STEP3-VL-10B开源镜像实操:CSDN平台一键启动+Supervisor服务管理详解
本文介绍了如何在星图GPU平台上自动化部署STEP3-VL-10B多模态视觉语言模型(阶跃星辰)。该平台提供了一键启动功能,极大简化了部署流程。部署后,用户可通过WebUI或API快速体验其核心应用场景,例如上传图片并让其进行详细描述、图表分析或OCR文字识别,实现高效的多模态AI交互。
STEP3-VL-10B开源镜像实操:CSDN平台一键启动+Supervisor服务管理详解
如果你正在寻找一个既强大又轻便的多模态AI模型,能看懂图片、理解图表、甚至帮你分析复杂的视觉问题,那么STEP3-VL-10B绝对值得你花10分钟了解一下。
这个由阶跃星辰开源的10B参数模型,虽然体积不大,但能力却相当惊人。它在多个专业测试中,表现甚至超过了那些参数量大它10-20倍的“巨无霸”模型。更棒的是,现在通过CSDN星图镜像,你可以像点外卖一样,一键就能把它部署起来,完全不用操心复杂的安装配置。
今天这篇文章,我就带你从零开始,手把手教你如何在CSDN平台上快速启动STEP3-VL-10B,并详细讲解如何用Supervisor这个工具来管理服务。无论你是AI开发者、研究人员,还是只是想体验一下多模态AI的魅力,这篇文章都能让你在15分钟内搞定一切。
1. 为什么选择STEP3-VL-10B?
在深入操作之前,我们先简单了解一下这个模型到底有什么特别之处。
1.1 轻量级但能力超强
STEP3-VL-10B只有100亿参数,这个规模在现在的AI模型里算是比较“苗条”的。但你别看它体积小,能力却一点都不弱。
我举个例子你就明白了:它在MMMU(一个测试模型多学科多模态理解能力的基准)上拿到了78.11分,在MathVista(数学视觉推理测试)上更是达到了83.97分。这两个成绩在10B参数级别的模型里都是最好的,甚至比一些参数量大它10-20倍的模型还要好。
1.2 能做什么?
这个模型的核心能力就是“多模态”——既能理解文字,也能看懂图片,还能把两者结合起来进行推理。具体来说,它可以:
- 图片理解:你上传一张照片,它能告诉你图片里有什么、在发生什么
- OCR文字识别:从图片里提取文字信息,比如识别文档、截图中的文字
- 图表分析:看懂各种图表、表格,并进行分析
- GUI界面理解:理解软件界面、网页布局
- 空间理解:分析图片中的空间关系、物体位置
1.3 硬件要求亲民
相比那些动辄需要好几张A100的“大模型”,STEP3-VL-10B对硬件的要求友好多了:
| 硬件组件 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA显卡,24GB显存(比如RTX 4090) | A100 40GB/80GB |
| 内存 | 32GB | 64GB或以上 |
| CUDA | 12.x版本 | 12.4或更新 |
这意味着很多个人开发者、小团队都能跑得起来,不需要投入巨大的硬件成本。
2. CSDN平台一键部署:最简单的启动方式
好了,理论部分就说到这里,现在进入实战环节。在CSDN星图平台上部署STEP3-VL-10B,可能是目前最简单的方法了。
2.1 找到并启动镜像
首先,你需要访问CSDN星图镜像广场。在搜索框里输入“STEP3-VL-10B”,就能找到对应的镜像。
点击“一键部署”按钮,系统会自动为你分配算力资源。这个过程通常只需要几分钟,比你自己从头搭建环境要快得多。
2.2 访问WebUI界面
部署完成后,你会发现一个很贴心的设计:服务已经自动启动了,你什么都不用做。
在算力服务器的右侧导航栏里,你会看到一个“快速访问”的链接,直接点击就能打开STEP3-VL-10B的Web界面。
点击后,浏览器会打开一个类似这样的地址(每台服务器的地址不同):
https://gpu-pod699d9da7a426640397bd2855-7860.web.gpu.csdn.net/
这时候,你就看到了STEP3-VL-10B的交互界面:
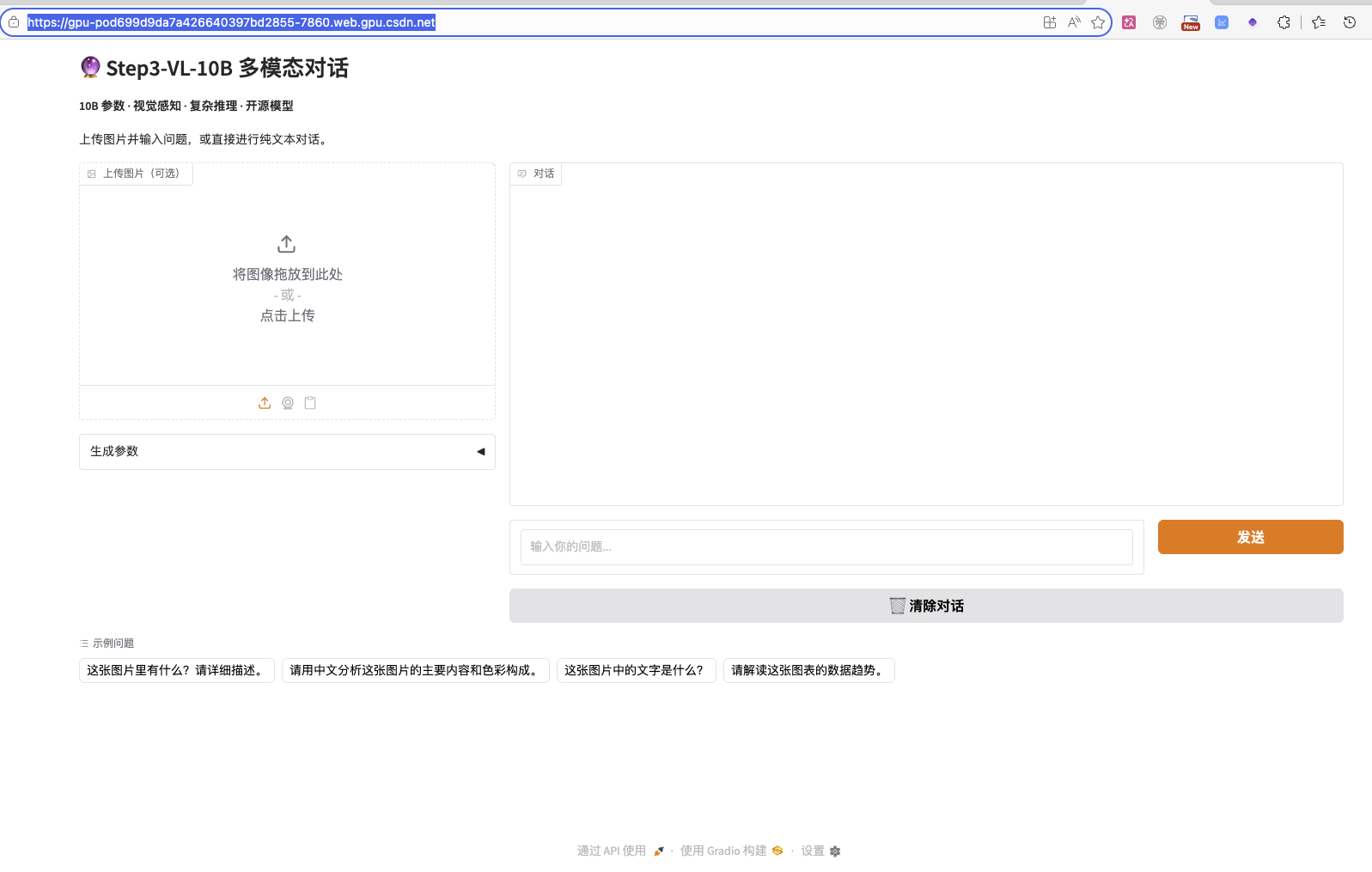
2.3 开始你的第一次多模态对话
界面非常直观,主要分为三个区域:
- 左侧对话历史:显示之前的对话记录
- 中间主区域:显示模型回复的内容
- 右下角输入区:你可以在这里输入文字,也可以上传图片
我们来试一个简单的例子:
- 点击输入框旁边的“上传”按钮,选择一张图片
- 在输入框里输入:“描述一下这张图片里有什么”
- 点击发送
几秒钟后,模型就会给出详细的图片描述。你可以试试各种类型的图片——风景照、图表、文档截图,看看它的识别能力如何。
3. Supervisor服务管理:掌控你的AI服务
你可能注意到了,我们并没有手动启动任何服务,但Web界面已经可以正常访问了。这背后就是Supervisor在起作用。
3.1 什么是Supervisor?
Supervisor是一个进程管理工具,你可以把它理解成一个“服务管家”。它的主要作用是:
- 自动启动:服务器重启后,自动启动你配置的服务
- 进程监控:实时监控服务运行状态
- 日志管理:集中管理服务的运行日志
- 故障恢复:服务意外崩溃时自动重启
在CSDN的STEP3-VL-10B镜像里,Supervisor已经预配置好了,开箱即用。
3.2 常用的Supervisor命令
虽然服务已经自动运行了,但有时候你可能需要手动管理。下面这些命令会很有用:
# 查看所有服务的状态
supervisorctl status
# 停止WebUI服务
supervisorctl stop webui
# 启动WebUI服务
supervisorctl start webui
# 重启WebUI服务
supervisorctl restart webui
# 停止所有服务
supervisorctl stop all
# 重新加载配置(修改配置后需要执行)
supervisorctl reload
3.3 修改服务配置
默认情况下,WebUI服务运行在7860端口。如果你需要修改端口(比如端口冲突了),可以这样做:
- 找到启动脚本文件:
/usr/local/bin/start-webui-service.sh
- 编辑这个文件,找到端口配置的地方:
source /Step3-VL-10B/venv/bin/activate
echo "Starting Step3-VL-10B webui service..."
exec python /root/Step3-VL-10B/webui.py \
--host 0.0.0.0 \
--port 7860 # 修改这个端口号
- 修改端口号后,重启服务:
supervisorctl restart webui
4. 手动启动与深度使用
虽然Supervisor已经帮我们自动管理了服务,但了解如何手动启动还是有必要的,特别是在调试或者需要临时运行的时候。
4.1 手动启动WebUI
如果你想要手动启动WebUI服务,可以按照以下步骤:
# 进入模型目录
cd ~/Step3-VL-10B
# 激活Python虚拟环境
source /Step3-VL-10B/venv/bin/activate
# 启动WebUI服务
python3 webui.py --host 0.0.0.0 --port 7860
执行完这些命令后,用浏览器访问你的服务器地址(格式:https://你的服务器地址-7860.web.gpu.csdn.net/),就能看到熟悉的界面了。

4.2 使用OpenAI兼容API
除了Web界面,STEP3-VL-10B还提供了API接口,这意味着你可以把它集成到自己的应用里。最棒的是,这个API和OpenAI的格式兼容,所以如果你之前用过ChatGPT的API,几乎可以无缝切换。
4.2.1 纯文本对话API
先来一个最简单的例子,纯文本对话:
curl -X POST https://gpu-pod699d9da7a426640397bd2855-7860.web.gpu.csdn.net/api/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Step3-VL-10B",
"messages": [{"role": "user", "content": "你好,请介绍一下你自己"}],
"max_tokens": 1024
}'
注意:你需要把上面的地址换成你自己服务器的实际地址。

4.2.2 多模态对话API(图片+文字)
这才是STEP3-VL-10B的强项——多模态理解。你可以同时发送图片和文字:
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Step3-VL-10B",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"
}
},
{
"type": "text",
"text": "描述这张图片,并告诉我蜜蜂在做什么"
}
]
}
],
"max_tokens": 1024
}'
这个例子中,我们同时发送了一张蜜蜂的图片和一个问题。模型会先“看”图片,然后结合你的问题给出回答。

4.3 API的常见使用场景
了解了基本的API调用后,你可能会想:这到底能用在什么地方?我举几个实际的例子:
场景一:智能客服系统 用户上传产品问题的截图,系统自动识别图片内容,结合用户描述给出解决方案。
场景二:教育辅助工具 学生上传数学题的图片,系统不仅识别题目文字,还能理解图表、公式,给出解题思路。
场景三:内容审核 自动识别用户上传的图片内容,判断是否符合平台规范,大大减轻人工审核压力。
场景四:数据分析 上传数据图表截图,让模型帮你分析趋势、提取关键信息。
5. 实际应用案例与技巧
光知道怎么用还不够,我们来看看在实际项目中,怎么让STEP3-VL-10B发挥最大价值。
5.1 图片描述的最佳实践
当你让模型描述图片时,不同的提问方式会得到不同质量的回答:
# 不太好的提问方式
"这是什么图片?"
# 更好的提问方式
"请详细描述这张图片的内容,包括主要物体、场景、颜色、动作等细节"
# 针对特定需求的提问
"从电商角度描述这张产品图片,突出产品特点和卖点"
5.2 处理复杂图表
STEP3-VL-10B在图表理解方面表现很出色。比如你上传一张销售数据图表,可以这样提问:
“分析这张销售数据图表,找出:
1. 哪个季度的销售额最高?
2. 整体趋势是上升还是下降?
3. 给出三条提升销售的建议”
5.3 结合上下文的多轮对话
模型支持多轮对话,这意味着你可以基于之前的回答继续深入:
第一轮:“描述这张建筑设计图” 第二轮:“根据你的描述,这个设计有哪些优点和缺点?” 第三轮:“如果要在图中增加一个停车场,放在什么位置最合适?”
5.4 性能优化建议
虽然STEP3-VL-10B相对轻量,但在实际使用中还是有一些优化空间的:
- 图片预处理:上传前适当压缩图片,减少传输和处理时间
- 批量处理:如果需要处理大量图片,考虑使用批量API(如果有的话)
- 缓存结果:对于相同的图片和问题,可以缓存模型回答
- 超时设置:在API调用时设置合理的超时时间,避免长时间等待
6. 常见问题与解决方法
在实际使用中,你可能会遇到一些问题。这里我整理了一些常见的情况和解决方法。
6.1 服务无法启动
问题:执行supervisorctl status发现服务不是RUNNING状态
可能原因和解决:
- 端口被占用:修改
start-webui-service.sh中的端口号 - 内存不足:检查服务器内存使用情况,确保有足够空闲内存
- 依赖问题:尝试重新安装依赖
cd ~/Step3-VL-10B source venv/bin/activate pip install -r requirements.txt
6.2 API调用返回错误
问题:调用API时返回4xx或5xx错误
检查步骤:
- 确认服务正在运行:
supervisorctl status - 确认端口正确:检查WebUI实际使用的端口
- 检查API地址:确保使用的是正确的完整URL
- 查看日志:
tail -f /var/log/supervisor/webui-stderr*.log
6.3 图片上传失败
问题:在WebUI中上传图片失败或无法识别
解决方法:
- 检查图片格式:支持常见格式如JPG、PNG、WEBP等
- 检查图片大小:过大的图片可能需要较长时间处理
- 尝试不同的浏览器:有些浏览器插件可能会干扰文件上传
6.4 响应速度慢
问题:模型响应时间较长
优化建议:
- 减少输入长度:过长的文本输入会影响速度
- 降低图片分辨率:在不影响识别的前提下适当压缩图片
- 使用更强大的GPU:如果条件允许,升级显卡
7. 进阶配置与定制
如果你需要更深入地定制STEP3-VL-10B,这里有一些进阶的配置选项。
7.1 修改模型参数
虽然WebUI界面提供了一些基础设置,但通过API你可以更精细地控制模型行为:
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Step3-VL-10B",
"messages": [{"role": "user", "content": "你的问题"}],
"max_tokens": 512, # 控制回复最大长度
"temperature": 0.7, # 控制随机性(0-2,越高越随机)
"top_p": 0.9, # 核采样参数
"frequency_penalty": 0.1, # 频率惩罚,减少重复
"presence_penalty": 0.1 # 存在惩罚,鼓励新话题
}'
7.2 使用系统提示词
你可以通过系统消息来设定模型的角色和行为:
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Step3-VL-10B",
"messages": [
{
"role": "system",
"content": "你是一个专业的医学影像分析助手,请用专业但易懂的语言回答用户关于医学影像的问题。"
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/xray.jpg"}
},
{"type": "text", "text": "分析这张X光片"}
]
}
],
"max_tokens": 1024
}'
7.3 监控与日志
为了更好地了解服务运行状态,你可以配置日志监控:
# 查看实时日志
tail -f /var/log/supervisor/webui-stdout*.log
# 查看错误日志
tail -f /var/log/supervisor/webui-stderr*.log
# 查看Supervisor自身日志
tail -f /var/log/supervisor/supervisord.log
8. 总结
通过这篇文章,你应该已经掌握了在CSDN平台上快速部署和使用STEP3-VL-10B的全部技能。我们来简单回顾一下重点:
一键部署的便利性:CSDN星图镜像让复杂的模型部署变得像点按钮一样简单,完全不需要担心环境配置、依赖安装这些繁琐的事情。
Supervisor的实用性:这个“服务管家”不仅让服务能够自动启动、自动恢复,还提供了完善的管理命令,让你能够轻松掌控服务的运行状态。
多模态能力的强大:STEP3-VL-10B虽然只有10B参数,但在图片理解、图表分析、OCR识别等方面的表现,完全不输给那些参数量大得多的模型。这对于很多实际应用场景来说,意味着可以在有限的硬件资源下获得出色的效果。
灵活的使用方式:无论是通过Web界面交互,还是通过API集成到自己的应用中,STEP3-VL-10B都提供了友好的接口。特别是OpenAI兼容的API设计,让已有ChatGPT集成经验的开发者能够快速上手。
实际应用价值:从智能客服到教育辅助,从内容审核到数据分析,这个模型的能力边界正在不断被开发者们拓展。而且随着开源社区的贡献,它的能力还会继续增强。
如果你之前因为大模型部署复杂、硬件要求高而犹豫,那么STEP3-VL-10B加上CSDN的一键部署方案,可能是你开始多模态AI探索的最佳起点。它平衡了能力、成本和易用性,让先进的AI技术真正变得触手可及。
现在,你可以去CSDN星图镜像广场找到STEP3-VL-10B镜像,亲自体验一下这个强大而轻便的多模态模型了。相信在实际使用中,你会发现更多有趣的应用可能。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献188条内容
已为社区贡献188条内容

所有评论(0)