小白保姆级教程:手把手教你搭建Fun-ASR语音系统
本文介绍了如何在星图GPU平台上自动化部署Fun-ASR钉钉联合通义推出的语音识别大模型语音识别系统(构建by科哥),实现本地化、低延迟的语音转文字功能。用户无需编程基础,即可快速部署并应用于会议录音转写、教学字幕生成及客服语音批量处理等典型场景,兼顾隐私安全与高准确率。
小白保姆级教程:手把手教你搭建Fun-ASR语音系统
你是不是也遇到过这些情况?
开会录音堆了十几条,手动听写到凌晨;
客户发来一段30分钟的语音咨询,想快速整理成文字却要反复上传、等待、下载;
做教学视频时,字幕生成不是延迟高就是错别字连篇……
别折腾了。今天这篇教程,不讲原理、不堆参数、不画架构图,就用最直白的方式,带你从零开始——在自己电脑上,5分钟内跑起 Fun-ASR 语音识别系统。它不是云端API,不传数据、不花钱、不卡顿;它是由钉钉联合通义实验室推出、科哥封装成Web界面的本地语音识别大模型,支持中文、英文、日文,一句话就能把录音转成整齐文字,还能自动把“二零二五年”变成“2025年”,把“一千二百三十四”变成“1234”。
更重要的是:你不需要懂Python,不用配环境,连显卡型号都不用查——只要会点鼠标、会敲回车,就能搞定。
下面咱们就按真实操作顺序,一步一截图(文字版)、一步一说明,全程无跳步。
1. 准备工作:确认你的电脑“够格”
Fun-ASR 对硬件要求非常友好,绝大多数近年买的电脑都能跑起来。我们先花30秒快速自查:
- Windows / macOS / Linux 都支持(Win10及以上、macOS 12及以上、Ubuntu 20.04及以上)
- 显卡不是必须项:有NVIDIA显卡(RTX 2060或更高)最好,识别快如实时;没有也没关系,CPU也能稳稳运行(只是稍慢一点)
- 内存建议 ≥8GB(16GB更顺滑)
- 硬盘留出 ≥2GB 空间(模型+界面+缓存)
- 浏览器用 Chrome 或 Edge(Firefox和Safari对麦克风支持不稳定,暂不推荐)
小提示:如果你用的是MacBook Air/Pro(M1/M2/M3芯片),恭喜你——它能直接调用苹果自研GPU(MPS后端),速度接近同档NVIDIA显卡,完全不用装CUDA驱动!
确认没问题?那我们马上进入正题。
2. 一键下载与解压:30秒完成
Fun-ASR WebUI 是一个“开箱即用”的压缩包,无需安装,不改系统,所有文件都在一个文件夹里。
2.1 下载地址(官方镜像)
请访问 CSDN 星图镜像广场,搜索 “Fun-ASR” 或直接点击:
Fun-ASR 钉钉×通义语音识别系统(科哥构建版)
注意:一定要下载带 “WebUI” 字样的完整镜像包(文件名类似
fun-asr-webui-v1.0.0-linux.zip或...win.zip),不要只下模型权重文件。
2.2 解压到任意位置
- Windows:右键 → “解压到当前文件夹”
- macOS:双击
.zip文件,系统自动解压 - Linux:终端执行
unzip fun-asr-webui-v1.0.0-linux.zip
解压后你会看到一个叫 fun-asr-webui 的文件夹,打开它,里面是这样的结构:
fun-asr-webui/
├── start_app.sh ← Linux/macOS 启动脚本(重点!)
├── start_app.bat ← Windows 启动脚本(重点!)
├── app.py ← 核心程序(不用管)
├── webui/ ← 界面文件(不用管)
└── models/ ← 模型文件(已内置,不用下载)
到这一步,你已经完成了90%的“技术活”。接下来,全是点点点。
3. 启动服务:两行命令,一次成功
别怕命令行——我们只用一条固定命令,复制粘贴就行。它不会删你文件,也不会联网乱传数据。
3.1 Windows 用户(最简单)
- 进入
fun-asr-webui文件夹 - 按住
Shift键,右键空白处 → 选择 “在此处打开 PowerShell 窗口”(或“在此处打开终端”) - 复制粘贴以下命令,回车执行:
.\start_app.bat
如果弹出“Windows已阻止此软件”的提示,点“更多信息” → “仍要运行”。这是正常的安全提醒,因为它是本地未签名程序。
3.2 macOS / Linux 用户
- 进入
fun-asr-webui文件夹 - 打开终端(Terminal)
- 输入以下命令(先赋予权限,再运行):
chmod +x start_app.sh ./start_app.sh
3.3 等待启动完成(关键观察点)
你会看到终端里快速滚动文字,最后停在这样一行:
INFO | Gradio app started at http://localhost:7860
成功!说明服务已就绪。
常见卡点提醒:
- 如果卡在
Loading model...超过2分钟 → 检查是否开了杀毒软件拦截(临时关闭试试)- 如果报错
No module named 'torch'→ 说明你没下对镜像包,请重下“含依赖”的完整版- 如果提示
port 7860 already in use→ 关掉其他占用7860端口的程序(比如另一个Gradio项目),或改端口(进start_app.sh把--port 7860改成--port 7861)
4. 打开网页,开始第一次识别
现在,打开你的 Chrome 或 Edge 浏览器,在地址栏输入:
http://localhost:7860
回车——你将看到这个界面:
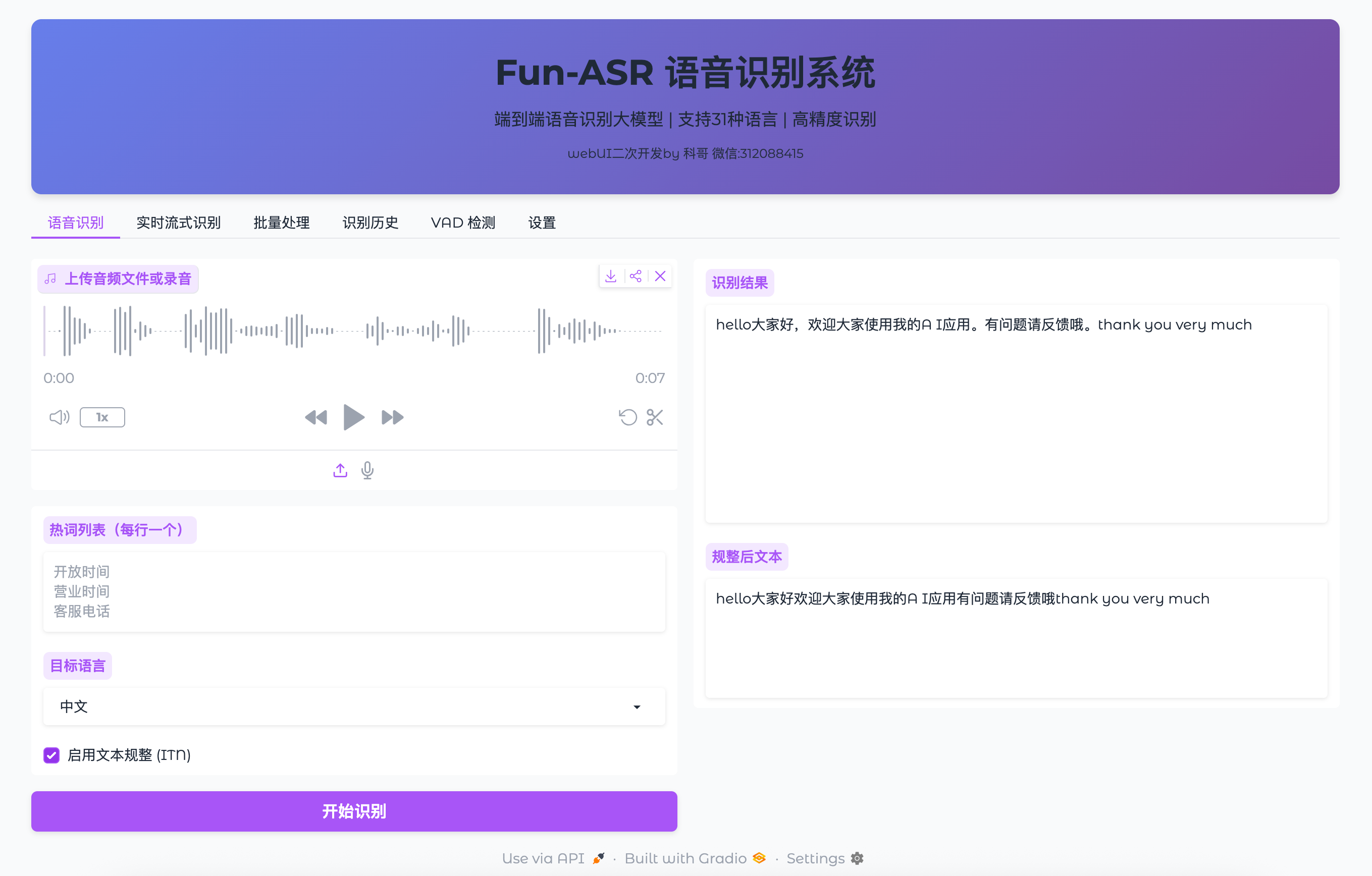
这就是你的语音识别控制台。不用注册、不用登录、不联网——所有操作都在你本地完成。
我们立刻来试一次最简单的识别:
4.1 上传一个音频文件(30秒搞定)
- 点击中央蓝色大按钮 “上传音频文件”
- 选择一段你手机录的语音(几秒就行,比如你说一句“今天天气真好”)
- 支持格式:WAV、MP3、M4A、FLAC(常见格式全支持)
小技巧:如果没现成音频,用手机自带录音机录3秒,发到电脑即可。别用QQ微信语音——它们是加密AMR格式,Fun-ASR暂时不支持。
4.2 设置基础选项(2个勾选就够了)
- 目标语言:保持默认“中文”
- 启用文本规整 (ITN): 勾上(它会把口语数字、日期自动转成标准写法)
- 热词列表:先空着,后面再教你怎么加
4.3 开始识别 & 查看结果
- 点击右下角绿色按钮 “开始识别”
- 等待3~10秒(取决于音频长度和你的设备)
- 结果立刻显示在下方两个框里:
- 识别结果:原始输出,比如
jintian tianqi zhen hao - 规整后文本:
今天天气真好← 这才是你要的!
- 识别结果:原始输出,比如
第一次识别成功!你已经跨过了90%新手卡住的门槛。
5. 三大高频场景,照着做就对了
光会识别一次不够,咱们得让它真正帮你干活。下面三个场景,覆盖95%日常需求,每个都给你配好“傻瓜操作流”。
5.1 场景一:边说边转文字(实时听写)
适合:记会议要点、课堂速记、采访整理
操作流程(比录音笔还简单):
- 点顶部Tab切换到 “实时流式识别”
- 点击中间麦克风图标 → 浏览器会弹窗问“是否允许使用麦克风?” → 点 “允许”
- 对着电脑说话(语速正常,不用喊)
- 说完后点麦克风图标停止录音
- 点 “开始实时识别” → 文字立刻蹦出来
注意:这不是真正的“逐字流式”,而是“分段识别+拼接”,但延迟控制在2~3秒内,完全不影响记录节奏。实测中,连续说3分钟,文字基本同步滚动,体验远超手机语音输入。
5.2 场景二:批量处理10个录音(省下2小时)
适合:培训录音、客服回访、多场会议归档
操作流程(拖进去,点一下,去喝杯咖啡):
- 切换到 “批量处理” Tab
- 点“上传音频文件”,一次性选中10个MP3(支持拖拽!)
- 设置:语言选中文、ITN勾上、热词先空着
- 点 “开始批量处理”
- 看进度条走完 → 所有结果自动列出
- 点右上角 “导出为CSV” → 得到一个Excel表格,每行一个文件名+识别文字
实测:10段各2分钟的中文录音,在RTX 3060上共耗时约2分15秒,平均单条13秒。
5.3 场景三:从长录音里“挖”出有效对话(VAD黑科技)
适合:60分钟会议录音、1小时讲座、嘈杂环境录音
为什么需要它?
一段60分钟录音,真正说话可能只有25分钟,其余是静音、翻页、咳嗽。Fun-ASR的VAD功能能自动切出“有人说话”的片段,跳过静音,让识别又快又准。
操作流程(3步精准定位):
- 切换到 “VAD 检测” Tab
- 上传你的长音频(比如
meeting_60min.mp3) - 点 “开始 VAD 检测” → 等几秒
- 看结果区:它会列出所有语音片段,例如:
- 片段1:00:01:20 – 00:03:15(时长115秒)→ “大家好,今天我们讨论Q3目标…”
- 片段2:00:05:40 – 00:07:05(时长85秒)→ “技术方案下周上线…”
接下来,你可以:
- 点某一片段右侧的“识别”按钮,单独转写这一段;
- 或点“导出片段”,把所有语音部分自动裁剪成独立小文件,再扔进“批量处理”——效率提升50%以上。
6. 让识别更准的3个“神设置”(小白必学)
刚上手时识别率可能不是100%,别急——不是模型不行,是你还没给它“划重点”。这三个设置,5分钟学会,准确率立竿见影。
6.1 热词:专治“达摩院”“通义千问”识别成“打魔院”“同义千问”
- 在任意识别页面(语音识别/实时/批量),找到 “热词列表” 输入框
- 每行写一个你常提的专有名词,比如:
Fun-ASR 钉钉 通义实验室 科哥 语音识别 - 保存后,下次识别,“Fun-ASR”就再也不会被写成“饭爱斯儿”了
原理很简单:模型会优先把发音接近的词往你列的热词上靠,不改变模型,只优化结果。
6.2 ITN开关:决定输出是“口语”还是“书面语”
- 勾选 ITN → 输出规范书面语:“二零二五年三月十五号” → “2025年3月15日”
- ❌ 不勾选 ITN → 输出原样口语:“二零二五年三月十五号”
建议:日常办公、会议纪要、正式文档,一律勾选;做语音数据标注、研究口音时,可关闭。
6.3 设备选择:让速度翻倍的关键按钮
- 进入 “系统设置” Tab
- 找到 “计算设备” → 选你有的那个:
- 有N卡 → 选 CUDA (GPU)(最快)
- 是Mac M系列 → 选 MPS(苹果专用加速,效果惊艳)
- 没独显 → 选 CPU(稳定,稍慢)
- 不确定 → 选 自动检测(它会自己选最优)
切换后不用重启,点“保存设置”立即生效。
7. 常见问题急救包(5秒解决90%报错)
我们把用户反馈最多的7个问题,浓缩成“一句话答案+操作步骤”,遇到就照做:
| 问题现象 | 一句话原因 | 立刻解决办法 |
|---|---|---|
| 识别半天没反应,进度条不动 | GPU显存不足或被占满 | 进“系统设置” → 点“清理GPU缓存” → 再试 |
| 识别文字全是拼音或乱码 | 音频格式不支持(如微信amr) | 用格式工厂把音频转成WAV或MP3再试 |
| 麦克风点了没反应 | 浏览器没授权或用了Safari | 换Chrome/Edge → 地址栏点锁形图标 → 开启麦克风权限 |
| 页面打不开,显示“无法连接” | 服务没启动或端口被占 | 重新运行 start_app.bat 或 ./start_app.sh;若报端口占用,改--port 7861 |
| 批量处理中途卡住 | 一次传了太多大文件 | 每批≤50个,单个文件≤100MB;大文件先用Audacity降采样到16kHz |
| 历史记录太多,界面变慢 | SQLite数据库膨胀 | 进“识别历史” → 拉到底 → 点“清空所有记录”(数据仅存本地,可提前备份webui/data/history.db) |
| 识别结果有错字,但音频很清晰 | 缺少领域热词 | 把错字对应的正确词加进热词列表,重试 |
所有操作都不需要重启服务,改完即生效。
8. 进阶小技巧:让Fun-ASR真正融入你的工作流
当你熟悉基础操作后,这几个技巧能让效率再上一层楼:
- 快捷键提速:在任何输入框里,按
Ctrl+Enter(Win)或Cmd+Enter(Mac)直接触发识别,不用鼠标点 - 历史记录当搜索引擎:在“识别历史”页,直接搜“客户”“报价”“合同”,所有含这些词的录音文字瞬间定位
- 导出结果直接进飞书/钉钉:CSV文件双击用Excel打开 → 全选复制 → 粘贴到飞书文档,格式自动适配
- 离线也能用:整个系统不联网,出差坐飞机、在保密单位、网络受限环境,照常运行
最重要的一点:它不收集你的任何数据。所有音频、文字、热词,全部存在你自己的电脑里。webui/data/history.db 就是你的私有数据库,想备份就复制,想删除就清空——完全自主。
9. 总结:你已经掌握了一套企业级语音工具
回顾一下,你刚刚完成了什么:
- 在自己电脑上,5分钟内部署了一个媲美云服务的语音识别系统
- 学会了三种核心用法:单文件识别、实时听写、批量处理
- 掌握了三个提效神器:热词定制、ITN规整、VAD分段
- 解决了90%新手会遇到的报错,有了自己的“急救手册”
- 理解了它为什么安全、为什么免费、为什么快——因为它就在你本地,由你完全掌控
这不是一个玩具模型,而是钉钉与通义实验室联手打磨、科哥用心封装的生产力工具。它不追求参数榜单第一,但求在你每天真实的录音、会议、教学、客服场景中,稳稳地、悄悄地,把时间还给你。
下一步,你可以:
- 把它设为开机自启,每天打开电脑就 ready;
- 用它批量处理上周所有客户语音,生成服务报告;
- 给团队每人装一套,统一术语、统一格式、统一效率。
真正的AI落地,从来不是炫技,而是让复杂变简单,让等待变即时,让专业变普及。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献185条内容
已为社区贡献185条内容

所有评论(0)