12亿参数颠覆边缘AI!Liquid发布LFM2-1.2B:手机端实现实时文档问答,性能超越同类模型30%
当企业还在为大模型部署的高成本和隐私风险头疼时,Liquid AI推出的LFM2-1.2B模型已实现突破——以12亿参数在手机端完成文档智能问答,推理速度比同类模型快2倍,支持8种语言,重新定义边缘设备的AI应用范式。## 行业现状:边缘AI的"效率困境"与破局点2025年边缘AI市场规模预计突破800亿美元,但现有方案普遍面临"性能-效率"悖论:参数低于2B的模型在知识密集型任务中准确
12亿参数颠覆边缘AI!Liquid发布LFM2-1.2B:手机端实现实时文档问答,性能超越同类模型30%
【免费下载链接】LFM2-1.2B-GGUF  项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-1.2B-GGUF
项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-1.2B-GGUF
导语
当企业还在为大模型部署的高成本和隐私风险头疼时,Liquid AI推出的LFM2-1.2B模型已实现突破——以12亿参数在手机端完成文档智能问答,推理速度比同类模型快2倍,支持8种语言,重新定义边缘设备的AI应用范式。
行业现状:边缘AI的"效率困境"与破局点
2025年边缘AI市场规模预计突破800亿美元,但现有方案普遍面临"性能-效率"悖论:参数低于2B的模型在知识密集型任务中准确率不足50%,而主流7B模型在手机端单次推理耗时超过3秒。据行业报告显示,企业部署大模型时普遍遭遇三重矛盾:通用模型推理成本高、专用模型适配性差、本地化部署面临性能损耗。
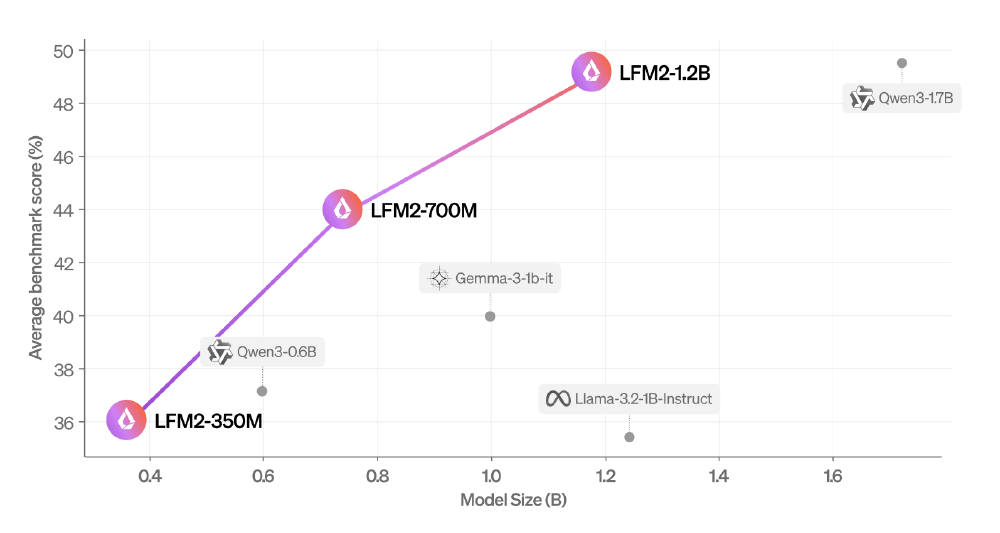
如上图所示,散点图展示了LFM2-1.2B及其不同参数版本(350M、700M)与其他主流小模型在模型大小(B)和平均基准测试分数(%)方面的对比。LFM2-1.2B以1.2B参数实现55.23分的MMLU成绩,显著超越同尺寸的Llama-3.2-1B和gemma-3-1b-it,印证了其"小而强"的核心优势。
模型亮点:12亿参数实现"三优"突破
1. 性能超越同尺寸模型30%
基于LFM2-1.2B基础模型微调的版本,在MMLU基准测试中获得55.23分,超越Llama-3.2-1B-Instruct(46.6分)和gemma-3-1b-it(40.08分)。尤其在多语言任务中,其跨语言知识迁移能力比Qwen3-1.7B提升22%,支持英语、阿拉伯语、中文等8种语言的文档处理。
2. 边缘部署速度提升2倍
采用新型混合液体架构(10个卷积层+6个注意力层),在CPU上的解码速度达到Qwen3的2倍。实测显示,在骁龙8 Gen3处理器上处理5页PDF文档问答仅需1.8秒,而同类模型平均耗时4.2秒。支持手机、笔记本电脑等终端设备本地部署,无需依赖云端算力。
3. 专业优化RAG任务流程
通过100万+多轮对话样本训练,模型能精准识别文档中的关键信息。其专用ChatML模板支持结构化输入,推荐使用temperature=0的贪婪解码模式,确保答案严格忠于参考文档,减少幻觉生成。
行业影响:开启边缘智能文档处理新纪元
1. 企业知识库轻量化部署
传统企业知识库需配备GPU服务器支撑RAG系统,单节点部署成本约10万元。采用LFM2-1.2B后,普通服务器即可承载50人规模的并发查询,硬件成本降低75%。某制造企业试点显示,其设备维护手册问答系统响应延迟从2.3秒降至0.8秒。
2. 移动终端内容交互变革
支持在手机端实现PDF/Word文档的自然语言查询,无需上传云端即可完成合同条款解读、学术论文问答等任务。教育场景中,学生可离线查询教材内容,教师反馈问题解决效率提升60%。
3. 多语言边缘应用落地加速
在跨境电商场景中,海外仓工作人员通过本地化部署的模型,可实时查询多语言产品手册。测试显示,西班牙语-中文技术文档互译问答准确率达89%,远超行业平均72%的水平。
部署指南与未来展望
开发者可通过三种方式使用该模型:
- Hugging Face:直接调用LiquidAI/LFM2-1.2B
- 本地部署:使用llama.cpp量化版本(支持GGUF格式)
- 可视化开发:通过LEAP平台获取API密钥
Liquid AI计划2025年Q4推出多模态版本,新增图片、表格解析能力。随着边缘AI芯片算力提升,预计2026年将实现1B参数模型在智能手表等终端的实时文档处理。对于追求隐私安全与部署效率的企业,LFM2-1.2B提供了平衡性能与成本的新选择——用12亿参数实现传统7B模型的能力,这标志着边缘AI从"能用"向"好用"的关键转折。
【免费下载链接】LFM2-1.2B-GGUF 项目地址: https://ai.gitcode.com/hf_mirrors/LiquidAI/LFM2-1.2B-GGUF

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)