【TextIn大模型加速器 + 火山引擎】大测TextIn对52种语言的支持与额外语种的施压
本文对TextIn通用文字识别功能进行了多语种场景测评。测试结果显示,该平台能准确识别官方支持的52种语言(包括中文、英语、法语等印欧语系语言),但对中东等非支持语种识别效果不佳。测评发现其文字识别精准度高,韩语等支持语种可达100%解析,但缺乏翻译功能。虽然存在部分语种不支持的问题,但整体表现优异,展现了强大的多语言处理能力。建议未来可扩展更多语种支持并增加翻译功能。

目录
前言
前两天我看到了个TextIn的活动,在看活动中有这么一条,支持50+中语言,那也就是对50多种语言的翻译是没有问题的,并且还能返回20+种格式,真的的好厉害,我对这点产生了浓厚的兴趣,所以今天我就来实打实的测评一下,好坏都有可能,这是一篇纯理性的测评文输出,希望能对大家产生一定的价值。

测试图片·多语种场景测评分析
我找到了官方支持的语种文档,特意的都看了看国家,知道的国家基本都是印欧的,也就是说以印欧语言为主,根据官方的支持文档,我转成了表格,截取图片都放在这里了,这是官方给的支持语言列表,我们根据这个进行具体的测试。
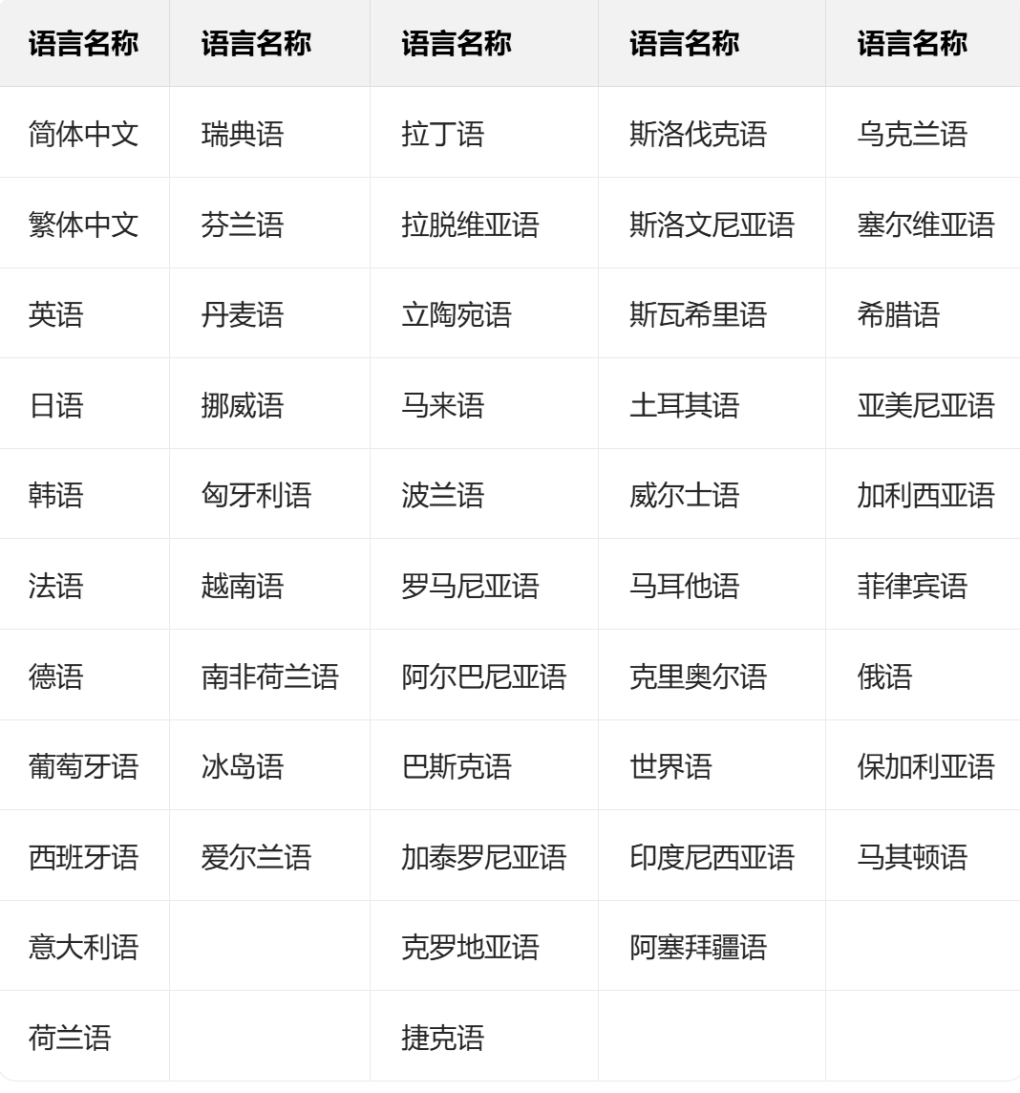
应用技术选型——通用文字识别52种支持语言测试
https://www.textin.com/console/dashboard/overview
登录后就直接能进来了,我们需要根据我们的需求来选择功能接口。
我们的需求是将图片中的信息读取出来,那么也就是通用文字识别即可,工作台全部产品处有一个搜索功能,并且下方显示的热门产品中第一个就是通用文字识别,我们直接点击使用这个功能,这个功能可以说为【通用文档解析】。
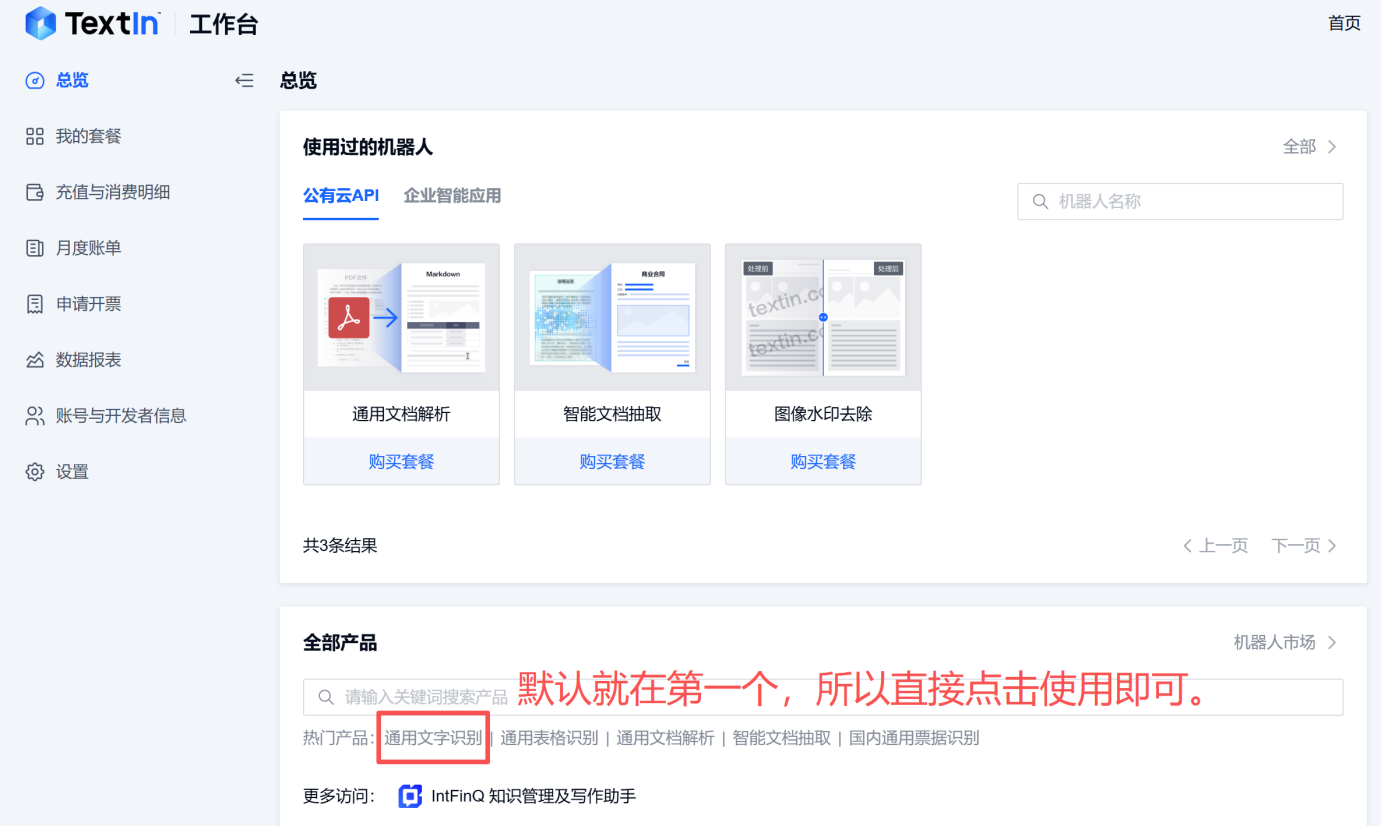
有在线使用,我们直接去测评,这样效率更高。

先上传图片,然后等着分析。
这里我随便截取了一部分进行识别,很直接的就能看到效果,都是识别成功的,并且是多语种的同步识别,没有进行拆分,这点就很强大了呢。
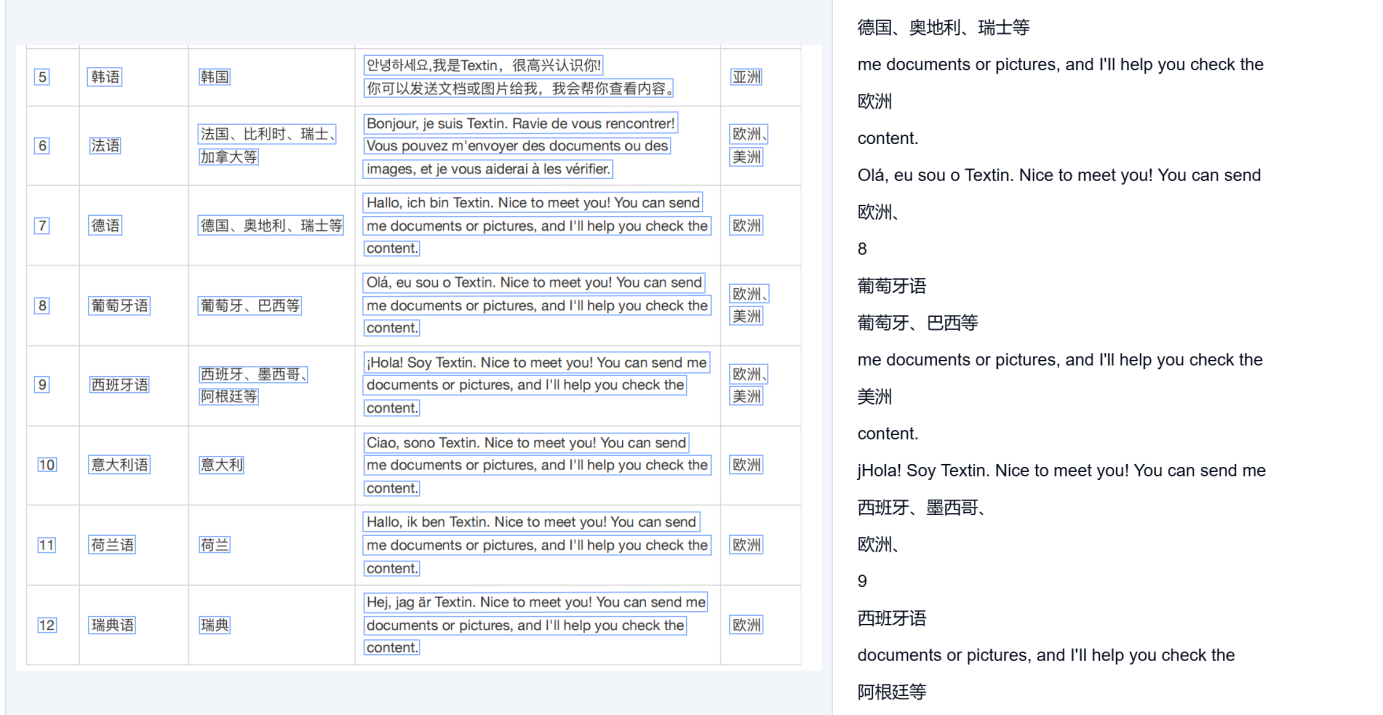
我这里根据语种源头进行分类:
|
所属国家 / 地区 |
语言名称 |
语种源头 |
所属国家 / 地区 |
语言名称 |
语种源头 |
|
中国 |
简体中文 |
汉藏语系汉语族 |
挪威 |
挪威语 |
印欧语系日耳曼语族 |
|
台湾、香港、澳门 |
繁体中文 |
汉藏语系汉语族 |
匈牙利 |
匈牙利语 |
乌拉尔语系芬兰 - 乌戈尔语族 |
|
美国、英国、澳大利亚、加拿大、新西兰等 |
英语 |
印欧语系日耳曼语族 |
越南 |
越南语 |
南亚语系孟 - 高棉语族 |
|
日本 |
日语 |
日本 - 琉球语系 |
南非 |
南非荷兰语 |
印欧语系日耳曼语族 |
|
韩国 |
韩语 |
朝鲜语系 |
芬兰 |
芬兰语 |
乌拉尔语系芬兰 - 乌戈尔语族 |
|
法国、比利时、瑞士、加拿大等 |
法语 |
印欧语系罗曼语族 |
丹麦 |
丹麦语 |
印欧语系日耳曼语族 |
|
德国、奥地利、瑞士等 |
德语 |
印欧语系日耳曼语族 |
阿尔巴尼亚 |
阿尔巴尼亚语 |
印欧语系阿尔巴尼亚语族 |
|
葡萄牙、巴西等 |
葡萄牙语 |
印欧语系罗曼语族 |
西班牙巴斯克地区 |
巴斯克语 |
孤立语系(无归属) |
|
西班牙、墨西哥、阿根廷等 |
西班牙语 |
印欧语系罗曼语族 |
西班牙加泰罗尼亚地区 |
加泰罗尼亚语 |
印欧语系罗曼语族 |
|
意大利 |
意大利语 |
印欧语系罗曼语族 |
克罗地亚 |
克罗地亚语 |
印欧语系斯拉夫语族 |
|
荷兰 |
荷兰语 |
印欧语系日耳曼语族 |
捷克 |
捷克语 |
印欧语系斯拉夫语族 |
|
瑞典 |
瑞典语 |
印欧语系日耳曼语族 |
爱沙尼亚 |
爱沙尼亚语 |
乌拉尔语系芬兰 - 乌戈尔语族 |
|
冰岛 |
冰岛语 |
印欧语系日耳曼语族 |
拉脱维亚 |
拉脱维亚语 |
印欧语系波罗的语族 |
|
爱尔兰 |
爱尔兰语 |
印欧语系凯尔特语族 |
立陶宛 |
立陶宛语 |
印欧语系波罗的语族 |
|
无特定国家 |
拉丁语 |
印欧语系罗曼语族 |
马来西亚、印度尼西亚等 |
马来语 |
南岛语系马来 - 波利尼西亚语族 |
|
无特定国家 |
世界语 |
人工构造语(基于罗曼语族) |
波兰 |
波兰语 |
印欧语系斯拉夫语族 |
|
西班牙加利西亚地区 |
加利西亚语 |
印欧语系罗曼语族 |
罗马尼亚 |
罗马尼亚语 |
印欧语系罗曼语族 |
|
菲律宾 |
菲律宾语 |
南岛语系马来 - 波利尼西亚语族 |
斯洛伐克 |
斯洛伐克语 |
印欧语系斯拉夫语族 |
|
俄罗斯 |
俄语 |
印欧语系斯拉夫语族 |
斯洛文尼亚 |
斯洛文尼亚语 |
印欧语系斯拉夫语族 |
|
保加利亚 |
保加利亚语 |
印欧语系斯拉夫语族 |
肯尼亚、坦桑尼亚等 |
斯瓦希里语 |
尼日尔 - 刚果语系班图语族 |
|
北马其顿 |
马其顿语 |
印欧语系斯拉夫语族 |
土耳其 |
土耳其语 |
阿尔泰语系突厥语族 |
|
乌克兰 |
乌克兰语 |
印欧语系斯拉夫语族 |
英国威尔士 |
威尔士语 |
印欧语系凯尔特语族 |
|
塞尔维亚 |
塞尔维亚语 |
印欧语系斯拉夫语族 |
马耳他 |
马耳他语 |
亚非语系闪米特语族 |
|
希腊 |
希腊语 |
印欧语系希腊语族 |
塞舌尔、毛里求斯等 |
克里奥尔语 |
混合语系(基于法语等) |
|
亚美尼亚 |
亚美尼亚语 |
印欧语系亚美尼亚语族 |
印度尼西亚 |
印度尼西亚语 |
南岛语系马来 - 波利尼西亚语族 |
|
阿塞拜疆 |
阿塞拜疆语 |
阿尔泰语系突厥语族 |
我总结的看了看,汉语系就是我们周边的国家,其它的基本都属于印欧语系列,中东语系基本不支持所以出现了对应的问题,只要在这52中语言内都是可以正常识别的。
我又再次测试了一些特殊字体,可以看到也都成功的识别并显示了。
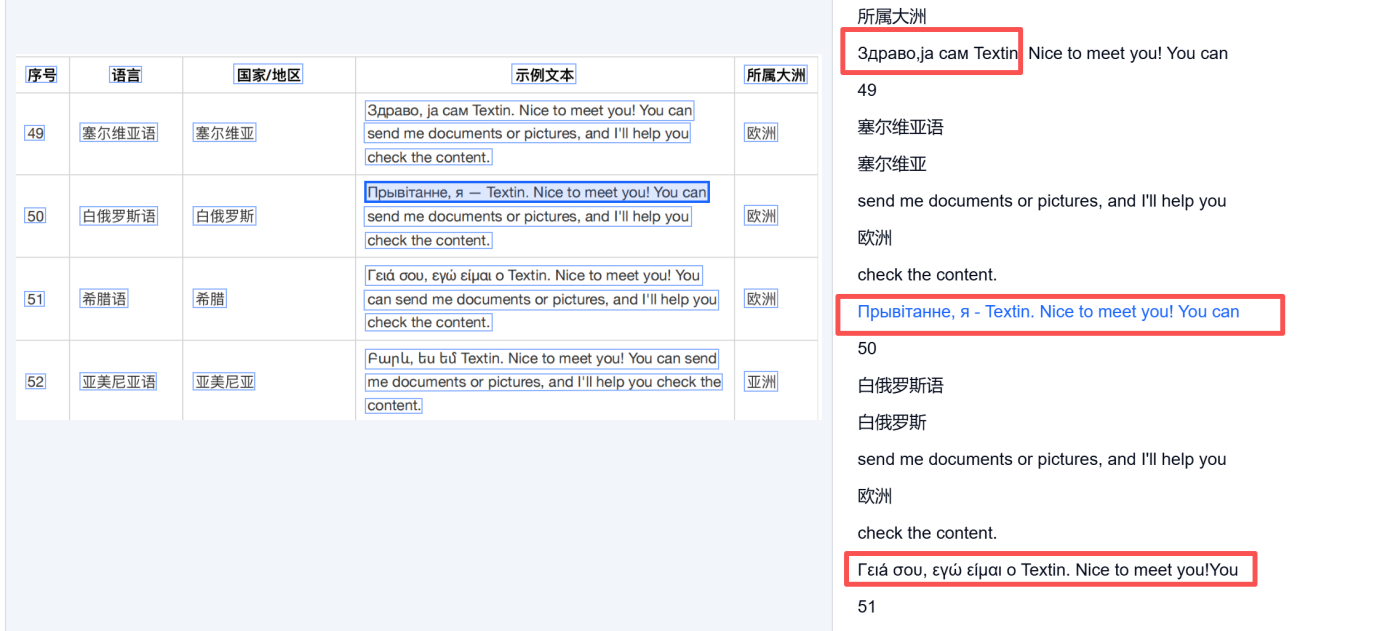
这就代表能力肯定是没有问题的了,且我测试的是靠后的几种语言。
非官方52种语言的额外语种的施压
下面的两张图片是我从孩子的书上拍的,可以看到有各种各样的语言,反正我是不认识。
但是我看了一下大致的国家都是中东那边的。


那么用TextIn来看看是否能用一些不认识的语言呢。
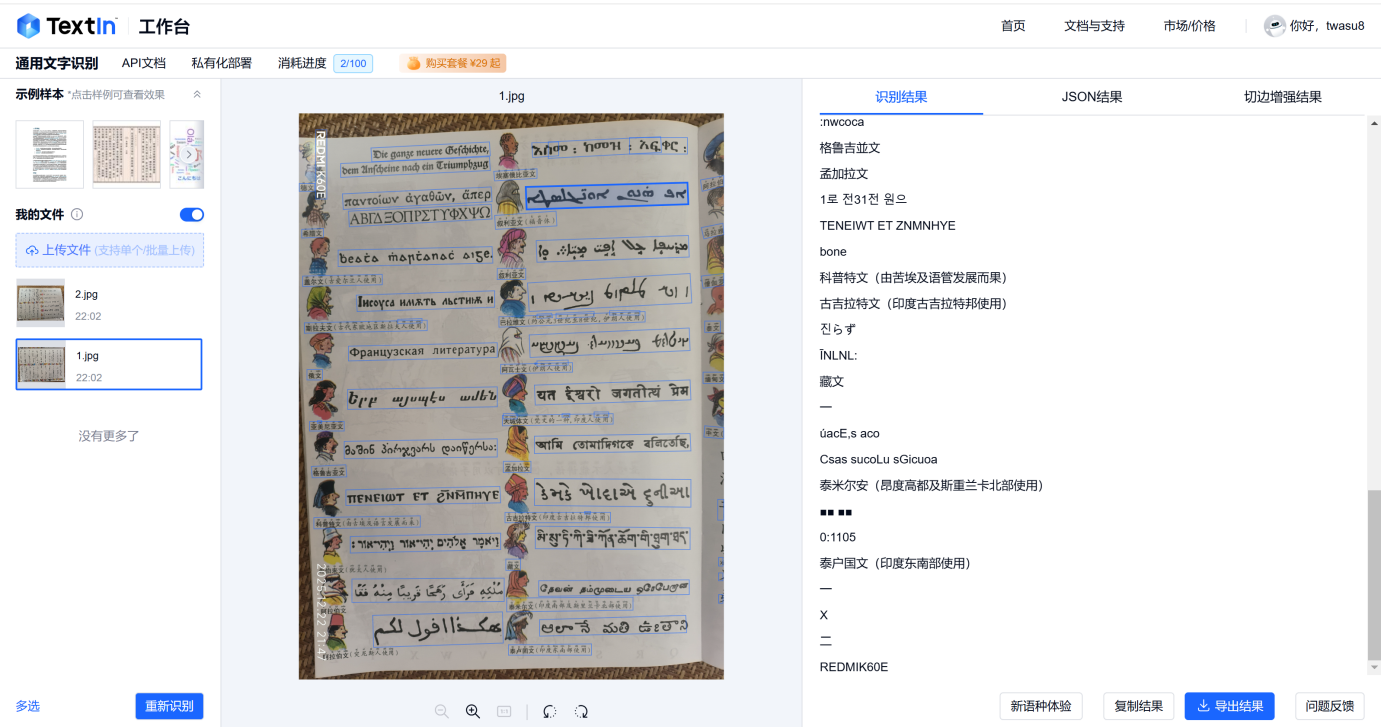
分析结果大小字都进行了识别,好多非52种支持语言的不认识的内容并没有给出对应的字符显示,然后我看到有【新语种体验】的选项,我进去试试。
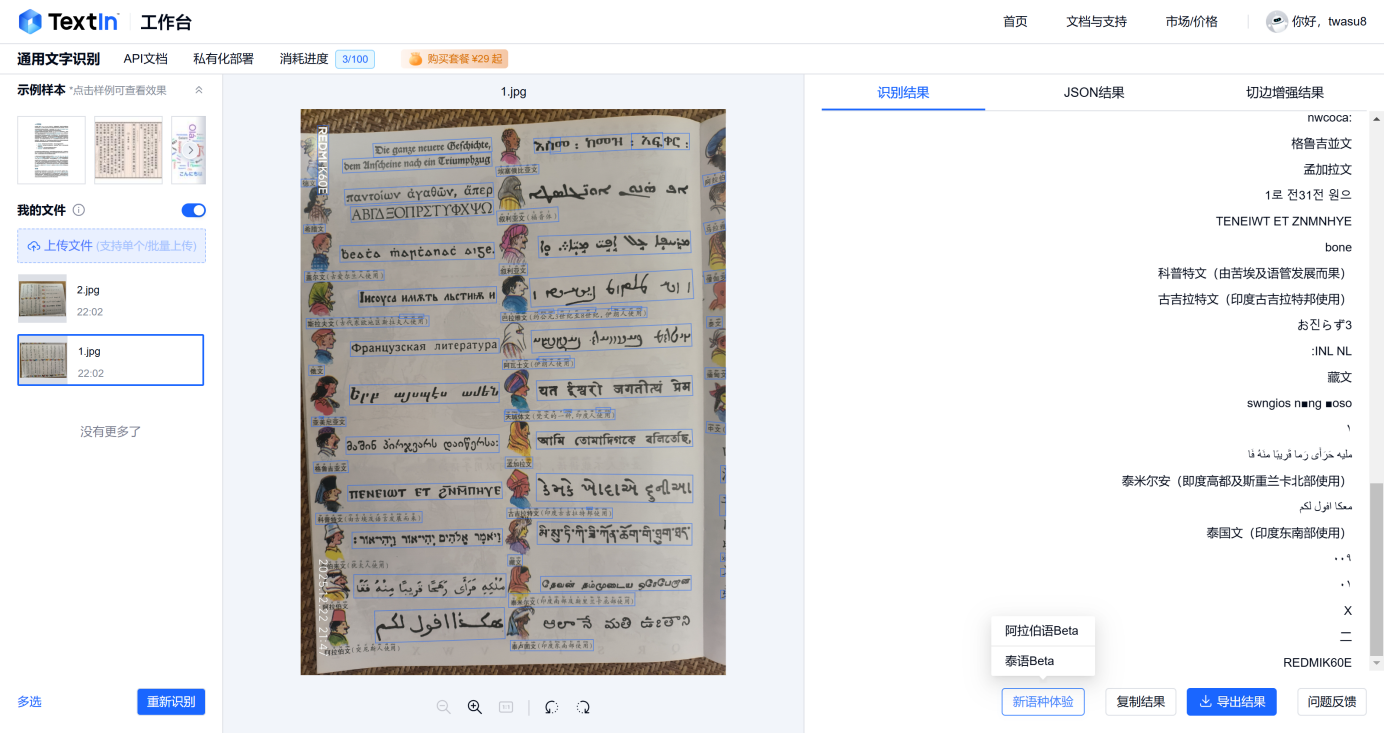
看到了有两种语言支持,不是获取所有的语言。可能是我们选择有问题,我们看看有没有其他对应的功能选项,看来没有不认识语言的识别,我们继续强行试试。
我接下来单独获取一部分文字来判断一下。

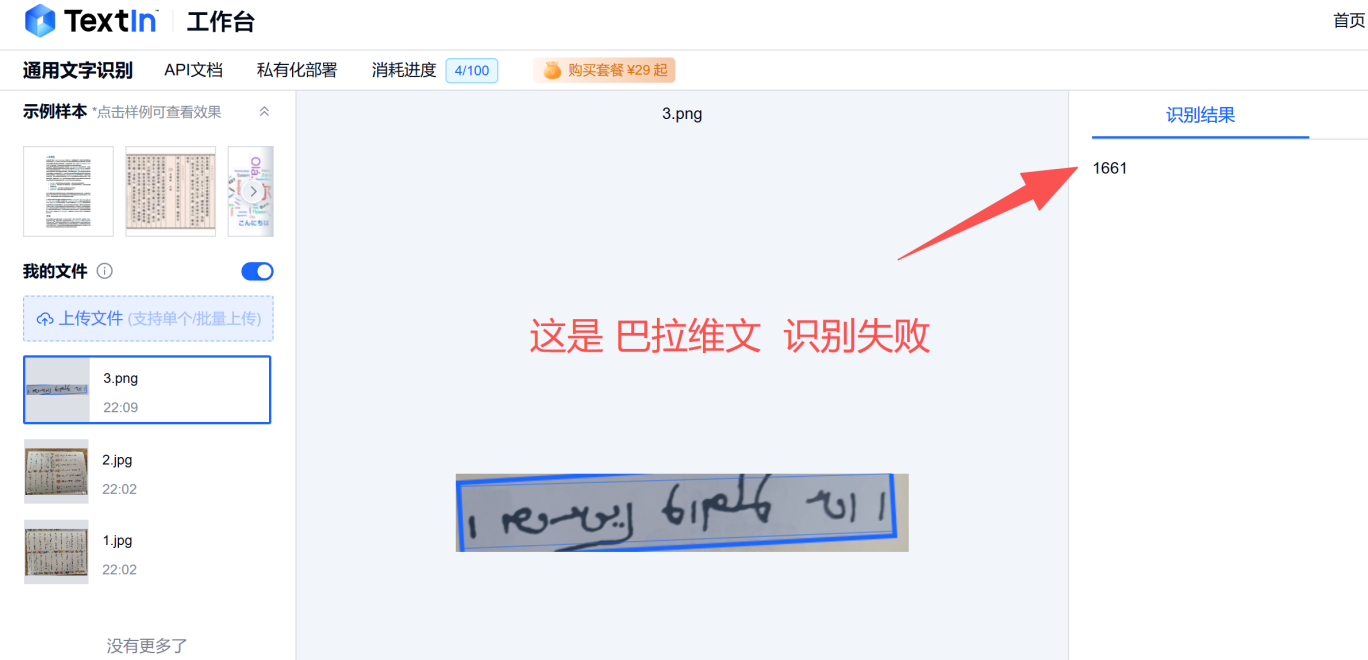
看来的确得在识别库里,其它的语种不行了。
我们再试试其它功能。

虽然没有对这些语言进行支持,可以不妨碍我提交一个工单,希望产品越做越好。
效果指标说明·文字识别深度分析
虽然没有给句具体的显示,但是我们也可以强行的深入分析一下看看。
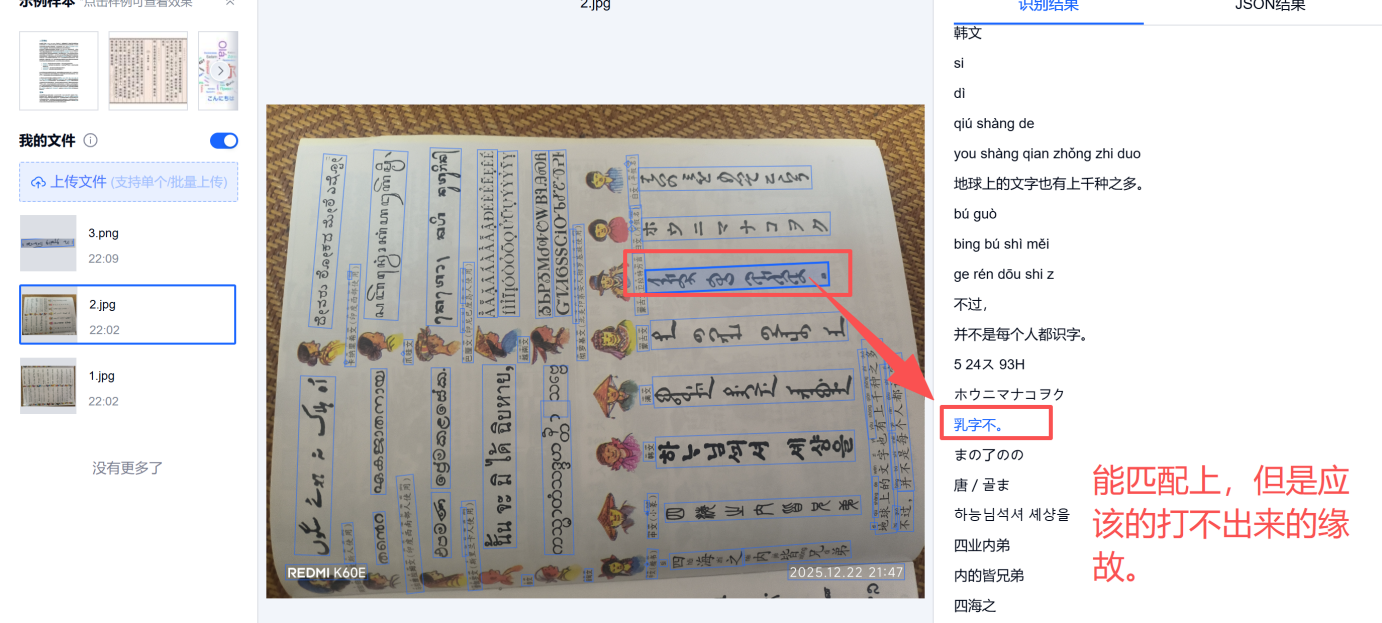
通过深入分析我了解到:
- 文字识别范围精准
- 文字进行100%读取
- 图片转文本失败由于无法正常显示对应语言的文字。
总结一下,我觉得应该是自己的问题,毕竟我电脑没有安装那么多语言包,所以想打印也无法打印出来,但是我又想,毕竟是Web返回回来的,应该在服务器上是支持这些多语种的,但是依然没有正常显示,所以我就有点凌乱了。
100%解析证据
我这里在韩语这里找到了100%解析的证据,一点没错,说明是很OK的,识别上没有任何问题,但是这里应该加上一个翻译功能,类似与使用QQ的截图功能,有一个翻译的功能,如果有这种多语言翻译的能力,这样的接口肯定超级好用啊。

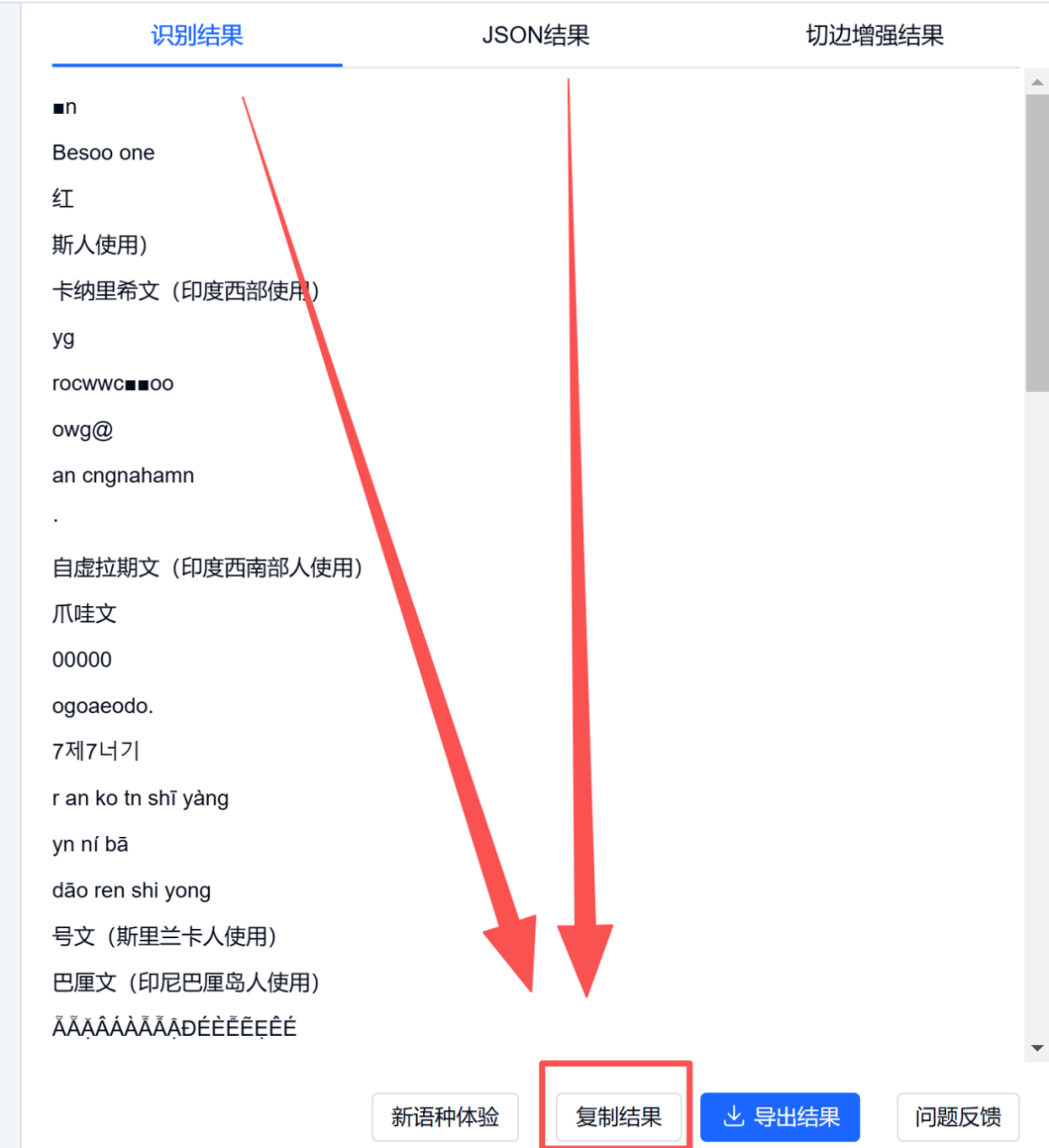
复制结果功能
效果大致如图,因为复制出来的内容是根据选择对应的返回结果来返回的,内容太多,我就不直接粘贴了,可从图片上看到。

选择方法:
总结分析
本次测评可能比较偏激,我针对的是整体的多种语言进分析,可以理解到难度超级的大,但是从整体的表现上来看,TextIn的技术团队能将所有的文本识别出来已经很强大了,对应的模型库如果是全语种文档的效果肯定会非常好,我们在效果指标说明中专门的解释了一下,并且对对应的语种进行了标注,可以清晰的看到进行了完整的解析,社会在发展,技术在迭代,相信不远的未来TextIn会支持更多的语种以及同步翻译的功能。
有想法测试一下的快来感受吧:https://www.textin.com/

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)