全网最强Elasticsearch快速入门
Mapping 定义了索引里字段的类型、分词规则,是搜索的核心,必须先定义 Mapping,再插入数据,不要让 ES 自动生成类型,会导致搜索不符合预期。核心字段类型创建索引并定义完整mapping(相当于建表)运行后返回acknowledged: true,说明创建成功,后续插入数据必须符合这个字段类型规范。
Elasticsearch(简称 ES)是一款开源的分布式全文搜索引擎 & 数据分析引擎,核心优势是海量数据的近实时检索、模糊匹配、聚合统计,常见用途:
- 电商商品搜索、站内全文检索
- 日志数据分析与监控(ELK 技术栈)
- 大数据指标统计、地理空间检索
- 智能推荐、舆情分析等
第一步:环境准备
利用docker拉取
Elasticsearch(es服务端)
Kibana(es的可视化工具)
IK 中文分词器(es插件)
第二步:基础概念
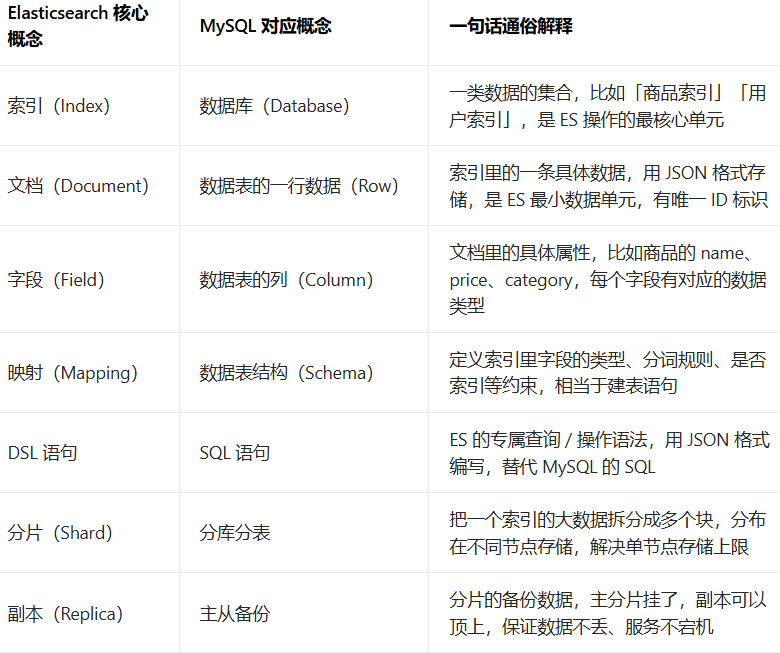
对于新手,重点是理解索引,文档,映射,DSL
第三步:Es基础操作
1.索引(相当于mysql里的库)操作:
创建索引:

查看索引:

删除索引:

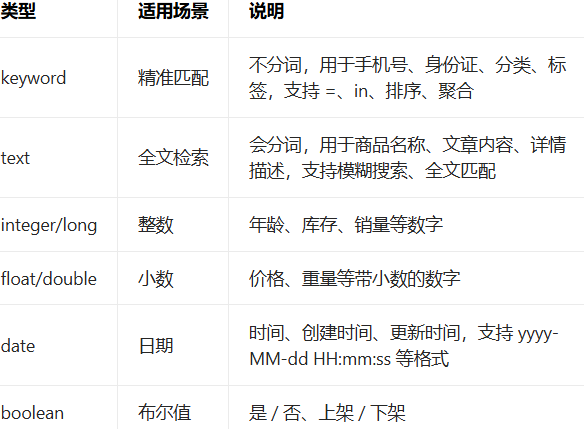
2.映射 Mapping 操作(相当于 MySQL 的建表,定义字段类型)
Mapping 定义了索引里字段的类型、分词规则,是搜索的核心,必须先定义 Mapping,再插入数据,不要让 ES 自动生成类型,会导致搜索不符合预期。
核心字段类型
创建索引并定义完整mapping(相当于建表)
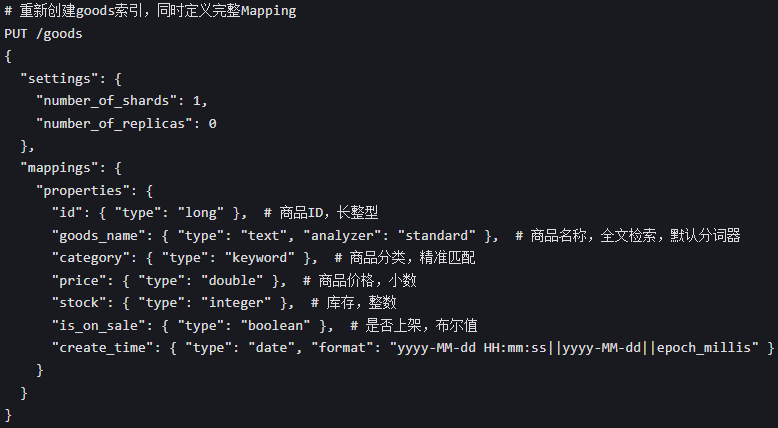
运行后返回acknowledged: true,说明创建成功,后续插入数据必须符合这个字段类型规范。
三、文档的基础操作(相当于 MySQL 的行数据增删改查)
文档相当于mysql里的行
新增文档(插入数据)
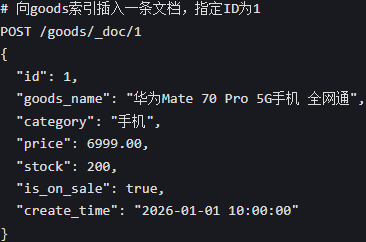
注:
doc是文档操作的标识,代表着一种操作的类型

批量插入文档(快速造测试数据)

查询文档
方式 1:根据文档 ID 精准查询
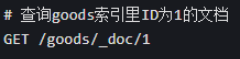
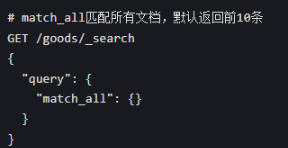
方式 2:查询索引里所有文档(相当于 MySQL 的 select * from goods)
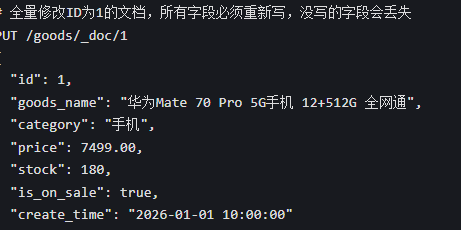
修改文档
方式 1:全量覆盖修改(和新增语法一致,ID 存在就覆盖,不存在就新增)
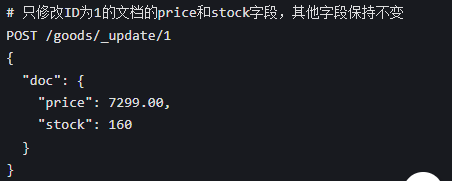
方式 2:局部修改
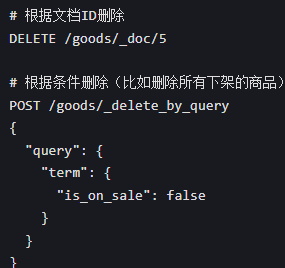
删除文档
四.核心搜索操作(ES 的核心能力)
query 是 Elasticsearch 搜索的核心关键字
所有搜索条件、匹配规则、过滤逻辑,全都写在 query 大括号 {} 里面。
1. 全文检索(match,最核心)
match 会对搜索关键词进行分词,然后和 text 类型的字段匹配,适合商品名称、文章内容的模糊搜索。

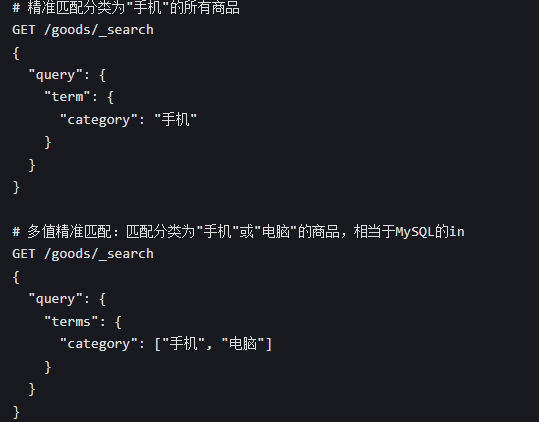
2. 精准匹配(term/terms,不分词)
term 不会对关键词分词,直接精准匹配,适合 keyword、数字、日期、布尔类型的字段,比如分类、状态、ID。
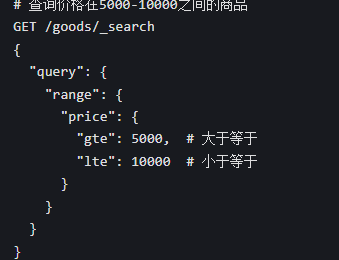
3. 范围查询(range)
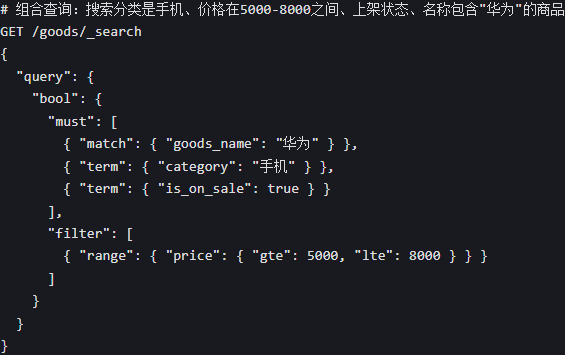
4. 组合查询(bool,多条件组合,最常用)
bool 查询可以把多个查询条件组合起来,相当于 MySQL 的 and/or/not,是实际开发中最常用的语法。bool 有 4 个核心参数:
- must:必须满足的条件,相当于 and,会计算相关性得分
- must_not:必须不满足的条件,相当于 not
- should:满足其中一个即可,相当于 or
- filter:过滤
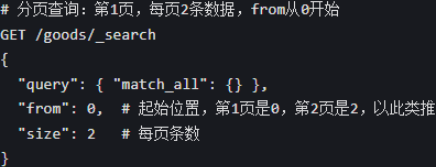
5. 分页、排序、高亮
分页
排序
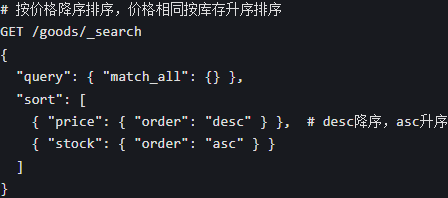
高亮

第四步:测试中文分词器
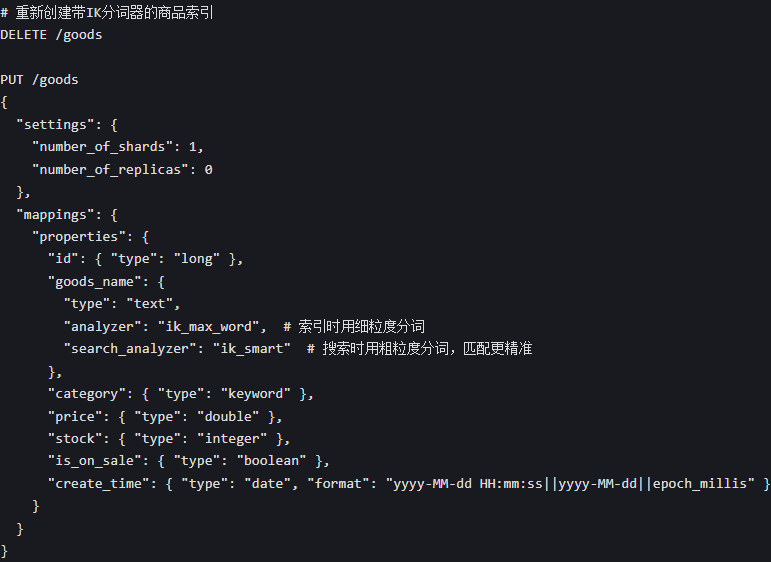
ES 默认的 standard 分词器对中文支持极差,会把中文拆成单个字,比如 "华为手机" 会拆成 "华"" 为 ""手"" 机 ",搜索效果完全不符合预期,中文搜索必须安装 IK 分词器。
1. 安装步骤
- 下载和 ES 版本完全一致的 IK 分词器 zip 包,不要解压
- 在 ES 的 plugins 目录下,新建一个名为
ik的文件夹 - 把下载的 zip 包解压到 ik 文件夹里
- 重启 ES 服务(关闭之前的命令行窗口,重新双击 elasticsearch.bat)
- 重启 Kibana 服务
2. 验证 IK 分词器是否安装成功

运行后能看到把 "华为"" 手机 " 分成完整的词,说明安装成功。
3. 把 IK 分词器配置到索引 Mapping 里

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)