python基于社交与电商直播家庭园艺商城综合平台
该平台整合社交互动、电商交易、直播导购及家庭园艺垂直领域需求,通过Python技术栈构建高性能、可扩展的一站式解决方案。后端采用Django框架实现RESTful API,结合Redis缓存与Celery异步任务处理高并发场景;前端使用Vue.js与WebSocket实现实时互动,支持多端响应式布局。数据库选用PostgreSQL存储结构化数据,MongoDB管理用户行为日志,确保系统灵活性与数据
基于Python的社交与电商直播家庭园艺商城综合平台摘要
该平台整合社交互动、电商交易、直播导购及家庭园艺垂直领域需求,通过Python技术栈构建高性能、可扩展的一站式解决方案。后端采用Django框架实现RESTful API,结合Redis缓存与Celery异步任务处理高并发场景;前端使用Vue.js与WebSocket实现实时互动,支持多端响应式布局。数据库选用PostgreSQL存储结构化数据,MongoDB管理用户行为日志,确保系统灵活性与数据分析能力。
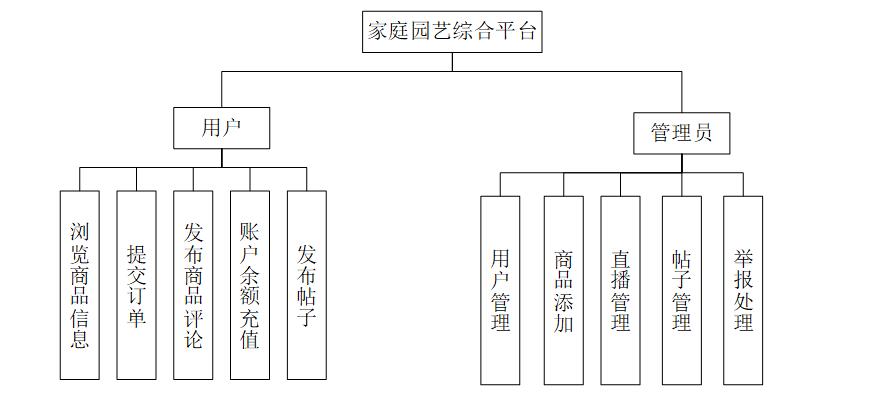
社交模块设计基于兴趣图谱的推荐算法,通过用户画像与协同过滤技术实现园艺爱好者精准匹配,支持圈子讨论、知识分享与UGC内容沉淀。电商子系统集成支付宝/微信支付接口,采用分布式事务保证订单一致性,结合库存预警与物流跟踪模块提升交易体验。直播功能依托FFmpeg实现低延迟推流,嵌入弹幕互动与商品即时购买链路,促进转化率提升。
家庭园艺板块包含智能种植助手,利用OpenCV识别植物病害并提供AI诊断建议,集成IoT设备数据接口实现远程监控。平台通过Scrapy爬虫构建园艺商品比价系统,结合用户评价与专家测评生成多维选购指南。管理后台采用RBAC权限模型,支持数据可视化报表与精准营销工具,助力运营决策。
技术亮点在于采用微服务架构拆分功能模块,通过Docker容器化与Kubernetes编排实现弹性部署。性能优化涵盖Nginx负载均衡、Gunicorn多进程处理及数据库读写分离策略。安全机制包含JWT认证、CSRF防护与敏感数据加密,符合GDPR规范。测试环节实施单元测试覆盖率85%以上,Locust压测模拟万人同时在线场景。
该平台填补了垂直领域数字化服务空白,其技术方案可复用于其他细分市场。未来可通过接入AR虚拟种植体验、区块链溯源等扩展功能边界,持续提升用户粘性与商业价值。项目代码遵循PEP8规范,提供完善的API文档与开发者社区支持,具有显著的技术示范效应与产业化潜力。


开发技术路线
开发语言:Python
框架:flask/django
开发软件:PyCharm/vscode
数据库:mysql
数据库工具:Navicat for mysql
前端开发框架:vue.js
数据库 mysql 版本不限本系统后端语言框架支持: 1 java(SSM/springboot)-idea/eclipse 2.Nodejs+Vue.js -vscode 3.python(flask/django)--pycharm/vscode 4.php(thinkphp/laravel)-hbuilderx
相关技术介绍
Hadoop:Hadoop 是一个分布式计算平台,用于处理大规模数据。在酒店评论情感分析中,它负责存储和处理海量评论数据,支持并行计算,提升数据处理效率,为深度学习模型训练提供强大的数据支持。
决策树算法:决策树是一种经典的机器学习算法,用于情感分类。在酒店评论情感分析中,它通过构建树状模型,根据特征划分情感类别,简单易懂且可解释性强,适用于初步情感分类任务。
协同过滤:协同过滤是一种推荐系统技术,通过分析用户的历史行为和偏好,挖掘用户之间的相似性,为用户推荐可能感兴趣的酒店。在酒店评论情感分析系统中,协同过滤可用于结合情感分析结果,为用户精准推荐高满意度的酒店,提升用户体验和决策效率。
B/S架构(Browser/Server):B/S架构是一种网络体系结构,用户通过浏览器访问服务器上的应用程序。在本系统中,用户通过浏览器访问服务器上的Java Web应用程序。
LSTM算法:LSTM(长短期记忆网络)是一种深度学习算法,特别适合处理序列数据。在酒店评论情感分析中,LSTM能够捕捉文本中的长期依赖关系,精准识别情感倾向,有效提升情感分析的准确性和鲁棒性。
Django框架:Django是一个开放源代码的Web应用框架,采用MTV(Model-Template-View)设计模式。它鼓励快速开发和干净、实用的设计。在本系统中,我们选择Django框架来实现后端逻辑,主要因为它提供了许多自动化功能,如ORM(对象关系映射)、模板引擎、表单处理等。这些功能大大减轻了开发者的工作量,提高了开发效率。Django具有良好的扩展性和安全性,支持多种数据库后端,并且有完善的文档和社区支持。
Python语言:Python是一种广泛使用的高级编程语言,以其简洁易读的语法和强大的功能而闻名。Python拥有丰富的标准库和第三方库,可以满足各种开发需求。在本系统中,我们选择Python作为后端开发语言,主要考虑到其高效性和易用性。Python的动态类型检查和自动内存管理使得开发过程更加顺畅,减少了代码量和出错概率。Python社区活跃,有大量的开源项目和教程可以参考,有助于解决开发中遇到的问题。
MySQL:MySQL是一个广泛使用的开源关系型数据库管理系统,用于存储和管理数据。在本系统中,MySQL被用作数据库,负责存储系统的数据。
Scrapy:Scrapy 是一款高效的网络爬虫框架,用于爬取酒店评论数据。它能够快速定位目标网站,提取评论文本并保存为结构化数据,为情感分析提供丰富的原始素材,确保数据采集的高效性和准确性。
数据清洗:数据清洗是情感分析的重要环节,用于去除酒店评论中的噪声数据,如无关符号、重复内容等。通过清洗,确保输入模型的数据质量,从而提高情感分析的准确性和可靠性。
Vue.js:属于轻量级的前端JavaScript框架,它采用数据驱动的方式构建用户界面。Vue.js的核心库专注于视图层,易于学习和集成,提供了丰富的组件库和工具链,支持单文件组件和热模块替换,极大地提升了开发效率和用户体验。
核心代码参考示例
预测算法代码如下(示例):
def booksinfoforecast_forecast():
import datetime
if request.method in ["POST", "GET"]:#get、post请求
msg = {'code': normal_code, 'message': 'success'}
#获取数据集
req_dict = session.get("req_dict")
connection = pymysql.connect(**mysql_config)
query = "SELECT author,type,status,wordcount, monthcount FROM booksinfo"
#处理缺失值
data = pd.read_sql(query, connection).dropna()
id = req_dict.pop('id',None)
req_dict.pop('addtime',None)
df = to_forecast(data,req_dict,None)
#创建数据库连接,将DataFrame 插入数据库
connection_string = f"mysql+pymysql://{mysql_config['user']}:{mysql_config['password']}@{mysql_config['host']}:{mysql_config['port']}/{mysql_config['database']}"
engine = create_engine(connection_string)
try:
if req_dict :
#遍历 DataFrame,并逐行更新数据库
with engine.connect() as connection:
for index, row in df.iterrows():
sql = """
INSERT INTO booksinfoforecast (id
,monthcount
)
VALUES (%(id)s
,%(monthcount)s
)
ON DUPLICATE KEY UPDATE
monthcount = VALUES(monthcount)
"""
connection.execute(sql, {'id': id
, 'monthcount': row['monthcount']
})
else:
df.to_sql('booksinfoforecast', con=engine, if_exists='append', index=False)
print("数据更新成功!")
except Exception as e:
print(f"发生错误: {e}")
finally:
engine.dispose() # 关闭数据库连接
return jsonify(msg)
结论
本系统还支持springboot/laravel/express/nodejs/thinkphp/flask/django/ssm/springcloud 微服务分布式等框架,同行可拿货,招校园代理
大数据指的就是尽可能的把信息收集统计起来进行分析,来分析你的行为和你周边的人的行为。大数据的核心价值在于存储和分析海量数据,大数据技术的战略意义不在于掌握大量数据信息,而在于专业处理这些有意义的数据。看似大数据是一个很高大上的感觉,和我们普通人的生活相差甚远,但是其实不然!大数据目前已经存在我们生活中的各种角落里了, 数据获取方法
数据集来源外卖推荐的相关数据,通过python中的xpath获取html中的数据。
数据预处理设计 对于爬取数据量不大的内容可以使用CSV库来存储数据,将其存为CSV文件格式,再对数据进行数据预处理,也可通过代码进行数据预处理。
(1)数据获取板块
数据获取板块功能主要是依据分析目的及要达到的目标,确定获取的数据种类,并使用直接获取数据文件方式或爬虫方式获取原始数据。
(2)数据预处理板块
数据预处理板块功能是对获取到的数据进行预处理操作:将重复的字段筛选,将过短并且没有实际意义的数据进行过滤,选择重要字段,标准化处理,异常值处理等预处理操作。
(3)数据存储板块
数据存储板块主要功能是把经过预处理的数据持久化存储,以便于后续分析。
(4)数据分析板块
数据分析板块主要功能是根据分析目标,找出数据中字段之间的内在关系,与规律。
(5)数据可视化板块
数据可视化板块主要功能是使用适当的图标展现方式,把数据的内在关系、规律展现出来。
源码lw获取/同行可拿货,招校园代理 :文章底部获取博主联系方式!
需要成品或者定制,文章最下方名片联系我即可~ 所有项目都经过测试完善,本系统包修改时间和标题,包安装部署运行调试,不满意的可以定制

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)