我“调教”了一个AI Agent,让它全天自动写测试用例:3分钟24条,准确率70%+
本文介绍了RAG(检索增强生成)技术的原理与应用开发实践。主要内容包括:1)RAG技术概述,解决传统生成模型的知识过时、领域局限等问题;2)RAG系统架构及关键技术,如文档分块、向量嵌入和向量数据库;3)使用FastAPI+CrewAI开发测试用例生成Agent的实战方案,涵盖知识库管理、向量化处理等核心模块实现;4)详细讲解了Qwen3-Embedding模型部署和ChromaDB向量数据库操作
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
这个专题非常受欢迎,目前已经更新到第三篇啦~
五、RAG知识库技术介绍
5.1 什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了信息检索和文本生成的技术框架,旨在通过引入外部知识库来提升生成模型(如GPT等)的准确性和可靠性。
RAG 解决的问题
传统的生成模型依赖预训练时学到的参数化知识,存在以下问题:
● 知识过时:训练数据可能已经过时
● 领域局限:缺乏特定领域的专业知识
● 幻觉问题:生成不准确或虚构的内容
● 无法更新:无法动态更新知识
RAG 的优势:
● 动态知识:可以随时更新知识库
● 领域专业:可以添加特定领域的知识
● 减少幻觉:基于真实文档生成答案
● 可追溯性:可以追溯答案来源
5.2 RAG 架构及执行流程
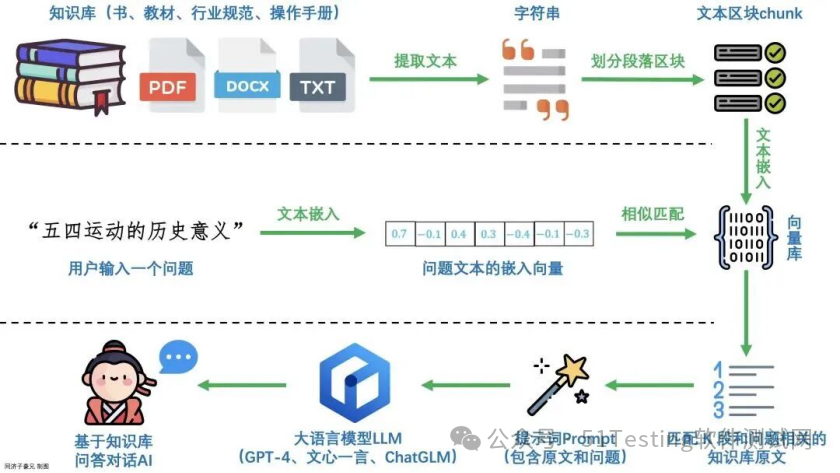
RAG 执行流程
1. 文档处理
├── 提取语料库内
├── 文档分块(Chunking)
└── 转化为向量(Embedding)2. 向量存储
├── 文本向量写入向量数据库
└── 建立索引3. 检索阶段
├── 用户查询转向量
├── 向量相似度搜索
└── 召回相关文档
4. 生成阶段
├── 构建提示词(Prompt)
├── 调用大模型生成结果
└── 返回答案RAG 系统架构图
┌─────────────┐
│ 用户查询 │
└──────┬──────┘│▼┌─────────────────┐│ 查询向量化 │ ← Embedding Model└──────┬──────────┘│▼┌─────────────────┐│ 向量相似度搜索 │ ← Vector Database(ChromaDB)└──────┬──────────┘│▼┌─────────────────┐│ 召回相关文档 │└──────┬──────────┘│▼┌─────────────────┐│ 构建提示词 │└──────┬──────────┘│▼┌─────────────────┐│ LLM 生成答案 │ ← MoonShot/GPT└──────┬──────────┘│▼┌─────────────────┐│ 返回结果 │└─────────────────┘
5.3 RAG 的关键技术
1. 文档分块(Chunking)
将长文档切分为小块,便于检索和处理。
分块策略:
● 固定长度分块:按字符数或 Token 数切分
● 语义分块:按段落、句子切分
● 滑动窗口:重叠切分,保留上下文
def chunk_text(text: str, chunk_size: int = 500, overlap: int = 50) -> List[str]:
"""文本分块"""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunk = text[start:end]
chunks.append(chunk)
start = end - overlap # 重叠部分
return chunks2. 向量嵌入(Embedding)
将文本转换为高维向量,便于计算相似度。
常用嵌入模型:
●OpenAI Embeddings:text-embedding-ada-002
●Sentence Transformers:all-MiniLM-L6-v2
●Qwen Embeddings:Qwen3-Embedding-4B(本项目使用)
3. 向量相似度计算
常用相似度算法:
●余弦相似度:最常用,范围 [-1, 1]
●欧氏距离:计算向量间的直线距离
●点积:向量内积
import numpy as np
def cosine_similarity(vec1, vec2):
"""余弦相似度"""
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))六、文本嵌入和向量化
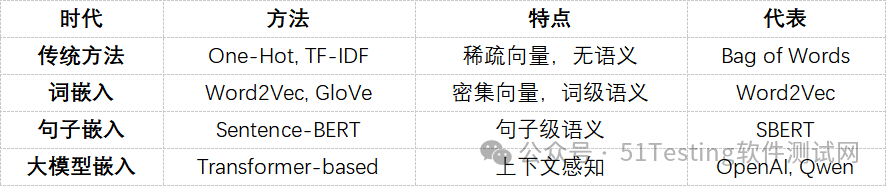
6.1 文本嵌入的方法介绍
文本嵌入(Text Embedding)是将文本转换为数值向量的过程,是 RAG 系统的核心技术。
文本嵌入的发展历程
现代嵌入模型对比
6.2 Qwen3-embedding嵌入模型部署介绍
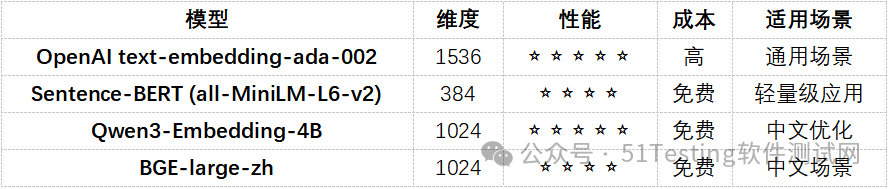
Qwen3-Embedding是阿里云开源的中文优化嵌入模型,具有以下特点:
●中文优化:针对中文语义理解优化
●高性能:在中文检索任务上表现优异
●本地部署:支持本地部署,无需调用 API
●开源免费:完全开源,无使用限制
模型规格

6.3 Ollama部署Qwen3-embedding模型
Ollama 是一个轻量级的本地大模型运行工具,支持多种开源模型。
安装 Ollama
macOS / Linux:
printcurl -fsSL https://ollama.com/install.sh | shf("hello world!");Windows:
访问 https://ollama.com/download 下载安装包。
拉取 Qwen3-Embedding 模型
# 拉取模型(量化版本,体积更小)
ollama pull dengcao/Qwen3-Embedding-4B:Q5_K_M
# 或拉取完整版本
ollama pull dengcao/Qwen3-Embedding-4B测试模型
# 启动 Ollama 服务(默认端口 11434)
ollama serve
# 测试嵌入
curl http://localhost:11434/api/embeddings -d '{
"model": "dengcao/Qwen3-Embedding-4B:Q5_K_M",
"prompt": "FastAPI 是一个高性能的 Web 框架"
}'Python调用示例
import requests
def get_embedding(text: str) -> list:
"""获取文本嵌入向量"""
url = "http://localhost:11434/api/embeddings"
response = requests.post(
url,
json={
"model": "dengcao/Qwen3-Embedding-4B:Q5_K_M",
"prompt": text
}
)
return response.json()['embedding']
embedding = get_embedding("FastAPI 是一个高性能的 Web 框架")
print(f"向量维度: {len(embedding)}") # 输出: 10246.4 什么是向量化?
向量化(Vectorization) 是将非结构化数据(如文本、图像)转换为数值向量的过程。
向量化的意义
1.数学计算:向量可以进行数学运算(加减乘除、距离计算)
2.相似度度量:通过向量距离衡量文本相似度
3.高效检索:向量数据库支持高效的相似度搜索
4.机器学习:向量是机器学习模型的输入格式
6.5 向量数据库 ChromaDB 详解
ChromaDB 是一个开源的向量数据库,专为 AI 应用设计。
ChromaDB 的特点
●轻量级:易于安装和部署
●高性能:支持百万级向量检索
●易用性:API 简单直观
●持久化:支持数据持久化存储
●过滤查询:支持元数据过滤
安装 ChromaDB
pip install chromadbChromaDB 基本操作
1. 创建客户端
import chromadb
# 内存模式(临时)
client = chromadb.Client()
# 持久化模式(推荐)
client = chromadb.PersistentClient(path="./data/vector_db")2. 创建集合(Collection)
# 创建集合
collection = client.create_collection(
name="knowledge_base",
metadata={"description": "知识库向量集合"}
)
# 获取已存在的集合
collection = client.get_collection(name="knowledge_base")
# 获取或创建集合
collection = client.get_or_create_collection(name="knowledge_base")3. 添加文档
# 添加文档(自动生成嵌入)
collection.add(
documents=["FastAPI 是一个高性能的 Web 框架", "Django 是一个全栈框架"],
metadatas=[{"source": "doc1"}, {"source": "doc2"}],
ids=["id1", "id2"]
)
# 添加文档(手动提供嵌入)
collection.add(
embeddings=[[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]],
documents=["文档 1", "文档 2"],
metadatas=[{"type": "text"}, {"type": "text"}],
ids=["id1", "id2"]
)4. 查询文档
# 查询相似文档
results = collection.query(
query_texts=["Python Web 框架"],
n_results=5 # 返回前5个最相似的文档
)
# 查询结果
print(results['documents']) # 文档内容
print(results['distances']) # 相似度距离
print(results['metadatas']) # 元数据5. 更新和删除
# 更新文档
collection.update(
ids=["id1"],
documents=["更新后的文档内容"]
)
# 删除文档
collection.delete(ids=["id1"])
# 删除集合
client.delete_collection(name="knowledge_base")七、使用FastAPI+CrewAI开发实战
接下来,笔者将详细介绍如何使用 FastAPI 和 CrewAI 开发一个完整的测试用例生成 Agent 应用。
7.1 系统架构设计
┌─────────────────────────────────────────────────────────────┐│ 前端 (Vue3 + ElementPlus) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ ││ │知识库管理│ │用例生成 │ │代码分析 │ │向量搜索 │ ││ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │└─────────────────────────────────────────────────────────────┘↓ HTTP/WebSocket┌─────────────────────────────────────────────────────────────┐│ FastAPI 后端服务 ││ ┌──────────────────────────────────────────────────────┐ ││ │ API 路由层 │ ││ │ /api/v1/knowledges /api/v1/case-generation │ ││ └──────────────────────────────────────────────────────┘ ││ ┌──────────────────────────────────────────────────────┐ ││ │ 业务逻辑层 (Services) │ ││ │ KnowledgeService | VectorService │ ││ └──────────────────────────────────────────────────────┘ ││ ┌──────────────────────────────────────────────────────┐ ││ │ Agent 智能体层 │ ││ │ RAGRetrievalAgent | CaseGeneratorAgent │ ││ └──────────────────────────────────────────────────────┘ ││ ┌──────────────────────────────────────────────────────┐ ││ │ 数据访问层 (Models + ORM) │ ││ │ Tortoise-ORM | SQLite │ ││ └──────────────────────────────────────────────────────┘ │└─────────────────────────────────────────────────────────────┘↓┌─────────────────────────────────────────────────────────────┐│ 外部服务 ││ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ ││ │ChromaDB │ │Ollama │ │MoonShot │ │SQLite │ ││ │向量数据库│ │嵌入模型 │ │大语言模型│ │关系数据库│ ││ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │└─────────────────────────────────────────────────────────────┘
7.2 知识库管理实现
7.2.1 数据模型定义
# models/knowledge.py
from tortoise.models import Model
from tortoise import fields
class Knowledge(Model):
"""知识库模型"""
id = fields.IntField(pk=True, description="知识库唯一标识")
name = fields.CharField(max_length=255, unique=True, description="知识库名称")
description = fields.TextField(null=True, description="知识库描述")
created_at = fields.DatetimeField(auto_now_add=True, description="创建时间")
updated_at = fields.DatetimeField(auto_now=True, description="更新时间")
class Meta:
table = "knowledges"
class KnowledgeFile(Model):
"""知识库文件模型"""
id = fields.IntField(pk=True)
knowledge = fields.ForeignKeyField(
"models.Knowledge",
related_name="files",
on_delete=fields.CASCADE
)
filename = fields.CharField(max_length=255)
file_path = fields.CharField(max_length=500)
file_size = fields.IntField()
status = fields.CharField(max_length=20, default="uploaded")
upload_time = fields.DatetimeField(auto_now_add=True)
processed_time = fields.DatetimeField(null=True)
class Meta:
table = "knowledge_files"7.2.2 知识库服务实现
# services/knowledge_service.py
from typing import List, Dict, Any
from models.knowledge import Knowledge, KnowledgeFile
from base.embedding_vector import embedding_service
classKnowledgeService:
"""知识库服务"""
async def create_knowledge(self, name: str, description: str = None) -> Knowledge:
"""创建知识库"""
knowledge = await Knowledge.create(
name=name,
description=description
)
return knowledge
async def upload_file(
self,
knowledge_id: int,
filename: str,
file_path: str,
file_size: int
) -> KnowledgeFile:
"""上传文件到知识库"""
# 创建文件记录
file_record = await KnowledgeFile.create(
knowledge_id=knowledge_id,
filename=filename,
file_path=file_path,
file_size=file_size,
status="uploaded"
)
# 异步处理文件(分块、向量化、存储)
await self._process_file(file_record)
return file_record
async def _process_file(self, file_record: KnowledgeFile):
"""处理文件: 分块、向量化、存储"""
# 1. 读取文件内容
with open(file_record.file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 2. 文档分块
chunks = self._chunk_text(content, chunk_size=500, overlap=50)
# 3. 准备文档块数据
chunk_data = [
{
"chunk_id": i,
"content": chunk,
"start_pos": i * 450,
"end_pos": i * 450 + len(chunk)
}
for i, chunk in enumerate(chunks)
]
# 4. 向量化并存储到 ChromaDB
await embedding_service.add_documents_to_collection(
knowledge_id=file_record.knowledge_id,
file_id=file_record.id,
chunks=chunk_data
)
# 5. 更新文件状态
file_record.status = "processed"
file_record.processed_time = datetime.now()
await file_record.save()
def _chunk_text(self, text: str, chunk_size: int = 500, overlap: int = 50) -> List[str]:
"""文本分块"""
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunk = text[start:end]
chunks.append(chunk)
start = end - overlap
return chunks
async def search_similar(
self,
query_text: str,
collection_id: int,
top_k: int = 10
) -> List[Dict[str, Any]]:
"""搜索相似文档"""
results = await embedding_service.search_similar_documents(
knowledge_id=collection_id,
query=query_text,
top_k=top_k
)
return results7.2.3 知识库 API 路由
# api/knowledges.py
from fastapi import APIRouter, UploadFile, File, Form
from typing import List
from services.knowledge_service import KnowledgeService
from schemas.knowledge import KnowledgeCreate, KnowledgeResponse
router = APIRouter(prefix="/api/v1/knowledges", tags=["知识库管理"])
knowledge_service = KnowledgeService()
@router.post("/", response_model=KnowledgeResponse)
async def create_knowledge(data: KnowledgeCreate):
"""创建知识库"""
knowledge = await knowledge_service.create_knowledge(
name=data.name,
description=data.description
)
return knowledge
@router.post("/{knowledge_id}/files")
async def upload_file(
knowledge_id: int,
file: UploadFile = File(...)
):
"""上传文件到知识库"""
# 保存文件
file_path = f"./data/upload/{file.filename}"
with open(file_path, "wb") as buffer:
content = await file.read()
buffer.write(content)
# 创建文件记录并处理
file_record = await knowledge_service.upload_file(
knowledge_id=knowledge_id,
filename=file.filename,
file_path=file_path,
file_size=len(content)
)
return {
"success": True,
"file_id": file_record.id,
"message": "文件上传成功,正在处理..."
}
@router.get("/{knowledge_id}/search")
async def search_knowledge(
knowledge_id: int,
query: str,
top_k: int = 10
):
"""搜索知识库"""
results = await knowledge_service.search_similar(
query_text=query,
collection_id=knowledge_id,
top_k=top_k
)
return {
"success": True,
"query": query,
"results": results
}后续将继续为大家介绍RAG检索 Agent 实现、测试用例生成 Agent 实现、WebSocket 实时通信和前端功能的实现等。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)