ClickHouse高级部分
部署服务器:
128G, 100G内存,32线程CPU
表级别优化
数据类型的优化
1. 时间字段类型
ClickHouse中建表时能用数值型或日期时间型表示的字段就不要用字符串,虽然ClickHouse底层将 DateTime 存储为时间戳 Long 类型,但不建议存储 Long 类型,因为 DateTime 不需要经过函数转换处理,执行效率高、可读性好。
2.空值存储类型
官方已经指出 Nullable 类型几乎总是会拖累性能,因为存储 Nullable 列时需要创建一个额外的文件来存储 NULL 的标记,并且 Nullable 列无法被索引。因此除非极特殊情况,应直接使用字段默认值表示空,或者自行指定一个在业务中无意义的值(例如用-1 表示没有值),具体详情见官方说明
分区和索引的优化
分区粒度根据业务特点决定,不宜过粗或过细。一般选择按天分区。
建表时必须指定索引列,ClickHouse 中的索引列即排序列,通过 order by 指定,一般在查询条件中经常被用来充当筛选条件的属性被纳入进来;可以是单一维度,也可以是组合维度的索引;通常需要满足高级列在前、查询频率大的在前原则。
组合索引维度: 就是order by后面跟了多个列。即这些列就是组合索引。根据查询频率,频率高的列放在order by的前面。
写入和删除优化
- 尽量不要执行单条或小批量删除和插入操作,这样会产生小分区文件,给后台
Merge 任务带来巨大压力。 - 不要一次写入太多分区,或数据写入太快,数据写入太快会导致 Merge 速度跟不上而报错,一般建议每秒钟发起 2-3 次写入操作,每次操作写入 2w~5w 条数据(依服务器性能而定)
- 写入过快报错,报错信息:
1. Code: 252, e.displayText() = DB::Exception: Too many parts(304).
Merges are processing significantly slower than inserts
2. Code: 241, e.displayText() = DB::Exception: Memory limit (for query)
exceeded:would use 9.37 GiB (attempt to allocate chunk of 301989888
bytes), maximum: 9.31 GiB
处理方式:
“ Too many parts 处理 ” :使用 WAL 预写日志,提高写入性能。
in_memory_parts_enable_wal 默认为 true
在服务器内存充裕的情况下增加内存配额,一般通过 max_memory_usage 来实现。
在服务器内存不充裕的情况下,建议将超出部分内容分配到系统硬盘上,但会降低执行速度,一般通过max_bytes_before_external_group_bymax_bytes_before_external_sort 参数实现。
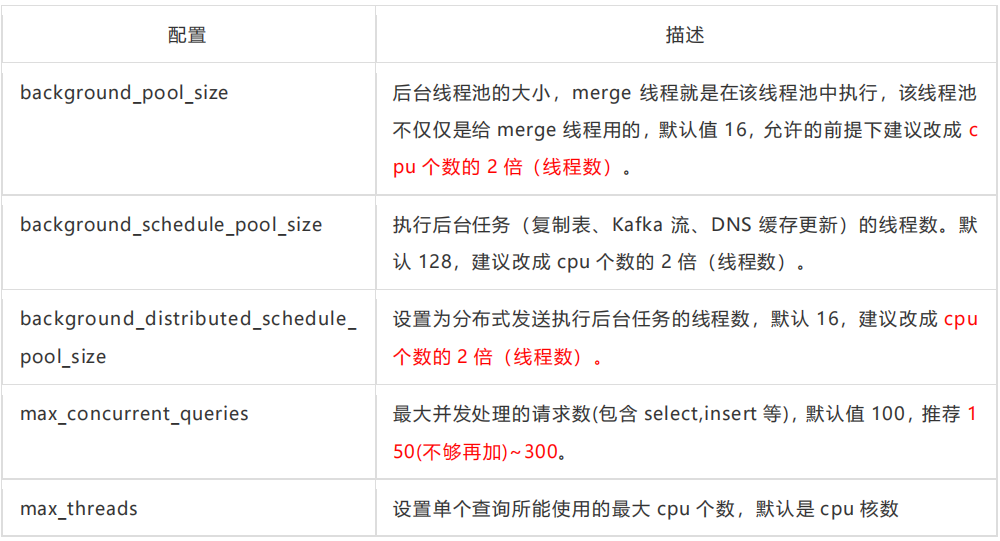
常见配置
配置项主要在 config.xml 或 users.xml 中, 基本上都在 users.xml 里。
config.xml 的配置项
users.xml 的配置项
cpu资源配置
内存资源配置

存储优化
ClickHouse 不支持设置多数据目录,为了提升数据 io 性能,可以挂载虚拟券组,一个券组绑定多块物理磁盘提升读写性能,多数据查询场景 SSD(固态) 会比普通机械硬盘快 2-3 倍。
虚拟券组: 多块硬盘挂在一个虚拟目录下。
语法优化
count优化
在调用 count 函数时,如果使用的是 count() 或者 count(*),且没有 where 条件,则
会直接使用 system.tables 的 total_rows,例如:
EXPLAIN SELECT count()FROM datasets.hits_v1;
Union
Expression (Projection)
Expression (Before ORDER BY and SELECT)
MergingAggregated
ReadNothing (Optimized trivial count)
注意 Optimized trivial count ,这是对 count 的优化。
如果 count 具体的列字段,则不会使用此项优化:
EXPLAIN SELECT count(CounterID) FROM datasets.hits_v1;
Union
Expression (Projection)
Expression (Before ORDER BY and SELECT)
Aggregating
Expression (Before GROUP BY)
ReadFromStorage (Read from MergeTree)
谓词下推
关于谓词下推,可参考谓词下推
查询优化
Prewhere 替代 where
Prewhere 和 where 语句的作用相同,用来过滤数据。不同之处在于 prewhere 只支持
*MergeTree 族系列引擎的表,首先会读取指定的列数据,来判断数据过滤,等待数据过滤之后再读取 select 声明的列字段来补全其余属性。
当查询列明显多于筛选列时使用 Prewhere 可十倍提升查询性能,Prewhere 会自动优化执行过滤阶段的数据读取方式,降低 io 操作。
默认情况下, where 条件会自动优化成 prewhere。
uniqCombined 替代 distinct
性能可提升 10 倍以上,uniqCombined 底层采用类似 HyperLogLog 算法实现,能接收 2%左右的数据误差,可直接使用这种去重方式提升查询性能。Count(distinct )会使用 uniqExact精确去重。
多表联查
多表 join 时要满足小表在右的原则,右表关联时被加载到内存中与左表进行比较,ClickHouse 中无论是 Left join 、Right join 还是 Inner join 永远都是拿着右表中的每一条记录到左表中查找该记录是否存在,所以右表必须是小表。
数据一致性
对数据一致性支持最好的引擎是 Mergetree,也只是保证最终一致性。
我们在使用 ReplacingMergeTree、SummingMergeTree 这类表引擎的时候,会出现短暂数据不一致的情况。
具体详情可见ClickHouse 如何实现数据一致性
物化视图
ClickHouse 的物化视图是一种查询结果的持久化,它确实是给我们带来了查询效率的提升。用户查起来跟表没有区别,它就是一张表,它也像是一张时刻在预计算的表,创建的过程它是用了一个特殊引擎,加上后来 as select,就是 create 一个 table as select 的写法。
“查询结果集”的范围很宽泛,可以是基础表中部分数据的一份简单拷贝,也可以是多表 join 之后产生的结果或其子集,或者原始数据的聚合指标等等。所以,物化视图不会随着基础表的变化而变化,所以它也称为快照(snapshot)
物化视图与普通视图的区别
普通视图不保存数据,保存的仅仅是查询语句,查询的时候还是从原表读取数据,可以将普通视图理解为是个子查询。物化视图则是把查询的结果根据相应的引擎存入到了磁盘或内存中,对数据重新进行了组织,你可以理解物化视图是完全的一张新表。
优点:
查询速度快,要是把物化视图这些规则全部写好,它比原数据查询快了很多,总的行数少了,因为都预计算好了。
缺点:
它的本质是一个流式数据的使用场景,是累加式的技术,所以要用历史数据做去重、去核这样的分析,在物化视图里面是不太好用的。在某些场景的使用也是有限的。而且如果一张表加了好多物化视图,在写这张表的时候,就会消耗很多机器的资源,比如数据带宽占满、存储一下子增加了很多。
注意点:
- 物化视图创建好之后,若源表被写入新数据则物化视图也会同步更新。
- POPULATE 关键字决定了物化视图的更新策略:若有 POPULATE 则在创建视图的过程会将源表已经存在的数据一并导入,类似于create table … as;若无 POPULATE 则物化视图在创建之后没有数据,只会在创建只有同步之后写入源表的数据;clickhouse 官方并不推荐使用 POPULATE,因为在创建物化视图的过程中同时写入的数据不能被插入物化视图。
- 物化视图不支持同步删除,若源表的数据不存在(删除了)则物化视图的数据仍然保留
- 物化视图是一种特殊的数据表,可以用 show tables 查看。
MaterializeMySQL 引擎
MySQL 的用户群体很大,为了能够增强数据的实时性,很多解决方案会利用 binlog 将数据写入到 ClickHouse。为了能够监听 binlog 事件,我们需要用到类似 canal 这样的第三方中间件,这无疑增加了系统的复杂度。
ClickHouse 20.8.2.3 版本新增加了 MaterializeMySQL 的 database 引擎,该 database 能映 射 到 MySQL 中 的 某 个 database , 并 自 动 在 ClickHouse 中 创 建 对 应 的ReplacingMergeTree。ClickHouse 服务做为 MySQL 副本,读取 Binlog 并执行 DDL 和 DML 请求,实现了基于 MySQL Binlog 机制的业务数据库实时同步功能。
特点:
- MaterializeMySQL 同时支持全量和增量同步,在 database 创建之初会全量同步MySQL 中的表和数据,之后则会通过 binlog 进行增量同步。
- MaterializeMySQL database 为其所创建的每张 ReplacingMergeTree 自动增加了_sign 和 _version 字段。
其中,_version 用作 ReplacingMergeTree 的 ver 版本参数,每当监听到 insert、update 和 delete 事件时,在 databse 内全局自增。而 _sign 则用于标记是否被删除,取值 1 或者 -1。
使用细则:
- MySQL DDL 查询被转换成相应的 ClickHouse DDL 查询(ALTER, CREATE, DROP, RENAME)。如果 ClickHouse 不能解析某些 DDL 查询,该查询将被忽略。
- MaterializeMySQL 不支持直接插入、删除和更新查询,而是将 DDL 语句进行相应转换:
MySQL INSERT 查询被转换为 INSERT with _sign=1。
MySQL DELETE 查询被转换为 INSERT with _sign=-1。
MySQL UPDATE 查询被转换成 INSERT with _sign=1 和 INSERT with _sign=-1。 - 如果在 SELECT 查询中没有指定_version,则使用 FINAL 修饰符,返回_version 的最大值对应的数据,即最新版本的数据。
如果在 SELECT 查询中没有指定_sign,则默认使用 WHERE _sign=1,即返回未删除状态(_sign=1)的数据。 - ClickHouse 数据库表会自动将 MySQL 主键和索引子句转换为 ORDER BY 元组。ClickHouse 只有一个物理顺序,由 ORDER BY 子句决定。如果需要创建新的物理顺序,请使用物化视图。
MySQL引擎
ClickHouse 的 MySQL 引擎允许用户将数据从 MySQL 迁移到 ClickHouse,并在 ClickHouse 中运行查询。这使得用户能够利用 ClickHouse 的高性能查询能力,同时保持与现有 MySQL 生态系统的兼容性。通过 ClickHouse,用户可以处理大量数据,执行复杂的分析,而不必更改他们已有的 MySQL 应用程序。
ClickHouse 的 MySQL 引擎基本上是通过在 ClickHouse 中创建一个表,该表通过配置与 MySQL 数据库中的表进行连接。这个表从 MySQL 中读取数据并在内部以列式存储格式保存。
数据流的过程如下:
- 用户在 ClickHouse 中创建一个表,指定 MySQL 数据源。
- ClickHouse 定期从 MySQL 中读取数据并将其存入列式存储中。
- 用户通过 ClickHouse 查询语言 (SQL) 执行查询,利用 ClickHouse 的查询优化能力。
与MaterializeMySQL 引擎的区别:
Engine=MySQL可以在ClickHouse中对MySQL数据进行操作。MaterializeMySQL主是用于实时同步MySQL数据,无法对MySQL进行操作。
MySQL数据往ClickHouse迁移方案
方案一:
ClickHouse 的MySQL表引擎可以对存储在远程 MySQL 服务器上的数据执行 SELECT 查询。基于这样能力,利用"CREATE … SELECT FROM"或者" INSERT INTO … SELECT FROM"语句即可完成数据导入。
具体步骤:
步骤1:在ClickHouse中创建MySQL表引擎。
步骤2:建立ClickHouse 表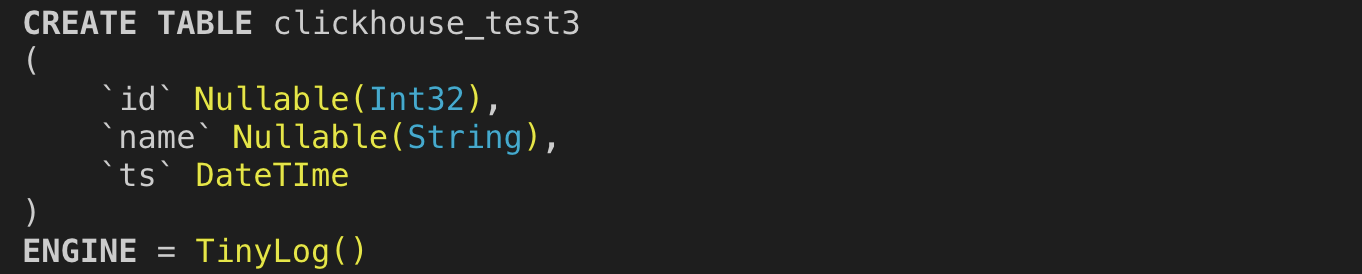
步骤3:将步骤1中的外表中数据,导入到ClickHouse表中
还可以将步骤2/3合并成一个步骤,即采用CREATE TABLE AS SELECT * FROM 方式来达到同样效果。
有人就要问了,既然ClickHouse支持MySQL外表引擎,还有必要将数据导入到ClickHouse中吗? 实际上还是非常有必要的。MySQL外表引擎,本身不存储数据,数据存储在MySQL中。在复制查询中,特别是有JOIN的情况下,访问外表是相当慢的,甚至不可能完成。
该方案有明显缺陷,无法增量导入数据。
方案二:
基于Altinity的工具实现数据导入。Altinity提供了一个工具clickhouse-mysql-data-reader来实现数据导入。该工具可以实现MySQL的存量数据导出,和增量数据的导出。
详情参考文章:ClickHouse 导入数据实战:MySQL篇
更多信息可参考:
阿里云ClickHouse云数据库地址

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)