Qwen3-VL-30B视频动态理解:时序分析模型部署教程
本文介绍了如何在星图GPU平台上自动化部署Qwen3-VL-30B镜像,以快速启用其强大的视频动态理解能力。用户可通过该平台轻松搭建环境,并利用该模型分析视频时序信息,例如自动解析一段健身教学视频中的关键动作步骤,实现智能化的视频内容理解与摘要生成。
Qwen3-VL-30B视频动态理解:时序分析模型部署教程
想不想让AI看懂视频里发生了什么?比如一段篮球比赛,它能告诉你谁投进了关键球;一段监控录像,它能分析出异常行为;或者一段教学视频,它能总结出核心步骤。这听起来像是科幻电影里的场景,但现在,通过Qwen3-VL-30B这个强大的视觉语言模型,你也能轻松实现。
Qwen3-VL-30B是通义千问系列目前最顶尖的视觉-语言模型,拥有300亿参数。它最大的亮点之一,就是增强的视频动态理解能力。这意味着它不再只是“看”一张静态图片,而是能“看懂”一段视频里随时间变化的动作、事件和逻辑关系。今天,我就带你从零开始,在CSDN星图平台上快速部署这个模型,并亲手体验它分析视频时序的魔力。
1. 学习目标与前置准备
在开始之前,我们先明确一下这篇教程能带给你什么,以及你需要准备些什么。
你能学到什么?
- 快速部署:在星图平台上一键拉起Qwen3-VL-30B模型服务。
- 核心使用:掌握如何上传视频、提出时序相关的问题,并获取模型的分析结果。
- 实战案例:通过几个具体的视频分析例子,理解模型在动作识别、事件总结、逻辑推理等方面的能力。
- 进阶技巧:了解如何通过优化提问方式,让模型的分析更精准、更深入。
你需要准备什么?
- 一个CSDN账号:用于登录星图平台。
- 一段你想分析的视频(可选):教程中会提供示例,但你也可以准备自己的视频(建议时长较短,几十秒为宜,格式常见如mp4、mov等)。
- 一颗好奇心:准备好探索多模态AI的边界。
整个过程非常简单,无需配置复杂的Python环境,也无需关心显卡驱动和模型下载,所有繁琐的工作星图平台都已经帮你做好了。我们直接开始吧。
2. 一分钟部署Qwen3-VL-30B模型
部署过程比你想的还要简单,基本上就是“找到入口-选择模型-开始对话”三步走。
2.1 第一步:进入Ollama模型交互页面
首先,登录你的CSDN账号,访问CSDN星图镜像广场。在广场中找到名为 “Qwen3-VL-30B” 的镜像。点击进入该镜像的详情页后,你会看到一个非常显眼的 “Ollama模型显示” 入口。这个入口就是通往模型交互界面的快速通道,点击它。
2.2 第二步:选择正确的模型版本
点击进入后,你会来到一个清爽的聊天界面。注意看页面顶部,通常有一个模型选择的下拉菜单。点击它,在列表中找到并选择 qwen3-vl:30b 这个选项。这一步至关重要,它确保你调用的是拥有视频理解能力的30B参数版本。
2.3 第三步:开始与模型对话
选择好模型后,页面下方会出现一个熟悉的输入框,就像你用任何聊天软件一样。到这里,部署就已经完成了!你已经成功启动了一个拥有300亿参数、具备高级视觉理解能力的AI助手。接下来,就是发挥它能力的时候了。
3. 上手实战:让模型看懂视频里的故事
现在,我们来真正试试它的“视频动态理解”能力。核心操作就是:上传视频 + 提出问题。
3.1 如何上传视频并提问
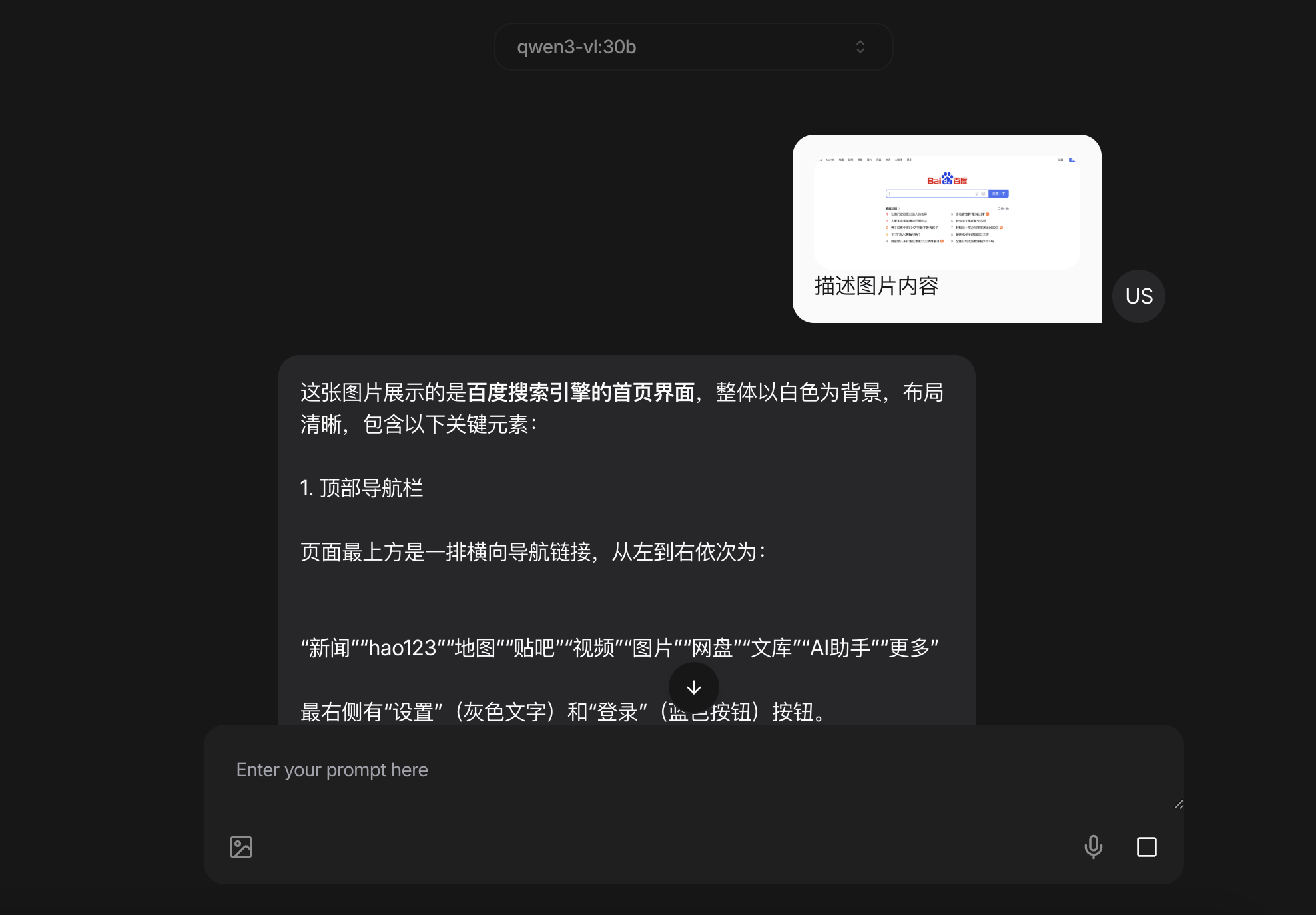
在输入框的左侧或上方,找一个上传文件的按钮(通常是一个回形针或云朵图标)。点击它,选择你准备好的视频文件。上传完成后,视频可能会以链接或缩略图的形式出现在输入框中。然后,直接在后面输入你的问题。
提问格式建议: 你可以直接描述你想知道的内容。例如:
- “描述一下这个视频里发生了什么。”
- “视频中的人依次做了哪些动作?”
- “请总结这个视频的关键步骤。”
3.2 实战案例一:分析一段健身教学视频
假设你上传了一段30秒的“深蹲教学”视频。
你的提问:“请按时间顺序列出视频中教练演示深蹲的关键步骤。”
模型的可能回答:
“好的,我分析了这段健身教学视频。教练的演示步骤如下:
- 起始姿势(0-5秒):教练双脚与肩同宽站立,背部挺直,目视前方。
- 下蹲过程(6-15秒):教练缓慢屈膝,臀部向后移动,仿佛要坐在一张椅子上,同时保持膝盖不超过脚尖,背部始终挺直。
- 最低点保持(16-20秒):在大腿与地面近乎平行时,教练稍作停顿,强调核心收紧。
- 起身还原(21-30秒):教练发力蹬地,用臀部和大腿力量将身体推回起始姿势,全程动作平稳。 此外,教练在过程中有口头提示‘注意呼吸,下蹲吸气,起身呼气’。”
你看,模型不仅识别了动作,还给出了粗略的时间戳和细节要点,完全像一个真正的健身教练在帮你分解动作。
3.3 实战案例二:理解一段简单的动画片段
上传一段猫追老鼠的卡通短片。
你的提问:“视频中的猫和老鼠之间发生了怎样的互动?结局如何?”
模型的可能回答:
“这是一段充满追逐情节的卡通片段。互动过程如下:
- 起初,老鼠正在偷吃奶酪,猫发现了它。
- 猫开始悄悄接近,然后突然扑向老鼠。
- 老鼠迅速逃跑,在房间里的桌子、椅子下灵活穿梭。
- 猫几次险些抓住老鼠,但都被老鼠用急转弯或利用小道具(如掉落的盘子)躲过。
- 最后,老鼠跑进了一个墙洞里,猫因为体型太大无法进入,在洞外沮丧地拍打地面。 结局是老鼠成功逃脱,猫的抓捕计划失败了。”
模型准确地抓住了“追逐”这一核心事件,并梳理出了起因、经过、结果,展现了基本的叙事理解能力。
4. 进阶技巧:提出更精准的问题
想要获得更高质量的分析结果,你可以问得更“聪明”一些。这里有一些小技巧:
- 指向具体时间点:“在视频第15秒的时候,那个人手里拿着什么?”
- 进行对比:“视频前半段和后半段,主角的情绪有什么变化?”
- 询问意图或原因:“根据视频内容,你认为这个人为什么要这么做?”
- 要求结构化总结:“用表格形式列出视频中出现的所有主要物体及其状态变化。”
- 结合图片理解:Qwen3-VL-30B也精通图片分析。你可以上传一张视频关键帧的截图,然后问:“结合刚才的视频和这张截图,分析一下场景的转换过程。”
一个进阶提问示例: 上传一段烹饪视频后,你可以问:“请将视频中的‘番茄炒蛋’菜谱整理成文字版,包括食材清单和分步做法。”
模型可能会生成一个结构清晰的菜谱,甚至能补充视频中语音提示的“少许盐”、“适量糖”等细节。
5. 总结与展望
通过这篇教程,你已经掌握了在CSDN星图平台上部署和使用Qwen3-VL-30B模型进行视频动态理解的全部流程。我们来简单回顾一下:
- 部署极简:利用星图镜像,无需环境配置,三步即可启动顶级视觉语言模型。
- 能力强大:Qwen3-VL-30B不仅能分析静态图像,更能理解视频中的时序信息,完成动作识别、事件总结和简单逻辑推理。
- 使用直观:核心操作就是“上传视频-提出问题”,通过自然语言即可与模型交互。
- 提问有技巧:更具体、更结构化的问题,往往能引导模型给出更精准、更有价值的回答。
这个技术的应用场景非常广泛:视频内容审核(自动识别违规行为)、教育辅助(自动生成教学视频的要点摘要)、智能安防(从监控中提取异常事件报告)、视频创作(自动为视频片段生成描述性标签或文案)等等。
现在,你已经拥有了一个强大的视频分析助手。不妨现在就去找一段有趣的视频,试试向Qwen3-VL-30B提问吧,看看它能否读懂画面背后的故事。从静态到动态,AI理解世界的方式,正因你的使用而变得更加生动和深刻。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献180条内容
已为社区贡献180条内容

所有评论(0)