_w] = resized
blob = padded.transpose(2, 0, 1)[None] # HWC -> CHW and add batch dim
blob = blob.astype(np.float32) / 255.0
return blob, (ratio, new_w, new_h)
def main():
# 加载ONNX模型
session = ort.InferenceSession('best.onnx', providers=['CUDAExecutionProvider'])
# 预处理输入
input_data, info = preprocess('./ultralytics/assets/zidane.jpg', 640)
# 推理
outputs = session.run(None, {session.get_inputs()[0].name: input_data})
print("ONNX模型推理成功!输出形状:", [o.shape for o in outputs])
if __name__ == '__main__':
main()
运行该脚本:
python test_onnx.py
若输出类似:
ONNX模型推理成功!输出形状: [(1, 8400, 56)]
说明模型结构完整,可以正常前向传播。
注意:输出维度
(1, 8400, 56)中,8400是Anchor数量,56包含4个坐标+1个置信度+51个类别概率(假设是COCO数据集)。具体含义取决于你训练时的配置。
5. 常见问题与解决方案
在模型导出过程中,经常会遇到一些典型问题。以下是我们在实践中总结的高频故障及应对策略。
5.1 动态轴设置失败导致部署受限
问题现象:导出后的ONNX模型只能接受固定尺寸输入,无法适应不同分辨率的摄像头流。
原因分析:未启用 dynamic=True 或导出时未正确声明动态维度。
解决方法:确保导出参数中包含:
model.export(
dynamic={
'images': {0: 'batch', 2: 'height', 3: 'width'}, # 动态batch、高、宽
'output0': {0: 'batch', 1: 'anchors'} # 输出也设为动态
}
)
这样可以让模型灵活处理各种输入尺寸,特别适合移动端和边缘设备的实际应用场景。
5.2 Simplify报错:“No module named ‘onnxsim’”
问题现象:开启 simplify=True 后提示缺少 onnxsim 模块。
解决方案:手动安装ONNX Simplifier:
pip install onnxsim
或者跳过简化步骤,后续再单独处理:
python -m onnxsim best.onnx best-sim.onnx
简化后的模型通常体积更小、推理更快,建议尽可能使用。
5.3 TensorRT转换失败:Unsupported ONNX operator
问题现象:将ONNX转为TensorRT时报错,提示某些OP不被支持。
根本原因:YOLO26中可能使用了较新的PyTorch操作(如SiLU、Focus层等),而旧版TensorRT未能完全支持。
应对方案:
- 升级TensorRT至8.6以上版本;
- 在导出时尽量避免自定义模块;
- 对于Focus这类特殊结构,考虑在模型设计阶段就替换为标准卷积。
6. 边缘部署前的最后检查清单
在将ONNX模型交给嵌入式团队之前,建议完成以下五项检查,确保无缝衔接。
6.1 检查清单
| 检查项 | 是否完成 | 说明 |
|---|---|---|
| 模型能正常加载并推理 | 是 | 使用ONNX Runtime验证 |
| 支持动态输入尺寸 | 是 | 查看输入tensor是否有dynamic_axes定义 |
| 输出结构清晰可解析 | 是 | 记录输出shape和含义 |
| 模型已简化 | 是 | 文件体积应比原始小10%-30% |
| 提供示例输入输出 | 是 | 附带一张测试图和预期结果 |
6.2 给嵌入式开发者的交接建议
- 提供
.onnx文件 + 简化后的版本; - 明确告知输入预处理方式(归一化、padding规则);
- 标注输出张量的结构(如bbox偏移、置信度、分类头位置);
- 若使用非标准激活函数(如SiLU),提醒对方注意实现一致性。
良好的协作始于清晰的接口文档,哪怕只是一个简单的README也能大幅提升集成效率。
7. 总结
本文围绕YOLO26模型的边缘部署准备,详细演示了如何从官方训练镜像出发,完成模型导出、ONNX转换、有效性验证的全流程。我们不仅给出了可执行的代码示例,还深入剖析了每个关键步骤背后的原理和潜在陷阱。
通过本次实践,你应该已经掌握了:
- 如何正确导出YOLO26为ONNX格式;
- 如何验证导出模型的功能完整性;
- 如何规避常见的导出错误;
- 如何为后续的边缘部署做好充分准备。
下一步,你可以尝试将生成的ONNX模型接入TensorRT或OpenVINO,在真实硬件上测试其性能表现。记住,模型部署不是一蹴而就的过程,而是持续优化的旅程。每一次成功的转换,都是通向产品落地的重要一步。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 26
26 0
0- 0



 已为社区贡献155条内容
已为社区贡献155条内容

所有评论(0)