Elasticsearch与HBase数据同步SEP机制详解
在大数据生态系统中,HBase作为分布式列式存储数据库,广泛应用于海量数据的实时读写场景;而Elasticsearch则以其强大的全文检索和实时分析能力,成为搜索与日志分析的首选引擎。然而,两者之间的数据互通成为系统集成中的关键问题。SEP(Streaming Exchange Protocol)机制正是为解决这一问题而设计的一套高效、可靠的数据同步方案。

简介:在大数据处理中,Elasticsearch和HBase分别以其强大的搜索分析能力和分布式存储优势被广泛应用。为了实现HBase数据实时同步至Elasticsearch,引入了SEP(Search Engine Persistence)机制,其核心依赖于 hbase-indexer 组件。本资料详细解析了SEP机制的工作流程,包括模型配置、变更监听、索引构建与数据传输等模块,并介绍了其数据过滤、批量同步、错误处理与监控告警等高级特性,适用于日志分析、监控系统和推荐系统等实时搜索场景。 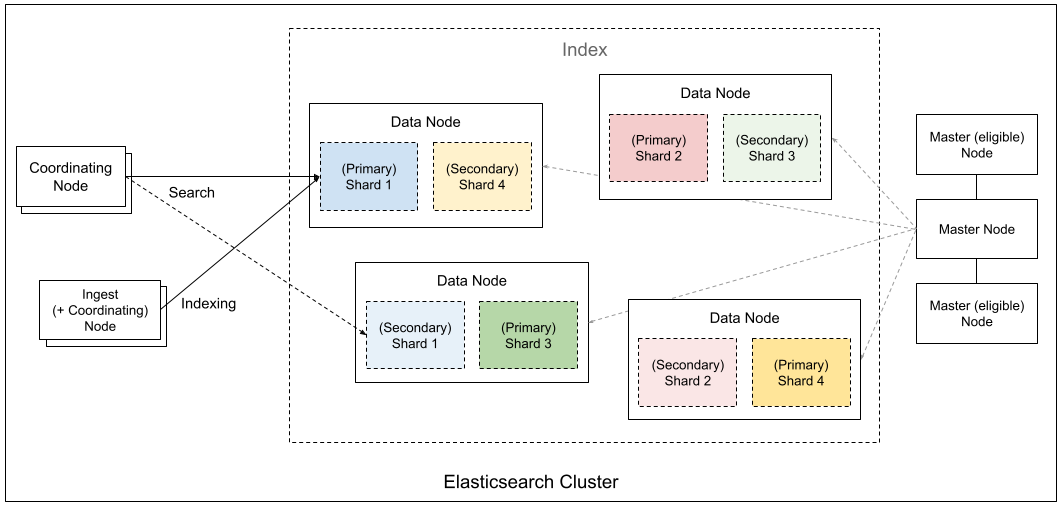
1. SEP机制概述
在大数据生态系统中,HBase作为分布式列式存储数据库,广泛应用于海量数据的实时读写场景;而Elasticsearch则以其强大的全文检索和实时分析能力,成为搜索与日志分析的首选引擎。然而,两者之间的数据互通成为系统集成中的关键问题。SEP(Streaming Exchange Protocol)机制正是为解决这一问题而设计的一套高效、可靠的数据同步方案。
本章将从SEP机制的定义出发,剖析其设计初衷与核心价值,并结合HBase与Elasticsearch之间的数据同步需求,阐述其在现代数据架构中的典型应用场景。同时,还将对SEP的整体架构进行宏观介绍,包括其核心组件与数据流向,为后续章节的技术细节分析奠定基础。
2. HBase与Elasticsearch同步原理
在现代大数据系统中,HBase 和 Elasticsearch 的结合使用日益频繁,尤其在需要实时读写与高效检索的场景下。HBase 提供了高可靠、高扩展的分布式存储能力,而 Elasticsearch 则擅长全文搜索、聚合分析等实时查询需求。将两者结合,能够构建出强大的实时数据平台。然而,如何实现两者之间的数据同步,是整个系统设计的关键环节。本章将从 HBase 与 Elasticsearch 的交互模型、SEP 机制的核心同步逻辑、以及一致性与容错机制三个方面,深入剖析其同步原理。
2.1 HBase与Elasticsearch的交互模型
HBase 与 Elasticsearch 的交互模型,是整个同步机制的起点。理解它们之间的数据流向和通信方式,对于构建高效的数据同步系统至关重要。
2.1.1 数据写入流程与事件触发
HBase 的写入流程基于 WAL(Write-Ahead Log)机制,所有写入操作都会先记录到 WAL 文件中,然后写入 MemStore,最终持久化到 HFile。这一流程确保了数据的持久性和一致性。
在 SEP 机制中,HBase 的写入操作会被监听并转化为事件,触发同步流程。通常,事件触发的方式包括:
- WAL日志监听 :通过读取 HBase 的 WAL 文件,捕获所有写入变更。
- Coprocessor插件 :在 HRegionServer 层面部署 Coprocessor 插件,拦截 Put、Delete 等操作。
- Kafka中间件 :将变更事件发送到 Kafka,由下游消费者进行处理。
以下是一个使用 Coprocessor 拦截 Put 操作的代码示例:
public class SEPEventHandler extends BaseRegionObserver {
@Override
public void postPut(final ObserverContext<RegionCoprocessorEnvironment> e, final Put put, final WALEdit edit, final boolean writeToWAL) {
// 获取 rowkey
byte[] rowKey = put.getRow();
// 获取列族、列名、值
for (Map.Entry<byte[], List<Cell>> entry : put.getFamilyCellMap().entrySet()) {
byte[] family = entry.getKey();
for (Cell cell : entry.getValue()) {
byte[] qualifier = CellUtil.cloneQualifier(cell);
byte[] value = CellUtil.cloneValue(cell);
// 构建事件对象
SEPEvent event = new SEPEvent(rowKey, family, qualifier, value);
// 发送事件到 Kafka 或其他消息队列
SEPEventProducer.send(event);
}
}
}
}
代码逻辑分析:
postPut方法在 HBase 完成 Put 操作后调用。- 获取 Put 操作的 rowkey、列族、列名和值。
- 构建一个
SEPEvent事件对象。 - 调用
SEPEventProducer.send(event)将事件发送到 Kafka 或其他消息中间件,触发后续的同步处理流程。
参数说明:
put.getRow():获取当前写入的 rowkey。put.getFamilyCellMap():获取所有列族与对应 Cell 的映射。CellUtil.cloneQualifier(cell):克隆列名(列限定符)。CellUtil.cloneValue(cell):克隆单元格的值。
2.1.2 同步通道的建立与维护
在 HBase 与 Elasticsearch 之间建立同步通道,通常依赖于消息队列(如 Kafka、RabbitMQ)或直接通过 RPC 通信。SEP 机制中常用的通道包括:
- Kafka Topic :用于解耦写入与消费流程,提升系统的可扩展性和可靠性。
- ZooKeeper :用于协调多个消费者实例,实现负载均衡与故障转移。
- REST API :Elasticsearch 提供 RESTful 接口用于数据写入。
同步通道流程图如下(使用 Mermaid 表示):
graph TD
A[HBase写入] --> B{Coprocessor拦截}
B --> C[提取变更事件]
C --> D[Kafka消息队列]
D --> E[消费者拉取消息]
E --> F{解析事件类型}
F --> G[Elasticsearch索引更新]
F --> H[删除操作处理]
G --> I[确认消费成功]
H --> I
I --> J[提交Offset]
流程说明:
- HBase 写入操作 触发 Coprocessor 拦截。
- Coprocessor 提取变更事件并发送至 Kafka。
- 消费者从 Kafka 拉取消息并解析事件类型(Put/Delete)。
- 根据事件类型执行相应的 Elasticsearch 操作。
- 成功执行后提交 Offset,确保消息不会重复消费。
2.2 SEP机制的核心同步逻辑
SEP(Search-Enabled Platform)机制是一种用于将 HBase 数据同步至 Elasticsearch 的架构。其核心同步逻辑主要包括变更捕获(Change Capture)和数据转换与索引更新策略两个方面。
2.2.1 变更捕获(Change Capture)机制
变更捕获是 SEP 机制的核心模块之一,用于监听 HBase 中的数据变化并生成变更事件。其关键在于如何高效、可靠地捕获到每一次写入、更新或删除操作。
常见的变更捕获方式包括:
| 捕获方式 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| WAL日志解析 | 读取HBase的WAL日志获取变更 | 实时性强,对HBase影响小 | 实现复杂,日志格式易变 |
| Coprocessor插件 | 在RegionServer层面监听事件 | 实时性强,可定制性强 | 需要编写Java代码,维护成本高 |
| Kafka集成 | 通过Kafka中转事件 | 松耦合,可扩展性强 | 增加中间层,延迟略高 |
其中,Coprocessor 插件方式在实际生产中应用最广泛,因其能够直接在 HBase 内部捕获事件,减少数据丢失风险。
以下是一个简单的变更事件对象定义:
public class SEPEvent {
private byte[] rowKey;
private byte[] family;
private byte[] qualifier;
private byte[] value;
private EventType type; // EventType.PUT / EventType.DELETE
public SEPEvent(byte[] rowKey, byte[] family, byte[] qualifier, byte[] value) {
this.rowKey = rowKey;
this.family = family;
this.qualifier = qualifier;
this.value = value;
this.type = EventType.PUT;
}
// Getter and Setter
}
参数说明:
rowKey:HBase 的 rowkey。family:列族。qualifier:列名(列限定符)。value:单元格的值。type:事件类型(如 PUT、DELETE)。
2.2.2 数据转换与索引更新策略
在将 HBase 数据同步至 Elasticsearch 时,需要进行数据结构的转换,并根据业务需求制定索引更新策略。
数据转换过程:
- 字段映射 :将 HBase 的列族、列名映射为 Elasticsearch 的字段名。
- 类型转换 :例如将 byte[] 转换为 String、Integer、Date 等类型。
- 文档构建 :将多个字段组合为一个 JSON 文档。
索引更新策略:
| 策略 | 描述 | 适用场景 |
|---|---|---|
| 单文档单字段 | 每个 HBase 列对应一个 Elasticsearch 字段 | 结构简单,字段明确 |
| 多字段组合文档 | 多个 HBase 列组合为一个文档 | 数据结构复杂,需聚合 |
| 动态字段映射 | 根据列名动态生成字段 | 非结构化数据,列名不固定 |
| 批量更新 | 合并多个变更事件,批量更新索引 | 提高性能,减少请求次数 |
以下是一个字段映射配置的 JSON 示例:
{
"mappings": {
"properties": {
"id": { "type": "keyword" },
"name": { "type": "text" },
"age": { "type": "integer" },
"created_at": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" }
}
}
}
字段说明:
id:映射为 keyword 类型,用于精确查询。name:映射为 text 类型,支持全文搜索。age:整数类型,适合范围查询。created_at:日期类型,支持时间聚合。
2.3 一致性与容错机制
在 HBase 与 Elasticsearch 的同步过程中,保证数据一致性与系统容错能力是至关重要的。任何环节的失败都可能导致数据不一致或丢失,因此需要设计完善的机制来保障系统的可靠性。
2.3.1 状态一致性保障
状态一致性保障主要解决两个问题:
- 数据一致性 :HBase 与 Elasticsearch 中的数据是否一致。
- 事件顺序一致性 :多线程或分布式环境下,事件是否按照 HBase 的写入顺序同步。
解决方案:
- 事务机制 :借助 Kafka 的事务支持,确保每一批数据要么全部提交,要么全部回滚。
- 唯一ID去重 :使用 rowkey 作为文档 ID,确保 Elasticsearch 的更新操作幂等。
- 时间戳排序 :每个事件携带时间戳,消费者按时间排序处理。
以下是一个基于 rowkey 的幂等更新示例:
public class ElasticsearchIndexer {
public void updateDocument(SEPEvent event) {
String id = Bytes.toString(event.getRowKey());
String indexName = "user_index";
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("id", id)
.field("name", Bytes.toString(event.getValue("name")))
.field("age", Bytes.toInt(event.getValue("age")))
.field("created_at", new Date())
.endObject();
IndexRequest request = new IndexRequest(indexName)
.id(id)
.source(builder);
// 使用 upsert 实现幂等更新
UpdateRequest updateRequest = new UpdateRequest(indexName, id)
.doc(builder)
.upsert(request);
client.update(updateRequest, RequestOptions.DEFAULT);
}
}
代码说明:
upsert方法用于在文档不存在时插入新文档,存在时更新内容,实现幂等性。- 使用 rowkey 作为文档 ID,确保每个 HBase 行对应唯一 Elasticsearch 文档。
2.3.2 故障恢复与数据重放机制
在实际运行中,可能会遇到消费者宕机、网络中断、Kafka offset 提交失败等问题。为此,SEP 机制需要具备故障恢复与数据重放的能力。
典型恢复机制:
- Offset 回退 :当消费者失败时,Kafka 可以回退 offset,重新消费消息。
- 断点续传 :记录消费进度,下次启动时从上次中断点继续处理。
- 数据重放 :通过重新读取 HBase WAL 日志或 Kafka 中的历史消息,进行数据补全。
数据重放流程图(使用 Mermaid):
graph LR
A[系统故障] --> B{是否有断点记录}
B -- 有 --> C[从断点恢复]
B -- 无 --> D[从Kafka起始Offset消费]
C --> E[重新同步数据]
D --> E
E --> F[更新Elasticsearch]
流程说明:
- 系统发生故障后,检查是否保存了消费断点。
- 若有断点记录,从该点恢复消费。
- 若无,则从 Kafka 的 earliest offset 开始消费。
- 重新同步数据并更新 Elasticsearch。
本章深入剖析了 HBase 与 Elasticsearch 的交互模型、SEP 机制的核心同步逻辑以及一致性与容错机制,为后续章节中 hbase-indexer 的组件结构与配置打下坚实基础。下一章将聚焦于 hbase-indexer 的模块组成与运行流程,进一步探讨其实现细节。
3. hbase-indexer组件结构解析
在构建 HBase 与 Elasticsearch 实时数据同步系统时, hbase-indexer 是核心组件之一,承担着从 HBase 读取变更事件、转换数据格式并写入 Elasticsearch 的关键任务。为了深入理解其工作机制,本章将从模块组成、运行流程以及配置启动等方面进行全面解析,帮助开发者和运维人员掌握其核心原理与操作细节。
3.1 hbase-indexer的模块组成
hbase-indexer 的设计采用了模块化架构,主要由输入源管理模块、转换处理模块和输出索引模块构成。这种结构设计不仅提高了组件的可维护性,也增强了系统的可扩展性和灵活性。
3.1.1 输入源管理模块
输入源管理模块负责监听 HBase 中的数据变更事件。它通常通过集成 HBase 的 Coprocessor 或读取 WAL(Write-Ahead Log)文件来获取变更数据。模块的主要职责包括:
- 建立与 HBase 集群的连接
- 订阅指定表的变更事件
- 缓冲事件流并进行初步过滤
public class HBaseInputSource {
private Connection hbaseConnection;
private TableName tableName;
private WALReader walReader;
public void startListening() {
walReader = new WALReader(hbaseConnection, tableName);
walReader.registerObserver(this::handleWALEntry);
}
private void handleWALEntry(WALEntry entry) {
// 处理每一个WAL条目
if (isRelevantEntry(entry)) {
Event event = convertToEvent(entry);
forwardToTransform(event);
}
}
}
代码逻辑分析:
HBaseInputSource类负责初始化与 HBase 的连接,并启动对 WAL 日志的监听。startListening方法通过WALReader注册观察者,监听 WAL 条目。handleWALEntry方法处理每一个 WAL 条目,判断是否需要处理,然后将其转换为事件并转发给转换模块。
参数说明:
hbaseConnection:HBase 的连接对象,用于与 HBase 集群通信。tableName:需要监听的 HBase 表名。walReader:用于读取 WAL 日志的组件。entry:代表 WAL 日志中的一个条目。
3.1.2 转换处理模块
转换处理模块的核心功能是将原始的 HBase 数据变更事件转换为适合 Elasticsearch 的文档结构。它通常依赖于一个 JSON 配置文件,定义字段映射规则、数据转换逻辑等。
public class DataTransformer {
private Map<String, String> fieldMapping;
public void loadMapping(String mappingFile) {
// 从文件加载映射规则
fieldMapping = JSON.parseObject(new FileReader(mappingFile), Map.class);
}
public ElasticsearchDocument transform(Event event) {
Map<String, Object> docFields = new HashMap<>();
for (Map.Entry<String, String> entry : fieldMapping.entrySet()) {
String esField = entry.getKey();
String hbaseColumn = entry.getValue();
Object value = event.getColumnValue(hbaseColumn);
docFields.put(esField, value);
}
return new ElasticsearchDocument(docFields);
}
}
代码逻辑分析:
DataTransformer类通过loadMapping方法从配置文件中加载字段映射规则。transform方法接收 HBase 事件对象,根据映射规则提取对应的列值,并构建 Elasticsearch 文档对象。
参数说明:
fieldMapping:字段映射关系,用于将 HBase 列名映射为 Elasticsearch 字段名。event:来自 HBase 的事件对象,包含变更数据。docFields:构建的 Elasticsearch 文档字段集合。
3.1.3 输出索引模块
输出索引模块负责将转换后的文档写入 Elasticsearch。它使用 Elasticsearch 的客户端 API 实现文档的批量提交、索引更新等操作。
public class ElasticsearchOutput {
private RestHighLevelClient client;
private String indexName;
public void submitDocument(ElasticsearchDocument document) {
IndexRequest request = new IndexRequest(indexName)
.source(document.getFields())
.id(document.getId());
try {
client.index(request, RequestOptions.DEFAULT);
} catch (IOException | ElasticsearchException e) {
handleFailure(document, e);
}
}
private void handleFailure(ElasticsearchDocument document, Exception e) {
// 重试机制或写入失败日志
}
}
代码逻辑分析:
ElasticsearchOutput类封装了与 Elasticsearch 的交互逻辑。submitDocument方法构造IndexRequest请求,将文档写入指定索引。- 若提交失败,调用
handleFailure进行异常处理。
参数说明:
client:Elasticsearch 的客户端对象,用于执行索引操作。indexName:目标索引名称。document:待提交的 Elasticsearch 文档对象。request:构建的索引请求对象。
3.1.4 模块间交互流程图
graph TD
A[HBase Input] --> B[Transform]
B --> C[Elasticsearch Output]
C --> D[(提交到ES)]
A --> E[WAL读取]
E --> F[事件解析]
F --> B
该流程图展示了 hbase-indexer 三大模块之间的交互关系,从 HBase 输入事件,到数据转换,再到 Elasticsearch 输出文档的全过程。
3.2 核心组件的运行流程
3.2.1 消费HBase事件流
hbase-indexer 消费 HBase 事件流的过程是其运行的核心步骤之一。该过程通常基于 HBase 的 Coprocessor 或者 WAL 日志读取机制实现。
事件流消费流程如下:
- 连接 HBase 集群 :建立与 HBase 的连接,确保能够读取指定表的 WAL 日志。
- 订阅事件 :通过注册监听器,订阅 HBase 表的变更事件。
- 事件捕获与缓存 :捕获 WAL 日志中的事件,并进行缓存以提高处理效率。
- 事件解析与转发 :解析事件内容,将其转换为通用事件对象并转发给下一流程。
| 阶段 | 描述 | 关键操作 |
|---|---|---|
| 连接阶段 | 建立 HBase 客户端连接 | 初始化 Connection 对象 |
| 监听阶段 | 注册监听器 | 使用 WALReader 注册回调 |
| 缓存阶段 | 缓存事件流 | 使用内存队列或磁盘缓存 |
| 转发阶段 | 事件解析与转发 | 构造事件对象并调用转换模块 |
3.2.2 文档构建与索引提交
一旦事件被转发到转换模块, hbase-indexer 就开始构建 Elasticsearch 文档并提交到索引中。
文档构建与提交流程如下:
- 字段映射解析 :根据配置文件加载字段映射规则。
- 字段提取与转换 :从事件中提取字段值并按照映射规则进行转换。
- 文档构建 :将转换后的字段组合成 Elasticsearch 文档对象。
- 索引提交 :使用 Elasticsearch 客户端将文档提交到目标索引中。
public class IndexingPipeline {
private DataTransformer transformer;
private ElasticsearchOutput output;
public void process(Event event) {
ElasticsearchDocument doc = transformer.transform(event);
output.submitDocument(doc);
}
}
代码逻辑分析:
IndexingPipeline类封装了从事件处理到文档提交的完整流程。process方法接收 HBase 事件,调用转换器生成文档,并提交至 Elasticsearch。
参数说明:
transformer:数据转换模块,负责字段映射和文档构造。output:输出模块,负责将文档提交至 Elasticsearch。event:HBase 变更事件对象。
文档提交策略
| 提交策略 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 实时提交 | 每个文档立即提交 | 延迟低,实时性强 | 吞吐量低,资源消耗高 |
| 批量提交 | 多个文档一起提交 | 吞吐量高,资源利用率高 | 延迟较高 |
| 异步提交 | 异步线程提交文档 | 提高并发性能 | 需要额外处理失败机制 |
3.3 hbase-indexer的配置与启动
3.3.1 配置文件结构解析
hbase-indexer 的配置文件通常采用 JSON 格式,定义输入源、字段映射、输出目标等关键参数。
{
"hbase": {
"zookeeper": "zk1:2181,zk2:2181",
"table": "user_profile"
},
"mapping": {
"name": "cf:name",
"age": "cf:age",
"email": "cf:email"
},
"elasticsearch": {
"hosts": ["es1:9200", "es2:9200"],
"index": "user_profile_index"
},
"batch_size": 100,
"retry_times": 3
}
配置说明:
hbase.zookeeper:HBase 的 Zookeeper 地址列表。hbase.table:需要监听的 HBase 表名。mapping:字段映射关系,左边为 Elasticsearch 字段名,右边为 HBase 列名。elasticsearch.hosts:Elasticsearch 集群节点地址。elasticsearch.index:目标索引名称。batch_size:批量提交文档数量。retry_times:失败重试次数。
3.3.2 服务启动与状态查看
启动 hbase-indexer 服务通常通过命令行执行:
java -jar hbase-indexer.jar --config config.json --start
启动后可通过以下方式查看服务状态:
curl http://localhost:8080/status
返回状态信息示例:
{
"status": "running",
"processed_events": 123456,
"failed_events": 78,
"last_error": "Connection refused to es2:9200",
"uptime": "2h 15m"
}
状态参数说明:
status:服务当前状态(running, stopped, error)processed_events:已处理事件数量failed_events:失败事件数量last_error:最近一次错误信息uptime:服务运行时间
通过本章的深入解析,我们全面了解了 hbase-indexer 的模块组成、运行流程和配置启动方式。下一章我们将进一步探讨如何设计和配置 HBase 与 Elasticsearch 的数据模型与字段映射。
4. 数据模型配置与字段映射
在构建 HBase 与 Elasticsearch 的数据同步系统中, 数据模型配置与字段映射 是决定系统灵活性、查询效率与索引准确性的关键环节。本章将深入探讨在 SEP(Search-Enabled Platform)机制中,如何合理设计数据模型,配置字段映射规则,并通过验证手段确保映射的正确性与稳定性。
4.1 数据模型设计原则
4.1.1 结构化与非结构化数据处理
HBase 本质上是一个面向列的 NoSQL 数据库,其数据模型是稀疏的、多维的键值存储。Elasticsearch 则是一个文档型搜索引擎,擅长处理 JSON 格式的半结构化或非结构化数据。在同步过程中,需要将 HBase 中的列族、列限定符与值结构,映射为 Elasticsearch 的字段结构。
结构化数据处理:
- HBase 中的固定列族(Column Family)和列限定符(Qualifier)可以映射为 Elasticsearch 的固定字段。
- 示例:用户表中的
cf1:username、cf1:email等字段可直接映射为username、email字段。
{
"rowkey": "user_001",
"cf1:username": "john_doe",
"cf1:email": "john@example.com"
}
非结构化数据处理:
- HBase 中的动态列限定符(如
cf1:tag_1,cf1:tag_2)可以映射为 Elasticsearch 的数组或多值字段。 - 可通过字段映射配置将多个列合并为一个数组字段。
{
"rowkey": "user_001",
"cf1:tag_1": "sports",
"cf1:tag_2": "technology"
}
映射结果:
{
"rowkey": "user_001",
"tags": ["sports", "technology"]
}
4.1.2 字段类型与索引策略
在 Elasticsearch 中,字段的类型决定了其是否可被索引、是否支持聚合、是否被分析等行为。合理配置字段类型对搜索性能至关重要。
| HBase 字段类型 | Elasticsearch 映射类型 | 说明 |
|---|---|---|
| String | keyword/text | keyword 用于精确匹配,text 用于全文检索 |
| Integer | integer | 整数类型,支持范围查询 |
| Long | long | 长整型 |
| Double | double | 浮点数 |
| Boolean | boolean | 布尔值 |
| Timestamp | date | 时间戳,支持时间范围查询 |
| JSON 字符串 | object | 可嵌套对象结构 |
字段索引策略建议:
- 对于需要全文检索的字段,使用
text类型并配合analyzer(分析器)。 - 对于精确匹配、聚合、排序等场景,使用
keyword类型。 - 对于多值字段(如标签),使用
text或keyword类型,视查询需求而定。 - 对嵌套对象使用
object类型,避免使用nested类型除非需要跨嵌套对象的查询。
4.2 字段映射的配置方式
4.2.1 JSON配置文件格式
hbase-indexer 使用 JSON 格式的映射文件来定义字段映射规则。其基本结构如下:
{
"name": "user_profile",
"table": "users",
"columnFamilies": [
{
"name": "cf1",
"columns": [
{
"name": "username",
"type": "string",
"target": "username"
},
{
"name": "email",
"type": "string",
"target": "email.keyword"
},
{
"name": "age",
"type": "int",
"target": "age"
}
]
}
]
}
字段说明:
name:映射配置名称。table:对应 HBase 表名。columnFamilies:定义列族及其字段。columns:每个字段的配置项。name:HBase 中的列限定符(Qualifier)。type:字段类型,用于转换数据格式。target:Elasticsearch 中的字段路径,支持嵌套结构。
4.2.2 嵌套字段与多值字段的处理
嵌套字段处理
HBase 的列族和列限定符结构可以通过映射配置生成嵌套字段:
{
"name": "user_profile",
"table": "users",
"columnFamilies": [
{
"name": "cf1",
"columns": [
{
"name": "first_name",
"type": "string",
"target": "name.first"
},
{
"name": "last_name",
"type": "string",
"target": "name.last"
}
]
}
]
}
转换结果:
{
"name": {
"first": "John",
"last": "Doe"
}
}
多值字段处理
当一个列族中包含多个相同语义的列时,可以通过正则匹配合并为一个数组字段:
{
"name": "user_tags",
"table": "users",
"columnFamilies": [
{
"name": "cf1",
"columns": [
{
"name": "tag_.*",
"type": "string",
"target": "tags"
}
]
}
]
}
转换结果:
{
"tags": ["sports", "technology", "reading"]
}
代码逻辑分析:
name: "tag_.*"表示匹配所有以tag_开头的列名。target: "tags"表示将这些列值合并为一个数组字段。- 这种方式适用于动态列结构的映射处理。
4.3 映射验证与测试方法
4.3.1 映射加载与校验流程
在部署 hbase-indexer 前,需对映射文件进行加载与校验,确保字段结构与 Elasticsearch 的索引模板一致。
映射加载流程:
- 读取 JSON 映射文件。
- 解析字段结构,构建字段映射关系。
- 与 Elasticsearch 的索引模板进行比对。
- 若字段类型不一致,输出警告或错误。
- 成功加载后,启动 hbase-indexer 服务。
校验流程图:
graph TD
A[加载JSON映射文件] --> B[解析字段结构]
B --> C{是否与ES模板匹配?}
C -->|是| D[加载成功]
C -->|否| E[输出警告/错误]
D --> F[启动hbase-indexer]
4.3.2 实例测试与结果验证
实例测试流程
- 向 HBase 表中插入测试数据。
- 检查 hbase-indexer 是否捕获到变更事件。
- 验证 Elasticsearch 中是否生成对应的文档。
- 使用 Kibana 或 curl 查询文档内容,验证字段映射是否正确。
测试代码示例:
# 插入HBase测试数据
echo "put 'users', 'user_001', 'cf1:username', 'john_doe'" | hbase shell
# 使用curl查询Elasticsearch文档
curl -X GET "http://localhost:9200/users/_search" | jq
返回结果示例:
{
"took": 15,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "users",
"_type": "_doc",
"_id": "user_001",
"_score": 1.0,
"_source": {
"username": "john_doe",
"email": "john@example.com",
"age": 28,
"tags": ["sports", "technology"]
}
}
]
}
}
验证要点:
- 字段名是否正确映射。
- 字段类型是否匹配。
- 多值字段是否正确合并为数组。
- 嵌套字段结构是否正确生成。
小结
在数据同步系统中, 数据模型配置与字段映射 不仅决定了数据在 Elasticsearch 中的结构,也直接影响了后续的查询性能与灵活性。通过合理的结构设计、字段类型配置、嵌套与多值字段处理,以及严格的映射验证流程,可以确保数据在同步过程中保持一致性与高效性。
在下一章中,我们将进一步深入到 HBase 的变更事件监听机制,探讨如何通过 Coprocessor 和 WAL 日志捕获数据变更事件,为同步系统提供实时性保障。
5. HBase变更事件监听实现
HBase作为分布式列式数据库,其数据变更事件的监听机制是构建实时数据同步系统(如HBase与Elasticsearch同步)的关键环节。本章将深入解析HBase的事件监听机制,重点介绍基于RegionServer和WAL日志的事件捕获方式,并结合Coprocessor组件实现变更事件的捕获与处理。此外,还将探讨事件消息的序列化与传输方式,包括Protobuf格式的使用以及与Kafka等消息队列的集成。
5.1 HBase事件监听机制概述
HBase的事件监听主要依赖于其底层的日志系统(WAL,Write-Ahead Log)和RegionServer的生命周期管理机制。通过监听HBase表的写入、更新和删除操作,系统能够及时捕获数据变更并触发后续的数据同步逻辑。
5.1.1 RegionServer与WAL日志的关系
在HBase中,每一个RegionServer负责管理一组Region。所有写入操作都必须先写入WAL日志,确保在系统崩溃时数据不会丢失。WAL日志记录了所有对HBase表的写操作,是实现数据变更监听的基础。
graph TD
A[Client Write Request] --> B[RegionServer]
B --> C{Write to WAL}
C --> D[Write to MemStore]
D --> E[Flush to HFile]
C --> F[Event Listener Trigger]
图5-1:HBase写入流程与事件监听触发关系图
WAL日志文件存储在HDFS上,其结构为HLog格式,包含多个HLogEntry记录。每条记录代表一次写操作(Put、Delete等)。通过解析WAL日志,可以捕获到HBase表的数据变更事件。
5.1.2 事件捕获的实现方式
HBase提供了多种事件捕获方式,主要包括:
- 使用WAL日志直接解析
- 通过Coprocessor进行事件监听
- 集成HBase Replication机制
| 实现方式 | 优点 | 缺点 |
|---|---|---|
| WAL日志解析 | 实时性强,可获取原始变更数据 | 实现复杂,依赖HDFS访问,需处理日志滚动问题 |
| Coprocessor监听 | 灵活性强,可嵌入业务逻辑 | 需要编写自定义代码,部署复杂 |
| HBase Replication | 原生支持,适合跨集群复制 | 延迟高,不适合实时同步场景 |
其中,Coprocessor方式是目前最常用的数据变更监听方式,因其具有良好的可扩展性和实时性。
5.2 使用Coprocessor监听变更
HBase的Coprocessor类似于关系型数据库的存储过程,允许开发者在RegionServer端执行自定义逻辑。通过实现 RegionObserver 接口,可以监听Put、Delete、Append等操作,并触发事件通知。
5.2.1 Coprocessor的部署与配置
要使用Coprocessor,首先需要编写一个类实现 RegionObserver 接口,并重写相关方法,例如 postPut() 、 postDelete() 等。
示例:定义一个简单的Coprocessor类
public class HBaseChangeEventCoprocessor extends BaseRegionObserver {
@Override
public void postPut(final ObserverContext<RegionCoprocessorEnvironment> e, final Put put, final WALEdit edit, final boolean writeToWAL) throws IOException {
byte[] rowKey = put.getRow();
System.out.println("Row inserted/updated: " + Bytes.toString(rowKey));
// 触发事件处理逻辑,如发送到Kafka
}
@Override
public void postDelete(final ObserverContext<RegionCoprocessorEnvironment> e, final Delete delete, final WALEdit edit, final boolean writeToWAL) throws IOException {
byte[] rowKey = delete.getRow();
System.out.println("Row deleted: " + Bytes.toString(rowKey));
// 触发事件处理逻辑
}
}
部署步骤如下:
- 将上述代码打包为JAR文件(如
hbase-coprocessor.jar)。 - 将JAR上传至HDFS:
bash hdfs dfs -put hbase-coprocessor.jar /user/hbase/coprocessor/ - 为HBase表添加Coprocessor:
bash hbase shell disable 'my_table' alter 'my_table', METHOD => 'table_att', 'coprocessor' => 'hdfs:///user/hbase/coprocessor/hbase-coprocessor.jar|com.example.HBaseChangeEventCoprocessor|1001|' enable 'my_table'
参数说明:
hdfs://...:JAR包的HDFS路径。com.example.HBaseChangeEventCoprocessor:实现类的全限定名。1001:优先级,数字越小优先级越高。|分隔符用于分隔参数。
5.2.2 自定义事件处理逻辑
在Coprocessor中捕获到数据变更事件后,需要将其封装为结构化的事件对象,并通过消息中间件传输到下游系统。
事件对象定义(使用Protobuf)
syntax = "proto3";
package event;
message HBaseChangeEvent {
string table_name = 1;
string row_key = 2;
string operation = 3; // "PUT", "DELETE", etc.
map<string, string> column_family = 4;
int64 timestamp = 5;
}
在Coprocessor中序列化事件并发送至Kafka
public class HBaseChangeEventCoprocessor extends BaseRegionObserver {
private KafkaProducer<String, byte[]> producer;
@Override
public void start(CoprocessorEnvironment env) throws IOException {
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-server:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.ByteArraySerializer");
producer = new KafkaProducer<>(props);
}
@Override
public void postPut(final ObserverContext<RegionCoprocessorEnvironment> e, final Put put, final WALEdit edit, final boolean writeToWAL) throws IOException {
HBaseChangeEvent.Builder eventBuilder = HBaseChangeEvent.newBuilder();
eventBuilder.setTableName("my_table");
eventBuilder.setRowKey(Bytes.toString(put.getRow()));
eventBuilder.setOperation("PUT");
eventBuilder.setTimestamp(System.currentTimeMillis());
// 构建列族信息
for (Map.Entry<byte[], List<Cell>> entry : put.getFamilyCellMap().entrySet()) {
String cf = Bytes.toString(entry.getKey());
for (Cell cell : entry.getValue()) {
eventBuilder.putColumnFamily(cf, Bytes.toString(CellUtil.cloneValue(cell)));
}
}
HBaseChangeEvent event = eventBuilder.build();
ProducerRecord<String, byte[]> record = new ProducerRecord<>("hbase_changes", event.toByteArray());
producer.send(record);
}
}
代码逻辑分析:
start()方法中初始化Kafka生产者,连接Kafka集群。- 在
postPut()方法中构造Protobuf格式的事件对象,包含表名、行键、操作类型、列族数据等。 - 将事件对象序列化为字节数组,并发送至Kafka的
hbase_changesTopic。 - 事件结构清晰,易于下游系统消费和处理。
5.3 事件消息的序列化与传输
为了确保事件数据在网络中高效、可靠地传输,必须采用高效的序列化格式和消息中间件。
5.3.1 Protobuf序列化机制
Protobuf(Protocol Buffers)是Google开源的一种高效的数据序列化协议,适用于结构化数据的序列化和反序列化。相比JSON或Java原生序列化,Protobuf具有体积小、速度快、跨语言支持好等优点。
Protobuf序列化优势:
- 数据体积小,节省带宽。
- 序列化/反序列化速度快。
- 支持多语言,便于异构系统通信。
示例:使用Protobuf反序列化事件
public class KafkaEventConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "kafka-server:9092");
props.put("group.id", "hbase-event-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.ByteArrayDeserializer");
KafkaConsumer<String, byte[]> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("hbase_changes"));
while (true) {
ConsumerRecords<String, byte[]> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, byte[]> record : records) {
try {
HBaseChangeEvent event = HBaseChangeEvent.parseFrom(record.value());
System.out.println("Received event: " + event.getRowKey());
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
}
}
}
}
}
代码分析:
- 使用KafkaConsumer订阅
hbase_changesTopic。 - 消费的消息值为字节数组,通过Protobuf的
parseFrom()方法反序列化为事件对象。 - 打印出事件中的行键信息,便于调试和后续处理。
5.3.2 Kafka与消息队列集成
Kafka作为高性能、可扩展的消息队列,广泛用于分布式系统中的事件传输。HBase变更事件通过Kafka传输,具有以下优势:
- 支持高并发写入与读取。
- 提供持久化存储,防止数据丢失。
- 支持多消费者组订阅,便于系统扩展。
Kafka集成架构图:
graph LR
A[HBase RegionServer] -->|事件推送| B[Kafka Broker]
B -->|消费事件| C[Elasticsearch Indexer]
B -->|消费事件| D[其他下游系统]
图5-2:Kafka在HBase变更事件传输中的架构图
通过将事件写入Kafka,可以实现:
- 异步处理,提升系统吞吐量。
- 多系统消费,实现数据多用途。
- 解耦HBase与Elasticsearch,提升系统可维护性。
综上所述,HBase变更事件的监听与处理是实现HBase与Elasticsearch数据同步的核心环节。通过合理使用Coprocessor、Protobuf序列化和Kafka消息队列,能够构建高效、稳定、可扩展的数据变更捕获系统,为后续的数据索引与查询提供坚实基础。
6. Elasticsearch索引文档构建
Elasticsearch作为分布式搜索和分析引擎,其核心操作之一是构建索引文档。在HBase与Elasticsearch的同步机制中,如何将HBase的变更数据高效、准确地转换为Elasticsearch的文档结构,是整个系统的关键环节。本章将从文档结构设计、构建过程、批处理机制以及失败处理等方面,深入探讨如何在实际应用中构建高质量的Elasticsearch索引文档。
6.1 文档结构与索引模板
Elasticsearch的文档结构决定了数据的存储方式与查询性能。通过索引模板(Index Template)可以预先定义文档字段的映射规则,确保数据一致性与高效检索。
6.1.1 映射模板的定义与应用
Elasticsearch支持通过索引模板为新建索引自动应用预定义的映射规则。模板可以包含字段类型、分词器、索引策略等信息,避免每次创建索引时手动定义字段。
{
"index_patterns": ["hbase_data*"],
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"dynamic": "strict",
"properties": {
"id": { "type": "keyword" },
"timestamp": { "type": "date" },
"content": { "type": "text", "analyzer": "standard" }
}
}
}
逻辑分析与参数说明:
"index_patterns":指定该模板适用于所有以hbase_data开头的索引。"settings":定义索引的分片与副本数量。"mappings":定义字段映射规则。"dynamic": "strict":禁止自动添加未定义字段,提升数据一致性。"id":使用keyword类型,适合精确匹配。"timestamp":使用date类型,支持时间范围查询。"content":使用text类型,并指定standard分词器,适用于全文检索。
操作步骤:
- 将上述模板保存为
hbase_template.json。 - 使用如下命令将其注册到Elasticsearch中:
curl -XPUT 'http://localhost:9200/_template/hbase_data_template' -H 'Content-Type: application/json' -d@hbase_template.json
流程图:
graph TD
A[用户定义模板] --> B[保存为JSON文件]
B --> C[调用Elasticsearch API上传模板]
C --> D[Elasticsearch验证模板]
D --> E[模板注册成功]
6.1.2 动态字段与静态字段的处理
Elasticsearch允许通过 dynamic 参数控制字段的自动添加行为。在HBase与Elasticsearch同步场景中,应根据业务需求合理选择字段处理策略。
| dynamic设置 | 行为说明 | 适用场景 |
|---|---|---|
| true | 自动添加新字段并推断类型 | 数据结构频繁变化,需快速适配 |
| false | 忽略新字段,不添加到映射 | 数据结构稳定,强调一致性 |
| strict | 遇到未定义字段抛出异常 | 强制字段规范,避免脏数据 |
示例:
{
"mappings": {
"dynamic": "false",
"properties": {
"id": { "type": "keyword" },
"timestamp": { "type": "date" }
}
}
}
在这种配置下,若HBase中新增了一个字段 location ,而该字段未在模板中定义,则不会被写入Elasticsearch。
逻辑分析:
- 使用
dynamic: false可防止意外字段进入索引,提升数据质量。 - 若业务需求允许字段动态扩展,可使用
true,但需注意潜在的字段爆炸风险。
6.2 文档内容的构建过程
在HBase与Elasticsearch的同步过程中,文档的构建是将HBase的变更数据(如Put、Delete)转换为Elasticsearch可识别的JSON格式的过程。
6.2.1 来源字段的提取与转换
HBase中的数据是以列族(ColumnFamily)和列(Column)的形式组织的,因此在转换为Elasticsearch文档时,需要将这些结构扁平化为JSON对象。
示例:HBase数据结构
RowKey: user_001
ColumnFamily: info
Columns:
name: John Doe
age: 30
email: john@example.com
转换为Elasticsearch文档:
{
"id": "user_001",
"name": "John Doe",
"age": 30,
"email": "john@example.com",
"timestamp": "2024-10-05T12:34:56Z"
}
逻辑分析:
RowKey被映射为文档的_id字段。- 每个列(Column)对应一个JSON字段。
timestamp字段通常用于记录数据变更时间,支持时间范围查询。
字段转换策略:
| HBase字段 | Elasticsearch字段类型 | 处理方式 |
|---|---|---|
| 数值类型(如年龄) | long / integer | 直接转换 |
| 字符串类型(如姓名) | text / keyword | 根据是否分词决定 |
| 时间戳 | date | ISO 8601格式 |
6.2.2 时间戳与ID字段的生成
时间戳和文档ID是Elasticsearch文档的重要组成部分,尤其在同步场景中,它们影响着数据的唯一性和查询效率。
时间戳字段:
- 推荐使用ISO 8601格式,如:
2024-10-05T12:34:56Z。 - 可从HBase的WAL日志中提取事件发生时间,或在数据转换阶段添加当前时间。
ID字段生成策略:
| 策略 | 说明 | 优点 | 缺点 |
|---|---|---|---|
| 使用HBase RowKey | 唯一且稳定 | 一致性高 | 需确保RowKey长度适配 |
| 自动生成UUID | 独立于HBase | 更加灵活 | 可能导致数据重复 |
| 结合RowKey与时间戳 | 唯一性高 | 保证唯一 | 增加ID长度 |
示例代码:
public class DocumentBuilder {
public static String buildDocument(String rowKey, Map<String, String> hbaseColumns) {
Map<String, Object> esDoc = new HashMap<>();
esDoc.put("id", rowKey);
esDoc.put("timestamp", new Date().toInstant().toString());
for (Map.Entry<String, String> entry : hbaseColumns.entrySet()) {
esDoc.put(entry.getKey(), entry.getValue());
}
return new Gson().toJson(esDoc);
}
}
逐行解读:
esDoc.put("id", rowKey);:将HBase的RowKey作为Elasticsearch的id字段。esDoc.put("timestamp", new Date().toInstant().toString());:添加当前时间戳,格式为ISO 8601。for循环:将HBase的列数据逐个映射到Elasticsearch文档中。Gson().toJson(esDoc):将Map结构转换为JSON字符串,便于后续提交。
6.3 批量文档的生成与提交
在高并发、大数据量的同步场景中,批量处理是提升Elasticsearch写入效率的关键策略。
6.3.1 批处理机制与优化
Elasticsearch提供了批量API(Bulk API),支持一次请求中提交多个文档操作(如Index、Update、Delete),从而减少网络往返次数,提高吞吐量。
批处理流程图:
graph LR
A[读取HBase事件] --> B[构建文档]
B --> C{是否达到批处理阈值?}
C -->|是| D[调用Bulk API提交]
C -->|否| E[继续缓存]
D --> F[处理响应]
F --> G[记录成功/失败]
优化建议:
- 批大小控制 :建议控制在5MB以内,避免单次请求过大导致超时。
- 线程并发 :使用多线程并发提交,提高吞吐能力。
- 内存缓存 :使用队列结构缓存待提交文档,防止内存溢出。
6.3.2 提交策略与失败处理
在实际生产环境中,Elasticsearch节点可能因负载高、网络不稳定等原因导致部分文档提交失败。因此,合理的提交策略与失败处理机制至关重要。
提交策略:
| 策略 | 说明 | 适用场景 |
|---|---|---|
| 同步提交 | 每次提交等待响应 | 数据准确性要求高 |
| 异步提交 | 使用回调处理响应 | 高吞吐、低延迟场景 |
失败处理机制:
- 重试机制 :对失败的文档进行重试,限制最大重试次数(如3次)。
- 断点续传 :记录已提交的文档位置,防止数据丢失。
- 日志记录 :记录失败文档内容,便于排查问题。
示例代码:
public class BulkProcessor {
private final RestHighLevelClient client;
public void bulkIndex(List<Map<String, Object>> documents) {
BulkRequest bulkRequest = new BulkRequest();
for (Map<String, Object> doc : documents) {
IndexRequest request = new IndexRequest("hbase_data");
request.id((String) doc.get("id"));
request.source(doc);
bulkRequest.add(request);
}
client.bulkAsync(bulkRequest, RequestOptions.DEFAULT, new ActionListener<BulkResponse>() {
@Override
public void onResponse(BulkResponse response) {
for (BulkItemResponse item : response.getItems()) {
if (item.isFailed()) {
System.err.println("Failed to index document: " + item.getFailureMessage());
}
}
}
@Override
public void onFailure(Exception e) {
System.err.println("Bulk indexing failed: " + e.getMessage());
}
});
}
}
逐行解读:
BulkRequest:构造批量请求对象。IndexRequest:为每个文档构造索引请求。client.bulkAsync:异步提交批量请求。ActionListener:监听响应结果,处理成功与失败情况。
本章系统讲解了Elasticsearch索引文档的构建过程,包括模板定义、字段映射策略、文档构建逻辑、时间戳与ID生成、以及批量处理与失败处理机制。下一章将深入探讨整个同步系统的运维与应用实践,包括性能调优、错误处理、状态监控等内容。
7. 数据同步系统的运维与应用实践
7.1 数据同步客户端配置
在实际部署HBase与Elasticsearch之间的数据同步系统时,客户端的配置至关重要。hbase-indexer作为核心组件,其客户端连接配置决定了系统的稳定性与安全性。
7.1.1 客户端连接参数配置
hbase-indexer客户端主要通过配置文件(如 hbase-indexer-site.xml )进行参数配置。以下是关键配置项及其说明:
| 配置项 | 说明 | 示例值 |
|---|---|---|
hbase.zookeeper.quorum |
HBase ZooKeeper集群地址 | zk1:2181,zk2:2181 |
hbase.indexer.elasticsearch.hosts |
Elasticsearch集群地址 | es1:9200,es2:9200 |
hbase.indexer.table |
要监听的HBase表名 | user_profile |
hbase.indexer.mapping.file |
字段映射配置文件路径 | /etc/hbase-indexer/mapping.json |
配置示例( hbase-indexer-site.xml 片段):
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181</value>
</property>
<property>
<name>hbase.indexer.elasticsearch.hosts</name>
<value>es1:9200,es2:9200</value>
</property>
<property>
<name>hbase.indexer.table</name>
<value>user_profile</value>
</property>
<property>
<name>hbase.indexer.mapping.file</name>
<value>/etc/hbase-indexer/mapping.json</value>
</property>
</configuration>
7.1.2 认证与权限控制
为了保障数据安全,系统支持Kerberos认证与RBAC权限控制。
- Kerberos认证 :通过配置
hbase-site.xml中的hbase.security.authentication为kerberos,并指定 keytab 文件和 principal。 - Elasticsearch权限控制 :使用基本认证(Basic Auth)或SSL证书进行访问控制。
例如,配置Elasticsearch Basic Auth:
<property>
<name>hbase.indexer.elasticsearch.username</name>
<value>elastic</value>
</property>
<property>
<name>hbase.indexer.elasticsearch.password</name>
<value>your_secure_password</value>
</property>
7.2 同步性能调优策略
7.2.1 批量同步与线程控制
为提高同步效率,hbase-indexer支持批量写入与多线程处理。
- 批量写入 :通过设置
hbase.indexer.elasticsearch.bulk.size控制每次提交的文档数量,默认为 100。 - 线程数控制 :设置
hbase.indexer.thread.count控制并行线程数,通常根据CPU核心数与网络带宽进行调整。
示例配置:
<property>
<name>hbase.indexer.elasticsearch.bulk.size</name>
<value>500</value>
</property>
<property>
<name>hbase.indexer.thread.count</name>
<value>8</value>
</property>
7.2.2 网络与资源瓶颈优化
- 网络优化 :将HBase、Elasticsearch与hbase-indexer部署在同一个局域网内,减少延迟。
- 资源限制 :通过JVM参数控制堆内存,避免OOM,如设置
-Xms4g -Xmx8g。 - 磁盘IO优化 :若使用WAL日志消费方式,确保磁盘读取速度足够支撑日志处理。
7.3 错误处理与日志记录
7.3.1 重试机制与断点续传
hbase-indexer内置了重试机制,支持在网络波动或Elasticsearch短暂不可用时自动重试。通过以下配置控制:
<property>
<name>hbase.indexer.elasticsearch.retry.count</name>
<value>5</value>
</property>
<property>
<name>hbase.indexer.elasticsearch.retry.wait</name>
<value>5000</value> <!-- 单位毫秒 -->
</property>
断点续传 :通过 hbase.indexer.checkpoint 机制记录消费偏移量,防止数据丢失。支持持久化到ZooKeeper或本地文件。
7.3.2 日志采集与分析
日志是运维的重要依据。hbase-indexer默认输出INFO级别日志,可通过log4j配置调整:
log4j.rootLogger=INFO, file
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.File=/var/log/hbase-indexer.log
log4j.appender.file.MaxFileSize=10MB
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{ISO8601} [%t] %-5p %c %x - %m%n
日志内容示例:
2025-04-05 10:20:01,123 [main] INFO org.apache.hadoop.hbase.indexer.HBaseIndexer - Starting HBaseIndexer for table user_profile
2025-04-05 10:20:05,456 [pool-1-thread-3] DEBUG org.apache.hadoop.hbase.indexer.elasticsearch.ElasticsearchWriter - Bulk request size: 500
7.4 同步状态监控与告警
7.4.1 监控指标与采集方式
关键监控指标包括:
- 同步延迟(lag)
- 每秒处理事件数(EPS)
- Elasticsearch写入成功率
- 线程状态与JVM内存使用
可通过Prometheus + Grafana进行监控采集:
# prometheus.yml 示例
scrape_configs:
- job_name: 'hbase-indexer'
static_configs:
- targets: ['hbase-indexer-host:8080']
7.4.2 告警配置与响应机制
使用Prometheus Alertmanager配置告警规则,如:
groups:
- name: hbase-indexer-alerts
rules:
- alert: HighSyncLag
expr: hbase_indexer_lag > 1000
for: 5m
labels:
severity: warning
annotations:
summary: "High sync lag on {{ $labels.instance }}"
description: "Sync lag is above 1000 events (current value: {{ $value }})"
响应机制可集成Slack、钉钉或企业微信进行通知。
7.5 典型应用场景分析
7.5.1 在日志分析系统中的应用
在日志分析系统中,HBase用于存储原始日志,Elasticsearch用于全文搜索与实时分析。hbase-indexer负责将日志写入HBase后,实时同步到ES,实现日志的实时可视化。
部署架构示意图(Mermaid流程图):
graph TD
A[HBase] -->|WAL事件| B(hbase-indexer)
B -->|JSON文档| C[Elasticsearch]
C -->|Kibana查询| D[Kibana]
B -->|Metrics| E[Prometheus]
E -->|Dashboard| F[Grafana]
7.5.2 在推荐系统中的集成与优化
在推荐系统中,用户行为数据写入HBase,通过hbase-indexer同步到Elasticsearch,构建用户画像索引,供推荐引擎实时查询。
优化建议:
- 使用
_id字段绑定用户ID,保证唯一性。 - 对关键字段(如点击、浏览)设置
keyword类型,便于聚合分析。 - 开启
dynamic_templates动态字段映射,适应不断变化的用户行为维度。
推荐系统字段映射示例(JSON):
{
"user_profile": {
"mappings": {
"dynamic_templates": [
{
"user_actions": {
"match": "action_*",
"mapping": {
"type": "keyword"
}
}
}
],
"properties": {
"user_id": { "type": "keyword" },
"last_login": { "type": "date" },
"preferences": { "type": "nested" }
}
}
}
(本章完)
简介:在大数据处理中,Elasticsearch和HBase分别以其强大的搜索分析能力和分布式存储优势被广泛应用。为了实现HBase数据实时同步至Elasticsearch,引入了SEP(Search Engine Persistence)机制,其核心依赖于 hbase-indexer 组件。本资料详细解析了SEP机制的工作流程,包括模型配置、变更监听、索引构建与数据传输等模块,并介绍了其数据过滤、批量同步、错误处理与监控告警等高级特性,适用于日志分析、监控系统和推荐系统等实时搜索场景。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献173条内容
已为社区贡献173条内容

所有评论(0)