探索 DL00658 - 自适应医学图像分割模型的奥秘
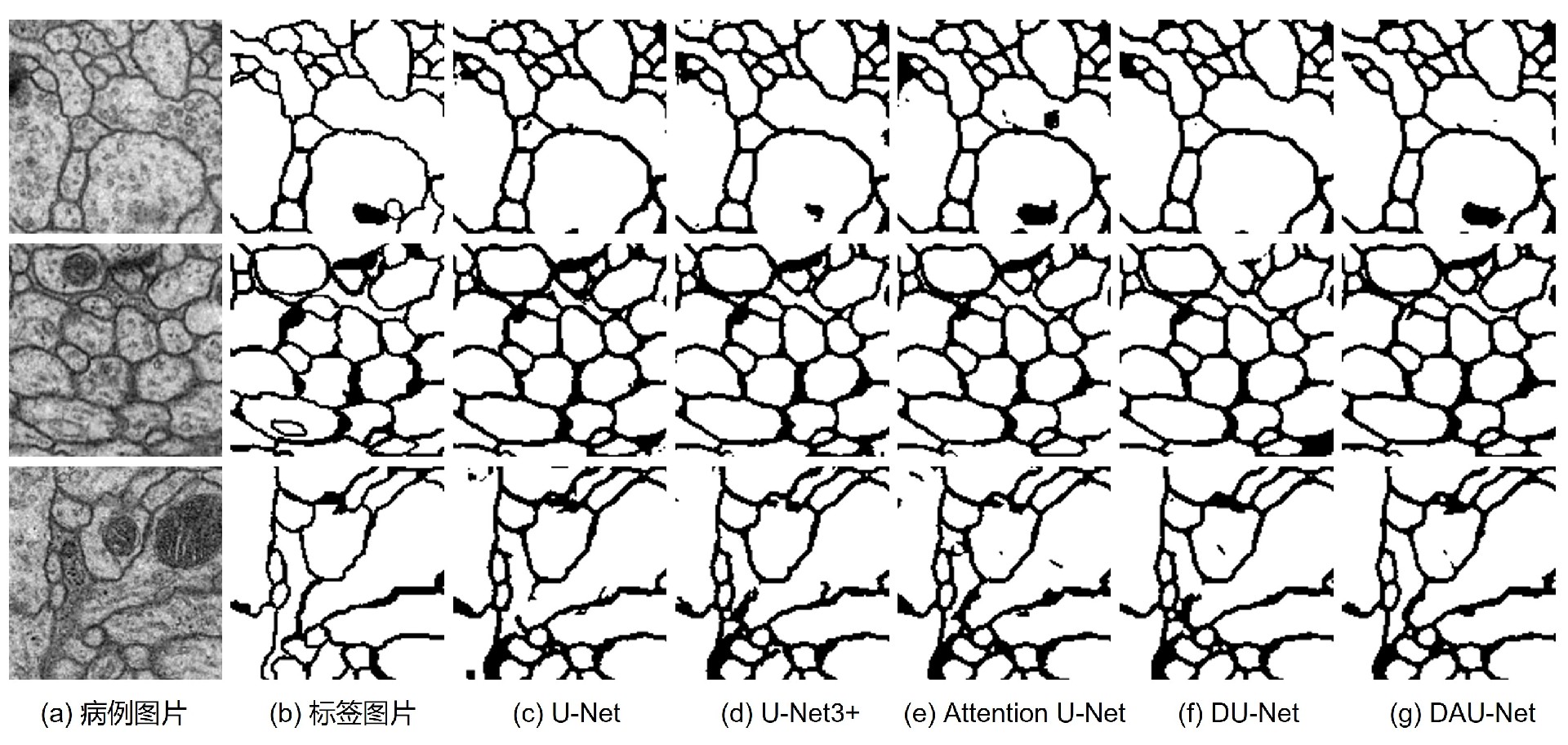
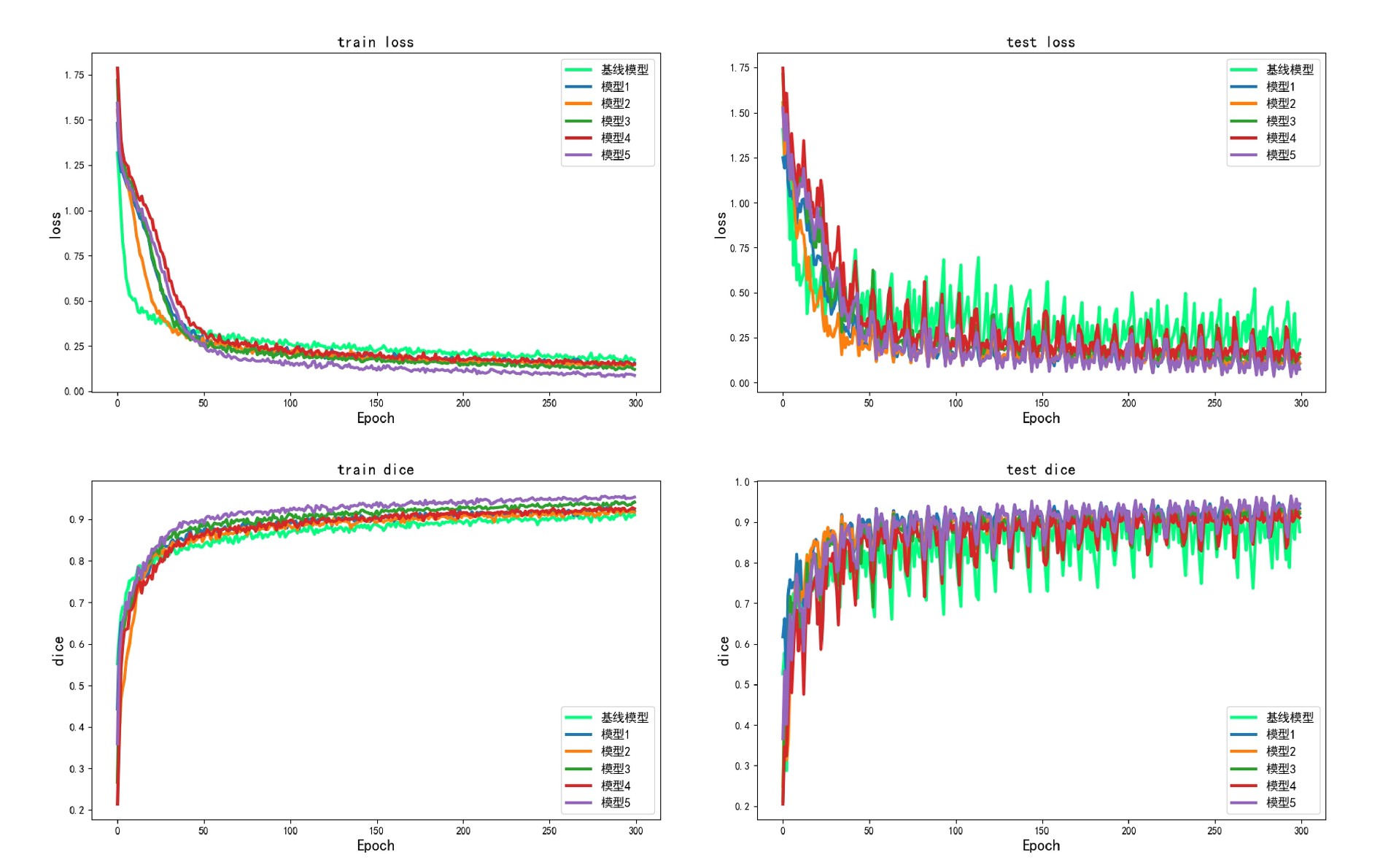
DL00658-自适应医学图像分割模型 模型使用可变形卷积自适应提取特征;利用全面的间隔跳跃连接在编码器上搜集特征信息,解码器上残差连接促进特征进行传递利用;残差注意力卷积优化编码器和解码器之间的语义差距,从通道和空间上的注意力抑制无关特征,突出有效特征,自适应促进二者之间的特征传递利用;除了提高精度外,模型还使用多尺度深度监督来进一步增强病灶区域边界分割并减少非病灶区域的过度分割。

在医学图像处理领域,精准的图像分割对于疾病诊断、治疗方案制定等都有着至关重要的意义。今天要和大家聊一聊 DL00658 这个自适应医学图像分割模型,看看它有哪些独特的 “本领”。
可变形卷积自适应提取特征
DL00658 模型的一大亮点是采用可变形卷积来自适应提取特征。传统卷积的卷积核大小和形状是固定的,在处理复杂多变的医学图像时,可能无法很好地适应图像中目标的各种形态。而可变形卷积则打破了这种限制。
以 PyTorch 代码为例(假设已经安装好 PyTorch 库):
import torch
import torch.nn as nn
import torchvision.ops as ops
class DeformConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, padding=1, bias=True):
super(DeformConv, self).__init__()
self.offset_conv = nn.Conv2d(in_channels, 2 * kernel_size * kernel_size, kernel_size=kernel_size, padding=padding)
nn.init.constant_(self.offset_conv.weight, 0)
nn.init.constant_(self.offset_conv.bias, 0)
self.modulator_conv = nn.Conv2d(in_channels, kernel_size * kernel_size, kernel_size=kernel_size, padding=padding)
nn.init.constant_(self.modulator_conv.weight, 0)
nn.init.constant_(self.modulator_conv.bias, 1)
self.deform_conv = ops.DeformConv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding, bias=bias)
def forward(self, x):
offset = self.offset_conv(x)
modulator = torch.sigmoid(self.modulator_conv(x))
out = self.deform_conv(x, offset, modulator)
return out这里,offsetconv 负责生成偏移量,让卷积核能够在图像上 “变形” 以更好地捕捉目标特征。modulatorconv 生成调制系数,用来调整卷积核各个位置的权重。通过这种方式,可变形卷积可以根据图像内容动态地改变卷积核的采样位置,从而自适应地提取医学图像中的各种特征。
全面的间隔跳跃连接与残差连接
模型还利用了全面的间隔跳跃连接在编码器上搜集特征信息,同时在解码器上使用残差连接促进特征传递利用。

编码器中的间隔跳跃连接有点像在不同楼层之间设置了一些 “秘密通道”,能让特征信息在不同层次之间快速传递。比如说,我们在搭建编码器时可能会有这样的代码片段(简单示意,非完整代码):
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
def forward(self, x):
out1 = self.conv1(x)
out2 = self.conv2(out1)
skip_connection = out1 + out2 # 这里简单模拟间隔跳跃连接,将不同层特征相加
out3 = self.conv3(skip_connection)
return out3这样可以让低级特征和中级特征相结合,为后续的处理保留更丰富的信息。

DL00658-自适应医学图像分割模型 模型使用可变形卷积自适应提取特征;利用全面的间隔跳跃连接在编码器上搜集特征信息,解码器上残差连接促进特征进行传递利用;残差注意力卷积优化编码器和解码器之间的语义差距,从通道和空间上的注意力抑制无关特征,突出有效特征,自适应促进二者之间的特征传递利用;除了提高精度外,模型还使用多尺度深度监督来进一步增强病灶区域边界分割并减少非病灶区域的过度分割。
在解码器中,残差连接则像是给特征传递铺了一条 “高速公路”。看下面简单的解码器残差连接代码(同样非完整代码):
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.conv1 = nn.Conv2d(256, 128, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(128, 64, kernel_size=3, padding=1)
def forward(self, x):
out1 = self.conv1(x)
identity = x # 残差连接,保留输入特征
out2 = self.conv2(out1 + identity) # 将经过处理的特征和原始特征相加
return out2残差连接能够让特征在传递过程中避免信息丢失,使解码器更好地利用编码器传递过来的特征。
残差注意力卷积优化语义差距
残差注意力卷积是 DL00658 模型用来优化编码器和解码器之间语义差距的关键技术。它从通道和空间上的注意力机制出发,抑制无关特征,突出有效特征,自适应地促进二者之间的特征传递利用。
还是来看代码(以简单的通道注意力为例):
class ChannelAttention(nn.Module):
def __init__(self, in_channels, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // ratio, in_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)这里,avg_pool 对每个通道进行全局平均池化,将特征图压缩成一个向量。fc 层则通过降维和升维操作,学习通道之间的重要性权重。最终通过权重与原特征图相乘,突出重要通道的特征,抑制无关通道特征。空间注意力也类似,只不过是在空间维度上进行操作。通过残差注意力卷积,编码器和解码器之间能够更有效地传递语义信息。
多尺度深度监督提升分割效果
除了前面提到的各种提升精度的方法,DL00658 模型还使用多尺度深度监督来进一步增强病灶区域边界分割并减少非病灶区域的过度分割。简单来说,就是在模型的不同层次上都进行监督学习。
比如,我们可以在模型的不同层输出特征图,并分别计算它们与真实标签的损失(这里以简单的交叉熵损失为例,代码示意):
criterion = nn.CrossEntropyLoss()
output1, output2, output3 = model(input) # 假设模型在不同层有输出
loss1 = criterion(output1, target)
loss2 = criterion(output2, target)
loss3 = criterion(output3, target)
total_loss = loss1 + loss2 + loss3这样,模型不仅关注最终输出的分割结果,还能从中间层的特征表示中学习到更多关于病灶和非病灶区域的信息,从而更好地进行边界分割,减少过度分割的情况。
DL00658 这个自适应医学图像分割模型通过多种创新技术的结合,在医学图像分割任务中展现出强大的潜力,为医学图像处理领域带来了新的思路和方法。希望未来能看到它在实际临床应用中发挥更大的作用。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)