深度学习项目训练环境教学资源丰富:配套CSDN专栏含32篇改进技巧与15个实战项目
本文介绍了如何在星图GPU平台上一键自动化部署深度学习项目训练环境镜像。该镜像预装了PyTorch等完整开发环境,并关联了包含32篇改进技巧与15个实战项目的教学专栏。用户可快速上手,应用于图像分类、目标检测等模型的训练、验证与优化,实现从环境搭建到项目精通的效率提升。
深度学习项目训练环境教学资源丰富:配套CSDN专栏含32篇改进技巧与15个实战项目
想快速上手深度学习项目,但总被环境配置、依赖安装、代码调试这些“脏活累活”绊住脚?今天给大家分享一个开箱即用的深度学习训练环境镜像,它基于我精心维护的 《深度学习项目改进与实战》 CSDN专栏,预装了完整的开发环境,让你能跳过繁琐的配置,直接进入核心的模型训练与改进环节。
这个镜像最大的亮点在于,它不仅仅是一个“干净”的环境,更是一个 “教学资源富集” 的起点。它背后链接着一个包含 32篇深度学习改进技巧详解 和 15个完整实战项目 的专栏。这意味着,你上传代码后,不仅能立刻开始训练,还能随时查阅专栏,学习如何优化模型、解决实际问题,实现从“跑通代码”到“精通项目”的跨越。
1. 环境概览:开箱即用的深度学习工作站
拿到一个新环境,最关心的就是“里面有什么”、“能不能直接用”。这个镜像已经为你准备好了深度学习项目开发所需的一切核心组件,真正做到拎包入住。
1.1 核心框架与版本
镜像的核心是稳定的 PyTorch 深度学习框架,具体版本经过精心挑选,在功能、性能和兼容性之间取得了良好平衡:
- 深度学习框架:
PyTorch == 1.13.0 - CUDA 工具包:
11.6(用于 GPU 加速计算) - 编程语言:
Python 3.10.0 - 配套视觉库:
torchvision == 0.14.0 - 配套音频库:
torchaudio == 0.13.0
这个组合是经过大量项目验证的“黄金搭档”,既能保证绝大多数最新模型代码的兼容性,又拥有出色的运行稳定性。
1.2 预装的关键依赖库
除了核心框架,镜像还预装了数据科学和深度学习项目中的常用“工具包”,你基本不需要再为安装这些库而烦恼:
- 数据处理三剑客:
numpy,pandas—— 用于高效处理数值和表格数据。 - 图像处理必备:
opencv-python—— 读图、写图、图像预处理都靠它。 - 可视化工具:
matplotlib,seaborn—— 绘制损失曲线、准确率图表、可视化特征图。 - 进度提示:
tqdm—— 让训练循环有个美观的进度条,随时掌握训练进度。 - 科学计算基础:
scipy等常用科学计算库。
简单来说,从数据加载、预处理、模型构建、训练到结果可视化,这条流水线上需要的常见工具,镜像都已经为你安装妥当。如果你有特殊需求,比如某个小众的库,也可以使用 pip install 自行轻松添加。
2. 快速上手:十分钟开启你的第一个训练
理论说完,我们直接动手。假设你已经成功启动了镜像,面对一个新的终端界面,可能会有点懵。别担心,跟着下面几步走,十分钟内你就能开始训练自己的模型。
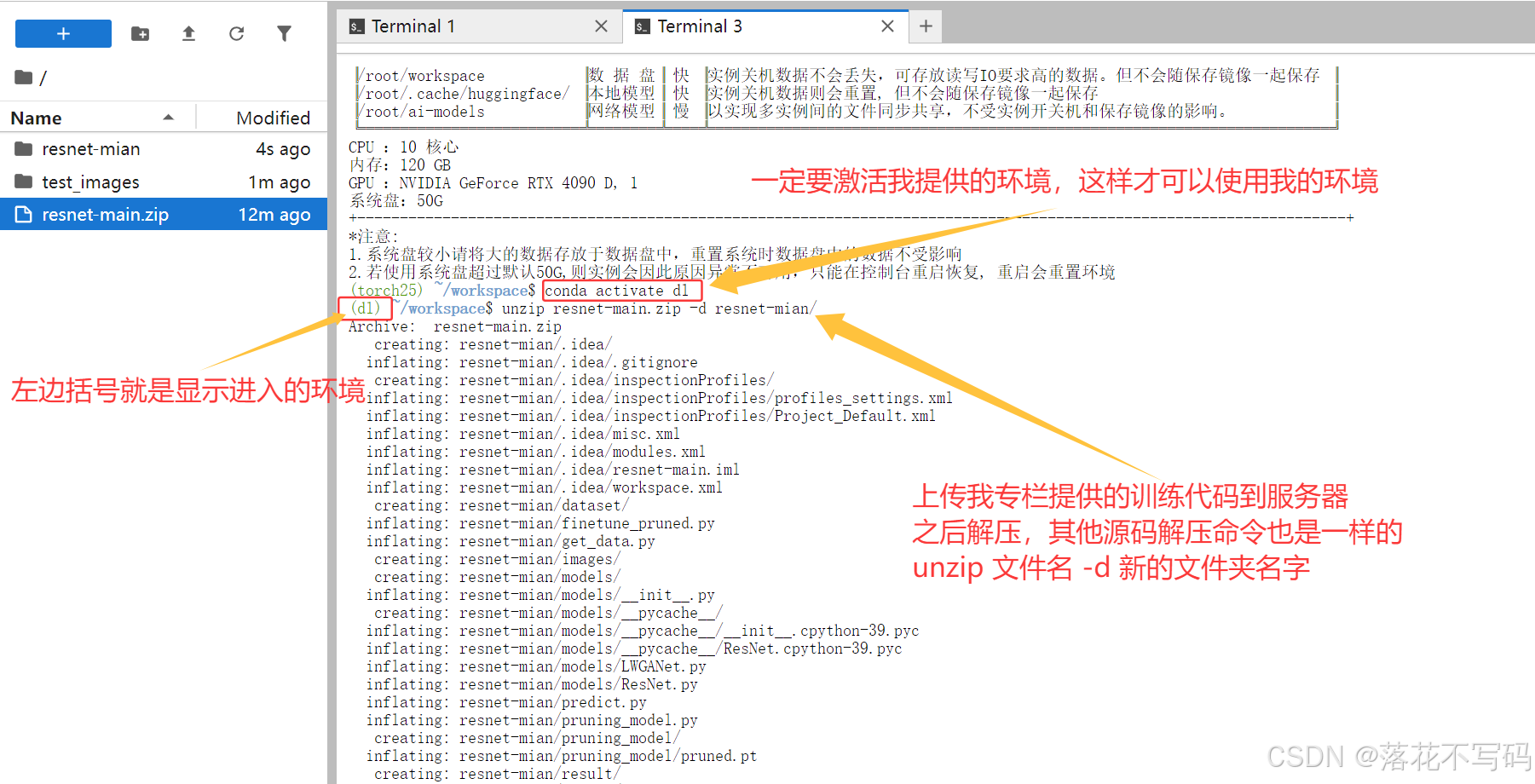
2.1 第一步:激活环境与准备代码
镜像启动后,你会看到一个命令行界面。我们首先要进入正确的“工作模式”。
-
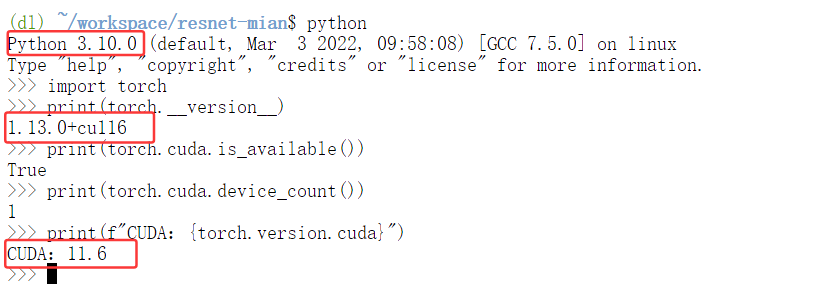
激活深度学习环境: 在终端中输入以下命令,激活名为
dl的 Conda 环境。这就像进入了一个专门为深度学习准备好的工作间。conda activate dl执行后,命令行提示符前通常会显示
(dl),表示你已经在该环境中。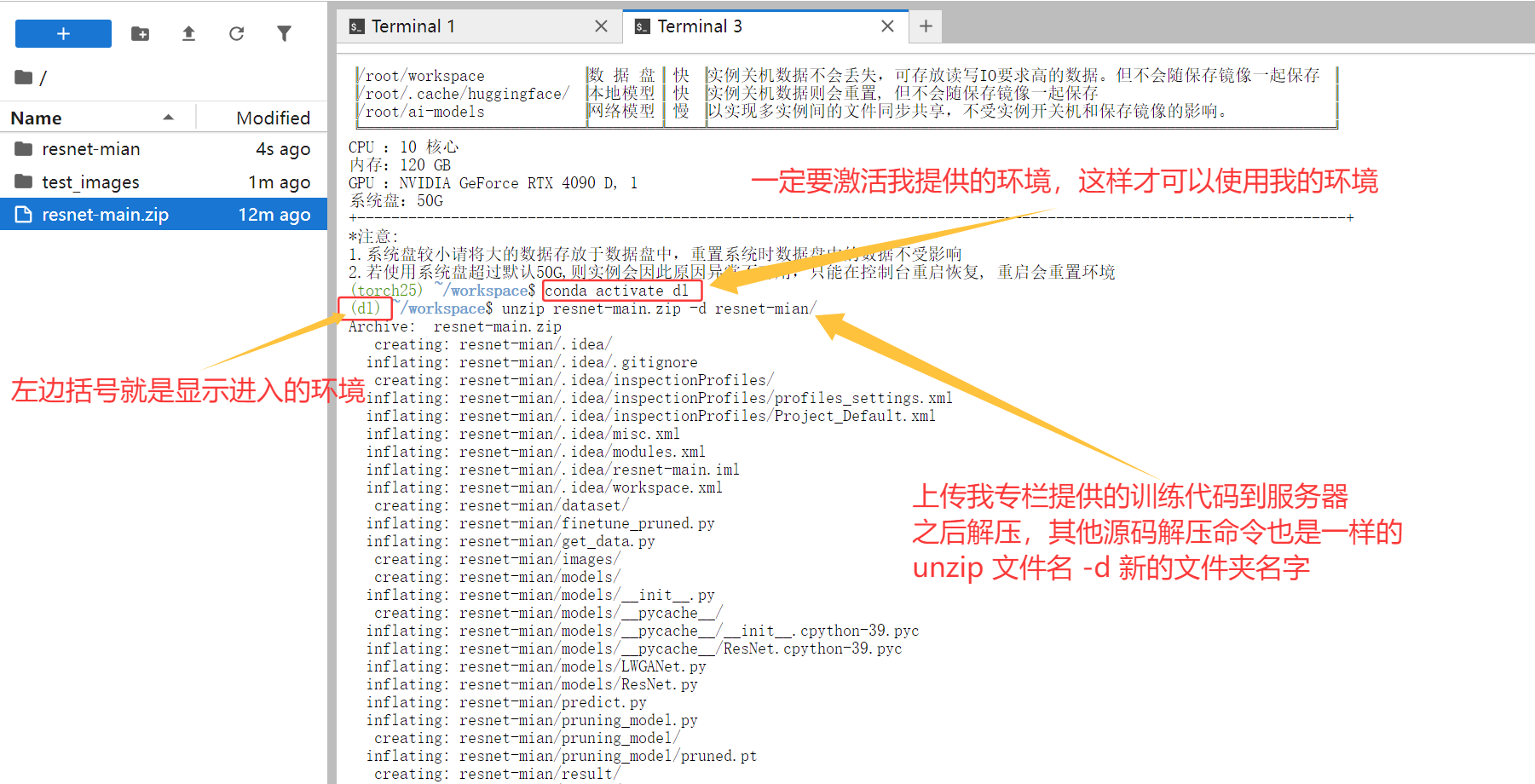
-
上传代码与数据: 使用
Xftp、WinSCP这类文件传输工具,将你在专栏中下载的实战项目代码,以及你自己的数据集,上传到镜像的/root/workspace/目录下。建议把数据放在数据盘。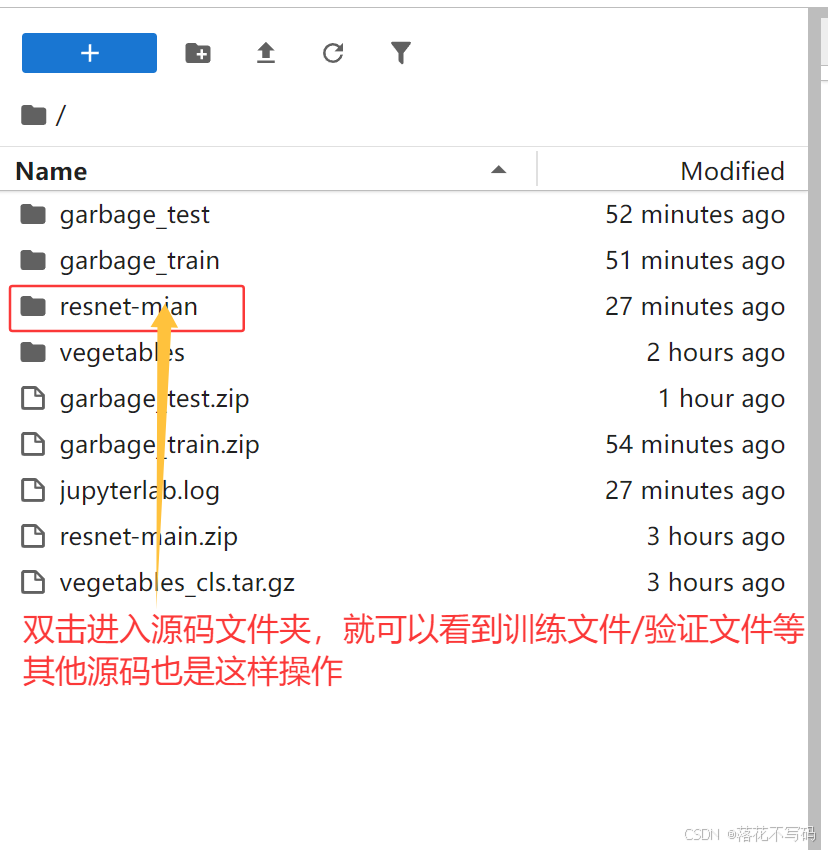
-
进入项目目录: 上传完成后,在终端中切换到你的代码目录。例如,如果你的代码文件夹叫
my_yolo_project:cd /root/workspace/my_yolo_project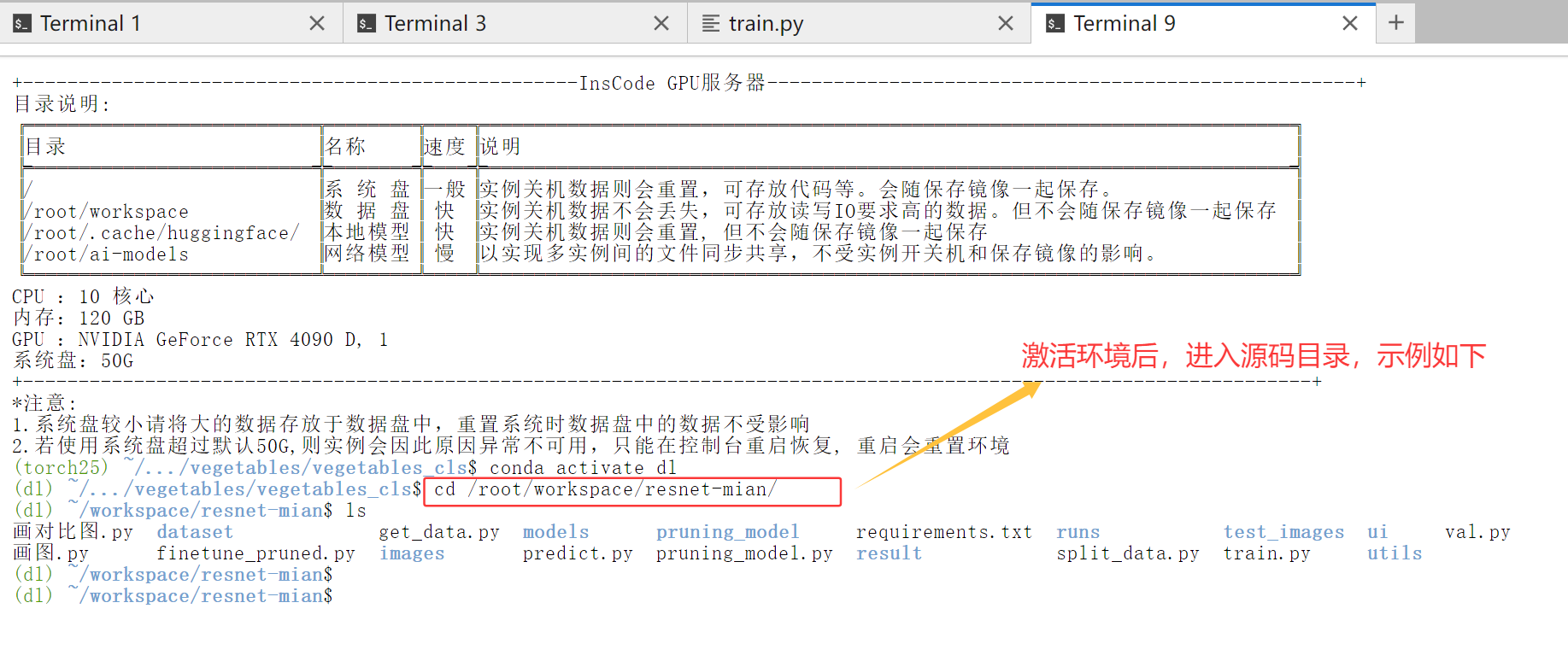
2.2 第二步:准备与开始训练
现在,你已经在正确的环境里,站在了你的项目代码面前。
-
解压数据集(如果需要): 如果你的数据集是压缩包,需要先解压。这里有两个常用命令:
- 解压
.zip文件到指定新文件夹:unzip your_dataset.zip -d new_folder_name - 解压
.tar.gz文件到当前目录或指定目录:# 解压到当前目录 tar -zxvf vegetables_cls.tar.gz # 解压到指定目录 tar -zxvf vegetables_cls.tar.gz -C /home/user/data/
- 解压
-
配置训练参数: 打开项目中的
train.py文件,修改关键的几个路径参数,这通常是数据路径、模型保存路径等。专栏对应的每篇文章都会详细说明这些参数如何配置。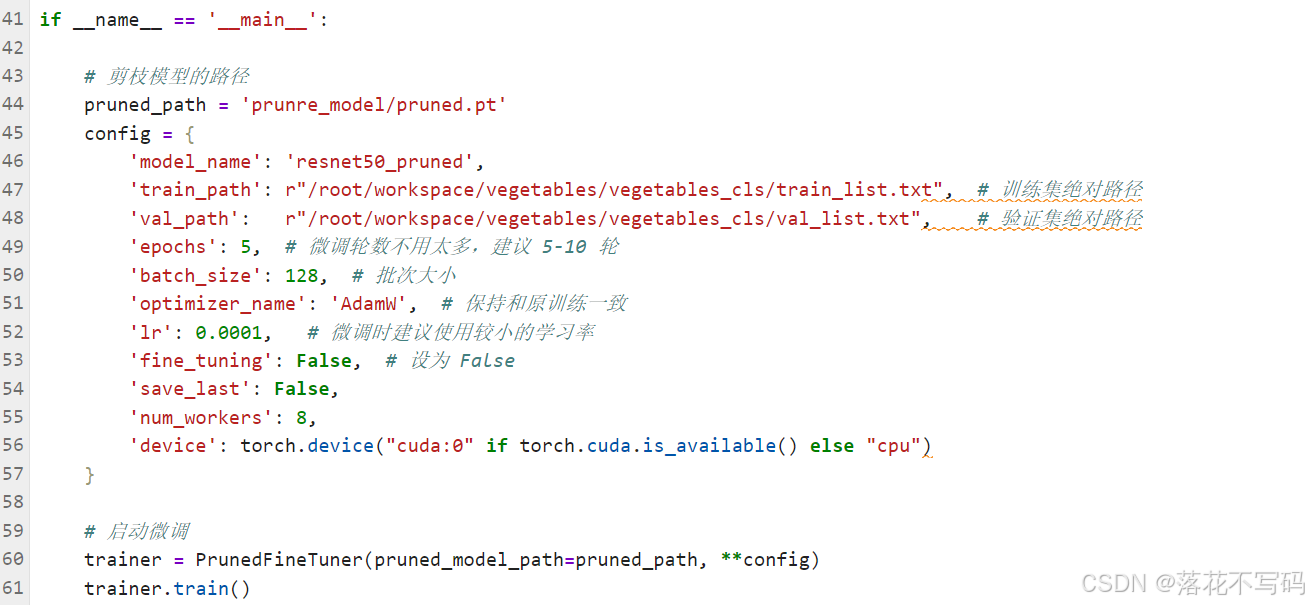
-
启动训练: 在终端中,运行一条简单的命令,训练就开始了:
python train.py终端会开始输出训练日志,包括当前的迭代次数、损失值、学习率等。训练完成后,模型权重文件会保存在你指定的目录下。

-
可视化训练结果: 训练结束后,你可以使用项目提供的绘图脚本(例如
plot_results.py),只需修改结果文件路径,就能生成损失曲线和精度曲线图,直观地评估训练过程。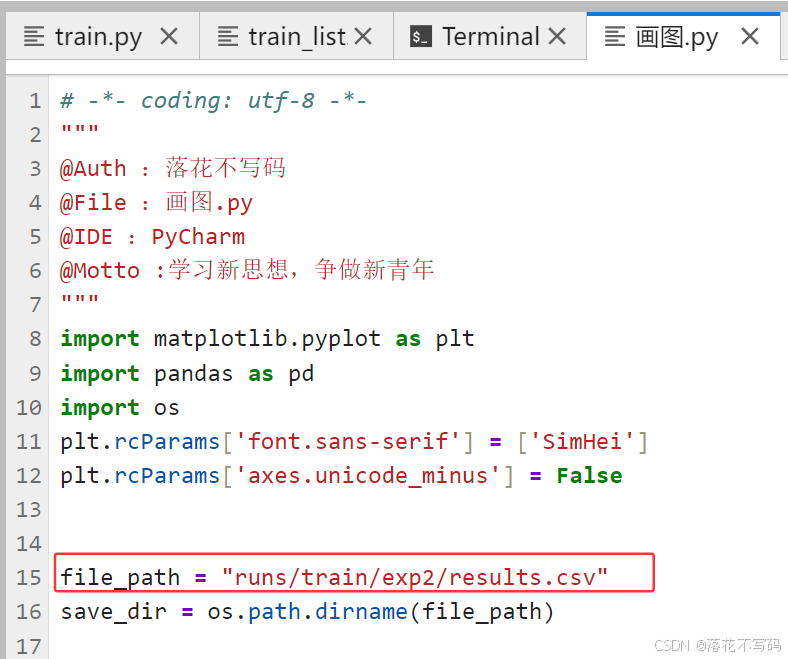
2.3 第三步:验证、优化与部署
模型训练好了,工作还没完。镜像环境和配套专栏能支持你走完后续所有关键步骤。
-
模型验证: 使用
val.py脚本在测试集上评估模型的最终性能。同样,修改脚本中的模型权重路径和数据路径后运行:python val.py终端会输出精确率、召回率、mAP等关键指标。

-
模型优化: 这是专栏的精华所在。如果你觉得模型太大、推理太慢,可以参照专栏中的 模型剪枝 文章,学习如何去除模型中冗余的部分,实现模型轻量化。
 如果你想在某个特定任务上获得更好效果,可以参照 模型微调 文章,利用预训练模型,用你自己的数据对其进行“二次训练”。
如果你想在某个特定任务上获得更好效果,可以参照 模型微调 文章,利用预训练模型,用你自己的数据对其进行“二次训练”。 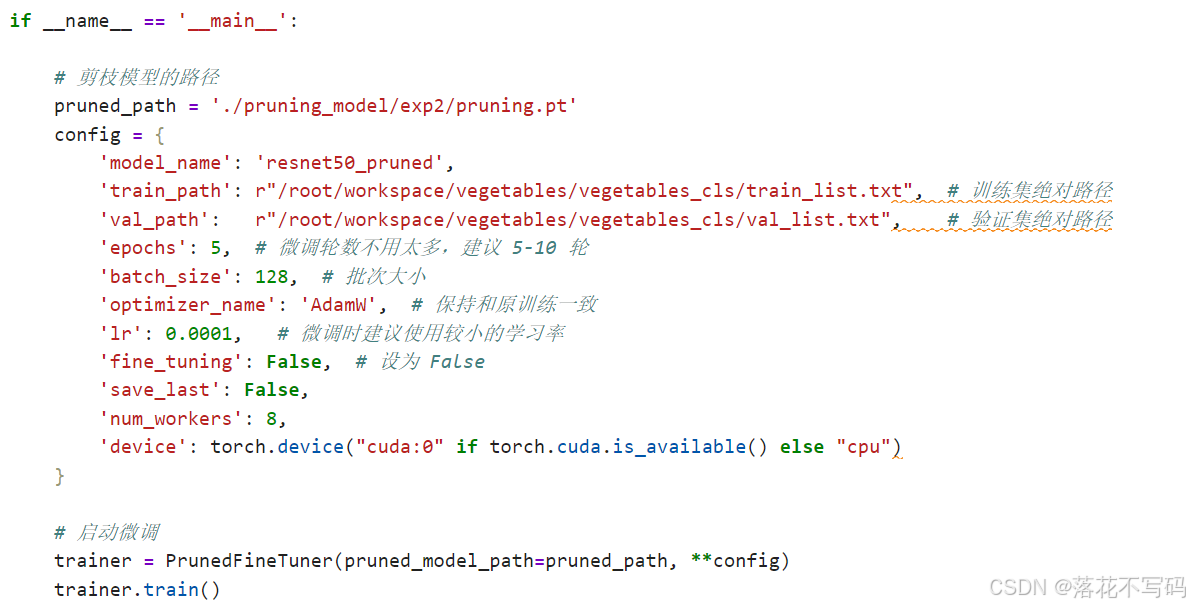
-
成果下载: 所有训练好的模型、日志、图表都保存在服务器上。使用
Xftp工具,像在本地电脑上拖拽文件一样,轻松地将它们下载到你的本地电脑中进行后续分析或部署。
3. 常见问题与解决思路
即使环境已经尽可能简化,新手在实践中仍可能遇到一些小问题。这里总结几个最常见的:
- 数据集路径错误:这是最高频的错误。请务必仔细检查
train.py、val.py等文件中关于数据集路径的参数,确保路径指向你上传并解压后的正确文件夹。数据集通常需要按特定格式(如ImageNet格式)组织。 - 忘记激活环境:在运行任何Python训练命令前,请确认终端提示符前有
(dl)字样。如果没有,务必先执行conda activate dl。 - 缺少某个依赖库:虽然镜像预装了大部分库,但如果你运行的代码需要某个特殊库,只需在激活的
dl环境中使用pip install package_name安装即可。 - 训练过程疑惑:如果在模型改进、调参、结果分析方面有疑问,最好的方法是回到 《深度学习项目改进与实战》 专栏,查找对应的技巧文章或实战项目,里面通常有深入的原理讲解和代码分析。
4. 总结:从环境到精通的捷径
回顾一下,这个深度学习训练环境镜像为你提供了什么:
- 零配置的起点:免去了数小时甚至数天的环境搭建、版本冲突调试过程,让你宝贵的精力集中在算法和模型本身。
- 即时的生产力:上传代码、修改路径、开始训练,三步就能跑起来,快速验证想法,看到结果。
- 强大的学习后盾:它不是一个孤立的工具,而是通往一个包含 32篇改进技巧 和 15个实战项目 的知识宝库的大门。当你遇到瓶颈时,你知道去哪里寻找答案和灵感。
- 完整的项目闭环:从环境准备、数据预处理、模型训练、验证评估,到模型优化(剪枝、微调)、结果可视化,它支持了一个深度学习项目全生命周期的核心操作。
对于初学者,它能帮你扫清最大的入门障碍;对于有经验的研究者或开发者,它能为你提供一个干净、稳定、可复现的基础环境,大幅提升实验效率。
深度学习的学习和实践,核心在于“动手”和“迭代”。这个镜像及其配套的丰富教学资源,正是为了最大化你的动手效率而设计的。现在,环境已经就绪,资源触手可及,是时候开始你的下一个深度学习项目了。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献153条内容
已为社区贡献153条内容

所有评论(0)