大数据运维
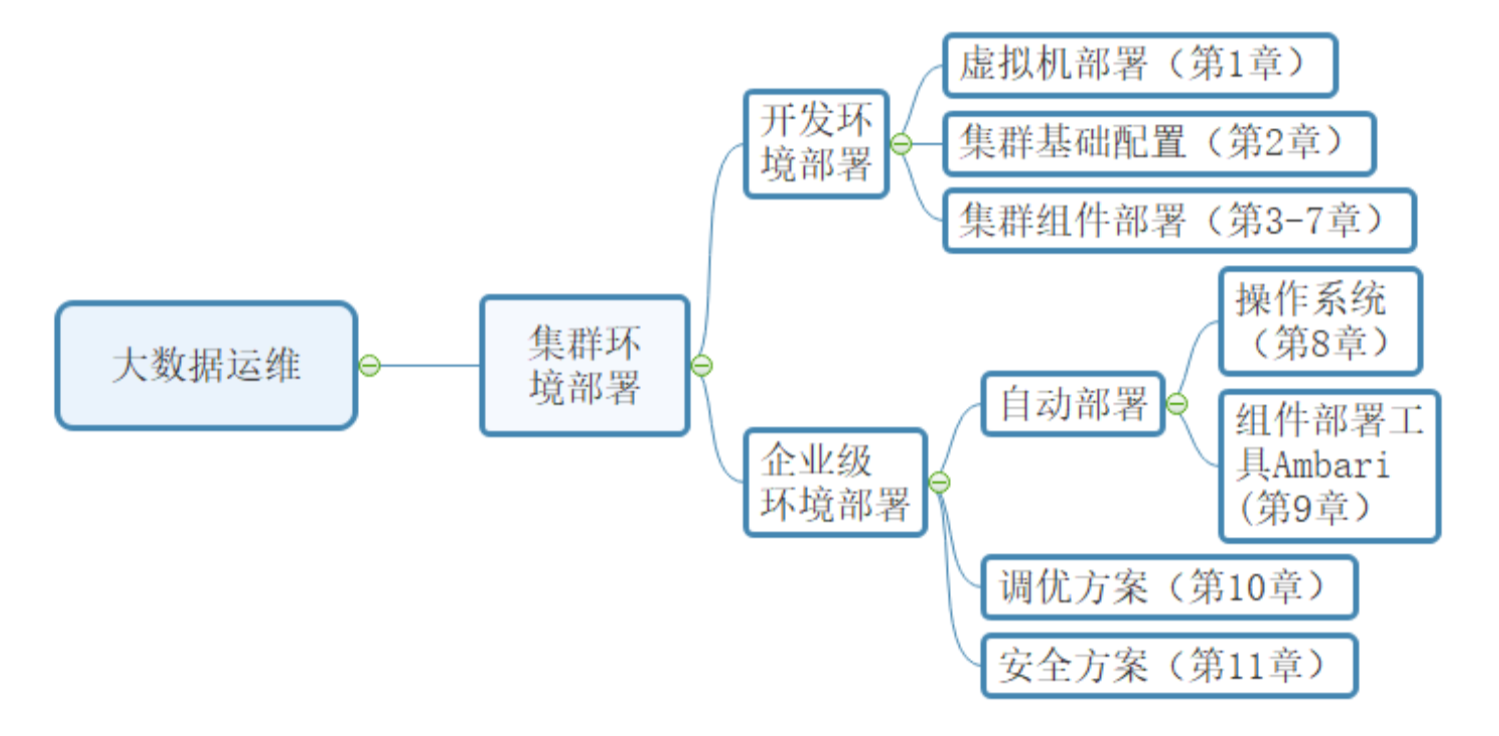 大数据运维的定义
大数据运维的定义
大数据运维(Big Data Operations)是指围绕大数据平台、工具及应用的部署、监控、优化和故障处理等全生命周期管理活动。其核心目标是保障数据管道的稳定性、计算资源的高效利用以及数据服务的可靠性,同时应对海量数据、高并发和分布式环境带来的挑战
分布式系统管理
涉及Hadoop、Spark、Flink等框架的集群部署、配置调优及资源调度。需掌握YARN、Kubernetes等资源管理工具,确保计算与存储资源动态分配。
未来发展趋势
- 云原生融合:大数据平台向Kubernetes迁移,利用Operator模式简化管理。
- AIOps应用:通过机器学习预测资源需求、自动扩缩容,实现智能运维。
- Serverless化:按需执行的数据处理服务(如AWS Glue)减少运维负担。
大数据运维正从手动干预转向自动化、智能化,要求从业者兼具分布式系统原理深度理解和工具链实战能力。
一、检查上网状态
1、ping www.baidu.com

2、dhclient
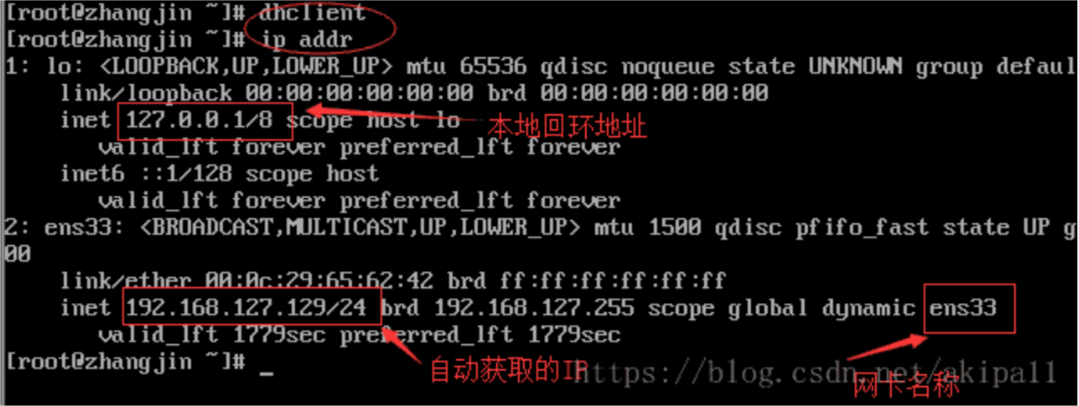
3、ping www.baidu.com
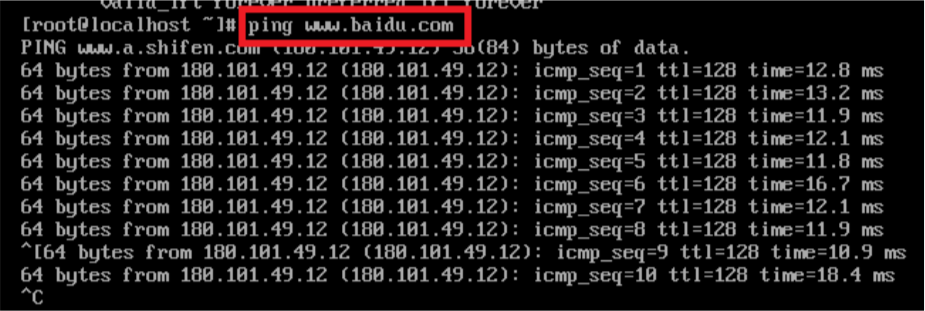
4、Windows下查看虚拟机
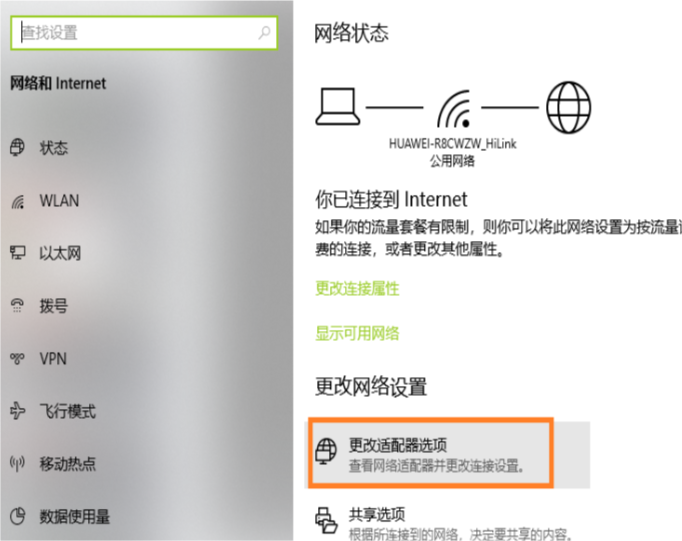
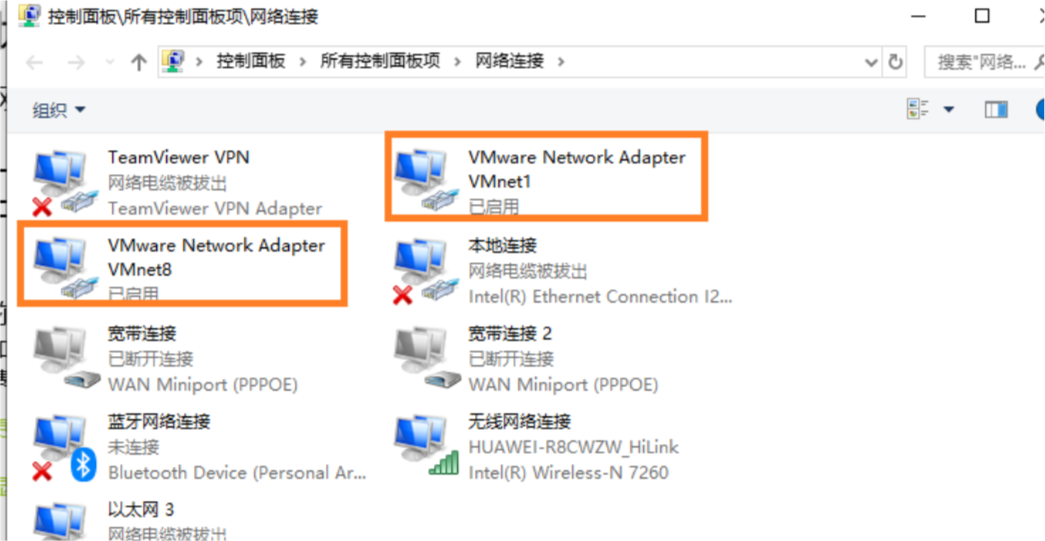
5、虚拟机下查看上网模式
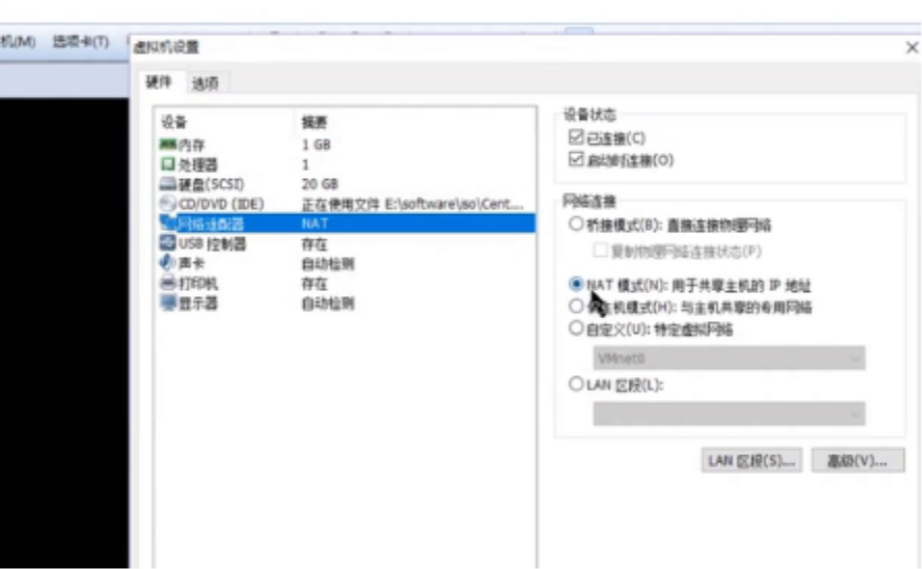
二、使用文件配置网络
2、配置文件各条目含义
NETMASK:掩码地址,Centos7支持使用PREFIX(PREFIX=24)以长度方式指明子网掩码GATEWAY:默认网关
USERCTL:是否允许普通用户控制此设备
PEERDNS:如果BOOTPROTO的值为“dhcp”,是否允许dhcp server分配的dns服务器指向
覆盖本地手动指定的dns服务器指向,默认允许
HWADDR=00:0C:29:EB:8B:6E:设备的MAC地址
NM_CONTROLLLED=yes:是否使用NetworkManager服务来控制接口(一般是使用network
服务的)
DEFROUTE:是否把当前网络设备设定为默认路由
IPV4_FAILURE_FATAL=no:是否开启ipv4致命错误检测
3、测试centos7配置网络
(1)更改配置文件
将ONBOOT=no改为yes,
将BOOTPROTO=dhcp改为BOOTPROTO=static,
并在后面增加几行内容:
IPADDR=192.168.2.128
NETMASK=255.255.255.0
GATEWAY=192.168.2.2
DNS1=119.29.29.29
(2)保存配置文件后,重新启动网络服务
[root@yuki ~]# systemctl restart network.service
(3)测试是否配置成功
[root@yuki ~]# ping www.baidu.
三、通过机器名字访问网络
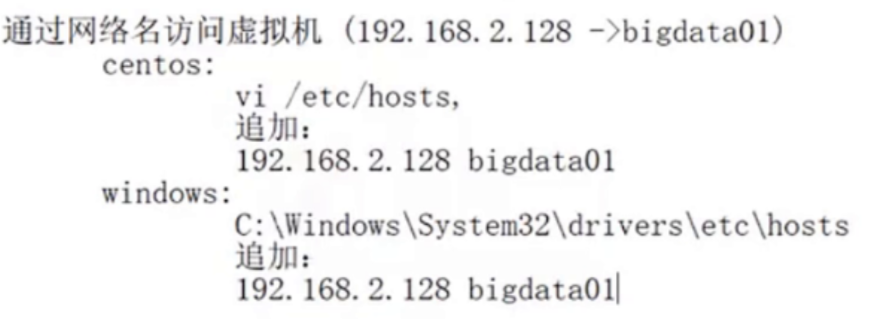
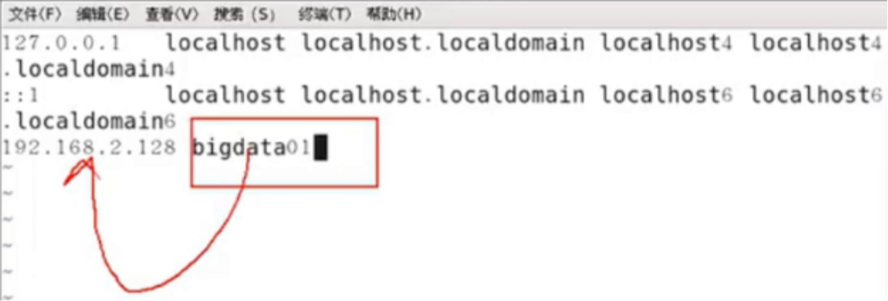
关键技术实践
自动化监控与告警
部署Prometheus、Grafana等工具实时监控集群健康状态,设置阈值触发告警。通过日志分析(如ELK栈)快速定位故障点,减少MTTR(平均修复时间)。
资源动态调度
基于YARN或Kubernetes实现资源弹性分配,根据负载自动扩展计算节点。采用容器化技术(如Docker)提升环境一致性和部署效率。
数据安全与合规
实施端到端加密(TLS/SSL)、RBAC权限控制及数据脱敏。定期审计访问日志,符合GDPR等法规要求。
性能优化策略
存储分层设计
热数据存于SSD,冷数据归档至对象存储(如S3)。使用Parquet/ORC列式存储降低I/O开销。
计算引擎调优
调整Spark并行度(spark.executor.cores)、内存参数(spark.memory.fraction),避免GC瓶颈。HDFS配置块大小(默认128MB)适应业务场景
工具链推荐
- 监控:Prometheus + AlertManager
- 调度:Airflow(工作流编排)
- 安全:Apache Ranger(策略管理)
- 备份:DistCp(跨集群数据同步)
大数据运维的核心结论
大数据运维的核心在于确保数据管道的稳定性、可扩展性和安全性。通过自动化监控、故障预警和资源优化,保障数据处理的实时性与准确性。运维团队需平衡性能与成本,同时应对数据量激增、技术栈复杂等挑战。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)