Linux 47 UDP协议:数据报传输的核心机制
·
目录
一.传输层
负责数据能够从发送端传输接收端
二.再谈端⼝号
端⼝号(Port)标识了⼀个主机上进⾏通信的不同的应⽤程序;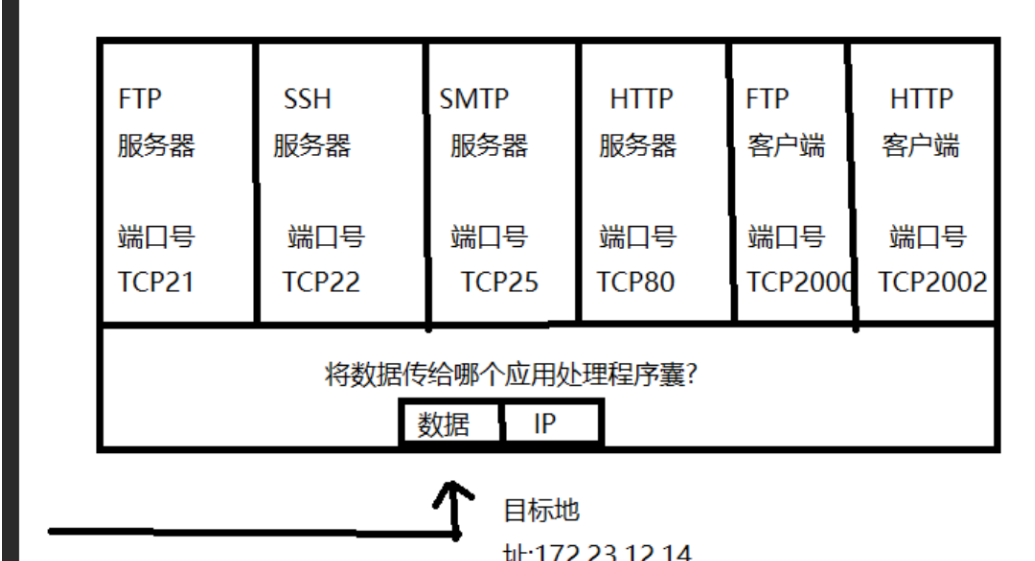
在TCP/IP协议中, ⽤ "源IP", "源端⼝号", "⽬的IP", "⽬的端⼝号", "协议号" 这样⼀个五元组来标识⼀个Z通信(可以通过netstat -n查看);
端⼝号范围划分
• 0 - 1023: 知名端⼝号, HTTP, FTP, SSH等这些⼴为使⽤的应⽤层协议, 他们的端⼝号都是固定的.(我们无法绑定)• 1024 - 65535: 操作系统动态分配的端⼝号. 客⼾端程序的端⼝号, 就是由操作系统从这个范围分配的.
认识知名端⼝号(Well-Know Port Number)
有些服务器是⾮常常⽤的, 为了使⽤⽅便, ⼈们约定⼀些常⽤的服务器, 都是⽤以下这些固定的端⼝号:
• ssh服务器, 使⽤22端⼝• ftp服务器, 使⽤21端⼝• telnet服务器, 使⽤23端⼝• http服务器, 使⽤80端⼝• https服务器, 使⽤443
执⾏下⾯的命令, 可以看到知名端⼝号
cat /etc/services三.UDP协议
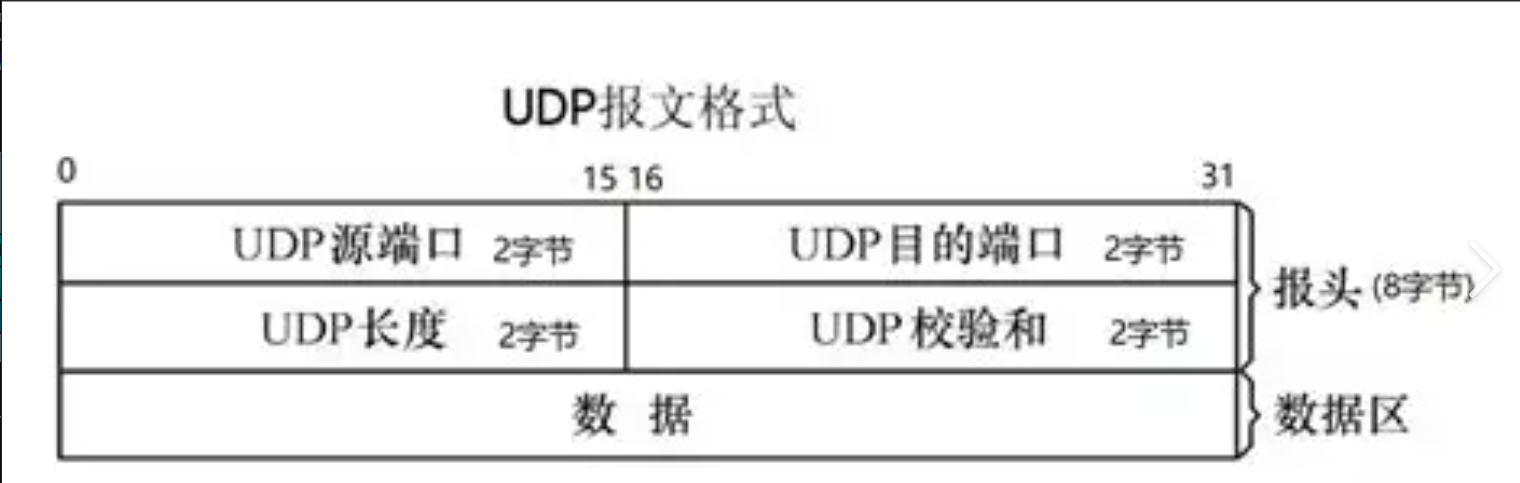
• 16位UDP⻓度, 表⽰整个数据报(UDP⾸部+UDP数据)的最⼤⻓度;
• 如果校验和出错, 就会直接丢弃;
3.1 UDP特点
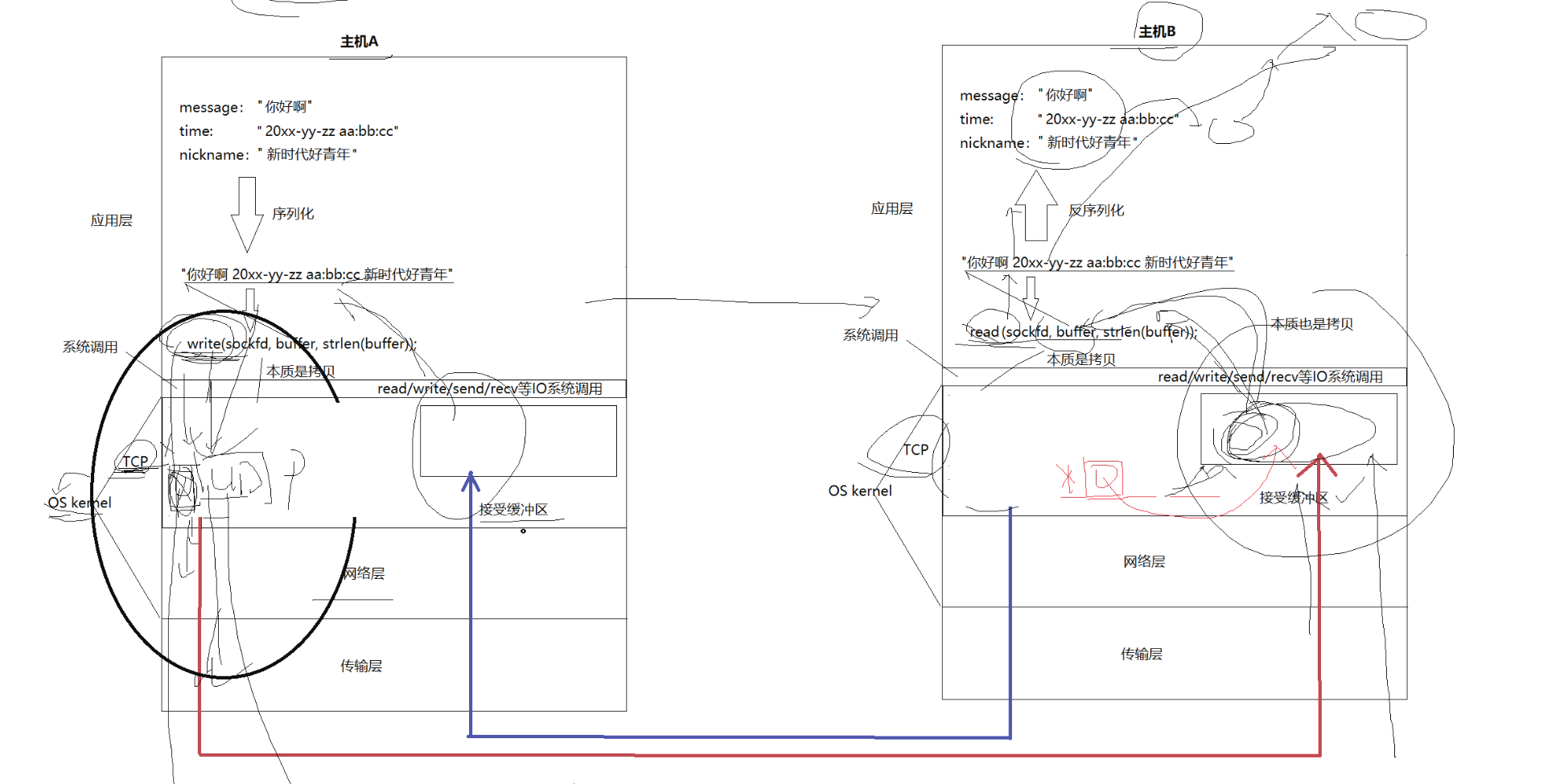
UDP传输的过程类似于寄信.
• ⽆连接: 知道对端的IP和端⼝号就直接进⾏传输, 不需要建⽴连接;
• 不可靠: 没有确认机制, 没有重传机制; 如果因为⽹络故障该段⽆法发到对⽅, UDP协议层也不会给
应⽤层返回任何错误信息;
• ⾯向数据报: 不能够灵活的控制读写数据的次数和数量;
3.2 面向数据报
应⽤层交给UDP多⻓的报⽂, UDP原样发送, 既不会拆分, 也不会合并; ⽤UDP传输100个字节的数据:
• 如果发送端调⽤⼀次sendto, 发送100个字节, 那么接收端也必须调⽤对应的⼀次recvfrom, 接收
100个字节; ⽽不能循环调⽤10次recvfrom, 每次接收10个字节;
3.3UDP的缓存区
• UDP没有真正意义上的 发送缓冲区. 调⽤sendto会直接交给内核, 由内核将数据传给⽹络层协议进⾏后续的传输动作;
• UDP具有接收缓冲区. 但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序⼀
致; 如果缓冲区满了, 再到达的UDP数据就会被丢弃;
UDP的socket既能读, 也能写, 这个概念叫做 全双⼯
根据前面的知识,我们知道UDP是没有写入缓存区的,而UDP也因为它的8字节固定报头及报头带有报文的长度,所以可以数据报读取
3.4管理报文
UDP协议,一个OS内部一定有大量的报文,那么如何管理呢?先描述,再组织
UDP的内部结构体代码
#include <linux/types.h>
#include <linux/socket.h>
#include <linux/netdevice.h>
#include <linux/skbuff.h>
#include <linux/atomic.h>
#include <net/ip.h>
#include <net/udp.h>
#include <net/tcp.h>
#include <net/icmp.h>
#include <net/igmp.h>
#include <net/ipv6.h>
#include <net/arp.h>
#include <net/dst.h>
#include <net/secpath.h>
struct sk_buff {
/* 链表节点:用于将多个sk_buff链接成队列 */
struct sk_buff *next;
struct sk_buff *prev;
/* 关联的套接字(如udp_sock/tcp_sock) */
struct sock *sk;
/* 时间戳(数据包接收/发送时间) */
struct skb_timestamp tstamp;
/* 数据包的输出/输入网卡设备 */
struct net_device *dev;
struct net_device *input_dev;
/* 传输层及以上报头(TCP/UDP/ICMP等) */
union {
struct tcphdr *th; // TCP 报头指针
struct udphdr *uh; // UDP 报头指针
struct icmphdr *icmph; // ICMP 报头指针
struct igmphdr *igmph; // IGMP 报头指针
struct iphdr *iph; // IPv4 报头指针(也可能放在nh)
struct ipv6hdr *ipv6h; // IPv6 报头指针(也可能放在nh)
unsigned char *raw; // 原始字节指针(通用访问)
} h;
/* 网络层报头(IP/ARP等) */
union {
struct iphdr *iph; // IPv4 报头指针
struct ipv6hdr *ipv6h; // IPv6 报头指针
struct arphdr *arph; // ARP 报头指针
unsigned char *raw; // 原始字节指针(通用访问)
} nh;
/* 链路层报头(MAC地址等) */
union {
unsigned char *raw; // 原始字节指针(通用访问)
} mac;
/* 路由相关信息(目的缓存) */
struct dst_entry *dst;
/* 安全路径(用于IPsec等) */
struct sec_path *sp;
/* 以下字段必须在结构体末尾(内存分配相关) */
unsigned int truesize; // sk_buff实际占用的内存大小
atomic_t users; // 引用计数(多模块共享时使用)
unsigned char *head; // 缓冲区起始地址(整个内存空间的头)
unsigned char *data; // 当前数据起始地址(报头/有效载荷的起始)
unsigned char *tail; // 当前数据结束地址(有效载荷的末尾)
unsigned char *end; // 缓冲区结束地址(整个内存空间的尾)
};3.4.1 描述
描述UDP报头的那些属性跳过,我们直接看关于内存描述方面
/* 以下字段必须在结构体末尾(内存分配相关) */
unsigned int truesize; // sk_buff实际占用的内存大小
atomic_t users; // 引用计数(多模块共享时使用)
unsigned char *head; // 缓冲区起始地址(整个内存空间的头)
unsigned char *data; // 当前数据起始地址(报头/有效载荷的起始)
unsigned char *tail; // 当前数据结束地址(有效载荷的末尾)
unsigned char *end; // 缓冲区结束地址(整个内存空间的尾这里的head等四个指针就是关于内存的描述
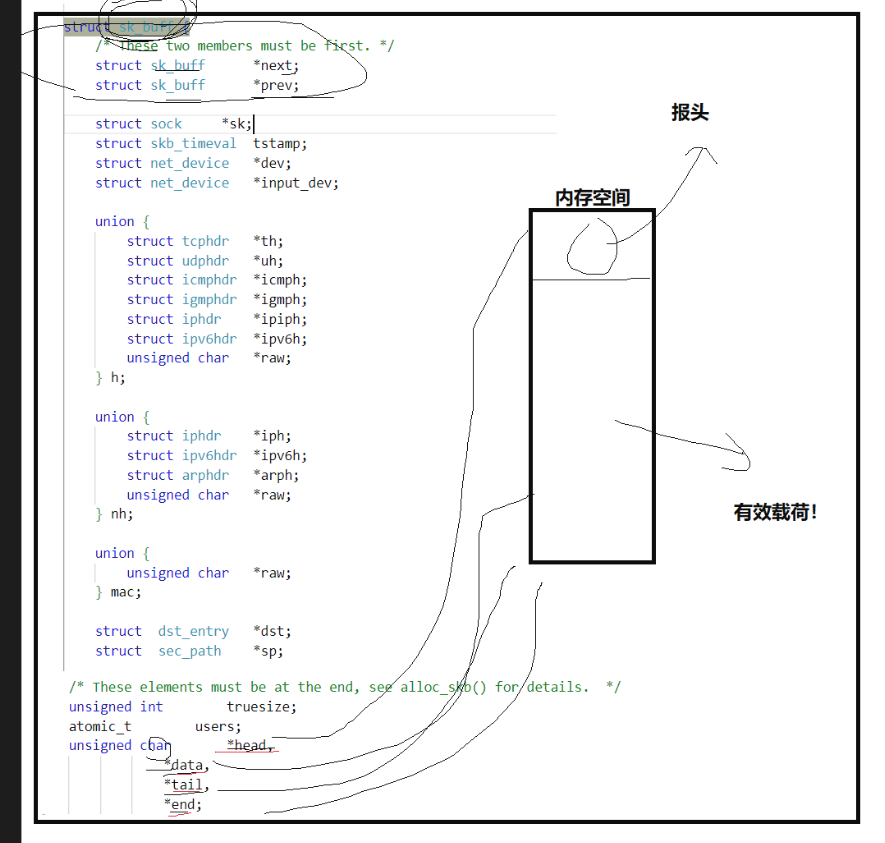
我们可以发现UDP的描述与内存与PCD和进程内存一样
解析head data tail end
head是数据区的起始地址,end是数据区的结束地址,两者之间的区间就是sk_buff分配的整块线性缓冲区的总大小(包含了头空间、各层协议头、应用层数据、尾空间等所有部分)。- 而实际被使用的 “有效数据” 范围,是由
data(有效数据的起始)和tail(有效数据的结束)指针来确定的。简单总结:
head+end→ 缓冲区总容量的边界;data+tail→ 缓冲区中有效数据的边界。
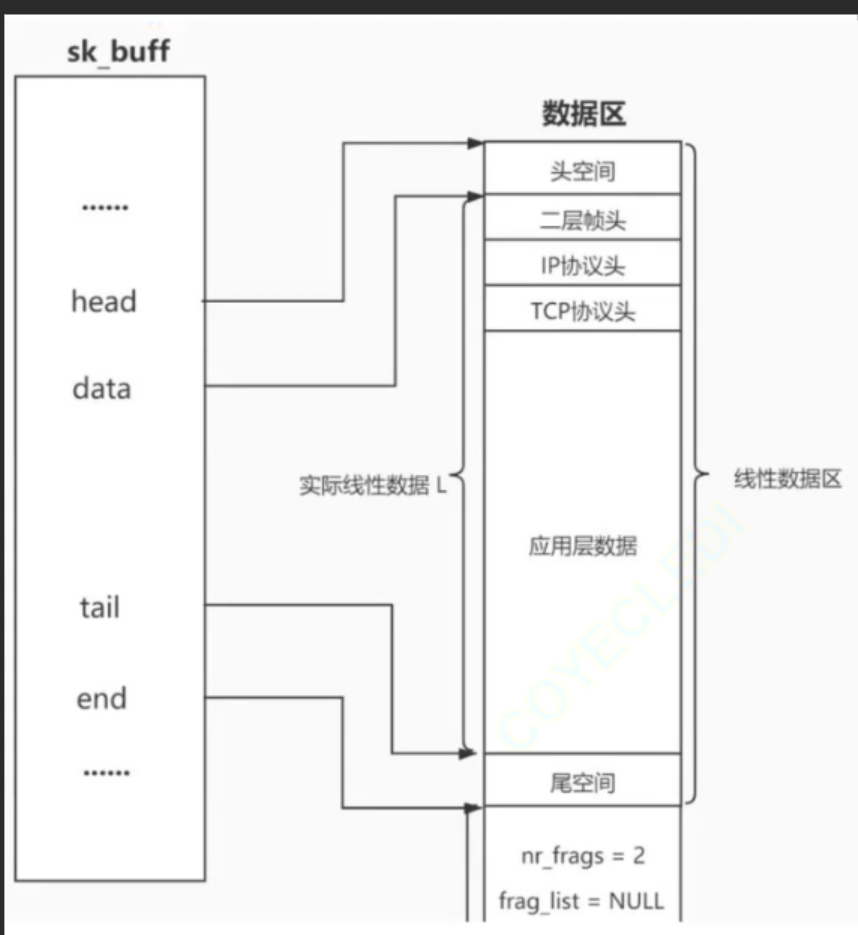
因此当你打包数据,从顶往下封装时,就是data指针在不断移动,封装协议,而接收方解包则是相反的过程

将设我们上面data移动,再强转读取
这里
data强转是为了把缓冲区地址映射成 UDP 协议头的结构体类型,方便直接操作协议头字段。具体原因:
data本身是sk_buff里的字符指针(char *),它指向的是缓冲区的地址,但字符指针只能按字节访问数据;- 而 UDP 协议头是一个结构化的数据(
struct udphdr),包含源端口、目的端口、长度、校验和等字段;- 把
data强转成(struct udphdr *)后,就能以 “结构体成员” 的方式直接读写 UDP 协议头的字段(比如((struct udphdr *)data)->source获取源端口),而不用手动按字节偏移计算位置。
3.4.2 组织
通过next prev两个1指针,将多个sk_buff形成队列,进行管理
/* 链表节点:用于将多个sk_buff链接成队列 */
struct sk_buff *next;
struct sk_buff *prev;
3.5 UDP使⽤注意事项
我们注意到, UDP协议⾸部中有⼀个16位的最⼤⻓度. 也就是说⼀个UDP能传输的数据最⼤⻓度是
64K(包含UDP⾸部).
然⽽64K在当今的互联⽹环境下, 是⼀个⾮常⼩的数字.
如果我们需要传输的数据超过64K, 就需要在应⽤层⼿动的分包, 多次发送, 并在接收端⼿动拼装;
3.6 基于UDP的应⽤层协议
• NFS: ⽹络⽂件系统
• TFTP: 简单⽂件传输协议
• DHCP: 动态主机配置协议
• BOOTP: 启动协议(⽤于⽆盘设备启动)
• DNS: 域名解析协议
🔥个人主页:Milestone-里程碑
❄️个人专栏: <<力扣hot100>> <<C++>><<Linux>>
🌟心向往之行必能至

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)