自动驾驶世界模型-范式02-BEV&规划-01:OccWorld: Learning a 3D Occupancy World Model for Autonomous Driving
Wenzhao Zheng1,* Weiliang Chen2,* Yuanhui Huang1 Borui Zhang1 Yueqi Duan2 Jiwen Lu1{ \mathrm { L } } { \mathrm { u } } ^ { 1 }Lu1 Department of Automation, Tsinghua University, China Department of Ele
OccWorld: Learning a 3D Occupancy World Model for Autonomous Driving
Wenzhao Zheng1,* Weiliang Chen2,* Yuanhui Huang1 Borui Zhang1 Yueqi Duan2 Jiwen Lu1{ \mathrm { L } } { \mathrm { u } } ^ { 1 }Lu1 Department of Automation, Tsinghua University, China Department of Electronic Engineering, Tsinghua University, China
wenzhao.zheng@outlook.com; {chen-wl20,huangyh22,zhang-br21}@mails.tsinghua.edu.cn; {duanyueqi,lujiwen}@tsinghua.edu.cn
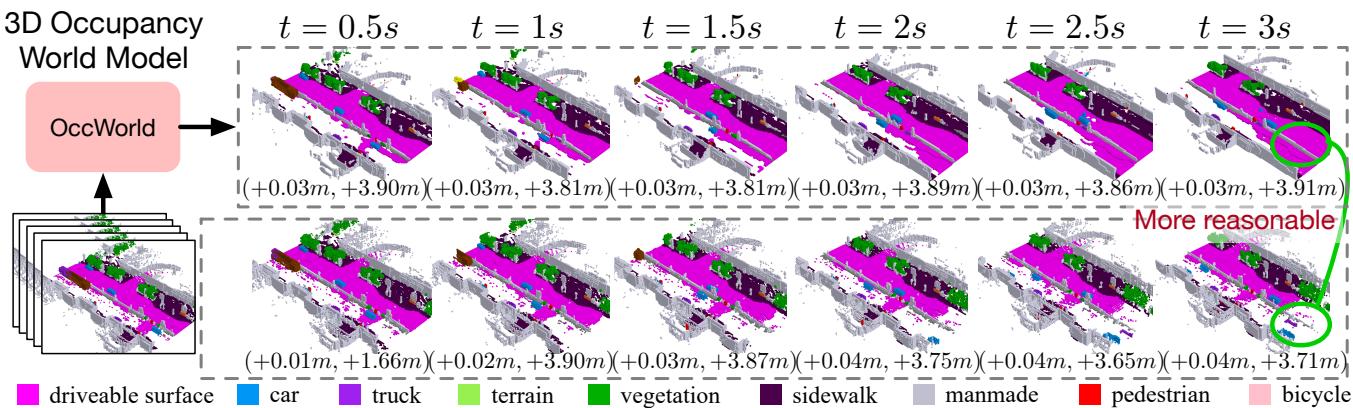
Figure 1. Given past 3D occupancy observations, our self-supervised OccWorld trained can forecast future scene evolutions and ego movements jointly. This task requires a spatial understanding of the 3D scene and temporal modeling of how driving scenarios develop. We observe that OccWorld can successfully forecast the movements of surrounding agents and future map elements such as drivable areas. OccWorld even generates more reasonable drivable areas than the ground truth, demonstrating its ability to understand the scene rather than memorizing training data. Still, it fails to forecast new vehicles entering the sight, which is difficult given their absence in the inputs.
Abstract
Understanding how the 3D scene evolves is vital for making decisions in autonomous driving. Most existing methods achieve this by predicting the movements of object boxes, which cannot capture more fine-grained scene information. In this paper, we explore a new framework of learning a world model, OccWorld, in the 3D Occupancy space to simultaneously predict the movement of the ego car and the evolution of the surrounding scenes. We propose to learn a world model based on 3D occupancy rather than 3D bounding boxes and segmentation maps for three reasons: 1) expressiveness. 3D occupancy can describe the more fine-grained 3D structure of the scene; 2) efficiency. 3D occupancy is more economical to obtain (e.g., from sparse LiDAR points). 3) versatility. 3D occupancy can adapt to both vision and LiDAR. To facilitate the modeling of the world evolution, we learn a reconstruction-based scene tokenizer on the 3D occupancy to obtain discrete scene tokens to describe the surrounding scenes. We then adopt a GPT-like spatial-temporal generative transformer to generate subsequent scene and ego tokens to decode the future occupancy and ego trajectory. Extensive experiments on the widely used nuScenes benchmark demonstrate the ability of
OccWorld to effectively model the evolution of the driving scenes. OccWorld also produces competitive planning results without using instance and map supervision. Code: https://github.com/wzzheng/OccWorld.
1. Introduction
Autonomous driving has been widely explored in recent years and demonstrated promising results in various scenarios [21, 57, 65, 68]. While LiDAR-based models typically show strong performance and robustness in 3D perception due to its capture of structural information [7, 35, 51, 61, 62], the more hardware-economical vision-centric solutions have dramatically caught up with the increased perception ability of deep networks [19, 32, 33, 42, 44].
Forecasting future scene evolutions is important to the safety of autonomous driving vehicles. Most existing methods follow a conventional pipeline of perception, prediction, and planning [17, 18, 25]. Perception aims to obtain a semantic understanding of the surrounding scene such as 3D object detection [19, 32, 33] and semantic map construction [30, 34, 37, 66]. The subsequent prediction module captures the motion of other traffic participants [11, 14, 24, 66], and the planning module then makes decisions based on previous outputs [17, 18, 25, 45]. How
OccWorld:为自动驾驶学习三维占用世界模型
Wenzhao Zheng1,* Weiliang Chen2,* Yuanhui Huang1 Borui Zhang1 Yueqi Duan2 Jiwen Lu1自动化系,清华大学,中国 电子工程系,清华大学,中国
wenzhao.zheng@outlook.com; {chen‑wl20,huangyh22,zhang‑br21}@mails.tsinghua.edu.cn;{ duanyueqi,lujiwen}@tsinghua.edu.cn
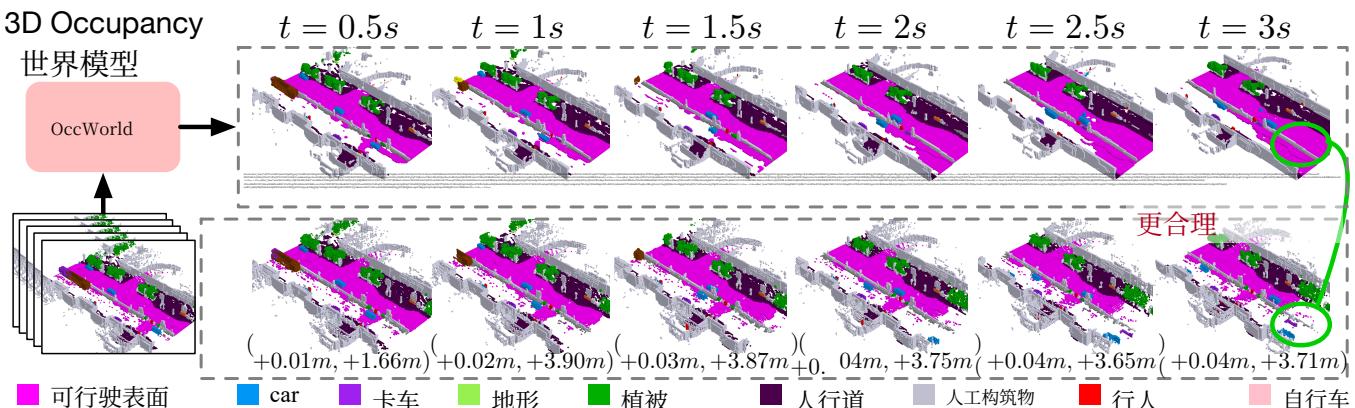
图 1. 给定过去的三维占据观测,我们自监督训练的 OccWorld 能够同时预测未来场景演化和自车运动。该任务既需要对三维场景的空间理解,又需要对驾驶场景如何演变进行时间建模。我们观察到 OccWorld 能成功预测周边主体的运动以及未来的地图要素,例如可行驶区域。OccWorld 甚至生成了比真实标签更合理的可行驶区域,显示出其理解场景而非记忆训练数据的能力。然而,它仍无法预测进入视野的新车辆——鉴于这些车辆在输入中不存在,这一任务很难做到。
摘要
理解三维场景如何演化对于自动驾驶中的决策至关重要。大多数现有方法通过预测目标边界框的运动来实现这一点,但这无法捕捉更细粒度的场景信息。在本文中,我们探索了在三维占据空间中学习世界模型OccWorld 的新框架,以同时预测自车的运动和周围场景的演化。我们提出基于三维占据而非三维边界框和分割图来学习世界模型,原因有三:1)表达力。三维占据可以描述场景更细粒度的三维结构;2)效率。三维占据更经济易得(例如来自稀疏激光雷达点);3)通用性。三维占据可适配视觉和激光雷达。为便于建模世界演化,我们在三维占据上学习了基于重建的场景分词器,以获得描述周围场景的离散场景令牌。随后我们采用类GPT的时空生成式变换器来生成后续的场景和自车令牌,以解码未来的占据和自车轨迹。在广泛使用的nuScenes 基准上的大量实验验证了
OccWorld 用于有效建模驾驶场景的演化。OccWorld 在不使用实例和地图监督的情况下也能产生具有竞争力的规划结果。代码:https://github.com/wzzheng/OccWorld。
1. 引言
近年来,自动驾驶得到了广泛研究,并在各种场景中展示了可喜的成果 [21, 57, 65, 68Jo6 8 \mathrm { J o }68Jo 。由于能够捕捉结构信息,基于激光雷达的模型在三维感知方面通常表现出较强的性能和鲁棒性 [7, 35, 51, 61,62], ,而随着深度网络感知能力的提升,硬件成本更低的以视觉为中心的方案已经迅速迎头赶上 [19, 32, 33, 42, 44]。
预测未来场景演化对于自动驾驶车辆的安全至关重要。大多数现有方法遵循感知、预测与规划的传统流水线 [17, 18, 25]。感知旨在获得对周围场景的语义理解,例如三维目标检测 [19, 32, 33] 和语义地图构建 [30, 34, 37, 66]。随后预测模块捕捉其他交通参与者的运动 [11, 14, 24, 66], ,而规划模块则基于之前的输出做出决策 [17, 18, 25, 45]。如‑
ever, this serial design usually requires ground-truth labels at each stage of training, yet the instance-level bounding boxes and high-definition maps are difficult to annotate. Furthermore, they usually only predict the motion of object bounding boxes, failing to capture more fine-grained information about the 3D scene.
In this paper, we explore a new paradigm to simultaneously predict the evolution of the surrounding scene and plan the future trajectory of the self-driving vehicle. We propose OccWorld, a world model in the 3D semantic occupancy space, to model the development of the driving scenes. We adopt 3D semantic occupancy as the scene representation over the conventional 3D bounding boxes and segmentation maps, which can describe the more finegrained 3D structure of the scene. Moreover, 3D occupancy can be effectively learned from sparse LiDAR points [21], and thus is a potentially more economical way to describe the surrounding scenes. Given the 3D semantic occupancy representation of the current scene, OccWorld aims to predict how it evolves as the self-driving vehicle advances. To achieve this, we first employ a vector-quantized variational autoencoder (VQVAE) [41] to refine high-level concepts and obtain discrete scene tokens in a self-supervised manner. We then tailor the generative pre-training transformers (GPT) [2] architecture and propose a spatial-temporal generative transformer to predict the subsequent scene tokens and ego tokens to forecast the future occupancy and ego trajectory, respectively. We first perform spatial mixing to aggregate scene tokens and obtain multi-scale tokens to represent scenes at multiple levels. We then apply temporal attention to tokens at different levels to predict tokens for the next frame and use a U-net structure to integrate them. Finally, we use the trained VQVAE decoder to transform scene tokens to the occupancy space and learn a trajectory decoder to obtain ego planning results.
To demonstrate the effectiveness of OccWorld, we formulate a challenging task of 4D occupancy forecasting, which aims to predict the 3D occupancy of the following frames given a few past frames. Our OccWorld can effectively forecast future evolutions including moving agents and static elements as shown in Figure 1, and achieves an average IoU of 26.63 and mIoU of 17.13 for 3s3 s3s future given 2s2 s2s history, OccWorld can also produce planning trajectories with an L2 error of 1.16 without using any instance and map annotations. Using self-supervised learned 3D occupancy from camera inputs [20], our method achieves non-trivial 4D occupancy forecasting and planning results, demonstrating the potential for interpretable end-to-end autonomous driving without additional human-annotated labels.
2. Related Work
3D Occupancy Prediction: 3D occupancy prediction aims to predict whether each voxel in the 3D space is occupied and its semantic label if occupied [21, 52, 53, 56, 57, 69]. Early methods exploited LiDAR as inputs to complete the 3D occupancy of the entire 3D scene [6, 29, 46, 59]. Recent methods began to explore the more challenging visionbased 3D occupancy prediction [4, 21] or applying vision backbones to efficiently perform LiDAR-based 3D occupancy prediction [69]. 3D occupancy provides more comprehensive descriptions of the surrounding scene and includes both dynamic and static elements [21, 57, 69]. It can also be efficiently learned from sparse accumulated multiple LiDAR scans [57], LiDAR [21], or video sequences [5]. However, existing methods only focus on obtaining the 3D semantic occupancy and ignore its temporal evolution, which is vital to the safety of autonomous driving. In this paper, we explore the task of 4D occupancy forecasting and propose a 3D occupancy world model to achieve this.
World Models for Autonomous Driving: World models have a long history in control engineering and artificial intelligence [49], which are usually defined as producing the next scene observation given action and past observations [12]. The development of deep neural networks [13, 48, 50] promoted the use of deep generative models [10, 28] as world models. Based on large pretrained image generative models like StableDiffusion [47], recent methods [9, 15, 31, 55, 60] can generate realistic driving sequences of diverse scenarios. However, they produce future observations in the 2D image space, lacking understanding of the 3D surrounding scene. Some other methods explore forecasting point clouds using unannotated LiDAR scans [26, 27, 40, 58], which ignore the semantic information and cannot be applied to vision-based or fusionbased autonomous driving. Considering this, we explore a world model in the 3D occupancy space to more comprehensively model the 3D scene evolution.
End-to-End Autonomous Driving: The ultimate goal of autonomous driving is to obtain controlling signals based on observations of the surrounding scenes. Recent methods follow this concept to output planning results for the ego car given sensor inputs [17, 18, 25, 53, 63]. Most of them follow a conventional pipeline of perception [21, 32, 33, 57, 65], prediction [11, 14, 36, 66], and planning [22, 23, 54, 67]. They usually first perform BEV perception to extract relevant information (e.g., 3D agent boxes, semantic maps, tracklets) and then exploit them to infer future trajectories of agents and the ego vehicle. The following methods incorporated more data [63] or extracted more intermediate features [17, 18, 25] to provide more information for the planner, which achieved remarkable performance. Most methods only model object motions and cannot capture the fine-grained structural and semantic information of the surroundings [11, 14, 24, 25, 66]. Differently, we propose a world model to predict the evolution of both the surrounding dynamic and static elements.
果, 这种串行设计通常在每个训练阶段都需要真实标签,但实例级边界框和高清地图难以标注。此外,它们通常仅预测目标边界框的运动,未能捕捉到关于三维场景的更细粒度信息。
在本文中,我们探索了一种新范式,旨在同时预测周围场景的演变并规划自动驾驶车辆的未来轨迹。我们提出了 OccWorld,一种基于三维语义占据空间的世界模型,用于建模驾驶场景的发展。我们采用三维语义占据作为场景表示,替代传统的三维边界框和分割图,因其能更细粒度地描述场景的三维结构。此外,三维占据可以从稀疏的 LiDAR 点有效学习 [21],,因此在描述周围场景方面具有潜在的更经济性。给定当前场景的三维语义占据表示,OccWorld 的目标是预测随着自动驾驶车辆前进,场景如何演变。为实现此目标,我们首先采用向量量化变分自编码器(VQVAE) [41]以自监督的方式精炼高层概念并获取离散的场景令牌。然后我们定制了生成式预训练变换器(GPT) [2]架构,提出了时空生成式变换器,用于分别预测后续的场景令牌和自我令牌,以预测未来的占据和自车轨迹。我们首先进行空间混合以聚合场景令牌,并获得用于在多个层次上表示场景的多尺度令牌。随后对不同层次的令牌应用时间注意力以预测下一帧的令牌,并使用 U‑net 结构将它们整合。最后,我们使用训练好的 VQVAE 解码器将场景令牌转换为占据空间,并学习一个轨迹解码器以获得自车规划结果。
为了证明 OccWorld 的有效性,我们提出了一个具有挑战性的任务:四维占据预测(4D occupancyforecasting),该任务旨在根据若干过去帧预测后续帧的三维占据。正如图1所示,我们的 OccWorld 能有效预测包括运动主体和静态元素在内的未来演化,并在 3s 未来给定2s历史的情况下取得了平均 IoU 为 26.63、mIoU 为 17.13 的成绩,OccWorld 还可以在不使用任何实例和地图标注的情况下生成 L2 误差为 1.16 的规划轨迹。使用来自相机输入的自监督学习三维占据 [20], ,我们的方法在四维占据预测和规划任务上取得了非平凡的结果,展示了无需额外人工标注即可实现可解释端到端自动驾驶的潜力。
2. 相关工作
3D OccupancyPrediction: 三维占据预测旨在预测三维空 间中每个体素是否被占据
以及在被占据时其语义标签 [21, 52, 53, 56, 57, 69]。早期方法使用激光雷达作为输入,以完成整个三维场景的三维占据重建 [6, 29, 46, 59]。近来的方法开始探索更具挑战性的基于视觉的三维占据预测 [4, 21] ,或将视觉骨干网络应用于高效执行基于激光雷达的三维占据预测 [69]。三维占据提供了对周围场景更全面的描述,包含动态和静态元素 [21,57,69]。它也可以从稀疏累积的多次激光雷达扫描高效学习 [57],LiDAR[21],或视频序列 [5]。然而,现有方法仅关注获取三维语义占据,而忽略了其时间演化,而时间演化对自动驾驶的安全至关重要。在本文中,我们探讨四维占据预测任务,并提出一个三维占据世界模型来实现该目标。
自动驾驶的世界模型:世界模型在控制工程和人工智能领域有着悠久历史,通常被定义为在给定动作和过去观测的条件下生成下一个场景观测的模型 [49], 。深度神经网络的发展 [13, 48, 50]促进了将深度生成模型 [10, 28] 用作世界模型。基于像StableDiffusion 这样的预训练大型图像生成模型 [47],,近期方法 [9, 15, 31, 55, 60] 能够生成多样场景的真实驾驶序列。然而,它们在二维图像空间中生成未来观测,缺乏对三维周围场景的理解。还有一些方法探索使用未标注的 LiDAR 扫描预测点云 [26, 27, 40, 58], ,但这些方法忽视语义信息,且无法应用于基于视觉或融合的自动驾驶。鉴于此,我们在三维占据空间中探索世界模型,以更全面地建模三维场景演化。
端到端自动驾驶: 自动驾驶的最终目标是基于对周围场景的观测获得控制信号。近期的方法遵循这一理念,基于传感器输入为自车输出规划结果[17, 18, 25, 53, 63]。它们大多采用传统的感知 [21,32, 33, 57, 65], 、预测 [11, 14, 36, 66], 与规划[22, 23, 54, 67] 流水线。通常先进行 BEV 感知以提取相关信息(例如,三维代理框、语义地图、轨迹片段),然后利用这些信息推断目标和自车的未来轨迹。随后的一些方法整合了更多数据 [63]或提取了更多中间特征 [17, 18, 25] ,以为规划器提供更丰富的信息,从而取得了显著的性能提升。大多数方法仅对目标运动建模,无法捕捉周围环境的细粒度结构和语义信息[11, 14, 24, 25, 66]。与此不同,我们提出了一个世界模型来预测周围动态与静态元素的演变。
Input: t = 1 Input: t=T−1t = T - 1t=T−1
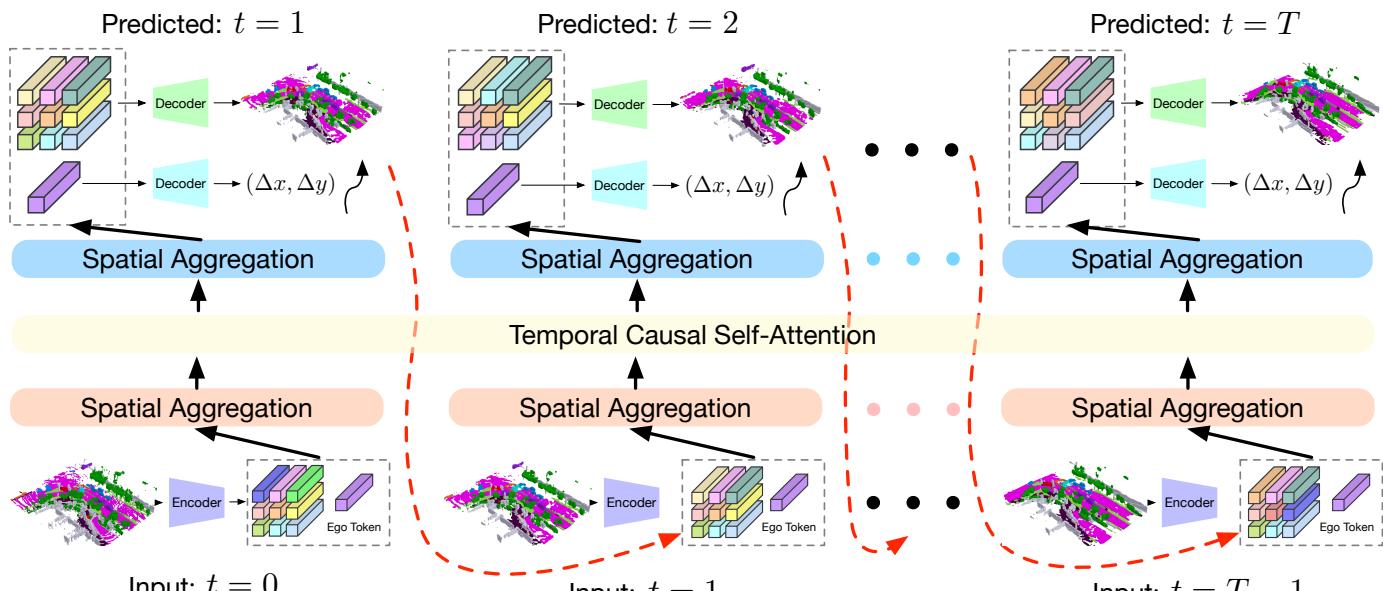
Figure 2. Framework of our OccWorld for 3D semantic occupancy forecast and motion planning. We adopt a GPT-like generative architecture to predict the next scene from previous scenes in an autoregressive manner. We adapt GPT [2] to the autonomous driving scenario with two key designs: 1) We train a 3D occupancy scene tokenizer to produce discrete high-level representations of the 3D scene; 2) We perform spatial mixing before and after spatial-wise temporal causal self-attention to efficiently produce globally consistent scene predictions. We use ground-truth and predicted scene tokens as inputs for future generations for training and inference, respectively.
3. Proposed Approach
3.1. World Model for Autonomous Driving
Autonomous driving aims to automatically steer a vehicle to fully prevent or partially reduce actions from human drivers [18]. Formally, the objective of autonomous driving is to obtain the control commands cT\mathbf { c } ^ { T }cT (e.g., throttle, steer, break) for the present time stamp TTT given the sensor inputs {sT,sT−1,⋅⋅⋅,sT−t}\{ \mathbf { s } ^ { T } , \mathbf { s } ^ { T - 1 } , \cdot \cdot \cdot , \mathbf { s } ^ { T - t } \}{sT,sT−1,⋅⋅⋅,sT−t} from the current and past ttt frames.
As the mapping from trajectories to control signals is highly dependent on the vehicle specifications and status, the literature usually assumes a given satisfactory controller and thus focuses on trajectory planning for the ego vehicle. An autonomous driving model AAA then takes input as the sensor inputs and ego trajectory from the past TTT frames and predicts the ego trajectory of future fff frames:
A({sT,sT−1,⋯ ,sT−t},{pT,pT−1,⋯ ,pT−t})={pT+1,pT+2,⋯ ,pT+f}, \begin{array} { r l } & { \quad A ( \{ \mathbf { s } ^ { T } , \mathbf { s } ^ { T - 1 } , \cdots , \mathbf { s } ^ { T - t } \} , \{ \mathbf { p } ^ { T } , \mathbf { p } ^ { T - 1 } , \cdots , \mathbf { p } ^ { T - t } \} ) } \\ & { = \{ \mathbf { p } ^ { T + 1 } , \mathbf { p } ^ { T + 2 } , \cdots , \mathbf { p } ^ { T + f } \} , } \end{array} A({sT,sT−1,⋯,sT−t},{pT,pT−1,⋯,pT−t})={pT+1,pT+2,⋯,pT+f},
where pt\mathbf { p } ^ { t }pt denotes the 3D ego position at the ttt -th time.
The conventional pipeline of autonomous driving usually follows a design of perception, prediction, and planning [17, 18, 25]. The perception module perp _ { e r }per perceives the surrounding scenes and extracts high-level information z\mathbf { z }z from the input sensor data s. The prediction module prep _ { r e }pre then integrates the high-level information z\mathbf { z }z to predict the future trajectory ti\mathbf { t } _ { i }ti of each agent in the scene. The planning module plap _ { l a }pla finally processes the perception and prediction results {z,{ti}}\left\{ \mathbf { z } , \left\{ \mathbf { t } _ { i } \right\} \right\}{z,{ti}} to plan the motion of the ego vehicle. The conventional pipeline can be formulated as:
pla(per({sT,⋯ ,sT−t}),pre(per({sT,⋯ ,ϕT−t})))={pT+1,pT+2,⋯ ,pT+f}. \begin{array} { r l } & { \quad p _ { l a } ( p _ { e r } ( \{ \mathbf { s } ^ { T } , \cdots , \mathbf { s } ^ { T - t } \} ) , p _ { r e } ( p _ { e r } ( \{ \mathbf { s } ^ { T } , \cdots , \mathbf { \phi } ^ { T - t } \} ) ) ) } \\ & { = \{ \mathbf { p } ^ { T + 1 } , \mathbf { p } ^ { T + 2 } , \cdots , \mathbf { p } ^ { T + f } \} . } \end{array} pla(per({sT,⋯,sT−t}),pre(per({sT,⋯,ϕT−t})))={pT+1,pT+2,⋯,pT+f}.
Despite the promising performance of this framework [17, 18, 25], it usually requires ground-truth labels for supervision at each stage, which can be laborious to annotate. It only considers object-level movement and fails to model more fine-grained evolutions.
Motivated by this, we explore a new world-model-based autonomous driving paradigm to comprehensively model the evolution of the surrounding scenes and the ego movements. Inspired by the recent success of generative pretraining transformers (GPT) [2] in natural language processing (NLP), we propose an auto-regressive generative modeling framework for autonomous driving scenarios. We define a world model www to act on scene representations y\mathbf { y }y and be able to predict future scenes. Formally, we formulate the function of a world model www as follows:
w({yT,⋅⋅⋅,yT−t},{pT,⋅⋅⋅,pT−t})=yT+1,pT+1. w ( \{ \mathbf { y } ^ { T } , \cdot \cdot \cdot , \mathbf { y } ^ { T - t } \} , \{ \mathbf { p } ^ { T } , \cdot \cdot \cdot , \mathbf { p } ^ { T - t } \} ) = \mathbf { y } ^ { T + 1 } , \mathbf { p } ^ { T + 1 } . w({yT,⋅⋅⋅,yT−t},{pT,⋅⋅⋅,pT−t})=yT+1,pT+1.
Having obtained the predicted scene yT+1\mathbf { y } ^ { T + 1 }yT+1 and the ego position pT+1\mathbf { p } ^ { T + 1 }pT+1 , we can add them to the input and further predict the next frame in an auto-regressive manner, as shown in Figure 2. The world model www captures the joint distribution of the evolution of the surrounding scene and the ego vehicle, considering their high-order interactions.
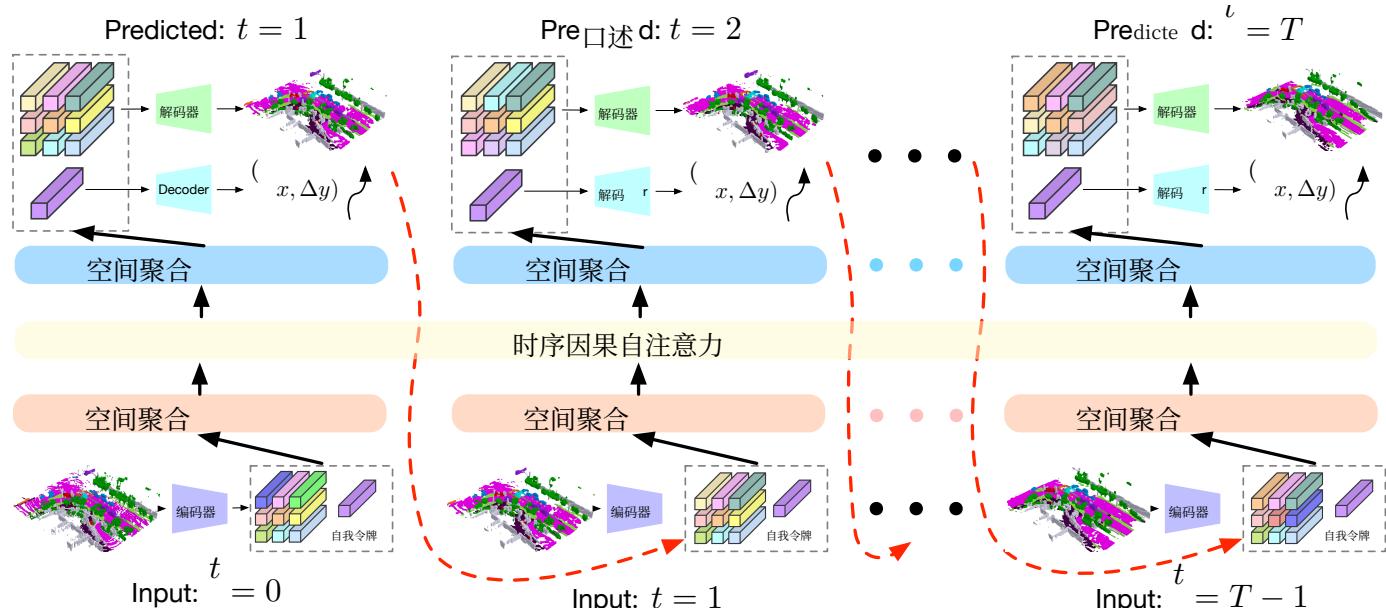
图 2。我们的OccWorld 在三维语义占据预测与运动规划方面的框架。我们采用类 GPT 的生成式架构,以自回归方式从先前场景预测下一个场景。我们将 GPT [2] 调整用于自动驾驶场景,包含两个关键设计:1)我们训练了一个三维占用场景分词器,以生成三维场景的离散高层表示;2)在空间式时序因果自注意力之前和之后执行空间混合,以高效地产生全局一致的场景预测。我们在训练和推理时分别使用真实场景标记和预测场景标记作为未来生成的输入。
3. 所提出的方法
3.1. 自动驾驶的世界模型
自动驾驶旨在自动控制车辆以完全避免或部分减轻人类驾驶员的操作 [18]∘[ 1 8 ] _ { \circ }[18]∘ 。形式上,自动驾驶的目标是在给定当前及过去帧的传感器输入 {sT,sT−1,⋅⋅⋅,sT−t}\{ \mathbf { s } ^ { T } , \mathbf { s } ^ { T - 1 } , \cdot \cdot \cdot , \mathbf { s } ^ { T - t } \}{sT,sT−1,⋅⋅⋅,sT−t} 的情况下,为当前时间戳 TTT 获取控制指令 cT\mathbf { c } ^ { T }cT (例如,油门、转向、制动)。
由于从轨迹到控制信号的映射高度依赖于车辆规格和状态,文献通常假设已有令人满意的控制器,因此关注自车的轨迹规划。自动驾驶模型 AAA 接收过去TTT 帧的传感器输入和自车轨迹作为输入,并预测未来fff 帧的自车轨迹:
A({sT,sT−1,⋯ ,sT−t},{pT,pT−1,⋯ ,pT−t})={pT+1,pT+2,⋯ ,pT+f}, \begin{array} { r l } & { \quad A ( \{ \mathbf { s } ^ { T } , \mathbf { s } ^ { T - 1 } , \cdots , \mathbf { s } ^ { T - t } \} , \{ \mathbf { p } ^ { T } , \mathbf { p } ^ { T - 1 } , \cdots , \mathbf { p } ^ { T - t } \} ) } \\ & { = \{ \mathbf { p } ^ { T + 1 } , \mathbf { p } ^ { T + 2 } , \cdots , \mathbf { p } ^ { T + f } \} , } \end{array} A({sT,sT−1,⋯,sT−t},{pT,pT−1,⋯,pT−t})={pT+1,pT+2,⋯,pT+f},
where p t\mathrm { ~ \bf ~ p ~ } ^ { t } p t 表示第 t时刻的三维自车位置。
传统的自动驾驶流水线通常遵循感知、预测与规划的设计 [17, 18, 25]。感知模块 perp _ { e r }per 从输入传感器数据 z\mathbf { z }z s中感知周围场景并提取高级信息。预测模块 prep _ { r e }pre 随后整合这些高级信息 z\mathbf { z }z 以预测场景中每个主体的未来轨迹 t˙i\mathbf { \dot { t } } _ { i }t˙i 。规划模块 plap _ { l a }pla 最终处理感知和预测结果 {z {\{ \mathbf { z } \ \left\{ \begin{array} { r l } \end{array} \right.{z { ti}}\mathbf { t } _ { i } \} \}ti}} 以规划自车的运动。
该传统流水线可表述为:
pla(per({sT,⋯ ,sT−t}),pre(per({sT,⋯ ,ϕT−t})))={pT+1,pT+2,⋯ ,pT+f}. \begin{array} { r l } & { \quad p _ { l a } ( p _ { e r } ( \{ \mathbf { s } ^ { T } , \cdots , \mathbf { s } ^ { T - t } \} ) , p _ { r e } ( p _ { e r } ( \{ \mathbf { s } ^ { T } , \cdots , \mathbf { \phi } ^ { T - t } \} ) ) ) } \\ & { = \{ \mathbf { p } ^ { T + 1 } , \mathbf { p } ^ { T + 2 } , \cdots , \mathbf { p } ^ { T + f } \} . } \end{array} pla(per({sT,⋯,sT−t}),pre(per({sT,⋯,ϕT−t})))={pT+1,pT+2,⋯,pT+f}.
尽管该框架 [17, 18, 25], 表现令人期待,但通常需要在每个阶段使用真实标签进行监督,这在标注上可能非常费力。它仅考虑对象级运动,未能对更细粒度的演变建模。
受此启发,我们探索了一种新的基于世界模型的自动驾驶范式,以全面建模周围场景与自车运动的演化。受最近在自然语言处理(NLP)中生成式预训练变换器(GPT)[2]成功的启发,我们提出了一个用于自动驾驶场景的自回归生成建模框架。我们将世界模型 www 定义为作用于场景表示y 并能够预测未来场景。形式上,我们将世界模型的函数 www 表述如下:
w({yT,⋅⋅⋅,yT−t},{pT,⋅⋅⋅,pT−t})=yT+1,pT+1. w ( \{ \mathbf { y } ^ { T } , \cdot \cdot \cdot , \mathbf { y } ^ { T - t } \} , \{ \mathbf { p } ^ { T } , \cdot \cdot \cdot , \mathbf { p } ^ { T - t } \} ) = \mathbf { y } ^ { T + 1 } , \mathbf { p } ^ { T + 1 } . w({yT,⋅⋅⋅,yT−t},{pT,⋅⋅⋅,pT−t})=yT+1,pT+1.
在获得了预测场景 yT+1\mathbf { y } ^ { T + 1 }yT+1 和自车位置 pT+1.\mathbf { p } ^ { T + 1 } .pT+1. 之后,我们可以将它们加入输入,并以自回归方式进一步预测下一帧,如图 2所示。世界模型 www 捕捉了周围场景与自车演变的联合分布,考虑了它们的高阶相互作用。
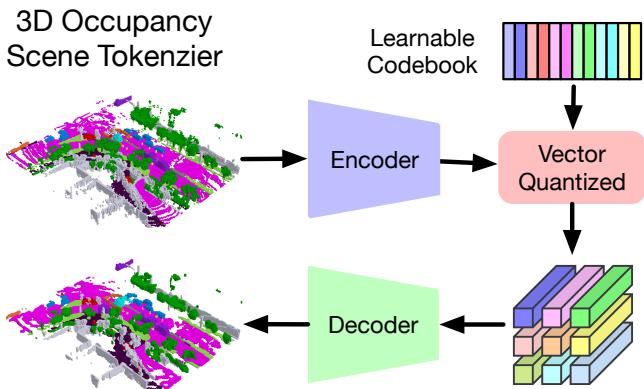
Figure 3. Illustration of the proposed 3D occupancy scene tokenizer. We use CNNs to encode the 3D occupancy and perform vector quantization to obtain discrete tokens using a learnable codebook [41]. We then employ a decoder to reconstruct the input 3D occupancy using the quantized tokens and use a reconstruction objective to train the autoencoder and codebook simultaneously.
3.2. 3D Occupancy Scene Tokenizer
As the world model www operates on the scene representation y\mathbf { y }y , its choice is vital to the performance of the world model. We select y based on three principles: 1) expressiveness. It should be able to comprehensively contain the 3D structural and semantic information of the 3D scene; 2) efficiency. It should be economical to learn (e.g., from weak supervision or self-supervision); 3) versatility. It should be able to adapt to both vision and LiDAR modalities.
Considering all the aforementioned principles, we propose to adopt 3D occupancy as the 3D scene representation y∈RHˉ×W×D\mathbf { y } \in \mathbb { R } ^ { \bar { H } \times W \times D }y∈RHˉ×W×D . 3D occupancy partitions the 3D space surrounding the ego car into H×W×DH \times W \times DH×W×D voxels and assigns each voxel with a label lll denoting whether it is occupied and which material it is occupied with. 3D occupancy provides a dense representation of the 3D scene and can describe both the 3D structural and semantic information of the scene. It can be effectively learned from sparse LiDAR annotations [21] or potentially from self-supervision of temporal frames [20]. 3D occupancy is also modalityagnostic and can be obtained from monocular camera [4], surrounding cameras [21, 53, 57], or LiDAR [69].
Despite its comprehensiveness, 3D occupancy only provides a low-level understanding of the scene, making it difficult to directly model its evolution. We therefore propose a self-supervised way to tokenize the scene into high-level tokens from 3D occupancy. We train a vector-quantized autoencoder (VQ-VAE) [41] on y\mathbf { y }y to obtain discrete tokens z\mathbf { z }z to better represent the scene, as shown in Figure 3.
For efficiency, we first transform the 3D occupancy y ∈\textbf { y } \in y ∈ RH×W×D\mathbb { R } ^ { H \times W \times D }RH×W×D to a BEV representation y^∈RH×Wˉ×D′C′\hat { \mathbf { y } } \in \mathbb { R } ^ { H \times \bar { W } \times D ^ { \prime } C ^ { \prime } }y^∈RH×Wˉ×D′C′ by assigning each category with a learnable class embedding ∈RC‾′\in \mathbb { R } ^ { \overline { { C } } ^ { \prime } }∈RC′ and concatenating them in the height dimension. We then adopt a lightweight encoder composed of 2D convolution layers to obtain down-sampled features zˆ ∈ R Hd × Wd ×C of the scene, where ddd is the down-sampling factor.
To obtain a more compact representation, we simultaneously learn a codebook Cˉ∈RN×Dˉ\bar { \mathbf { C } } \in \bar { \mathbb { R } ^ { N \times D } }Cˉ∈RN×Dˉ containing NNN codes. Each code c∈RC\mathbf { c } \in \mathbb { R } ^ { C }c∈RC in the codebook encodes a high-level concept of the scene, e.g., whether the corresponding position is occupied by a car. We quantized each spatial feature z^ij\hat { \mathbf { z } } _ { i j }z^ij in z^\hat { \mathbf { z } }z^ by classifying it to the nearest code N(z^ij,C)\mathcal { N } ( \hat { \mathbf { z } } _ { i j } , \mathbf { C } )N(z^ij,C) :
zij=N(z^ij,C)=minc∈C∣∣z^ij−c∣∣2, \mathbf { z } _ { i j } = \mathcal { N } ( \hat { \mathbf { z } } _ { i j } , \mathbf { C } ) = \operatorname* { m i n } _ { \mathbf { c } \in \mathbf { C } } | | \hat { \mathbf { z } } _ { i j } - \mathbf { c } | | _ { 2 } , zij=N(z^ij,C)=c∈Cmin∣∣z^ij−c∣∣2,
where ∣∣⋅∣∣2| | \cdot | | _ { 2 }∣∣⋅∣∣2 denotes the L2 norm. We then integrate the quantized features {zij}\{ { \bf { z } } _ { i j } \}{zij} to obtain the final scene representation z RH×W×C .
To reconstruct y~\widetilde { \mathbf { y } }y from the learned scene representation z\mathbf { z }z e, we use a decoder of 2D deconvolution layers to progressively upsample z\mathbf { z }z to its original BEV resolution H×W×C′′H \times W \times C ^ { \prime \prime }H×W×C′′ . We then perform a split in the channel dimension to reconstruct the height dimension H×W×D×C′′D\begin{array} { r } { H \times W \times D \times \frac { C ^ { \prime \prime } } { D } } \end{array}H×W×D×DC′′ and apply a softmax layer on each spatial feature to classify them into occupied semantics or unoccupied H×W×DH \times W \times DH×W×D .
The scene tokenizer transforms 3D occupancy into a more compact discrete space to encode higher-level concepts. This refined compact space facilitates the modeling of scene evolution for the subsequent world model.
3.3. Spatial-Temporal Generative Transformer
The core of autonomous driving lies in the prediction of how the surrounding world evolves and planning the movement of the ego vehicle accordingly. While conventional methods usually perform the two tasks separately [17, 18], we propose to learn a world model www to jointly model the distributions of scene evolution and ego trajectory.
As defined in (3), a world model www takes as inputs the past scenes and ego positions and predicts their outcome after driving a certain time interval. Based on expressiveness, efficiency, and versatility, we adopt 3D occupancy y\mathbf { y }y as the scene representation and use a self-supervised tokenizer to obtain high-level scene tokens T={zi}\mathbf { T } = \{ \mathbf { z } _ { i } \}T={zi} . To integrate the ego movement, we further aggregate T\mathbf { T }T with an ego token z0∈RC\mathbf { z } _ { 0 } \in \mathbb { R } ^ { C }z0∈RC to encode the spatial position of the ego vehicle.
The proposed OccWorld www then functions on the world tokens T\mathbf { T }T , which can be formulated as:
w(TT,⋅⋅⋅,TT−t)=TT+1, w ( \mathbf { T } ^ { T } , \cdot \cdot \cdot , \mathbf { T } ^ { T - t } ) = \mathbf { T } ^ { T + 1 } , w(TT,⋅⋅⋅,TT−t)=TT+1,
where TTT is the current time stamp, and ttt is the number of history frames available.
Inspired by the remarkable sequential prediction performance of GPT [2], we adopt a GPT-like autoregressive transformer architecture to instantiate (5). However, the migration of GPT from natural language processing to the autonomous driving scenario is not trivial. GPTs predict a single token each time, while the world model www in autonomous driving is required to predict a set of tokens T\mathbf { T }T as
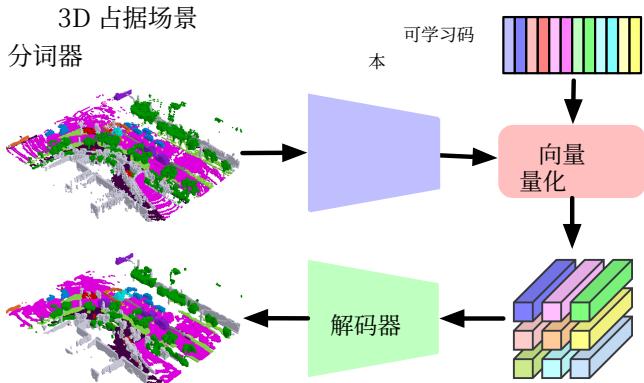
图 3。所提出的三维占据场景分词器示意图。我们使用卷积神经网络对三维占据进行编码,并使用可学习码本执行向量量化以获得离散令牌 [41]∘[ 4 1 ] _ { \circ }[41]∘ 。然后我们使用解码器利用量化后的令牌重建输入的三维占据,并使用重建目标同时训练自编码器和码本。
3.2. 三维占据场景分词器
由于世界模型 www 在场景表示y上运行,y 的选择对世界模型的性能至关重要。我们基于三项原则选择y :
1)表现力。它应能全面包含三维场景的三维结构和语义信息;2)效率。它应当易于学习(例如,从弱监督或自监督中);3)通用性。它应能适应视觉和激光雷达两种模态。
考虑到上述所有原则,我们建议采用三维占据作为三维场景表示 y∈RH×W×D,\mathbf { y } \in \mathbb { R } ^ { H \times W \times D } ,y∈RH×W×D, 。三维占据将自车周围的三维空间划分为 H×W×DH \times W \times DH×W×D 体素,并为每个体素分配一个标签 lll ,表示该体素是否被占据以及被何种材料占据。三维占据提供了对三维场景的稠密表示,能够描述场景的三维结构和语义信息。它可以从稀疏激光雷达标注中有效学习 [21] ,或可能通过时间帧的自监督学习得到 [20]∘[ 2 0 ] _ { \circ }[20]∘ 。三维占据也是模态无关的,可从单目相机 [4],、周围相机 [21, 53, 57],或激光雷达 [69]获得。
尽管三维占据表述非常全面,但它只提供了对场景的低层理解,因此很难直接对其演变建模。为此,我们提出了一种自监督方法,将三维占据场景标记化为高层令牌。我们训练了一个向量量化自编码器 (VQ‑VAE)[41] 在y 上以获得离散令牌 z\mathbf { z }z 来更好地表示场景,如图3所示。
为提高效率,我们首先将三维占据 y\mathbf { y }y ∈RH×W×D\in \mathbb { R } ^ { H \times W \times D }∈RH×W×D 转换为鸟瞰图表示 y^∈RH×W×DC′\hat { \mathbf { y } } \in \mathbb { R } ^ { H \times W \times D C ^ { \prime } }y^∈RH×W×DC′ ,通过为每个类别分配一个可学习的类别嵌入 ∈RC′\in \mathbb { R } ^ { C ^ { \prime } }∈RC′ 并在高度维度上将它们连接起来。然后我们采用由二维卷积层组成的轻量级编码器来获得下采样特征 z^∈R H ×ΣdW×C et − \hat { \mathbf { z } } \in \mathbb { R } ^ { \textit { H } \times \mathbf { \Sigma } _ { d } ^ { W } \times C \mathrm { ~ et ~ { ~ } { ~ - ~ } ~ } }z^∈R H ×ΣdW×C et − 场景的下采样特征,其中 ddd 是下采样因子。
为了获得更紧凑的表示,我们同时学习了一个包含NNN 个 codes 的码本 C∈RN×D\mathbf { C } \in \mathbb { R } ^ { N \times D }C∈RN×D 。码本中的每个code c∈RC\mathbf { c } \in \mathbb { R } ^ { C }c∈RC 编码了场景的一个高层概念,例如相应位置是否被汽车占据。我们通过将每个空间特征 z^ij\mathbf { \hat { z } } ^ { i j }z^ij 在 z^\scriptstyle \mathbf { \hat { z } }z^ 中分类到最近的 code N(z^ij,C)\mathcal { N } ( \hat { \mathbf { z } } _ { i j } , \mathbf { C } )N(z^ij,C) 来对其进行量化:
zij=N(z^ij,C)=minc∈C∣∣z^ij−c∣∣2, \mathbf { z } _ { i j } = \mathcal { N } ( \hat { \mathbf { z } } _ { i j } , \mathbf { C } ) = \operatorname* { m i n } _ { \mathbf { c } \in \mathbf { C } } | | \hat { \mathbf { z } } _ { i j } - \mathbf { c } | | _ { 2 } , zij=N(z^ij,C)=c∈Cmin∣∣z^ij−c∣∣2,
其中 ∣∣⋅∣∣2| | \cdot | | _ { 2 }∣∣⋅∣∣2 表示 L2 范数。然后我们整合量化后的特征 {zij}\{ \mathbf { z } _ { i j } \}{zij} 以获得最终的场景表示 z∈RH×W×C,\mathbf { z } \in \mathbb { R } ^ { H \times W \times C } ,z∈RH×W×C, 。
要从学习到的场景表示 ∼y\sim \mathbf { y }∼y z重建,我们使用由二维反卷积层组成的解码器,逐步对 z˙\mathbf { \dot { z } }z˙ 进行上采样,恢复到其原始的鸟瞰视角分辨率 H×W×C′′H \times W \times C ^ { \prime \prime }H×W×C′′ 。然后我们在通道维上进行拆分以重建高度维度 H×W×D×DC′′H \times W \times D \times { _ { D } ^ { C ^ { \prime \prime } } }H×W×D×DC′′ ,并在每个空间特征上应用Softmax 层,将其分类为占据语义或未占据 H×W×D∘H \times W \times D _ { \circ }H×W×D∘
场景分词器将三维占据映射到更为紧凑的离散空间,以便编码更高层次的概念。这个优化后的紧凑空间有助于为后续的世界模型建模场景演化。
3.3. 时空生成式变换器
自动驾驶的核心在于预测周围环境如何演变,并据此规划自车的运动。尽管传统方法通常将这两项任务分开执行 [17, 18],我们提出学习一个世界模型 www 以联合建模场景演化和自车轨迹的分布。
如公式(3)所定义,世界模型 www 以过去的场景和自车位置作为输入,并预测在驾驶一段时间间隔后的结果。基于表达能力、效率和通用性,我们采用三维占据y\mathbf { y }y 作为场景表示,并使用自监督的分词器来获得高级场景令牌 T={zi}c{ \bf T } = \{ { \bf z } _ { i } \} _ { \sf c }T={zi}c 。为整合自车运动,我们进一步将 T\mathbf { T }T 与一个自我令牌聚合 z0∈RC\mathbf { z } _ { 0 } \in \mathbb { R } ^ { C }z0∈RC 以编码自车的空间位置。
所提出的 OccWorld www 随后在世界令牌T上运行,其可表述为:
w(TT,⋅⋅⋅,TT−t)=TT+1, w ( \mathbf { T } ^ { T } , \cdot \cdot \cdot , \mathbf { T } ^ { T - t } ) = \mathbf { T } ^ { T + 1 } , w(TT,⋅⋅⋅,TT−t)=TT+1,
其中 TTT 是当前时间戳, ttt 是可用的历史帧数。
受到 GPT 出色的序列预测性能的启发 [2], 我们采用了类似 GPT 的自回归变换器架构来实现(5)。然而,将 GPT 从自然语言处理迁移到自动驾驶场景并非易事。GPT 每次只预测单个令牌,而世界模型 www 在自动驾驶中需要预测一组令牌T作为
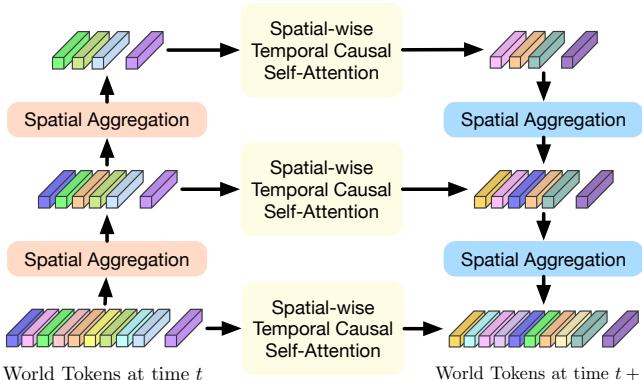
Figure 4. Illustration of the proposed spatial-temporal generative transformer. As each scene is composed of numerous world tokens, we adopt spatial mixing modules to model their intrinsic dependencies and obtain multi-scale world tokens to capture multi-level information. We then perform spatial-wise temporal causal self-attention at each level to forecast the next scene. We employ a U-net structure to aggregate the multi-scale predictions. the next future. Due to the vast number of world tokens, directly leveraging the GPT architecture to predict each token ∈TT+1\in \mathbf { T } ^ { T + 1 }∈TT+1 is both inefficient and ineffective.
Both the spatial relations of world tokens within each time stamp and the temporal relations of tokens across different time stamps should be considered to comprehensively model the world evolution. Therefore, we propose a spatial-temporal generative transformer architecture to effectively process past world tokens and make predictions of the next future, as shown in Figure 4.
We apply spatial aggregation (e.g., self-attention [8]) to world tokens T\mathbf { T }T to enable interactions between scene tokens as well as ego tokens. We then merge the scene tokens in each 2×22 \times 22×2 window with a stride of 2 and thus down-sample the scene tokens by a factor of 4. We repeat this procedure for KKK times to obtain world tokens of hierarchical scales {T0,⋯ ,TK}\{ \mathbf { T } _ { 0 } , \cdots , \mathbf { T } _ { K } \}{T0,⋯,TK} to describe the 3D scene at different levels.
We use several sub-world models w={w0,⋅⋅⋅,wK}w = \{ w _ { 0 } , \cdot \cdot \cdot , w _ { K } \}w={w0,⋅⋅⋅,wK} to predict the future at different spatial scales. For each sub-world model wiw _ { i }wi , we impose temporal attention on the tokens {zTj,i, · {zj,iT,⋅⋅⋅,zj,iT−t}\{ \mathbf { z } _ { j , i } ^ { T } , \cdot \cdot \cdot , \mathbf { z } _ { j , i } ^ { T - t } \}{zj,iT,⋅⋅⋅,zj,iT−t} at each position jjj to obtain the predicted corresponding token zj,iT+1\mathbf { z } _ { j , i } ^ { T + 1 }zj,iT+1 of the next frame:
z^j,iT+1=TA(zj,iT,⋅⋅⋅,zj,iT−t), \begin{array} { r } { \hat { \mathbf { z } } _ { j , i } ^ { T + 1 } = \mathrm { T A } ( \mathbf { z } _ { j , i } ^ { T } , \cdot \cdot \cdot , \mathbf { z } _ { j , i } ^ { T - t } ) , } \end{array} z^j,iT+1=TA(zj,iT,⋅⋅⋅,zj,iT−t),
where TA denotes masked temporal attention which blocks the effect of future tokens to previous tokens. zj,it∈Tit\mathbf { z } _ { j , i } ^ { t } \in \mathbf { T } _ { i } ^ { t }zj,it∈Tit represents the jjj -th world token of the iii -th scale at time stamp ttt . We finally employ a U-net structure to aggregate predicted tokens at different scales to ensure spatial consistency.
Our spatial-temporal generative transformer can model the world evolution in driving sequences considering the joint distributions of world tokens within each time and across time. The temporal attention predicts the evolution of a fixed position in the surrounding area, while the spatial aggregation makes each token aware of the global scene.
3.4. OccWorld: a 3D Occupancy World Model
We present the overall training framework of our OccWorld model for autonomous driving. Having obtained the forecasted world tokens, we reuse the scene decoder ddd to decode the predicted 3D occupancy y^T+1=d(z^T+1)\hat { \mathbf { y } } ^ { T + 1 } = d ( \hat { \mathbf { z } } ^ { T + 1 } )y^T+1=d(z^T+1) and additionally learn an ego decoder degod _ { e g o }dego to produce the ego displacement p^T+1=dˉego(z^0T+1)\hat { p } ^ { T + 1 } = \bar { d } _ { e g o } ( \hat { z } _ { 0 } ^ { T + 1 } )p^T+1=dˉego(z^0T+1) w.r.t the current frame.
We adopt a two-stage training strategy to effectively train our OccWorld. For the first stage, we train the scene tokenizer eee and decoder ddd using 3D occupancy loss [21]:
Je,d=Lsoft(d(e(y)),y)+λ1Llovasz(d(e(y)),y), J _ { e , d } = L _ { s o f t } ( d ( e ( \mathbf { y } ) ) , \mathbf { y } ) + \lambda _ { 1 } L _ { l o v a s z } ( d ( e ( \mathbf { y } ) ) , \mathbf { y } ) , Je,d=Lsoft(d(e(y)),y)+λ1Llovasz(d(e(y)),y),
where Lsoft\scriptstyle L _ { s o f t }Lsoft and LlovaszL _ { l o v a s z }Llovasz is the softmax and lovasz-softmax loss [1], respectively, and λ1\lambda _ { 1 }λ1 is a balance factor.
For the second stage, we adopt the learned scene tokenizer eee to obtain scene tokens z\mathbf { z }z for all the frames and constrain the discrepancy between predicted tokens z^\hat { \mathbf { z } }z^ and z\mathbf { z }z . We then apply the softmax loss to enforce the correct classification of z^\hat { \mathbf { z } }z^ to the correct codes in the codebook C\mathbf { C }C as z\mathbf { z }z . For the ego token, we simultaneously learn the ego decoder degod _ { e g o }dego and apply L2 loss on the predicted displacement p^=dego(z^0)\hat { p } = d _ { e g o } ( \hat { \mathbf { z } } _ { 0 } )p^=dego(z^0) and the ground-truth one p\mathbf { p }p . The overall objective for the second stage can be formulated as follows:
Jw,dego=∑t=1T(∑j=1M0Lsoft(z^j,0t,C(zj,0t)+λ2LL2(dego(z^0t),pt)), \begin{array} { r } { J _ { w , d _ { e g o } } = \displaystyle \sum _ { t = 1 } ^ { T } ( \sum _ { j = 1 } ^ { M _ { 0 } } L _ { s o f t } ( \hat { \mathbf { z } } _ { j , 0 } ^ { t } , \mathbf { C } ( \mathbf { z } _ { j , 0 } ^ { t } ) } \\ { + \lambda _ { 2 } L _ { L 2 } ( d _ { e g o } ( \hat { \mathbf { z } } _ { 0 } ^ { t } ) , \mathbf { p } ^ { t } ) ) , } \end{array} Jw,dego=t=1∑T(j=1∑M0Lsoft(z^j,0t,C(zj,0t)+λ2LL2(dego(z^0t),pt)),
where T\mathrm { T }T and M0M _ { 0 }M0 are the numbers of frames and spatial tokens of the original scale, respectively. C(⋅)\mathbf { C } ( \cdot )C(⋅) denotes the index of the corresponding code in the codebook C\mathbf { C }C . LL2L _ { L 2 }LL2 measures the L2 discrepancy between two trajectories.
For efficient training, we use tokens obtained by the scene tokenizer eee as inputs but apply masked temporal attention [2] to block the effect of future tokens. During inference, we progressively predict world tokens of the next frame using predicted tokens of past frames.
Our OccWorld can be applied to various types of 3D occupancy to adapt to different settings (e.g., end-to-end autonomous driving). The scene representation model rrr can be an oracle providing ground-truth occupancy, or a perception model taking images or LiDAR as inputs. Different from the conventional perception, predicting, and planning pipeline, OccWorld models the joint evolution of the surrounding scene and the ego movement to capture highorder interactions between the ego vehicle and the environment. Combined with machine-annotated [57], LiDARcollected [21], or self-supervised [20] 3D occupancy, OccWorld has the potential to scale up to large-scale training, paving the way for large driving models.
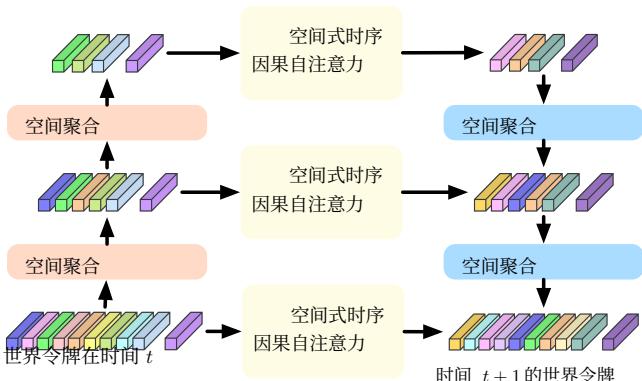
Figure 4. 所提出的时空生成变换器示意图。由于每个场景由大量世界令牌构成,我们采用空间混合模块来建模它们的内在依赖并获取多尺度世界代币以捕捉多层次信息。然后在每个层级上执行空间式时序因果自注意力以预测下一个场景。我们使用 U‑net 结构来聚合多尺度预测,以预测下一个未来。由于世界令牌数量巨大,直接利用 GPT 架构逐个预测每个令牌 TT+1\mathbf { T } ^ { T + 1 }TT+1 既低效又无效。
在每个时间戳内对世界令牌的空间关系以及跨不同时刻令牌的时间关系都应被考虑,以全面建模世界演化。因此,我们提出了一种时空生成式变换器架构,用于有效处理过去的世界令牌并对下一个未来进行预测,如图4所示。
我们对世界令牌应用空间聚合(例如,自注意力 [8])T以启用场景标记与自车标记之间的交互。然后我们以步幅为 2 在每个 2×22 \times 22×2 窗口中合并场景标记,从而将场景标记下采样 4 倍。我们对 KKK 次重复此过程,以获得层次尺度的世界令牌 {T0,⋯ ,TK}\{ \mathbf { T } _ { 0 } , \cdots , \mathbf { T } _ { K } \}{T0,⋯,TK} ,用于在不同层级描述三维场景。
我们使用多个子世界模型 w={w0,⋅⋅⋅,wK}w = \{ w _ { 0 } , \cdot \cdot \cdot , w _ { K } \}w={w0,⋅⋅⋅,wK} 在
不同空间尺度上预测未来。对于每个子世界模型 wiw _ { i }wi ,
我们在每个位置 注意力以得到下 jjj 对令牌 个帧的 {zj,iT,⋅⋅⋅,zj,iT−t}\{ \mathbf { z } _ { j , i } ^ { T } , \cdot \cdot \cdot , \mathbf { z } _ { j , i } ^ { T - t } \}{zj,iT,⋅⋅⋅,zj,iT−t} 加时间zjTˉ+1\mathbf { z } _ { j } ^ { \bar { T } + 1 }zjTˉ+1
z^j,iT+1=TA(zj,iT,⋅⋅⋅,zj,iT−t), \begin{array} { r } { \hat { \mathbf { z } } _ { j , i } ^ { T + 1 } = \mathrm { T A } ( \mathbf { z } _ { j , i } ^ { T } , \cdot \cdot \cdot , \mathbf { z } _ { j , i } ^ { T - t } ) , } \end{array} z^j,iT+1=TA(zj,iT,⋅⋅⋅,zj,iT−t),
where TA denotes masked temporal attention which blocksthe effect of future tokens toprevious tokens. zjti∈Tit\mathbf { z } _ { j } ^ { t } { } _ { i } \in \mathbf { T } _ { i } ^ { t }zjti∈Tit ,代表在时间戳 ttt 下第 iii 个尺度的第 jjj 个世界令牌。我们最终采用 U‑net 结构来聚合不同尺度上预测的令牌,以确保空间一致性。
我们的时空生成式变换器可以在驾驶序列中建模世界演化,考虑每个时间点内以及跨时间的世界令牌的联合分布。时间注意力预测周边区域固定位置的演化,而空间聚合使每个令牌能感知全局场景。
3.4. OccWorld:一个三维占据世界模型
我们展示了用于自动驾驶的 OccWorld 模型的整体训练框架。在得到预测的世界令牌后,我们重用场景解码器 ddd 来解码预测的三维占据 y^T+1=d(z^T+1)\hat { \mathbf { y } } ^ { T + 1 } = d ( \hat { \mathbf { z } } ^ { T + 1 } )y^T+1=d(z^T+1) ,并额外学习一个自我解码器 degod _ { e g o }dego ,以生成相对于当前帧的自车位移 p^T+1=dego(z^0T+1)\hat { p } ^ { T + 1 } = d _ { e g o } ( \hat { z } _ { 0 } ^ { T + 1 } )p^T+1=dego(z^0T+1) 。
我们采用两阶段训练策略来有效训练我们的
OccWorld。在第一阶段,我们使用三维占用损失 [21]训练场景令牌器 eee 和解码器 ddd :
Je,d=Lsoft(d(e(y)),y)+λ1Llovasz(d(e(y)),y), J _ { e , d } = L _ { s o f t } ( d ( e ( \mathbf { y } ) ) , \mathbf { y } ) + \lambda _ { 1 } L _ { l o v a s z } ( d ( e ( \mathbf { y } ) ) , \mathbf { y } ) , Je,d=Lsoft(d(e(y)),y)+λ1Llovasz(d(e(y)),y),
其中 Lsoft\scriptstyle L _ { s o f t }Lsoft 和 LlovaszL _ { l o v a s z }Llovasz 分别是 softmax 和Lovász‑softmax 损失 [1], ,且 λ1\lambda _ { 1 }λ1 是一个平衡因子。
在第二阶段,我们采用学习到的场景令牌器 eee 来获得所有帧的场景令牌 z\mathbf { z }z 并约束预测令牌 z^\scriptstyle \mathbf { \hat { z } }z^ 与 z\mathbf { z }z 之间的差异。然后我们对 z^\scriptstyle \mathbf { \hat { z } }z^ 应用 softmax 损失,以将其分类为码本 C\mathbf { C }C 中对应的正确代码 z∘\mathbf { z } _ { \circ }z∘ 。对于自车令牌,我们同时学习自我解码器 degod _ { e g o }dego 并对预测位移p^=dego(z^0)\hat { p } = d _ { e g o } ( \hat { \mathbf { z } } _ { 0 } )p^=dego(z^0) 与真实位移 p\mathbf { p }p 施加 L2 损失。第二阶段的总体目标可表述如下:
Jw,dego=∑t=1T(∑j=1M0Lsoft(z^j,0t,C(zj,0t)+λ2LL2(dego(z^0t),pt)), \begin{array} { r } { J _ { w , d _ { e g o } } = \displaystyle \sum _ { t = 1 } ^ { T } ( \sum _ { j = 1 } ^ { M _ { 0 } } L _ { s o f t } ( \hat { \mathbf { z } } _ { j , 0 } ^ { t } , \mathbf { C } ( \mathbf { z } _ { j , 0 } ^ { t } ) } \\ { + \lambda _ { 2 } L _ { L 2 } ( d _ { e g o } ( \hat { \mathbf { z } } _ { 0 } ^ { t } ) , \mathbf { p } ^ { t } ) ) , } \end{array} Jw,dego=t=1∑T(j=1∑M0Lsoft(z^j,0t,C(zj,0t)+λ2LL2(dego(z^0t),pt)),
其中 T\mathrm { T }T 和 M0M _ { 0 }M0 分别是原始尺度的帧数和空间令牌数。C(⋅)\mathbf { C } ( \cdot )C(⋅) 表示码本 C\mathbf { C }C 中相应代码的索引。 LL2L _ { L 2 }LL2 衡量两条轨迹之间的 L2 损失差异。
为提高训练效率,我们使用场景分词器 eee 得到的令牌作为输入,但应用掩蔽时序注意力 [2]来阻断未来令牌的影响。在推理时,我们使用已预测的过去帧令牌逐步预测下一帧的世界令牌。
我们的 OccWorld 可应用于各种类型的三维占据,以适应不同的设置(例如端到端自动驾驶)。场景表示模型 rrr 可以是提供真实占据的 Oracle,或是以图像或 LiDAR 作为输入的感知模型。与传统的感知、预测和规划流水线不同,OccWorld 建模了周围场景与自车运动的联合演化,以捕捉自车与环境之间的高阶交互。结合机器标注 [57], 的 LiDAR‑采集 [21], 或自监督 [20] 3的四维占据,OccWorld 有潜力扩展到大规模训练,为大型驾驶模型铺平道路。
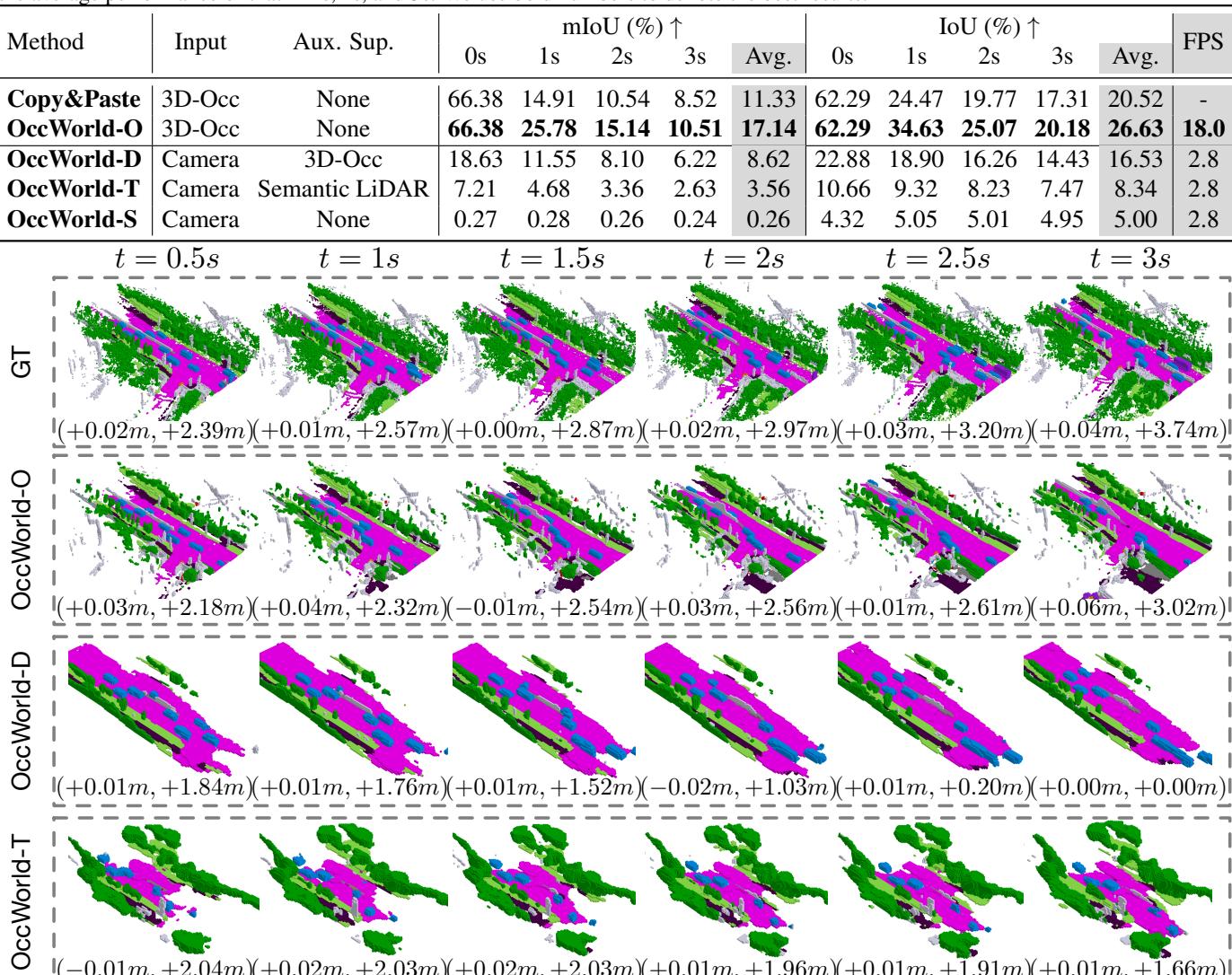
Figure 5. Visualizations of the forecasting and planning results of OccWorld-O, OccWorld-D, and OccWorld-T.
4. Experiments
4.1. Task Descriptions
In this paper, we explore a world-model-based framework for autonomous driving and propose OccWorld to model the joint evolutions of ego trajectory and scene evolutions. We conduct two tasks to evaluate our OccWorld: 4D occupancy forecasting on the Occ3D dataset [52] and motion planning on the nuScenes dataset [3]. We present the dataset and evaluation metric details in the supplementary material.
4D occupancy forecasting. 3D occupancy prediction aims to reconstruct the semantic occupancy for each voxel in the surrounding space, which cannot capture the temporal evolution of the 3D occupancy. In this paper, we explore the task of 4D occupancy forecasting, which aims to forecast the future 3D occupancy given a few historical occupancy inputs. We use mIoU and IoU as the evaluation metric.
Motion planning. The objective of motion planning is to produce safe future trajectories for the self-driving vehicle given ground-truth surrounding information or perception results. The planned trajectory is represented by a series of 2D waypoints in the BEV plane (ground plane). We use L2 error and collision rate as the evaluation metric.
4.2. Implementation Details
We followed existing works [18, 25] and used a 2-second historical context to forecast the subsequent 3 seconds. The scene tokenizer employs a down-sampling factor of 4, featuring a codebook comprising 512 nodes and a 128- dimensional feature representation. The spatial-temporal generative transformer comprises 3 scales, each incorporating 6 layers of spatial-wise temporal attention for scene tokens with 2 layers of spatial cross-attention and temporal cross-attention for ego planning tokens.
Table 1. 四维占据预测性能。Aux. Sup. 表示除自车轨迹外的辅助监督。Avg. 表示 1秒、2秒和3秒的平均性能。我们使用加粗数字表

(0.01m, +2.04m)(+0.02m, +2.03m)(+0.02m, +2.03m)(+0.01m, +1.96m)(+0.01m, +1.91m)(+0.01m, +1.66m)
图5。 OccWorld‑O、OccWorld‑D 和 OccWorld‑T 的预测与规划结果可视化。
4. 实验
4.1. 任务描述
在本文中,我们探索了一个基于世界模型的自动驾驶框架,并提出 OccWorld 来建模自车轨迹与场景演化的联合演变。我们通过两项任务来评估我们的 OccWorld:
Occ3D 数据集上的四维占据预测 [52] 以及 nuScenes 数据集上的运动规划 [3]。我们在补充材料中给出了数据集和评估指标的详细信息。
四维占据预测。 三维占据预测旨在重建周围空间中每个体素的语义占据,但无法捕捉三维占据的时间演化。本文探讨了四维占据预测任务,目标是在给定若干历史占据输入的情况下预测未来的三维占据。我们使用 mIoU 和 IoU 作为评估指标。
运动规划。 运动规划的目标是在给定真实周围信息或感知结果的情况下,为自动驾驶车辆生成安全的未来轨迹。所规划的轨迹由鸟瞰图平面(地面平面)上的一系列 2D 航点表示。我们使用 L2 误差和碰撞率作为评估指标。
4.2. 实现细节
我们遵循现有工作 [18, 25],使用 2 秒的历史上下文来预测随后 3 秒。场景分词器采用下采样因子为 4,码本包含 512 个节点,特征表示为 128 维。时空生成式 transformer 由 3 个尺度组成,每个尺度包含 6 层空间维时间注意力用于场景令牌,并为自车规划令牌配备 2 层空间交叉注意力和时间交叉注意力。
Table 2. Motion planning performance. Aux. Sup. denotes auxiliary supervision apart from the ego trajectory. We use bold and underlined numbers to denote the best and second-best results, respectively. † denotes using the metric computation adopted in VAD [25].
| Method | Input | Aux. Sup. | L2(m)↓ 2s | Collision Rate (%)↓ | FPS | ||||||
| 1s | 3s | Avg. | 1s | 2s | 3s | Avg. | |||||
| IL [43] | LiDAR | None | 0.44 | 1.15 | 2.47 | 1.35 | 0.08 | 0.27 | 1.95 | 0.77 | - |
| NMP [64] | LiDAR | Box & Motion | 0.53 | 1.25 | 2.67 | 1.48 | 0.04 | 0.12 | 0.87 | 0.34 | - |
| FF[16] | LiDAR | Freespace | 0.55 | 1.20 | 2.54 | 1.43 | 0.06 | 0.17 | 1.07 | 0.43 | - |
| EO [26] | LiDAR | Freespace | 0.67 | 1.36 | 2.78 | 1.60 | 0.04 | 0.09 | 0.88 | 0.33 | - |
| ST-P3 [17] | Camera | Map&Box & Depth | 1.33 | 2.11 | 2.90 | 2.11 | 0.23 | 0.62 | 1.27 | 0.71 | 1.6 |
| UniAD [18] | Camera | Map & Box & Motion & Tracklets & Occ | 0.48 | 0.96 | 1.65 | 1.03 | 0.05 | 0.17 | 0.71 | 0.31 | 1.8 |
| VAD-Tiny [25] | Camera | Map&Box &Motion | 0.60 | 1.23 | 2.06 | 1.30 | 0.31 | 0.53 | 1.33 | 0.72 | 16.8 |
| VAD-Base [25] OccNet [53] | Camera | Map & Box & Motion | 0.54 | 1.15 | 1.98 | 1.22 | 0.04 | 0.39 | 1.17 | 0.53 | 4.5 |
| Camera | 3D-Occ & Map& Box | 1.29 | 2.13 | 2.99 | 2.14 | 0.21 | 0.59 | 1.37 | 0.72 | 2.6 | |
| OccNet [53] | 3D-Occ | Map&Box | 1.29 | 2.31 | 2.98 | 2.25 | 0.20 | 0.56 | 1.30 | 0.69 | - |
| OccWorld-O | 3D-Occ | None | 0.43 | 1.08 | 1.99 | 1.17 | 0.07 | 0.38 | 1.35 | 0.60 | 18.0 |
| OccWorld-D | Camera | 3D-Occ | 0.52 | 1.27 | 2.41 | 1.40 | 0.12 | 0.40 | 2.08 | 0.87 | 2.8 |
| OccWorld-T OccWorld-S | Camera | Semantic LiDAR | 0.54 | 1.36 | 2.66 | 1.52 | 0.12 | 0.40 | 1.59 | 0.70 | 2.8 |
| Camera | None | 0.67 | 1.69 | 3.13 | 1.83 | 0.19 | 1.28 | 4.59 | 2.02 | 2.8 | |
| VAD-Tinyt [25] | Camera | Map & Box & Motion | 0.46 | 0.76 | 1.12 | 0.78 | 0.21 | 0.35 | 0.58 | 0.38 | 16.8 |
| VAD-Baset [25] | Camera | Map & Box & Motion | 0.41 | 0.70 | 1.05 | 0.72 | 0.07 | 0.17 | 0.41 | 0.22 | 4.5 |
| OccWorld-Ot | 3D-Occ | None | 0.32 | 0.61 | 0.98 | 0.64 | 0.06 | 0.21 | 0.47 | 0.24 | 18.0 |
| OccWorld-Dt | Camera | 3D-Occ | 0.39 | 0.73 | 1.18 | 0.77 | 0.11 | 0.19 | 0.67 | 0.32 | 2.8 |
| OccWorld-Tt | Camera | Semantic LiDAR | 0.40 | 0.77 | 1.28 | 0.82 | 0.12 | 0.22 | 0.56 | 0.30 | 2.8 |
| OccWorld-St | Camera | None | 0.49 | 0.95 | 1.55 | 0.99 | 0.19 | 0.56 | 1.54 | 0.76 | 2.8 |
During training, we applied mask operations to all temporal attention mechanisms to prevent the influence of future information on forecasting. For inference, we employ autoregressive prediction to foresee 3 seconds into the future based on a 2-second historical context. We adopted the AdamW optimizer [39] and a Cosine Annealing scheduler [38] for training. We set an initial learning rate of 1×1 \times1× 10−31 0 ^ { - 3 }10−3 and the weight decay at 0.01 and. We use a batch size of 1 per GPU on 8 NVIDIA GeForce RTX 4090 GPUs.
4.3. Results and Analysis
4D occupancy forecasting. We evaluated the 4D occupancy forecasting performance of our OccWorld in several settings: OccWorld-O (using ground-truth 3D occupancy), OccWorld-D (using predicted results of TPVFormer [21] trained with dense ground-truth 3D occupancy), OccWorldT (using predicted results of TPVFormer [21] trained with sparse semantic LiDAR1), and OccWorld-S (using predicted results of TPVFormer [20] trained in a selfsupervised manner2). Copy&Paste denotes copying the current ground-truth occupancy as future observations. The 0s results represent the reconstruction accuracy.
We compare the performance of the aforementioned settings in Table 1. We observe that OccWorld-O can generate non-trivial future 3D occupancy with much better results than Copy&Paste, showing that our model learns the underlying scene evolution. OccWorld-D, OccWorld-T, and OccWorld-S can be seen as end-to-end vision-based 4D occupancy forecasting methods as they take surrounding images as input. This task is very challenging since it requires both 3D structure reconstruction and forecasting. It is especially difficult for the self-supervised OccWorld-S, which exploits no 3D occupancy information even during training. Still, our OccWorld generates future 3D occupancy with non-trivial mIoU and IoU on the end-to-end setting.
Visualizations. We visualize the output results of the proposed OccWorld in Figure 5. We see that our models can successfully forecast the movements of cars and can complete unseen map elements in the inputs such as drivable areas. The planning trajectory is also more accurate with better 4D occupancy forecasting.
Motion planning. We compare the motion planning performance of the proposed OccWorld with state-of-the-art end-to-end autonomous driving methods, as shown in Table 2. We also evaluate our model under different settings as those in the 4D occupancy forecasting task.
We see that UniAD achieves the best overall performance, which exploits various types of auxiliary supervision to improve its planning quality. Despite the strong performance, the additional annotations in the 3D space are
表 2。 运动规划性能。Aux. Sup. 表示除自车轨迹外的辅助监督。我们使用加粗和带下划线的数字分别表示最佳和第二佳结果。 †表示使用 VAD 中采用的度量计算方法 [25]。
| 方法 | 输入 | 辅助监督 | L2(米)← | 碰撞率 (%) | FPS | ||||||
| 1s | 2s | 3s | Avg. | 1s | 2s | 3s | Avg. | ||||
| IL [43] | 激光雷达 | None | 0.44 1.15 | 2.47 | 1.35 | 0.08 0.27 | 1.95 0.77 | - | |||
| NMP [64] | 激光雷达 | 盒子&运动 | 0.53 1.25 2.67 | 1.48 | 0.040.12 0.87 | 0.34 | - | ||||
| FF[16] | 激光雷达 | 自由空间 | 0.55 1.20 2.54 | 1.43 | 0.060.171.07 | 0.43 | - | ||||
| EO[26] | 激光雷达 | 自由空间 | 0.67 1.36 2.78 | 1.60 | 0.04 0.090.88 | 0.33 | - | ||||
| ST-P3 [17] | 相机 | 地图&盒子&深度 | 1.33 2.11 2.90 | 2.11 | 0.23 0.62 1.27 | 0.71 | 1.6 | ||||
| UniAD [18] | 相机 | 地图与盒子与运动与轨迹片段与遮挡 | 0.480.96 1.65 | 1.03 | 0.05 0.17 0.71 | 0.31 | 1.8 | ||||
| VAD-Tiny [25] | 相机 | 地图与盒子与运动 | 0.60 1.23 2.06 | 1.30 | 0.31 0.53 1.33 | 0.72 | 16.8 | ||||
| VAD-Base [25] | 相机 | 地图与盒子与运动 | 0.54 1.15 1.98 | 1.22 | 0.040.39 1.17 | 0.53 | 4.5 | ||||
| OccNet [53] | 相机 | 3D-Occ&地图&盒子 | 1.29 2.13 2.99 | 2.14 | 0.21 0.59 1.37 | 0.72 | 2.6 | ||||
| OccNet [53] | 3D-Occ | 地图&盒子 | 1.29 2.31 2.98 | 2.25 | 0.20 0.56 1.30 | 0.69 | - | ||||
| OccWorld-0 | 3D-Occ | None | 0.431.08 1.99 | 1.17 | 0.07 0.38 1.35 | 0.60 | 18.0 | ||||
| OccWorld-D | 相机 | 3D-Occ | 0.52 1.27 2.41 | 1.40 | 0.12 0.40 2.08 | 0.87 | 2.8 | ||||
| OccWorld-T | 相机 | 语义激光雷达 | 0.54 1.36 2.66 | 1.52 | 0.12 0.40 1.59 | 0.70 | 2.8 | ||||
| OccWorld-S | 相机 | None | 0.67 1.69 3.13 | 1.83 | 0.19 1.28 4.59 | 2.02 | 2.8 | ||||
| VAD-Tinyt [25] | 相机 | 地图与盒子与运动 | 0.46 0.76 1.12 | 0.78 | 0.21 0.35 0.58 | 0.38 | 16.8 | ||||
| VAD-Base† [25] | 相机 | 地图与盒子与运动 | 0.41 0.70 1.05 0 | 0.070.17 0.41 0. | 4.5 | ||||||
| OccWorld-Ot | 3D-0cc | None | 0.32 0.61 0.98 0 | 0.060.21 0.47 | 0.24 | 18.0 | |||||
| OccWorld-Dt | 相机 | 3D-0cc | 0.39 0.73 1.18 | 0.77 | 0.11 0.19 0.67 | 0.32 | 2.8 | ||||
| OccWorld-Tt | 相机 | 语义激光雷达 | 0.40 0.77 1.28 | 0.82 | 0.12 0.22 0.56 | 0.30 | 2.8 | ||||
| OccWorld-St | 相机 | None | 0.49 0.95 1.55 | 0.99 | 0.19 0.56 1.54 | 0.76 | 2.8 | ||||
在训练过程中,我们对所有时间注意力机制应用了掩码操作,以防止未来信息影响预测。推理时,我们采用自回归预测,基于 2 秒的历史上下文预测未来3 秒。训练中我们采用 AdamW 优化器 [39]和余弦退火调度器 [38] 。我们将初始学习率设为 1×10−31 \times 1 0 ^ { - 3 }1×10−3 ,权重衰减设为 0.010 . 0 10.01 。我们在 8 块 NVIDIA GeForceRTX 4090 GPU 上每块 GPU 使用批量大小为 1∘1 _ { \circ }1∘
4.3. 结果与分析
4D occupancy forecasting. 我们在多种设置下评估了OccWorld 的四维占据预测性能:OccWorld‑O(使用真实的三维占用),OccWorld‑D(使用由TPVFormer [21]在具有密集真实 3D 占据的条件下训练后预测的结果),OccWorld‑T(使用由 TPVFormer[21] 在稀疏语义激光雷达上训练后预测的结果1),以及 OccWorld‑S(使用由 TPVFormer [20] 以自监督方式训练后预测的结果2)。Copy&Paste 表示将当前的真实占据复制作为未来观测。0s 的结果代表重建精度。
我们在表1中比较了上述设置的性能。我们观察到OccWorld‑O能够生成
非平凡的未来三维占据,其结果远优于Copy&Paste,表明我们的模型学习到了潜在的场景演化。OccWorld‑D、OccWorld‑T和OccWorld‑S可以视为端到端基于视觉的4D占据预测方法,因为它们以周围图像作为输入。该任务极具挑战性,因为它既需要三维结构重建又需要预测。对于自监督的OccWorld‑S尤其困难,它在训练期间甚至不利用任何三维占据信息。尽管如此,在端到端设置下,我们的OccWorld仍然能够生成具有非平凡mIoU和IoU的未来三维占据。
可视化。 我们在图5中可视化了所提出的OccWorld 的输出结果。可以看到我们的模型能够成功预测汽车的运动,并能补全输入中未见的地图元素,例如可行驶区域。基于更好的四维占据预测,规划轨迹也更为准确。
运动规划。 我们将所提出的 OccWorld 在运动规划方面的表现与最先进的端到端自动驾驶方法进行了比较,如表2所示。我们还在与四维占据预测任务中相同的不同设置下评估了我们的模型。
我们看到 UniAD 达到最佳的整体表现,它利用多种类型的辅助监督来提升其规划质量。尽管性能强劲,但在三维空间中的额外标注
Table 3. Effect of different hyperparameters for the scene tokenizer. We use bold numbers to denote the best results.
| Setting | Reconstruction | Forecasting mIoU (%) ↑ | Planning L2 (m)↓ | FPS | |||||||
| mIoU个 | IoU↑ | 1s | 2s | 3s | Avg. | 1s | 2s | 3s | Avg. | ||
| (502,128,512) | 66.38 | 62.29 | 25.78 | 15.14 | 10.51 | 17.14 | 0.43 | 1.08 | 1.99 | 1.17 | 18.0 |
| (502,128,256) | 63.40 | 60.33 | 24.25 | 14.34 | 10.13 | 16.24 | 0.42 | 1.08 | 1.95 | 1.15 | 17.8 |
| (50²,128,1024) | 60.50 | 59.07 | 23.55 | 14.66 | 10.68 | 16.30 | 0.47 | 1.18 | 2.19 | 1.28 | 17.8 |
| (252,256,512) | 36.28 | 44.02 | 12.10 | 8.13 | 6.20 | 8.81 | 3.27 | 6.54 | 9.78 | 6.53 | 28.1 |
| (100²,128,512) | 78.12 | 71.63 | 18.71 | 10.75 | 7.68 | 12.38 | 0.50 | 1.25 | 2.33 | 1.36 | 6.7 |
| (50²,64,512) | 64.98 | 61.50 | 21.83 | 12.90 | 9.28 | 14.67 | 0.49 | 1.24 | 2.26 | 1.33 | 20.1 |
Table 4. Ablation study of the spatial-temporal generative transformer. We report average results over the 1s, 2s, and 3s.
| Method | Forecast mIoU↑ IoU↑ | Planning L2↓ Col. | FPS | |||
| OccWorld-O | 17.14 | 26.63 | 1.17 0.60 | 18.0 | ||
| w/o spatial attn | 10.07 | 21.44 | 1.42 | 1.21 | 28.6 26.5 | |
| w/o temporal attn | 8.98 | 20.10 | 2.06 | 2.56 | ||
| w/o ego w/o ego temporal | 15.13 12.07 | 24.66 23.09 | 1 5.89 | 18.8 1 6.23 18.5 | ||
very difficult to obtain, making it difficult to scale to largescale driving data. As an alternative, OccWorld demonstrates competitive performance by employing 3D occupancy as the scene representation which can be efficiently obtained by accumulating LiDAR scans [57].
We observe that using ground-truth 3D occupancy as inputs, our OccWorld-O outperforms the previous perceptionprediction-planning-based method OccNet [53] by a large margin without using maps and bounding boxes as supervision, demonstrating the superiority of the world-model paradigm for autonomous driving. Our end-to-end models OccWorld-D and OccWorld-T also demonstrate competitive performance using only 3D occupancy as supervision and OccWorld-S delivers non-trivial results with no supervision other than the future trajectory, showing the potential for interpretable end-to-end autonomous driving.
Though our model demonstrates very competitive L2 error, it slightly falls behind on the collision rate. This is because it is more difficult to learn safe trajectories without the guidance of freespace or bounding box. Still, OccWorld-O demonstrates comparable collision rates with OccNet which exploits map and box supervision, showing that OccWorld can learn the concept of freespace with 3D occupancy.
We also observe that OccWorld shows excellent shortterm planning performance (1s), but worsens quickly when planning longer futures. For example, OccWorld-O achieves the best L2 error at 1s among all the methods but reaches 1.99 at 3s compared to 1.65 of UniAD. This might result from the diverse future generations of world models, which might deviate from the ground-truth trajectory.
Analysis of the scene tokenizer. We analyze the effect of different hyperparameters for the scene tokenizer in Table 3. The setting denotes latent spatial resolution, latent channel dimension, and the codebook size. We see that using a larger codebook than 512 leads to overfitting and using a smaller codebook, spatial resolution, or channel dimension might not be enough to capture the scene distribution. The reconstruction accuracy greatly improves with a larger spatial resolution, yet leads to poor forecasting and planning performance. This is because the tokens cannot learn high-level concepts and are difficult to forecast the future.
Analysis of the spatial-temporal generative transformer. We conducted an ablation study on both 4D occupancy forecasting and motion planning to analyze the design of the proposed spatial-temporal generative transformer, as shown in Table 4. w/o spatial attn denotes discarding spatial aggregation and directly applying temporal attention to the input tokens. w/o temporal attn represents that we replace the temporal attention with a simple convolution to output the next scene using the current world tokens. w/o ego represents that we discard the ego token. w/o ego temporal represents that we replace the temporal attention of the ego token with a simple MLP. We observe that using spatial aggregation to model spatial dependencies and using temporal attention to integrate history information is vital to the performance of both 4D occupancy forecasting and motion planning tasks. Also, only performing the 4D occupancy forecasting task without predicting motion reduces the performance. This verifies the effectiveness of joint modeling of scene evolutions and ego trajectories. Finally, discarding the ego temporal attention leads to poor planning and surprisingly worse 3D forecast occupancy performance. We think this is because integrating a wrongly predicted ego trajectory will mislead the forecasting.
5. Conclusion
In this paper, we have presented a 3D occupancy world model (OccWorld) to model the joint evolutions of ego movements and surrounding scenes. We have employed a 3D occupancy scene tokenizer to extract high-level concepts and used a spatial-temporal generative transformer for future prediction in an auto-regressive manner. Both quantitive and visualization results have shown that OccWorld can effectively predict future scene evolutions in the comprehensive 3D semantic occupancy space. We believe that OccWorld has paved the way for interpretable end-to-end autonomous driving without additional supervision signals.
表 3∘3 _ { \circ }3∘ 。 场景分词器不同超参数的影响。 我们使用加粗数字表示最佳结果。
| 设置 | 重建 mloU | 预测 mIoU(%)↑ | 规划L2 (米) | √ | FPS | ||||||
| ↑ | IoU↑ | 1s | 2s | 3s | Avg. | 1s | 2s | 3s | Avg. | ||
| (502,128,512) | 66.38 | 62.29 | 25.78 | 15.14 | 10.51 | 17.14 | 0.43 | 1.08 | 1.99 | 1.17 | 18.0 |
| (50²,128,256) | 63.40 | 60.33 | 24.25 | 14.34 | 10.13 | 16.24 | 0.42 | 1.08 | 1.95 | 1.15 | 17.8 |
| (50²,128,1024) | 60.50 | 59.07 | 23.55 | 14.66 | 10.68 | 16.30 | 0.47 | 1.18 | 2.19 | 1.28 | 17.8 |
| (252,256,512) | 36.28 | 44.02 | 12.10 | 8.13 | 6.20 | 8.81 | 3.27 | 6.54 | 9.78 | 6.53 | 28.1 |
| (100²,128,512) | 78.12 | 71.63 | 18.71 | 10.75 | 7.68 | 12.38 | 0.50 | 1.25 | 2.33 | 1.36 | 6.7 |
| (502,64,512) | 64.98 | 61.50 | 21.83 | 12.90 | 9.28 | 14.67 | 0.49 | 1.24 | 2.26 | 1.33 | 20.1 |
表4。 消融研究:时空生成式变换器。 我们报告了对1秒、2秒和3秒的平均结果。
| 方法 | 预测 mIoU↑ | IoU↑ | 规划 L2↓ 颜色← | FPS |
| OccWorld-O | 17.14 | 26.63 | 1.17 0.60 | 18.0 |
| 无空间注意力 | 10.07 | 21.44 | 1.42 1.21 | 28.6 |
| 无时间注意力 | 8.98 | 20.10 | 2.06 2.56 | 26.5 |
| 无自车 | 15.13 | 24.66 | 1 1 | 18.8 |
| 无自车时间维度 | 12.07 | 23.09 | 5.89 6.23 | 18.5 |
非常难以获取,使其难以扩展到大规模驾驶数据。作为替代,OccWorld 通过采用可高效由累积激光雷达扫描获得的三维占据作为场景表示,展示了具有竞争力的性能 [57]。
我们观察到,使用真实的三维占据作为输入时,OccWorld‑O 在没有使用地图和边界框作为监督的情况下,比之前基于感知‑预测‑规划的方法 OccNet [53]提升显著,这证明了世界模型范式在自动驾驶中的优越性。我们的端到端模型 OccWorld‑D 和 OccWorld‑T 同样展示了使用仅三维占据作为监督时的竞争性能,而OccWorld‑S 在除了未来轨迹以外没有任何监督的情况下也给出了非平凡的结果,展示了可解释端到端自动驾驶的潜力。
尽管我们的模型在 L2 损失上表现非常具有竞争力,但在碰撞率上略有不足。这是因为在没有自由空间或边界框引导的情况下学习安全轨迹更困难。不过,OccWorld‑O 在碰撞率上与利用地图和边界框监督的OccNet 表现相当,这表明 OccWorld 能通过三维占据学习到自由空间的概念。
我们还观察到 OccWorld 在短期规划(1秒)上表现出色,但在规划更长远未来时表现迅速恶化。例如,OccWorld‑O 在所有方法中在 1秒 时取得了最好的 L2误差,但在 3秒 时达到 1.99,而 UniAD 为 1.65。这可能是由于世界模型生成的未来存在多样性,导致偏离真实轨迹。
场景分词器分析。我们分析了表3中场景分词器不同超参数的影响。设置表示潜在空间分辨率、潜在通道维度以及码本大小。我们发现,
比512更大的码本会导致过拟合,而使用更小的码本、空间分辨率或通道维度可能不足以捕捉场景分布。重建精度随着更大空间分辨率显著提高,但却导致预测和规划性能下降。这是因为令牌无法学习到高层次概念,难以对未来进行预测。
时空生成 Transformer 的分析。我们在四维占据预测和运动规划两方面进行了消融研究,以分析所提出的时空生成 Transformer 的设计,如表4所示。w/o spatial attn 表示舍弃空间聚合,直接对输入令牌应用时间注意力。w/o temporal attn 表示我们用简单卷积替换时间注意力,以便使用当前世界令牌输出下一个场景。w/o ego 表示舍弃自我令牌。w/oego temporal 表示我们用简单的 MLP 替换自我令牌的时间注意力。我们观察到,使用空间聚合来建模空间依赖关系以及使用时间注意力来整合历史信息,对于四维占据预测和运动规划任务的性能至关重要。此外,仅执行四维占据预测任务而不预测运动会降低性能,这验证了对场景演化和自车轨迹进行联合建模的有效性。最后,舍弃自车的时间注意力会导致规划性能下降,并且令人惊讶地使 3D 预测占据性能更差。我们认为这是因为整合错误预测的自车轨迹会误导预测。
5. 结论
在本文中,我们提出了一个三维占用世界模型(OccWorld),用于建模自车运动与周围场景的联合演化。我们采用了三维占用场景分词器来提取高层概念,并使用时空生成式变换器以自回归方式进行未来预测。定量与可视化结果均表明,OccWorld 能在全面的三维语义占用空间中有效预测未来场景演化。我们认为 OccWorld 为无需额外监督信号的可解释端到端自动驾驶铺平了道路。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献116条内容
已为社区贡献116条内容

所有评论(0)