机器学习中的K-均值聚类算法
摘要:K-均值聚类是一种基于距离的平坦聚类算法,通过迭代计算质心将数据点分配到K个簇中。其步骤包括:初始化K个质心,计算数据点到质心的距离,重新分配数据点并更新质心,直至收敛。该算法高效且适用于大数据,但对初始质心敏感且需预先确定K值。应用场景包括图像分割、客户细分、异常检测等。Python实现可通过scikit-learn库完成,但需注意数据标准化和多次初始化以避免局部最优。算法优势在于简单快速,但存在对初始值和数据尺度敏感的局限性。
目录
K-均值聚类算法
K均值聚类算法计算重心并迭代,直到找到最优重心。它假设簇的数量已经已知。它也被称为平坦聚类算法。通过算法从数据中识别出的簇数以K-均值中的“K”表示。
在该算法中,数据点被分配到一个簇中,使得数据点与质心之间的平方距离之和最小。需要理解的是,簇内变异越少,同一簇内的数据点会越相似。
K-均值算法的工作原理
我们可以通过以下步骤理解K均值聚类算法的工作原理 −
- 步骤1 − 首先,我们需要指定该算法需要生成的簇数K。
- 步骤2 − 接下来,随机选取K个数据点,并将每个数据点分配到一个聚类。简单来说,就是根据数据点的数量对数据进行分类。
- 步骤3 − 现在计算簇质心。
- 步骤4 − 接下来,继续迭代,直到找到最优重心,即将数据点分配到不再变化的簇−
4.1 − 首先,计算数据点与重心之间的平方距离之和。
4.2 − 现在,我们必须将每个数据点分配给比其他星团(重心)更近的星团。
4.3 − 最后,通过取该簇所有数据点的平均值来计算该簇的重心。
K-均值采用期望最大化方法来求解该问题。期望步用于将数据点分配到最近的簇,最大化步用于计算每个聚类的重心。
在使用 K-均值算法时,我们需要注意以下事项 −
- 在使用包括K均值在内的聚类算法时,建议对数据进行标准化,因为此类算法使用基于距离的测量来确定数据点之间的相似性。
- 由于K-均值的迭代性质和质心的随机初始化,K-均值可能停留在局部最优解,而可能不会收敛到全局最优。这就是为什么建议使用不同的重心初始化方式。
K-均值算法是一个简单高效且可处理大数据集的算法。然而,它存在一些局限性,如对初始质心的敏感性、趋向局部最优收敛以及假设所有簇方差相等。
K-均值聚类的目标
聚类分析的主要目标为 −
- 从我们所处理的数据中获得有意义的直觉。
- 先进行聚类预测不同子群体不同模型的构建位置。
使用Python实现K-均值算法
Python 有多个库,提供各种机器学习算法的实现,包括 K-平均聚类。让我们看看如何用 scikit-learn 库在 Python 中实现 K-Means 算法。
示例1
这是一个简单的例子,帮助理解k均值的工作原理。在这个例子中,我们生成300个随机数据点,包含两个特征。并应用K均值算法生成聚类。
步骤1 − 导入所需库
要在 Python 中实现 K-Means 算法,首先需要导入所需的库。我们将分别使用numpy库和matplotlib库进行数据处理和可视化,scikit-learn库用于K-Means算法。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans步骤2 − 生成数据
为了测试K均值算法,我们需要生成一些样本数据。在这个例子中,我们将生成300个随机数据点,包含两个特征。我们也会对数据进行可视化。
X = np.random.rand(300,2)
plt.figure(figsize=(7.5, 3.5))
plt.scatter(X[:, 0], X[:, 1], s=20, cmap='summer');
plt.show()输出
步骤3 − 初始化k-均值
接下来,我们需要通过指定簇数(K)和最大迭代次数来初始化K-均值算法。
kmeans = KMeans(n_clusters=3, max_iter=100)步骤4 − 训练模型
初始化K均值算法后,我们可以通过拟合数据来训练模型。
kmeans.fit(X)步骤5 − 可视化这些星团
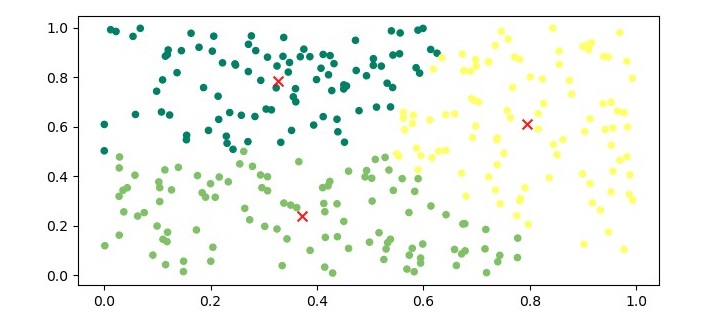
为了可视化聚类,我们可以绘制数据点并根据分配的聚类给它们上色。
plt.figure(figsize=(7.5, 3.5))
plt.scatter(X[:,0], X[:,1], c=kmeans.labels_, s=20, cmap='summer')
plt.scatter(kmeans.cluster_centers_[:,0], kmeans.cluster_centers_[:,1],
marker='x', c='r', s=50, alpha=0.9)
plt.show()输出
上述代码的输出将是一张图,数据点根据分配的聚类为颜色,重心则用红色的“x”符号标记。
示例2
在这个例子中,我们首先生成包含4个不同斑点的二维数据集,然后应用k-均值算法来查看结果。
首先,我们将从导入必要的包开始——
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans以下代码将生成包含四个斑点−的二维空间
from sklearn.datasets import make_blobs
X, y_true = make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0)接下来,以下代码将帮助我们可视化数据集——
plt.scatter(X[:, 0], X[:, 1], s=20);
plt.show()
接下来,创建一个KMeans对象并提供簇数,训练模型并进行预测,如下 −
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)现在,借助后续代码,我们可以绘制并可视化由k-均值Python估计器选定的簇中心 −
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=20, cmap='summer')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='blue', s=100, alpha=0.9);
plt.show()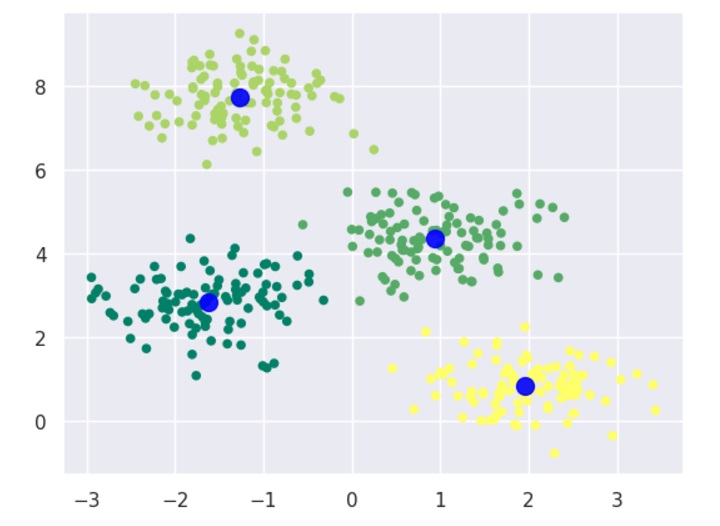
示例3
让我们换个例子,在简单数字数据集上应用K均值聚类。K-means 会尝试识别相似数字,而不使用原始标签信息。
首先,我们将从导入必要的包开始——
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
from sklearn.cluster import KMeans接着,从sklearn加载数字数据集,并将其做成一个对象。我们还可以通过以下方式确定该数据集中的行和列数 −
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shape输出
(1797, 64)
上述输出显示该数据集包含1797个样本,包含64个特征。
我们可以像上文示例1 −中那样进行聚类
kmeans = KMeans(n_clusters=10, random_state=0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shape输出
(10, 64)
上述输出显示K均值创建了10个簇,包含64个特征。
fig, ax = plt.subplots(2, 5, figsize=(8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks=[], yticks=[])
axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary)输出
输出是下图,显示通过k-平均数学习的簇中心。
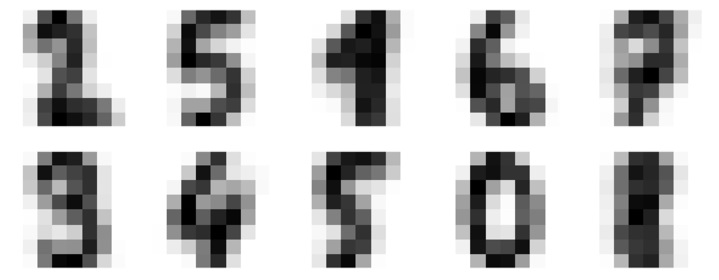
以下代码行将将学习到的簇标签与其中真实的标签匹配 −
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]接下来,我们可以检查准确性如下 −
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)输出
0.7935447968836951
上述输出显示准确率约为80%。
K-均值聚类算法的优势
以下是K-均值聚类算法的一些优势——
- 它非常容易理解和实施。
- 如果变量数量众多,则K均值会比层次聚类更快。
- 在重心计算时,实例可以改变簇。
- 相比层级聚类,K-均值形成的聚类更紧密。
K-均值聚类算法的缺点
以下是K均值聚类算法的一些缺点 −
- 预测簇的数量,即k的值,有点困难。
- 输出受到初始输入(如簇数(k)等影响。
- 数据的顺序会对最终输出产生强烈影响。
- 它对重新标配非常敏感。如果我们通过归一化或标准化来重新调整数据,那么输出将完全改变。最终输出。
- 如果聚类具有复杂的几何形状,它在进行聚类工作时并不理想。
K-均值聚类的应用
K-均值聚类是一种多功能算法,在多个领域有多种应用。这里我们重点介绍了一些重要的应用——
图像分割
K-均值聚类可用于根据像素的颜色或纹理将图像分割成不同的区域。该技术广泛应用于计算机视觉领域,如物体识别、图像检索和医学影像。
客户细分
K-平均聚类可用于根据客户的购买行为或人口统计特征将客户划分为不同群体。该技术广泛应用于营销应用,如客户留存、忠诚度计划和定向广告。
异常检测
K均值聚类可以通过识别不属于任何聚类的数据点来检测数据集中的异常。该技术广泛应用于欺诈检测、网络入侵检测和预测性维护。
基因组数据分析
K-均值聚类可用于分析基因表达数据,识别共调或共表达的不同基因组。该技术广泛应用于生物信息学领域,如药物发现、疾病诊断和个性化医疗。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)