DeploySharp 0.0.8 震撼升级!支持PP-OCR v4/v5 全系列模型极速推理,开源免费且多平台支持,RTX 3060 上狂飙至 23ms!我的项目我做主,从此加速不求人。
DeploySharp 0.0.8 震撼升级!支持PP-OCR v4/v5 全系列模型极速推理,开源免费且多平台支持,RTX 3060 上狂飙至 23ms!我的项目我做主,从此加速不求人。
嘿,C# 开发者朋友们注意了!DeploySharp 迎来了一次重大升级——0.0.8 版本正式上线啦!这次更新带来了大家期待已久的 PP-OCR v4 和 v5 全系列模型支持,从文本检测、方向分类到文字识别,一个不少。更炸裂的是,OpenVINO、TensorRT、ONNX Runtime 这三大主流推理引擎全部打通,在 RTX 3060 上推理速度最快能飙到 23ms,比闪电还快!
📖 目录
- 一、DeploySharp 是个啥?
- 二、PP-OCR v4/v5 模型支持
- 三、推理引擎全面支持
- 四、性能表现:说话要靠数据
- 五、案例演示:眼见为实
- 六、快速开始:三步上手
- 七、软件获取
- 八、技术支持
一、DeploySharp 是个啥?
简单来说,DeploySharp 就是专为 C# 开发者打造的一把"瑞士军刀"——一个跨平台的模型部署框架。不管你是想加载模型、管理配置,还是执行推理,它都能一站式搞定。
这个项目由「椒颜皮皮虾」开发并开源,遵循 Apache 2.0 许可协议。自从在 GitHub 上架以来,已经收获了广泛关注和星标。
架构设计有点东西
DeploySharp 的设计思路很清晰,就像搭积木一样:
- 统一入口:
DeploySharp作为总指挥,集成模型加载、推理执行等核心功能 - 模块化分层:通过
DeploySharp.Engine(推理引擎)、DeploySharp.Data(数据处理)、DeploySharp.Model(模型定义)等子命名空间,各司其职 - 泛型设计:关键类都用上了泛型,图像处理、分类、检测等各种任务都能友好接入
想看源码?戳这里
https://github.com/guojin-yan/DeploySharp.git
1. 推理引擎全家桶
DeploySharp 一口气支持了三种主流推理引擎,任君选择:
| 推理引擎 | 状态 | 支持设备 | 性能特点 |
|---|---|---|---|
| OpenVINO | 已就绪 | CPU、GPU0(集显)、GPU1(独显)、NPU | Intel 硬件优化 |
| ONNX Runtime | 已就绪 | CPU、GPU(CUDA/DML) | 跨平台兼容性好 |
| TensorRT | 已就绪 | GPU(TensorRT) | NVIDIA GPU 极致性能 |
简单说:
- 手里是 Intel CPU 的?选 OpenVINO,优化到位
- 想跨平台尝鲜的?ONNX Runtime 绝对不坑你
- 有 NVIDIA 显卡且追求极致速度的?TensorRT 就是为你准备的
2. 图像处理两种选择
框架给你留了后路,两种图像处理库任你选:
| 图像处理库 | 特点 | 适用场景 |
|---|---|---|
| ImageSharp | 纯 C# 实现,跨平台兼容性好,无原生依赖 | 跨平台应用、Web 应用 |
| OpenCvSharp | OpenCV 的 C# 封装,功能强大,性能优异 | 桌面应用、高性能场景 |
怕麻烦选 ImageSharp,追求性能选 OpenCvSharp,就是这么任性。
3. 跨平台运行时全覆盖
不管你用的是哪个版本的 .NET,DeploySharp 都能接得住:
- .NET Framework 4.8 / 4.8.1(老用户别担心)
- .NET Core 3.1
- .NET 5.0 ~ .NET 10.0(新用户随便上)
4. NuGet 包生态
4.1 核心包
| 包名 | 描述 | NuGet 链接 |
|---|---|---|
| JYPPX.DeploySharp | DeploySharp API 核心库 | https://www.nuget.org/packages/JYPPX.DeploySharp/ |
核心包里装的是啥?
- 推理引擎的统一抽象接口
- 数据结构定义
- 模型配置基类
- 性能分析工具
- 日志系统
- 可视化基础功能
4.2 图像处理扩展包
| 包名 | 描述 | NuGet 链接 |
|---|---|---|
| JYPPX.DeploySharp.ImageSharp | 使用 ImageSharp 的图像处理扩展 | https://www.nuget.org/packages/JYPPX.DeploySharp.ImageSharp/ |
| JYPPX.DeploySharp.OpenCvSharp | 使用 OpenCvSharp 的图像处理扩展 | https://www.nuget.org/packages/JYPPX.DeploySharp.OpenCvSharp/ |
扩展包给你带来:
- 图像加载和保存
- 图像预处理实现
- 可视化功能实现
- 批量处理支持
5. 支持的模型清单
截至目前,DeploySharp 已经完成了以下模型的封装,而且还在不断扩充中:
| Model Name | Model Type | OpenVINO | ONNX Runtime | TensorRT |
|---|---|---|---|---|
| YOLOv5 | Detection | ✅ | ✅ | ✅ |
| YOLOv5 | Segmentation | ✅ | ✅ | ✅ |
| YOLOv6 | Detection | ✅ | ✅ | ✅ |
| YOLOv7 | Detection | ✅ | ✅ | ✅ |
| YOLOv8 | Detection | ✅ | ✅ | ✅ |
| YOLOv8 | Segmentation | ✅ | ✅ | ✅ |
| YOLOv8 | Pose | ✅ | ✅ | ✅ |
| YOLOv8 | Oriented Bounding Boxes | ✅ | ✅ | ✅ |
| YOLOv9 | Detection | ✅ | ✅ | ✅ |
| YOLOv9 | Segmentation | ✅ | ✅ | ✅ |
| YOLOv10 | Detection | ✅ | ✅ | ✅ |
| YOLOv11 | Detection | ✅ | ✅ | ✅ |
| YOLO11 | Segmentation | ✅ | ✅ | ✅ |
| YOLO11 | Pose | ✅ | ✅ | ✅ |
| YOLO11 | Oriented Bounding Boxes | ✅ | ✅ | ✅ |
| YOLO12 | Detection | ✅ | ✅ | ✅ |
| Anomalib | Segmentation | ✅ | ✅ | ✅ |
| PP-YOLOE | Detection | ✅ | ✅ | ✅ |
| DEIMv2 | Detection | ✅ | ✅ | ✅ |
| RFDETR | Detection | ✅ | ✅ | ✅ |
| RFDETR | Segmentation | ✅ | ✅ | ✅ |
| RTDETR | Detection | ✅ | ✅ | ✅ |
| YOLO26 | Detection | ✅ | ✅ | ✅ |
| YOLO26 | Segmentation | ✅ | ✅ | ✅ |
| YOLO26 | Pose | ✅ | ✅ | ✅ |
| YOLO26 | Oriented Bounding Boxes | ✅ | ✅ | ✅ |
| PP-OCR v5 | Detection | ✅ | ✅ | ✅ |
| PP-OCR v5 | Classification | ✅ | ✅ | ✅ |
| PP-OCR v5 | Recognize | ✅ | ✅ | ✅ |
| PP-OCR v5 | Det+Cls+Rec | ✅ | ✅ | ✅ |
| PP-OCR v4 | Detection | ✅ | ✅ | ✅ |
| PP-OCR v4 | Classification | ✅ | ✅ | ✅ |
| PP-OCR v4 | Recognize | ✅ | ✅ | ✅ |
| PP-OCR v4 | Det+Cls+Rec | ✅ | ✅ | ✅ |
二、PP-OCR v4/v5 模型支持
OCR 是什么鬼?
OCR(光学字符识别)这东西,说白了就是把图片里的文字"抠"出来,变成可编辑的文本。想想看,以前扫个文档还得手打,现在一键搞定,这不就是黑科技嘛!
数字化办公、文档管理、票据识别……这些场景全得靠它。百度飞桨开源的 PP-OCR 作为 OCR 界的"扛把子",以识别精度高、功能丰富著称,深受开发者喜爱。
同一套代码,多种引擎自由切
得益于 DeploySharp 底层接口统一的优势,开发者现在可以用同一段代码在 OpenVINO、TensorRT、ONNX Runtime 等多种推理引擎间自由切换。就像换衣服一样方便,代码不用改,引擎随便换!
最近,我们完成了 PP-OCR v4/v5 的支持更新,给 .NET 开发者送上了一份完整的 OCR 解决方案大礼。功能已经集成到 DeploySharp 开源项目中,代码已上传仓库,NuGet 包也已发布,坐等大家来体验!
2.1 模型架构:三段式流水线
PP-OCR 采用经典的"检测-分类-识别"三阶段流水线架构,就像一个精密的工厂车间:
输入图片
│
▼
┌─────────────┐
│ 文本检测 │ → 第一步:找出图片里哪里有文字,标出位置
│ (Detection) │
└─────────────┘
│
▼
┌─────────────┐
│ 文本方向分类 │ → 第二步:判断文字有没有颠倒(比如倒着拍的照片)
│ (Classifier)│
└─────────────┘
│
▼
┌─────────────┐
│ 文本识别 │ → 第三步:把检测到的文字框里的内容认出来
│ (Recognition)│
└─────────────┘
│
▼
输出识别结果 → 搞定!
2.2 v4 和 v5 有啥区别?
| 特性 | PP-OCR v4 | PP-OCR v5 |
|---|---|---|
| Cls 输入尺寸 | 48x192 | 80x160 |
| 精度 | 高 | 更高 |
| 推理速度 | 较快 | 相当 |
| 模型体积 | 较小 | 相当 |
一句话总结:v5 精度更高,但速度和体积与 v4 基本持平。如果你的应用场景对精度要求更高,果断上 v5!
2.3 配置很简单
DeploySharp 为不同版本的 PP-OCR 提供了预设配置,不用费脑细胞:
PP-OCR v4 一键配置:
PaddleOCRConfig config = PaddleOCRConfig.GetPPOCRv4Config(
detModelPath: @"E:\Model\ppocrv4\det\det.onnx",
clsModelPath: @"E:\Model\ppocrv4\cls\cls.onnx",
recModelPath: @"E:\Model\ppocrv4\rec\rec.onnx",
recDictPath: @"E:\Model\ppocrv4\ppocr_keys_v1.txt"
);
// v4 特点:Cls 输入尺寸为 48x192
PP-OCR v5 一键配置:
PaddleOCRConfig config = PaddleOCRConfig.GetPPOCRv5Config(
detModelPath: @"E:\Model\ppocrv5\PP-OCRv5_mobile_det_onnx.onnx",
clsModelPath: @"E:\Model\ppocrv5\PP-OCRv5_mobile_cls_onnx.onnx",
recModelPath: @"E:\Model\ppocrv5\PP-OCRv5_mobile_rec_onnx_combined.onnx",
recDictPath: @"E:\Model\ppocrv5\ppocrv5_dict.txt"
);
// v5 特点:Cls 输入尺寸为 80x160
自定义配置(适合有特殊需求的朋友):
// 分别指定检测(det)、分类(cls)和识别(rec)模型的本地路径,以及字典文件路径
var paddleOCRConfig = new PaddleOCRConfig(
detModelPath: @"E:\Model\ppocrv5\PP-OCRv5_mobile_det_onnx.onnx", // 检测模型:负责定位文字框
clsModelPath: @"E:\Model\ppocrv5\PP-OCRv5_mobile_cls_onnx.onnx", // 分类模型:判断文字方向(可选)
recModelPath: @"E:\Model\ppocrv5\PP-OCRv5_mobile_rec_onnx_combined.onnx", // 识别模型:负责认字
recDictPath: @"E:\Model\ppocrv5\ppocrv5_dict.txt" // 字典文件:模型能识别的字符表
);
三、推理引擎全面支持
DeploySharp 最新版本支持的推理引擎,前面已经说过,这里再详细唠唠各家的特点:
3.1 OpenVINO:Intel 的亲儿子
支持设备:
- CPU(普通电脑也能跑)
- Intel iGPU(Intel 集显)
- Intel GPU(Intel 独显,比如 Arc 系列)
- AUTO(混合模式:CPU + iGPU 双剑合璧)
什么时候用它?
- 手头没有独立显卡
- 用的是 Intel 处理器
- 对稳定性要求贼高的生产环境
3.2 TensorRT:NVIDIA 的速度之王
支持设备:
- NVIDIA GPU(必须有 N 卡)
- CUDA 11.x / 12.x
什么时候用它?
- 手里有 NVIDIA 显卡
- 追求极致推理速度,就是要快
- 可以接受离线模型转换的过程
3.3 ONNX Runtime:万能选手
支持设备:
- CPU(最基础)
- CUDA 12(N 卡专属)
- DML GPU(DirectML,支持 AMD/NVIDIA/Intel 全家桶显卡)
- TensorRT(通过 ONNX Runtime 调用)
什么时候用它?
- 需要跨平台部署
- 快速原型验证
- 需要支持多厂商显卡
四、性能表现:说话要靠数据
空口无凭,咱们上实测数据!
4.1 性能对比实测
测试设备1:Intel 组合拳
| 推理引擎 | 设备 | 设备类型 | PP-OCR v4 推理时间 | PP-OCR v5 推理时间 |
|---|---|---|---|---|
| OpenVINO | CPU | Intel Core Ultra 9 288V 8核 | 81 ms | 148 ms |
| OpenVINO | IGPU | Intel Arc 140V GPU (16GB) | 46 ms | 61 ms |
| OpenVINO | AUTO | Intel Core Ultra 9 288V 8核 + Intel Arc 140V GPU | 47 ms | 62 ms |
| ONNX Runtime DML | IGPU | Intel Arc 140V GPU | 241 ms | 188 ms |
解读: Intel 自家的 OpenVINO 在 Intel 硬件上表现抢眼,集显加速效果明显。
测试设备2:AMD + NVIDIA 组合
| 推理引擎 | 设备 | 设备类型 | PP-OCR v4 推理时间 | PP-OCR v5 推理时间 |
|---|---|---|---|---|
| OpenVINO | CPU | AMD Ryzen 7 5800H 8核 | 94ms | 236ms |
| ONNX Runtime | CPU | AMD Ryzen 7 5800H 8核 | 295ms | 329 ms |
| ONNX Runtime DML | GPU | NVIDIA GeForce RTX 3060 | 73ms | 81ms |
| ONNX Runtime CUDA | GPU | NVIDIA GeForce RTX 3060 | 62ms | 62ms |
| ONNX Runtime TensorRT | GPU | NVIDIA GeForce RTX 3060 | 28ms | 40 ms |
| TensorRT | GPU | NVIDIA GeForce RTX 3060 | 29ms | 49ms |
解读: RTX 3060 上 TensorRT 和 ONNX Runtime TensorRT 模式都能跑到 30ms 左右,速度相当可观!
优化版本:还能更快!
经过一番优化调优,我们拿到了更漂亮的成绩:
| 推理引擎 | 设备 | 设备类型 | PP-OCR v4 推理时间 | PP-OCR v5 推理时间 |
|---|---|---|---|---|
| ONNX Runtime DML | GPU | NVIDIA GeForce RTX 3060 | 60ms | 59ms |
| ONNX Runtime CUDA | GPU | NVIDIA GeForce RTX 3060 | 58ms | 56ms |
| ONNX Runtime TensorRT | GPU | NVIDIA GeForce RTX 3060 | 25ms | 26ms |
| TensorRT | GPU | NVIDIA GeForce RTX 3060 | 23ms | 36ms |
温馨提示:关于优化细节,这里先卖个关子,后续我会单独写一篇文章揭秘,敬请期待!
4.2 性能优化小贴士
想让你的模型跑得更快?试试这几招:
- 调整并发数:根据 GPU 核心数设置合理的并发数量,不是越多越好
- 优化 Batch Size:适当增大 Batch Size 可以提高 GPU 利用率,但要避免爆显存
- 模型精度:使用 FP16 量化可进一步提升推理速度,精度损失微乎其微
- 预热推理:首次推理较慢是正常现象(加载模型需要时间),后续推理速度会显著提升
- Rec模型最大输入宽度:这个参数很关键!根据你识别的文字内容调整宽度,能有效降低推理时间
五、案例演示:眼见为实
5.1 控制台 Demo
项目路径: demos/DeploySharp.OpenCvSharp.PaddleOcr.Demo
核心代码(保姆级注释版):
using DeploySharp.Data;
using DeploySharp.Engine;
using DeploySharp.Log;
using DeploySharp.Model;
using OpenCvSharp;
using System.Diagnostics;
namespace DeploySharp.OpenCvSharp.PaddleOcr.Demo
{
internal class Program
{
static void Main(string[] args)
{
// 第一步:设置日志级别,避免刷屏
MyLogger.SetLevel(Log.LogLevel.ERROR);
string imagePath = @"E:\Data\ocr\demo_1.jpg";
Mat img = Cv2.ImRead(imagePath);
// 第二步:创建 PP-OCR v5 配置
PaddleOCRConfig paddleOCRConfig = new PaddleOCRConfig(
detModelPath: @"E:\Model\ppocrv5\PP-OCRv5_mobile_det_onnx.onnx",
clsModelPath: @"E:\Model\ppocrv5\PP-OCRv5_mobile_cls_onnx.onnx",
recModelPath: @"E:\Model\ppocrv5\PP-OCRv5_mobile_rec_onnx_combined.onnx",
recDictPath: @"E:\Model\ppocrv5\ppocrv5_dict.txt"
);
// 第三步:配置推理引擎和设备
// 1. 设置全局推理后端为 ONNX Runtime
paddleOCRConfig.GlobalInferenceBackend = InferenceBackend.OnnxRuntime;
// 2. 配置硬件加速设备
paddleOCRConfig.GlobalDeviceType = DeviceType.GPU0;
// GlobalOnnxRuntimeDeviceType 指定 ONNX Runtime 具体使用的执行提供者(EP)
// OnnxRuntimeDeviceType.Cuda 表示启用 CUDA 加速(需确保安装了 CUDA 和 cuDNN)
paddleOCRConfig.GlobalOnnxRuntimeDeviceType = OnnxRuntimeDeviceType.Cuda;
// 3. 设置并发与批处理参数
// MaxConcurrency: 并发处理的最大线程数,设为 4 可充分利用 CPU 多核能力或 GPU 并行能力
paddleOCRConfig.MaxConcurrency = 4;
// GlobalMaxBatchSize: 动态批处理的最大批次大小
// 设为 4 允许引擎将 4 张图片打包一次性推理,大幅提升 GPU 利用率和吞吐量
paddleOCRConfig.GlobalMaxBatchSize = 4;
// 4. 配置识别模型的具体参数
// InferImageHeight: 统一将输入图片的高度缩放到 48 像素,这是 PP-OCRv5 识别模型的固定要求
paddleOCRConfig.RecConfig.InferImageHeight = 48;
// MaxImageWidth: 限制输入图片的最大宽度为 320 像素
// 适当限制宽度可减少显存占用并提高推理速度,通常能覆盖大多数长条形文字图片
paddleOCRConfig.RecConfig.MaxImageWidth = 320;
// 第四步:创建预测器并执行推理
using (PaddleOcrPredictor paddleOcrPredictor = new PaddleOcrPredictor(paddleOCRConfig))
{
// 预热:第一次推理会慢一点,模型加载需要时间
OcrResult ocrResult = paddleOcrPredictor.Predict(img);
// 性能测试:记录推理时间
Stopwatch sw = Stopwatch.StartNew();
ocrResult = paddleOcrPredictor.Predict(img);
sw.Stop();
// 第五步:输出结果
Console.WriteLine(ocrResult.ToString());
Console.WriteLine("---- Profiling Time ----");
paddleOcrPredictor.PrintTimeProfiling();
Console.WriteLine($"Inference time: {sw.ElapsedMilliseconds} ms");
// 可视化:在原图上标注识别结果
Mat resultMat = Visualize.DrawOcrResult(img, ocrResult, new VisualizeOptions(1.0f));
Cv2.ImShow("image", resultMat);
Cv2.WaitKey();
}
}
}
}
运行效果截图:
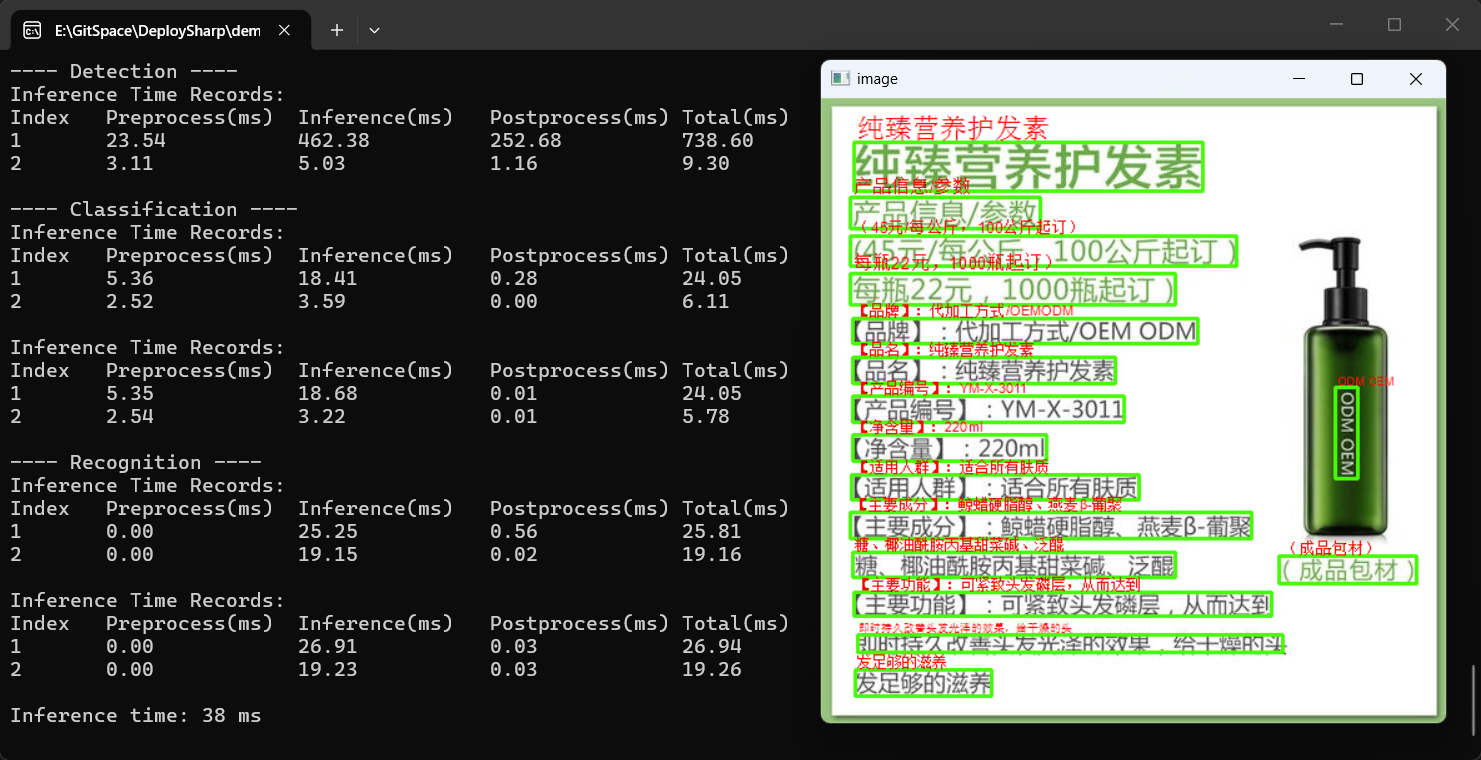
控制台输出示例:
========== OCR 识别结果 (共 16 处) ==========
[序号 1]
区域: Center: [81.8, 467.7] Size: 109.4x20.8 Angle: 0.0°
检测置信度: 0.98
方向: 0 (ID:0, 置信度:1.00)
内容: 发足够的滋养
识别置信度: 1.00
----------------------------------------
[序号 2]
区域: Center: [199.5, 436.5] Size: 340.6x14.6 Angle: 0.0°
检测置信度: 1.00
方向: 0 (ID:0, 置信度:1.00)
内容: 即时持久改善头发光泽的效果,给干燥的头
识别置信度: 0.97
----------------------------------------
[序号 3]
区域: Center: [193.2, 404.7] Size: 334.4x18.8 Angle: 0.0°
检测置信度: 0.81
方向: 0 (ID:0, 置信度:1.00)
内容: 【主要功能】:可紧致头发磷层,从而达到
识别置信度: 0.99
----------------------------------------
[序号 4]
区域: Center: [421.4, 377.6] Size: 109.4x21.9 Angle: 0.0°
检测置信度: 0.94
方向: 0 (ID:0, 置信度:1.00)
内容: (成品包材)
识别置信度: 1.00
----------------------------------------
(省略部分结果...)
[序号 16]
区域: Center: [165.6, 55.2] Size: 279.2x39.6 Angle: 0.0°
检测置信度: 0.91
方向: 0 (ID:0, 置信度:1.00)
内容: 纯臻营养护发素
识别置信度: 1.00
========================================
---- Profiling Time ----
---- Detection ----
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 23.54 462.38 252.68 738.60
2 3.11 5.03 1.16 9.30
---- Classification ----
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 5.36 18.41 0.28 24.05
2 2.52 3.59 0.00 6.11
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 5.35 18.68 0.01 24.05
2 2.54 3.22 0.01 5.78
---- Recognition ----
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 25.25 0.56 25.81
2 0.00 19.15 0.02 19.16
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 26.91 0.03 26.94
2 0.00 19.23 0.03 19.26
Inference time: 38 ms
5.2 桌面应用 Demo
项目路径: applications/.NET 8.0/JYPPX.DeploySharp.OpenCvSharp.PaddleOcr
主要功能一览:
| 功能 | 说明 |
|---|---|
| 推理模型选择 | 支持 PP-OCR v4、PP-OCR v5 一键切换 |
| 推理引擎选择 | OpenVINO / TensorRT / ONNX Runtime(多种执行提供者) |
| 推理设备选择 | CPU / GPU0 / GPU1 / AUTO |
| ONNX工具选择 | 支持CUDA、OpenVINO、TensorRT、DML等执行提供者 |
| 并发数量 | 支持 1-8 个并发引擎,根据设备性能设置,不是越多越好哦 |
| 批量处理(BatchSize) | 支持 1-16 的 Batch Size,同样要量力而行 |
| Det\Cls\Rec模型 配置 | 设置模型路径、模型输入形状限制,自由度超高 |
| 时间测试 | 连续 10 次推理,输出详细性能分析、平均时间 |
| 结果可视化 | 图像标注和文本结果显示,所见即所得 |
界面截图:
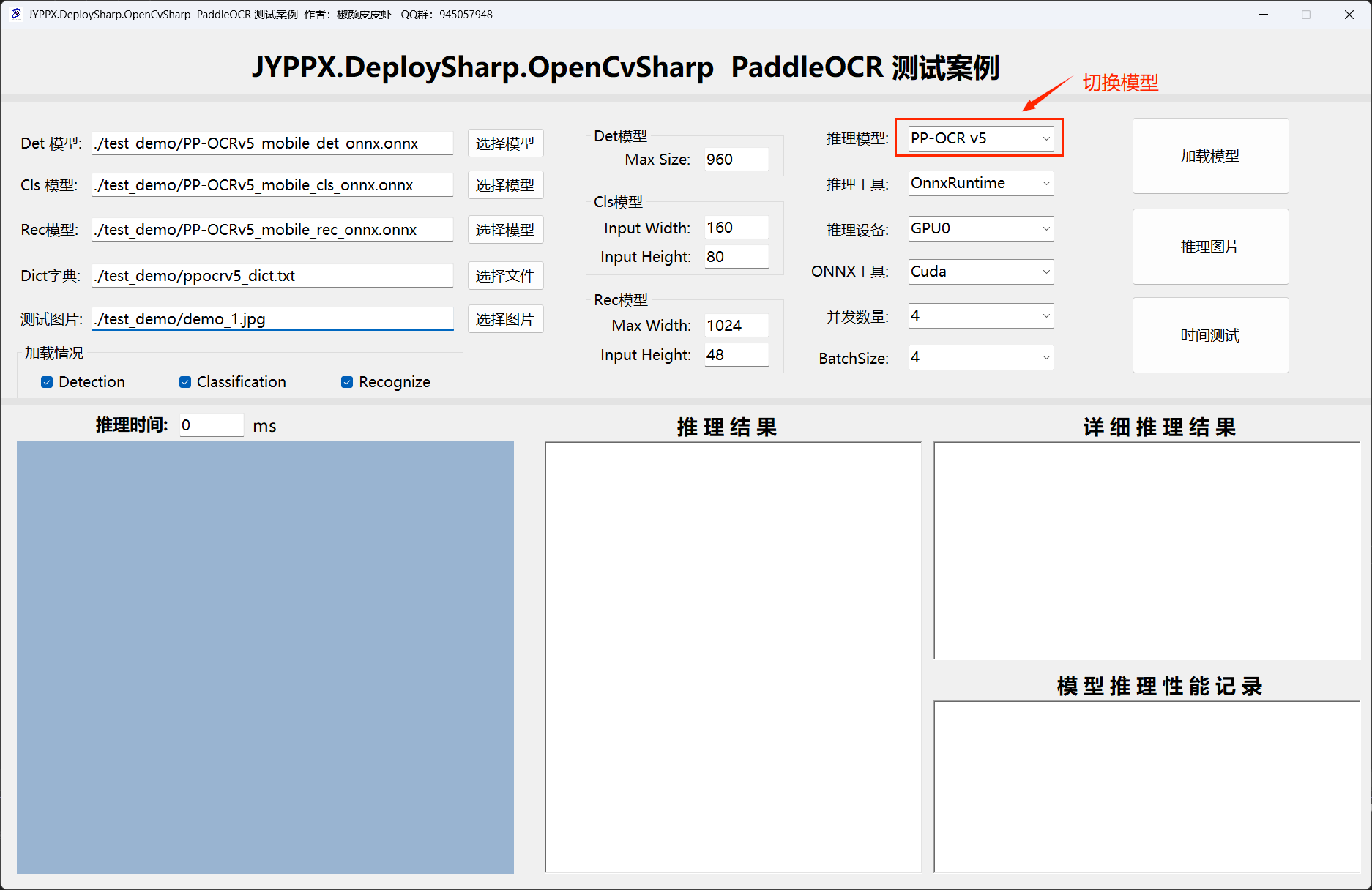
推理结果展示:
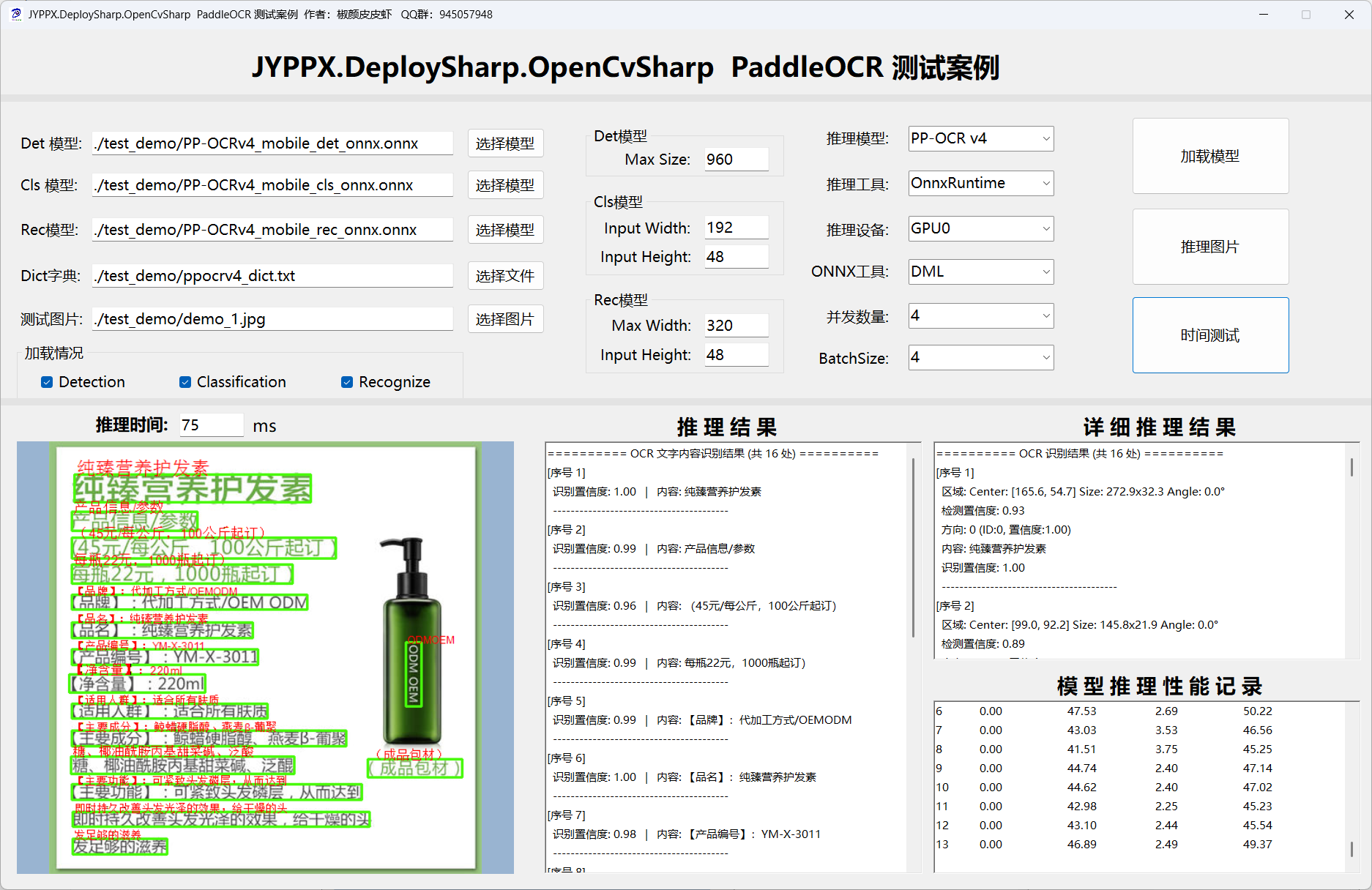
六、快速开始:三步上手
6.1 控制台 Demo 使用指南
第一步:克隆项目
git clone https://github.com/guojin-yan/DeploySharp.git
cd DeploySharp
第二步:准备模型文件
下载 PP-OCR 模型文件并放置到指定路径(记得创建文件夹哦):
E:\Model\ppocrv5\
├── PP-OCRv5_mobile_det_onnx.onnx # 检测模型
├── PP-OCRv5_mobile_cls_onnx.onnx # 分类模型
├── PP-OCRv5_mobile_rec_onnx_combined.onnx # 识别模型
└── ppocrv5_dict.txt # 字典文件
第三步:修改代码中的模型路径
编辑 demos/DeploySharp.OpenCvSharp.PaddleOcr.Demo/Program.cs,把模型路径改成你实际的路径。
第四步:编译运行
使用 Visual Studio 打开解决方案,或者用 dotnet CLI:
cd demos/DeploySharp.OpenCvSharp.PaddleOcr.Demo
dotnet run
6.2 桌面应用 Demo 使用指南
第一步:克隆项目
git clone https://github.com/guojin-yan/DeploySharp.git
cd DeploySharp/applications/.NET\ 8.0/JYPPX.DeploySharp.OpenCvSharp.PaddleOcr
第二步:准备模型文件
将模型文件放置到 test_demo 目录下:
test_demo\
├── PP-OCRv4_mobile_det_onnx.onnx
├── PP-OCRv4_mobile_cls_onnx.onnx
├── PP-OCRv4_mobile_rec_onnx.onnx
├── ppocrv4_dict.txt
├── PP-OCRv5_mobile_det_onnx.onnx
├── PP-OCRv5_mobile_cls_onnx.onnx
├── PP-OCRv5_mobile_rec_onnx.onnx
└── ppocrv5_dict.txt
第三步:编译运行
用 Visual Studio 打开解决方案直接运行,或者用命令行:
dotnet run
第四步:使用说明
- 选择模型版本(PP-OCR v4/v5)
- 选择推理引擎和设备
- 点击「加载模型」
- 选择测试图片
- 点击「推理图片」或「时间测试」
- 查看识别结果和性能数据
就这么简单!
七、软件获取
7.1 源码下载
DeploySharp 项目已完全开源,欢迎 Fork 和 Star!
主仓库:
https://github.com/guojin-yan/DeploySharp.git
分支说明:
DeploySharpV1.0- v1.0 开发分支
7.2 模型文件获取
PP-OCR 模型文件可以从以下途径获取:
- PaddleOCR 官方仓库:https://github.com/PaddlePaddle/PaddleOCR
- 交流群下载:加入 945057948 QQ交流群,在群文件中下载转换好的模型
7.3 可执行程序
不想自己编译?没问题!加入技术交流群,从群文件下载最新编译好的可执行程序,开箱即用。
八、技术支持
8.1 反馈与交流
遇到问题?有好的建议?欢迎通过以下方式联系我们:
- GitHub Issues:在项目仓库提交 Issue 或 Pull Request
- QQ 交流群:加入 945057948,获取实时技术支持
- 微信公众号:CSharp与边缘模型部署(更多教程+案例等你来)
- CSDN 博客:guojin.blog.csdn.net(技术文章持续更新)
8.2 相关资源
想深入了解技术细节?这里有官方文档:
- DeploySharp 主页:https://github.com/guojin-yan/DeploySharp
- PaddleOCR 官方:https://github.com/PaddlePaddle/PaddleOCR
- OpenVINO 官方:https://docs.openvino.ai/
- TensorRT 官方:https://docs.nvidia.com/deeplearning/tensorrt/
- ONNX Runtime 官方:https://onnxruntime.ai/docs/
结语
DeploySharp 0.0.8 版本的发布,标志着我们在 AI 模型部署领域又迈出了重要一步。通过新增对 PP-OCR v4/v5 的完整支持,以及提供 OpenVINO、TensorRT、ONNX Runtime 等多种推理引擎的统一接口,我们为 .NET 开发者提供了一套强大而灵活的 OCR 部署解决方案。
无论是想快速原型验证,还是需要生产环境部署,DeploySharp 都能满足你的需求。同一段代码,多种引擎自由切换,让 .NET 开发者在 AI 部署的道路上少走弯路。
想深入了解 PP-OCR 在不同平台上的部署细节?后续我们将陆续推出 OpenVINO、TensorRT、ONNX Runtime 全平台实战教程,还有上文埋下的"速度优化"伏笔,敬请期待!
未来,我们将继续优化框架性能,支持更多模型类型和推理引擎,为 .NET 开发者提供更完善的 AI 模型部署解决方案。
期待您的使用和反馈!

作者:Guojin Yan
版本:DeploySharp 0.0.8
发布时间:2026年2月
【文章声明】
本文主要内容基于作者的研究与实践,部分表述借助 AI 工具进行了辅助优化。由于技术局限性,文中可能存在错误或疏漏之处,恳请各位读者批评指正。如果内容无意中侵犯了您的权益,请及时通过公众号后台与我们联系,我们将第一时间核实并妥善处理。感谢您的理解与支持!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 40
40 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)