第五章:利用RAG知识库实现智能AI系统【从零构建企业级智能问答应用】(附全部代码)
本文介绍了一个基于RAG架构的智能问答系统完整实现方案。系统采用前后端分离设计,后端使用FastAPI框架构建文档处理、向量检索和大模型调用服务,前端采用Vue3实现交互界面。核心功能包括文档上传解析、文本切片、向量化存储、语义检索和基于上下文的智能问答。文章详细阐述了系统架构设计、技术选型、模块实现及部署方案,并提供了性能优化和应用场景扩展建议。该系统解决了大语言模型知识滞后问题,通过检索增强生
目录
前言
在人工智能技术飞速发展的今天,大语言模型(LLM)已经展现出强大的文本理解和生成能力。然而,通用大模型在面对特定领域问题时,往往存在知识滞后、幻觉现象以及缺乏私有数据支撑等痛点。检索增强生成(Retrieval-Augmented Generation,RAG)技术的出现,为解决这些问题提供了优雅的方案。
RAG的核心思想是将信息检索与文本生成相结合,在用户提出问题后,首先从知识库中检索出相关的文档片段,然后将这些片段作为上下文与用户问题一起提交给大语言模型,从而生成更准确、更具时效性的回答。这种架构既保留了大模型的生成能力,又通过外部知识库实现了知识的动态更新和定制化扩展。
本文将带领读者从零开始,完整实现一个基于RAG架构的智能问答系统。我们将采用前后端分离的架构,后端使用Python语言和FastAPI框架,负责文档处理、向量化存储、检索召回和模型调用;前端使用Vue3框架,提供用户友好的交互界面。通过本项目的学习,读者不仅能够理解RAG的核心原理,还能掌握实际工程落地的完整流程,包括:文档切片、向量数据库应用、Embedding模型选择、大模型API集成、异步任务处理等关键技术点。
让我们开始这段RAG应用开发的实践之旅,亲手打造一个智能、高效、可扩展的AI问答系统。
一、项目需求效果分析
1.1 业务场景设定
假设我们是一家科技公司,拥有大量的技术文档、产品手册、API文档和常见问题解答。这些文档分散在各个部门和系统中,员工在查找信息时需要花费大量时间。我们希望构建一个智能问答系统,让员工能够用自然语言提问,系统自动从文档库中检索相关信息,并由AI生成准确、易懂的答案。
1.2 核心需求分析
1.2.1 功能性需求
-
文档管理:支持上传多种格式的文档(TXT、Markdown、PDF等),对文档内容进行解析和预处理
-
知识库构建:将文档内容切分成合理的文本片段,生成向量嵌入并存储到向量数据库中
-
智能问答:用户输入问题后,系统检索相关文档片段,结合大模型生成答案
-
对话历史:保存用户与系统的对话记录,支持上下文关联的多轮对话
-
答案溯源:显示答案所依据的原始文档片段,增加可信度
-
管理后台:支持知识库的增删改查、文档更新等管理功能
1.2.2 非功能性需求
-
响应速度:问答响应时间控制在3秒以内(不含大模型生成时间)
-
准确性:检索结果的准确率达到85%以上
-
可扩展性:支持后续增加新的文档类型和模型接口
-
易用性:界面简洁直观,交互流畅
二、功能列表
2.1 系统功能全景图
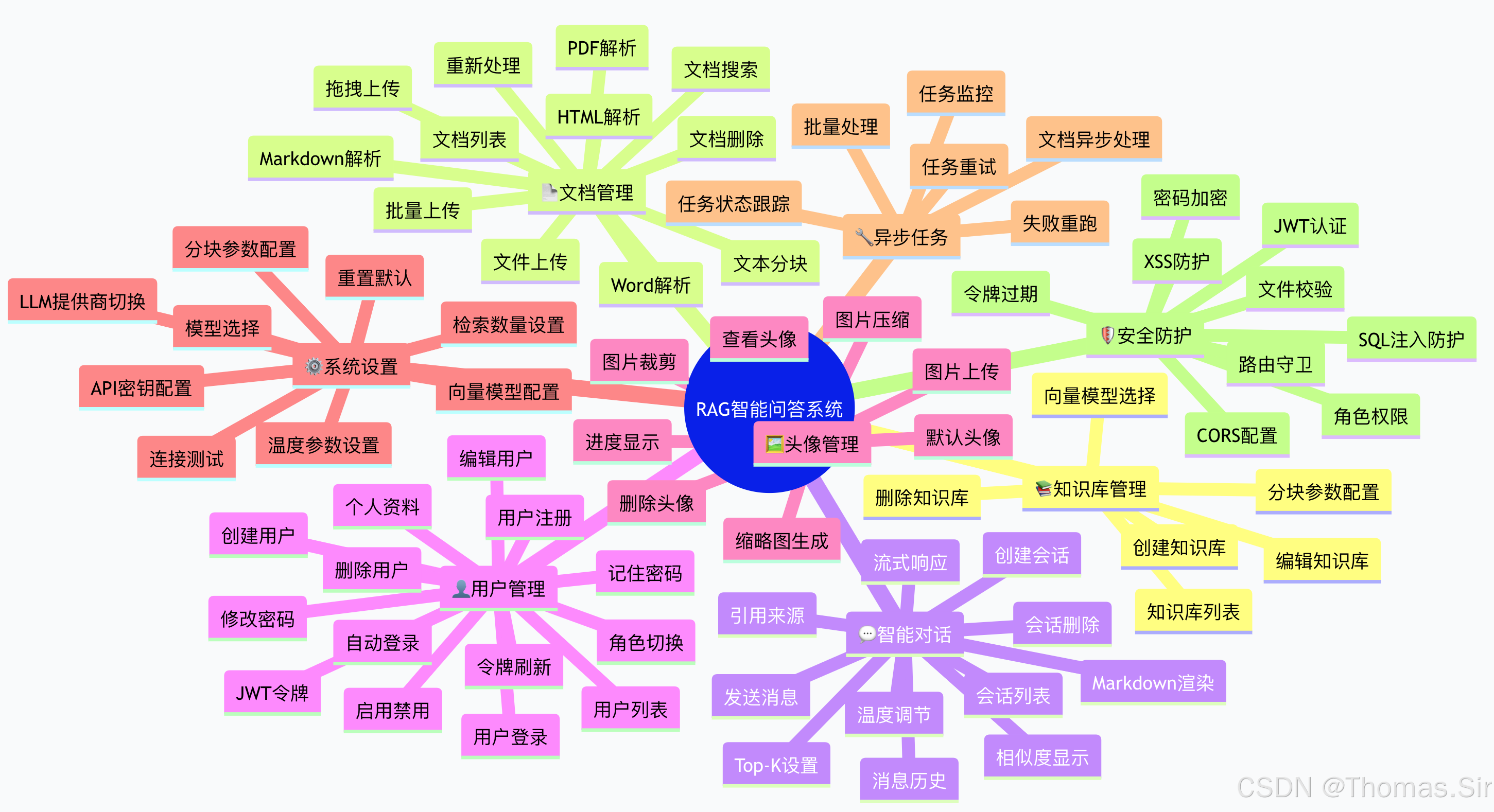
2.2 核心功能模块详细列表
📚 知识库管理
| 编号 | 功能模块 | 子功能 | 功能描述 | 优先级 |
|---|---|---|---|---|
| 1.1 | 知识库CRUD | 创建知识库 | 支持创建新知识库,配置名称、描述、分块参数 | ⭐⭐⭐⭐⭐ |
| 1.2 | 编辑知识库 | 修改知识库名称、描述、分块大小、分块重叠 | ⭐⭐⭐⭐ | |
| 1.3 | 删除知识库 | 删除知识库及其所有文档和向量数据 | ⭐⭐⭐⭐ | |
| 1.4 | 查询列表 | 分页查看所有知识库,支持搜索筛选 | ⭐⭐⭐⭐⭐ | |
| 1.5 | 详情查看 | 查看知识库详细配置和统计数据 | ⭐⭐⭐⭐ | |
| 1.6 | 参数配置 | 分块大小 | 设置文档分块字符数(100-2000) | ⭐⭐⭐⭐⭐ |
| 1.7 | 分块重叠 | 设置分块间重叠字符数(0-500) | ⭐⭐⭐⭐ | |
| 1.8 | 向量模型 | 选择向量化模型(bge-small/base/large) | ⭐⭐⭐⭐ |
📄 文档管理
| 编号 | 功能模块 | 子功能 | 功能描述 | 优先级 |
|---|---|---|---|---|
| 2.1 | 文档上传 | 单文件上传 | 支持PDF/DOCX/TXT/MD/HTML格式 | ⭐⭐⭐⭐⭐ |
| 2.2 | 拖拽上传 | 支持拖拽文件到上传区域 | ⭐⭐⭐⭐ | |
| 2.3 | 批量上传 | 支持同时上传多个文档 | ⭐⭐⭐⭐ | |
| 2.4 | 进度显示 | 实时显示上传和处理进度 | ⭐⭐⭐⭐⭐ | |
| 2.5 | 文档解析 | PDF解析 | 提取PDF文本内容和结构 | ⭐⭐⭐⭐⭐ |
| 2.6 | Word解析 | 解析DOCX段落和表格 | ⭐⭐⭐⭐⭐ | |
| 2.7 | Markdown解析 | 解析MD文件转纯文本 | ⭐⭐⭐⭐ | |
| 2.8 | HTML解析 | 解析HTML提取正文 | ⭐⭐⭐ | |
| 2.9 | 文本分块 | 按配置大小自动分块 | ⭐⭐⭐⭐⭐ | |
| 2.10 | 文档管理 | 文档列表 | 展示所有文档,支持筛选 | ⭐⭐⭐⭐⭐ |
| 2.11 | 文档搜索 | 按文件名搜索文档 | ⭐⭐⭐⭐ | |
| 2.12 | 状态查看 | 查看处理状态和错误信息 | ⭐⭐⭐⭐ | |
| 2.13 | 文档删除 | 删除文档及对应向量数据 | ⭐⭐⭐⭐ | |
| 2.14 | 重新处理 | 失败文档支持重新处理 | ⭐⭐⭐ |
💬 智能对话
| 编号 | 功能模块 | 子功能 | 功能描述 | 优先级 |
|---|---|---|---|---|
| 3.1 | 会话管理 | 创建会话 | 创建新对话会话 | ⭐⭐⭐⭐⭐ |
| 3.2 | 会话列表 | 查看历史对话列表 | ⭐⭐⭐⭐⭐ | |
| 3.3 | 会话删除 | 删除指定对话会话 | ⭐⭐⭐⭐ | |
| 3.4 | 会话重命名 | 修改对话标题 | ⭐⭐⭐ | |
| 3.5 | 消息交互 | 发送消息 | 向AI发送问题 | ⭐⭐⭐⭐⭐ |
| 3.6 | 流式响应 | 实时流式返回AI回答 | ⭐⭐⭐⭐⭐ | |
| 3.7 | 消息历史 | 查看完整对话历史 | ⭐⭐⭐⭐⭐ | |
| 3.8 | 引用来源 | 显示回答引用的文档来源 | ⭐⭐⭐⭐⭐ | |
| 3.9 | 相似度显示 | 显示引用文档相似度分数 | ⭐⭐⭐⭐ | |
| 3.10 | 消息复制 | 复制AI回答内容 | ⭐⭐⭐ | |
| 3.11 | Markdown渲染 | 支持代码高亮和表格 | ⭐⭐⭐⭐⭐ | |
| 3.12 | 参数调节 | 温度参数 | 调节回答创造性(0-2) | ⭐⭐⭐⭐ |
| 3.13 | Top-K设置 | 设置检索文档数量(1-20) | ⭐⭐⭐⭐ | |
| 3.14 | 最大Token | 限制回答最大长度 | ⭐⭐⭐⭐ |
👤 用户管理
| 编号 | 功能模块 | 子功能 | 功能描述 | 优先级 |
|---|---|---|---|---|
| 4.1 | 用户认证 | 用户注册 | 新用户注册账号 | ⭐⭐⭐⭐⭐ |
| 4.2 | 用户登录 | 用户名/邮箱登录 | ⭐⭐⭐⭐⭐ | |
| 4.3 | JWT令牌 | 基于JWT的无状态认证 | ⭐⭐⭐⭐⭐ | |
| 4.4 | 令牌刷新 | 自动刷新过期的访问令牌 | ⭐⭐⭐⭐ | |
| 4.5 | 记住密码 | AES加密存储,自动填充 | ⭐⭐⭐⭐ | |
| 4.6 | 自动登录 | 打开页面自动登录 | ⭐⭐⭐ | |
| 4.7 | 退出登录 | 清除会话和令牌 | ⭐⭐⭐⭐⭐ | |
| 4.8 | 用户管理 | 用户列表 | 管理员查看所有用户 | ⭐⭐⭐⭐⭐ |
| 4.9 | 创建用户 | 管理员创建新用户 | ⭐⭐⭐⭐ | |
| 4.10 | 编辑用户 | 修改用户信息 | ⭐⭐⭐⭐ | |
| 4.11 | 删除用户 | 软删除用户(禁用) | ⭐⭐⭐⭐ | |
| 4.12 | 角色切换 | 切换用户角色(admin/user) | ⭐⭐⭐⭐ | |
| 4.13 | 启用/禁用 | 控制用户账户状态 | ⭐⭐⭐⭐ | |
| 4.14 | 批量操作 | 批量导出/删除用户 | ⭐⭐⭐ | |
| 4.15 | 个人资料 | 查看资料 | 查看个人信息 | ⭐⭐⭐⭐⭐ |
| 4.16 | 编辑资料 | 修改邮箱、姓名 | ⭐⭐⭐⭐ | |
| 4.17 | 修改密码 | 修改登录密码 | ⭐⭐⭐⭐⭐ |
🖼️ 头像管理
| 编号 | 功能模块 | 子功能 | 功能描述 | 优先级 |
|---|---|---|---|---|
| 5.1 | 头像上传 | 图片上传 | 支持JPG/PNG/GIF/WEBP格式 | ⭐⭐⭐⭐⭐ |
| 5.2 | 图片裁剪 | 上传前裁剪头像 | ⭐⭐⭐⭐ | |
| 5.3 | 进度显示 | 显示上传进度 | ⭐⭐⭐⭐ | |
| 5.4 | 图片压缩 | 自动压缩优化图片 | ⭐⭐⭐⭐ | |
| 5.5 | 头像管理 | 查看头像 | 点击放大查看 | ⭐⭐⭐⭐ |
| 5.6 | 删除头像 | 删除已上传头像 | ⭐⭐⭐⭐ | |
| 5.7 | 默认头像 | 基于用户名生成默认头像 | ⭐⭐⭐⭐⭐ | |
| 5.8 | 缩略图 | 自动生成缩略图 | ⭐⭐⭐ |
⚙️ 系统设置
| 编号 | 功能模块 | 子功能 | 功能描述 | 优先级 |
|---|---|---|---|---|
| 6.1 | 模型配置 | LLM提供商 | 切换OpenAI/智谱AI | ⭐⭐⭐⭐⭐ |
| 6.2 | API密钥配置 | 配置API密钥 | ⭐⭐⭐⭐⭐ | |
| 6.3 | 模型选择 | 选择具体模型版本 | ⭐⭐⭐⭐ | |
| 6.4 | 向量模型 | 选择向量化模型 | ⭐⭐⭐⭐ | |
| 6.5 | 计算设备 | CPU/GPU选择 | ⭐⭐⭐ | |
| 6.6 | 检索配置 | 默认Top-K | 设置默认检索数量 | ⭐⭐⭐⭐ |
| 6.7 | 温度参数 | 设置默认温度 | ⭐⭐⭐⭐ | |
| 6.8 | 最大Token | 设置默认最大长度 | ⭐⭐⭐⭐ | |
| 6.9 | 分块参数 | 设置默认分块配置 | ⭐⭐⭐⭐ | |
| 6.10 | 系统信息 | 版本信息 | 显示系统版本 | ⭐⭐⭐ |
| 6.11 | 连接测试 | 测试LLM连接 | ⭐⭐⭐⭐ | |
| 6.12 | 重置默认 | 恢复默认配置 | ⭐⭐⭐ |
🔧 异步任务
| 编号 | 功能模块 | 子功能 | 功能描述 | 优先级 |
|---|---|---|---|---|
| 7.1 | 任务队列 | 文档异步处理 | 后台处理文档解析向量化 | ⭐⭐⭐⭐⭐ |
| 7.2 | 任务状态跟踪 | 实时跟踪处理进度 | ⭐⭐⭐⭐⭐ | |
| 7.3 | 任务重试 | 失败任务自动重试 | ⭐⭐⭐⭐ | |
| 7.4 | 批量处理 | 批量文档并行处理 | ⭐⭐⭐⭐ | |
| 7.5 | 任务监控 | 活跃任务查看 | 查看正在执行的任务 | ⭐⭐⭐ |
| 7.6 | 任务撤销 | 撤销正在执行的任务 | ⭐⭐⭐ | |
| 7.7 | 失败任务重跑 | 手动重跑失败任务 | ⭐⭐⭐⭐ |
🛡️ 安全防护
| 编号 | 功能模块 | 子功能 | 功能描述 | 优先级 |
|---|---|---|---|---|
| 8.1 | 认证安全 | JWT令牌 | 无状态认证 | ⭐⭐⭐⭐⭐ |
| 8.2 | 密码加密 | bcrypt加密存储 | ⭐⭐⭐⭐⭐ | |
| 8.3 | 令牌过期 | 30分钟自动过期 | ⭐⭐⭐⭐ | |
| 8.4 | 刷新令牌 | 7天刷新周期 | ⭐⭐⭐⭐ | |
| 8.5 | 数据安全 | SQL注入防护 | 参数化查询 | ⭐⭐⭐⭐⭐ |
| 8.6 | XSS防护 | 输入内容转义 | ⭐⭐⭐⭐⭐ | |
| 8.7 | CORS配置 | 跨域访问控制 | ⭐⭐⭐⭐ | |
| 8.8 | 文件校验 | 类型/大小限制 | ⭐⭐⭐⭐⭐ | |
| 8.9 | 权限控制 | 角色权限 | 管理员/普通用户 | ⭐⭐⭐⭐⭐ |
| 8.10 | 路由守卫 | 前端路由权限 | ⭐⭐⭐⭐⭐ |
📊 数据统计
| 编号 | 功能模块 | 子功能 | 功能描述 | 优先级 |
|---|---|---|---|---|
| 9.1 | 知识库统计 | 文档总数 | 显示知识库文档数量 | ⭐⭐⭐⭐ |
| 9.2 | 分块总数 | 显示向量块数量 | ⭐⭐⭐⭐ | |
| 9.3 | 处理进度 | 显示文档处理进度 | ⭐⭐⭐⭐ | |
| 9.4 | 对话统计 | 会话数量 | 显示历史会话数 | ⭐⭐⭐ |
| 9.5 | 消息数量 | 显示消息总数 | ⭐⭐⭐ |
2.3 API接口列表
| 模块 | 接口路径 | 方法 | 功能描述 |
|---|---|---|---|
| 知识库 | /api/v1/knowledge-bases |
GET | 获取知识库列表 |
/api/v1/knowledge-bases |
POST | 创建知识库 | |
/api/v1/knowledge-bases/{id} |
GET/PUT/DELETE | 详情/更新/删除 | |
| 文档 | /api/v1/documents |
GET | 获取文档列表 |
/api/v1/documents/upload |
POST | 上传文档 | |
/api/v1/documents/{id} |
GET/DELETE | 详情/删除 | |
| 对话 | /api/v1/chat/conversations |
GET/POST | 会话列表/创建 |
/api/v1/chat/conversations/{id}/messages |
GET | 获取消息 | |
/api/v1/chat/query |
POST | 发送消息 | |
/api/v1/chat/stream |
GET | 流式对话 | |
| 认证 | /api/v1/auth/login |
POST | 用户登录 |
/api/v1/auth/refresh |
POST | 刷新令牌 | |
/api/v1/auth/logout |
POST | 退出登录 | |
/api/v1/auth/me |
GET | 获取当前用户 | |
/api/v1/auth/change-password |
POST | 修改密码 | |
| 用户 | /api/v1/users |
GET/POST | 用户列表/创建 |
/api/v1/users/{id} |
GET/PUT/DELETE | 详情/更新/删除 | |
/api/v1/users/{id}/role |
PUT | 更新角色 | |
/api/v1/users/{id}/toggle |
PUT | 启用/禁用 | |
| 头像 | /api/v1/avatar/upload |
POST | 上传头像 |
/api/v1/avatar |
DELETE | 删除头像 | |
| 设置 | /api/v1/settings |
GET/PUT | 获取/更新设置 |
/api/v1/settings/test-llm |
POST | 测试LLM连接 | |
/api/v1/settings/reset |
POST | 重置设置 |
2.4 功能统计汇总
| 模块 | 功能数量 | 核心功能 | 扩展功能 |
|---|---|---|---|
| 📚 知识库管理 | 8 | 5 | 3 |
| 📄 文档管理 | 14 | 9 | 5 |
| 💬 智能对话 | 14 | 10 | 4 |
| 👤 用户管理 | 17 | 12 | 5 |
| 🖼️ 头像管理 | 8 | 5 | 3 |
| ⚙️ 系统设置 | 12 | 8 | 4 |
| 🔧 异步任务 | 7 | 5 | 2 |
| 🛡️ 安全防护 | 10 | 8 | 2 |
| 📊 数据统计 | 5 | 3 | 2 |
| 总计 | 95 | 65 | 30 |
2.5 版本迭代计划
| 版本 | 核心功能 | 预计时间 |
|---|---|---|
| v1.0 | 基础RAG问答 + 文档管理 + 用户认证 | ✅ 已完成 |
| v1.5 | 多租户支持 + 图片OCR + 网页爬虫 | 🔄 开发中 |
| v2.0 | 音频转录 + 数据导出 + 移动端适配 | 📋 计划中 |
2.6 文档处理流程
-
用户上传文档 → 2. 后端接收并存储 → 3. 异步任务处理 → 4. 解析文档内容 → 5. 文本切片(按段落、固定大小等策略) → 6. 调用Embedding模型生成向量 → 7. 存储到向量数据库 → 8. 更新文档状态
2.7 问答流程
-
用户输入问题 → 2. 前端发送请求 → 3. 后端将问题向量化 → 4. 在向量数据库中检索相似片段 → 5. 构建Prompt(包含检索到的上下文) → 6. 调用大模型API → 7. 解析返回结果 → 8. 返回答案和来源
三、效果展示


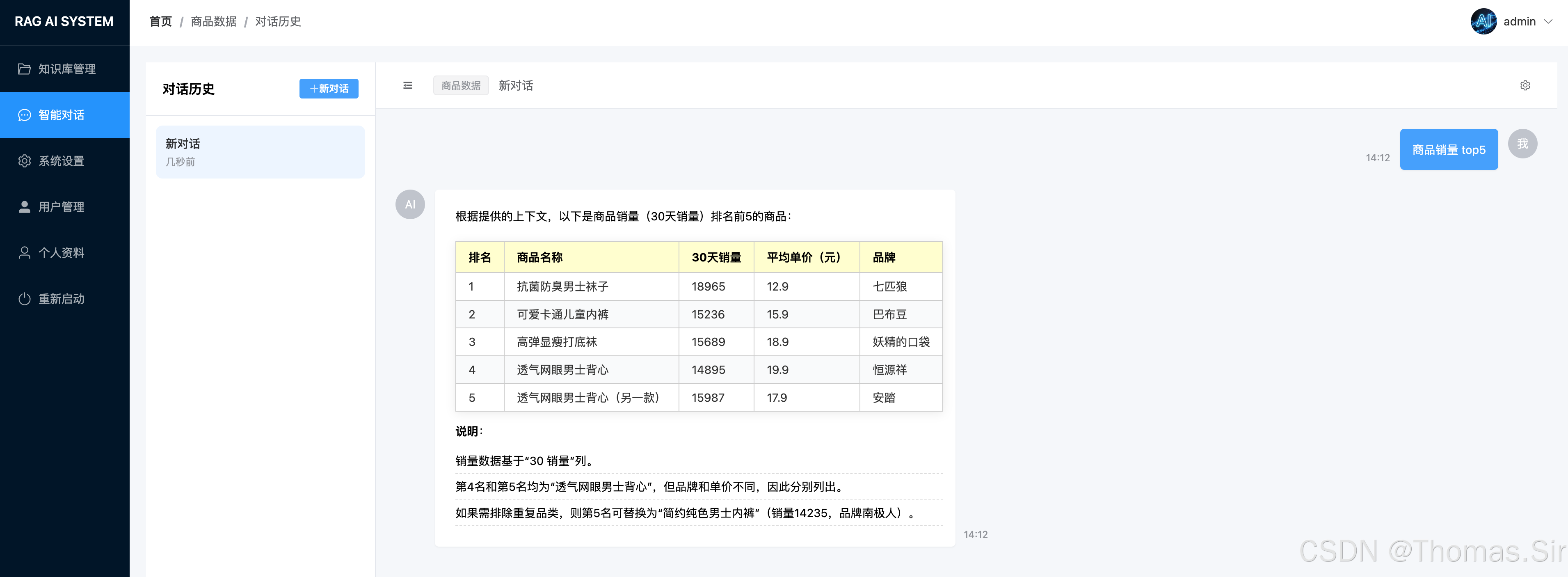
四、服务端编码
4.1 项目结构
rag-ai-system-backend/
├── app/
│ ├── __init__.py
│ ├── main.py # FastAPI应用入口
│ ├── config.py # 配置文件
│ ├── models/
│ │ ├── __init__.py
│ │ ├── document.py # 文档数据模型
│ │ ├── conversation.py # 对话数据模型
│ │ └── schemas.py # Pydantic模型
│ ├── services/
│ │ ├── __init__.py
│ │ ├── document_service.py # 文档处理服务
│ │ ├── embedding_service.py# 向量化服务
│ │ ├── rag_service.py # RAG问答服务
│ │ └── llm_service.py # 大模型调用服务
│ ├── api/
│ │ ├── __init__.py
│ │ ├── v1/
│ │ │ ├── __init__.py
│ │ │ ├── documents.py # 文档管理接口
│ │ │ ├── chat.py # 问答接口
│ │ │ └── knowledge.py # 知识库管理接口
│ ├── core/
│ │ ├── __init__.py
│ │ ├── database.py # 数据库连接
│ │ ├── vector_store.py # 向量数据库封装
│ │ └── tasks.py # Celery异步任务
│ ├── utils/
│ │ ├── __init__.py
│ │ ├── file_parser.py # 文件解析工具
│ │ ├── text_splitter.py # 文本切片工具
│ │ └── logger.py # 日志工具
│ └── static/ # 静态文件
├── requirements.txt
├── .env.example
├── docker-compose.yml
└── README.md4.2 环境配置
# requirements.txt
# Web 框架
fastapi==0.135.2
uvicorn[standard]==0.42.0
python-multipart==0.0.22
python-multipart>=0.0.6
httpx==0.28.1
# 数据库 & 向量库
sqlalchemy==2.0.48
chromadb==1.5.5
pymysql==1.1.2
# 异步任务
celery==5.6.3
redis==6.0.0
# AI & 深度学习
openai==2.30.0
sentence-transformers==5.3.0
torch==2.2.2
zhipuai
# 文档处理
PyPDF2==3.0.1
python-docx==1.2.0
markdown==3.10.2
beautifulsoup4==4.14.3
openpyxl
Pillow>=10.0.0
# 配置 & 数据校验
python-dotenv==1.2.2
pydantic==2.12.5
pydantic-settings==2.13.1
# 工具库
loguru==0.7.3
numpy
requests
cryptography
argon2_cffi
# 安全 & 认证
python-jose[cryptography]>=3.3.0
passlib[bcrypt]>=1.7.4
email-validator>=2.0.0
# 部署工具
honcho4.3 数据模型设计
“”“app/models/document.py”“”
"""
文档管理数据模型
定义文档和文档片段的数据表结构
"""
from sqlalchemy import Column, Integer, String, Text, DateTime, Float, Enum, Index
from sqlalchemy.sql import func
from sqlalchemy.ext.declarative import declarative_base
import enum
Base = declarative_base()
class DocumentStatus(str, enum.Enum):
"""文档处理状态枚举"""
PENDING = "pending" # 等待处理
PROCESSING = "processing" # 处理中
COMPLETED = "completed" # 处理完成
FAILED = "failed" # 处理失败
class Document(Base):
"""文档主表"""
__tablename__ = "documents"
id = Column(Integer, primary_key=True, autoincrement=True)
filename = Column(String(255), nullable=False, comment="原始文件名")
file_path = Column(String(500), nullable=False, comment="文件存储路径")
file_size = Column(Integer, comment="文件大小(字节)")
file_type = Column(String(50), comment="文件类型")
# 文档元数据
title = Column(String(500), comment="文档标题")
author = Column(String(200), comment="作者")
create_time = Column(DateTime, server_default=func.now(), comment="创建时间")
update_time = Column(DateTime, onupdate=func.now(), comment="更新时间")
# 处理状态
status = Column(Enum(DocumentStatus), default=DocumentStatus.PENDING, comment="处理状态")
error_message = Column(Text, comment="错误信息")
chunks_count = Column(Integer, default=0, comment="切片数量")
# 统计信息
view_count = Column(Integer, default=0, comment="查看次数")
# 索引
__table_args__ = (
Index('idx_status', 'status'),
Index('idx_create_time', 'create_time'),
)
class DocumentChunk(Base):
"""文档切片表"""
__tablename__ = "document_chunks"
id = Column(Integer, primary_key=True, autoincrement=True)
document_id = Column(Integer, nullable=False, comment="关联的文档ID")
chunk_index = Column(Integer, nullable=False, comment="切片序号")
content = Column(Text, nullable=False, comment="切片文本内容")
# 向量存储的ID(关联到向量数据库)
vector_id = Column(String(100), comment="向量数据库中的ID")
# 元数据
create_time = Column(DateTime, server_default=func.now(), comment="创建时间")
# 索引
__table_args__ = (
Index('idx_document_id', 'document_id'),
Index('idx_vector_id', 'vector_id'),
)app/models/schemas.py
"""
Pydantic模型定义
用于API请求和响应的数据验证
"""
from pydantic import BaseModel, Field
from typing import List, Optional, Dict, Any
from datetime import datetime
from enum import Enum
# ========== 文档相关模型 ==========
class DocumentUploadResponse(BaseModel):
"""文档上传响应"""
id: int
filename: str
status: str
message: str
class DocumentInfo(BaseModel):
"""文档信息"""
id: int
filename: str
title: Optional[str]
file_size: int
status: str
chunks_count: int
create_time: datetime
update_time: Optional[datetime]
class Config:
from_attributes = True
class DocumentDetail(BaseModel):
"""文档详情"""
id: int
filename: str
title: Optional[str]
author: Optional[str]
file_size: int
file_type: str
status: str
error_message: Optional[str]
chunks_count: int
create_time: datetime
update_time: Optional[datetime]
class DocumentChunkInfo(BaseModel):
"""文档切片信息"""
id: int
chunk_index: int
content: str
document_id: int
# ========== 问答相关模型 ==========
class ChatRequest(BaseModel):
"""问答请求"""
question: str = Field(..., min_length=1, max_length=2000, description="用户问题")
conversation_id: Optional[int] = Field(None, description="对话ID,用于多轮对话")
top_k: Optional[int] = Field(5, ge=1, le=20, description="检索数量")
temperature: Optional[float] = Field(0.7, ge=0, le=2, description="生成温度")
class Config:
json_schema_extra = {
"example": {
"question": "什么是RAG技术?",
"conversation_id": None,
"top_k": 5,
"temperature": 0.7
}
}
class SourceDocument(BaseModel):
"""参考来源"""
document_id: int
document_name: str
chunk_id: int
content: str
similarity: float
class ChatResponse(BaseModel):
"""问答响应"""
answer: str
sources: List[SourceDocument]
conversation_id: int
message_id: int
class ConversationInfo(BaseModel):
"""对话信息"""
id: int
title: str
created_at: datetime
updated_at: datetime
class MessageInfo(BaseModel):
"""消息信息"""
id: int
role: str
content: str
sources: Optional[str]
created_at: datetime
# ========== 知识库管理模型 ==========
class KnowledgeBaseStats(BaseModel):
"""知识库统计"""
total_documents: int
total_chunks: int
completed_documents: int
failed_documents: int
processing_documents: int
class SearchRequest(BaseModel):
"""搜索请求"""
query: str = Field(..., min_length=1, description="搜索查询")
top_k: int = Field(5, ge=1, le=20, description="返回结果数量")
similarity_threshold: Optional[float] = Field(0.7, ge=0, le=1, description="相似度阈值")
class SearchResult(BaseModel):
"""搜索结果"""
content: str
document_id: int
document_name: str
chunk_id: int
similarity: float
# ========== 系统管理模型 ==========
class SystemConfig(BaseModel):
"""系统配置"""
llm_provider: str
embedding_model: str
top_k: int
similarity_threshold: float
class APIKeyConfig(BaseModel):
"""API密钥配置"""
provider: str
api_key: str
model: Optional[str] = None4.4 数据库初始化
"""
app/core/database.py
数据库连接管理模块
提供SQLAlchemy数据库会话管理和初始化功能
"""
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker, Session
from typing import Generator
from app.config import settings
import logging
logger = logging.getLogger(__name__)
# 创建数据库引擎
# 根据数据库类型配置连接池
if settings.database_url.startswith("sqlite"):
# SQLite配置
engine = create_engine(
settings.database_url,
connect_args={"check_same_thread": False},
echo=settings.debug
)
else:
# MySQL/PostgreSQL配置
engine = create_engine(
settings.database_url,
pool_size=10,
max_overflow=20,
pool_pre_ping=True,
echo=settings.debug
)
# 创建会话工厂
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
# 创建基类
Base = declarative_base()
def get_db() -> Generator[Session, None, None]:
"""
依赖注入:获取数据库会话
每个请求结束后自动关闭会话
"""
db = SessionLocal()
try:
yield db
finally:
db.close()
def init_database():
"""
初始化数据库
创建所有表结构
"""
try:
# 导入所有模型,确保Base知道它们
from app.models import document, conversation
# 创建表
Base.metadata.create_all(bind=engine)
logger.info("数据库初始化成功")
except Exception as e:
logger.error(f"数据库初始化失败: {e}")
raise4.5 向量数据库封装
"""
app/core/vector_store.py
向量数据库封装模块
基于ChromaDB实现文档向量的存储和检索
"""
import chromadb
from chromadb.config import Settings as ChromaSettings
from typing import List, Dict, Any, Optional, Tuple
import logging
from app.config import settings
logger = logging.getLogger(__name__)
class VectorStore:
"""
向量数据库管理类
封装ChromaDB的常见操作
"""
def __init__(self):
"""初始化向量数据库客户端"""
self.client = chromadb.Client(ChromaSettings(
chroma_db_impl="duckdb+parquet",
persist_directory=settings.chroma_persist_dir,
anonymized_telemetry=False
))
# 获取或创建集合
self.collection = self.client.get_or_create_collection(
name=settings.chroma_collection_name,
metadata={"hnsw:space": "cosine"} # 使用余弦相似度
)
logger.info(f"向量数据库初始化成功,集合名称: {settings.chroma_collection_name}")
def add_documents(
self,
ids: List[str],
embeddings: List[List[float]],
metadatas: List[Dict[str, Any]],
documents: List[str]
) -> bool:
"""
添加文档向量到数据库
Args:
ids: 文档ID列表
embeddings: 向量列表
metadatas: 元数据列表
documents: 原始文本列表
Returns:
是否添加成功
"""
try:
self.collection.add(
ids=ids,
embeddings=embeddings,
metadatas=metadatas,
documents=documents
)
logger.info(f"成功添加 {len(ids)} 个文档向量")
return True
except Exception as e:
logger.error(f"添加文档向量失败: {e}")
return False
def search(
self,
query_embedding: List[float],
top_k: int = 5,
where: Optional[Dict[str, Any]] = None
) -> List[Dict[str, Any]]:
"""
向量相似度搜索
Args:
query_embedding: 查询向量
top_k: 返回结果数量
where: 过滤条件
Returns:
搜索结果列表,每个结果包含id、distance、metadata、document
"""
try:
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
where=where
)
# 格式化返回结果
formatted_results = []
if results['ids'] and results['ids'][0]:
for i in range(len(results['ids'][0])):
formatted_results.append({
'id': results['ids'][0][i],
'distance': results['distances'][0][i] if results['distances'] else 1.0,
'metadata': results['metadatas'][0][i] if results['metadatas'] else {},
'document': results['documents'][0][i] if results['documents'] else ''
})
logger.info(f"搜索完成,找到 {len(formatted_results)} 个结果")
return formatted_results
except Exception as e:
logger.error(f"向量搜索失败: {e}")
return []
def delete_documents(self, ids: List[str]) -> bool:
"""
删除文档向量
Args:
ids: 要删除的文档ID列表
Returns:
是否删除成功
"""
try:
self.collection.delete(ids=ids)
logger.info(f"成功删除 {len(ids)} 个文档向量")
return True
except Exception as e:
logger.error(f"删除文档向量失败: {e}")
return False
def delete_by_metadata(self, where: Dict[str, Any]) -> bool:
"""
根据元数据条件删除文档
Args:
where: 过滤条件,例如 {"document_id": 1}
Returns:
是否删除成功
"""
try:
# 先查询符合条件的文档
results = self.collection.get(where=where)
if results['ids']:
self.collection.delete(ids=results['ids'])
logger.info(f"成功删除 {len(results['ids'])} 个文档向量")
return True
except Exception as e:
logger.error(f"根据元数据删除文档向量失败: {e}")
return False
def get_collection_stats(self) -> Dict[str, Any]:
"""获取集合统计信息"""
try:
count = self.collection.count()
return {
'name': settings.chroma_collection_name,
'document_count': count,
'metadata': self.collection.metadata
}
except Exception as e:
logger.error(f"获取集合统计失败: {e}")
return {}
# 创建全局向量数据库实例
vector_store = VectorStore()4.6 文档处理工具
"""
app/services/document_parser.py
文件解析工具模块
支持多种格式文档的内容提取
"""
import os
import re
from typing import List, Any
import PyPDF2
from docx import Document
import markdown
from bs4 import BeautifulSoup
from huggingface_hub import login
from loguru import logger
import pandas as pd
class DocumentParser:
"""文档解析器类"""
# 支持的文档类型
SUPPORTED_TYPES = {
'.pdf': 'parse_pdf',
'.docx': 'parse_docx',
'.txt': 'parse_text',
'.md': 'parse_markdown',
'.html': 'parse_html',
'.xlsx': 'parse_xlsx',
'.xls': 'parse_xlsx'
}
def __init__(self, chunk_size: int = 500, chunk_overlap: int = 50):
"""
初始化解析器
Args:
chunk_size: 分块大小(字符数)
chunk_overlap: 分块重叠大小
"""
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
def parse_document(self, file_path: str, filename: str) -> tuple[str, list[str], list[Any]]:
"""
解析文档
Args:
file_path: 文件路径
filename: 文件名
Returns:
(完整文本, 分块列表, 元数据列表)
"""
file_ext = os.path.splitext(filename)[1].lower()
if file_ext not in self.SUPPORTED_TYPES:
raise ValueError(f"不支持的文件类型: {file_ext}")
logger.info("6.3.1 获取解析方法并执行")
parser_method = self.SUPPORTED_TYPES[file_ext]
parser_func = getattr(self, parser_method)
text = parser_func(file_path)
logger.info("6.3.2 清理文本")
text = self.clean_text(text)
logger.info("6.3.3 分块")
chunks = self.split_text(text)
logger.info("6.3.4 为每个分块添加元数据")
chunk_metadatas = []
for i, chunk in enumerate(chunks):
chunk_metadatas.append({
'source': filename,
'chunk_index': i,
'total_chunks': len(chunks),
'file_type': file_ext
})
return text, chunks, chunk_metadatas
@staticmethod
def parse_pdf(file_path: str) -> str:
"""解析PDF文件"""
text = ""
try:
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
for page_num, page in enumerate(pdf_reader.pages):
page_text = page.extract_text()
if page_text:
text += f"\n--- Page {page_num + 1} ---\n"
text += page_text
logger.info(f"PDF解析完成: {file_path}, 页数: {len(pdf_reader.pages)}")
except Exception as e:
logger.error(f"PDF解析失败: {e}")
raise
return text
@staticmethod
def parse_docx(file_path: str) -> str:
"""解析DOCX文件"""
text = ""
try:
doc = Document(file_path)
for paragraph in doc.paragraphs:
if paragraph.text.strip():
text += paragraph.text + "\n"
# 解析表格
for table in doc.tables:
for row in table.rows:
row_text = []
for cell in row.cells:
row_text.append(cell.text.strip())
text += " | ".join(row_text) + "\n"
logger.info(f"DOCX解析完成: {file_path}")
except Exception as e:
logger.error(f"DOCX解析失败: {e}")
raise
return text
@staticmethod
def parse_text(file_path: str) -> str:
"""解析纯文本文件"""
try:
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
logger.info(f"文本文件解析完成: {file_path}")
return text
except UnicodeDecodeError:
# 尝试其他编码
with open(file_path, 'r', encoding='gbk') as file:
text = file.read()
logger.info(f"文本文件解析完成(GBK): {file_path}")
return text
@staticmethod
def parse_markdown(file_path: str) -> str:
"""解析Markdown文件"""
with open(file_path, 'r', encoding='utf-8') as file:
md_text = file.read()
# 转换为纯文本(保留结构)
html = markdown.markdown(md_text)
soup = BeautifulSoup(html, 'html.parser')
text = soup.get_text()
logger.info(f"Markdown解析完成: {file_path}")
return text
def parse_html(self, file_path: str) -> str:
"""解析HTML文件"""
with open(file_path, 'r', encoding='utf-8') as file:
html_text = file.read()
soup = BeautifulSoup(html_text, 'html.parser')
# 移除script和style标签
for script in soup(["script", "style"]):
script.decompose()
text = soup.get_text()
text = self.clean_text(text)
logger.info(f"HTML解析完成: {file_path}")
return text
@staticmethod
def parse_xlsx(file_path: str) -> str:
"""
优化版:输出与原Excel完全一致的可视化对齐表格
自动计算列宽,空单元格保留,AI友好格式
"""
text = ""
try:
excel_file = pd.ExcelFile(file_path)
sheet_names = excel_file.sheet_names
logger.info(f"Excel 工作表: {sheet_names}")
for sheet_name in sheet_names:
# 完全按原始行列读取
df = pd.read_excel(file_path, sheet_name=sheet_name, header=None, dtype=str)
text += f"\n===== 工作表:{sheet_name} =====\n"
if df.empty:
text += "(空表)\n"
continue
# 转为二维列表,空值处理为空字符串
rows = []
for _, row in df.iterrows():
cells = [str(val).strip() if pd.notna(val) else "" for val in row]
rows.append(cells)
# 计算每列最大宽度
col_count = max(len(row) for row in rows) if rows else 0
col_widths = [0] * col_count
for row in rows:
for idx, cell in enumerate(row):
if idx < col_count and len(cell) > col_widths[idx]:
col_widths[idx] = len(cell)
# 生成对齐表格行
for row in rows:
row_str = []
for idx, cell in enumerate(row):
if idx < col_count:
# 左对齐,保证列整齐
row_str.append(cell.ljust(col_widths[idx]))
text += " | ".join(row_str) + "\n"
logger.info(f"Excel 解析完成: {file_path}")
except Exception as e:
logger.error(f"Excel 解析失败: {e}")
raise
return text
@staticmethod
def clean_text(text: str) -> str:
"""
清理文本:不破坏表格对齐结构
"""
# 只合并连续空行,不影响表格
text = re.sub(r'\n\s*\n', '\n\n', text)
return text.strip()
def split_text(self, text: str) -> List[str]:
"""
将文本分块
Args:
text: 原始文本
Returns:
文本块列表
"""
chunks = []
if len(text) <= self.chunk_size:
return [text]
paragraphs = text.split('\n\n')
current_chunk = ""
for paragraph in paragraphs:
if len(current_chunk) + len(paragraph) > self.chunk_size:
if current_chunk:
chunks.append(current_chunk.strip())
if len(paragraph) > self.chunk_size:
sentences = re.split(r'([。!?!?])', paragraph)
temp_chunk = ""
for part in sentences:
if len(temp_chunk) + len(part) > self.chunk_size:
if temp_chunk:
chunks.append(temp_chunk.strip())
temp_chunk = part
else:
temp_chunk += part
current_chunk = temp_chunk
else:
current_chunk = paragraph
else:
current_chunk = current_chunk + "\n\n" + paragraph if current_chunk else paragraph
if current_chunk:
chunks.append(current_chunk.strip())
logger.info(f"文本分块完成: 原始长度 {len(text)}, 分块数 {len(chunks)}")
return chunks
def set_chunk_params(self, chunk_size: int, chunk_overlap: int):
"""设置分块参数"""
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlapapp/utils/text_splitter.py
"""
文本切片工具模块
将长文本切分成适合向量化的短文本块
"""
import re
import logging
from typing import List, Optional
from app.config import settings
logger = logging.getLogger(__name__)
class TextSplitter:
"""
文本切片器
支持多种切片策略
"""
def __init__(
self,
chunk_size: int = 500,
chunk_overlap: int = 50,
separators: Optional[List[str]] = None
):
"""
初始化文本切片器
Args:
chunk_size: 切片大小(字符数)
chunk_overlap: 切片重叠大小
separators: 分隔符列表,按优先级排序
"""
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.separators = separators or ["\n\n", "\n", "。", "!", "?", ";", ",", " ", ""]
def split_by_separator(self, text: str, separator: str) -> List[str]:
"""使用分隔符分割文本"""
if separator == "":
# 按字符分割
return list(text)
# 使用正则表达式分割,保留分隔符
pattern = re.escape(separator)
parts = re.split(f'({pattern})', text)
# 将分隔符合并回原文本
chunks = []
for i in range(0, len(parts), 2):
if i + 1 < len(parts):
chunks.append(parts[i] + parts[i + 1])
else:
chunks.append(parts[i])
return [chunk for chunk in chunks if chunk.strip()]
def merge_chunks(self, chunks: List[str], separator: str) -> str:
"""合并文本块"""
return separator.join(chunks)
def split_text(self, text: str) -> List[str]:
"""
将文本切分成多个块
Args:
text: 原始文本
Returns:
文本块列表
"""
if not text:
return []
# 如果文本长度小于切片大小,直接返回
if len(text) <= self.chunk_size:
return [text]
chunks = []
current_chunk = ""
# 尝试使用不同的分隔符进行分割
for separator in self.separators:
if not current_chunk:
# 使用当前分隔符分割
splits = self.split_by_separator(text, separator)
# 合并小的块
for split in splits:
if len(current_chunk) + len(split) <= self.chunk_size:
current_chunk += split
else:
# 当前块已满,保存
if current_chunk:
chunks.append(current_chunk.strip())
# 如果split本身超过chunk_size,需要进一步分割
if len(split) > self.chunk_size:
# 递归分割长块
sub_chunks = self.split_text(split)
chunks.extend(sub_chunks)
current_chunk = ""
else:
current_chunk = split
# 处理剩余的块
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = ""
# 如果成功分割出多个块,返回
if len(chunks) > 1:
break
# 如果没有成功分割,使用固定大小分割
if not chunks:
chunks = self.fixed_size_split(text)
# 添加重叠
if self.chunk_overlap > 0 and len(chunks) > 1:
chunks = self.add_overlap(chunks)
logger.info(f"文本切片完成,共生成 {len(chunks)} 个块")
return chunks
def fixed_size_split(self, text: str) -> List[str]:
"""固定大小分割"""
chunks = []
for i in range(0, len(text), self.chunk_size - self.chunk_overlap):
chunk = text[i:i + self.chunk_size]
if chunk:
chunks.append(chunk)
return chunks
def add_overlap(self, chunks: List[str]) -> List[str]:
"""为相邻的块添加重叠内容"""
overlapped_chunks = []
for i, chunk in enumerate(chunks):
if i == 0:
overlapped_chunks.append(chunk)
else:
# 从前一个块中获取重叠部分
prev_chunk = chunks[i - 1]
overlap_text = prev_chunk[-self.chunk_overlap:] if len(prev_chunk) > self.chunk_overlap else prev_chunk
# 将重叠部分添加到当前块开头
overlapped_chunk = overlap_text + chunk
overlapped_chunks.append(overlapped_chunk)
return overlapped_chunks
def split_document(self, content: str, metadata: dict = None) -> List[dict]:
"""
分割文档并返回带元数据的块
Args:
content: 文档内容
metadata: 文档元数据
Returns:
带元数据的块列表,每个块包含text和metadata
"""
chunks = self.split_text(content)
result = []
for i, chunk in enumerate(chunks):
chunk_metadata = {
"chunk_index": i,
"chunk_count": len(chunks),
**metadata
} if metadata else {"chunk_index": i}
result.append({
"text": chunk,
"metadata": chunk_metadata
})
return result
# 使用配置创建全局切片器实例
text_splitter = TextSplitter(
chunk_size=settings.chunk_size,
chunk_overlap=settings.chunk_overlap
)4.7 Embedding服务
"""
app/services/embedding_service.py
向量化服务模块
使用Sentence Transformers将文本转换为向量
"""
import logging
from typing import List, Union
import numpy as np
from sentence_transformers import SentenceTransformer
from app.config import settings
logger = logging.getLogger(__name__)
class EmbeddingService:
"""
文本向量化服务
将文本转换为高维向量表示
"""
def __init__(self):
"""初始化Embedding模型"""
self.model_name = settings.embedding_model_name
self.device = settings.embedding_device
try:
# 加载模型
self.model = SentenceTransformer(self.model_name, device=self.device)
logger.info(f"Embedding模型加载成功: {self.model_name}, 设备: {self.device}")
# 获取向量维度
self.dimension = self.model.get_sentence_embedding_dimension()
logger.info(f"向量维度: {self.dimension}")
except Exception as e:
logger.error(f"加载Embedding模型失败: {e}")
raise
def embed_text(self, text: str) -> List[float]:
"""
将单个文本转换为向量
Args:
text: 输入文本
Returns:
向量列表
"""
try:
# 模型要求输入为列表
embedding = self.model.encode([text], convert_to_numpy=True)
return embedding[0].tolist()
except Exception as e:
logger.error(f"文本向量化失败: {e}")
raise
def embed_texts(self, texts: List[str]) -> List[List[float]]:
"""
批量将文本转换为向量
Args:
texts: 文本列表
Returns:
向量列表的列表
"""
try:
embeddings = self.model.encode(texts, convert_to_numpy=True)
return embeddings.tolist()
except Exception as e:
logger.error(f"批量文本向量化失败: {e}")
raise
def compute_similarity(self, text1: str, text2: str) -> float:
"""
计算两个文本的相似度
Args:
text1: 文本1
text2: 文本2
Returns:
余弦相似度,范围[-1, 1]
"""
try:
embedding1 = self.embed_text(text1)
embedding2 = self.embed_text(text2)
# 计算余弦相似度
vec1 = np.array(embedding1)
vec2 = np.array(embedding2)
cosine_sim = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
return float(cosine_sim)
except Exception as e:
logger.error(f"计算相似度失败: {e}")
return 0.0
def get_model_info(self) -> dict:
"""获取模型信息"""
return {
"model_name": self.model_name,
"dimension": self.dimension,
"device": self.device,
"max_sequence_length": self.model.get_max_seq_length()
}
# 创建全局Embedding服务实例
embedding_service = EmbeddingService()4.8 大模型服务
"""
app/services/llm_service.py
大模型调用服务模块
支持多种大模型API的统一调用接口
"""
import logging
import json
from typing import List, Dict, Any, Optional
import httpx
from openai import OpenAI
from app.config import settings
logger = logging.getLogger(__name__)
class LLMService:
"""
大模型服务基类
定义统一的调用接口
"""
def __init__(self, provider: str = None):
self.provider = provider or settings.llm_provider
self._init_client()
def _init_client(self):
"""根据配置初始化客户端"""
if self.provider == "openai":
if not settings.openai_api_key:
raise ValueError("OpenAI API密钥未配置")
self.client = OpenAI(
api_key=settings.openai_api_key,
base_url=settings.openai_base_url
)
self.model = settings.openai_model
elif self.provider == "zhipu":
# 智谱AI配置
if not settings.zhipu_api_key:
raise ValueError("智谱AI API密钥未配置")
from zhipuai import ZhipuAI
self.client = ZhipuAI(api_key=settings.zhipu_api_key)
self.model = settings.zhipu_model
elif self.provider == "qwen":
# 阿里千问配置
if not settings.qwen_api_key:
raise ValueError("千问API密钥未配置")
self.client = OpenAI(
api_key=settings.qwen_api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
self.model = settings.qwen_model
else:
raise ValueError(f"不支持的LLM提供商: {self.provider}")
logger.info(f"大模型客户端初始化成功,提供商: {self.provider}, 模型: {self.model}")
def chat(
self,
messages: List[Dict[str, str]],
temperature: float = 0.7,
max_tokens: int = 2000,
**kwargs
) -> str:
"""
调用大模型进行对话
Args:
messages: 消息列表,格式为[{"role": "user", "content": "..."}]
temperature: 温度参数,控制随机性
max_tokens: 最大生成token数
**kwargs: 其他参数
Returns:
模型生成的回复文本
"""
try:
if self.provider == "openai":
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
**kwargs
)
return response.choices[0].message.content
elif self.provider == "zhipu":
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
**kwargs
)
return response.choices[0].message.content
elif self.provider == "qwen":
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
**kwargs
)
return response.choices[0].message.content
else:
raise ValueError(f"不支持的LLM提供商: {self.provider}")
except Exception as e:
logger.error(f"调用大模型失败: {e}")
raise
def stream_chat(
self,
messages: List[Dict[str, str]],
temperature: float = 0.7,
**kwargs
):
"""
流式对话,返回生成器
Args:
messages: 消息列表
temperature: 温度参数
**kwargs: 其他参数
Yields:
生成的文本片段
"""
try:
if self.provider == "openai":
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
stream=True,
**kwargs
)
for chunk in response:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
elif self.provider == "zhipu":
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
stream=True,
**kwargs
)
for chunk in response:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
elif self.provider == "qwen":
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
temperature=temperature,
stream=True,
**kwargs
)
for chunk in response:
if chunk.choices[0].delta.content:
yield chunk.choices[0].delta.content
except Exception as e:
logger.error(f"流式调用大模型失败: {e}")
yield f"错误: {str(e)}"
def get_model_info(self) -> Dict[str, Any]:
"""获取模型信息"""
return {
"provider": self.provider,
"model": self.model,
"available": True
}
# 创建全局LLM服务实例
llm_service = LLMService()4.9 RAG核心服务
"""
app/services/rag_service.py
RAG核心服务模块
整合检索和生成,实现检索增强生成
"""
import logging
import uuid
from typing import List, Dict, Any, Optional, Tuple
from sqlalchemy.orm import Session
from app.services.embedding_service import embedding_service
from app.services.llm_service import llm_service
from app.core.vector_store import vector_store
from app.models.document import Document, DocumentChunk, DocumentStatus
from app.models.conversation import Conversation, Message
from app.config import settings
logger = logging.getLogger(__name__)
class RAGService:
"""
检索增强生成服务
实现完整的RAG流程
"""
def __init__(self):
self.top_k = settings.top_k
self.similarity_threshold = settings.similarity_threshold
def retrieve(
self,
query: str,
top_k: int = None,
similarity_threshold: float = None,
filter_condition: Optional[Dict] = None
) -> List[Dict[str, Any]]:
"""
检索相关文档片段
Args:
query: 查询文本
top_k: 返回结果数量
similarity_threshold: 相似度阈值
filter_condition: 过滤条件
Returns:
检索结果列表
"""
top_k = top_k or self.top_k
threshold = similarity_threshold or self.similarity_threshold
try:
# 1. 将查询文本向量化
query_vector = embedding_service.embed_text(query)
# 2. 在向量数据库中检索
results = vector_store.search(
query_embedding=query_vector,
top_k=top_k,
where=filter_condition
)
# 3. 过滤低于阈值的结果
filtered_results = []
for result in results:
# 距离转相似度(余弦距离转余弦相似度)
similarity = 1 - result['distance']
if similarity >= threshold:
filtered_results.append({
**result,
'similarity': similarity
})
logger.info(f"检索完成,查询: {query[:50]}..., 找到 {len(filtered_results)} 个相关片段")
return filtered_results
except Exception as e:
logger.error(f"检索失败: {e}")
return []
def build_prompt(
self,
query: str,
context: List[Dict[str, Any]],
conversation_history: Optional[List[Dict[str, str]]] = None
) -> List[Dict[str, str]]:
"""
构建提示词
Args:
query: 用户问题
context: 检索到的上下文
conversation_history: 对话历史
Returns:
消息列表
"""
# 系统提示词
system_prompt = """你是一个专业的技术文档助手,你的职责是基于提供的文档内容回答用户的问题。
请遵循以下规则:
1. 只根据提供的文档内容回答问题,不要使用你自己的知识
2. 如果文档中没有相关信息,请明确告知用户"未找到相关信息"
3. 回答要准确、简洁、有条理,可以使用列表形式
4. 如果引用文档内容,请标注来源
5. 回答使用中文
提供的参考文档:
"""
# 添加上下文
context_text = ""
for i, ctx in enumerate(context, 1):
doc_name = ctx.get('metadata', {}).get('filename', '未知文档')
content = ctx.get('document', '')
context_text += f"\n[{i}] 来源:{doc_name}\n{content}\n"
system_prompt += context_text
messages = [{"role": "system", "content": system_prompt}]
# 添加对话历史
if conversation_history:
for msg in conversation_history:
messages.append(msg)
# 添加当前问题
messages.append({"role": "user", "content": query})
return messages
def generate_answer(
self,
query: str,
context: List[Dict[str, Any]],
conversation_history: Optional[List[Dict[str, str]]] = None,
temperature: float = 0.7
) -> str:
"""
生成答案
Args:
query: 用户问题
context: 检索到的上下文
conversation_history: 对话历史
temperature: 生成温度
Returns:
生成的答案
"""
try:
# 构建提示词
messages = self.build_prompt(query, context, conversation_history)
# 调用大模型
answer = llm_service.chat(
messages=messages,
temperature=temperature,
max_tokens=2000
)
logger.info(f"答案生成成功,长度: {len(answer)}")
return answer
except Exception as e:
logger.error(f"生成答案失败: {e}")
return f"生成答案时出错: {str(e)}"
def chat(
self,
question: str,
conversation_id: Optional[int] = None,
db: Session = None,
top_k: int = None,
temperature: float = 0.7
) -> Tuple[str, List[Dict], int, int]:
"""
完整的问答流程
Args:
question: 用户问题
conversation_id: 对话ID
db: 数据库会话
top_k: 检索数量
temperature: 生成温度
Returns:
(答案, 来源列表, 对话ID, 消息ID)
"""
# 1. 检索相关文档
retrieved_docs = self.retrieve(question, top_k)
# 2. 获取对话历史
conversation_history = []
if conversation_id and db:
# 获取最近的对话历史
messages = db.query(Message).filter(
Message.conversation_id == conversation_id
).order_by(Message.created_at.desc()).limit(10).all()
# 反转顺序
messages.reverse()
for msg in messages:
conversation_history.append({
"role": msg.role,
"content": msg.content
})
# 3. 生成答案
answer = self.generate_answer(
query=question,
context=retrieved_docs,
conversation_history=conversation_history,
temperature=temperature
)
# 4. 保存对话记录
if db:
# 如果没有对话ID,创建新对话
if not conversation_id:
conversation = Conversation()
conversation.title = question[:50] # 使用问题前50字作为标题
db.add(conversation)
db.flush()
conversation_id = conversation.id
# 保存用户消息
user_message = Message(
conversation_id=conversation_id,
role="user",
content=question
)
db.add(user_message)
db.flush()
# 保存助手消息
import json
sources = []
for doc in retrieved_docs:
sources.append({
"document_id": doc.get('metadata', {}).get('document_id'),
"document_name": doc.get('metadata', {}).get('filename', '未知'),
"content": doc.get('document', ''),
"similarity": doc.get('similarity', 0)
})
assistant_message = Message(
conversation_id=conversation_id,
role="assistant",
content=answer,
sources=json.dumps(sources, ensure_ascii=False)
)
db.add(assistant_message)
db.flush()
db.commit()
message_id = assistant_message.id
# 5. 格式化来源返回
formatted_sources = []
for doc in retrieved_docs:
formatted_sources.append({
"document_id": doc.get('metadata', {}).get('document_id'),
"document_name": doc.get('metadata', {}).get('filename', '未知'),
"chunk_id": doc.get('metadata', {}).get('chunk_id'),
"content": doc.get('document', ''),
"similarity": doc.get('similarity', 0)
})
return answer, formatted_sources, conversation_id, message_id if db else None
# 创建全局RAG服务实例
rag_service = RAGService()4.10 异步任务处理
"""
app/task/tasks.py
Celery异步任务模块
处理文档上传后的耗时操作
"""
import os
import uuid
import logging
from celery import Celery
from sqlalchemy.orm import Session
from app.config import settings
from app.core.database import SessionLocal
from app.models.document import Document, DocumentChunk, DocumentStatus
from app.utils.file_parser import FileParser
from app.utils.text_splitter import text_splitter
from app.services.embedding_service import embedding_service
from app.core.vector_store import vector_store
from app.core.database import engine
logger = logging.getLogger(__name__)
# 创建Celery应用
celery_app = Celery(
"rag_ai_tasks",
broker=settings.celery_broker_url,
backend=settings.celery_result_backend
)
# 配置Celery
celery_app.conf.update(
task_serializer='json',
accept_content=['json'],
result_serializer='json',
timezone='Asia/Shanghai',
enable_utc=True,
task_track_started=True,
task_time_limit=30 * 60, # 30分钟超时
task_soft_time_limit=25 * 60, # 25分钟软超时
)
@celery_app.task(bind=True, name="process_document")
def process_document(self, document_id: int):
"""
异步处理文档任务
Args:
document_id: 文档ID
"""
db = SessionLocal()
try:
# 1. 获取文档信息
document = db.query(Document).filter(Document.id == document_id).first()
if not document:
logger.error(f"文档不存在: {document_id}")
return {"error": "文档不存在"}
# 更新状态为处理中
document.status = DocumentStatus.PROCESSING
db.commit()
logger.info(f"开始处理文档: {document.filename}, ID: {document_id}")
# 2. 解析文件内容
content = FileParser.parse_file(document.file_path, document.file_type)
if not content:
raise ValueError("文件内容为空")
logger.info(f"文档解析成功,内容长度: {len(content)}")
# 3. 文本切片
chunks = text_splitter.split_document(
content,
metadata={
"document_id": document.id,
"filename": document.filename,
"file_type": document.file_type
}
)
if not chunks:
raise ValueError("文本切片失败,未生成任何切片")
logger.info(f"文本切片完成,共 {len(chunks)} 个切片")
# 4. 生成向量并存储
texts = [chunk["text"] for chunk in chunks]
embeddings = embedding_service.embed_texts(texts)
# 准备向量数据库数据
vector_ids = []
metadatas = []
for i, (chunk, embedding) in enumerate(zip(chunks, embeddings)):
vector_id = f"doc_{document.id}_chunk_{i}_{uuid.uuid4().hex[:8]}"
vector_ids.append(vector_id)
# 添加chunk_id到元数据
metadata = {
**chunk["metadata"],
"chunk_id": i,
"vector_id": vector_id
}
metadatas.append(metadata)
# 保存到数据库
chunk_record = DocumentChunk(
document_id=document.id,
chunk_index=i,
content=chunk["text"],
vector_id=vector_id
)
db.add(chunk_record)
# 存储到向量数据库
success = vector_store.add_documents(
ids=vector_ids,
embeddings=embeddings,
metadatas=metadatas,
documents=texts
)
if not success:
raise ValueError("向量存储失败")
# 5. 更新文档状态
document.status = DocumentStatus.COMPLETED
document.chunks_count = len(chunks)
db.commit()
logger.info(f"文档处理完成: {document.filename}, 切片数: {len(chunks)}")
return {
"success": True,
"document_id": document_id,
"chunks_count": len(chunks)
}
except Exception as e:
logger.error(f"文档处理失败: {e}")
# 更新文档状态为失败
try:
document = db.query(Document).filter(Document.id == document_id).first()
if document:
document.status = DocumentStatus.FAILED
document.error_message = str(e)
db.commit()
except Exception as db_error:
logger.error(f"更新文档状态失败: {db_error}")
return {
"success": False,
"document_id": document_id,
"error": str(e)
}
finally:
db.close()
@celery_app.task(name="delete_document")
def delete_document(document_id: int):
"""
异步删除文档任务
删除文档相关的所有数据,包括向量数据库中的记录
Args:
document_id: 文档ID
"""
db = SessionLocal()
try:
# 1. 获取文档的切片
chunks = db.query(DocumentChunk).filter(
DocumentChunk.document_id == document_id
).all()
# 2. 从向量数据库中删除
vector_ids = [chunk.vector_id for chunk in chunks if chunk.vector_id]
if vector_ids:
vector_store.delete_documents(vector_ids)
# 3. 删除数据库记录
db.query(DocumentChunk).filter(
DocumentChunk.document_id == document_id
).delete()
db.query(Document).filter(Document.id == document_id).delete()
db.commit()
logger.info(f"文档删除成功: {document_id}")
return {
"success": True,
"document_id": document_id
}
except Exception as e:
logger.error(f"文档删除失败: {e}")
db.rollback()
return {
"success": False,
"document_id": document_id,
"error": str(e)
}
finally:
db.close()4.11 API接口实现
"""
app/api/v1/documents.py
文档管理API接口
提供文档的上传、查询、删除等功能
"""
import os
import shutil
import uuid
from typing import List
from fastapi import APIRouter, Depends, HTTPException, UploadFile, File, Query
from sqlalchemy.orm import Session
from app.core.database import get_db
from app.models.document import Document, DocumentStatus
from app.models.schemas import (
DocumentInfo, DocumentDetail, DocumentUploadResponse,
DocumentChunkInfo
)
from app.core.tasks import process_document, delete_document
from app.config import settings
import logging
logger = logging.getLogger(__name__)
router = APIRouter(prefix="/documents", tags=["文档管理"])
@router.post("/upload", response_model=DocumentUploadResponse)
async def upload_document(
file: UploadFile = File(...),
db: Session = Depends(get_db)
):
"""
上传文档
"""
# 1. 验证文件类型
filename = file.filename
ext = os.path.splitext(filename)[1].lower()
if ext not in settings.allowed_extensions:
raise HTTPException(
status_code=400,
detail=f"不支持的文件类型,仅支持: {', '.join(settings.allowed_extensions)}"
)
# 2. 验证文件大小
file_size = 0
content = await file.read()
file_size = len(content)
if file_size > settings.max_file_size:
raise HTTPException(
status_code=400,
detail=f"文件大小超过限制,最大: {settings.max_file_size / 1024 / 1024}MB"
)
# 3. 保存文件
upload_dir = "uploads"
os.makedirs(upload_dir, exist_ok=True)
# 生成唯一文件名
unique_filename = f"{uuid.uuid4().hex}_{filename}"
file_path = os.path.join(upload_dir, unique_filename)
with open(file_path, "wb") as f:
f.write(content)
# 4. 创建文档记录
document = Document(
filename=filename,
file_path=file_path,
file_size=file_size,
file_type=ext,
title=filename, # 默认标题为文件名
status=DocumentStatus.PENDING
)
db.add(document)
db.commit()
db.refresh(document)
# 5. 触发异步处理任务
process_document.delay(document.id)
logger.info(f"文档上传成功: {filename}, ID: {document.id}")
return DocumentUploadResponse(
id=document.id,
filename=filename,
status=document.status.value,
message="文档已上传,正在后台处理中"
)
@router.get("/", response_model=List[DocumentInfo])
async def get_documents(
skip: int = Query(0, ge=0),
limit: int = Query(20, ge=1, le=100),
status: str = None,
db: Session = Depends(get_db)
):
"""
获取文档列表
"""
query = db.query(Document)
if status:
query = query.filter(Document.status == status)
documents = query.order_by(Document.create_time.desc()).offset(skip).limit(limit).all()
return [
DocumentInfo(
id=doc.id,
filename=doc.filename,
title=doc.title,
file_size=doc.file_size,
status=doc.status.value,
chunks_count=doc.chunks_count,
create_time=doc.create_time,
update_time=doc.update_time
)
for doc in documents
]
@router.get("/{document_id}", response_model=DocumentDetail)
async def get_document(
document_id: int,
db: Session = Depends(get_db)
):
"""
获取文档详情
"""
document = db.query(Document).filter(Document.id == document_id).first()
if not document:
raise HTTPException(status_code=404, detail="文档不存在")
# 增加查看次数
document.view_count += 1
db.commit()
return DocumentDetail(
id=document.id,
filename=document.filename,
title=document.title,
author=document.author,
file_size=document.file_size,
file_type=document.file_type,
status=document.status.value,
error_message=document.error_message,
chunks_count=document.chunks_count,
create_time=document.create_time,
update_time=document.update_time
)
@router.get("/{document_id}/chunks", response_model=List[DocumentChunkInfo])
async def get_document_chunks(
document_id: int,
skip: int = Query(0, ge=0),
limit: int = Query(20, ge=1, le=100),
db: Session = Depends(get_db)
):
"""
获取文档的切片列表
"""
from app.models.document import DocumentChunk
document = db.query(Document).filter(Document.id == document_id).first()
if not document:
raise HTTPException(status_code=404, detail="文档不存在")
chunks = db.query(DocumentChunk).filter(
DocumentChunk.document_id == document_id
).order_by(DocumentChunk.chunk_index).offset(skip).limit(limit).all()
return [
DocumentChunkInfo(
id=chunk.id,
chunk_index=chunk.chunk_index,
content=chunk.content,
document_id=chunk.document_id
)
for chunk in chunks
]
@router.delete("/{document_id}")
async def delete_document_api(
document_id: int,
db: Session = Depends(get_db)
):
"""
删除文档
"""
document = db.query(Document).filter(Document.id == document_id).first()
if not document:
raise HTTPException(status_code=404, detail="文档不存在")
# 触发异步删除任务
delete_document.delay(document_id)
logger.info(f"文档删除任务已触发: {document_id}")
return {
"success": True,
"message": "文档删除任务已触发"
}app/api/v1/chat.py
"""
智能问答API接口
提供问答、对话管理等接口
"""
from typing import List, Optional
from fastapi import APIRouter, Depends, HTTPException, Query
from sqlalchemy.orm import Session
from app.core.database import get_db
from app.models.conversation import Conversation, Message
from app.models.schemas import (
ChatRequest, ChatResponse, SourceDocument,
ConversationInfo, MessageInfo
)
from app.services.rag_service import rag_service
import logging
logger = logging.getLogger(__name__)
router = APIRouter(prefix="/chat", tags=["智能问答"])
@router.post("/ask", response_model=ChatResponse)
async def ask_question(
request: ChatRequest,
db: Session = Depends(get_db)
):
"""
问答接口
"""
try:
# 调用RAG服务
answer, sources, conversation_id, message_id = rag_service.chat(
question=request.question,
conversation_id=request.conversation_id,
db=db,
top_k=request.top_k,
temperature=request.temperature
)
# 格式化来源
formatted_sources = [
SourceDocument(
document_id=src["document_id"],
document_name=src["document_name"],
chunk_id=src["chunk_id"],
content=src["content"][:500], # 限制来源内容长度
similarity=src["similarity"]
)
for src in sources
]
return ChatResponse(
answer=answer,
sources=formatted_sources,
conversation_id=conversation_id,
message_id=message_id
)
except Exception as e:
logger.error(f"问答失败: {e}")
raise HTTPException(status_code=500, detail=str(e))
@router.get("/conversations", response_model=List[ConversationInfo])
async def get_conversations(
skip: int = Query(0, ge=0),
limit: int = Query(20, ge=1, le=100),
db: Session = Depends(get_db)
):
"""
获取对话列表
"""
conversations = db.query(Conversation).order_by(
Conversation.updated_at.desc()
).offset(skip).limit(limit).all()
return [
ConversationInfo(
id=conv.id,
title=conv.title,
created_at=conv.created_at,
updated_at=conv.updated_at
)
for conv in conversations
]
@router.get("/conversations/{conversation_id}", response_model=List[MessageInfo])
async def get_conversation_messages(
conversation_id: int,
db: Session = Depends(get_db)
):
"""
获取对话的消息历史
"""
conversation = db.query(Conversation).filter(
Conversation.id == conversation_id
).first()
if not conversation:
raise HTTPException(status_code=404, detail="对话不存在")
messages = db.query(Message).filter(
Message.conversation_id == conversation_id
).order_by(Message.created_at).all()
return [
MessageInfo(
id=msg.id,
role=msg.role,
content=msg.content,
sources=msg.sources,
created_at=msg.created_at
)
for msg in messages
]
@router.delete("/conversations/{conversation_id}")
async def delete_conversation(
conversation_id: int,
db: Session = Depends(get_db)
):
"""
删除对话
"""
conversation = db.query(Conversation).filter(
Conversation.id == conversation_id
).first()
if not conversation:
raise HTTPException(status_code=404, detail="对话不存在")
db.delete(conversation)
db.commit()
return {"success": True, "message": "对话已删除"}app/api/v1/knowledge.py
"""
知识库管理API接口
提供知识库统计、搜索等功能
"""
from fastapi import APIRouter, Depends, HTTPException
from sqlalchemy.orm import Session
from app.core.database import get_db
from app.models.document import Document, DocumentStatus
from app.models.schemas import KnowledgeBaseStats, SearchRequest, SearchResult
from app.services.rag_service import rag_service
from app.core.vector_store import vector_store
import logging
logger = logging.getLogger(__name__)
router = APIRouter(prefix="/knowledge", tags=["知识库管理"])
@router.get("/stats", response_model=KnowledgeBaseStats)
async def get_knowledge_base_stats(
db: Session = Depends(get_db)
):
"""
获取知识库统计信息
"""
total_documents = db.query(Document).count()
completed_documents = db.query(Document).filter(
Document.status == DocumentStatus.COMPLETED
).count()
failed_documents = db.query(Document).filter(
Document.status == DocumentStatus.FAILED
).count()
processing_documents = db.query(Document).filter(
Document.status == DocumentStatus.PROCESSING
).count()
# 获取向量数据库统计
vector_stats = vector_store.get_collection_stats()
return KnowledgeBaseStats(
total_documents=total_documents,
total_chunks=vector_stats.get('document_count', 0),
completed_documents=completed_documents,
failed_documents=failed_documents,
processing_documents=processing_documents
)
@router.post("/search", response_model=List[SearchResult])
async def search_knowledge(
request: SearchRequest,
db: Session = Depends(get_db)
):
"""
知识库搜索
"""
try:
results = rag_service.retrieve(
query=request.query,
top_k=request.top_k,
similarity_threshold=request.similarity_threshold
)
search_results = []
for result in results:
search_results.append(
SearchResult(
content=result['document'],
document_id=result.get('metadata', {}).get('document_id'),
document_name=result.get('metadata', {}).get('filename', '未知'),
chunk_id=result.get('metadata', {}).get('chunk_id'),
similarity=result.get('similarity', 0)
)
)
return search_results
except Exception as e:
logger.error(f"知识库搜索失败: {e}")
raise HTTPException(status_code=500, detail=str(e))app/main.py
"""
FastAPI应用入口
"""
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
from fastapi.staticfiles import StaticFiles
import logging
from app.config import settings
from app.core.database import init_database
from app.api.v1 import documents, chat, knowledge
# 配置日志
logging.basicConfig(
level=logging.INFO if not settings.debug else logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# 创建FastAPI应用
app = FastAPI(
title=settings.app_name,
version=settings.app_version,
description="基于RAG架构的智能问答系统API",
docs_url="/docs" if settings.debug else None,
redoc_url="/redoc" if settings.debug else None
)
# 配置CORS
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境应配置具体域名
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 注册路由
app.include_router(documents.router, prefix="/api/v1")
app.include_router(chat.router, prefix="/api/v1")
app.include_router(knowledge.router, prefix="/api/v1")
# 挂载静态文件
app.mount("/static", StaticFiles(directory="static"), name="static")
@app.on_event("startup")
async def startup_event():
"""应用启动时的初始化"""
logger.info("正在启动应用...")
# 初始化数据库
init_database()
logger.info("应用启动完成")
@app.on_event("shutdown")
async def shutdown_event():
"""应用关闭时的清理"""
logger.info("应用正在关闭...")
@app.get("/")
async def root():
"""根路径"""
return {
"name": settings.app_name,
"version": settings.app_version,
"status": "running"
}
@app.get("/health")
async def health_check():
"""健康检查"""
return {"status": "healthy"}五、客户端编码
5.1 项目结构
rag-ai-system-frontend/
├── public/
│ └── index.html
├── src/
│ ├── assets/ # 静态资源
│ ├── components/ # 组件
│ │ ├── chat/
│ │ │ ├── ChatWindow.vue # 聊天窗口
│ │ │ ├── MessageItem.vue # 消息项
│ │ │ └── SourcePanel.vue # 来源面板
│ │ ├── document/
│ │ │ ├── DocumentList.vue # 文档列表
│ │ │ ├── DocumentUpload.vue # 文档上传
│ │ │ └── DocumentDetail.vue # 文档详情
│ │ └── common/
│ │ ├── Loading.vue # 加载组件
│ │ └── MarkdownRenderer.vue # Markdown渲染
│ ├── views/
│ │ ├── ChatView.vue # 问答页面
│ │ ├── DocumentsView.vue # 文档管理页面
│ │ └── KnowledgeView.vue # 知识库管理页面
│ ├── router/
│ │ └── index.js # 路由配置
│ ├── stores/
│ │ ├── chat.js # 对话状态管理
│ │ ├── document.js # 文档状态管理
│ │ └── knowledge.js # 知识库状态管理
│ ├── api/
│ │ ├── chat.js # 问答API
│ │ ├── document.js # 文档API
│ │ └── knowledge.js # 知识库API
│ ├── utils/
│ │ ├── request.js # Axios封装
│ │ └── markdown.js # Markdown工具
│ ├── App.vue
│ └── main.js
├── package.json
├── vite.config.js
└── .env.development5.2 环境配置
.env.development
VITE_API_BASE_URL=http://localhost:8000/api/v1
VITE_WS_URL=ws://localhost:8000/wspackage.json
{
"name": "rag-ai-system-frontend",
"version": "1.0.0",
"type": "module",
"scripts": {
"dev": "vite",
"build": "vite build",
"preview": "vite preview"
},
"dependencies": {
"vue": "^3.3.8",
"vue-router": "^4.2.5",
"pinia": "^2.1.7",
"axios": "^1.6.2",
"element-plus": "^2.4.3",
"@element-plus/icons-vue": "^2.1.0",
"markdown-it": "^13.0.2",
"highlight.js": "^11.9.0",
"dayjs": "^1.11.10"
},
"devDependencies": {
"@vitejs/plugin-vue": "^4.5.0",
"vite": "^5.0.0"
}
}vite.config.js
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
import path from 'path'
export default defineConfig({
plugins: [vue()],
resolve: {
alias: {
'@': path.resolve(__dirname, './src')
}
},
server: {
port: 3000,
proxy: {
'/api': {
target: 'http://localhost:8000',
changeOrigin: true
}
}
}
})5.3 主入口文件
src/main.js
import { createApp } from 'vue'
import { createPinia } from 'pinia'
import ElementPlus from 'element-plus'
import 'element-plus/dist/index.css'
import * as ElementPlusIconsVue from '@element-plus/icons-vue'
import App from './App.vue'
import router from './router'
const app = createApp(App)
// 注册Element Plus图标
for (const [key, component] of Object.entries(ElementPlusIconsVue)) {
app.component(key, component)
}
app.use(createPinia())
app.use(router)
app.use(ElementPlus)
app.mount('#app')src/App.vue
<template>
<div id="app">
<el-container>
<el-header>
<div class="header-content">
<h1>
<el-icon><ChatDotRound /></el-icon>
RAG智能问答系统
</h1>
<div class="nav">
<el-menu mode="horizontal" :router="true">
<el-menu-item index="/chat">
<el-icon><ChatLineRound /></el-icon>
智能问答
</el-menu-item>
<el-menu-item index="/documents">
<el-icon><Document /></el-icon>
文档管理
</el-menu-item>
<el-menu-item index="/knowledge">
<el-icon><DataAnalysis /></el-icon>
知识库管理
</el-menu-item>
</el-menu>
</div>
</div>
</el-header>
<el-main>
<router-view />
</el-main>
</el-container>
</div>
</template>
<script setup>
import { ChatDotRound, ChatLineRound, Document, DataAnalysis } from '@element-plus/icons-vue'
</script>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
#app {
height: 100vh;
display: flex;
flex-direction: column;
}
.el-header {
background-color: #409EFF;
color: white;
padding: 0;
box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
}
.header-content {
display: flex;
align-items: center;
justify-content: space-between;
height: 100%;
padding: 0 20px;
}
.header-content h1 {
font-size: 20px;
display: flex;
align-items: center;
gap: 10px;
}
.el-menu--horizontal {
background-color: transparent;
border-bottom: none;
}
.el-menu--horizontal .el-menu-item {
color: white;
}
.el-menu--horizontal .el-menu-item.is-active {
color: white;
border-bottom-color: white;
}
.el-main {
background-color: #f5f7fa;
padding: 20px;
overflow-y: auto;
}
</style>5.4 API封装
src/utils/request.js
import axios from 'axios'
import { ElMessage } from 'element-plus'
// 创建axios实例
const request = axios.create({
baseURL: import.meta.env.VITE_API_BASE_URL,
timeout: 60000,
headers: {
'Content-Type': 'application/json'
}
})
// 请求拦截器
request.interceptors.request.use(
config => {
// 可以在这里添加token等认证信息
return config
},
error => {
return Promise.reject(error)
}
)
// 响应拦截器
request.interceptors.response.use(
response => {
return response.data
},
error => {
const message = error.response?.data?.detail || error.message || '请求失败'
ElMessage.error(message)
return Promise.reject(error)
}
)
export default requestsrc/api/chat.js
import request from '@/utils/request'
/**
* 问答接口
* @param {Object} data - 请求数据
* @returns {Promise}
*/
export const askQuestion = (data) => {
return request.post('/chat/ask', data)
}
/**
* 获取对话列表
* @param {Object} params - 分页参数
* @returns {Promise}
*/
export const getConversations = (params) => {
return request.get('/chat/conversations', { params })
}
/**
* 获取对话消息
* @param {number} conversationId - 对话ID
* @returns {Promise}
*/
export const getConversationMessages = (conversationId) => {
return request.get(`/chat/conversations/${conversationId}`)
}
/**
* 删除对话
* @param {number} conversationId - 对话ID
* @returns {Promise}
*/
export const deleteConversation = (conversationId) => {
return request.delete(`/chat/conversations/${conversationId}`)
}src/api/document.js
import request from '@/utils/request'
/**
* 上传文档
* @param {FormData} formData - 表单数据
* @returns {Promise}
*/
export const uploadDocument = (formData) => {
return request.post('/documents/upload', formData, {
headers: {
'Content-Type': 'multipart/form-data'
}
})
}
/**
* 获取文档列表
* @param {Object} params - 查询参数
* @returns {Promise}
*/
export const getDocuments = (params) => {
return request.get('/documents/', { params })
}
/**
* 获取文档详情
* @param {number} id - 文档ID
* @returns {Promise}
*/
export const getDocumentDetail = (id) => {
return request.get(`/documents/${id}`)
}
/**
* 获取文档切片
* @param {number} id - 文档ID
* @param {Object} params - 分页参数
* @returns {Promise}
*/
export const getDocumentChunks = (id, params) => {
return request.get(`/documents/${id}/chunks`, { params })
}
/**
* 删除文档
* @param {number} id - 文档ID
* @returns {Promise}
*/
export const deleteDocument = (id) => {
return request.delete(`/documents/${id}`)
}src/api/knowledge.js
import request from '@/utils/request'
/**
* 获取知识库统计
* @returns {Promise}
*/
export const getKnowledgeStats = () => {
return request.get('/knowledge/stats')
}
/**
* 搜索知识库
* @param {Object} data - 搜索参数
* @returns {Promise}
*/
export const searchKnowledge = (data) => {
return request.post('/knowledge/search', data)
}5.5 状态管理
src/stores/chat.js
import { defineStore } from 'pinia'
import { ref } from 'vue'
import { askQuestion, getConversations, getConversationMessages } from '@/api/chat'
export const useChatStore = defineStore('chat', () => {
// 状态
const conversations = ref([])
const currentConversation = ref(null)
const messages = ref([])
const loading = ref(false)
// 发送消息
const sendMessage = async (question, conversationId = null, temperature = 0.7) => {
loading.value = true
try {
const res = await askQuestion({
question,
conversation_id: conversationId,
temperature
})
// 添加用户消息
messages.value.push({
id: Date.now(),
role: 'user',
content: question,
created_at: new Date().toISOString()
})
// 添加助手消息
messages.value.push({
id: res.message_id,
role: 'assistant',
content: res.answer,
sources: res.sources,
created_at: new Date().toISOString()
})
// 更新当前对话ID
if (!currentConversation.value || currentConversation.value.id !== res.conversation_id) {
currentConversation.value = {
id: res.conversation_id,
title: question.slice(0, 50)
}
// 刷新对话列表
await fetchConversations()
}
return res
} finally {
loading.value = false
}
}
// 获取对话列表
const fetchConversations = async () => {
try {
const res = await getConversations({ skip: 0, limit: 50 })
conversations.value = res
} catch (error) {
console.error('获取对话列表失败:', error)
}
}
// 加载对话消息
const loadConversation = async (conversationId) => {
try {
const res = await getConversationMessages(conversationId)
messages.value = res
currentConversation.value = conversations.value.find(c => c.id === conversationId)
} catch (error) {
console.error('加载对话失败:', error)
}
}
// 清空当前对话
const clearCurrentConversation = () => {
currentConversation.value = null
messages.value = []
}
return {
conversations,
currentConversation,
messages,
loading,
sendMessage,
fetchConversations,
loadConversation,
clearCurrentConversation
}
})5.6 核心组件实现
src/components/chat/ChatWindow.vue
<template>
<div class="chat-window">
<div class="messages-container" ref="messagesContainer">
<div v-if="messages.length === 0" class="empty-state">
<el-icon :size="64"><ChatDotRound /></el-icon>
<h3>开始对话</h3>
<p>输入您的问题,我将从知识库中为您寻找答案</p>
</div>
<MessageItem
v-for="message in messages"
:key="message.id"
:message="message"
/>
<div v-if="loading" class="loading-message">
<el-skeleton animated>
<template #template>
<el-skeleton-item variant="text" style="width: 80%" />
<el-skeleton-item variant="text" style="width: 60%" />
</template>
</el-skeleton>
</div>
</div>
<div class="input-area">
<el-input
v-model="inputText"
type="textarea"
:rows="3"
placeholder="请输入您的问题..."
:disabled="loading"
@keydown.ctrl.enter="send"
/>
<div class="input-actions">
<div class="settings">
<el-slider
v-model="temperature"
:min="0"
:max="2"
:step="0.1"
:format-tooltip="formatTemperature"
style="width: 200px"
/>
<span class="label">温度: {{ temperature }}</span>
</div>
<el-button
type="primary"
:loading="loading"
@click="send"
>
发送
</el-button>
</div>
</div>
</div>
</template>
<script setup>
import { ref, nextTick, watch } from 'vue'
import { useChatStore } from '@/stores/chat'
import MessageItem from './MessageItem.vue'
import { ChatDotRound } from '@element-plus/icons-vue'
const chatStore = useChatStore()
const messages = chatStore.messages
const loading = chatStore.loading
const inputText = ref('')
const temperature = ref(0.7)
const messagesContainer = ref(null)
// 发送消息
const send = async () => {
if (!inputText.value.trim() || loading.value) return
const question = inputText.value
inputText.value = ''
await chatStore.sendMessage(
question,
chatStore.currentConversation?.id,
temperature.value
)
// 滚动到底部
await nextTick()
scrollToBottom()
}
// 滚动到底部
const scrollToBottom = () => {
if (messagesContainer.value) {
messagesContainer.value.scrollTop = messagesContainer.value.scrollHeight
}
}
// 格式化温度显示
const formatTemperature = (val) => {
return `随机性: ${val}`
}
// 监听消息变化,自动滚动
watch(messages, () => {
nextTick(() => {
scrollToBottom()
})
}, { deep: true })
</script>
<style scoped>
.chat-window {
display: flex;
flex-direction: column;
height: 100%;
background: white;
border-radius: 8px;
overflow: hidden;
}
.messages-container {
flex: 1;
overflow-y: auto;
padding: 20px;
}
.empty-state {
text-align: center;
padding: 60px 20px;
color: #909399;
}
.empty-state .el-icon {
font-size: 64px;
margin-bottom: 20px;
}
.empty-state h3 {
margin-bottom: 10px;
color: #606266;
}
.input-area {
border-top: 1px solid #e4e7ed;
padding: 20px;
background: #f5f7fa;
}
.input-actions {
display: flex;
justify-content: space-between;
align-items: center;
margin-top: 12px;
}
.settings {
display: flex;
align-items: center;
gap: 12px;
}
.settings .label {
font-size: 12px;
color: #909399;
}
.loading-message {
padding: 12px;
background: #f5f7fa;
border-radius: 8px;
margin: 10px 0;
max-width: 70%;
}
</style>src/components/chat/MessageItem.vue
<template>
<div class="message-item" :class="message.role">
<div class="message-avatar">
<el-avatar :size="40">
<el-icon v-if="message.role === 'user'"><User /></el-icon>
<el-icon v-else><Service /></el-icon>
</el-avatar>
</div>
<div class="message-content">
<div class="message-header">
<span class="role-name">{{ message.role === 'user' ? '我' : 'AI助手' }}</span>
<span class="time">{{ formatTime(message.created_at) }}</span>
</div>
<div class="message-body">
<MarkdownRenderer :content="message.content" />
<!-- 来源信息 -->
<div v-if="message.sources && message.sources.length" class="sources">
<el-divider content-position="left">
<el-icon><Link /></el-icon>
参考来源
</el-divider>
<SourcePanel :sources="message.sources" />
</div>
</div>
</div>
</div>
</template>
<script setup>
import { User, Service, Link } from '@element-plus/icons-vue'
import MarkdownRenderer from '@/components/common/MarkdownRenderer.vue'
import SourcePanel from './SourcePanel.vue'
import dayjs from 'dayjs'
const props = defineProps({
message: {
type: Object,
required: true
}
})
const formatTime = (time) => {
if (!time) return ''
return dayjs(time).format('HH:mm:ss')
}
</script>
<style scoped>
.message-item {
display: flex;
margin-bottom: 20px;
animation: fadeIn 0.3s ease;
}
@keyframes fadeIn {
from {
opacity: 0;
transform: translateY(10px);
}
to {
opacity: 1;
transform: translateY(0);
}
}
.message-item.user {
flex-direction: row-reverse;
}
.message-item.user .message-content {
background: #409EFF;
color: white;
margin-right: 12px;
margin-left: 60px;
}
.message-item.assistant .message-content {
background: #f5f7fa;
margin-left: 12px;
margin-right: 60px;
}
.message-avatar {
flex-shrink: 0;
}
.message-content {
flex: 1;
border-radius: 12px;
padding: 12px 16px;
word-wrap: break-word;
}
.message-header {
display: flex;
justify-content: space-between;
margin-bottom: 8px;
font-size: 12px;
}
.message-item.user .message-header {
color: rgba(255, 255, 255, 0.8);
}
.message-item.assistant .message-header {
color: #909399;
}
.role-name {
font-weight: bold;
}
.message-body {
line-height: 1.6;
}
.sources {
margin-top: 12px;
font-size: 12px;
}
.message-item.user .sources {
color: rgba(255, 255, 255, 0.8);
}
</style>src/components/chat/SourcePanel.vue
<template>
<div class="source-panel">
<div
v-for="(source, index) in sources"
:key="index"
class="source-item"
>
<div class="source-header">
<el-icon><Document /></el-icon>
<span class="source-name">{{ source.document_name }}</span>
<el-tag size="small" type="info">
相似度: {{ (source.similarity * 100).toFixed(1) }}%
</el-tag>
</div>
<div class="source-content">
{{ truncateContent(source.content, 200) }}
</div>
<div class="source-actions">
<el-button
size="small"
text
@click="showFullContent(source)"
>
查看详情
</el-button>
</div>
</div>
<!-- 详情对话框 -->
<el-dialog
v-model="dialogVisible"
title="参考来源详情"
width="60%"
>
<div class="dialog-content">
<div class="dialog-meta">
<p><strong>文档名称:</strong> {{ currentSource?.document_name }}</p>
<p><strong>相似度:</strong> {{ currentSource ? (currentSource.similarity * 100).toFixed(1) + '%' : '' }}</p>
</div>
<el-divider />
<div class="dialog-text">
{{ currentSource?.content }}
</div>
</div>
</el-dialog>
</div>
</template>
<script setup>
import { ref } from 'vue'
import { Document } from '@element-plus/icons-vue'
const props = defineProps({
sources: {
type: Array,
default: () => []
}
})
const dialogVisible = ref(false)
const currentSource = ref(null)
const truncateContent = (content, maxLength) => {
if (!content) return ''
if (content.length <= maxLength) return content
return content.slice(0, maxLength) + '...'
}
const showFullContent = (source) => {
currentSource.value = source
dialogVisible.value = true
}
</script>
<style scoped>
.source-panel {
margin-top: 8px;
}
.source-item {
background: rgba(255, 255, 255, 0.5);
border-radius: 8px;
padding: 12px;
margin-bottom: 8px;
border-left: 3px solid #409EFF;
}
.source-header {
display: flex;
align-items: center;
gap: 8px;
margin-bottom: 8px;
flex-wrap: wrap;
}
.source-name {
font-weight: bold;
font-size: 13px;
color: #409EFF;
}
.source-content {
font-size: 12px;
color: #606266;
line-height: 1.5;
margin-bottom: 8px;
word-break: break-all;
}
.source-actions {
text-align: right;
}
.dialog-content {
max-height: 500px;
overflow-y: auto;
}
.dialog-meta {
margin-bottom: 16px;
}
.dialog-meta p {
margin: 8px 0;
}
.dialog-text {
white-space: pre-wrap;
line-height: 1.6;
font-size: 14px;
}
</style>六、总结
通过本文的完整实现,我们从零构建了一个功能完整的企业级RAG智能问答系统。整个项目涵盖了前后端开发的各个环节,展示了如何将理论知识转化为实际可用的产品。让我们回顾一下本项目的主要成果和收获。
6.1 适合场景
- 企业知识库:整合公司内部文档、规章制度、产品手册
- 客服机器人:基于产品FAQ和操作手册构建智能客服
- 技术文档助手:帮助开发者快速查找API文档和技术方案
- 法律文书检索:在法律文档库中快速定位相关条款
- 医疗知识问答:基于医学文献和临床指南构建辅助系统
6.2 优化方向
虽然当前系统已经具备完整功能,但仍有优化空间:
6.2.1 性能优化
- 实现向量检索的缓存机制
- 使用GPU加速Embedding计算
- 优化大模型调用的并发处理
6.2.2 检索质量提升
- 引入混合检索(向量检索+关键词检索)
- 实现重排序(Rerank)机制
- 添加查询改写和意图识别
6.2.3 功能增强
- 支持更多文档格式(Excel、PPT、图片OCR)
- 实现文档自动摘要
- 添加用户反馈和模型微调功能
6.2.4 安全加固
- 添加用户认证和权限管理
- 实现API密钥加密存储
- 增加内容安全过滤
6.3 学习建议
对于想要深入学习RAG技术的读者,建议:
- 理解原理:深入学习Transformer架构、Attention机制、向量检索原理
- 动手实践:尝试修改代码,如添加新的文档解析器、更换Embedding模型
- 关注前沿:关注RAG领域的最新研究,如Self-RAG、RAPTOR等
- 参与开源:贡献代码到开源项目,在实践中提升
结语
RAG技术的出现,为解决大语言模型的知识局限提供了有效途径。通过本文的项目实践,我们不仅掌握了RAG系统的开发技能,更重要的是理解了如何将AI技术落地到实际业务场景中。随着大模型技术的不断发展,RAG架构也将持续演进,相信在不久的将来,会有更多创新的应用场景涌现。
希望本文能够帮助读者建立起RAG系统开发的完整知识体系,并能够在此基础上进行创新和扩展。技术的学习永无止境,让我们保持探索的热情,在AI技术的浪潮中不断前行。
🌟 感谢您耐心阅读到这里!
🚀 技术成长没有捷径,但每一次的阅读、思考和实践,都在默默缩短您与成功的距离。
💡 如果本文对您有所启发,欢迎点赞👍、收藏📌、分享📤给更多需要的伙伴!
🗣️ 期待在评论区看到您的想法、疑问或建议,我会认真回复,让我们共同探讨、一起进步~
🔔 关注我,持续获取更多干货内容!
🤗 我们下篇文章见!
附录
项目源码下载![]() https://download.csdn.net/download/SearchB/92788416
https://download.csdn.net/download/SearchB/92788416
导读
第一章:RAG知识库开发之【LLM的缺陷分析以及具体场景案例分析】
第三章:RAG知识库开发之【RAG系统工作流程详细解析:从数据源到智能问答的全链路实战指南】
第四章:RAG知识库开发之【深入浅出 Naive RAG:从零构建你的第一个检索增强生成系统】
第五章:RAG知识库开发之【利用RAG知识库实现智能AI系统:从零构建企业级智能问答应用】
第六章:RAG知识库开发之【深入浅出RAG使用效果评估:从指标到实践】
第七章:RAG知识库开发之【RAG开源应用完全解析:从RAGFlow到Dify的实战指南】
第八章:RAG知识库开发之【Dify 实现数据库数据智能查询系统:从零构建企业级自然语言查询助手】
第九章:RAG知识库开发之【LangChain 基础入门:从零构建大模型应用】
第十章:RAG知识库开发之【LangSmith 从入门到精通:构建生产级 LLM 应用的全链路可观测性平台】
第十一章:RAG知识库开发之【RAG 的缺陷分析与优化:从入门到实践的完全指南】

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)