毕业设计:基于Spark和springboot的共享单车数据存储系统(源码)
目录
毕业设计:基于SpringBoot的学生选课管理系统(源码+文档)
毕业设计:基于学术知识图谱的检索系统(源码+二次扩展)
毕业设计:基于python+flask的动漫推荐系统(源码)
毕业设计:基于python+flask的宠物用品商城(源码)毕业设计:基于Spark和Hive的抖音大数据可视化分析(源码)
毕业设计:基于Spark和springboot的共享单车数据存储系统(源码)
毕业设计:基于vue+springboot的留守儿童管理平台(源码)
毕业设计:基于springboot+vue的智慧公交管理系统(源码)毕业设计:基于YOLO+DeepSeek行人车辆多目标检测系统(源码)
毕业设计:基于YOLO+deepseek的表情/情绪分析系统(源码)
毕业设计:基于YOLO+DeepSeek垃圾分类检测系统(源码)毕业设计:基于YOLOV8+DeepSeek苹果叶片病害检测系统(源码)
毕业设计:基于YOLO+Pytorch的海洋生物检测系统(源码)
毕业设计:基于springAi+vue的非遗数字文化馆(源码)
毕业设计:基于SpringBoot+Vue的奶茶点单系统(源码)
毕业设计:基于SpringBoot3+Vue3的电影院购票系统(源码)
一、项目背景
随着共享经济的蓬勃发展和绿色出行理念的深入人心,共享单车已成为城市公共交通体系中不可或缺的重要组成部分。截至2025年,国内主要共享单车平台累计投放车辆超过3000万辆,注册用户规模突破6亿,日均骑行订单量高达8000万次。共享单车的普及有效解决了城市出行"最后一公里"难题,在缓解交通拥堵、降低碳排放等方面发挥了积极作用。然而,共享单车的大规模运营也带来了一系列管理挑战,海量运营数据的有效存储与利用成为制约行业高质量发展的关键瓶颈。
共享单车系统每时每刻都在产生规模庞大的异构数据。用户扫码开锁、骑行轨迹、停车落锁等行为实时产生位置轨迹数据;车辆状态上报、电池电量、故障报修等形成设备运维数据;用户注册信息、骑行套餐、押金充值等构成用户账户数据。以一线城市为例,单日产生的骑行记录数据可达数千万条,位置上报数据更是数以亿计。这些数据不仅体量巨大,而且具有实时性强、时空关联度高等特点,对数据存储系统的写入性能、扩展能力和查询效率提出了极高要求。
目前,共享单车行业在数据管理方面普遍面临多重困境。传统的关系型数据库在处理海量高频写入时往往出现性能瓶颈,难以支撑千万级用户并发访问;车辆轨迹数据的时空特性需要专门的数据模型支撑,而传统存储方案无法高效处理时空查询;运营决策所需的多维度统计分析(如区域热力分布、潮汐规律分析、车辆调度优化等)依赖强大的计算能力,传统技术栈难以在合理时间内完成复杂分析任务;此外,数据孤岛现象普遍存在,运营数据、财务数据、运维数据分散存储,难以形成统一的数据视图支撑精细化运营。
在此背景下,构建一个高性能、可扩展、智能化的共享单车数据存储系统具有重要的现实意义和应用价值。Hadoop分布式文件系统和Hive数据仓库能够实现海量结构化数据的低成本可靠存储,支持通过类SQL语言进行复杂查询分析;而Spark作为新一代分布式计算引擎,凭借内存计算优势,可以高效完成海量轨迹数据的时空分析和聚合计算任务,为车辆调度、潮汐预测等业务场景提供实时数据支撑;SpringBoot作为成熟的Java企业级开发框架,能够快速构建RESTful API接口,实现业务系统与底层大数据平台的无缝对接。
本毕业设计拟基于Spark、Hive和SpringBoot构建共享单车数据存储系统,实现对车辆轨迹、用户骑行、设备状态等数据的统一采集、高效存储和智能分析。系统将重点解决海量高频数据写入的性能问题,设计适用于时空数据的存储模型,并通过数据可视化技术直观呈现共享单车的运营态势。项目的实施将为共享单车企业的精细化运营和城市慢行交通系统的优化提供有力的数据支撑。
二、技术介绍
本系统基于Hadoop大数据生态和Java企业级开发技术构建,采用分层架构设计,自下而上分为数据采集层、分布式存储层、计算处理层、业务服务层和前端展示层,各层之间通过标准接口进行数据交互,形成完整的数据存储与分析解决方案。
数据采集层采用Flume分布式日志收集系统,实时监听共享单车智能锁上报的位置数据、状态数据以及用户骑行行为日志。针对共享单车设备数量多、上报频率高的特点,配置Kafka消息队列作为数据缓冲中间件,有效应对数据洪峰,确保采集过程的高吞吐和低延迟。同时,使用Canal组件实时捕获业务数据库(MySQL)中的用户信息、订单记录等变更数据,实现业务数据与大数据平台的准实时同步。
分布式存储层以Hadoop分布式文件系统(HDFS)为核心,利用其高容错、高扩展的特性存储海量原始骑行轨迹数据和业务日志。在HDFS之上构建Hive数据仓库,将结构化数据抽象为二维表模型,并针对共享单车数据的时空特性进行优化设计:采用分区表存储策略,按日期和城市分区,显著提升查询效率;使用Parquet列式存储格式,减少I/O开销并提高数据压缩比;针对轨迹点数据设计Geohash编码索引,为后续时空查询奠定基础。此外,采用HBase作为实时查询数据库,利用其高性能随机读写能力存储最新车辆状态和实时位置信息,支撑业务系统对单点数据的快速访问。
计算处理层以Spark作为核心计算引擎,充分发挥其内存计算优势。Spark SQL用于日常ETL作业,完成数据清洗、格式转换、指标聚合等任务;Spark Streaming实现流式计算,对实时接入的车辆位置数据进行分钟级处理,计算各区域车辆热度、潮汐趋势等实时指标;Spark MLlib机器学习库应用于骑行需求预测,基于历史骑行数据训练回归模型,预测未来时段各站点的车辆供需情况,为智能调度提供决策支持。Spark与Hive无缝集成,可直接读取Hive表数据进行分布式计算,计算结果写回Hive或导出至MySQL关系数据库供业务系统调用。
业务服务层采用SpringBoot框架构建,提供RESTful API接口封装底层数据访问逻辑。整合MyBatis持久层框架操作MySQL中的业务数据和汇总结果,通过Hive JDBC接口执行复杂查询任务,利用HBase Java API实现实时位置数据的快速检索。Spring Security负责接口访问控制和用户认证,保障系统数据安全。同时集成Swagger生成在线接口文档,方便前后端协作开发。
前端展示层采用Vue.js渐进式框架结合ECharts可视化库构建管理驾驶舱,以直观的图表形式展示共享单车运营态势,包括实时车辆分布热力图、区域骑行流量排行、潮汐现象分析、车辆健康状况监控等核心指标。通过WebSocket技术实现实时数据推送,确保大屏展示数据的时效性。
任务调度与监控引入Apache Airflow实现ETL工作流的自动化编排与调度,设置每日定时任务完成数据汇总、指标计算和报表生成。采用Apache Ambari对Hadoop集群进行统一监控管理,及时发现并处理集群异常,保障系统稳定运行。整个技术架构充分发挥了Hive的存储管理能力、Spark的高性能计算能力、SpringBoot的快速开发能力以及可视化技术的交互表达能力,形成了一套完整、高效、可扩展的共享单车数据存储与分析解决方案。
三、功能介绍
本系统面向共享单车运营企业和城市交通管理部门,提供涵盖数据采集、存储、分析到可视化的全流程功能模块,助力实现精细化运营和科学化决策。
数据采集与接入功能支持多源异构数据的实时接入。系统通过Flume与Kafka集群对接智能锁设备,实时采集车辆位置上报数据、开关锁状态、电池电量等设备信息,单日可处理数亿条位置轨迹数据。同时,通过Canal组件准实时同步业务数据库中的用户信息、骑行订单、支付记录等数据,确保运营数据与大数据平台的一致性。采集模块具备数据校验和异常过滤机制,自动剔除格式错误或超出合理范围的数据,保障原始数据质量。
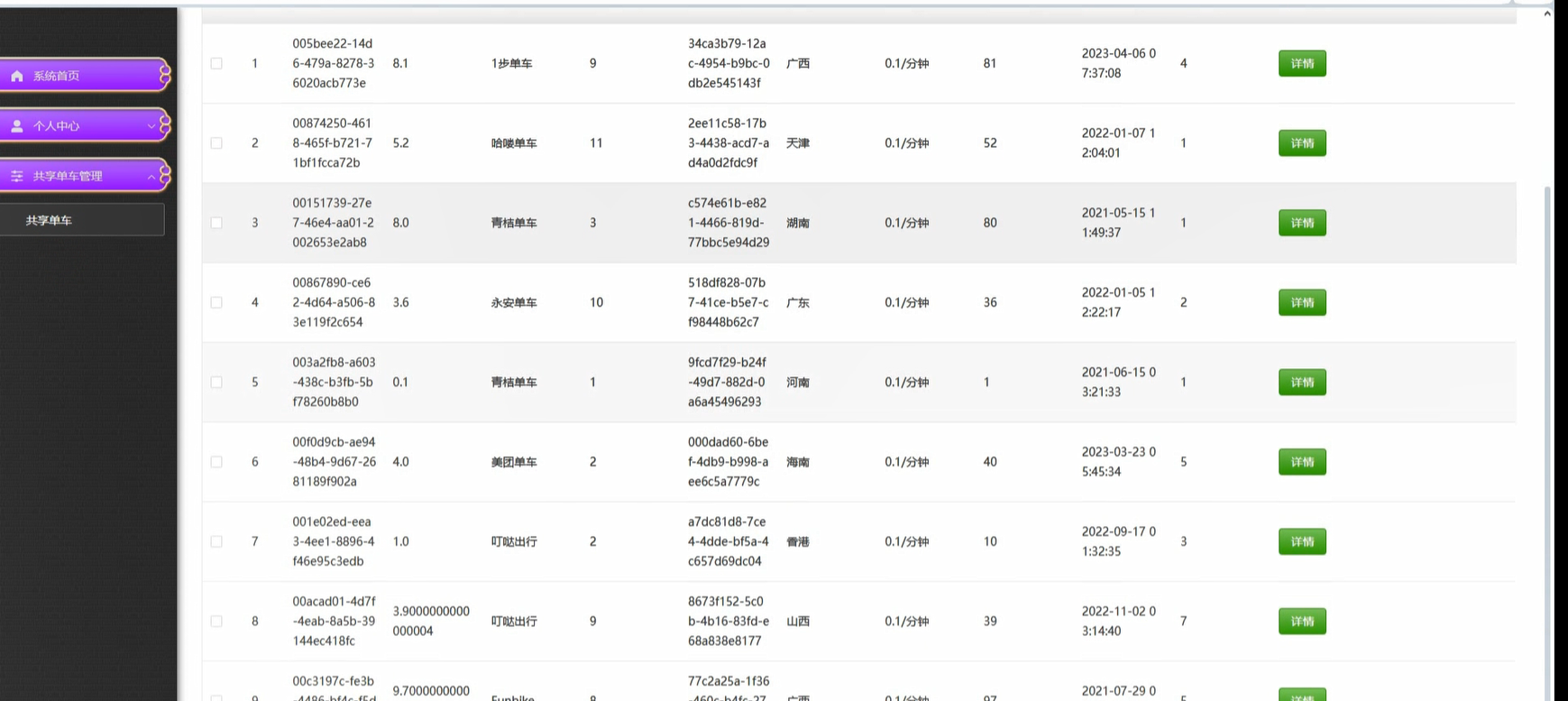
分布式存储管理功能提供高效可靠的海量数据存储能力。基于HDFS构建的存储层可容纳PB级历史数据,支持按时间、城市、车辆类型等多维度分区存储策略,降低查询扫描范围。Hive数据仓库将原始数据抽象为事实表和维度表,包括骑行事实表、车辆维度表、用户维度表、区域维度表等,形成规范的星型模型,为多维分析奠定基础。针对实时查询场景,HBase中维护最新车辆状态和实时位置快照,支持毫秒级单点查询和范围扫描。
数据ETL与清洗功能自动完成原始数据的加工处理。每日定时执行的Spark作业对采集的原始数据进行空值填充、异常值剔除、格式规范化等清洗操作,计算骑行时长、骑行距离、消耗卡路里等衍生指标,并将处理后的数据加载至HIVE分析层。针对轨迹数据,采用地图匹配算法将GPS点序列匹配至实际道路,修正漂移点,生成标准的骑行路径信息。
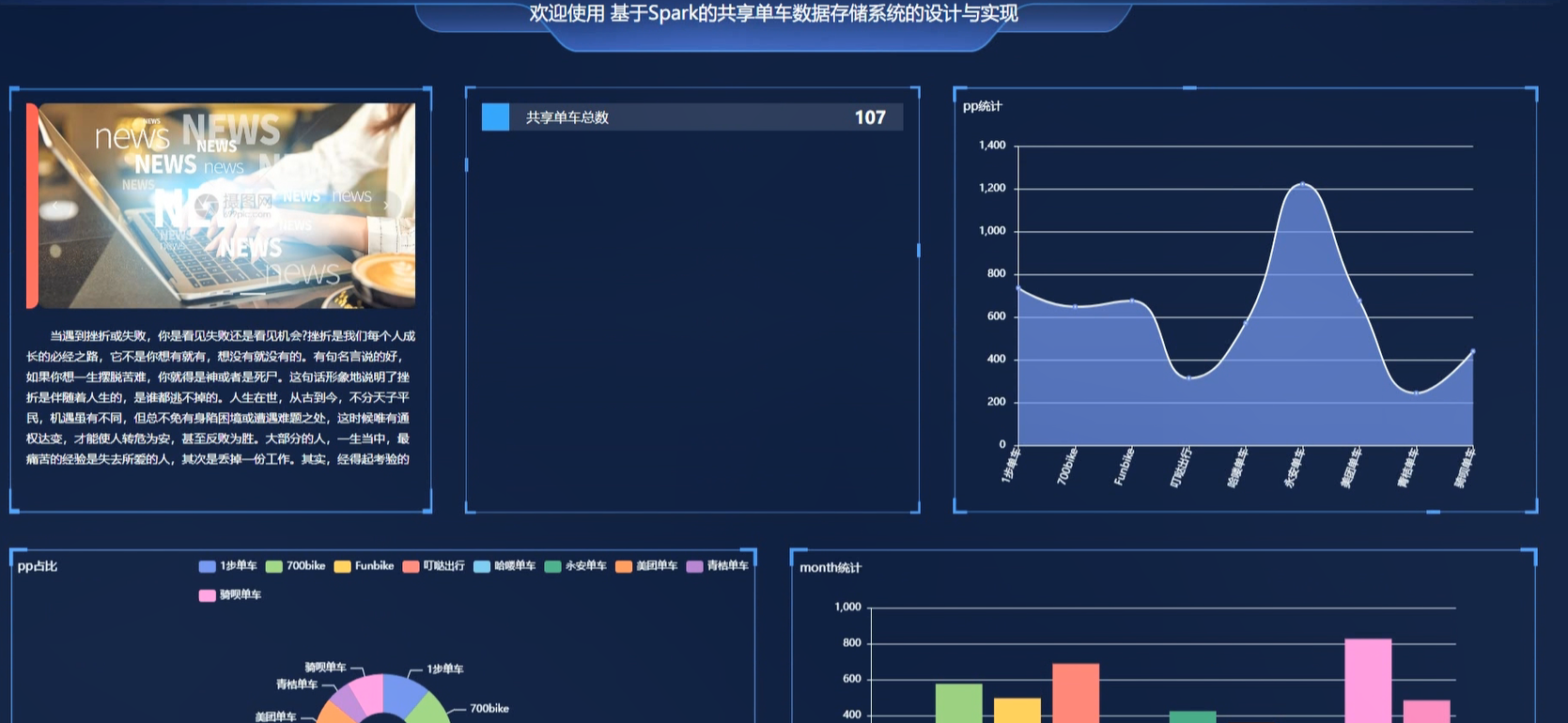
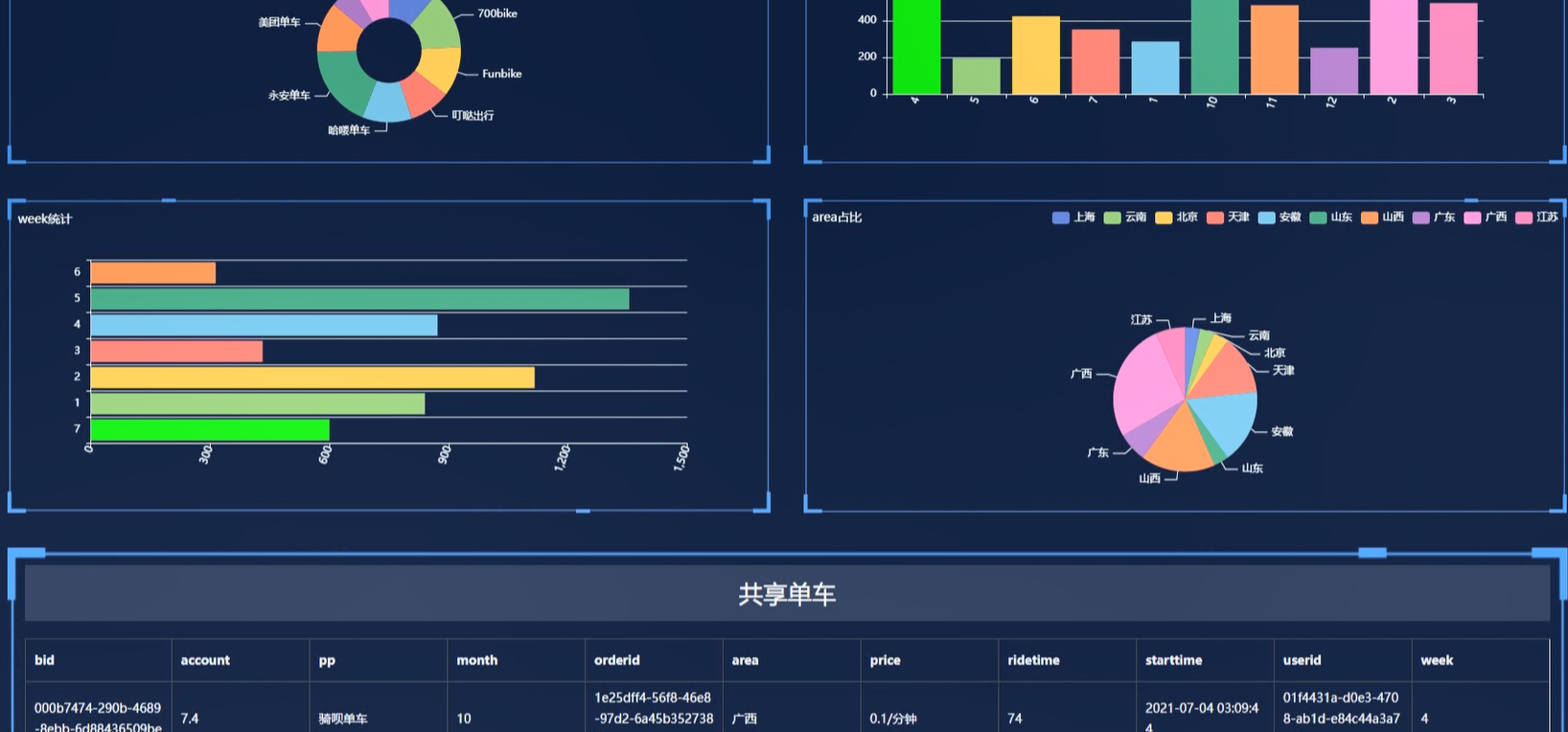
多维度统计分析功能支持从时间、空间、用户、车辆等多个维度对共享单车运营状况进行深度洞察。时间维度分析包括分时段骑行量统计、高峰时段识别、季节性规律分析;空间维度分析涵盖区域骑行热力分布、潮汐现象量化、站点借还平衡度评估;用户维度分析涉及用户骑行频次分级、骑行偏好挖掘、用户流失预警;车辆维度分析包括车辆周转率计算、故障率统计、车辆生命周期分析。所有分析结果以汇总表形式存储在Hive或MySQL中,供可视化调用。
实时监控与预警功能基于Spark Streaming流计算引擎,对实时接入的数据进行秒级处理,动态监测各区域车辆存量、异常滞留、低电量车辆分布等关键指标。当区域车辆数低于阈值或出现大量淤积时,系统自动触发预警,通过短信或APP推送通知运维人员及时调度。同时,对车辆故障报警信息进行实时分析,智能派发维修工单,提升运维响应效率。
智能预测与辅助决策功能应用Spark MLlib机器学习算法,基于历史骑行数据训练预测模型,实现未来时段各站点或区域的借还需求预测。系统结合天气数据、节假日信息、历史规律等因素,生成未来24小时各区域供需热力图,为车辆调度提供前瞻性指导。此外,通过聚类算法识别热门骑行路线和常发拥堵点,为城市慢行交通规划提供数据支撑。
可视化驾驶舱功能以直观的图表形式呈现共享单车运营全貌。大屏展示界面集成实时车辆分布地图、区域热度排行榜、潮汐现象动态演示、车辆健康状况仪表盘等核心模块。支持多级下钻分析,管理者可点击任意区域查看详细运营指标,对比不同行政区、街道的运营差异。历史趋势对比功能支持自定义时间段查询,直观展示运营指标的变化规律。
系统管理与权限控制功能提供完善的用户管理和安全机制。管理员可通过后台管理系统配置数据采集任务、管理ETL作业调度、查看集群运行状态。基于角色的权限控制确保不同级别的用户只能访问授权的数据模块,保障运营数据的安全性。操作日志记录所有关键操作行为,满足审计需求。
四、系统实现

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)