小白也能懂的语音活动检测:FSMN VAD镜像保姆级教程
本文介绍了如何在星图GPU平台上自动化部署FSMN VAD阿里开源的语音活动检测模型 构建by科哥镜像,实现音频中有效语音段的毫秒级精准切分。用户无需编程基础,即可通过WebUI快速完成会议录音、客服电话等场景下的语音-静音分离,显著提升语音识别前处理效率与准确率。
小白也能懂的语音活动检测:FSMN VAD镜像保姆级教程
1. 什么是语音活动检测?一句话说清
你有没有遇到过这些情况:
- 会议录音里夹杂着长时间的沉默、翻纸声、空调噪音,想提取真正说话的部分却无从下手
- 电话客服录音中,一半时间是等待音、按键音、背景人声,真正有用的对话只占一小段
- 给一段30分钟的播客音频做字幕,结果识别引擎把所有环境音都当成了“语音”,生成一堆乱码
这时候,就需要一个“听觉过滤器”——语音活动检测(Voice Activity Detection,简称VAD)。
它不负责听懂你说什么,也不转成文字,它的任务只有一个:精准标出“哪里在说话,哪里是静音或噪声”。就像给音频画上高亮荧光笔:绿色段落是有效语音,灰色段落是该跳过的空白。
FSMN VAD,正是阿里达摩院FunASR项目中开源的工业级VAD模型。它小(仅1.7MB)、快(处理速度是实时的33倍)、准(中文场景下误检率低),而且已经打包成开箱即用的WebUI镜像——这就是本文要带你一步步上手的主角。
不用装Python、不用配环境、不用写代码。只要你有浏览器,就能让这段“听觉过滤器”为你工作。
2. 镜像快速启动:三步完成部署
这个镜像由开发者“科哥”基于FunASR二次封装,核心是Gradio WebUI界面,所有操作都在网页里完成。整个过程不需要任何命令行基础,小白也能照着做。
2.1 启动前确认两件事
- 你的机器已安装 Docker(Windows/Mac用户推荐Docker Desktop,Linux用户请确保docker服务正在运行)
- 你的机器至少有 4GB可用内存(FSMN VAD本身很轻量,但Docker容器需基础资源)
小贴士:如果你还没装Docker,现在花5分钟去官网下载安装(https://www.docker.com/products/docker-desktop/),比折腾Python环境省心10倍。
2.2 一键拉取并运行镜像
打开终端(Mac/Linux)或命令提示符(Windows),粘贴执行以下命令:
docker run -d \
--name fsmn-vad \
-p 7860:7860 \
-v $(pwd)/output:/root/output \
--gpus all \
registry.cn-hangzhou.aliyuncs.com/compshare/fsmn-vad:latest
命令说明(你只需知道这三点):
-p 7860:7860:把容器里的7860端口映射到你电脑的7860端口,这是WebUI的默认入口-v $(pwd)/output:/root/output:把你当前文件夹下的output文件夹,挂载为容器内保存结果的位置(自动创建)--gpus all:如果显卡支持CUDA,会自动启用GPU加速;没有NVIDIA显卡也完全没问题,CPU版一样流畅
注意:首次运行会自动下载镜像(约300MB),需要一点时间。看到一长串字母数字开头的容器ID(如
a1b2c3d4e5)就说明启动成功了。
2.3 打开网页,进入系统
在浏览器地址栏输入:
http://localhost:7860
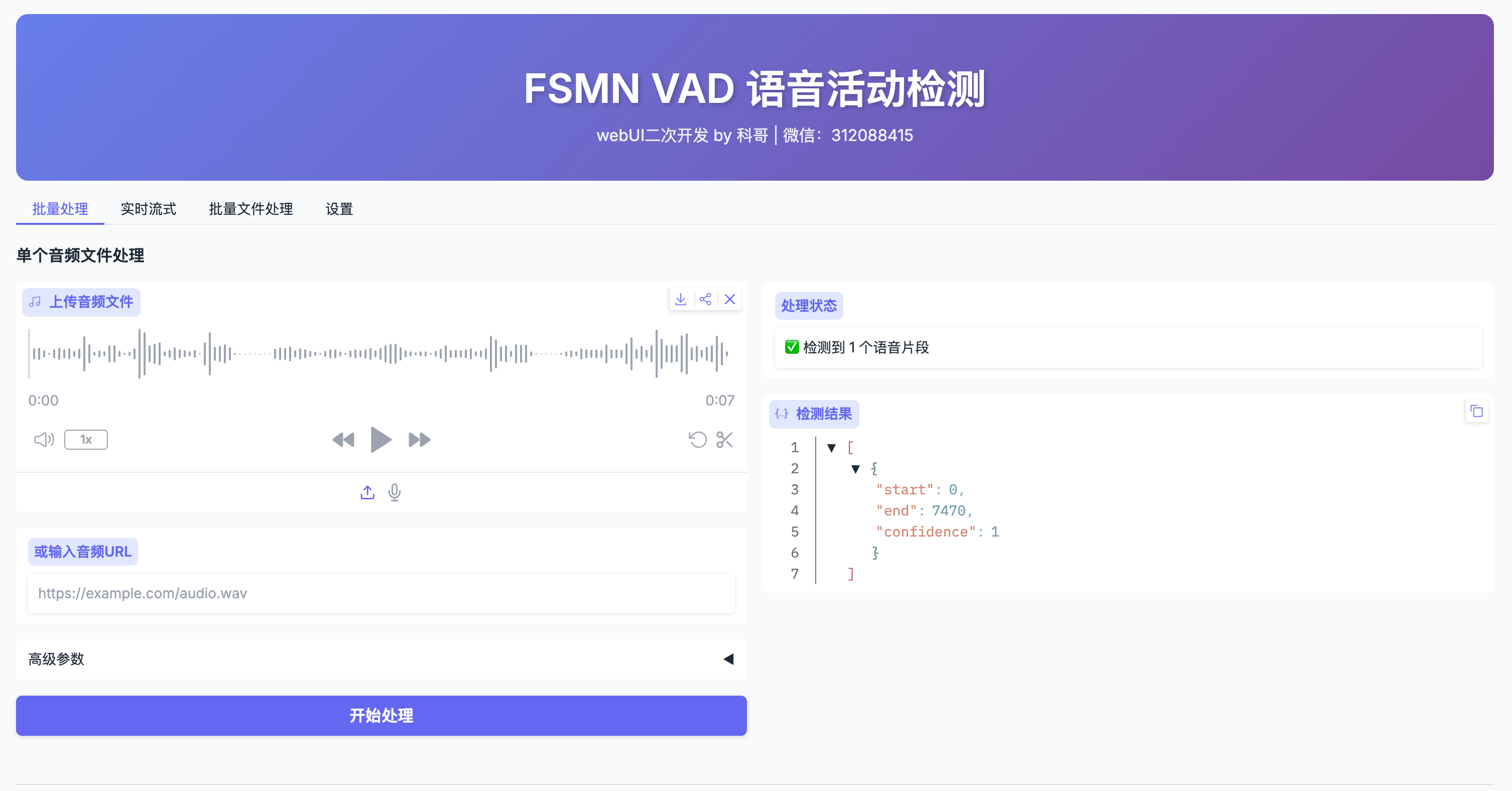
你将看到一个简洁的蓝色界面,顶部有四个Tab:“批量处理”、“实时流式”、“批量文件处理”、“设置”。这就是FSMN VAD的全部操作面板。
验证是否成功:点击右上角“设置”Tab,能看到“模型加载状态: 已加载”和“模型大小:1.7M”——说明一切就绪。
3. 核心功能实操:从上传音频到拿到时间戳
我们以最常用、最实用的“批量处理”模块为例,手把手走完一次完整流程。你将得到一份JSON格式的结果,精确到毫秒地告诉你:“语音从第70毫秒开始,到第2340毫秒结束”。
3.1 上传你的第一个音频文件
- 点击顶部Tab切换到 “批量处理”
- 在中间区域,你会看到一个虚线框,写着“上传音频文件”
- 方法一(推荐):直接把你的
.wav、.mp3、.flac或.ogg文件拖进去 - 方法二:点击虚线框,从文件浏览器中选择
小白友好提示:
- 如果你手头没有测试音频,可以点此下载示例文件(实际是.wav,命名带.png仅为兼容显示)
- 推荐优先使用
.wav格式(16kHz采样率、单声道、16bit),效果最稳;MP3也可用,但压缩可能引入轻微噪声
3.2 (可选)调整两个关键参数
刚接触时,强烈建议先用默认参数跑通一次。等熟悉后再微调。这里提前说明它们的作用,避免你被“专业术语”吓退:
| 参数名 | 实际含义 | 小白怎么理解 | 默认值 | 调整建议 |
|---|---|---|---|---|
| 尾部静音阈值 | “说完话后,等多久才敢认定人真的停了?” | 值越大,越“耐心”,不怕截断;值越小,越“急躁”,容易切碎 | 800ms | 会议录音→调大(1000~1500ms);快速对话→调小(500~700ms) |
| 语音-噪声阈值 | “多像人声才算‘语音’?多像噪音就该扔掉?” | 值越大,越“挑剔”,宁可漏判也不误判;值越小,越“宽容”,宁可误判也不漏判 | 0.6 | 嘈杂环境(地铁、菜市场)→调小(0.4~0.5);安静办公室→调大(0.7~0.8) |
怎么调?点击“高级参数”按钮展开,滑动条即可调节。调完不用点“保存”,直接下一步生效。
3.3 开始处理 & 查看结果
- 点击 “开始处理” 按钮(蓝色,居中)
- 等待几秒钟(70秒音频仅需约2秒),页面下方会出现结果区域
你会看到两部分内容:
- 处理状态:例如 “检测到 2 个语音片段”
- 检测结果:一个清晰的JSON代码块,类似这样:
[
{
"start": 70,
"end": 2340,
"confidence": 1.0
},
{
"start": 2590,
"end": 5180,
"confidence": 1.0
}
]
这就是你要的核心信息!
start: 语音开始时间(单位:毫秒 → 70ms = 0.07秒)end: 语音结束时间(2340ms = 2.34秒)confidence: 置信度(0~1之间,1.0表示模型非常确定这是语音)
🧩 后续能做什么?
- 把这些时间戳导入剪辑软件(如Audacity、Premiere),自动切出纯语音段
- 输入给语音识别模型(如FunASR的ASR模块),只识别“有效部分”,大幅提升准确率和速度
- 导入Excel计算总语音时长、平均语速、停顿次数等分析指标
4. 三个真实场景,教你参数怎么调
参数不是玄学。下面用你工作中最可能遇到的三个例子,告诉你“为什么这么调”、“调了有什么用”。
4.1 场景一:整理一场2小时技术分享会录音
痛点:发言人语速慢、习惯性停顿、结尾常有“呃…”“这个…”等语气词,用默认参数容易把一句话切成三四段。
操作:
- 上传会议录音(WAV格式最佳)
- 尾部静音阈值 → 调至 1200ms(比默认800ms更大)
- 语音-噪声阈值 → 保持默认 0.6(会议室通常安静)
- 点击“开始处理”
效果:
- 原本被切成“大家好…(停顿)…今天讲FSMN…(停顿)…它很轻量…”的片段,现在合并为一个连贯语音段
- 你导出的时间戳,可以直接作为剪辑标记,保留自然语流,避免生硬切割
4.2 场景二:分析一段嘈杂的门店客服电话录音
痛点:背景有收银机“滴”声、顾客交谈声、空调嗡鸣,模型容易把“滴”声误判为语音,导致结果里出现大量100ms左右的无效碎片。
操作:
- 上传电话录音(MP3也可)
- 尾部静音阈值 → 保持默认 800ms(电话对话节奏快,无需过度容忍停顿)
- 语音-噪声阈值 → 调至 0.75(提高判定门槛,过滤掉高频短促噪声)
- 点击“开始处理”
效果:
- 那些零散的“滴”声、咳嗽声、键盘敲击声基本消失
- 剩下的都是客服与顾客清晰、持续的对话片段,时长普遍在2~8秒,可直接用于质检或转录
4.3 场景三:批量检查100份录音是否有效(质量初筛)
痛点:收到一批用户上传的语音反馈,但其中混有静音文件、错误格式文件、全程播放广告的录音,人工听一遍太耗时。
操作:
- 不用调参数!直接用默认值(800ms + 0.6)
- 依次上传每个文件,观察“处理状态”
- 判断标准:
- 检测到 ≥1 个语音片段(且
end-start > 500ms)→ 有效录音,存入“待处理”文件夹 - 检测到 0 个语音片段,或只有多个<200ms的碎片 → 极大概率是静音/无效文件,移入“复核”文件夹
- 检测到 ≥1 个语音片段(且
效果:
- 100份录音,3分钟内完成初筛
- 人力从“逐个盲听”降为“只复核可疑文件”,效率提升20倍以上
5. 常见问题解答:小白最可能卡住的地方
我们把文档里分散的Q&A,按真实使用顺序重新梳理,直击痛点。
5.1 Q:上传后没反应,或者提示“处理失败”,怎么办?
A:先检查音频本身
- 用系统自带播放器(如Windows Media Player、QuickTime)打开,确认能正常播放
- 右键属性 → 查看“采样率”是否为 16000 Hz(16kHz)。如果不是,用免费工具Audacity转换:
文件 → 导入 → 音频→Tracks → Stereo Track to Mono→文件 → 导出 → 导出为WAV→在弹出窗口中,设置采样率:16000Hz
5.2 Q:检测结果里有语音片段,但时间戳看起来不对(比如start=0, end=100000)
A:大概率是音频开头有很长静音
- FSMN VAD默认会把“开头静音+第一段语音”连在一起判为一个片段
- 解决方案:在Audacity中裁掉前3秒静音,再上传
5.3 Q:处理速度慢?等了半分钟还没出结果
A:检查两点
- 是否上传了超大文件?单个文件建议 < 500MB(FSMN VAD对长音频优化极好,但极端大文件仍需时间)
- Docker是否被限资源?在Docker Desktop设置中,给Docker分配至少 3GB内存和2个CPU核心
5.4 Q:如何停止这个服务?不想让它一直运行
A:两种安全方式
- 图形化:打开Docker Desktop → 在Containers/Apps列表找到
fsmn-vad→ 点击右侧“STOP”按钮 - 命令行:在终端执行
docker stop fsmn-vad
再次启动?只需
docker start fsmn-vad,无需重新拉取镜像。
6. 进阶技巧:让VAD成为你工作流的智能开关
当你熟悉基础操作后,这几个技巧能让效率再上一个台阶。
6.1 把结果直接变成可编辑的字幕(SRT格式)
FSMN VAD本身不生成字幕,但它的JSON输出是完美起点。用任意文本编辑器(如记事本),把结果改成SRT格式只需三步:
- 复制JSON中的
start和end值 - 换算成SRT时间码(格式:
00:00:00,000 --> 00:00:02,340)- 70ms →
00:00:00,070 - 2340ms →
00:00:02,340
- 70ms →
- 按SRT标准格式填写:
1
00:00:00,070 --> 00:00:02,340
[语音片段1]
2
00:00:02,590 --> 00:00:05,180
[语音片段2]
自动化提示:用Python写个5行脚本就能批量转换(需要时可留言索取)。
6.2 用命令行批量处理(适合程序员/自动化党)
虽然WebUI很友好,但如果你有100个文件要处理,点100次显然不现实。镜像内置了命令行接口:
# 进入容器内部
docker exec -it fsmn-vad /bin/bash
# 在容器内运行(示例)
python /root/app/vad_cli.py --input /root/test.wav --output /root/output/result.json
注意:你需要先把音频文件复制进容器(
docker cp test.wav fsmn-vad:/root/),或挂载包含音频的文件夹(启动时加-v /your/audio/folder:/root/audio)。
6.3 理解“置信度”的实际意义
confidence字段不是摆设。它代表模型对这一段是“真语音”的把握程度:
confidence == 1.0:几乎100%确定,通常是清晰、响亮、无干扰的语音confidence ≈ 0.8~0.9:较确定,可能有轻微背景音或语速较快confidence < 0.5:模型自己都犹豫,建议人工复核,或用更高阈值过滤
实用建议:在Excel中筛选
confidence < 0.7的片段,单独归类,作为重点质检对象。
7. 总结:你已经掌握了一项被低估的AI基建能力
回顾一下,你刚刚完成了:
从零部署一个工业级语音活动检测系统(无需编程基础)
上传任意常见格式音频,3秒内获得毫秒级精准时间戳
理解两个核心参数的真实含义,并能根据会议、电话、质检等场景灵活调整
解决了“上传失败”“结果不准”“速度慢”等新手最易卡壳的问题
掌握了将时间戳转化为字幕、批量处理、置信度过滤等进阶用法
FSMN VAD的价值,不在于它多炫酷,而在于它解决了语音AI流水线中最基础、最易被忽视的一环——没有干净的语音片段,再强的ASR模型也会被噪声拖垮,再好的TTS合成也会因静音而失真。
它就像一位沉默的守门人,站在所有语音应用的入口处,帮你把“声音”真正变成可计算、可分析、可落地的“数据”。
下一步,你可以:
- 把它和FunASR的ASR模块串联,构建端到端语音转文字流水线
- 将时间戳喂给视频剪辑工具,自动生成“发言人高光时刻”合集
- 用Python脚本定时扫描文件夹,实现无人值守的录音质检
技术从不遥远。你点开浏览器的那一刻,就已经站在了语音智能的门口。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献159条内容
已为社区贡献159条内容

{kind=link}
所有评论(0)