人脸多特征实时检测实例
本文介绍了一个基于计算机视觉的人脸分析系统,通过深度学习模型实现实时人脸检测、性别识别和年龄预测。系统采用OpenCV的DNN模块加载预训练模型,包括人脸检测模型(TensorFlow格式)和性别/年龄分类模型(Caffe格式)。核心技术流程包括:1) 使用blobFromImage进行图像预处理;2) 执行模型推理获取检测结果;3) 对输出进行置信度过滤和坐标转换;4) 添加中文标签显示功能。系
·
文章目录
一、核心功能实现原理
采用多种计算机视觉技术,通过摄像头实时采集视频流,对画面中人脸进行多维度分析。系统核心技术包括深度学习模型推理、人脸关键点检测、几何特征计算和实时图像处理。
二、模型加载与初始化模块
2.1 模型文件配置
faceProto = "model/opencv_face_detector.pbtxt" # 人脸检测模型配置文件
faceModel = "model/opencv_face_detector_uint8.pb" # 人脸检测模型权重文件
ageProto = "model/deploy_age.prototxt" # 年龄识别模型配置文件
ageModel = "model/age_net.caffemodel" # 年龄识别模型权重文件
genderProto = "model/deploy_gender.prototxt" # 性别识别模型配置文件
genderModel = "model/gender_net.caffemodel" # 性别识别模型权重文件
参数说明:
- pbtxt文件:TensorFlow模型的文本配置文件,描述网络结构
- pb文件:TensorFlow模型的二进制权重文件
- prototxt文件:Caffe模型的网络结构定义文件
- caffemodel文件:Caffe模型的训练权重文件
2.2 模型加载方法
# 加载神经网络模型
ageNet = cv2.dnn.readNet(ageModel, ageProto) # 加载年龄识别模型
genderNet = cv2.dnn.readNet(genderModel, genderProto) # 加载性别识别模型
faceNet = cv2.dnn.readNet(faceModel, faceProto) # 加载人脸检测模型
方法解析:
cv2.dnn.readNet()是OpenCV的深度学习模块核心函数- 参数1:模型权重文件路径
- 参数2:模型配置文件路径
- 函数返回一个网络对象,可用于前向传播计算
2.3 数据预处理参数
ageList = ['0-2岁', '4-6岁', '8-12岁', '15-20岁', '25-32岁',
'38-43岁', '48-53岁', '60-100岁'] # 年龄分类标签
genderList = ['男性', '女性'] # 性别分类标签
mean = (78.4263377603, 87.7689143744, 114.895847746) # 图像均值减去的RGB值
参数作用:
ageList:8个年龄段的分类标签,对应模型输出层的8个神经元genderList:2个性别分类标签,对应模型输出层的2个神经元mean:训练模型时使用的图像均值,用于输入数据标准化
三、人脸检测模块
3.1 人脸检测函数
def getBoxes(net, frame):
"""
使用深度学习模型检测图像中的人脸位置
设计思路:
1. 将输入图像转换为模型需要的blob格式
2. 执行前向传播获得检测结果
3. 过滤低置信度的检测框
4. 将归一化坐标转换为像素坐标
5. 在图像上绘制检测框
参数详解:
net: cv2.dnn.readNet()加载的人脸检测模型对象
frame: 输入图像,格式为numpy数组(H, W, C)
返回值:
frame: 绘制了人脸检测框的图像
faceBoxes: 人脸边界框列表,每个元素为[x1, y1, x2, y2]
"""
frameHeight, frameWidth = frame.shape[:2]
# 关键步骤1:图像预处理
blob = cv2.dnn.blobFromImage(
frame, # 输入图像
1.0, # 缩放因子
(300, 300), # 模型输入尺寸
[104, 117, 123], # 减去的BGR均值
True, # 交换RB通道(OpenCV默认BGR,模型需要RGB)
False # 不裁剪图像中心
)
# 关键步骤2:模型推理
net.setInput(blob) # 设置模型输入
detections = net.forward() # 执行前向传播
faceBoxes = []
# 关键步骤3:结果解析
for i in range(detections.shape[2]): # 遍历所有检测结果
confidence = detections[0, 0, i, 2] # 获取置信度
if confidence > 0.7: # 置信度阈值过滤
# 关键步骤4:坐标转换(归一化→像素)
x1 = int(detections[0, 0, i, 3] * frameWidth)
y1 = int(detections[0, 0, i, 4] * frameHeight)
x2 = int(detections[0, 0, i, 5] * frameWidth)
y2 = int(detections[0, 0, i, 6] * frameHeight)
faceBoxes.append([x1, y1, x2, y2]) # 保存人脸框
# 关键步骤5:可视化
cv2.rectangle(
frame, # 目标图像
(x1, y1), # 矩形左上角
(x2, y2), # 矩形右下角
(0, 255, 0), # 颜色(绿色)
int(round(frameHeight / 150)), # 线宽(自适应)
6 # 线条类型
)
return frame, faceBoxes
核心参数详解:
cv2.dnn.blobFromImage()参数:
frame:输入图像1.0:像素值缩放因子,保持原始强度(300, 300):模型要求的输入尺寸[104, 117, 123]:训练时使用的BGR均值,用于数据标准化True:交换R和B通道,因为模型在RGB图像上训练False:不进行中心裁剪
检测结果数据结构:
detections.shape为(1, 1, N, 7),其中N为检测到的对象数- 每个检测包含7个值:[batch_id, class_id, confidence, x1, y1, x2, y2]
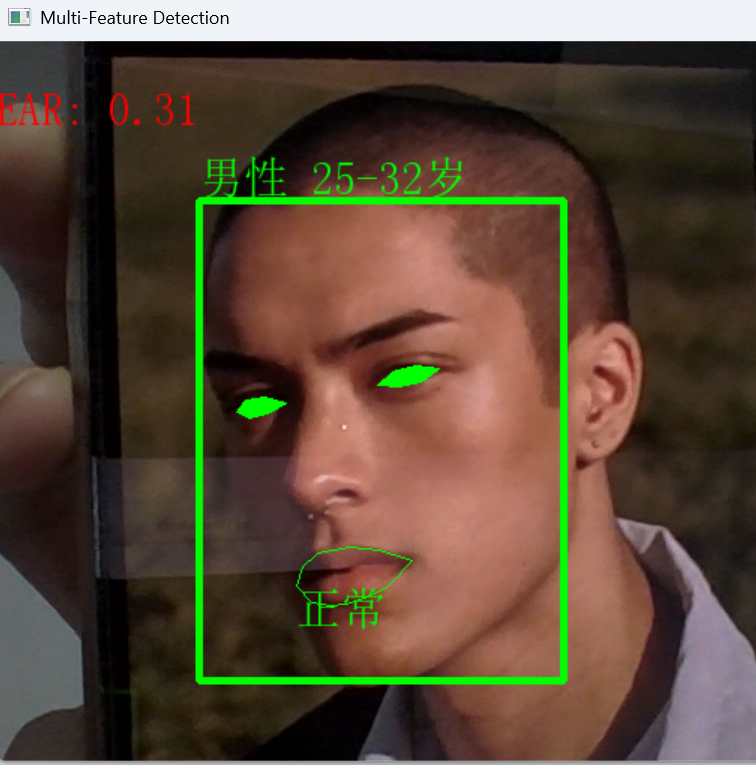
四、性别与年龄识别模块
4.1 中文文本绘制函数
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
"""
解决OpenCV无法直接显示中文的问题
设计思路:使用PIL库绘制中文,再转换回OpenCV格式
参数详解:
img: 输入图像,可以是numpy数组或PIL Image
text: 要绘制的中文文本
position: 文本起始位置(x, y)
textColor: 文本颜色,默认为绿色(0, 255, 0)
textSize: 字体大小,默认为30
返回值:
添加了中文文本的图像(numpy数组,BGR格式)
"""
if (isinstance(img, np.ndarray)):
# 关键步骤1:格式转换
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img) # 创建绘图对象
# 关键步骤2:字体加载
fontStyle = ImageFont.truetype(
"simsun.ttc", # 字体文件路径(宋体)
textSize, # 字体大小
encoding="utf-8" # 编码格式
)
# 关键步骤3:文本绘制
draw.text(position, text, textColor, font=fontStyle)
# 关键步骤4:格式转换回OpenCV
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
4.2 性别年龄识别流程
# 核心识别逻辑
if faceBoxes:
for faceBox in faceBoxes:
x1, y1, x2, y2 = faceBox
# 步骤1:提取人脸区域
face = frame[y1:y2, x1:x2] # 图像切片操作
# 步骤2:准备模型输入
blob = cv2.dnn.blobFromImage(
face, # 人脸区域图像
1.0, # 缩放因子
(227, 227), # 性别年龄模型输入尺寸
mean, # 标准化用的均值
swapRB=False, # 不交换通道(已在训练时处理)
crop=False # 不裁剪
)
# 步骤3:性别识别
genderNet.setInput(blob) # 设置模型输入
genderOuts = genderNet.forward() # 前向传播
gender = genderList[genderOuts[0].argmax()] # 取最大概率类别
# 步骤4:年龄识别
ageNet.setInput(blob) # 设置模型输入
ageOuts = ageNet.forward() # 前向传播
age = ageList[ageOuts[0].argmax()] # 取最大概率类别
# 步骤5:结果显示
result = "{} {}".format(gender, age) # 拼接结果
frame = cv2AddChineseText(frame, result, (x1, y1 - 30)) # 显示在面部上方

算法特点:
- 使用两个独立的CNN模型分别进行性别和年龄识别
- 模型输出为概率分布,取最大值作为预测结果
- 年龄识别为分类问题而非回归问题,使用年龄段而非具体年龄
五、面部表情识别模块
5.1 dlib人脸关键点检测器
# 关键点检测器初始化
detector = dlib.get_frontal_face_detector() # 人脸检测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat") # 关键点预测器
# 关键点检测流程
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转换为灰度图(dlib要求)
faces = detector(gray, 0) # 检测人脸,第二个参数表示上采样次数
for face in faces:
shape = predictor(frame, face) # 获取68个关键点
shape = np.array([[p.x, p.y] for p in shape.parts()]) # 转换为numpy数组
参数说明:
dlib.get_frontal_face_detector():返回一个基于HOG+SVM的人脸检测器shape_predictor_68_face_landmarks.dat:预训练的68点人脸关键点模型detector(gray, 0):0表示不进行图像上采样,适用于标准分辨率图像
5.2 嘴部特征计算函数
def MAR(shape):
"""
计算嘴部纵横比(Mouth Aspect Ratio)
设计思路:
1. 计算嘴部上下三对对应点的垂直距离
2. 计算平均值作为嘴部垂直张开度
3. 计算嘴部水平宽度
4. 比值反映嘴部张开程度
关键点索引说明:
48-54: 外嘴唇轮廓
60-64: 内嘴唇轮廓
50,58: 上嘴唇中点与下嘴唇中点
参数:
shape: 68x2的关键点坐标数组
返回值:
MAR值,越大表示嘴张得越开
"""
# 垂直距离计算(三对对应点)
A = euclidean_distances(shape[50].reshape(1, 2), shape[58].reshape(1, 2))
B = euclidean_distances(shape[51].reshape(1, 2), shape[57].reshape(1, 2))
C = euclidean_distances(shape[52].reshape(1, 2), shape[56].reshape(1, 2))
# 水平宽度计算(嘴角到嘴角)
D = euclidean_distances(shape[48].reshape(1, 2), shape[54].reshape(1, 2))
return ((A + B + C) / 3) / D
def MJR(shape):
"""
计算嘴部宽度与脸宽比例(Mouth Jaw Ratio)
设计思路:
1. 嘴部宽度反映微笑时嘴角拉伸程度
2. 脸宽作为参考基准
3. 比值越大表示微笑越明显
参数:
shape: 68x2的关键点坐标数组
返回值:
MJR值,越大表示微笑越明显
"""
# 嘴部宽度(嘴角到嘴角)
M = euclidean_distances(shape[48].reshape(1, 2), shape[54].reshape(1, 2))
# 脸部宽度(颧骨到颧骨)
J = euclidean_distances(shape[3].reshape(1, 2), shape[13].reshape(1, 2))
return M / J
关键点索引解释:
- 索引0-16:下巴轮廓
- 索引17-21:右眉毛
- 索引22-26:左眉毛
- 索引27-35:鼻子
- 索引36-41:右眼
- 索引42-47:左眼
- 索引48-60:外嘴唇
- 索引61-67:内嘴唇
5.3 表情分类逻辑
# 恢复被注释的显示代码
frame = cv2AddChineseText(frame, result, (50, 100)) # 固定位置显示
cv2.putText(frame, result, (50, 150),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2) # OpenCV英文显示
# 表情判断逻辑
mar = MAR(shape)
mjr = MJR(shape)
result = "正常"
if mar > 0.5: # 嘴部张开度阈值
result = "大笑"
elif mjr > 0.45: # 微笑拉伸阈值
result = "微笑"
# 嘴部轮廓可视化
mouthHull = cv2.convexHull(shape[48:61]) # 生成嘴部凸包
frame = cv2AddChineseText(frame, result,
(int(mouthHull[0, 0, 0]), int(mouthHull[0, 0, 1]))) # 嘴部位置显示
cv2.drawContours(frame, [mouthHull], -1, (0, 255, 0), 1) # 绘制轮廓

阈值选择依据:
MAR > 0.5:基于大量实验数据,当嘴部垂直高度达到水平宽度的一半时,通常为大笑MJR > 0.45:微笑时嘴角拉伸,嘴宽通常达到脸宽的45%以上
六、疲劳状态检测模块
6.1 眼部纵横比计算
def eye_aspect_ratio(eye):
"""
计算眼部纵横比(Eye Aspect Ratio)
设计思路:
1. 计算眼部上下两对点的垂直距离
2. 计算平均值作为眼部垂直闭合度
3. 计算眼部水平宽度作为基准
4. 比值越小表示眼睛闭合程度越大
关键点索引(单眼6个点):
0: 左眼角
1: 上眼睑中点
2: 右眼角
3: 下眼睑中点
4: 下眼睑右侧
5: 上眼睑右侧
参数:
eye: 6x2的眼部关键点坐标数组
返回值:
EAR值,正常睁眼时约为0.25-0.35,闭眼时接近0
"""
# 垂直距离计算
A = euclidean_distances(eye[1].reshape(1, 2), eye[5].reshape(1, 2))
B = euclidean_distances(eye[2].reshape(1, 2), eye[4].reshape(1, 2))
# 水平宽度计算
C = euclidean_distances(eye[0].reshape(1, 2), eye[3].reshape(1, 2))
ear = ((A + B) / 2.0) / C
return ear
def drawEye(eye):
"""
绘制眼部填充区域
参数:
eye: 眼部关键点坐标
实现方法:
1. 使用凸包算法连接眼部关键点
2. 填充凸包区域实现可视化
"""
eyehull = cv2.convexHull(eye) # 生成眼部凸包
cv2.drawContours(
frame, # 目标图像
[eyehull], # 轮廓列表
-1, # 绘制所有轮廓
(0, 255, 0), # 填充颜色(绿色)
-1 # 负值表示填充内部
)
6.2 疲劳检测逻辑
COUNTER = 0 # 连续闭眼帧数计数器
# 眼部关键点提取
rightEye = shape[36:42] # 右眼关键点(索引36-41)
leftEye = shape[42:48] # 左眼关键点(索引42-47)
# EAR计算
rightEAR = eye_aspect_ratio(rightEye)
leftEAR = eye_aspect_ratio(leftEye)
ear = (leftEAR + rightEAR) / 2.0 # 双眼平均值
# 疲劳状态判断
if ear < 0.3: # EAR阈值
COUNTER += 1 # 增加闭眼帧数
if COUNTER >= 50: # 连续闭眼帧数阈值
# 危险警告显示
frame = cv2AddChinesetext(
frame,
"!!!!危险!!!!",
(250, 250), # 屏幕中央位置
textColor=(255, 0, 0), # 红色强调
textSize=50 # 大字号
)
else:
COUNTER = 0 # 眼睛睁开,重置计数器
# 眼部可视化
drawEye(leftEye)
drawEye(rightEye)
# EAR值显示
info = "EAR: {:.2f}".format(ear[0][0]) # 格式化显示两位小数
frame = cv2AddChinesetext(frame, info, (0, 30)) # 左上角显示
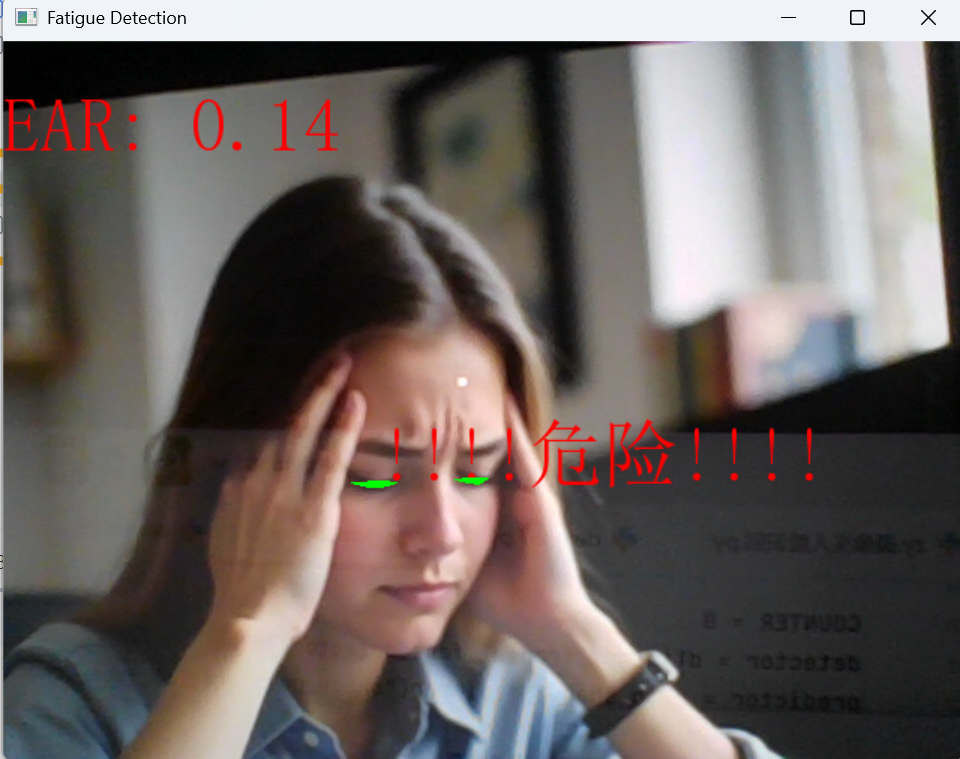
阈值设定原理:
ear < 0.3:正常睁眼时EAR约为0.25-0.35,低于0.3表示眼睛部分闭合COUNTER >= 50:以30fps计算,连续闭眼约1.67秒触发警告,避免眨眼误报
七、集成主循环
7.1 主循环结构
COUNTER = 0 # 全局疲劳计数器
while True:
# 步骤1:视频帧读取
ret, frame = cap.read()
frame = cv2.flip(frame, 1) # 水平镜像,使显示更自然
# 步骤2:性别年龄识别(基于OpenCV DNN)
frame_dnn, faceBoxes = getBoxes(faceNet, frame)
# 步骤3:多特征分析(基于dlib)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # dlib需要灰度图
faces = detector(gray, 0)
# 步骤4:遍历所有人脸进行特征分析
for face in faces:
# 关键点检测
shape = predictor(frame, face)
shape = np.array([[p.x, p.y] for p in shape.parts()])
# 表情识别
mar = MAR(shape)
mjr = MJR(shape)
# ...表情判断逻辑...
# 疲劳检测
rightEye = shape[36:42]
leftEye = shape[42:48]
# ...疲劳判断逻辑...
# 步骤5:显示结果
cv2.imshow("Multi-Feature Detection", frame)
# 步骤6:退出检测
if cv2.waitKey(1) == 27: # ESC键退出
break

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)