【JchatMind智能体 | 第七天】引入知识库与 RAG
本文介绍了基于Agent视角的RAG(检索增强生成)技术实现。主要内容包括:1)RAG在Agent系统中的定位,将其视为普通工具而非特殊模式;2)知识库构建与检索两条主线,包括文档拆分、向量生成和存储入库流程;3)采用Markdown章节标题作为拆分单元的设计考量;4)仅对标题生成Embedding而非全文的优化策略;5)相似度搜索的核心实现逻辑。文章强调RAG作为系统能力,通过PostgreSQ
前言
本项目非原创,我也是作为一名初学者跟着一起学习。项目来源于:代码随想录-知识星球。
在知识星球里看到卡哥分享这个项目 ,感觉还不错,于是想要学习一下这个项目怎么写。项目日记也会同步更新。(本人不分享本项目源码,支持项目付费)
本文由我学习该项目并结合AI整理总结而来,分享出来学习过程中的心得体会,由浅入深,用于日后的回顾,同时也希望能给你带来帮助。
目录
KnowledgeTool:RAG 在 Agent 世界的入口
【JchatMind智能体 | 第六天】Agent Loop 的第一次落地![]() https://blog.csdn.net/h52412224/article/details/159246781?spm=1001.2014.3001.5502【JchatMind智能体 | 第五天】实现带记忆的聊天功能
https://blog.csdn.net/h52412224/article/details/159246781?spm=1001.2014.3001.5502【JchatMind智能体 | 第五天】实现带记忆的聊天功能![]() https://blog.csdn.net/h52412224/article/details/159158927【JchatMind智能体 | 第四天】Spring AI 集成与多模型支持
https://blog.csdn.net/h52412224/article/details/159158927【JchatMind智能体 | 第四天】Spring AI 集成与多模型支持![]() https://blog.csdn.net/h52412224/article/details/159078281
https://blog.csdn.net/h52412224/article/details/159078281
前面我们用 JChatMindV1 和 V2 版本,已经实现了工具调用和 Agent Loop 这些核心功能。但在实际开发中,很快会遇到一个新问题:很多任务需要的不是实时数据,而是系统内部的专属知识,比如项目文档、业务规则、数据库结构说明等。
这些信息既不适合写死在提示词里,也不可能指望模型凭记忆猜对,它们更像是只属于当前系统的说明书。RAG 检索增强生成的作用,正是在这里体现出来的。
之前我们提到过,RAG 不是模型能力,而是系统能力。模型本身并不会学会你的文档,它只是被系统在合适的时机,提供了一小段与当前问题最相关的背景信息。
所以在 JChatMind 中,我们没有把 RAG 设计成特殊的模型模式,而是把它当成一个普通工具。在 Agent 的世界里,RAG 和查天气、查日期没有本质区别:
-
都是模型发现自己不知道答案
-
都是通过工具向系统请求信息
-
都是拿到结果后继续推理
Agent 视角下的 RAG 调用
从 Agent 的角度看,一次完整的 RAG 流程是这样的:
用户提出问题
↓
Agent 判断:我是否需要查阅知识库?
↓
Agent 调用 KnowledgeTool
↓
系统执行向量检索
↓
返回相关文档内容
↓
Agent 基于内容生成最终回答对 Agent 来说,它最关心的就是现在缺的背景信息是什么。
知识库与 RAG 的两条主线
本章内容可以分成两条清晰的主线:把内容放进知识库,以及从知识库中搜索内容。
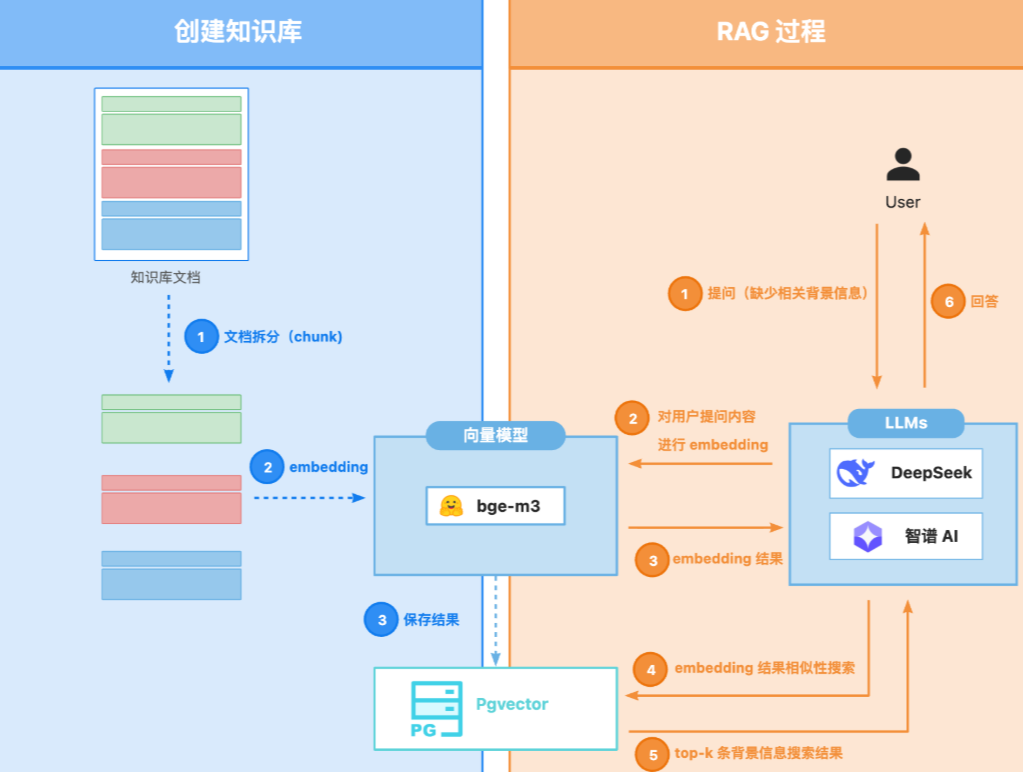
将内容放入知识库
-
文档拆分:先把完整的文档拆分成一个个语义完整的小片段,也就是 chunk。
-
生成向量:对每个 chunk 的标题进行 embedding,用向量模型转成 1024 维的向量。
-
存储入库:把向量和对应的文本内容,一起存入 PostgreSQL + pgvector 中。
这样,知识库就构建完成了。模型本身并没有记住这些知识,但系统已经具备了随用随取的能力。
从知识库查询内容
-
用户提问:用户提出一个需要背景知识的问题。
-
问题向量化:对用户的问题进行 embedding,生成向量。
-
相似度检索:用问题向量在向量数据库中搜索最相关的 Top-K 个 chunk。
-
生成回答:把检索到的内容作为补充上下文,和用户问题一起发给大模型,让模型生成最终回答。
这一步的本质是:RAG 负责找对信息,AI 负责说清楚信息。
为什么文档必须拆分
不要一上来就做 embedding,先把文档结构搞清楚。
在真实系统中,知识库往往由完整文档组成。如果直接把整篇文档交给模型,会立刻遇到几个问题:
-
文档可能很长,超过模型的上下文限制
-
每次问题只和其中很小一部分相关
-
token 成本和干扰信息都不可控
因此,第一步必须是拆文档。拆分的方式有很多,比如按段落、按固定长度等。在 JChatMind 中,我们采用了一种比较稳定的方法:按 Markdown 的章节标题拆分。
每一个一级或二级标题,对应一个可被独立检索的语义单元。比如下面这个电商系统数据库设计文档的片段:
# 电商系统(eshop)数据库设计文档(PostgreSQL)
| `t_order_header` | 订单主表 |
| `t_order_item` | 订单明细 |
| `t_payment` | 支付记录 |
| `t_shipment` | 发货记录 |
| `t_comment_topic` | 评论话题定义(“物流”、“质量”等) |
| `t_comment` | **评论表,核心分析对象** |
| `t_comment_topic_mapping` | 评论-话题关联表(多对多) |
| `t_comment_summary_daily` | 评论日汇总表,用于加速统计 |
| `t_system_kv` | 系统配置 / 开关表 |
---
## 3. 表结构设计(分表说明 + DDL)
### 3.1 用户表 `t_app_user`
**用途**:
存储系统用户(买家、卖家、运营、客服等)的基础信息。
**字段要点**:
* `id`: 用户主键 UUID
* `email`: 登录邮箱,唯一
* `phone`: 手机号
* `display_name`: 显示昵称
* `status`: 用户状态(active / blocked / deleted)
* `metadata`: 扩展信息(渠道、终端等)
```sql
CREATE TABLE t_app_user (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) UNIQUE NOT NULL,
phone VARCHAR(32),
display_name VARCHAR(128) NOT NULL,
password_hash VARCHAR(255) NOT NULL,
status VARCHAR(32) NOT NULL DEFAULT 'active', -- active / blocked / deleted
metadata JSONB,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
COMMENT ON TABLE t_app_user IS '用户表:存储系统用户的基础信息';
COMMENT ON COLUMN t_app_user.email IS '登录邮箱,唯一';
COMMENT ON COLUMN t_app_user.display_name IS '用户显示昵称';
COMMENT ON COLUMN t_app_user.status IS '用户状态:active / blocked / deleted';
```
### 3.2 角色表 `t_role`
**用途**:
定义系统角色,如管理员、客服、运营等。
```sql
CREATE TABLE t_role (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
code VARCHAR(64) UNIQUE NOT NULL,
name VARCHAR(128) NOT NULL,
description TEXT,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
COMMENT ON TABLE t_role IS '角色表:定义系统中的角色(管理员、客服等)';
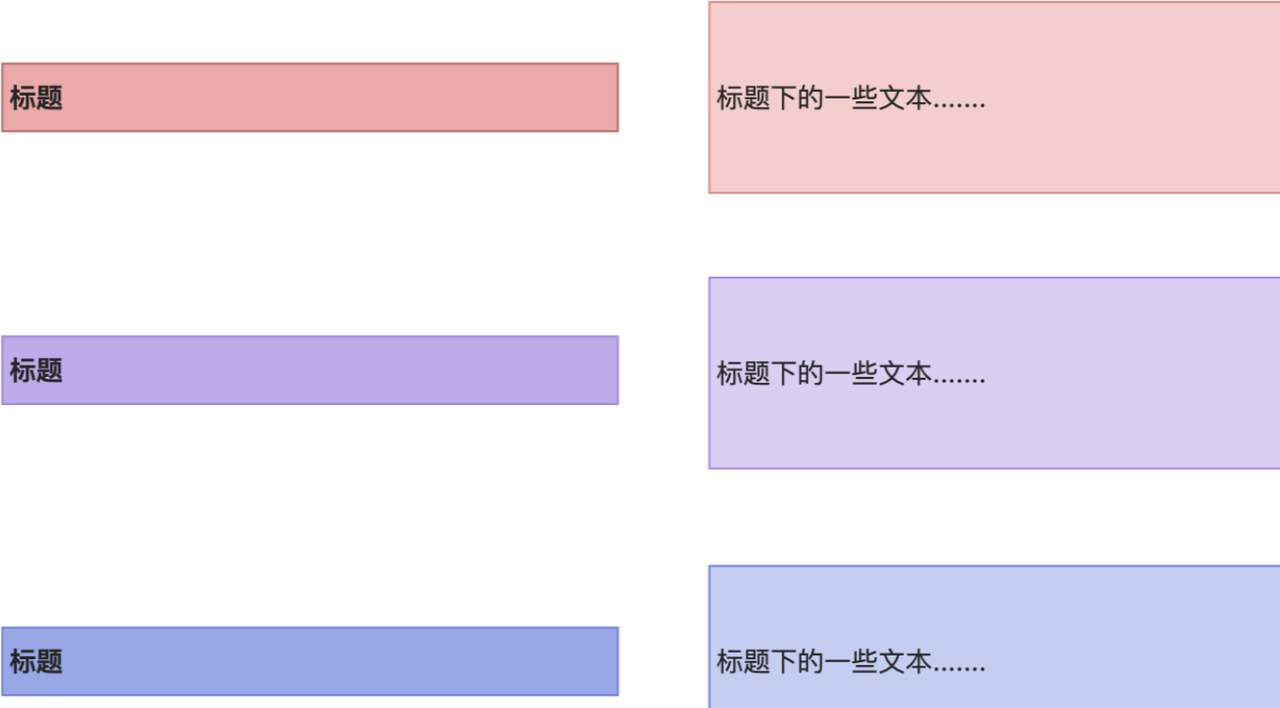
```像这样的文档格式一般如下:

每篇文档都可以被拆分一块块的内容,每一块又分为两个部分:标题和内容。
就像下面这个示例一样。
### 3.1 用户表 `t_app_user`
**用途**:
存储系统用户(买家、卖家、运营、客服等)的基础信息。
**字段要点**:
* `id`: 用户主键 UUID
* `email`: 登录邮箱,唯一
* `phone`: 手机号
* `display_name`: 显示昵称
* `status`: 用户状态(active / blocked / deleted)
* `metadata`: 扩展信息(渠道、终端等)
```sql
CREATE TABLE t_app_user (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email VARCHAR(255) UNIQUE NOT NULL,
phone VARCHAR(32),
display_name VARCHAR(128) NOT NULL,
password_hash VARCHAR(255) NOT NULL,
status VARCHAR(32) NOT NULL DEFAULT 'active', -- active / blocked / deleted
metadata JSONB,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
COMMENT ON TABLE t_app_user IS '用户表:存储系统用户的基础信息';
COMMENT ON COLUMN t_app_user.email IS '登录邮箱,唯一';
COMMENT ON COLUMN t_app_user.display_name IS '用户显示昵称';
COMMENT ON COLUMN t_app_user.status IS '用户状态:active / blocked / deleted';我们会把它拆分成:
-
标题:用户表
t_app_user -
内容:用户表的详情。
按照这种拆分方式,每篇文档我们都拆分成下面的结构:
然后我们再将标题进行 embedding 处理,通过向量模型将其转成向量,保持文本不变:

然后我们将标题的向量和标题下的内容存入 chunk_bge_m3 表中:
embedding 字段存储向量,content 存文本。
具体实现方式是我们通过解析 AST 的方式,提取所有标题,并将每个标题下面的内容视为一个完整章节。
这样拆出来的每一块,都有非常明确的语义边界,既不会太碎,也不会太大,恰好适合作为 RAG 的最小单元。
具体实现时,我们通过解析 Markdown 的 AST 来提取章节:
public interface MarkdownParserService {
/**
* 解析 Markdown 文件,提取标题和对应的内容
*/
List<MarkdownSection> parseMarkdown(InputStream inputStream);
@Data
@AllArgsConstructor
@ToString
class MarkdownSection {
private String title;
private String content;
}
}解析逻辑也很直观:找到所有标题节点,然后收集从当前标题到下一个标题之间的所有内容,得到一组 (title, content) 对。
解析入口:
public List<MarkdownSection> parseMarkdown(InputStream inputStream) {
try {
// 读取文件内容
originalMarkdownContent = new String(inputStream.readAllBytes(), StandardCharsets.UTF_8);
// 解析 Markdown
Document document = parser.parse(originalMarkdownContent);
// 提取标题和内容
List<MarkdownSection> sections = new ArrayList<>();
extractSections(document, sections);
log.info("解析 Markdown 完成,共提取 {} 个章节", sections.size());
return sections;
} catch (Exception e) {
log.error("解析 Markdown 失败", e);
throw new RuntimeException("解析 Markdown 失败: " + e.getMessage(), e);
}
}对 titie 生成 embedding,并持久化到数据库中:
for (MarkdownParserService.MarkdownSection section : sections) {
String title = section.getTitle();
String content = section.getContent();
if (title == null || title.trim().isEmpty()) {
continue;
}
// 对标题进行 embedding
float[] embedding = ragService.embed(title);
// 创建 ChunkBgeM3 实体
ChunkBgeM3 chunk = ChunkBgeM3.builder()
.kbId(kbId)
.docId(documentId)
.content(content != null ? content : "")
.metadata(null) // 可以存储标题信息到 metadata
.embedding(embedding)
.createdAt(now)
.updatedAt(now)
.build();
chunkBgeM3Mapper.insert(chunk);
}简单看一下 ragService.embed() 方法,和调用 LLM 类似,都是发送一个 HTTP 请求,然后接受调用结果。 在这里我们是调用本地部署的 bge-m3 模型,将 title 转成向量:
private final WebClient webClient;
@Override
public float[] embed(String text) {
return doEmbed(text);
}
private float[] doEmbed(String text) {
EmbeddingResponse resp = webClient.post()
.uri("/api/embeddings")
.bodyValue(Map.of(
"model", "bge-m3",
"prompt", text
))
.retrieve()
.bodyToMono(EmbeddingResponse.class)
.block();
Assert.notNull(resp, "Embedding response cannot be null");
return resp.getEmbedding();
}为什么只对标题生成 Embedding
我们没有对完整内容生成向量,而是只对章节标题生成 Embedding。章节的具体内容则原样存储,用于最终返回给 Agent。
这个设计背后有几个现实的考虑:
-
标题是天然的语义标签:标题本身就是作者对内容的高度概括,用它来检索最精准。
-
成本更低,效果更稳定:标题长度稳定,token 数量少,生成向量的成本更低,效果也更稳定。
-
内容才是模型需要阅读的:真正需要交给模型理解的是内容,而不是标题。
简单来说,就是标题负责找,内容负责看。这是一个非常适合 Agent 使用场景的折中方案。
另外,我们没有用独立的向量数据库,而是直接用 PostgreSQL + pgvector。这样做的好处是:
-
不需要引入额外的基础设施
-
向量数据和业务数据在同一数据库中
-
查询路径清晰,可调试,可观测
相似度搜索的核心逻辑
一次完整的相似度搜索流程如下:
-
将查询文本生成 Embedding
-
使用该向量在指定知识库范围内执行相似度排序
-
返回最相关的若干个章节内容
对应的 SQL 查询也非常直观:
SELECT id, kb_id, doc_id, content, metadata, embedding, created_at, updated_at
FROM chunk_bge_m3
WHERE kb_id = CAST(? AS uuid)
ORDER BY embedding <-> ?::vector
LIMIT ?在这个过程中,embedding 只是检索的索引键,真正返回给 Agent 的,始终是原始的文档内容。
KnowledgeTool:RAG 在 Agent 世界的入口
Agent 并不会直接调用 RagService,它只认识一个工具:KnowledgeTool。
@Tool(
name = "KnowledgeTool",
description = "从知识库中执行语义检索"
)
public String knowledgeQuery(String kbsId, String query) {
List<String> results = ragService.similaritySearch(kbsId, query);
return String.join("\n", results);
}为了让 Agent 在 Think 阶段能够正确判断是否要使用 RAG,我们会在提示词中明确告诉它:
-
当前允许访问哪些知识库
-
每个知识库的大致用途
这些信息不会被模型记住,但会在当前决策中起到关键的引导作用。一旦模型意识到这个问题可以通过知识库解决,它就会主动选择调用 KnowledgeTool。
上述内容也同步在我的飞书,欢迎访问
https://my.feishu.cn/wiki/QLauws6lWif1pnkhB8IcAvkhncc?from=from_copylink
如果我的内容对你有帮助,请点赞,评论,收藏。创作不易,你们的支持就是我坚持下去的动力!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)